视觉学习笔记12——百度飞浆框架的PaddleOCR 安装、标注、训练以及测试
系列文章目录
虚拟环境部署
参考博客1
参考博客2
参考博客3
参考博客4
文章目录
- 系列文章目录
- 一、简单介绍
- 1.OCR介绍
- 2.PaddleOCR介绍
- 二、安装
- 1.anaconda基础环境
- 1)anaconda的基本操作
- 2)搭建飞浆的基础环境
- 2.安装paddlepaddle-gpu版本
- 1)安装
- 2)验证
- 3.pip安装paddleocr whl包
- 1)2.6版本的paddleocr安装
- 2)验证
- 4.安装PPOCRLabel
- 1)2.6版本paddleocr和PPOCRLabel的版本对应
- 2)2.7版本paddleocr和PPOCRLabel的版本对应
- 三、PPOCRLabel标注
- 四、PaddleOCR训练与测试
- 1.文本检测模型训练与测试
- 1)下载预训练模型
- 2)修改参数配置文件
- 3)可视化训练过程
- 4)模型评估测试
- 2.文本识别模型训练
- 1)下载预训练模型
- 2)修改参数配置文件
- 3)可视化训练过程
- 4)模型评估测试
- 五、补充
一、简单介绍
1.OCR介绍
OCR(光学字符识别)是一种将图像中的文字自动转换为可编辑文本的技术。现在,各大厂商均有提供各种场景的OCR识别的API。但是,也有一些开源的OCR框架和工具,可以支持自我定制和训练,使得开发人员能够更加灵活地应对不同场景下的OCR需求。
OCR(光学字符识别)的简单实现流程通常包括以下步骤:
1、图像预处理:首先,对输入的图像进行预处理,包括灰度化、二值化、去噪等操作。这些操作有助于提高字符识别的准确性和稳定性。
2、文本区域检测:使用图像处理技术(如边缘检测、轮廓分析等),找到图像中可能包含文本的区域。这些区域通常是字符或文本行的边界。
3、字符分割:对于文本行,需要将其分割为单个字符。这可以通过字符之间的间距、连通性等特征进行分割。
4、特征提取:对于每个字符,提取其特征表示。常见的特征包括形状、角度、纹理等。特征提取有助于将字符转化为可供分类器处理的数值表示。
5、字符分类:使用分类器(如机器学习算法或深度学习模型)对提取的字符特征进行分类,将其识别为相应的字符类别。分类器可以是预训练模型,也可以是自定义训练的模型。
6、后处理:对识别的字符进行后处理,如纠正错误、校正倾斜、去除冗余等。这可以提高最终结果的准确性和可读性。
7、输出结果:将识别的字符组合成最终的文本输出,可以是单个字符、单词或完整的文本。
2.PaddleOCR介绍
飞桨首次开源文字识别模型套件PaddleOCR,目标是打造丰富、领先、实用的文本识别模型/工具库。 PaddleOCR是一个基于飞桨开发的OCR(Optical Character Recognition,光学字符识别)系统。其技术体系包括文字检测、文字识别、文本方向检测和图像处理等模块。以下是其优点:
高精度:PaddleOCR采用深度学习算法进行训练,可以在不同场景下实现高精度的文字检测和文字识别。
多语种支持:PaddleOCR支持多种语言的文字识别,包括中文、英文、日语、韩语等。同时,它还支持多种不同文字类型的识别,如手写字、印刷体、表格等。
高效性:PaddleOCR的训练和推理过程都采用了高效的并行计算方法,可大幅提高处理速度。同时,其轻量化设计也使得PaddleOCR能够在移动设备上进行部署,适用于各种场景的应用。
易用性:PaddleOCR提供了丰富的API接口和文档说明,用户可以快速进行模型集成和部署,实现自定义的OCR功能。同时,其开源代码也为用户提供了更好的灵活性和可扩展性。
鲁棒性:PaddleOCR采用了多种数据增强技术和模型融合策略,能够有效地应对图像噪声、光照变化等干扰因素,并提高模型的鲁棒性和稳定性。
总之,PaddleOCR具有高精度、高效性、易用性和鲁棒性等优点,为用户提供了一个强大的OCR解决方案。
对比其他开源的OCR项目:
优点:
轻量模型,执行速度快
支持pip直接安装
ocr识别效果好,效果基本可以比肩大厂收费ocr(非高精版)
支持表格和方向识别
支持补充训练且很方便
缺点:
部分符号识别效果一般,如 '|‘识别为’1’
对于部分加粗字体可能出现误识别,需要自己补充训练
偶尔会出现部分内容丢失的情况
二、安装
1.anaconda基础环境
1)anaconda的基本操作
查看conda环境:
conda info --envs创建虚拟环境
conda create -n your_env_name python=x.x激活或者切换虚拟环境source activate your_env_nam查看虚拟环境中的库conda list关闭虚拟环境
source deactivate 删除虚拟环境
conda remove -n your_env_name --all
2)搭建飞浆的基础环境
因为是新项目,所以专门使用anaconda搭建该项目的基本环境
使用anaconda的环境复制命令,复制一个已经安装好常用库的虚拟环境,这样就可以省下重新安装大部分库的工作了,可以参考虚拟环境部署
假设已有环境名为A,需要生成的环境名为B:(我自己用过,在同一台机器上克隆原始环境到另一个环境,挺好用的)
conda create -n B --clone A比如:
conda create -n ocr --clone py36
2.安装paddlepaddle-gpu版本
1)安装
进入准备好的anaconda环境
根据对应的cuda和cudnn版本,安装对应的paddlepaddle版本
建议不要安装最新的paddlepaddle版本,我安装最新的一直失败
飞浆官网提供的旧版本安装命令
一定要根据自己的环境,选择正确的命令,比如:
# CUDA 10.2
python3 -m pip install paddlepaddle-gpu==2.4.2 -i https://pypi.tuna.tsinghua.edu.cn/simple
2)验证
验证安装是否成功,终端输入python,然后分别输入以下两行代码
import paddlepaddle.utils.run_check()

