安装LLaMA-Factory微调chatglm3,修改自我认知
安装git clone https://github.com/hiyouga/LLaMA-Factory.git
conda create -n llama_factory python=3.10
conda activate llama_factory
cd LLaMA-Factory
pip install -r requirements.txt
之后运行
单卡训练,
CUDA_VISIBLE_DEVICES=0 python src/train_web.py,按如下配置
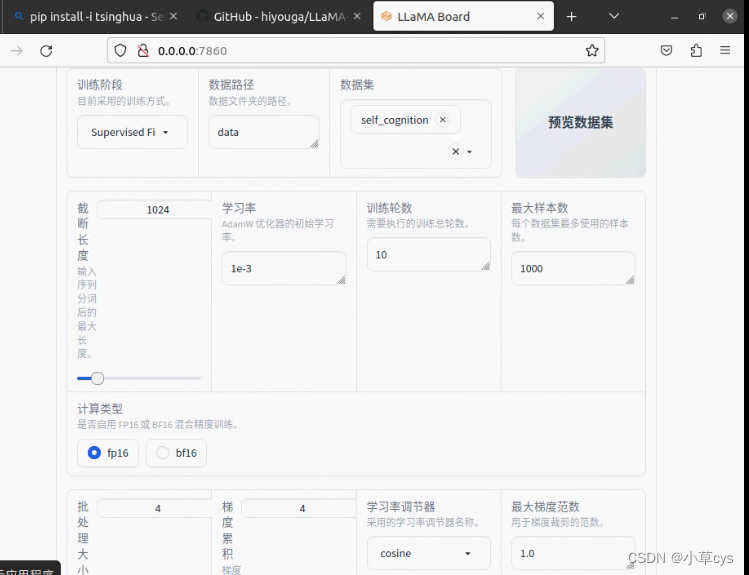
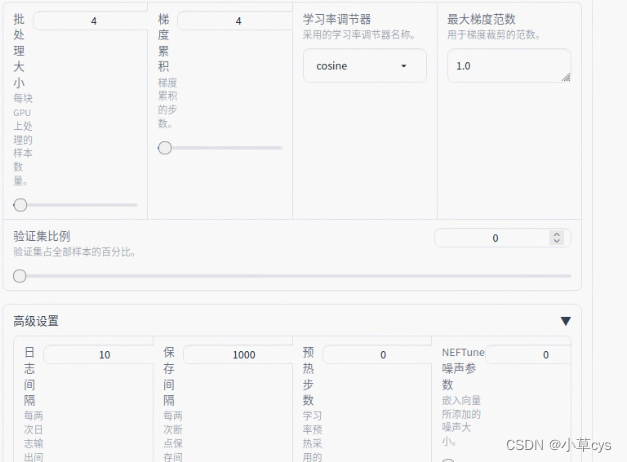
demo_tran.sh
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py \--stage sft \--model_name_or_path /data/models/llm/chatglm3-lora/ \--do_train \--overwrite_output_dir \--dataset self_cognition \--template chatglm3 \--finetuning_type lora \--lora_target query_key_value \--output_dir export_chatglm3 \--overwrite_cache \--per_device_train_batch_size 4 \--gradient_accumulation_steps 4 \--lr_scheduler_type cosine \--logging_steps 10 \--save_steps 1000 \--learning_rate 1e-3 \--num_train_epochs 10.0 \--plot_loss \--fp16export_model.sh
python src/export_model.py \--model_name_or_path /data/models/llm/chatglm3-lora/ \--template chatglm3 \--finetuning_type lora \--checkpoint_dir /data/projects/LLaMA-Factory/export_chatglm3 \--export_dir lora_merge_chatglm3cli_demo.sh
python src/cli_demo.py \--model_name_or_path /data/models/llm/chatglm3-lora/ \--template default \--finetuning_type lora 注意合并模型的时候,最后复制chatglm3的tokenizer.model和tokenizer_config.json到合并后模型覆盖之后,要修改
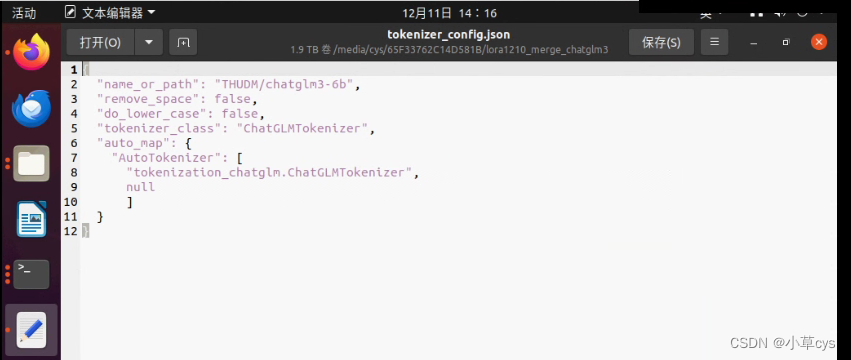
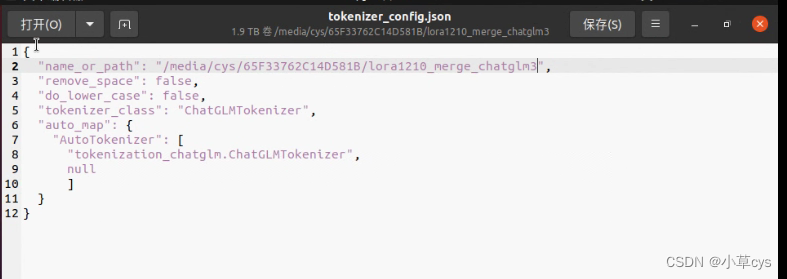 不覆盖会有这个错误,
