05 python数据容器
5.1 数据容器认识

5.2 python列表
5.2.1 列表的定义
'''
演示数据容器之:list
语法:[元素,元素,....]
'''
#定义一个列表List
List = ['itheima','uityu','gsdfg']
List1 = ['itheima','6666','True']
print(List)
print(List1)
print(type(List))
print(type(List1))
#定义嵌套列表
List2 = [[1,2,3],['dadd','dadad','fefefe']]
print(List2)
print(type(List2))
5.2.2 列表的下标索引
''' 通过下标索引取出对应位置的数据 '''#定义列表 List = ['tom','python','lalal']#列表[下标索引],从前向后从0开始,每次+1, 从后往前从-1开始,每次-1 print(List[0]) print(List[1]) print(List[-1])#定义嵌套列表 List1 = [[1,2,3],[123,333,444]] #取出嵌套索引的元素 print(List1[0][1]) print(List1[1][-2])
5.2.3 列表的常用操作方法
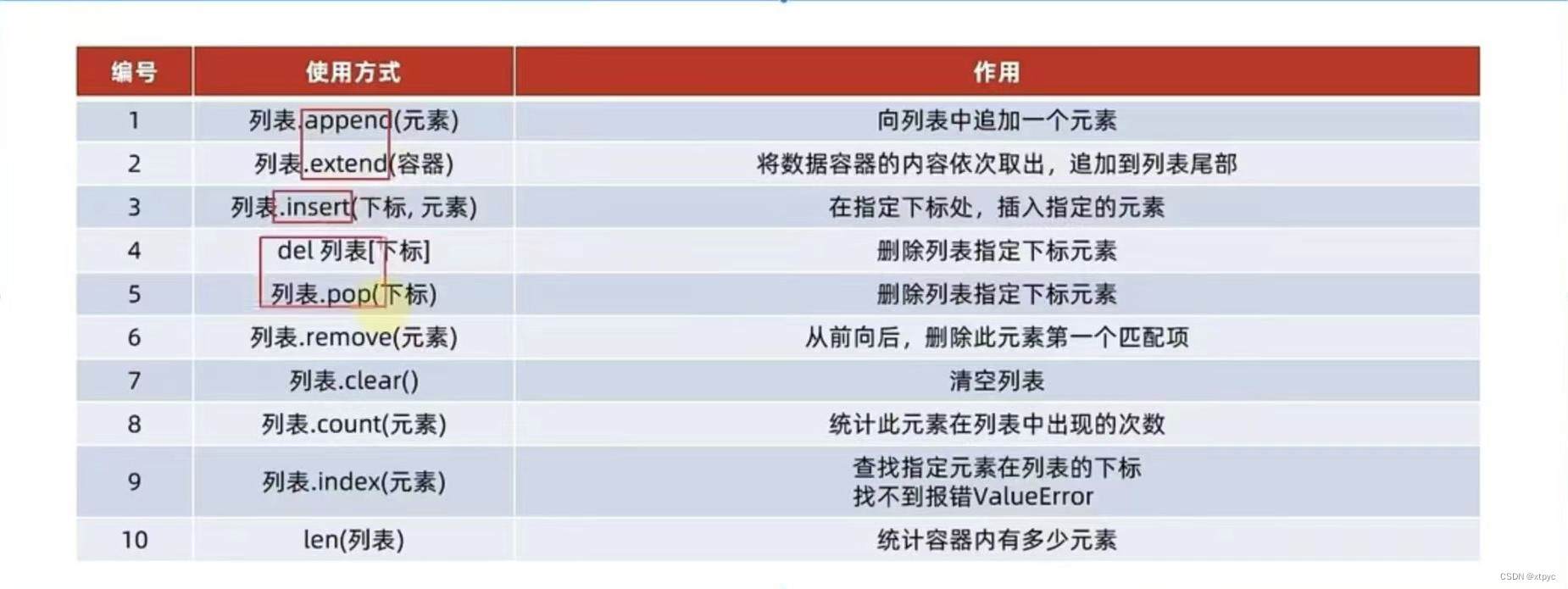
'''
演示数据容器之:List列表常用操作
'''my_list = [11111,'num',['qqqqq',676767]]#1.1 查找某元素在列表内的下标索引 列表.index
index = my_list.index(['qqqqq',676767])
print(f'[qqqqq,676767]在列表中的下标索引是:{index}')# 1.2如果查找的元素不存在,会报错
# index = my_list.index(0000)
# print(f'0000在列表中的下标索引是:{index}')#2 修改特定下标索引的值
my_list[0] = 9999
print(f'列表被修改后的值是:{my_list}')#3 在特定位置插入新元素 列表.insert
my_list.insert(1,777777)
print(f'列表插入元素后它的结果是:{my_list}')#4 在元素列表中追加一个元素,在列表尾部加入新元素 列表.append
my_list.append('学python')
print(f'列表在追加元素后,结果是:{my_list}')#5 在元素列表中追加一个新列表,在列表尾部加入新列表 列表.extend
my_list2 = [1,'best']
my_list.extend(my_list2)
print(f'列表在追加列表后,结果是:{my_list}')#6 删除列表中的元素(两种方法)
my_list3 = [11111,'num',['qqqqq',676767]]
#6.1 del方法 列表[下标]
del my_list3[2][1]
print(f'del方法删除后的结果是{my_list3}')
#6.2 方法2: 列表.pop(下标) 列表.pop
my_list3 = [11111,'num',['qqqqq',676767]]
my_list3.pop(1)
print(f'列表.pop(下标)方法删除后的结果是{my_list3}')#7 删除某元素在列表的第一个匹配项 列表.remove
my_list4 = [11111,11111,111111,111111,'num','num','num',['qqqqq',676767]]
my_list4.remove('num')
my_list4.remove('num')
my_list4.remove('num')
print(f'通过remove方法移除元素后,列表的结果是:{my_list4}')#8 清空列表 列表.clear
my_list4.clear()
print(f'列表被清空了,结果是:{my_list4}')#9 统计列表内某元素的数量 列表.count
my_list5 = [11111,11111,111111,111111,'num','num','num',['qqqqq',676767]]
count = my_list5.count('num')
print(f'列表中num的数量为:{count}')#统计列表中有多少元素 len(列表)
my_list6 = [11111,11111,111111,111111,'num','num','num',['qqqqq',676767]]
count = len(my_list6)
print(f'列表中的元素数量为:{count}')
5.2.4 列表的基础操作案例

