基于Python+WaveNet+MFCC+Tensorflow智能方言分类—深度学习算法应用(含全部工程源码)(三)
目录
- 前言
- 引言
- 总体设计
- 系统整体结构图
- 系统流程图
- 运行环境
- 模块实现
- 1. 数据预处理
- 2. 模型构建
- 1)定义模型结构
- 2)优化损失函数
- 3. 模型训练及保存
- 1)模型训练
- 2)模型保存
- 3)映射保存
- 相关其它博客
- 工程源代码下载
- 其它资料下载

前言
博主前段时间发布了一篇有关方言识别和分类模型训练的博客,在读者的反馈中发现许多小伙伴对方言的辨识和分类表现出浓厚兴趣。鉴于此,博主决定专门撰写一篇关于方言分类的博客,以满足读者对这一主题的进一步了解和探索的需求。上篇博客可参考:
《基于Python+WaveNet+CTC+Tensorflow智能语音识别与方言分类—深度学习算法应用(含全部工程源码)》
引言
本项目以科大讯飞提供的数据集为基础,通过特征筛选和提取的过程,选用WaveNet模型进行训练。旨在通过语音的梅尔频率倒谱系数(MFCC)特征,建立方言和相应类别之间的映射关系,解决方言分类问题。
首先,项目从科大讯飞提供的数据集中进行了特征筛选和提取。包括对语音信号的分析,提取出最能代表语音特征的MFCC,为模型训练提供有力支持。
其次,选择了WaveNet模型进行训练。WaveNet模型是一种序列生成器,用于语音建模,在语音合成的声学建模中,可以直接学习采样值序列的映射,通过先前的信号序列预测下一个时刻点值的深度神经网络模型,具有自回归的特点。
在训练过程中,利用语音的MFCC特征,建立了方言和相应类别之间的映射关系。这样,模型能够识别和分类输入语音的方言,并将其划分到相应的类别中。
最终,通过这个项目,实现了方言分类问题的解决方案。这对于语音识别、语音助手等领域具有实际应用的潜力,也有助于保护和传承各地区的语言文化。
总体设计
本部分包括系统整体结构图和系统流程图。
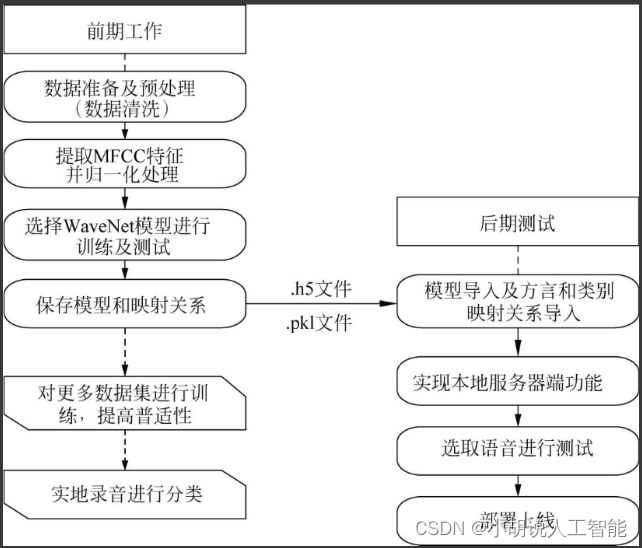
系统整体结构图
系统整体结构如图所示。
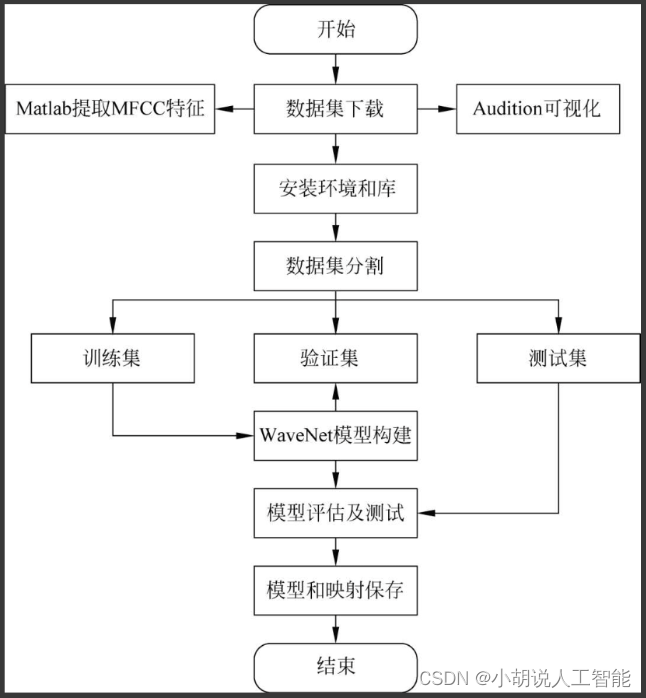
系统流程图
系统流程如图所示。
运行环境
本部分包括Python环境、TensorFlow环境、JupyterNotebook环境、PyCharm环境。
详见博客。
模块实现
本项目包括4个模块:数据预处理、模型构建、模型训练及保存、模型生成。下面分别给出各模块的功能介绍及相关代码。
1. 数据预处理
本部分包括数据介绍、数据测试和数据处理。
详见博客。
2. 模型构建
数据加载进模型之后,需要定义模型结构并优化损失函数。
1)定义模型结构
卷积层使用带洞因果卷积,卷积后的感知范围与卷积层数呈现指数级增长关系。WaveNet模型是一种序列生成器,用于语音建模,在语音合成的声学建模中,可以直接学习采样值序列的映射,通过先前的信号序列预测下一个时刻点值的深度神经网络模型,具有自回归的特点。相关代码如下:
epochs = 10#迭代次数
num_blocks = 3
filters = 128
#层叠
drop_rate = 0.25
#防止过拟合
X = Input(shape=(None, mfcc_dim,), dtype='float32')
#一维卷积
def conv1d(inputs, filters, kernel_size, dilation_rate):return Conv1D(filters=filters, kernel_size=kernel_size, strides=1, padding='causal', activation=None, dilation_rate=dilation_rate)(inputs)
#步长strides为1
#参数padding=’causal’即为采用因果卷积
def batchnorm(inputs):#批规范化函数return BatchNormalization()(inputs)#BN算法,每一层后增加了归一化层
