【Pytorch】学习记录分享3——PyTorch 自动微分与线性回归
【【Pytorch】学习记录分享3——PyTorch 自动微分与线性回归
- 1. autograd 包,自动微分
- 2. 线性模型回归演示
- 3. GPU进行模型训练
小结:只需要将前向传播设置好,调用反向传播接口,即可实现反向传播的链式求导
1. autograd 包,自动微分
自动微分是机器学习工具包必备的工具,它可以自动计算整个计算图的微分。
PyTorch内建了一个叫做torch.autograd的自动微分引擎,该引擎支持的数据类型为:浮点数Tensor类型 ( half, float, double and bfloat16) 和复数Tensor 类型(cfloat, cdouble)
PyTorch中与自动微分相关的常用的Tensor属性和函数:
属性requires_grad:
默认值为False,表明该Tensor不会被自动微分引擎计算微分。设置为True,表明让自动微分引擎计算该Tensor的微分
属性grad:存储自动微分的计算结果,即调用backward()方法后的计算结果
方法backward(): 计算微分,一般不带参数,等效于:backward(torch.tensor(1.0))。若backward()方法在DAG的root上调用,它会依据链式法则自动计算DAG所有枝叶上的微分。
方法no_grad():禁用自动微分上下文管理, 一般用于模型评估或推理计算这些不需要执行自动微分计算的地方,以减少内存和算力的消耗。另外禁止在模型参数上自动计算微分,即不允许更新该参数,即所谓的冻结参数(frozen parameters)。
zero_grad()方法:PyTorch的微分是自动积累的,需要用zero_grad()方法手动清零
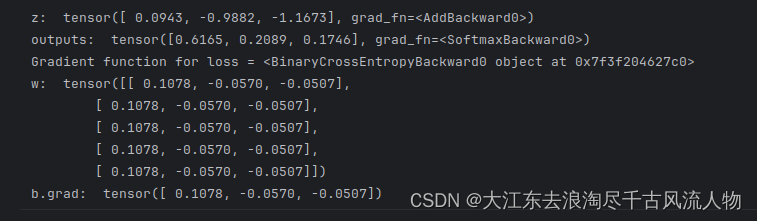
# 模型:z = x@w + b;激活函数:Softmax
x = torch.ones(5) # 输入张量,shape=(5,)
labels = torch.zeros(3) # 标签值,shape=(3,)
w = torch.randn(5,3,requires_grad=True) # 模型参数,需要计算微分, shape=(5,3)