3.pip安装paddleocr whl包
1)2.6版本的paddleocr安装
推荐使用2.0.1+版本,最新版本为2.7,我选择2.6版本,但是2.6版本的paddleocr和PPOCRLabel之间出现一些未解决环境bug,所以关于2.6版本的paddleocr安装仅供参考,安装命令如下:
pip install "paddleocr>=2.6"
使用了以上命令安装却出现PyMuPDF错误,如下:
Building wheel for PyMuPDF (setup.py) ... error..................ERROR: Failed building wheel for PyMuPDF
github查到具体解决方案
使用如下命令重新安装:
pip install "paddleocr>=2.6" --upgrade PyMuPDF==1.18.0
2)验证
首先使用以下命令查看虚拟环境中的paddleocr是不是2.6版本:
conda list
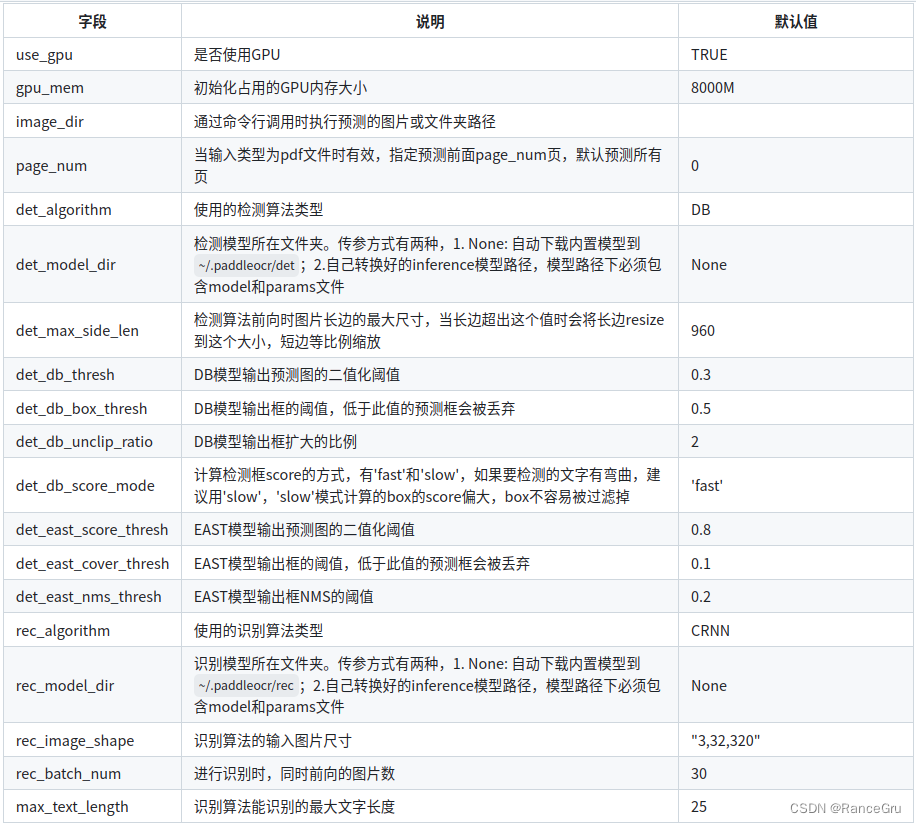
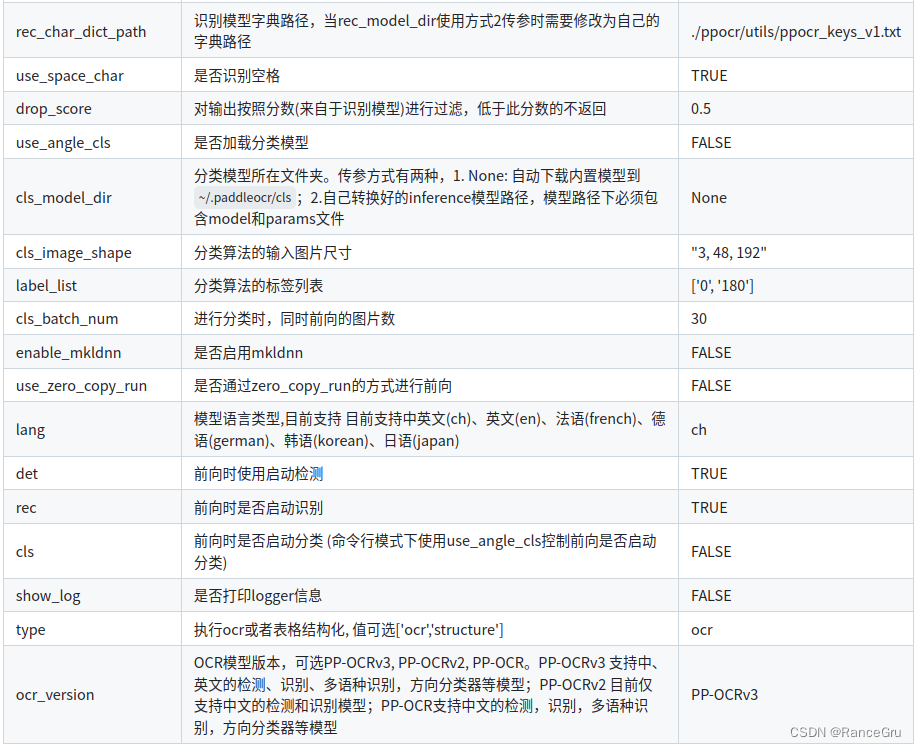
其次下载以下官方提供的推理测试模型进行测试:
det_model_dir是文本检测的位置,
rec_model_dir是文本识别的位置,
cls_model_dir是方向分类的位置,
最后使用以下代码,更新模型与图片路径进行测试:
import os
import timefrom paddleocr import PaddleOCR
import pandas as pd
import numpy as np
import cv2def ocr_predict(img):'''det_model_dir:文本检测rec_model_dir:文本识别cls_model_dir:方向分类'''ocr = PaddleOCR(det_model_dir="路径/det/ch/ch_PP-OCRv4_det_infer/",rec_model_dir="路径/rec/ch/ch_PP-OCRv4_rec_infer/",cls_model_dir="路径/cls/ch_ppocr_mobile_v2.0_cls_infer/",lang='ch', use_angle_cls=True,use_gpu=False)result = ocr.ocr(img)print(result)if __name__ == '__main__':img_path = "路径/ys.jpeg"ocr_predict(img_path)
测试图片:

测试结果:
[[[[[57.0, 31.0], [977.0, 32.0], [977.0, 75.0], [57.0, 74.0]],
(‘椰树集团直接从椰子农户收购海南自种老椰子’, 0.98974609375)], [[[54.0, 93.0], [976.0,
95.0], [976.0, 138.0], [54.0, 136.0]], (‘每个致富价五元,比原来收购价提高两倍’, 0.994292140007019)], [[[172.0, 163.0], [855.0, 163.0], [855.0, 205.0], [172.0, 205.0]], (‘转手收购的椰子不享受致富价’, 0.9931609630584717)], [[[61.0,
230.0], [961.0, 230.0], [961.0, 309.0], [61.0, 309.0]], (‘致富价保证30年不降’, 0.9948785901069641)], [[[128.0, 341.0], [985.0, 341.0], [985.0, 380.0], [128.0, 380.0]], (‘为助力乡村经济振兴,响应省政府大力发展’, 0.9951123595237732)], [[[35.0, 394.0], [745.0, 394.0], [745.0, 437.0], [35.0, 437.0]],
(‘三棵树(椰子树、橡胶树、槟榔树)’, 0.9626081585884094)], [[[757.0, 396.0], [983.0,
396.0], [983.0, 436.0], [757.0, 436.0]], (‘的号召,让’, 0.9951451420783997)], [[[37.0, 451.0], [982.0, 451.0], [982.0, 490.0], [37.0, 490.0]], (‘农民致富,实现椰树集团年产值百亿元,打造’, 0.9915739893913269)],
[[[80.0, 507.0], [980.0, 507.0], [980.0, 546.0], [80.0, 546.0]],
(‘百年椰树”,决定从2021年7月10日开始按’, 0.981215238571167)], [[[33.0, 558.0],
[692.0, 562.0], [692.0, 604.0], [33.0, 601.0]], (‘致富价收购海南农民自种老椰子。’,
0.992202877998352)], [[[35.0, 629.0], [526.0, 629.0], [526.0, 654.0], [35.0, 654.0]], (‘四组收购地址:文昌市东郊镇码头村码头路113号’, 0.9902203679084778)],
[[[754.0, 630.0], [983.0, 630.0], [983.0, 652.0], [754.0, 652.0]],
(‘收购电话:13322039539’, 0.9966092109680176)], [[[35.0, 667.0], [327.0,
667.0], [327.0, 692.0], [35.0, 692.0]], (‘六组收购地址:琼海市合石村’, 0.99151611328125)], [[[754.0, 666.0], [985.0, 666.0], [985.0, 691.0], [754.0, 691.0]], (‘收购电话:13627592295’, 0.9962812662124634)], [[[35.0,
705.0], [562.0, 705.0], [562.0, 730.0], [35.0, 730.0]], (‘八组收购地址:文昌市东郊镇、万宁市长丰镇牛漏村’, 0.980197548866272)], [[[753.0, 704.0],
[983.0, 704.0], [983.0, 729.0], [753.0, 729.0]], (‘收购电话:13876033357’,
0.9965571165084839)], [[[34.0, 742.0], [398.0, 742.0], [398.0, 767.0], [34.0, 767.0]], (‘九组收购地址:文昌市东郊镇白石村’, 0.993116557598114)], [[[754.0,
743.0], [983.0, 743.0], [983.0, 765.0], [754.0, 765.0]], (‘收购电话:13976682778’, 0.9968530535697937)], [[[187.0, 780.0], [396.0,
780.0], [396.0, 805.0], [187.0, 805.0]], (‘文昌市会文镇冠南村’, 0.9976257681846619)], [[[753.0, 780.0], [986.0, 780.0], [986.0, 805.0], [753.0, 805.0]], (‘收购电话:18789985540’, 0.9975140690803528)], [[[35.0, 817.0], [727.0, 818.0], [727.0, 843.0], [35.0, 842.0]],
(‘十组收购地址:文昌市蓬莱镇绿涛收购点、琼海市塔洋镇里文收购点’, 0.9777908325195312)], [[[754.0,
819.0], [983.0, 819.0], [983.0, 841.0], [754.0, 841.0]], (‘收购电话:13907682168’, 0.9975283741950989)], [[[37.0, 856.0], [444.0,
856.0], [444.0, 881.0], [37.0, 881.0]], (‘十一组收购地址:文昌市铺前镇、万宁市’, 0.9792234897613525)], [[[753.0, 855.0], [982.0, 855.0], [982.0, 880.0], [753.0, 880.0]], (‘收购电话:13707557555’, 0.9971356987953186)]]]
4.安装PPOCRLabel
1)2.6版本paddleocr和PPOCRLabel的版本对应
以上完成了paddlepaddle和paddleocr的安装,并成功通过测试
接下来应该完成PPOCRLabel标注工具的安装与使用
打开paddleocr库选择2.6版本下载并解压
https://github.com/PaddlePaddle/PaddleOCR/archive/refs/heads/release/2.6.zip
接着直接进入PPOCRLabel文件夹:
cd PaddleOCR-release-2.6/PPOCRLabel
安装PPOCRLabel,为标注数据作准备,运行以下代码:
python setup.py bdist_wheel
该目录下dist文件夹中会生成一个whl文件
接着运行:
pip3 install dist/PPOCRLabel-2.1.3-py2.py3-none-any.whl
可能会提示缺少polygon 库,可以使用pip install Polygon3 -i https://pypi.tuna.tsinghua.edu.cn/simple命令安装。
如果还提示缺少其他包,同样是用pip install “packname” -i https://pypi.tuna.tsinghua.edu.cn/simple命令安装即可。
安装过程可能会出现的报错:
#无法导入str2int_tuple
ImportError: cannot import name 'str2int_tuple'
/anaconda3/envs/ocr/lib/python3.6/site-packages/paddleocr/tools/infer
目录下的utility.py文件内部缺少str2int_tuple函数,是因为源码安装与命令行安装的paddleocr所导致的,根据源码的utility.py文件去修改虚拟环境下的utility.py文件即可,主要进行以下修改:
# 查找str2bool函数
def str2bool(v):return v.lower() in ("true", "yes", "t", "y", "1")#在str2bool函数后面添加str2int_tuple函数
def str2int_tuple(v):return tuple([int(i.strip()) for i in v.split(",")])
PPOCRLabel安装成功后,运行以下命令打开:
python PPOCRLabel --lang ch
或
PPOCRLabel --lang ch
在尝试打开PPOCRLabel时,出现了一个bug:
Got keys from plugin meta data ("xcb")
QFactoryLoader::QFactoryLoader() checking directory path "/anaconda3/envs/ocr/bin/platforms" ...
loaded library "/anaconda3/envs/ocr/lib/python3.8/site-packages/cv2/qt/plugins/platforms/libqxcb.so"
QObject::moveToThread: Current thread (0xeb24e0) is not the object's thread (0x5bcd480).
Cannot move to target thread (0xeb24e0)qt.qpa.plugin: Could not load the Qt platform plugin "xcb" in "/anaconda3/envs/ocr/lib/python3.8/site-packages/cv2/qt/plugins" even though it was found.
This application failed to start because no Qt platform plugin could be initialized. Reinstalling the application may fix this problem.Available platform plugins are: xcb, eglfs, linuxfb, minimal, minimalegl, offscreen, vnc, wayland-egl, wayland, wayland-xcomposite-egl, wayland-xcomposite-glx, webgl.
这是一个QT问题,很多人都遇见这个问题,常见的解决方法如下:
1、添加bashrc环境export QT_DEBUG_PLUGINS=1,查看是否缺少某些库文件,sudo apt-get install 安装补充
2、降低opencv-contrib-python和opencv-python的版本
3、调整pyqt5的版本或者使用conda安装不使用pip安装pyqt5
4、安装opencv-python-headless库
。。。。。。