age = [21,25,21,23,22,20]#追加31到列表末尾 age.append(31) print(age)#追加新列表到列表尾部 age1 = [29,33,30] age.extend(age1) print(age)#取出第一个元素 age.pop(0) print(age)#取出最后一个元素 del age[7] print(age)#查看31在列表中的下表位置 index = age.index(31) print(index)
5.3 元组
5.3.1 元组的定义和操作
'''
演示tuple元组的定义和操作
'''
#定义元祖
t1 = (1,'hello',True)
t2 = ()
t3 = tuple()
print(f't1的类型是{type(t1)},内容是{t1}')
print(f't2的类型是{type(t2)},内容是{t2}')
print(f't3的类型是{type(t3)},内容是{t3}')#定义单个元素的元素(单个元素需要带上单个逗号)
t4 = (1,)
t5 = (2)
print(f't4的类型是{type(t4)},内容是{t4}')
print(f't5的类型是{type(t5)},内容是{t5}')# 元组的嵌套
t6 = ((1,2,3),(9,0,34))
print(f't6的类型是{type(t6)},内容是{t6}')# 下标索引取出内容
num = t6[1][1]
print(f'从嵌套元祖中取出的数据是:{num}')#元组的操作:index查找方法
t1 = (1,0,'hello',True,False,True,False,True,False,'hhhh')
index = t1.index(False)
print(f'True在t1中的下标是:{index}')#元组的操作: count统计方法
num = t1.count(True)
print(f'在元祖中统计True的数量有{num}个')#元祖的操作:len函数统计元组元素的的数量
num = len(t1)
print(f'元祖的数量有:{num}个')#元组的遍历 while循环
index = 0
while index < len(t1):print(f"元组的元素有:{t1[index]}")index += 1#元组的遍历 for循环
for i in t1:print(f"2元组的元素有:{i}")# 定义一个元组
#元组的元素不可修改,但元组内列表内容元素可以修改
t10 = (1,2,[3333,5555])
print(f't10的内容是:{t10}')
t10[2][0] = '黑马python'
t10[2][1] = '西八'
print(f't10的内容是:{t10}')
5.3.2 元组的基本操作案例

#定义元组
information = ('周几轮',18,['basketball','rap'])#查询年龄所在下标位置
index = information.index(18)
print(f'年龄所在下标位置:{index}')#查询学生姓名
name = information[0]
print(f"学生姓名是{name}")#删除学生爱好basketball
del information[2][0]
print(information)#增加爱好dance
information[2].append('dance')
print(information)
5.4 字符串
5.4.1 字符串的定义和操作
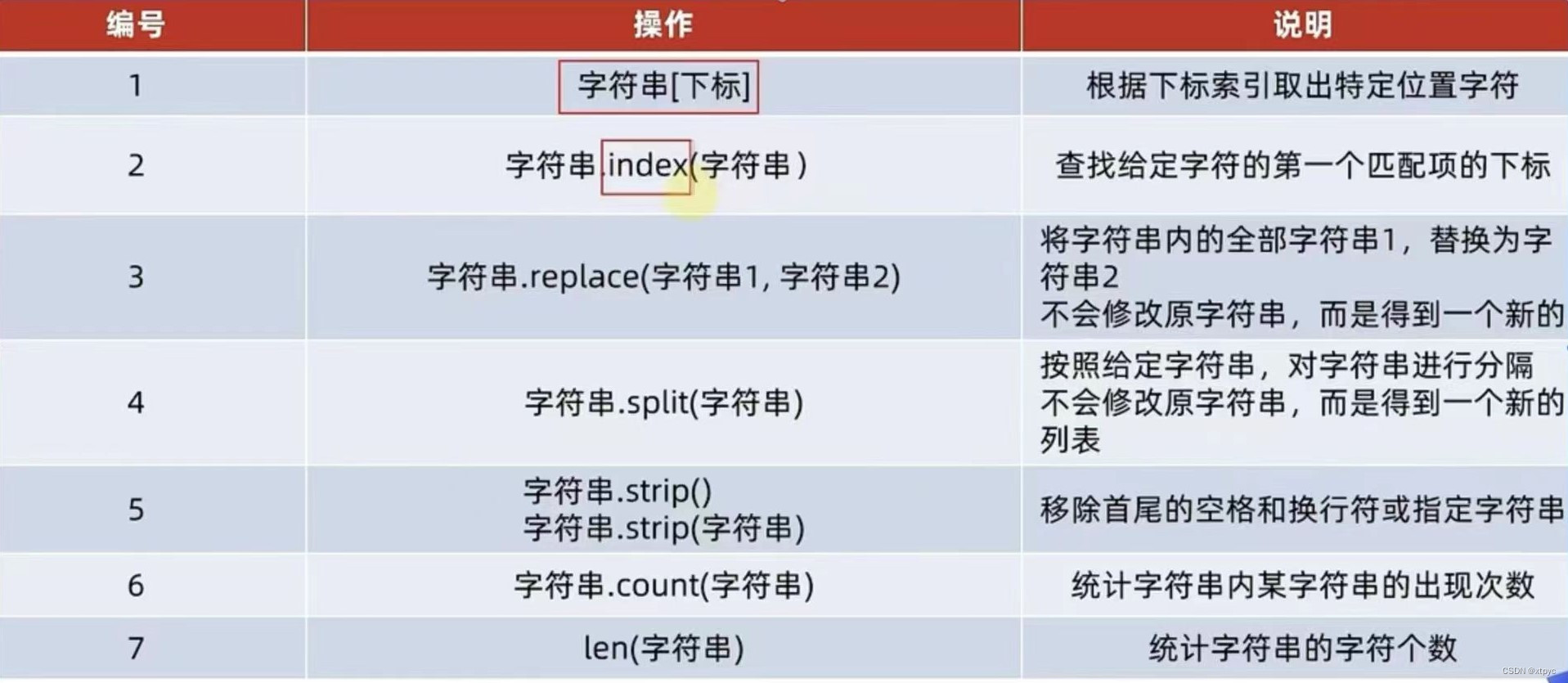
'''
演示以数据容器的角色,学习字符串的相关操作
'''my_str = 'python learning time'
#通过下标索引取值
a = my_str[3]
b = my_str[-6]
print(f'下标为2的值是:{a},下标为-6的值是{b}')# index方法
c = my_str.index('learning')
print(f'learing的起始下标是:{c}')#replace方法
new_my_str = my_str.replace("i",'程序')
print(f'{my_str}替换i后结果是:{new_my_str}')#split方法 字符串的分割
my_str3 = 'aaabbaddaeeaggakka'
my_str3_list = my_str3.split('a')
print(f'字符串{my_str3}按照a进行split分割后得到:{my_str3_list},类型是:{type(my_str3_list)}')#strip方法 去除字符串收尾元素
my_str = ' 123python learning time21 '
new_my_str = my_str.split() #不传入参数,则去除首尾空格
print(new_my_str)
new_my_str2 = my_str.split('12')
print(new_my_str2)#统计字符串某字符串出现的次数
my_str = ' 123python learning time21 '
count = my_str.count('2')
print(f'2出现的次数是{count}')#统计字符串的长度
count = len(my_str)
print(f'字符串{my_str}的长度是{count}')#字符串的while的循环遍历
my_str2 = 'whoiam'
index = 0
while index < len(my_str2):print(my_str2[index])index += 1#字符串的for的循环遍历
for i in my_str3:print(i)
5.4.2字符串的大小比较
'''
演示字符串的大小比较
'''#abc 比较abd
print(f"abc 小于 abd的结果是:{'abd' > 'abc'}")#ab比较a
print(f"a小于 ab的结果是:{'ab' > 'a'}")#ab比较A
print(f"A小于 a的结果是:{'a' > 'A'}")#key1比较key2
print(f"key1小于 key2的结果是:{'key2' > 'key1'}")
5.4.3字符串的基础操作案例