b = torch.randn(3, requires_grad=True) # 模型参数,需要计算微分, shape=(3,)
z = x@w + b # 模型前向计算
outputs = torch.nn.functional.softmax(z) # 激活函数
print("z: ",z)
print("outputs: ",outputs)
loss = torch.nn.functional.binary_cross_entropy(outputs, labels)
# 查看loss函数的微分计算函数
print('Gradient function for loss =', loss.grad_fn)
# 调用loss函数的backward()方法计算模型参数的微分
loss.backward()
# 查看模型参数的微分值
print("w: ",w.grad)
print("b.grad: ",b.grad)
小姐:
| 方法 | 描述 |
|---|---|
| .requires_grad 设置为True | 会开始跟踪针对 tensor 的所有操作 |
| .backward() | 张量的梯度将累积到 .grad 属性 |
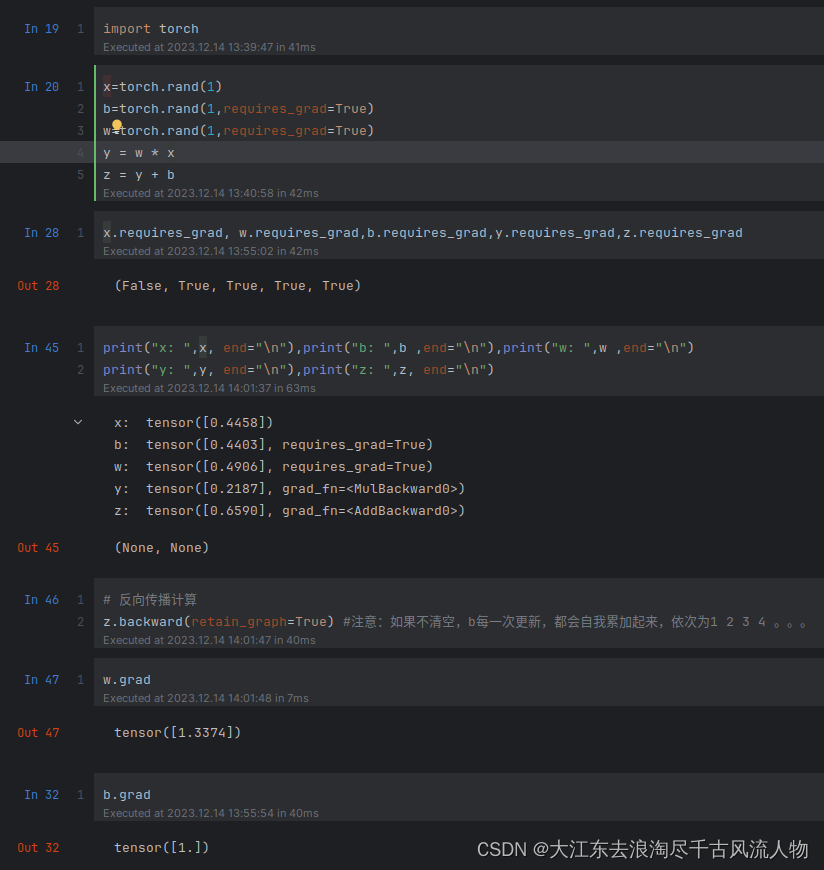
import torchx=torch.rand(1)
b=torch.rand(1,requires_grad=True)
w=torch.rand(1,requires_grad=True)
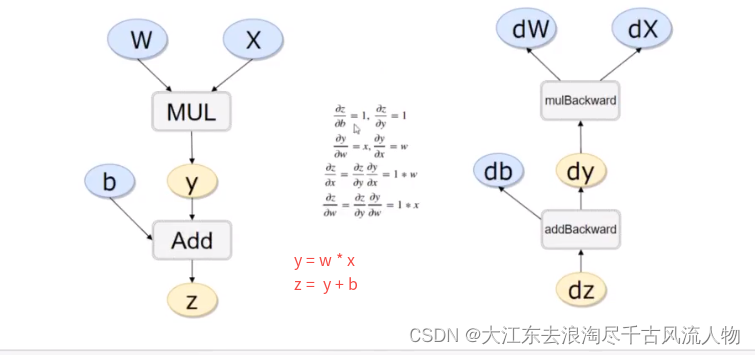
y = w * x
z = y + bx.requires_grad, w.requires_grad,b.requires_grad,y.requires_grad,z.requires_gradprint("x: ",x, end="\n"),print("b: ",b ,end="\n"),print("w: ",w ,end="\n")
print("y: ",y, end="\n"),print("z: ",z, end="\n")# 反向传播计算
z.backward(retain_graph=True) #注意:如果不清空,b每一次更新,都会自我累加起来,依次为1 2 3 4 。。。w.grad
b.grad
运行结果:
反向传播求导原理:
2. 线性模型回归演示