不覆盖会有这个错误,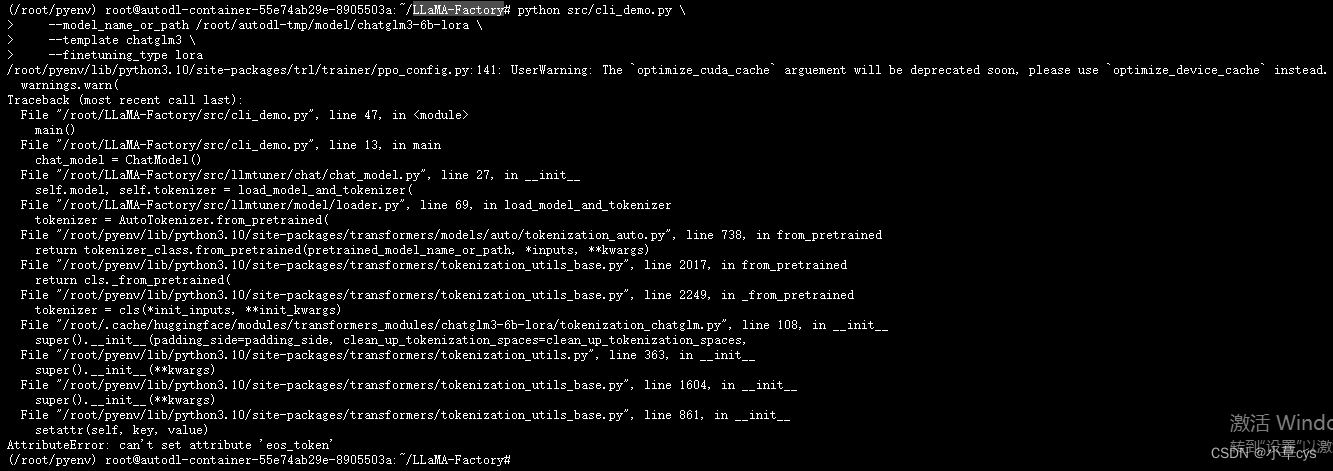
Use DeepSpeed方法
deepspeed --num_gpus 3 --master_port=9901 src/train_bash.py \--deepspeed ds_config.json \--stage sft \--model_name_or_path /media/cys/65F33762C14D581B/chatglm2-6b \--do_train True \--finetuning_type lora \--template chatglm2 \--flash_attn False \--shift_attn False \--dataset_dir data \--dataset self_cognition,sharegpt_zh \--cutoff_len 1024 \--learning_rate 0.001 \--num_train_epochs 10.0 \--max_samples 1000 \--per_device_train_batch_size 4 \--gradient_accumulation_steps 4 \--lr_scheduler_type cosine \--max_grad_norm 1.0 \--logging_steps 10 \--save_steps 1000 \--warmup_steps 0 \--neft_alpha 0 \--train_on_prompt False \--upcast_layernorm False \--lora_rank 8 \--lora_dropout 0.1 \--lora_target query_key_value \--resume_lora_training True \--output_dir saves/ChatGLM2-6B-Chat/lora/train_2023-12-12-23-26-49 \--fp16 True \--plot_loss Trueds_config.json的格式下面的:
{"train_batch_size": "auto","train_micro_batch_size_per_gpu": "auto","gradient_accumulation_steps": "auto","gradient_clipping": "auto","zero_allow_untested_optimizer": true,"fp16": {"enabled": "auto","loss_scale": 0,"initial_scale_power": 16,"loss_scale_window": 1000,"hysteresis": 2,"min_loss_scale": 1}, "zero_optimization": {"stage": 2,"allgather_partitions": true,"allgather_bucket_size": 5e8,"reduce_scatter": true,"reduce_bucket_size": 5e8,"overlap_comm": false,"contiguous_gradients": true}
}跑成功的效果图:

如果出现下面 这个问题,
[E ProcessGroupNCCL.cpp:916] [Rank 3] NCCL watchdog thread terminated with exception: CUDA error: the launch timed out and was terminated CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect. For debugging consider passing CUDA_LAUNCH_BLOCKING=1. Compile with `TORCH_USE_CUDA_DSA` to enable device-side assertions.
可能原因是显卡坏了或者显卡不是同一个型号!
相关文章:
安装LLaMA-Factory微调chatglm3,修改自我认知
安装git clone https://github.com/hiyouga/LLaMA-Factory.git conda create -n llama_factory python3.10 conda activate llama_factory cd LLaMA-Factory pip install -r requirements.txt 之后运行 单卡训练, CUDA_VISIBLE_DEVICES0 python src/train_web.py…...
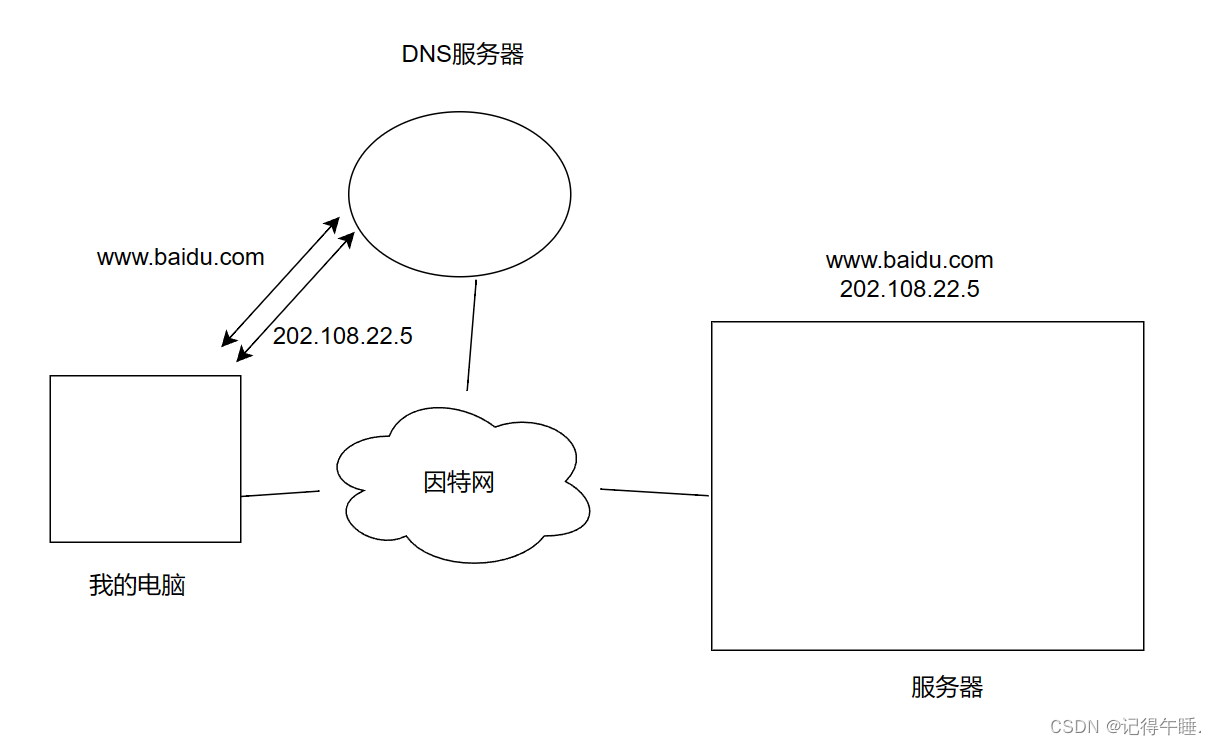
以太网协议与DNS
以太网协议 以太网协议DNS 以太网协议 以太网用于在计算机和其他网络设备之间传输数据,以太网既包含了数据链路层的内容,也包含了物理层的内容. 以太网数据报: 其中目的IP和源IP不是网络层的目的IP和源IP,而是mac地址.网络层的主要负责是整体的转发过程,数据链路层负责的是局…...