str = 'itheima itcast boxuegu'#统计字符串内it数量
count = str.count('it')
print(f'字符串内it数量有:{count}')#将空格替换为|
new_str = str.replace(' ','|')
print(f'将字符串{str}内空格替换为|的结果为{new_str}')#按照|字符分割为列表
new_str_list = new_str.split("|")
print(new_str_list)
5.5 对数据容器进行切片操作
5.5.1 演示对序列进行切片操作
'''
演示对序列进行切片操作
'''#对list进行切片,从1开始,4结束,步长1
my_list = [0,1,2,3,4,5,6]
re = my_list[1:4] #步长默认1,可以不写
print(f'结果1:{re}')#对tuple进行切片,最开始,到最后结束,步长1
my_tuple = (0,1,2,3,4,5,6)
re2 = my_tuple[:] #步长默认1,可以不写
print(f'结果2:{re2}')#对str进行切片,最开始,到最后结束,步长2
my_str = '0123456'
re3 = my_str[::2]
print(f'结果3:{re3}')#对str进行切片,最开始,到最后结束,步长-1
my_str = '0,1,2,3,4,5,6'
re4 = my_str[::-1]
print(f'结果4:{re4}')#对列表进行切片,从3开始,1结束,步长-1
my_list = [0,1,2,3,4,5,6,7,8,9,100]
re5 = my_list[3:1:-1]
print(f'结果5:{re5}')#对元祖进行切片,最开始,到最后结束,步长-2
my_tuple = (0,1,2,3,4,5,6,3333,7,89,99,99999)
re6 = my_tuple[::-2]
print(f'结果6:{re6}')
5.5.2 对数据容器操作的基础案例