我遇到的这个这个问题其实是pyqt5与cv2之间的冲突问题,pyqt5与anaconda3/envs/ocr/lib/python3.8/site-packages/cv2/qt/plugins/platforms发生了冲突,,以上的方法大多数也是倾向于解决掉cv2中的platforms。
官方提供的思路如下:
pip install opencv-python==4.2.0.32 -i https://pypi.tuna.tsinghua.edu.cn/simple
如果不想修改cv版本,那么就去把anaconda3/envs/ocr/lib/python3.8/site-packages/cv2/qt/plugins/platforms中的platforms重命名即可。
按理来说到这里就没有问题了,但是我在启动PPOCRLabel时又出现以下报错而且打不开PPOCRLabel,至今没有解决:
Got keys from plugin meta data ("xcb_glx")
QFactoryLoader::QFactoryLoader() checking directory path "/anaconda3/envs/ocr/bin/xcbglintegrations" ...
loaded library "/anaconda3/envs/ocr/lib/python3.8/site-packages/PyQt5/Qt5/plugins/xcbglintegrations/libqxcb-glx-integration.so"
[2023/12/06 09:42:12] ppocr WARNING: When args.layout is false, args.ocr is automatically set to false
折腾了几天后,觉得是2.6版本paddleocr和PPOCRLabel之间的bug导致的,因为使用2.7版本就能够打开PPOCRLabel。
2)2.7版本paddleocr和PPOCRLabel的版本对应
最新版本2.7,安装命令如下:
pip install "paddleocr==2.7"
与2.6版本的PPOCRLabel源码安装类似
打开paddleocr库选择2.7版本下载并解压
接着直接进入PPOCRLabel文件夹:
cd PaddleOCR-release-2.7/PPOCRLabel
安装PPOCRLabel,为标注数据作准备,运行以下代码:
python setup.py bdist_wheel
该目录下dist文件夹中会生成一个whl文件
接着运行:
#这里就有一些不同
pip3 install dist/paddleocr-2.7.0.1-py3-none-any.whl
可能会提示缺少polygon 库,可以使用pip install Polygon3 -i https://pypi.tuna.tsinghua.edu.cn/simple命令安装。
如果还提示缺少其他包,同样是用pip install “packname” -i https://pypi.tuna.tsinghua.edu.cn/simple命令安装即可。
PPOCRLabel安装成功后,运行以下命令打开:
python PPOCRLabel --lang ch
或
PPOCRLabel --lang ch
在尝试打开PPOCRLabel时,同样出现bug:
Got keys from plugin meta data ("xcb")
QFactoryLoader::QFactoryLoader() checking directory path "/anaconda3/envs/ocr/bin/platforms" ...
loaded library "/anaconda3/envs/ocr/lib/python3.8/site-packages/cv2/qt/plugins/platforms/libqxcb.so"
QObject::moveToThread: Current thread (0xeb24e0) is not the object's thread (0x5bcd480).
Cannot move to target thread (0xeb24e0)qt.qpa.plugin: Could not load the Qt platform plugin "xcb" in "/anaconda3/envs/ocr/lib/python3.8/site-packages/cv2/qt/plugins" even though it was found.
This application failed to start because no Qt platform plugin could be initialized. Reinstalling the application may fix this problem.Available platform plugins are: xcb, eglfs, linuxfb, minimal, minimalegl, offscreen, vnc, wayland-egl, wayland, wayland-xcomposite-egl, wayland-xcomposite-glx, webgl.
官方提供的思路如下:
pip install opencv-python==4.2.0.32 -i https://pypi.tuna.tsinghua.edu.cn/simple
如果不想修改cv版本,那么就去把anaconda3/envs/ocr/lib/python3.8/site-packages/cv2/qt/plugins/platforms中的platforms重命名即可。
启动PPOCRLabelPPOCRLabel --lang ch又出现以下报错:
Got keys from plugin meta data ("xcb_glx")
QFactoryLoader::QFactoryLoader() checking directory path "/anaconda3/envs/ocr/bin/xcbglintegrations" ...
loaded library "/anaconda3/envs/ocr/lib/python3.8/site-packages/PyQt5/Qt5/plugins/xcbglintegrations/libqxcb-glx-integration.so"
[2023/12/06 09:42:12] ppocr WARNING: When args.layout is false, args.ocr is automatically set to false
但是PPOCRLabel却能够成功开启。
三、PPOCRLabel标注
1)先命令行打开PPOCRLabel图形化界面
2)打开左上角的PaddleOCR选项列表,点击选择模型选项,然后选择中文&英文,确认
3)打开左上角的文件选项列表,点击打开目录选项,打开需要标注的图片所在文件夹
4)点击左下角的自动标注选项,PPOCRLabel会自动调用模型对每张图片进行标注,等待进度条100%,然后OK
5)自动标注结束以后,打开左上角的文件选项列表,点击导出标记结果和导出识别结果选项
6)开始对每张图片进行检查,点击矩形标注和多点标注选项,手动修改不好的检测框和标签,没问题的点击确认,不喜欢的点击删除图片选项,PPOCRLabel工具操作快捷键如下
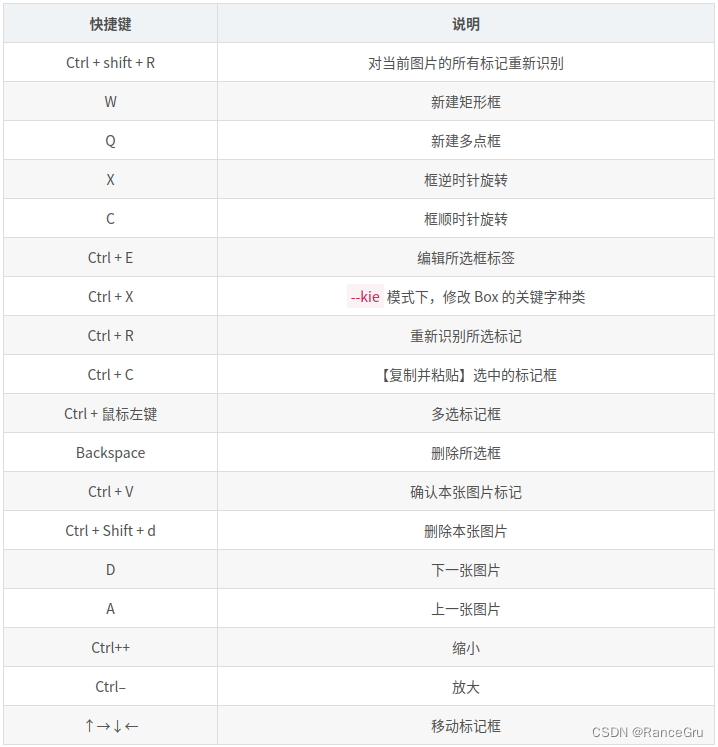
7)标注结束以后,再次点击导出标记结果和导出识别结果选项,然后检查图片文件夹中是否生成以下文件
| 文件名 | 说明 |
|---|---|
| Label.txt | 检测标签,可直接用于PPOCR检测模型训练。用户每确认5张检测结果后,程序会进行自动写入。当用户关闭应用程序或切换文件路径后同样会进行写入。 |
| fileState.txt | 图片状态标记文件,保存当前文件夹下已经被用户手动确认过的图片名称。 |
| Cache.cach | 缓存文件,保存模型自动识别的结果。 |
| rec_gt.txt | 识别标签。可直接用于PPOCR识别模型训练。需用户手动点击菜单栏“文件” - "导出识别结果"后产生。 |
| crop_img | 识别数据。按照检测框切割后的图片。与rec_gt.txt同时产生。 |
8)输入以下命令执行数据集划分脚本:
trainValTestRatio 是训练集、验证集、测试集的图像数量划分比例,根据实际情况设定,默认是6:2:2
datasetRootPath 是PPOCRLabel标注的完整数据集存放路径。默认路径是 PaddleOCR/train_data 分割数据集前
cd ./PPOCRLabel # 将目录切换到PPOCRLabel文件夹下
python gen_ocr_train_val_test.py --trainValTestRatio 6:2:2 --datasetRootPath /home/完整数据集存放路径/train_data
train_data格式如下:
|-train_data|-crop_img|- 001_crop_0.png|- 002_crop_0.jpg|- 003_crop_0.jpg| ...| Label.txt| rec_gt.txt|- 001.png|- 002.jpg|- 003.jpg| ...
划分好的数据集会保存在PaddleOCR/train_data下面
此时文字检测和文字识别的数据集就都制作好了。
四、PaddleOCR训练与测试
为了加强垂直领域或者说特殊环境下的检测能力,所以会专门使用对应环境的数据集进行训练,得到我们理想中的的模型。
1.文本检测模型训练与测试
根据官方文本检测教程中最简单直接的思路进行训练,至于其他训练方法可以深入参考官方教程。
1)下载预训练模型
准备好数据集后,可以下载模型预训练文件:
MobileNetV3_large_x0_5_pretrained模型下载
还可以选择以下模型:
# 下载MobileNetV3的预训练模型
wget -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/pretrained/MobileNetV3_large_x0_5_pretrained.pdparams
# 或,下载ResNet18_vd的预训练模型
wget -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/pretrained/ResNet18_vd_pretrained.pdparams
# 或,下载ResNet50_vd的预训练模型
wget -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/pretrained/ResNet50_vd_ssld_pretrained.pdparams
下载之后在paddleocr根目录下建立pretrain_models文件夹,并将训练模型放在该文件夹下并解压。
2)修改参数配置文件
修改/PaddleOCR/configs/det目录下的det_mv3_db.yml,或者复制一份重命名。
有关配置文件各项参数的详细解释,请参考官方文档
部分常见配置的修改,建议根据各自训练环境自定义配置文件
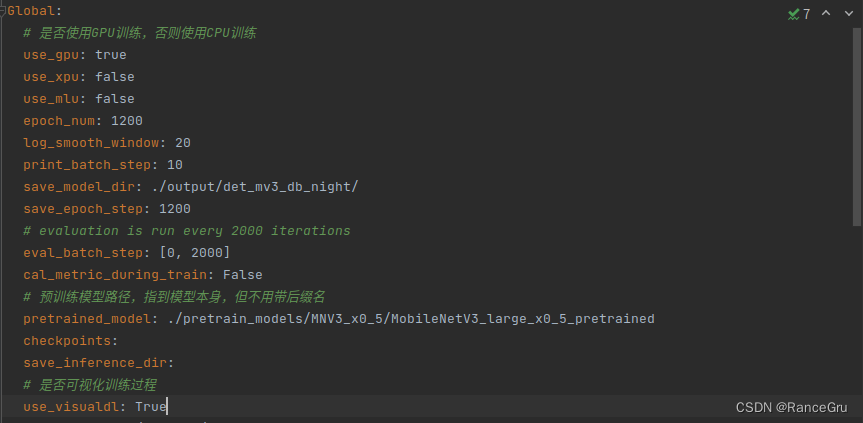