import torch
import torch.nn as nn## 线性回归模型: 本质上就是一个不加 激活函数的 全连接层
class LinearRegressionModel(nn.Module):def __init__(self, input_size, output_size):super(LinearRegressionModel, self).__init__()self.linear = nn.Linear(input_size, output_size)def forward(self, x):out = self.linear(x)return out
input_size = 1
output_size = 1model = LinearRegressionModel(input_size, output_size)
model# 指定号参数和损失函数
epochs = 500
learning_rate = 0.01
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
criterion = nn.MSELoss()# train model
for epoch in range(epochs):epochs+=1#注意 将numpy格式的输入数据转换成 tensorinputs = torch.from_numpy(x_train)labels = torch.from_numpy(y_train)#每次迭代梯度清零optimizer.zero_grad()#前向传播outputs = model(inputs)#计算损失loss = criterion(outputs, labels)#反向传播loss.backward()#updates weight and parametersoptimizer.step()if epoch % 50 == 0:print("Epoch: {}, Loss: {}".format(epoch, loss.item()))# predict model test,预测结果并且奖结果转换成np格式
predicted =model(torch.from_numpy(x_train).requires_grad_()).data.numpy()
predicted#model save
torch.save(model.state_dict(),'model.pkl')#model 读取
model.load_state_dict(torch.load('model.pkl'))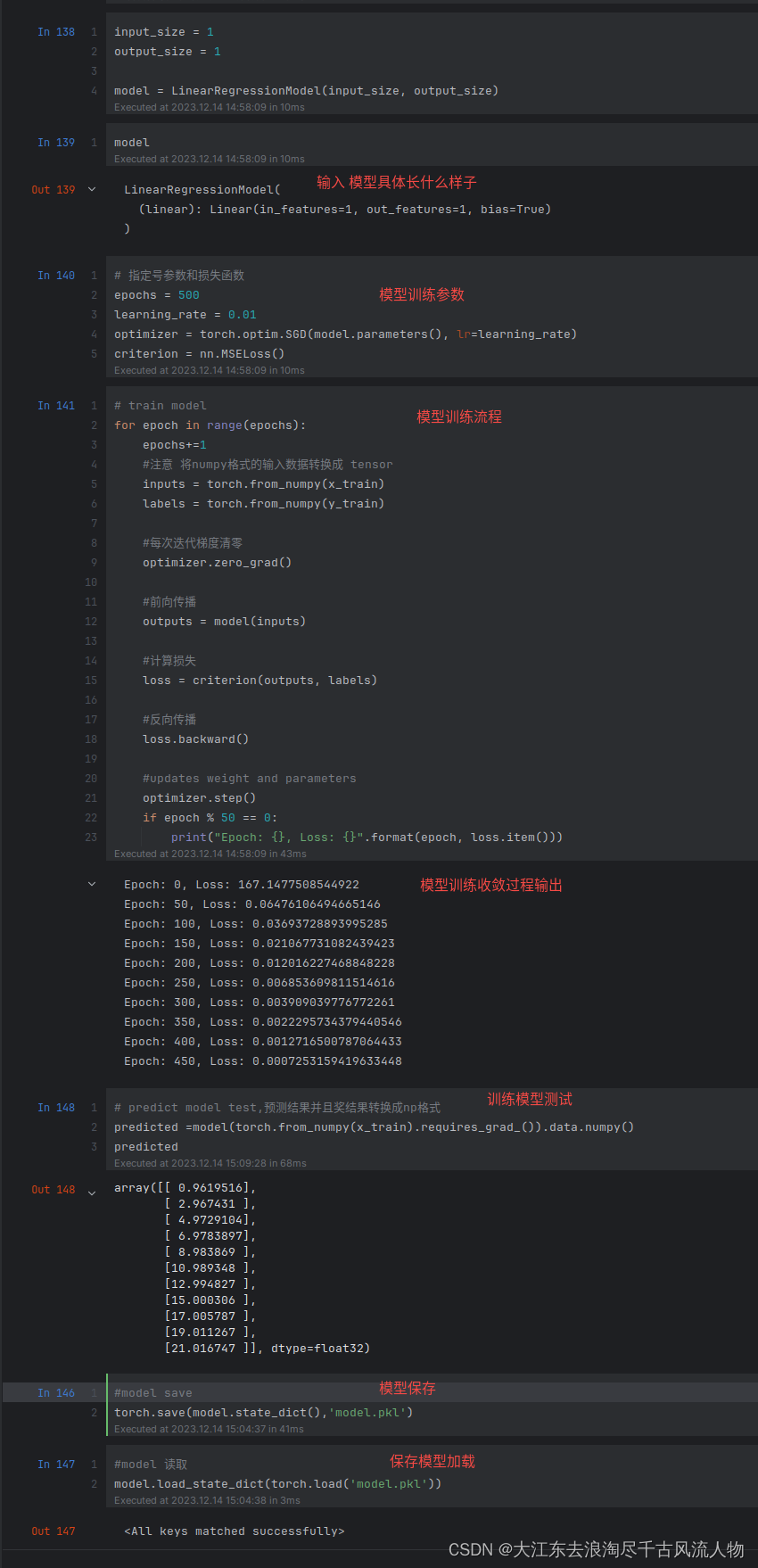
3. GPU进行模型训练
只需要 将模型和数据传入到“cuda”中运行即可,详细实现见截图
import torch
import torch.nn as nn
import numpy as np# #构建一个回归方程 y = 2*x+1#构建输如数据,将输入numpy格式转成tensor格式
x_values = [i for i in range(11)]
x_train = np.array(x_values,dtype=np.float32)
x_train = x_train.reshape(-1,1)y_values = [2*i + 1 for i in x_values]
y_train = np.array(y_values, dtype=np.float32)
y_train = y_train.reshape(-1,1)## 线性回归模型: 本质上就是一个不加 激活函数的 全连接层
class LinearRegressionModel(nn.Module):def __init__(self, input_size, output_size):super(LinearRegressionModel, self).__init__()self.linear = nn.Linear(input_size, output_size)def forward(self, x):out = self.linear(x)return outinput_size = 1
output_size = 1model = LinearRegressionModel(input_size, output_size)device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)# 指定号参数和损失函数
epochs = 500
learning_rate = 0.01
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
criterion = nn.MSELoss()# train model
for epoch in range(epochs):epochs+=1#注意 将numpy格式的输入数据转换成 tensorinputs = torch.from_numpy(x_train)labels = torch.from_numpy(y_train)#每次迭代梯度清零optimizer.zero_grad()#前向传播outputs = model(inputs)#计算损失loss = criterion(outputs, labels)#反向传播loss.backward()#updates weight and parametersoptimizer.step()if epoch % 50 == 0:print("Epoch: {}, Loss: {}".format(epoch, loss.item()))# predict model test,预测结果并且奖结果转换成np格式
predicted = model(torch.from_numpy(x_train).requires_grad_()).data.numpy()
predicted#model save
torch.save(model.state_dict(),'model.pkl')