def activation(inputs, activation):
#定义激活函数,实现神经元输入/输出之间的非线性化return Activation(activation)(inputs)
def res_block(inputs, filters, kernel_size, dilation_rate):
#残差块hf = activation(batchnorm(conv1d(inputs, filters, kernel_size, dilation_rate)), 'tanh')hg = activation(batchnorm(conv1d(inputs, filters, kernel_size, dilation_rate)), 'sigmoid')h0 = Multiply()([hf, hg])ha = activation(batchnorm(conv1d(h0, filters, 1, 1)), 'tanh')hs = activation(batchnorm(conv1d(h0, filters, 1, 1)), 'tanh')return Add()([ha, inputs]), hs
2)优化损失函数
通过Adam()方法进行梯度下降,动态调整每个参数的学习率,进行模型参数优化。
(“loss='categorical_crossentropy'”)。
#定义损失函数和优化器
optimizer = Adam(lr=0.01, clipnorm=5)
#Adam利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率
model = Model(inputs=X, outputs=Y)
model.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=['accuracy'])
#模块编译,采用交叉熵损失函数
lr_decay = ReduceLROnPlateau(monitor='loss', factor=0.2, patience=1, min_lr=0.000)
#ReduceLROnPlateau基于训练过程中的某些测量值对学习率进行动态下降
history = model.fit_generator( #使用fit_generator函数来进行训练generator=batch_generator(X_train, Y_train), steps_per_epoch=len(X_train) // batch_size,epochs=epochs, validation_data=batch_generator(X_dev, Y_dev), validation_steps=len(X_dev) // batch_size,
callbacks=[checkpointer, lr_decay])
3. 模型训练及保存
本部分包括模型训练、模型保存和映射保存。
1)模型训练
模型相关代码如下:
epochs = 10 #参数设置
num_blocks = 3
filters = 128
drop_rate = 0.25
X = Input(shape=(None, mfcc_dim,), dtype='float32') #输入数据
def conv1d(inputs, filters, kernel_size, dilation_rate): #卷积return Conv1D(filters=filters, kernel_size=kernel_size, strides=1, padding='causal', activation=None, dilation_rate=dilation_rate)(inputs)
def batchnorm(inputs): #批标准化return BatchNormalization()(inputs)
def activation(inputs, activation): #激活定义return Activation(activation)(inputs)