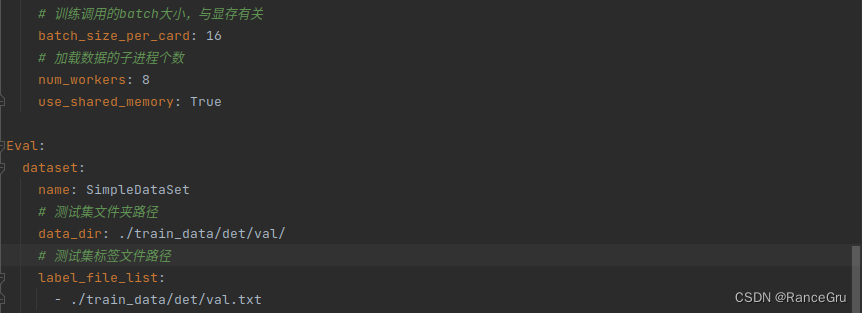
python tools/train.py -c configs/llw/det_mv3_db.yml -o Global.pretrained_model=./pretrain_models/MNV3_x0_5/MobileNetV3_large_x0_5_pretrained
如果提示RuntimeError: CUDA out of memory.就需要降低batch,或者清理GPU缓存,总会有奇奇怪怪的进程占着资源不放。
3)可视化训练过程
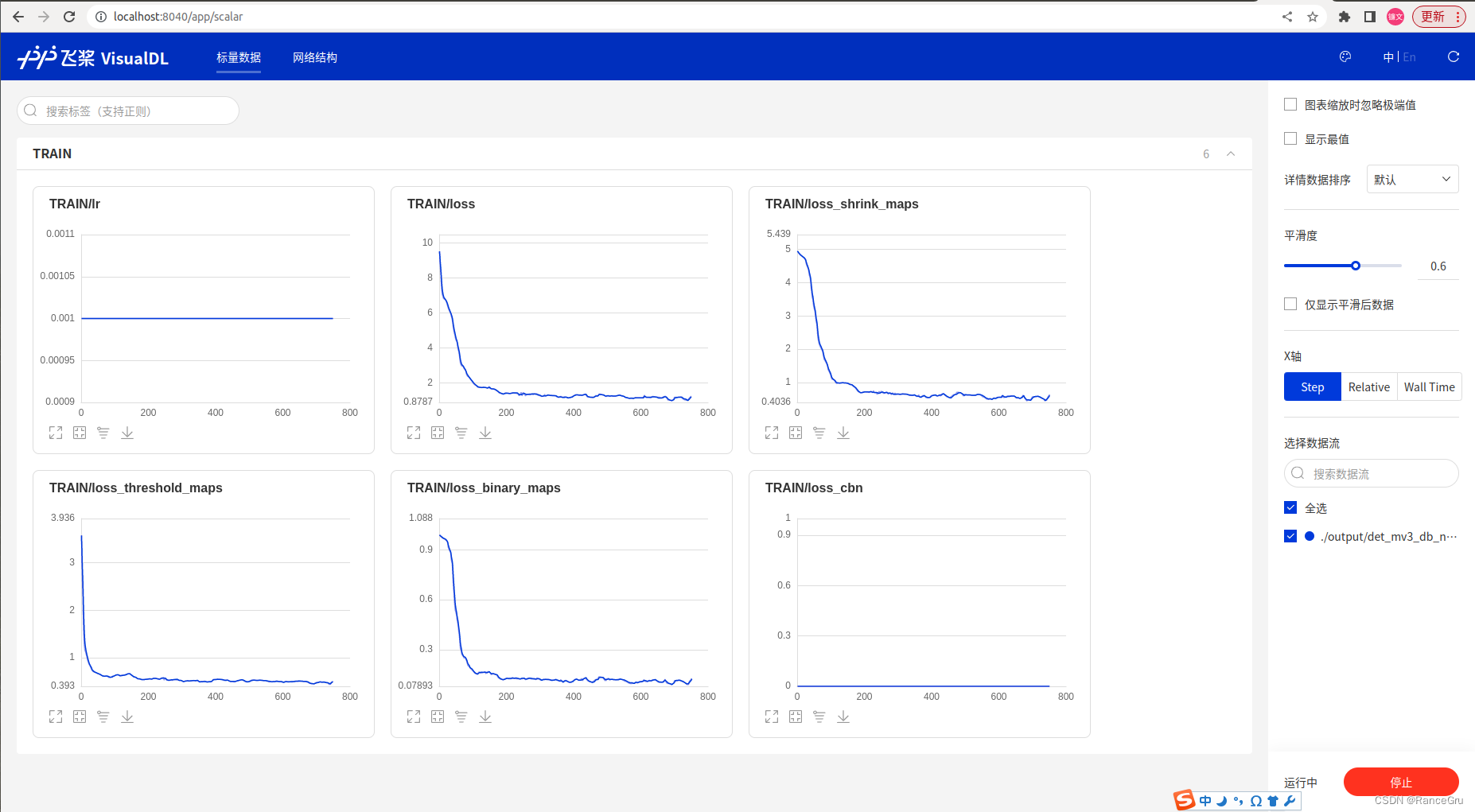
训练过程中,PaddleOCR文件夹下再开一个终端,输入以下命令+模型输出地址可视化训练过程:
visualdl --logdir "./output/db_mv3"