相关文章:
【Pytorch】学习记录分享3——PyTorch 自动微分与线性回归
【【Pytorch】学习记录分享3——PyTorch 自动微分与线性回归 1. autograd 包,自动微分2. 线性模型回归演示3. GPU进行模型训练 小结:只需要将前向传播设置好,调用反向传播接口,即可实现反向传播的链式求导 1. autograd 包&#x…...

Android Studio实现俄罗斯方块
文章目录 一、项目概述二、开发环境三、详细设计3.1 CacheUtils类3.2 BlockAdapter类3.3 CommonAdapter类3.4 SelectActivity3.5 MainActivity 四、运行演示五、项目总结 一、项目概述 俄罗斯方块是一种经典的电子游戏,最早由俄罗斯人Alexey Pajitnov在1984年创建。…...

【Hive】——DDL(DATABASE)
1 概述 2 创建数据库 create database if not exists test_database comment "this is my first db" with dbproperties (createdByAllen);3 描述数据库信息 describe 可以简写为desc extended 可以展示更多信息 describe database test_database; describe databa…...

【华为OD题库-092】单词加密-java
题目 输入一个英文句子,句子中包含若干个单词,每个单词间有一个空格需要将句子中的每个单词按照要求加密输出。要求: 1)单词中包括元音字符(‘aeuio’、‘AEUIO’,大小写都算),则将元音字符替换成’*) 2)单词中不包括元音字符&…...

构建一个简单的 npm 验证项目
构建一个简单的 npm 验证项目 0. 背景1. 构建过程1-1. 创建项目并初始化1-2. 安装 mjs 支持的 package1-3. 在 package.json 中添加 mjs 脚本1-4. 创建 index.mjs 文件1-5. 执行脚本 2. (Optional)环境变量配置 0. 背景 工作上需要验证一下 npm 程序,所以需要构建一…...
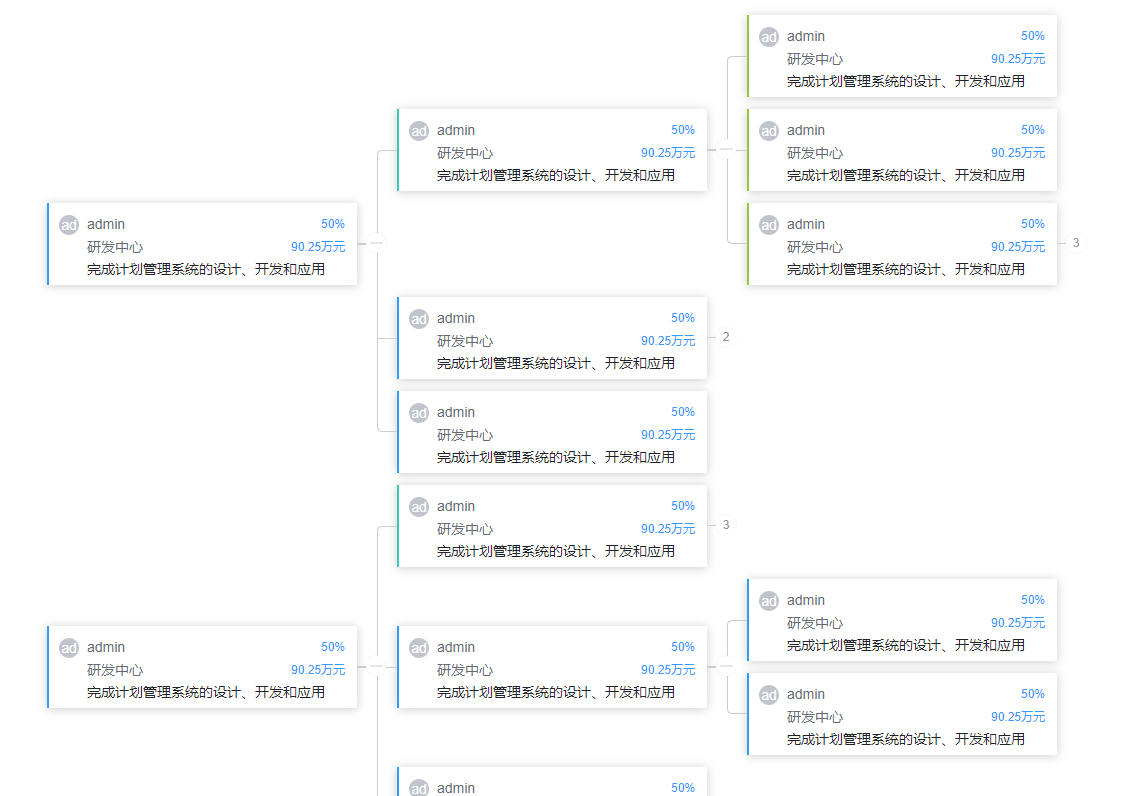
利用vue-okr-tree实现飞书OKR对齐视图
vue-okr-tree-demo 因开发需求需要做一个类似飞书OKR对齐视图的功能,参考了两位大神的代码: 开源组件vue-okr-tree作者博客地址:http://t.csdnimg.cn/5gNfd 对组件二次封装的作者博客地址:http://t.csdnimg.cn/Tjaf0 开源组件v…...
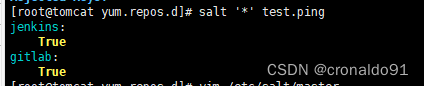
持续集成交付CICD:CentOS 7 安装SaltStack
目录 一、理论 1.SaltStack 二、实验 1.主机一安装master 2.主机二安装第一台minion 3.主机三安装第二台minion 4.测试SaltStack 三、问题 1.CentOS 8 如何安装SaltStack 一、理论 1.SaltStack (1)概念 SaltStack是基于python开发的一套C/S自…...
vscode 环境配置
必备插件 配置调试 {// Use IntelliSense to learn about possible attributes.// Hover to view descriptions of existing attributes.// For more information, visit: https://go.microsoft.com/fwlink/?linkid830387"version": "0.2.0","confi…...
pytorch文本分类(二):引入pytorch处理文本数据
pytorch文本数据处理 目录 pytorch文本数据处理1. Pytorch背景2. 数据分割3. 数据加载Dataset代码分析字典的用途代码修改的目的 Dataloader 4. 练习 原学习任务链接 相关数据链接:https://pan.baidu.com/s/1iwE3LdRv3uAkGGI2fF9BjA?pwdro0v 提取码:ro…...