Spring Boot的日志
打印日志 打印日志的步骤: • 在程序中得到日志对象. • 使用日志对象输出要打印的内容 在程序中得到日志对象 在程序中获取日志对象需要使用日志工厂LoggerFactory,代码如下: package com.example.demo;import org.slf4j.Logger; import org.slf4j.LoggerFactory;public c…...
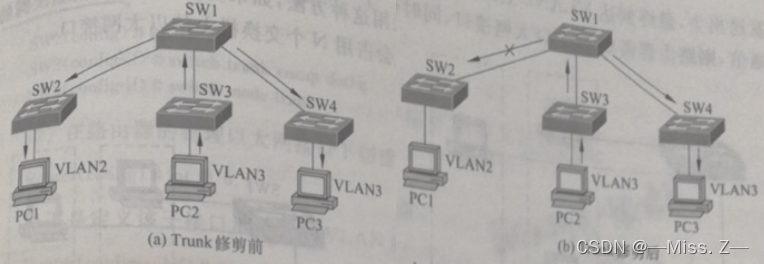
Cisco Packet Tracer配置命令——交换机篇
交换机VLAN配置 在简单的网络环境中,当交换机配置完端口后,即可直接应用,但若在复杂或规模较大的网络环境中,一般还要进行VLAN的规划,因此在交换机上还需进行 VLAN 的配置。交换机的VLAN配置工作主要有VLAN的建立与删…...