打开http://localhost:8040/,点击标量数据,即可看见实时信息
4)模型评估测试
评估模型,输入以下命令:
python tools/eval.py -c configs/det/det_mv3_db.yml -o Global.checkpoints=./output/db_mv3/best_accuracy

对训练好的模型导出导出到/inference/det_db文件夹下,输入以下命令
python tools/export_model.py -c configs/det/det_mv3_db_ocr.yml -o Global.pretrained_model=./output/db_mv3/best_accuracy Global.save_inference_dir=./inference/det_db
最后使用以下代码,把自己训练的模型更新到det_model_dir,进行测试:
import os
import timefrom paddleocr import PaddleOCR
import pandas as pd
import numpy as np
import cv2def ocr_predict(img):'''det_model_dir:文本检测rec_model_dir:文本识别cls_model_dir:方向分类'''ocr = PaddleOCR(det_model_dir="路径/inference/det_db/",rec_model_dir="路径/rec/ch/ch_PP-OCRv4_rec_infer/",cls_model_dir="路径/cls/ch_ppocr_mobile_v2.0_cls_infer/",lang='ch', use_angle_cls=True,use_gpu=False)result = ocr.ocr(img)print(result)if __name__ == '__main__':img_path = "路径/ys.jpeg"ocr_predict(img_path)
同样成功获取到文本坐标,再根据坐标信息使用ch_PP-OCRv4_rec_infer模型进行识别,具体结果与上文一样,不在此复诉。
2.文本识别模型训练
根据官方文本识别教程中最简单直接的思路进行训练,至于其他训练方法可以深入参考官方教程。
1)下载预训练模型
准备好数据集后,可以下载模型预训练文件:
中英文超轻量ch_PP-OCRv3_rec_train模型下载
还可以选择以下模型:
# 下载中英文超轻量PP-OCRv4模型
wget -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/PP-OCRv4/chinese/ch_PP-OCRv4_rec_train.tar
# 或,下载中英文超轻量PP-OCRv3模型
wget -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_train.tar
# 或,下载英文超轻量PP-OCRv3模型
wget -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_rec_train.tar
下载之后将训练模型放在pretrain_models文件夹下并解压。
ch_PP-OCRv4_rec_train模型训练涉及到模型蒸馏,所以退而求其次使用ch_PP-OCRv3_rec_train模型。
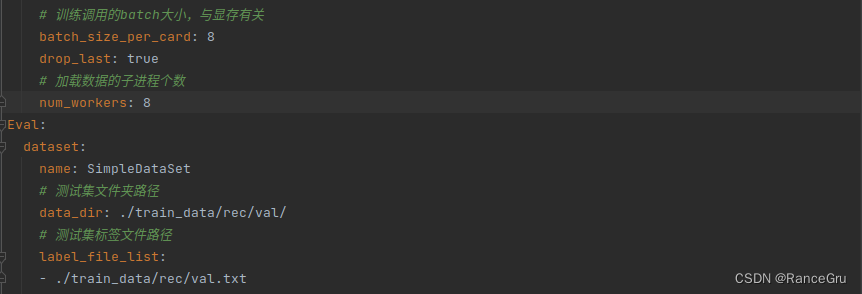
2)修改参数配置文件
修改/PaddleOCR/configs/rec/PP-OCRv3/目录下的cn_PP-OCRv3_rec.yml,或者复制一份重命名。
有关配置文件各项参数的详细解释,请参考官方文档
部分常见配置的修改,建议根据各自训练环境自定义配置文件


python tools/train.py -c configs/llw/ch_PP-OCRv3_rec.yml -o Global.pretrained_model=./pretrain_models/ch_PP-OCRv3_rec_train/best_accuracy
如果提示RuntimeError: CUDA out of memory.就需要降低batch,或者清理GPU缓存,总会有奇奇怪怪的进程占着资源不放。
3)可视化训练过程
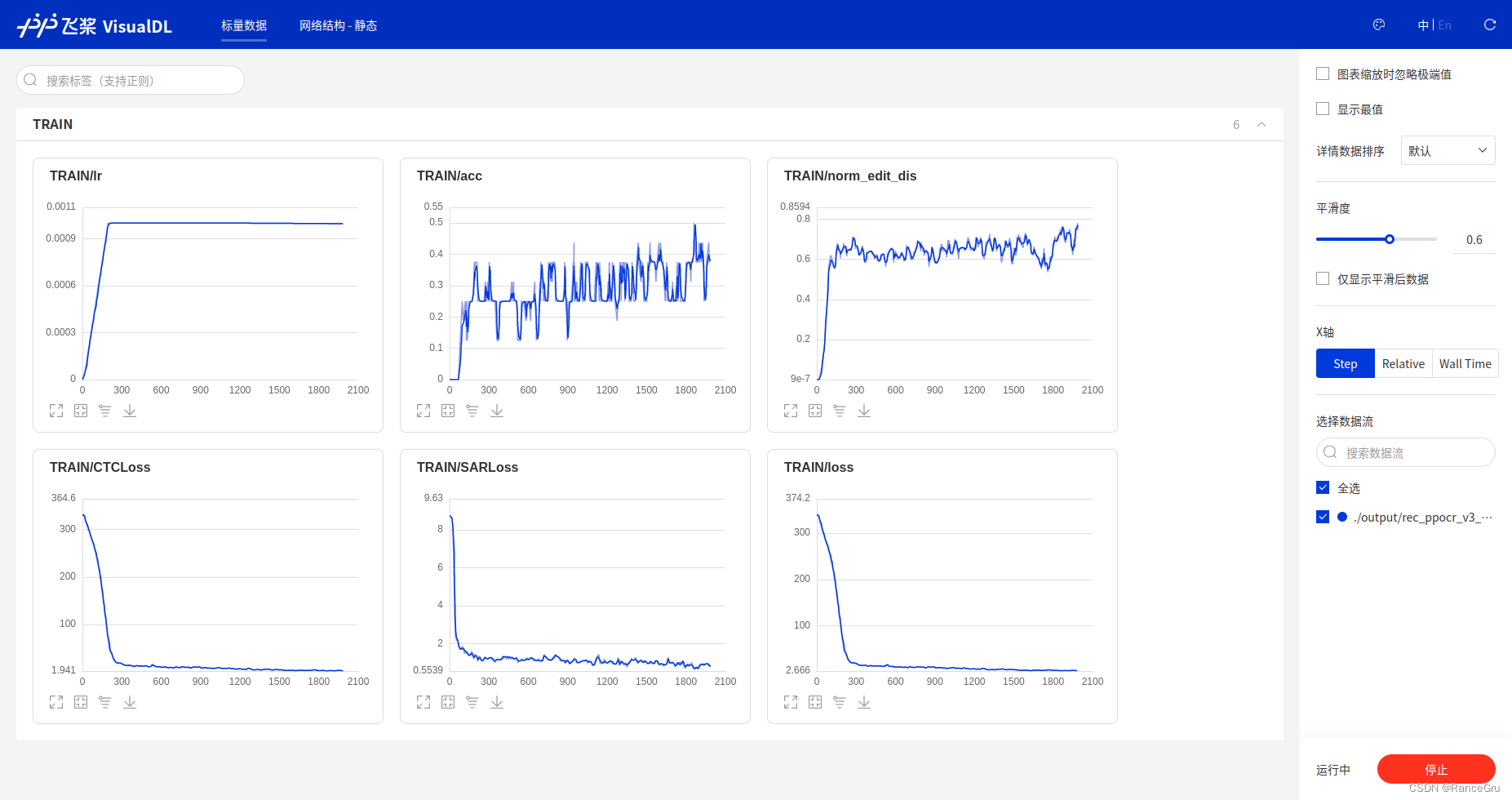
训练过程中,PaddleOCR文件夹下再开一个终端,输入以下命令+模型输出地址可视化训练过程:
visualdl --logdir "./output/rec_ppocr_v3"
打开http://localhost:8040/,点击标量数据,即可看见实时信息
4)模型评估测试
评估模型,输入以下命令:
python tools/eval.py -c configs/rec/ch_PP-OCRv3_rec.yml -o Global.checkpoints=./output/rec_ppocr_v3/latest