Centos硬盘操作合集
一、硬盘命令说明 lsblk 列出系统上的所有磁盘列表 查看磁盘列表 参数意义 blkid 列出硬盘UUID [rootzs ~]# blkid /dev/sda1: UUID"77dcd110-dad6-45b8-97d4-fa592dc56d07" TYPE"xfs" /dev/sda2: UUID"oDT0oD-LCIJ-Xh7r-lBfd-axLD-DRiN-Twa…...
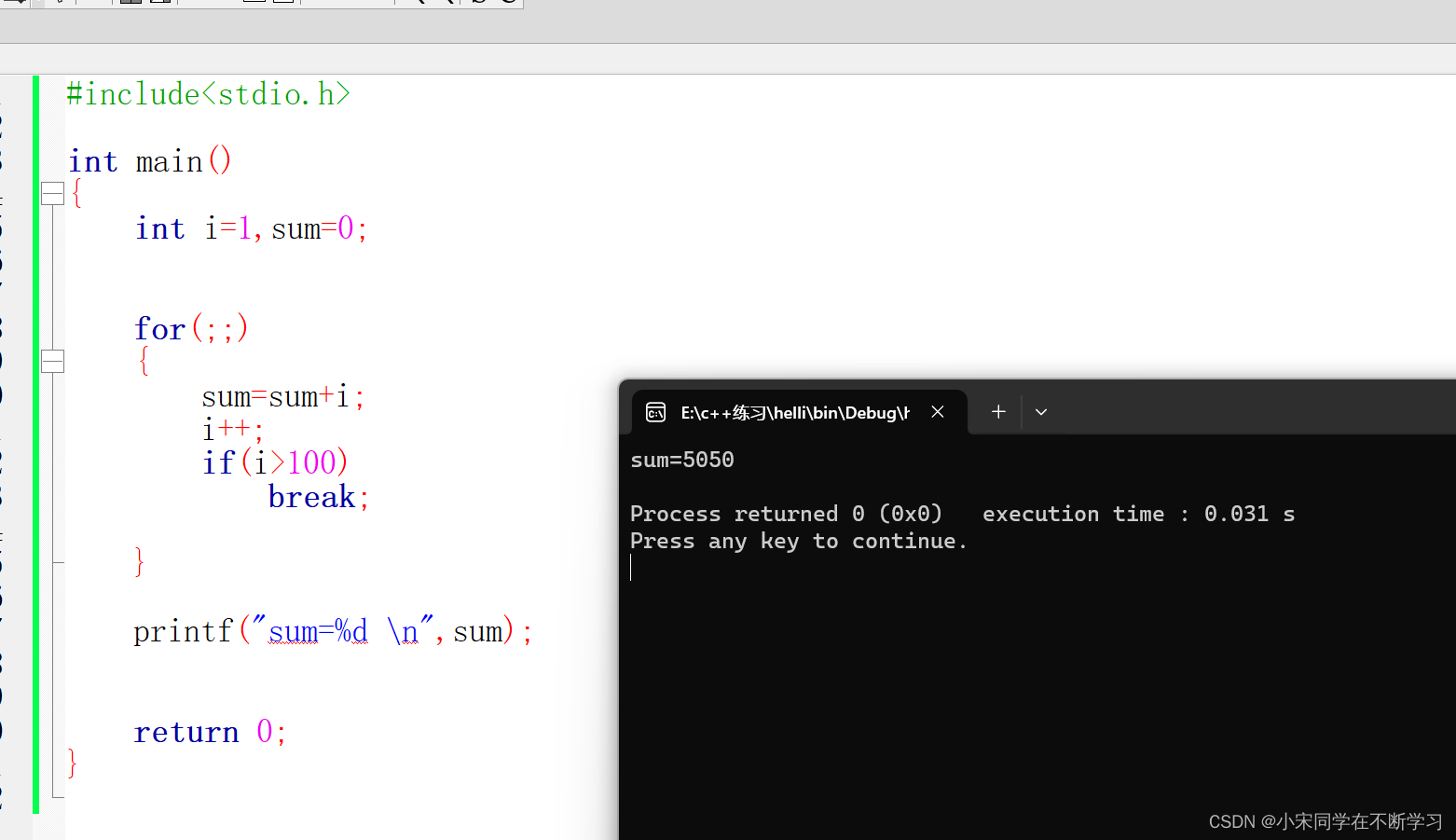
三大循环语句