python单例模式
设计模式:单例模式(Singleton Pattern)。单例模式确保一个类只有一个实例,并提供一个全局访问点来获取这个实例。 class Singleton:_instance Nonedef __new__(cls):if cls._instance is None:cls._instance super().__new__(cl…...

环境保护:人类生存的最后机会
随着科技的进步和人类文明的不断发展,地球上的自然资源也在以惊人的速度消耗殆尽。人类对于环境的无止境的掠夺,使得我们的地球正面临着前所未有的环境危机。环境污染、全球变暖、大规模灭绝等问题不断困扰着我们,似乎指向了人类生存的最后机…...
头歌-Python 基础
第1关:建模与仿真 1、 建模过程,通常也称为数学优化建模(Mathematical Optimization Modeling),不同之处在于它可以确定特定场景的特定的、最优化或最佳的结果。这被称为诊断一个结果,因此命名为▁▁▁。 填空1答案:决…...
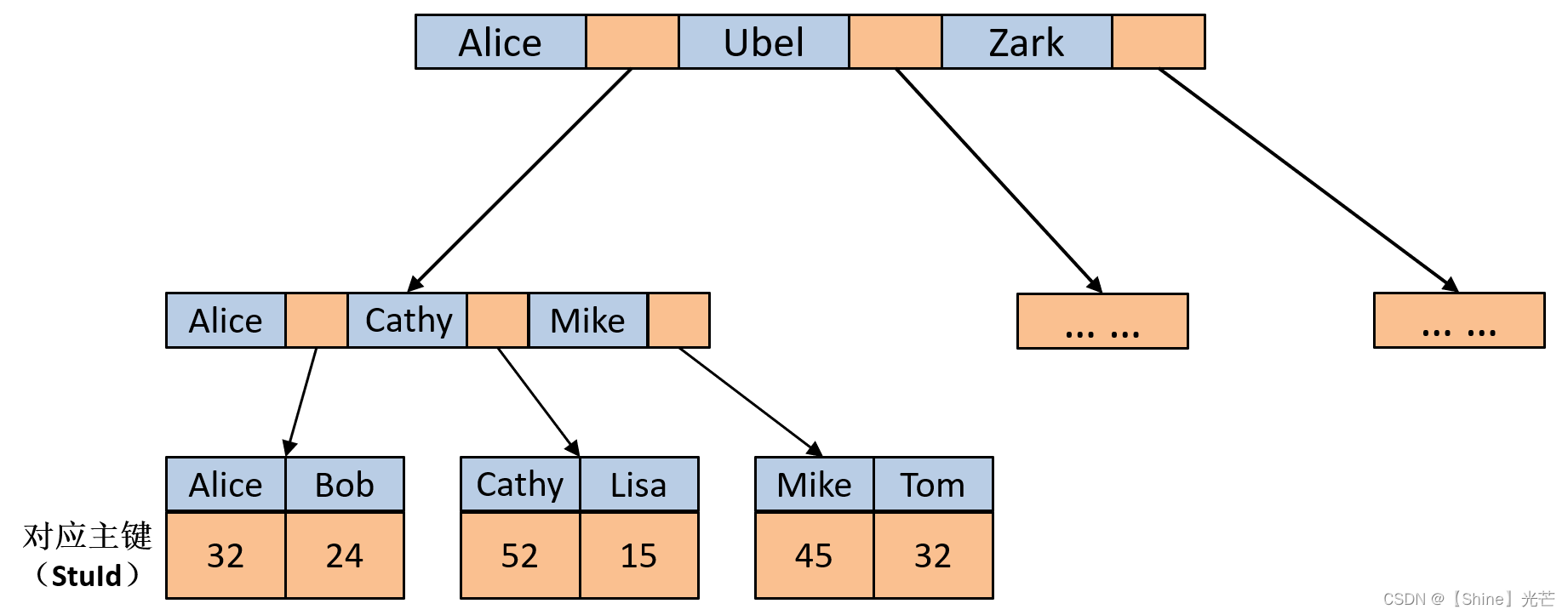
C++数据结构:B树
目录 一. 常见的搜索结构 二. B树的概念 三. B树节点的插入和遍历 3.1 插入B树节点 3.2 B树遍历 四. B树和B*树 4.1 B树 4.2 B*树 五. B树索引原理 5.1 索引概述 5.2 MyISAM 5.3 InnoDB 六. 总结 一. 常见的搜索结构 表示1为在实际软件开发项目中,常用…...

【07】ES6:对象的扩展
一、对象字面量语法扩展 1、属性简写 当属性名称和属性值的变量名称相同时,可以省略冒号的变量名称。 const foo barconst baz { foo } // 等同于 const baz { foo: foo }baz // { foo: bar }function f(x, y) {return { x, y } } // 等同于 function f(x, y)…...
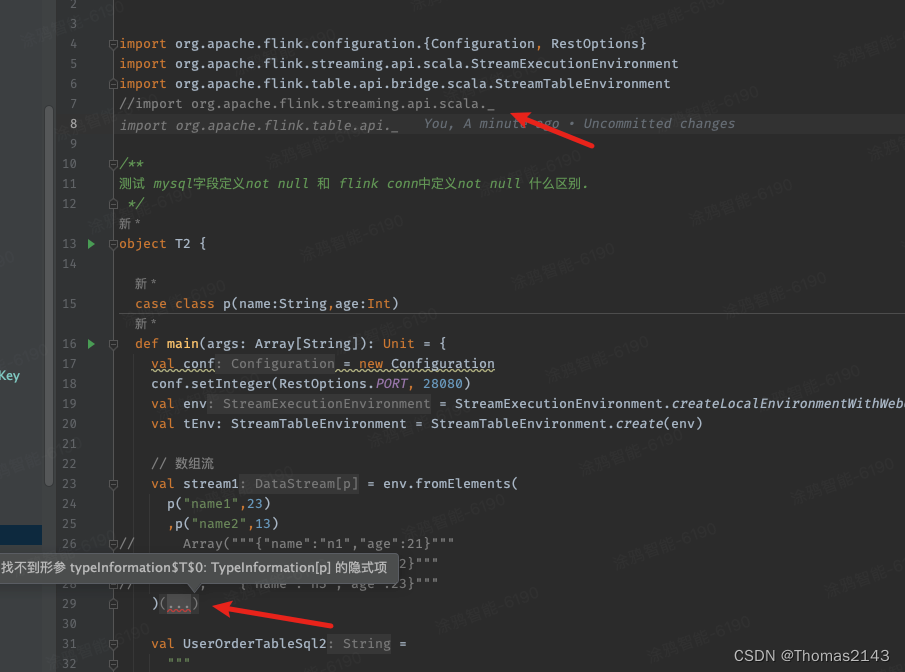
flink找不到隐式项
增加 import org.apache.flink.streaming.api.scala._ 即可...