str = '万过薪月,员序程马黑来,nohtyp学'#方法一 切片,倒序取出
re = str[9:4:-1]
print(re)#方法二 倒序取出,然后切片
re2 = str[::-1][9:14]
print(re2)#方法三,split分割,replace分割“来”为空,倒序字符串
re3 = str.split(',')[1].replace('来','')[::-1]
print(re3)
5.6 集合
5.6.1 集合的定义和操作
'''
演示数据容器集合
'''
#定义集合 集合会去重,不支持重复元素
my_set = {'sss','qqq','wwww','rrr','ww'}
my_set_empty = set() #定义空集合
print(f'{my_set},{type(my_set)}')
print(f'{my_set_empty},{type(my_set_empty)}')#添加新元素
my_set.add("python")
print(f'{my_set}')#移除元素
my_set.remove('python')
print(f'{my_set}')#从集合中随机取出元素
element =my_set.pop()
print(f'{my_set},{element}')#清空集合
my_set.clear()
print(f'{my_set}')#取出两个集合的差集 会产生新集合,集合1和2不变
set1 = {1,2,3}
set2 = {1,5,3}
set3 = set1.difference(set2)
print(f'{set1},{set2},{set3}')#消除两个集合的差集 不会产生新集合,集合1变
set1 = {1,2,3}
set2 = {1,5,3}
set3 = set1.difference_update(set2)
print(f'{set1},{set2}')#两个集合合并 会产生新集合,集合1和2不变
set1 = {1,2,3}
set2 = {1,5,3}
set3 = set1.union(set2)
print(f'{set1},{set2},{set3}')#统计集合数量
count = len(set3)
print(f'{count}')#集合的遍历
#集合不支持下标索引,不可以while循环
for i in set3:print(f"{i}")'''
集合的基本操作案例
'''
my_list = [1,2,3,4,5,6,7,8,9,0,5,6,5,3,21,1,334,4,3,2,1]#定义空集合
set = set()#通过for循环遍历列表
#将列表中元素添加到集合中
for i in my_list:print(f'{i}')set.add(i)
print(f"{set}")
5.7 字典
5.7.1 字典的定义和操作
'''
演示字典的定义
'''#定义字典 字典中的key不可以重复 {key,value}
my_dict = {'网咯红':99 ,'周几轮':88 ,'林俊杰':77 }
#定义空字典
my_dict2 = {}
my_dict3 = dict()
print(f'{my_dict},{type(my_dict)},\n'f'{my_dict2},{type(my_dict2)},\n'f'{my_dict3},{type(my_dict3)}')#从字典中基于key获取value
score = my_dict['林俊杰']
print(f'{score}')#字典的嵌套,key,value可以是任意数据类型,(key不可为字典)
stu_score_dict = {'王力宏':{'aa':77,'bb':55,'cc':66},'周杰伦':{'aa': 47,'bb': 555,'cc': 106},'林俊杰':{'aa': 127,'bb': 545,'cc': 876}
}
print(f'{stu_score_dict}')#查看学生成绩
score = stu_score_dict['周杰伦']['aa']
print(f'{score}')'''
字典的常用操作
'''
my_dict = {'网咯红':99 ,'周几轮':88 ,'林俊杰':77 }
#新增元素
my_dict['张学友'] = 62
print(f'{my_dict}')#更新元素
my_dict['周几轮'] = 9
print(f'{my_dict}')#删除元素score = my_dict.pop('周几轮')
print(f'{my_dict},{score}')#清空元素
my_dict.clear()
print(f'{my_dict}')#遍历字典
#获取全部key
my_dict = {'网咯红':99 ,'周几轮':88 ,'林俊杰':77 }
keys = my_dict.keys()
print(f'{keys}')
# 方式1 通过获取所有key来遍历字典
for key in keys:print(f'{key},{my_dict[key]}')#方式2 通过直接对字典进行for循环,每一次循环得到key
for key in my_dict:print(f'222\t{key},aaaa\t{my_dict[key]}')#统计字典内的元素数量
num = len(my_dict)
print(f'{num}')'''
字典的基本操作案例
'''#定义字典
my_dict = {'王力宏':{'部门':'科技部','工资':3000,'级别':1},'周杰伦':{'部门': '市场部','工资': 5000,'级别': 2},'林俊杰':{'部门': '市场部','工资': 7000,'级别': 3},'张学友':{'部门': '科技部','工资': 4000,'级别': 1},'刘德华':{'部门': '市场部','工资': 6000,'级别': 2}
}
#遍历字典,找到name这个key
for name in my_dict:#判断name key对应的级别是否为1if my_dict[name]['级别'] == 1:#如果是级别加1,工资加1000my_dict[name]['级别'] += 1my_dict[name]['工资'] += 1000
print(f'{my_dict}')
5.8 数据容器的通用操作
'''
演示数据容器的通用操作
'''list1 = [17,27,30,4,45]
tuple1 = (10,2,3,44,5)
str1 = 'abcdefghij'
set1 = {1,2,3,4,5}
dict1 = {'key8':9,'key2':8,'key6':7,'key4':6,'key7':4}#len元素个数
num = len(list1)
print(f'{num}')num = len(tuple1)
print(f'{num}')num = len(str1)
print(f'{num}')num = len(set1)
print(f'{num}')num = len(dict1)
print(f'{num}')#max 最大元素
print(f'列表 最大的元素是:{max(list1)}')
print(f'元组 最大的元素是:{max(tuple1)}')
print(f'字符串最大的元素是:{max(str1)}')
print(f'集合 最大的元素是:{max(set1)}')
print(f'字典 最大的元素是:{max(dict1)}')#min最小元素
print(f'列表 最小的元素是:{max(list1)}')
print(f'元组 最小的元素是:{max(tuple1)}')
print(f'字符串最小的元素是:{max(str1)}')
print(f'集合 最小的元素是:{max(set1)}')
print(f'字典 最小的元素是:{max(dict1)}')#类型转换:容器转列表
print(f'列表 列表转换为列表的结果是:{list(list1)}')
print(f'元组 元组转换为列表的结果是:{list(tuple1)}')
print(f'字符串转字符串换为列表的结果是:{list(str1)}')
print(f'集合 集合转换为列表的结果是:{list(set1)}')
print(f'字典 字典转换为列表的结果是:{list(dict1)}')#类型转换:容器转元组
print(f'列表 列表转换为元组的结果是:{tuple(list1)}')
print(f'元组 元组转换为元组的结果是:{tuple(tuple1)}')
print(f'字符串转字符串换为元组的结果是:{tuple(str1)}')
print(f'集合 集合转换为元组的结果是:{tuple(set1)}')
print(f'字典 字典转换为元组的结果是:{tuple(dict1)}')#类型转换:容器转字符串
print(f'列表 列表转换为字符串的结果是:{str(list1)}')
print(f'元组 元组转换为字符串的结果是:{str(tuple1)}')
print(f'字符串转字符串换为字符串结果是: {str(str1)}')
print(f'集合 集合转换为字符串的结果是:{str(set1)}')
print(f'字典 字典转换为字符串的结果是:{str(dict1)}')#类型转换:容器转集合
print(f'列表 列表转换为集合的结果是:{set(list1)}')
print(f'元组 元组转换为集合的结果是:{set(tuple1)}')
print(f'字符串 字符串换为集合的结果是:{set(str1)}')
print(f'集合 集合转换为集合的结果是:{set(set1)}')
print(f'字典 字典转换为集合的结果是:{set(dict1)}')#容器的通用排序功能 排序后结果会变成列表对象
print(f'列表 列表排序的结果是:{sorted(list1)}')
print(f'元组 元组排序的结果是:{sorted(tuple1)}')
print(f'字符串 字符排序的结果是:{sorted(str1)}')
print(f'集合 集合排序的结果是:{sorted(set1)}')
print(f'字典 字典排序的结果是:{sorted(dict1)}')#反向排序
print(f'列表 列表反向排序的结果是:{sorted(list1,reverse=True)}')
print(f'元组 元组反向排序的结果是:{sorted(tuple1,reverse=True)}')
print(f'字符串 字符反向排序的结果是: {sorted(str1,reverse=True)}')
print(f'集合 集合反向排序的结果是: {sorted(set1,reverse=True)}')
print(f'字典 字典反向排序的结果是:{sorted(dict1,reverse=True)}')
相关文章:
05 python数据容器
5.1 数据容器认识 5.2 python列表 5.2.1 列表的定义 演示数据容器之:list 语法:[元素,元素,....] #定义一个列表List List [itheima,uityu,gsdfg] List1 [itheima,6666,True] print(List) print(List1) print(type(List)) pr…...