goto 我们看代码去感受goto的循环,那么goto循环最经常搭配的就是loop,那么就像如下代码 这个代码中loop:就是个标志,然后程序正常向下运行,goto loop;就会让她回到loop,然后在运行到goto loop…...
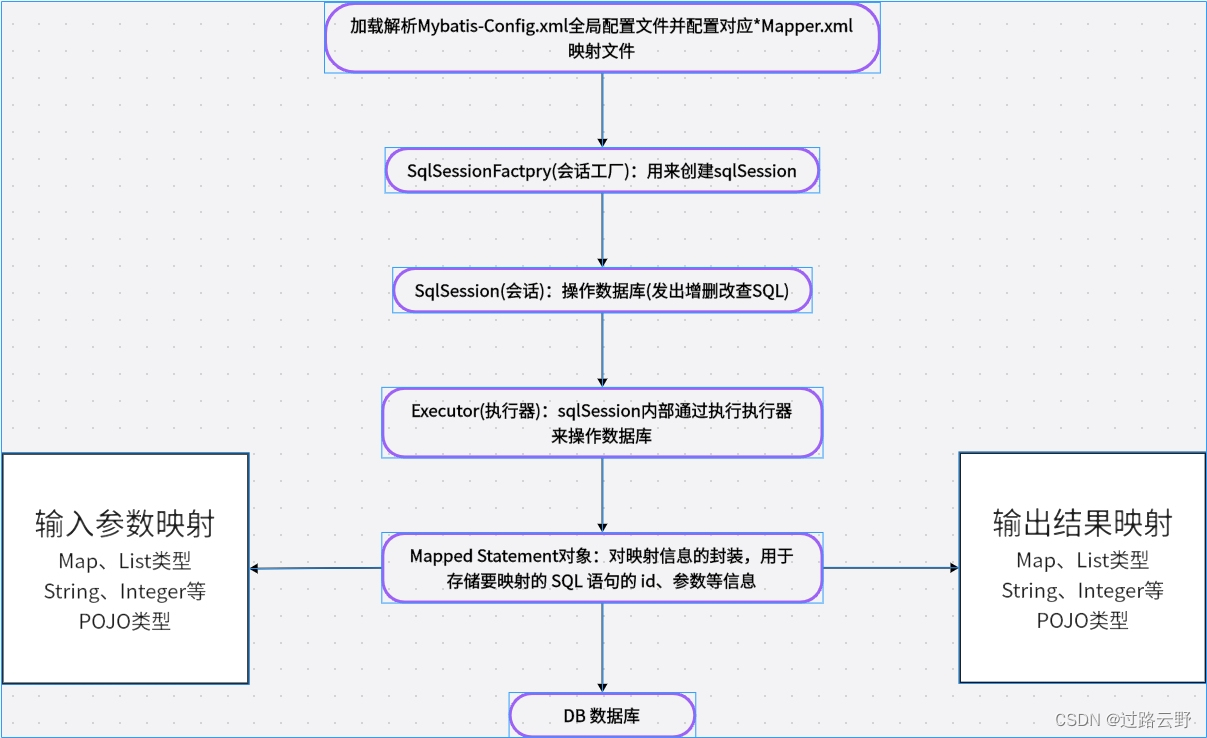
Mybatis详解
MyBatis是什么 MyBatis是一个持久层框架,用于简化数据库操作的开发。它通过将SQL语句和Java方法进行映射,实现了数据库操作的解耦和简化。以下是MyBatis的优点和缺点: 优点: 1. 灵活性:MyBatis允许开发人员编写原生的…...