对训练好的模型导出导出到/inference/rec_v3文件夹下,输入以下命令
python tools/export_model.py -c configs/rec/ch_PP-OCRv3_rec.yml -o Global.pretrained_model=./output/rec_ppocr_v3/best_accuracy Global.save_inference_dir=./inference/rec_v3
最后使用以下代码,把自己训练的模型更新到rec_model_dir,进行测试:
import os
import timefrom paddleocr import PaddleOCR
import pandas as pd
import numpy as np
import cv2def ocr_predict(img):'''det_model_dir:文本检测rec_model_dir:文本识别cls_model_dir:方向分类'''ocr = PaddleOCR(det_model_dir="路径/inference/det_db/",rec_model_dir="路径inference/rec_v3/",cls_model_dir="路径/cls/ch_ppocr_mobile_v2.0_cls_infer/",lang='ch', use_angle_cls=True,use_gpu=False)result = ocr.ocr(img)print(result)if __name__ == '__main__':img_path = "路径/ys.jpeg"ocr_predict(img_path)
五、补充
更多官方模型链接
yml部分参数说明
相关文章:
视觉学习笔记12——百度飞浆框架的PaddleOCR 安装、标注、训练以及测试
系列文章目录 虚拟环境部署 参考博客1 参考博客2 参考博客3 参考博客4 文章目录 系列文章目录一、简单介绍1.OCR介绍2.PaddleOCR介绍 二、安装1.anaconda基础环境1)anaconda的基本操作2)搭建飞浆的基础环境 2.安装paddlepaddle-gpu版本1)安装…...

深入分析ClassLocader工作机制
文章目录 一、ClassLoader简介1. 概念2. ClassLoader类结构分析 二、ClassLoader的双亲委派机制三、Class文件的加载流程1. 简介2. 加载字节码到内存3. 验证与解析4. 初始化Class对象 四、常见加载类错误分析1. ClassNotFoundException2. NoClassDefFoundError3. UnsatisfiledL…...
算法通关村第十二关—字符串转换(青铜)
一、转换成小写字母 LeetCode709.给你一个字符串s,将该字符串中的大写字母转换成相同的小写字母,返回新的字符串。 示例1: 输入:s"Hello" 输出:"hello" 示例2: 输入:s&qu…...
)
C#基础与进阶扩展合集-基础篇(持续更新)
目录 本文分两篇,进阶篇点击:C#基础与进阶扩展合集-进阶篇 一、基础入门 Ⅰ 关键字 Ⅱ 特性 Ⅲ 常见异常 Ⅳ 基础扩展 1、哈希表 2、扩展方法 3、自定义集合与索引器 4、迭代器与分部类 5、yield return 6、注册表 7、不安全代码 8、方法…...

ReactJs笔记摘录
文章目录 前言目录结构组件动态组件高阶组件 Hook函数useStateuseEffectuseContextuseReduceruseCallbackuseMemo JSX语法根元素与斜杠使用变量推荐使用className替代class属性写法三元表达式 vs &&antd和tailwindcss 组件通信父传子:props和自定义函数事件…...

2023 re:Invent使用 PartyRock 和 Amazon Bedrock 安全高效构建 AI 应用程序
前言 本篇文章授权活动官方亚马逊云科技文章转发、改写权,包括不限于在 亚马逊云科技开发者社区, 知乎,自媒体平台,第三方开发者媒体等亚马逊云科技官方渠道 “Your Data, Your AI, Your Future.(你的数据,你的AI&…...

Mac 打不开github解决方案
序言 github 时有打不开的情况,为此很是烦恼,这里分享一下如何解决这种问题,其实问题的本质是在访问github网页时无法通过github.com的二级域名进行动态域名解析。 解决方案 手动配置静态文件hosts,将该域名和IP的映射关系添加…...

十五 动手学深度学习v2计算机视觉 ——全连接神经网络FCN
文章目录 FCN FCN 全卷积网络先使用卷积神经网络抽取图像特征,然后通过卷积层将通道数变换为类别个数,最后通过转置卷积层将特征图的高和宽变换为输入图像的尺寸。 因此,模型输出与输入图像的高和宽相同,且最终输出通道包含了该空…...
elementUI中的 “this.$confirm“ 基本用法,“this.$confirm“ 调换 “确认“、“取消“ 按钮的位置
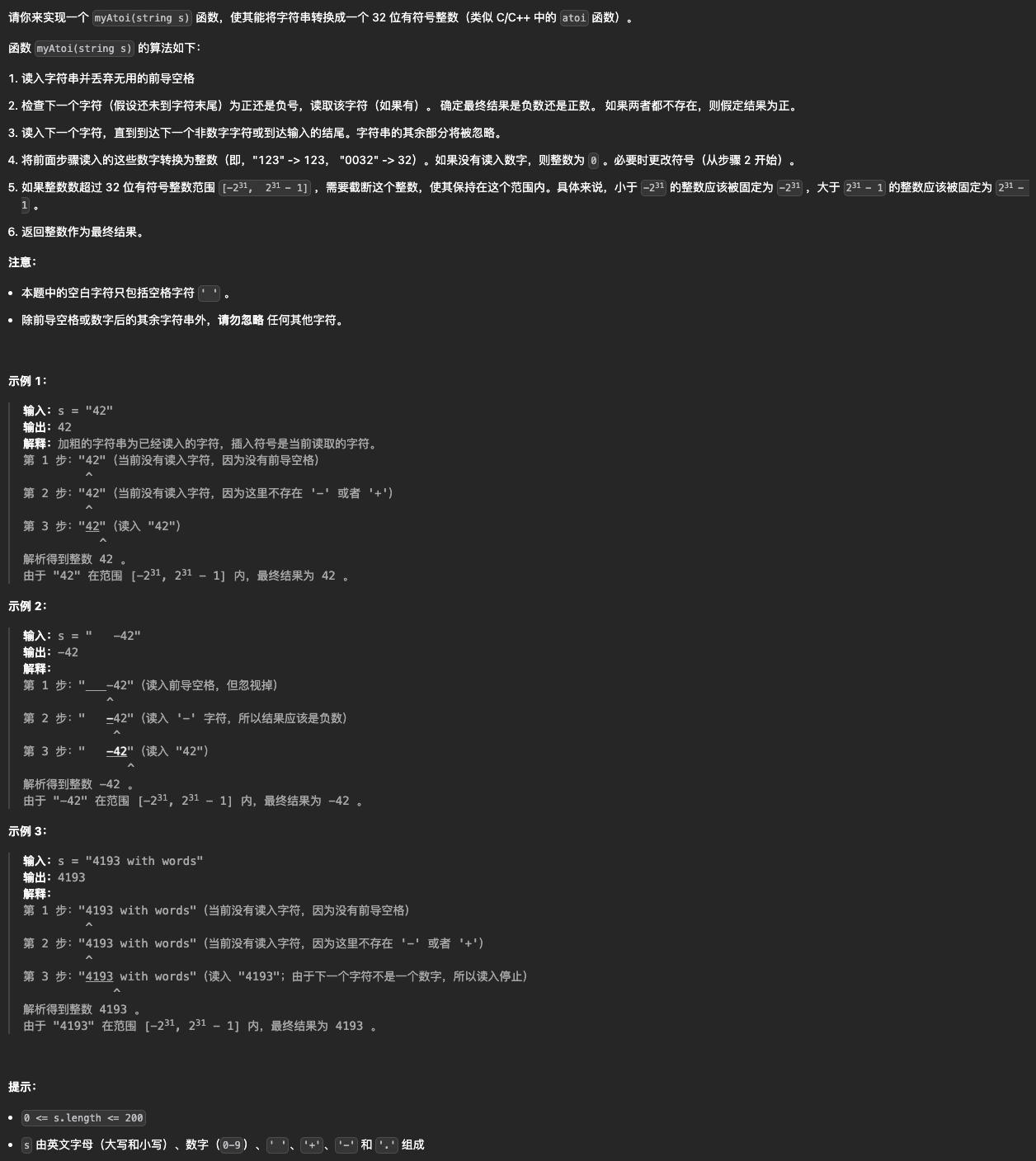
文章目录 前言具体操作总结 前言 elementUI中的 "this.$confirm" 基本用法,"this.$confirm" 调换 "确认"、"取消" 按钮的位置 具体操作 基本用法 <script> this.$confirm(这是数据(res.data࿰…...