def res_block(inputs, filters, kernel_size, dilation_rate): #残差层hf = activation(batchnorm(conv1d(inputs, filters, kernel_size, dilation_rate)), 'tanh')hg = activation(batchnorm(conv1d(inputs, filters, kernel_size, dilation_rate)), 'sigmoid')h0 = Multiply()([hf, hg])ha = activation(batchnorm(conv1d(h0, filters, 1, 1)), 'tanh')hs = activation(batchnorm(conv1d(h0, filters, 1, 1)), 'tanh')return Add()([ha, inputs]), hs
#模型训练
h0 = activation(batchnorm(conv1d(X, filters, 1, 1)), 'tanh')
shortcut = []
for i in range(num_blocks):for r in [1, 2, 4, 8, 16]:h0, s = res_block(h0, filters, 7, r)shortcut.append(s) #直连
h1 = activation(Add()(shortcut), 'relu')
h1 = activation(batchnorm(conv1d(h1, filters, 1, 1)), 'relu')
#参数batch_size, seq_len, filters
h1 = batchnorm(conv1d(h1, num_class, 1, 1))
#参数batch_size, seq_len, num_class
#池化
h1 = GlobalMaxPooling1D()(h1) #参数batch_size,num_class
Y = activation(h1, 'softmax')
h1 = activation(Add()(shortcut), 'relu')
h1 = activation(batchnorm(conv1d(h1, filters, 1, 1)), 'relu')
#参数batch_size, seq_len, filters
h1 = batchnorm(conv1d(h1, num_class, 1, 1))
#参数batch_size, seq_len, num_class
h1 = GlobalMaxPooling1D()(h1) #参数batch_size, num_class
Y = activation(h1, 'softmax')
optimizer = Adam(lr=0.01, clipnorm=5)
model = Model(inputs=X, outputs=Y) #模型
model.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=['accuracy'])
checkpointer = ModelCheckpoint(filepath='fangyan.h5', verbose=0)
lr_decay = ReduceLROnPlateau(monitor='loss', factor=0.2, patience=1, min_lr=0.000)
history = model.fit_generator( #训练generator=batch_generator(X_train, Y_train), steps_per_epoch=len(X_train) // batch_size,epochs=epochs, validation_data=batch_generator(X_dev, Y_dev), validation_steps=len(X_dev) // batch_size, callbacks=[checkpointer, lr_decay])
训练输出结果如图所示。