spring cloud alibaba RocketMQ 最佳实践
目录 概述使用准备工作引入依赖创建Topic代码应用启动消息接收再扩展一个 结束 概述 github 文档地址 rocket mq example RocketMQ 版本为 5.1.4 使用 准备工作 阅读此文需要事先准备 RocketMQ ,如有疑问,请移步 RocketMQ 服务搭建 引入依赖 此处…...

php使用OpenCV实现从照片中截取身份证区域照片
<?php // 获取上传的文件 $file $_FILES[file]; // 获取文件的临时名称 $tmp_name $file[tmp_name]; // 获取文件的类型 $type $file[type]; // 获取文件的大小 $size $file[size]; // 获取文件的错误信息 $error $file[error]; // 检查文件是否上传成功 if ($er…...

抖音ip地址切换会看不到视频吗
随着社交媒体平台的快速发展,抖音已经成为了许多人分享生活点滴、展示才艺的热门平台。然而,有时候使用抖音时会遇到一些问题,比如IP地址切换后无法观看视频。那么,为什么会出现这种情况呢?让我们分析一下。 首先&…...
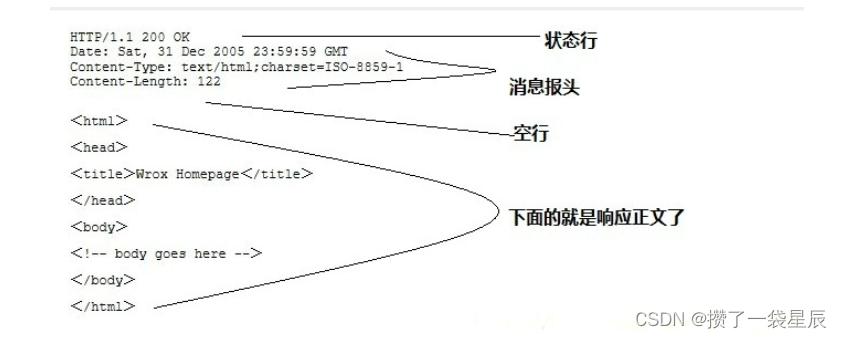
有关爬虫http/https的请求与响应
简介 HTTP协议(HyperText Transfer Protocol,超文本传输协议):是一种发布和接收 HTML页面的方法。 HTTPS(Hypertext Transfer Protocol over Secure Socket Layer)简单讲是HTTP的安全版,在HTT…...

模块二——滑动窗口:438.找到字符串中所有字母异位词
文章目录 题目描述算法原理滑动窗口哈希表 代码实现 题目描述 题目链接:438.找到字符串中所有字母异位词 算法原理 滑动窗口哈希表 因为字符串p的异位词的⻓度⼀定与字符串p 的⻓度相同,所以我们可以在字符串s 中构造⼀个⻓度为与字符串p的⻓度相同…...

排序算法(二)-冒泡排序、选择排序、插入排序、希尔排序、快速排序、归并排序、基数排序
排序算法(二) 前面介绍了排序算法的时间复杂度和空间复杂数据结构与算法—排序算法(一)时间复杂度和空间复杂度介绍-CSDN博客,这次介绍各种排序算法——冒泡排序、选择排序、插入排序、希尔排序、快速排序、归并排序、基数排序。 文章目录 排…...
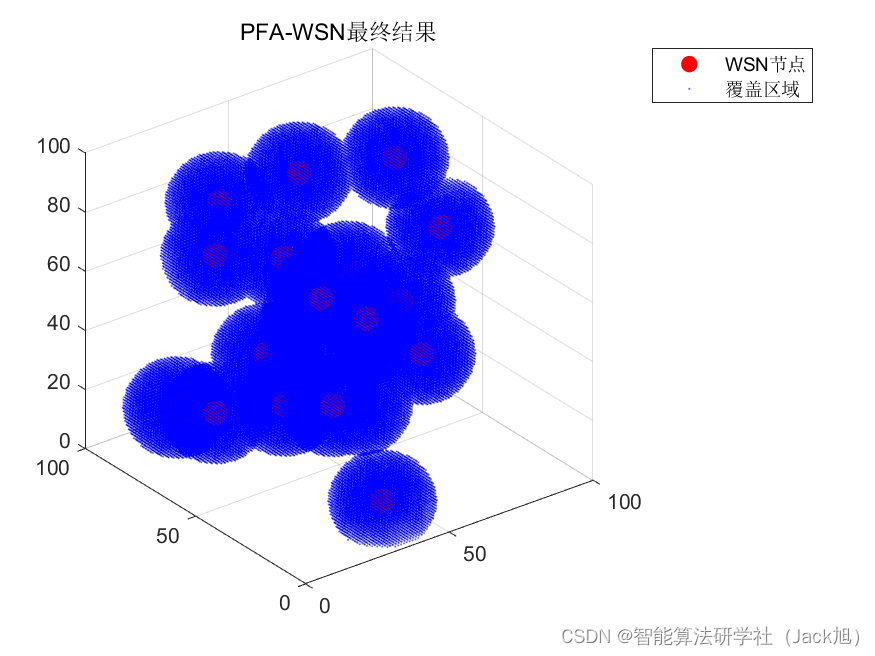
智能优化算法应用:基于探路者算法3D无线传感器网络(WSN)覆盖优化 - 附代码
智能优化算法应用:基于探路者算法3D无线传感器网络(WSN)覆盖优化 - 附代码 文章目录 智能优化算法应用:基于探路者算法3D无线传感器网络(WSN)覆盖优化 - 附代码1.无线传感网络节点模型2.覆盖数学模型及分析3.探路者算法4.实验参数设定5.算法结果6.参考文…...