相机倾斜棋盘格标定全记录 vs200+opencv安装
论文参考是这个 Geiger A, Moosmann F, Car , et al. Automatic camera and range sensor calibration using a single shot[C]//Robotics and Automation (ICRA), 2012 IEEE International Conference on. IEEE, 2012: 3936-3943. 代码是这个github 花了一上午配好了c环境。。…...
QT- QT-lximagerEidtor图片编辑器
QT- QT-lximagerEidtor图片编辑器 一、演示效果二、关键程序三、下载链接 功能如下: 1、缩放、旋转、翻转和调整图像大小 2、幻灯片 3、缩略图栏(左、上或下);不同的缩略图大小 4、Exif数据栏 5、内联图像重命名 6、自定义快捷方式…...

PyQt 如何通过连续点击托盘图标显示隐藏主窗口并且在主窗口隐藏时调整界面到托盘图标附近
不废话直接看代码 # -*- codingutf-8 -*- # # author: Ruben # mail: 773849069qq.com # time: 2023/12/8 # u""" 一个托盘图标的小部件 """ from Qt import QtWidgets, QtGui, QtCore# --*--*--*--*--*--*--*--*--*--…...
什么是纯净IP?如何判断IP地址的纯净度?有哪些干净IP推荐?
您是否想知道什么使代理“干净”或如何确保您的代理不会将您列入网站的黑名单?对于通过代理访问网络的人来说,干净的代理是无缝在线体验的重要组成部分。在这篇文章中,我们将深入研究干净代理的世界,并探讨决定其质量的因素。 一、…...

MySQL和Minio数据备份
文章目录 一、MySQL数据备份1. MySQL客户端2. 数据增量备份3. 数据增量还原4. 数据全量备份5. 数据全量还原 二、Minio数据备份1. Minio客户端2. 数据备份3. 数据还原 三、其他参考1. 设置定时备份2. 数据拷贝到其他服务器3. MySQL其他语句 一、MySQL数据备份 Linux环境&#…...

在Go中过滤范型集合:性能回顾
在一个真实的 Golang 场景中使用泛型,同时寻找与 Stream filter(Predicate<? super T> predicate)和 Python list comprehension 等同的函数。我没有依赖现有的包,而是选择自己写一个过滤函数,以达到学习的目的 func filterStrings(c…...
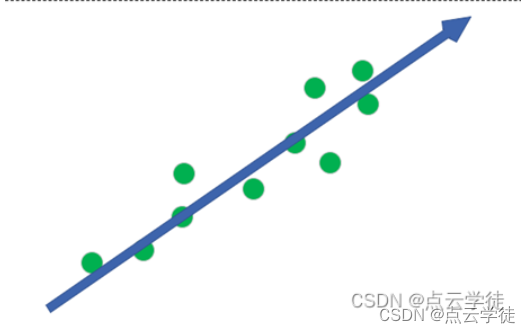
MATLAB 最小二乘直线拟合方法二 (36)
MATLAB 最小二乘直线拟合方法二 (36) 一、算法介绍二、算法实现1.代码2.结果一、算法介绍 这里介绍另一种拟合直线点云的方法,更为简单方便,结果与前者一致,主要内容直接复制代码使用即可,原理简单看代码即可,下面是具体的实现和拟合结果展示 二、算法实现 1.代码 代…...
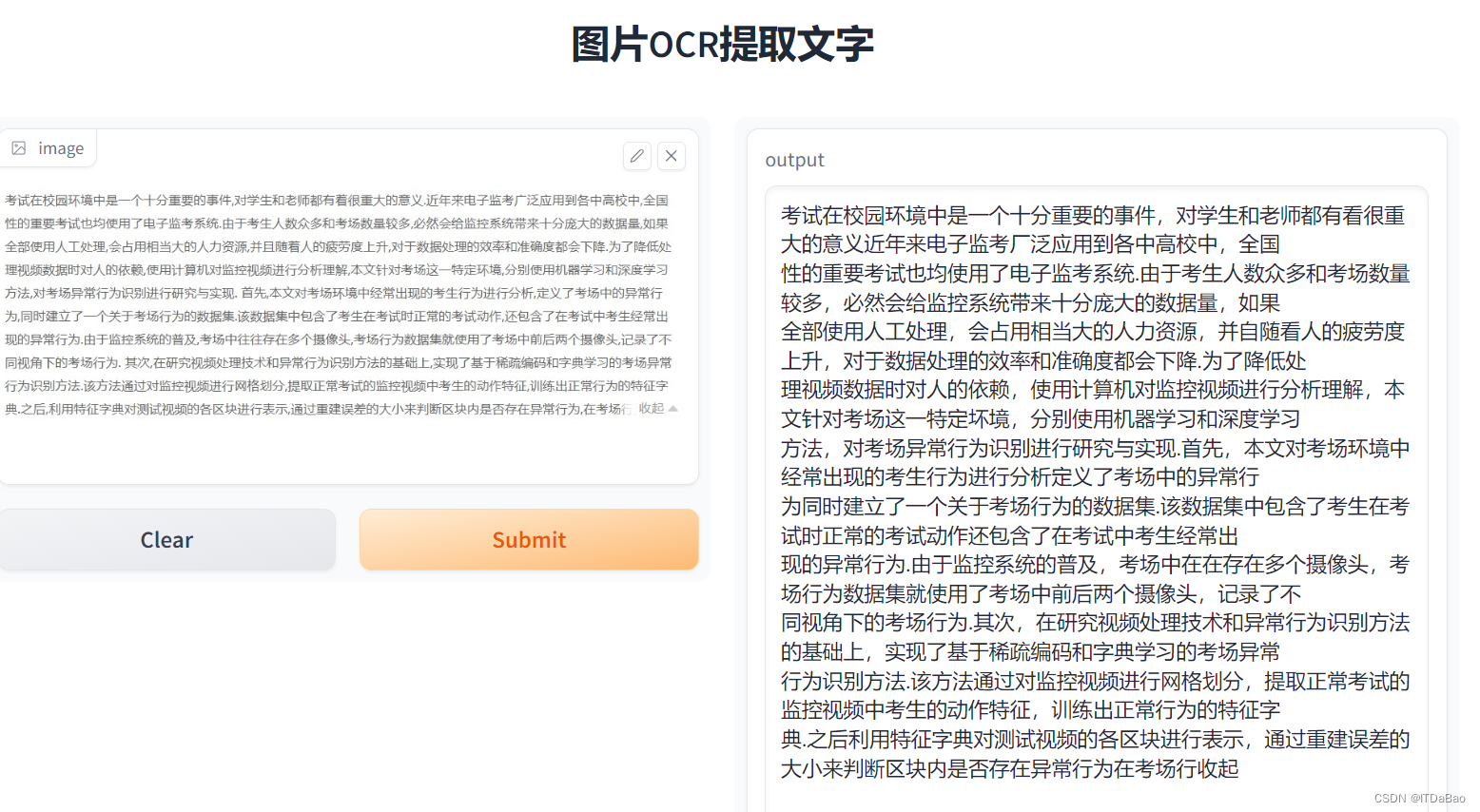
Python 实现:OCR在图片中提取文字(基于Gradio实现)
Paddle OCR PaddleOCR 基于深度学习技术实现的,使用十分简单。 先看效果 可以看出来识别效果还是不错的,里面的“湿”字识别成了繁体字。如果不是连体字,就不会出现这个问题。 1.测试环境 操作系统:Win10 Python:3…...