通过观察训练集和测试集的损失函数、准确率大小来评估模型的训练程度,进行模型训练的进一步决策。训练集和测试集的损失函数(或准确率)不变且基本相等为模型训练的最佳状态。
可以将训练过程中保存的准确率和损失函数以图的形式表现出来,方便观察。
import matplotlib.pyplot as plt
#解决中文显示问题
plt.rcParams['font.sans-serif'] = ['KaiTi']
plt.rcParams['axes.unicode_minus'] = False
#解决保存图像中负号"-"显示为方块的问题
#指定默认字体
2)模型保存
为了能够在本地服务器调用模型,将模型保存为.h5格式的文件,Keras使用HDF5文件系统来保存模型,在使用过程中,需要Keras提供好的模型导入功能,即可加载模型。h5文件是层次结构。在数据集中还有元数据,即metadata对于每一个dataset而言,除了数据本身之外,这个数据集还有很多的属性信息。HDF5同时支持存储数据集对应的属性信息,所有属性信息的集合叫metadata。
相关代码如下:
model = Model(inputs=X, outputs=Y) #模型
model.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=['accuracy']) #参数输出
checkpointer = ModelCheckpoint(filepath='fangyan.h5', verbose=0)
#模型的保存,保存路径是filepath
3)映射保存
保存方言与类别之间的映射关系,将映射文件保存为.pkl格式,以便调用,pkl是Python保存文件的一种格式,该存储方式可以将Python项目过程中用到的一些临时变量或者需要提取、暂存的字符串、列表、字典等数据保存,使用pickle模块可将任意一个Python对象转换成系统字节。
相关代码如下:
with open('resources.pkl', 'wb') as fw:pickle.dump([class2id, id2class, mfcc_mean, mfcc_std], fw)
相关其它博客
基于Python+WaveNet+MFCC+Tensorflow智能方言分类—深度学习算法应用(含全部工程源码)(一)
基于Python+WaveNet+MFCC+Tensorflow智能方言分类—深度学习算法应用(含全部工程源码)(二)
基于Python+WaveNet+MFCC+Tensorflow智能方言分类—深度学习算法应用(含全部工程源码)(四)
工程源代码下载
详见本人博客资源下载页
其它资料下载
如果大家想继续了解人工智能相关学习路线和知识体系,欢迎大家翻阅我的另外一篇博客《重磅 | 完备的人工智能AI 学习——基础知识学习路线,所有资料免关注免套路直接网盘下载》
这篇博客参考了Github知名开源平台,AI技术平台以及相关领域专家:Datawhale,ApacheCN,AI有道和黄海广博士等约有近100G相关资料,希望能帮助到所有小伙伴们。
相关文章:
基于Python+WaveNet+MFCC+Tensorflow智能方言分类—深度学习算法应用(含全部工程源码)(三)
目录 前言引言总体设计系统整体结构图系统流程图 运行环境模块实现1. 数据预处理2. 模型构建1)定义模型结构2)优化损失函数 3. 模型训练及保存1)模型训练2)模型保存3)映射保存 相关其它博客工程源代码下载其它资料下载…...
(第5天)进阶 RHEL 7 安装单机 Oracle 19C NON-CDB 数据库
进阶 RHEL 7 安装单机 Oracle 19C NON-CDB 数据库(第5天) 真快,实战第 5 天了,我们来讲讲 19C 的数据库安装吧!19C 是未来几年 Oracle 数据库的大趋势,同样的作为长期稳定版,11GR2 在 2020 年 10 月份官方就宣布停止 Support 了,19C 将成为新的长期稳定版,并持续支持…...
AI自动生成代码工具
AI自动生成代码工具是一种利用人工智能技术来辅助或自动化软件开发过程中的编码任务的工具。这些工具使用机器学习和自然语言处理等技术,根据开发者的需求生成相应的源代码。以下是一些常见的AI自动生成代码工具,希望对大家有所帮助。北京木奇移动技术有…...