高效排队,紧急响应:RabbitMQ Priority Queue全面指南【RabbitMQ 九】
欢迎来到我的博客,代码的世界里,每一行都是一个故事 高效排队,紧急响应:RabbitMQ Priority Queue全面指南 引言前言第一:初识RabbitMQ Priority Queue插件插件的背景和目的:为什么需要消息优先级࿱…...

零编程DIY柔性硅胶霓虹LED灯带:低成本打造专属自拍背景墙
1. 项目概述:打造你的专属发光背景每次刷社交媒体,看到那些博主在酷炫的霓虹灯背景前拍出质感大片,是不是心里也痒痒的?但一想到定制霓虹灯牌动辄上千的费用和复杂的安装,热情瞬间被浇灭一半。别急,今天分享…...

十六呀,今天对我们都是很特殊的一天吧
今天对你坦白了 不是表白,是坦白 说了一些你早就知道的话 我说我想放下了 我说交给时间 不是我真的想放下 是我没有别的选择了 就做好朋友吧 如果你还愿意的话 我们会是很好的朋友 放下吧,如果真的可以,真的甘心的话。 好久好久之后 也许真的…...

ElevenLabs语音克隆合规红线速查手册,2024最新GDPR+CCPA+中国《生成式AI服务管理暂行办法》三重适配指南
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs语音克隆合规性认知总览 语音克隆技术正以前所未有的精度重塑人机交互边界,但其法律与伦理风险亦同步升级。ElevenLabs 作为行业领先者,明确将《服务条款》第5.2条与《…...

完全掌握Adobe软件激活:5个实用技巧深度解析
完全掌握Adobe软件激活:5个实用技巧深度解析 【免费下载链接】Adobe-GenP Adobe CC 2019/2020/2021/2022/2023 GenP Universal Patch 3.0 项目地址: https://gitcode.com/gh_mirrors/ad/Adobe-GenP 你是否曾经为Adobe Creative Cloud的订阅费用感到困扰&…...

中国科学院大学与上海人工智能实验室联手打造的“排版医生“
这项由中国科学院大学、上海人工智能实验室及上海交通大学联合开展的研究,以预印本形式发布于2026年5月,论文编号为arXiv:2605.10341,感兴趣的读者可通过该编号在arXiv平台查阅完整原文。**研究概要:那个让所有人头疼的"最后…...
那点事儿)
从激光雷达到智能家居:深入浅出聊聊激光安全分类(Class 1/2/3/4)那点事儿
从激光雷达到智能家居:深入浅出聊聊激光安全分类(Class 1/2/3/4)那点事儿 激光技术正悄然渗透进我们生活的每个角落——从自动驾驶汽车的"眼睛"到智能门锁的指纹识别,从工业切割到医疗美容,这些看似毫不相关…...

VideoDownloadHelper终极指南:三分钟掌握免费视频下载插件
VideoDownloadHelper终极指南:三分钟掌握免费视频下载插件 【免费下载链接】VideoDownloadHelper Chrome Extension to Help Download Video for Some Video Sites. 项目地址: https://gitcode.com/gh_mirrors/vi/VideoDownloadHelper VideoDownloadHelper是…...
)
Mac磁盘工具里找不到APFS格式?别急,可能是你的U盘分区表选错了(GUID分区图详解)
Mac磁盘工具里找不到APFS格式?可能是分区表惹的祸 当你准备将外置存储设备格式化为APFS时,却发现磁盘工具里压根没有这个选项——这种场景对Mac用户来说并不陌生。上周帮同事迁移数据时就遇到了这个典型问题:一块全新的SSD移动硬盘插入MacBoo…...
)
TVA 在宠物混合监护场景中的创新应用(5)
重磅预告:本专栏将独家连载新书《智能体视觉技术与应用》(系列丛书)部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。…...

3大技术优势:AEUX如何实现Sketch/Figma到After Effects的无缝设计转换
3大技术优势:AEUX如何实现Sketch/Figma到After Effects的无缝设计转换 【免费下载链接】AEUX Editable After Effects layers from Sketch artboards 项目地址: https://gitcode.com/gh_mirrors/ae/AEUX AEUX是一款专注于提升UX动效设计效率的开源工具&#…...