【网络编程】-- 04 UDP
网络编程 6 UDP 6.1 初识Tomcat 服务端 自定义 STomcat S 客户端 自定义 C浏览器 B 6.2 UDP 6.2.1 udp实现发送消息 接收端: package com.duo.lesson03;import java.net.DatagramPacket; import java.net.DatagramSocket; import java.net.SocketExceptio…...

【脚本】图片-音视频-压缩文件处理
音视频处理 一,图片操作1,转换图片格式2,多张图片合成视频 二,音频操作1,转换音频格式2,分割音频为多段3,合成多段音频 三,视频操作1,转换视频格式2,提取视频…...

跨品牌的手机要怎样相互投屏?iPhone和iPad怎么相互投屏?
选择买不同品牌的手机是基于品牌声誉、产品特点、价格和性价比等多个因素的综合考虑。每个人的需求和偏好不同,选择适合自己的手机品牌是一个个人化的决策。 一些品牌可能更加注重摄影功能,而其他品牌可能更加注重性能和速度。选择不同品牌的手机可以根据…...
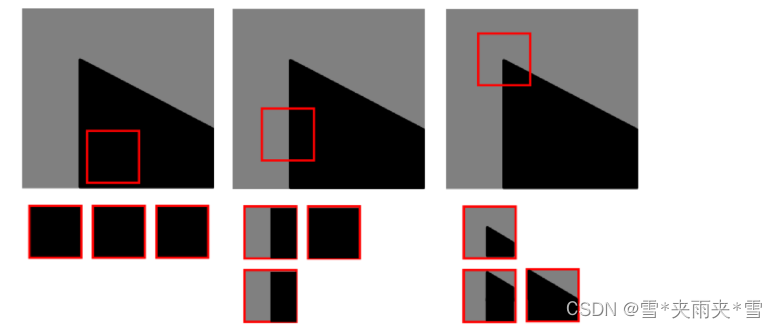
图像特征提取-角点
角点特征 大多数人都玩过拼图游戏。首先拿到完整图像的碎片,然后把这些碎片以正确的方式排列起来从而重建这幅图像。如果把拼图游戏的原理写成计算机程序,那计算机就也会玩拼图游戏了。 在拼图时,我们要寻找一些唯一的特征,这些…...
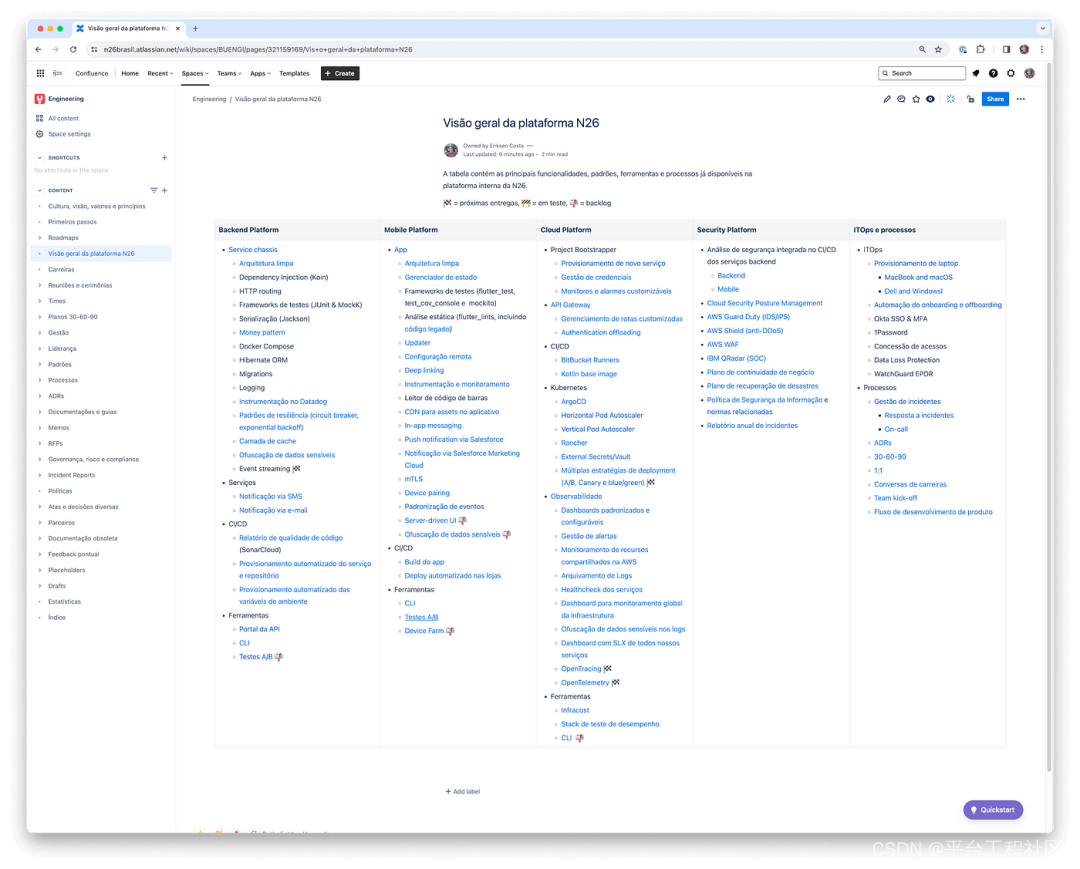
N26:构建无缝体验的平台工程之路-Part 2