jmeter和postman的对比
1.创建接口用例集(没区别) Postman是Collections,Jmeter是线程组,没什么区别。 2.步骤的实现(有区别) Postman和jmeter都是创建http请求 区别1:postman请求的请求URL是一个整体,j…...

深度学习在人体动作识别领域的应用:开源工具、数据集资源及趋动云GPU算力不可或缺
人体动作识别检测是一种通过使用计算机视觉和深度学习技术,对人体姿态和动作进行实时监测和分析的技术。该技术旨在从图像或视频中提取有关人体姿态、动作和行为的信息,以便更深入地识别和理解人的活动。 人体动作识别检测的基本步骤包括: 数…...
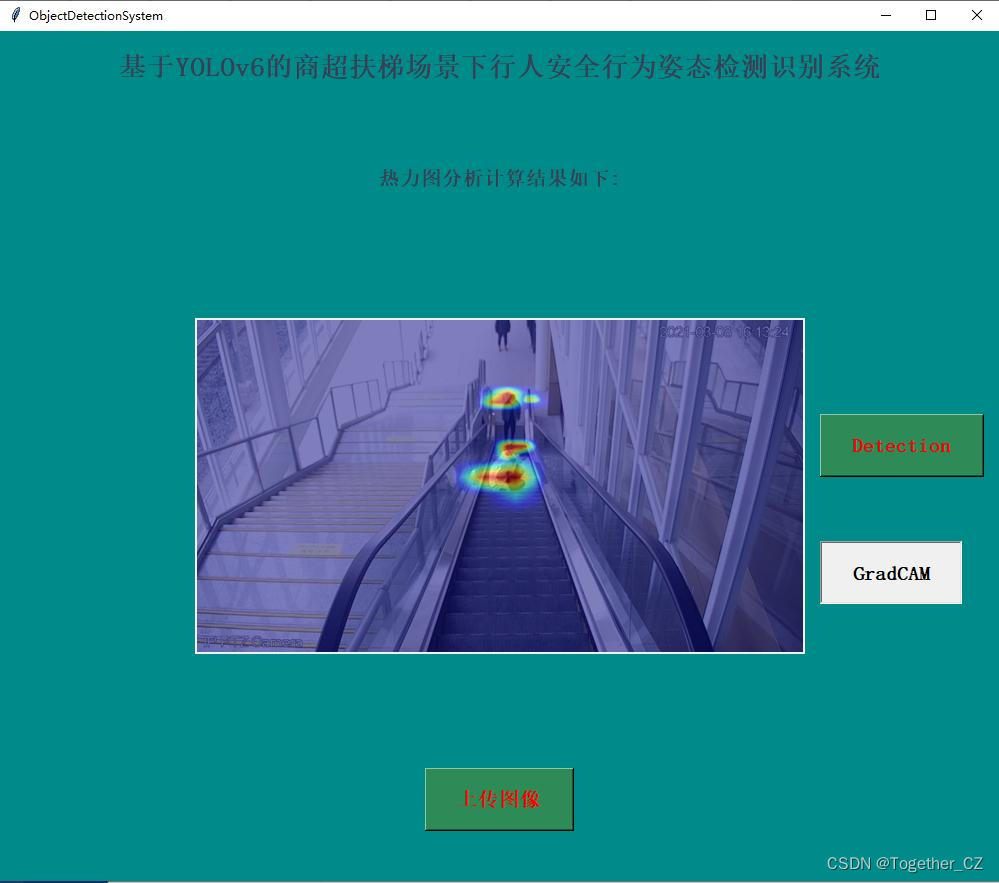
科技提升安全,基于YOLOv6开发构建商超扶梯场景下行人安全行为姿态检测识别系统
在商超等人流量较为密集的场景下经常会报道出现一些行人在扶梯上摔倒、受伤等问题,随着AI技术的快速发展与不断普及,越来越多的商超、地铁等场景开始加装专用的安全检测预警系统,核心工作原理即使AI模型与摄像头图像视频流的实时计算…...
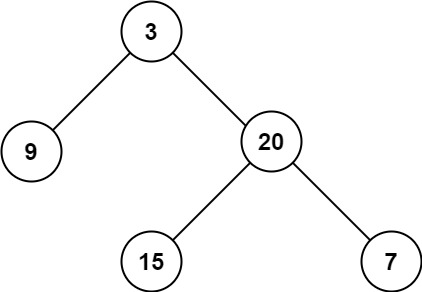
二叉树的最大深度
问题描述: 给定一个二叉树 root ,返回其最大深度。 二叉树的 最大深度 是指从根节点到最远叶子节点的最长路径上的节点数。 示例 1: 输入:root [3,9,20,null,null,15,7] 输出:3示例 2: 输入࿱…...
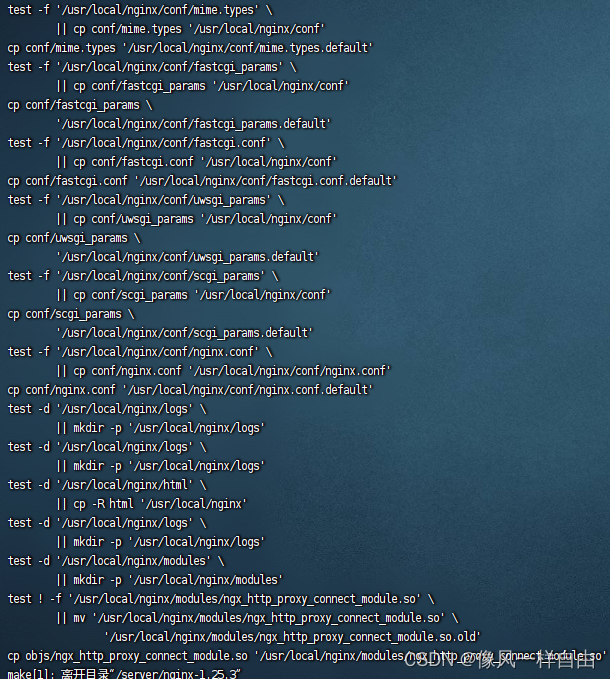
nginx配置正向代理支持https
操作系统版本: Alibaba Cloud Linux 3.2104 LTS 64位 nginx版本: nginx-1.25.3 1. 下载软件 切换目录 cd /server wget http://nginx.org/download/nginx-1.25.3.tar.gz 1.1解压 tar -zxvf nginx-1.25.3.tar.gz 1.2切换到源码所在目录…...