idea插件开发报错: ZipException opening “slf4j.jar“: zip END header not found
错误信息 E:\idea-workspace\#idea-plugin\JSON2Object\src\main\java\com\hgy\plugin\json2object\GenerateAction.java:1: 错误: 无法访问com.hgy.plugin.json2object package com.hgy.plugin.json2object; ^ZipException opening "slf4j.jar": zip END header no…...
【Linux】多线程编程
目录 1. 线程基础知识 2. 线程创建 3. 线程ID(TID) 4. 线程终止 5. 线程取消 6. 线程等待 7. 线程分离 8. 线程互斥 8.1 初始化互斥量 8.2 销毁互斥量 8.3 互斥量加锁和解锁 9. 可重入和线程安全 10. 线程同步之条件变量 10.1 初始化条件变…...
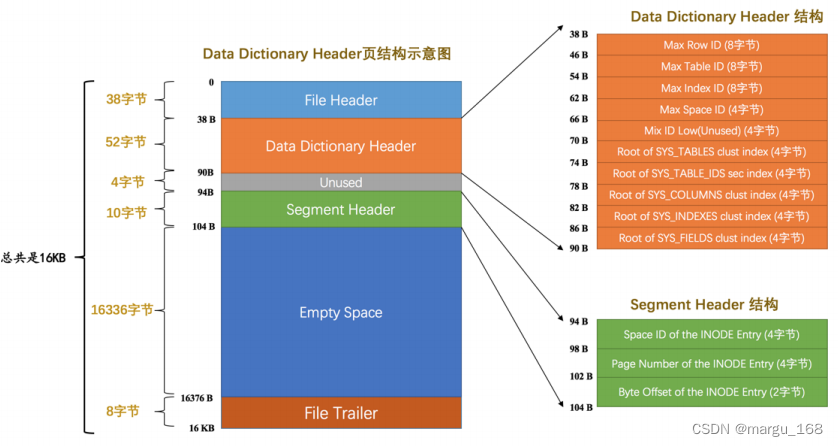
【Mysql】InnoDB的表空间(九)
概述 表空间是一个在 InnoDB 中比较抽象的概念,对于系统表空间来说,对应着文件系统中一个或多个实际文件;而对于每个独立表空间来说,对应着文件系统中一个名为表名.ibd 的实际文件。可以把表空间想象成由很多个页组成的池子&…...

【09】ES6:Set 和 Map 数据结构
一、Set 1、基本语法 定义 Set 是一系列无序、没有重复值的数据集合。数组是一系列有序(下标索引)的数据集合。 Set 本身是一个构造函数,用来生成 Set 数据结构。 const s new Set() [2, 3, 5, 4, 5, 2, 2].forEach(x > s.add(x))fo…...