在第一部分,我们介绍了 N26 团队为达成 “在 Day 1 实现轻松部署” 的目标而设定的战略规划和开发人员体验图,在这一部分,我们将带您了解该团队如何构建最简可行平台以及该平台如何运作。 01 计划构建最简可行平台 我们通…...

【Hadoop-Distcp】通过Distcp的方式进行两个HDFS集群间的数据迁移
【Hadoop-Distcp】通过Distcp的方式进行两个HDFS集群间的数据迁移 1)Distcp 工具简介及参数说明2)Shell 脚本 1)Distcp 工具简介及参数说明 【Hadoop-Distcp】工具简介及参数说明 2)Shell 脚本 应用场景: 两个实时集…...
【Linux】使用Bash和GNU Parallel并行解压缩文件
介绍 在本教程中,我们将学习如何使用Bash脚本和GNU Parallel实现高效并行解压缩多个文件。这种方法在处理大量文件时可以显著加快提取过程。 先决条件 确保系统上已安装以下内容: BashGNU Parallel 你可以使用以下命令在不同Linux系统上安装它们&am…...

T天池SQL训练营(五)-窗口函数等
–天池龙珠计划SQL训练营 5.1窗口函数 5.1.1窗口函数概念及基本的使用方法 窗口函数也称为OLAP函数。OLAP 是OnLine AnalyticalProcessing 的简称,意思是对数据库数据进行实时分析处理。 为了便于理解,称之为窗口函数。常规的SELECT语句都是对整张表进…...

道可云元宇宙每日资讯|上海市区块链关键技术攻关专项项目立项清单公布
道可云元宇宙每日简报(2023年12月11日)讯,今日元宇宙新鲜事有: 上海市2023年度区块链关键技术攻关专项项目立项清单公布 据上海市科学技术委员会近日发布通知,上海市2023年度“科技创新行动计划”区块链关键技术攻关…...