奥比中光 Femto Bolt相机ROS配置
机械臂手眼标定详解 作者: Herman Ye Auromix 测试环境: Ubuntu20.04/22.04 、ROS1 Noetic/ROS2 Humble、X86 PC/Jetson Orin、Kinect DK/Femto Bolt 更新日期: 2023/12/12 注1: Auromix 是一个机器人爱好者开源组织。 注2&#…...

scala表达式
1.8 表达式(重点) # 语句(statement):一段可执行的代码# 表达式(expression):一段可以被求值的代码,在Scala中一切都是表达式 - 表达式一般是一个语句块,可包含一条或者多条语句,多条语句使用“…...
uniapp,点击选中并改变颜色,第二次点击取消选中状态
一、效果图 二、代码实现 字符串的indexOf和数组的indexOf用法一致! arr.indexOf(item) 该方法返回某个元素在数组中的位置。若没检索到,则返回 -1。 关键代码:(通过:class绑定) :class"selectList.indexOf(sub.type) ! -1 ? right_ite…...

mmyolo的bbox_loss和检测bbox都是空
最近用mmyolo训练自己的数据集的时候发现训练的时候loss_bbox0,测试和eval的时候结果也全是空的,排除了数据集读取的问题,最后发现是config中自定义了自己的类别但是没有传给dataset。。。 简而言之,在自定义了数据集里的metainf…...
Linux——基本指令(二)
个人主页:日刷百题 系列专栏:〖C语言小游戏〗〖Linux〗〖数据结构〗 〖C语言〗 🌎欢迎各位→点赞👍收藏⭐️留言📝 写在前面: 紧接上一章,我们在理解接下来的命令之前,…...
渲染农场对工业产品渲染带来的意义与优势?
随着科技的进步,利用精细渲染图来呈现和推广工业设计的创新已成为行业标准。这些图像在产品研发、设计评审和营销阶段起着关键作用,同时对产品最终的成功也产生深远影响。然而,由于产品设计日渐复杂,制作渲染图的任务变得极具挑战…...
产品入门第二讲:Axure产品元件库的使用
📚📚 🏅我是默,一个在CSDN分享笔记的博主。📚📚 🌟在这里,我要推荐给大家我的专栏《Axure》。🎯🎯 🚀无论你是编程小白,还是…...
Linux 静默安装单机 Oracle 19C 数据库)
(第7天)Linux 静默安装单机 Oracle 19C 数据库
Linux 静默安装安装单机 Oracle 19C 数据库(第7天) 很多朋友经常会问,如果生产环境不允许安装 Linux 图形化界面怎么办?是不是有其他的方式来安装部署 Oracle 数据库呢?答案是肯定的! 我们可以通过命令行的方式来静默安装,不调用图形化界面,当然也就没有那么简单了!…...