Java通过documents4j和libreoffice把word转为pdf
文章目录 word转pdf的相关第三方jar说明Linux系统安装LibreOffice在线安装离线安装word转pdf验证 Java工具类代码 word转pdf的相关第三方jar说明 docx4j 免费开源、稍微复杂点的word,样式完全乱了,且xalan升级为2.7.3后会报错。poi 免费开源、官方文档少…...
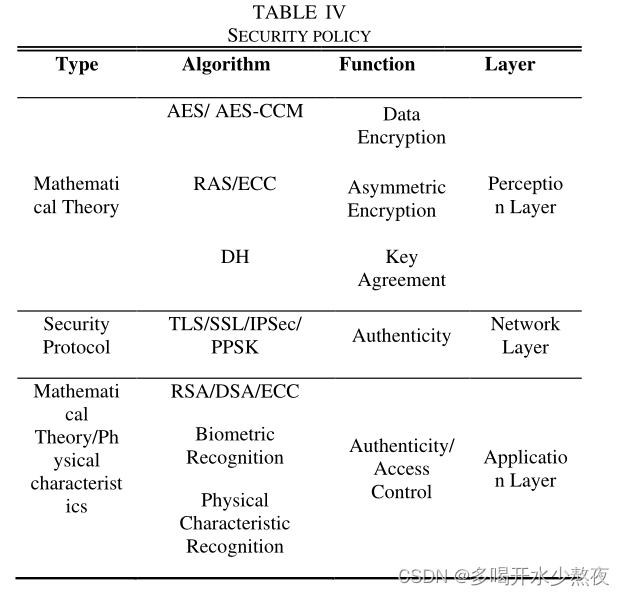
物联网时代的访问控制研究综述
A survey on Access Control in the Age of Internet of Things 文章目录 A B S T R A C T引言A. Comparison Between This Paper and Existing SurveysB. Contributions II.ACCESS CONTROL BACKGROUNDIII. ACCESS CONTROL CHALLENGES IN IOT SEARCHA. Characteristics of IoT …...
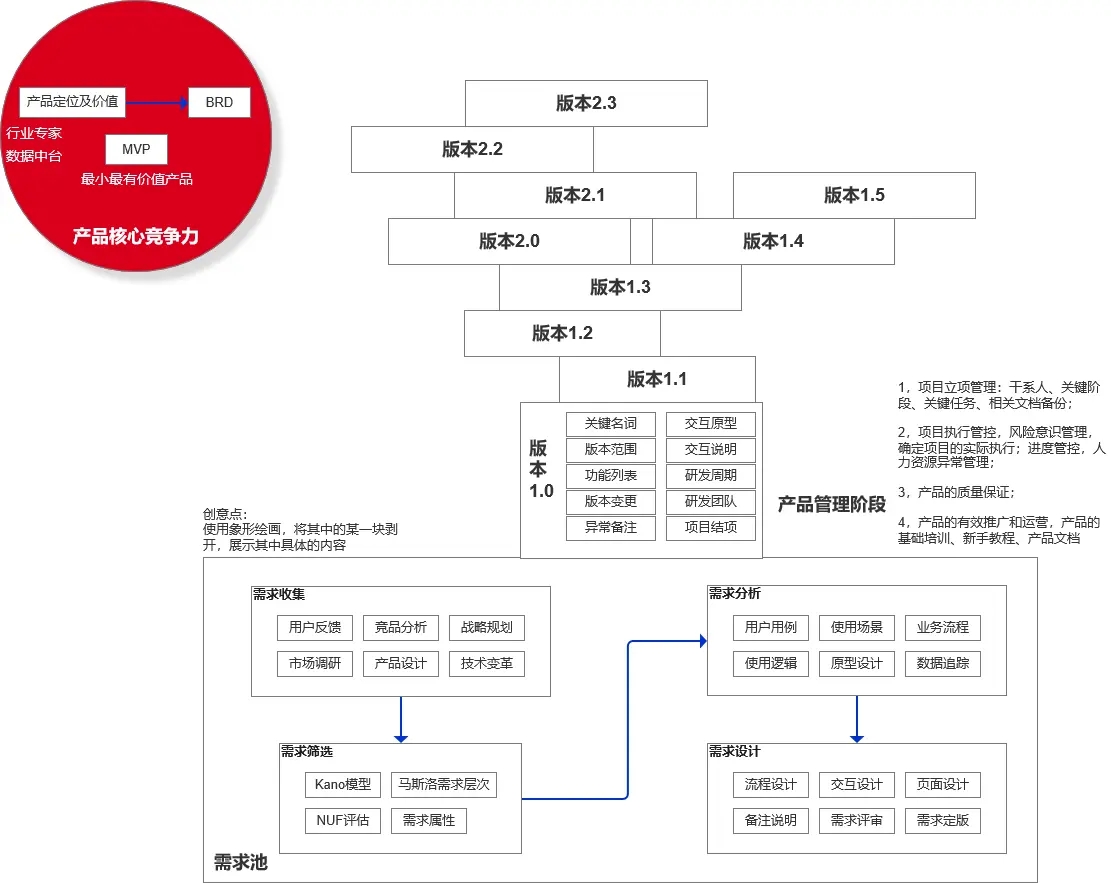
【产品经理】需求池和版本树
在这个人人都是产品经理的时代,每位入行的产品人进阶速度与到达高度各有不同。本文作者结合自身三年产品行业的经历,根据案例拆解产品行业的极简研发过程、需求池、版本树、产品自我优化等相关具体方法论。 一、产品研发的极简过程 1. 产品概述 产品就…...

Qt图像处理-OpenCv中Mat与QImage互转
Qt图像处理时需要OpenCv中Mat与QImage互转,具体代码如下 创建EditPhoto,头文件,使用前需要配置好opencv #include <QObject> #include <QImage> #include <QDebug>#include<opencv2/core/core.hpp> #include<opencv2/highgui/highgui.hpp> …...