大语言模型有什么意义?亚马逊训练自己的大语言模型有什么用?
近年来,大语言模型的崭露头角引起了广泛的关注,成为科技领域的一项重要突破。而在这个领域的巅峰之上,亚马逊云科技一直致力于推动人工智能的发展。那么,作为一家全球科技巨头,亚马逊为何会如此注重大语言模型的研发与…...

VSCode光标主题定制指南:从颜色令牌到扩展开发
1. 项目概述:一个为开发者定制的光标主题集合如果你和我一样,每天有超过8小时的时间都泡在代码编辑器里,那么你一定会对编辑器里那个千篇一律的、闪烁的竖线光标感到审美疲劳。warrenwoodhouse/cursors这个项目,就是来解决这个“小…...

Adobe-GenP终极指南:5分钟破解Adobe创意套件限制的完整教程
Adobe-GenP终极指南:5分钟破解Adobe创意套件限制的完整教程 【免费下载链接】Adobe-GenP Adobe CC 2019/2020/2021/2022/2023 GenP Universal Patch 3.0 项目地址: https://gitcode.com/gh_mirrors/ad/Adobe-GenP 你是否曾因为Adobe Creative Cloud高昂的订阅…...

Solidworks PDM二次开发实战:文件夹权限与数据卡配置详解
1. Solidworks PDM二次开发入门指南 如果你正在使用Solidworks PDM管理产品数据,可能会遇到需要批量创建文件夹并设置权限的场景。比如新项目启动时,需要为不同部门创建标准化的文件夹结构,同时设置工程师只读、管理员完全控制的权限规则。手…...

Zotero插件市场:三步快速上手的插件管理神器
Zotero插件市场:三步快速上手的插件管理神器 【免费下载链接】zotero-addons Zotero Add-on Market | Zotero插件市场 | Browsing, installing, and reviewing plugins within Zotero 项目地址: https://gitcode.com/gh_mirrors/zo/zotero-addons 想象一下&a…...

使用mcp-maker快速构建AI工具调用服务器:从协议原理到工程实践
1. 项目概述与核心价值最近在折腾AI应用开发,特别是想给大语言模型(LLM)装上更强大的“手脚”,让它能直接操作我电脑上的各种软件和工具。这听起来很酷,对吧?但实际操作起来,你会发现一个核心痛…...

【2026最新】鸿蒙NEXT ArkUI实战:培训班管理系统UI界面开发全攻略
鸿蒙UI开发总是踩坑?ArkUI组件用法记不住?本文用15分钟带你彻底搞懂ArkUI核心组件、布局系统、自定义组件和交互动画,附完整培训班管理系统实战代码和踩坑记录,让你的鸿蒙App界面从此丝滑流畅!一、培训班管理界面设计1…...

基于双线性插值的AMG8833热成像分辨率提升方案与嵌入式实现
1. 项目概述:从8x8到15x15,一次软件驱动的热成像分辨率革命如果你玩过基于AMG8833这类低成本红外热成像传感器的项目,大概率会对它那8x8的“马赛克”图像印象深刻——64个像素点,勉强能看出个温度轮廓,但细节ÿ…...

深度解析VS Code Live Server:高效前端开发实时预览配置秘籍
深度解析VS Code Live Server:高效前端开发实时预览配置秘籍 【免费下载链接】vscode-live-server Launch a development local Server with live reload feature for static & dynamic pages. 项目地址: https://gitcode.com/gh_mirrors/vs/vscode-live-serv…...

Arm Neoverse CMN-700架构与寄存器配置详解
1. Arm Neoverse CMN-700架构概览在现代多核处理器设计中,如何高效实现缓存一致性一直是核心挑战。Arm Neoverse CMN-700(Coherent Mesh Network)作为第二代一致性网格网络IP,采用分布式架构解决了从16核到256核规模的数据一致性问…...

视觉显著目标的自适应分割与动态网格生成算法研究
ArticleObjectiveMethodComments视觉显著目标的自适应分割背景是基于视觉注意模型和最大熵分割算法,针对复杂背景下的显著目标分割问题。目的是提出一种自适应显著目标分割方法,以便快速准确地从场景图像中检测出显著目标。试验用的方法是通过颜色、强度…...