智能优化算法应用:基于入侵杂草算法3D无线传感器网络(WSN)覆盖优化 - 附代码
智能优化算法应用:基于入侵杂草算法3D无线传感器网络(WSN)覆盖优化 - 附代码 文章目录 智能优化算法应用:基于入侵杂草算法3D无线传感器网络(WSN)覆盖优化 - 附代码1.无线传感网络节点模型2.覆盖数学模型及分析3.入侵杂草算法4.实验参数设定5.算法结果6.…...
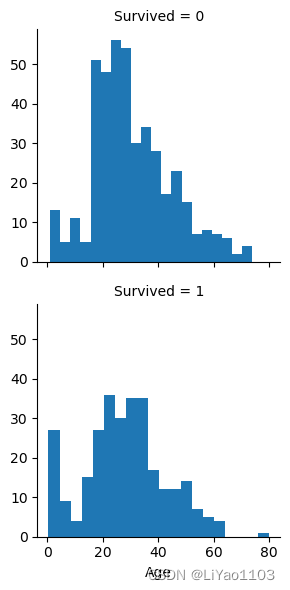
数据挖掘目标(Kaggle Titanic 生存测试)
import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns1.数据导入 In [2]: train_data pd.read_csv(r../老师文件/train.csv) test_data pd.read_csv(r../老师文件/test.csv) labels pd.read_csv(r../老师文件/label.csv)[Su…...
【Vue】router.push用法实现路由跳转
目录 router.push用法 在Login.vue中 在Register.vue中 上一篇:登录与注册界面的制作 https://blog.csdn.net/m0_67930426/article/details/134895214?spm1001.2014.3001.5502 制作了登录与注册界面,并介绍了相关表单元素即属性的用法 在登录页面…...
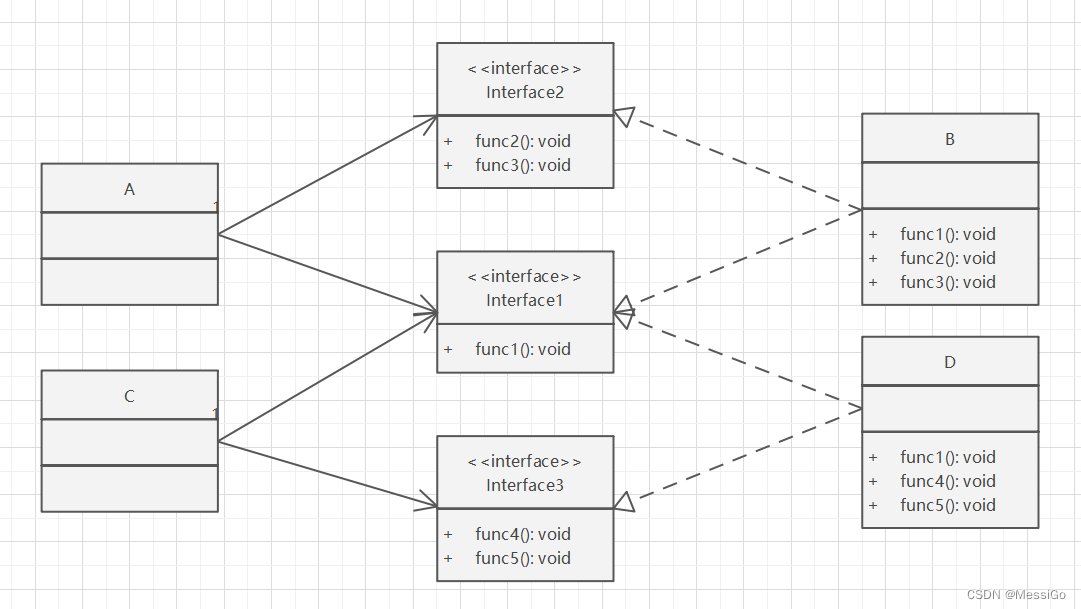
设计原则 | 接口隔离原则
一、接口隔离原则 1、原理 客户端不应该依赖它不需要的接口,即一个类对另一个类的依赖应该建立在最小的接口上。如果强迫客户端依赖于那些它们不使用的接口,那么客户端就面临着这个未使用的接口的改变所带来的变更,这无意间导致了客户程序之…...