构建外卖小程序:技术代码实践
在这个数字化的时代,外卖小程序已经成为餐饮业的一项重要工具。在本文中,我们将通过一些简单而实用的技术代码,向您展示如何构建一个基本的外卖小程序。我们将使用微信小程序平台作为例子,但这些原理同样适用于其他小程序平台。 …...
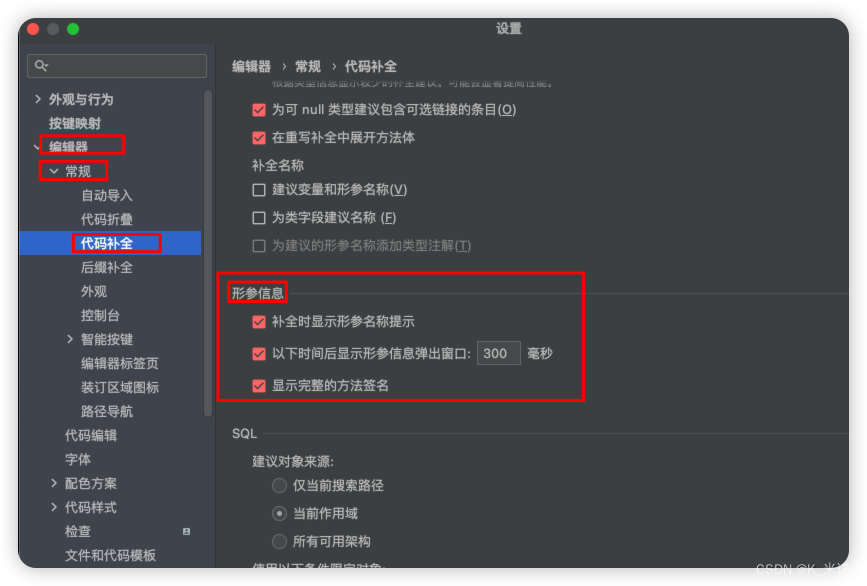
IDEA中显示方法、类注释信息
目录 一、IDEA测试版本及环境二、操作步骤2.1 鼠标悬停在某一个方法上,从而显示方法的注释信息2.2 调用方法时同步显示方法注释信息2.3 在new一个对象时,这个对象有很多重载的构造方法,想要重载的构造函数都显示出来 一、IDEA测试版本及环境 …...

《数据结构、算法与应用C++语言描述》- 堆排序 - 借助priority_queue的C++实现
堆排序 完整可编译运行代码见:Github::Data-Structures-Algorithms-and-Applications/_27HeapSort 定义 借助堆进行排序。先用n个待排序的元素初始化一个小根堆,然后从堆中逐个提取(即删除元素)元素。初始化的时间复杂度为O(n),大根堆中每…...

CN2628 可用太阳能供电 5 伏特低压差电压调制集成电路
概述: CN2628是一款可用太阳能供电的低噪声线性电压调制集成电路,采用固定5.0V输出电压,最大 输出电流可达1安培,在5.5V到7V的输入电压范围内输出电压精度可达1%。CN2628工作电流只有520微安,而且同输入和输出的压差没有关系。 CN…...

g1810,g3810,ip2700,g5080,g1800,ts3380,TS8380,ts6480报错5B00,P07,E08,5b02,1704,1700,5b04,佳能v6.200,亲测有用。
下载:点这里下载 备用下载:https://pan.baidu.com/s/1WrPFvdV8sq-qI3_NgO2EvA?pwd0000 常见型号如下: G系列 G1000、G1100、G1200、G1400、G1500、G1800、G1900、G1010、G1110、G1120、G1410、G1420、G1411、G1510、G1520、G1810、G1820、…...

MATLAB/Simulink模型化设计驱动树莓派:从LED闪烁到快速原型开发
1. 项目概述:当MATLAB/Simulink遇见树莓派 如果你是一名算法工程师、控制工程师,或者正在学习嵌入式系统,那么“模型化设计”和“快速原型开发”这两个词对你来说一定不陌生。它们听起来很高大上,但核心目标其实很朴素࿱…...

DIY智能电机推子:从闭环控制到MIDI交互的硬件实战
1. 项目概述与核心价值如果你玩过专业的音频混音台,或者在一些高端的灯光控制台上见过那种会自己“嗖”一下滑到指定位置的推子,那你一定对电机推子(Motorized Fader)不陌生。这东西的魅力在于,它既是精准的模拟输入设…...

[具身智能-767]:AMCL全局撒粒子重搜与局部小范围匹配,是否算法过程是相似的,不同的是:粒子的数量、覆盖的区域、最终的精度?
AMCL 全局重搜 VS 局部匹配 详细对比核心定论二者底层算法流程、运算逻辑、执行步骤 100% 完全一致,统一遵循:运动预测→观测权重计算→粒子重采样→位姿融合输出这套粒子滤波逻辑,仅在粒子分布范围、粒子总数、收敛活动区间、定位误差精度四…...

Node.js代理池实战:proxy-agents库核心原理与高级应用
1. 项目概述与核心价值最近在折腾一些需要处理大量网络请求的自动化脚本,比如数据采集、API测试或者模拟用户操作,一个绕不开的痛点就是IP被封。单个IP频繁请求,对方服务器很容易就把你拉黑了。这时候,代理池就成了刚需。市面上成…...

免费开源字体编辑器终极指南:5个核心模块带你从零到专业设计
免费开源字体编辑器终极指南:5个核心模块带你从零到专业设计 【免费下载链接】fontforge Free (libre) font editor for Windows, Mac OS X and GNULinux 项目地址: https://gitcode.com/gh_mirrors/fo/fontforge 想要免费编辑字体却找不到合适的工具&#x…...

SingleFile CLI架构解析:高性能网页批量保存解决方案与实战指南
SingleFile CLI架构解析:高性能网页批量保存解决方案与实战指南 【免费下载链接】SingleFile Web Extension for saving a faithful copy of a complete web page in a single HTML file 项目地址: https://gitcode.com/gh_mirrors/si/SingleFile SingleFile…...

Outfit字体技术实现:9种字重的几何无衬线字体架构设计与应用实践
Outfit字体技术实现:9种字重的几何无衬线字体架构设计与应用实践 【免费下载链接】Outfit-Fonts The most on-brand typeface 项目地址: https://gitcode.com/gh_mirrors/ou/Outfit-Fonts 在现代数字产品设计中,字体选择往往决定了界面的视觉层次…...
)
手把手教你为AK7739音频芯片移植TDM接口(基于Linux ALSA框架)
手把手教你为AK7739音频芯片移植TDM接口(基于Linux ALSA框架) 在嵌入式音频系统开发中,TDM(Time Division Multiplexing)接口因其高带宽和多通道支持能力,成为专业音频设备的首选方案。AK7739作为一款高性能…...