TPFanCtrl2:ThinkPad笔记本风扇控制的终极自定义方案
TPFanCtrl2:ThinkPad笔记本风扇控制的终极自定义方案 【免费下载链接】TPFanCtrl2 ThinkPad Fan Control 2 (Dual Fan) for Windows 10 and 11 项目地址: https://gitcode.com/gh_mirrors/tp/TPFanCtrl2 对于ThinkPad用户而言,原厂的风扇控制策略…...

CANN/asc-devkit SIMD矢量加法
Adds 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.com/cann/…...

PostgreSQL列式存储革命:cstore_fdw完整指南与10个性能优化技巧
PostgreSQL列式存储革命:cstore_fdw完整指南与10个性能优化技巧 【免费下载链接】cstore_fdw Columnar storage extension for Postgres built as a foreign data wrapper. Check out https://github.com/citusdata/citus for a modernized columnar storage implem…...

如何一键自动化部署Office:LKY Office Tools完整配置指南
如何一键自动化部署Office:LKY Office Tools完整配置指南 【免费下载链接】LKY_OfficeTools 一键自动化 下载、安装、激活 Office 的利器。 项目地址: https://gitcode.com/GitHub_Trending/lk/LKY_OfficeTools 在Windows系统中安装Microsoft Office一直是个…...

不用真飞机!用BetaFlight遥控器玩转PX4无人机仿真:QGC配置与手动飞行入门
用BetaFlight遥控器解锁PX4仿真飞行:从硬件配置到手动操控全指南 当大多数PX4开发者还在用键盘和鼠标操作仿真无人机时,一群来自穿越机社区的玩家已经找到了更硬核的玩法——用真实的BetaFlight遥控器直接控制Gazebo里的虚拟飞行器。这种将硬件与仿真环境…...

企业Agent落地:从0到1搭建员工Agent体系
一、项目背景 某中型企业在数字化转型过程中遇到以下痛点: 合同审批流程平均耗时3天,效率低下员工每天约30%的时间花在重复操作上流程规则散落在员工经验中,难以标准化缺乏统一的操作审计和权限管理 二、落地路径 阶段一:验证…...
)
宇视DMX易用性推宣—即时回放进度条拖动(B3358P510版本开始支持)
一.功能介绍通过拖动进度条调整即时回放的时间点。即时回放:从当前时刻开始倒放回放画面,最多可倒放至24小时前,如无录像则无法回放。二.配置步骤1、进入平台【实况播放】界面,选中相机拖动到右侧窗格播放实…...

英雄联盟个性化工具终极指南:3分钟免费打造专属游戏身份
英雄联盟个性化工具终极指南:3分钟免费打造专属游戏身份 【免费下载链接】LeaguePrank 项目地址: https://gitcode.com/gh_mirrors/le/LeaguePrank 想要在英雄联盟中展示与众不同的个人资料吗?LeaguePrank是一款开源免费的英雄联盟个性化工具&am…...
)
Linux 系统编程 文件篇 (二)
[TOC] Linux 系统编程 文件篇 (二) 1 open 函数介绍 1.1 标记位 上一篇的结尾,我们讲到了我们用的打开文件的库函数其实是封装了,这个 open 的系统调用,然后解释了这个 open 函数的 这个标记位,flags 是一个…...

Sub-agent 协同失效的 3 类边界场景:Claude Code 8.1 机制原理解析
1. Sub-agent 协同失效不是 Bug,是机制在“按说明书执行” 大多数人第一次遇到 Sub-agent 返回空响应、反复循环调用主 Agent、或在多轮协作后突然“忘记”前序任务时,第一反应是:配置错了?网络不稳定?模型退化了?我试过把 claude-code 从 8.0.3 升到 8.1.1,又降回 8.0…...