K8S 常用命令
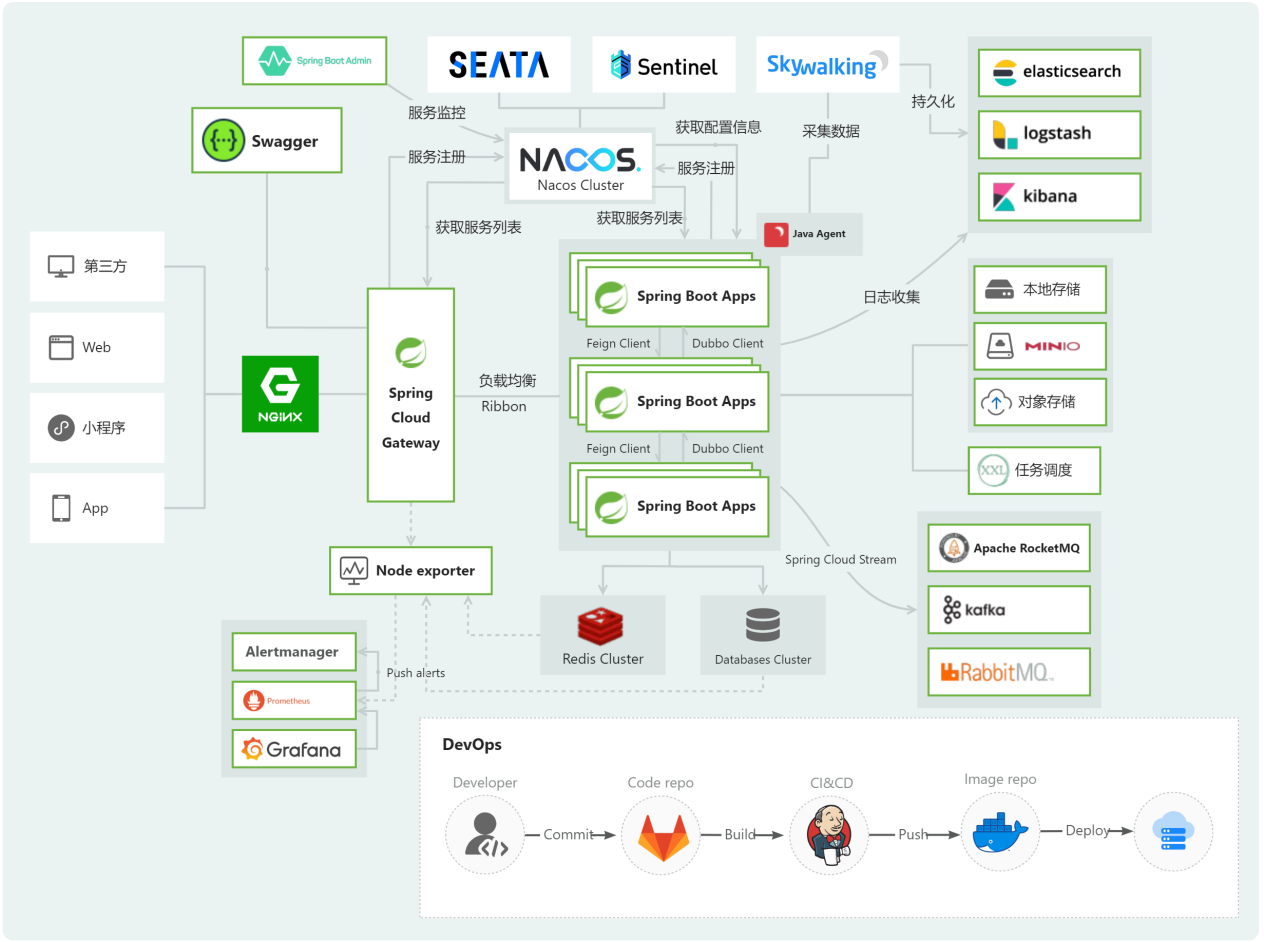
获取所有的pod资源: kubectl get pod 获取所有的命名空间: kubectl get namespace 获取所有的Deployment资源: kubectl get deployment 删除指定的deploy: kubectl delete deploy nginx 获取所有的服务: kubectl get serv…...

12.使用 Redis 优化登陆模块
目录 1. 使用 Redis 优化登陆模块 1.1 使用 Redis 存储验证码 1.2 使用 Redis 存储登录凭证 1.3 使用 Redis 缓存用户信息 1. 使用 Redis 优化登陆模块 使用 Redis 存储验证码:验证码需要频繁的访问与刷新,对性能要求较高;验证码不需要永…...
Nacos-NacosRule 负载均衡—设置集群使本地服务优先访问
userservice: ribbon: NFLoadBalancerRuleClassName: com.alibaba.cloud.nacos.ribbon.NacosRule # 负载均衡规则 NacosRule 权重计算方法 目录 一、介绍 二、示例(案例截图) 三、总结 一、介绍 NacosRule是AlibabaNacos自己实现的一个负载均衡策略&…...
软件设计师——信息安全(二)
📑前言 本文主要是【信息安全】——软件设计师——信息安全的文章,如果有什么需要改进的地方还请大佬指出⛺️ 🎬作者简介:大家好,我是听风与他🥇 ☁️博客首页:CSDN主页听风与他 🌄…...

Unity中实现ShaderToy卡通火(原理实现篇)
文章目录 前言一、我们在片元着色器中,实现卡通火的大体框架1、使用 noise 和 _CUTOFF 判断作为显示火焰的区域2、_CUTOFF : 用于裁剪噪波范围的三角形3、noise getNoise(uv, t); : 噪波函数 二、顺着大体框架依次解析具体实现的功能1、 uv.x * 4.0; : …...
引迈信息-JNPF平台怎么样?值得入手吗?
目录 1.前言 2.引迈低代码怎么样? 3.平台亮点展示 4.引迈产品特点 5.引迈产品技术栈: 1.前言 低代码是近几年比较火的一种应用程序快速开发方式,它能帮助用户在开发软件的过程中大幅减少手工编码量,并通过可视化组件加速应用…...
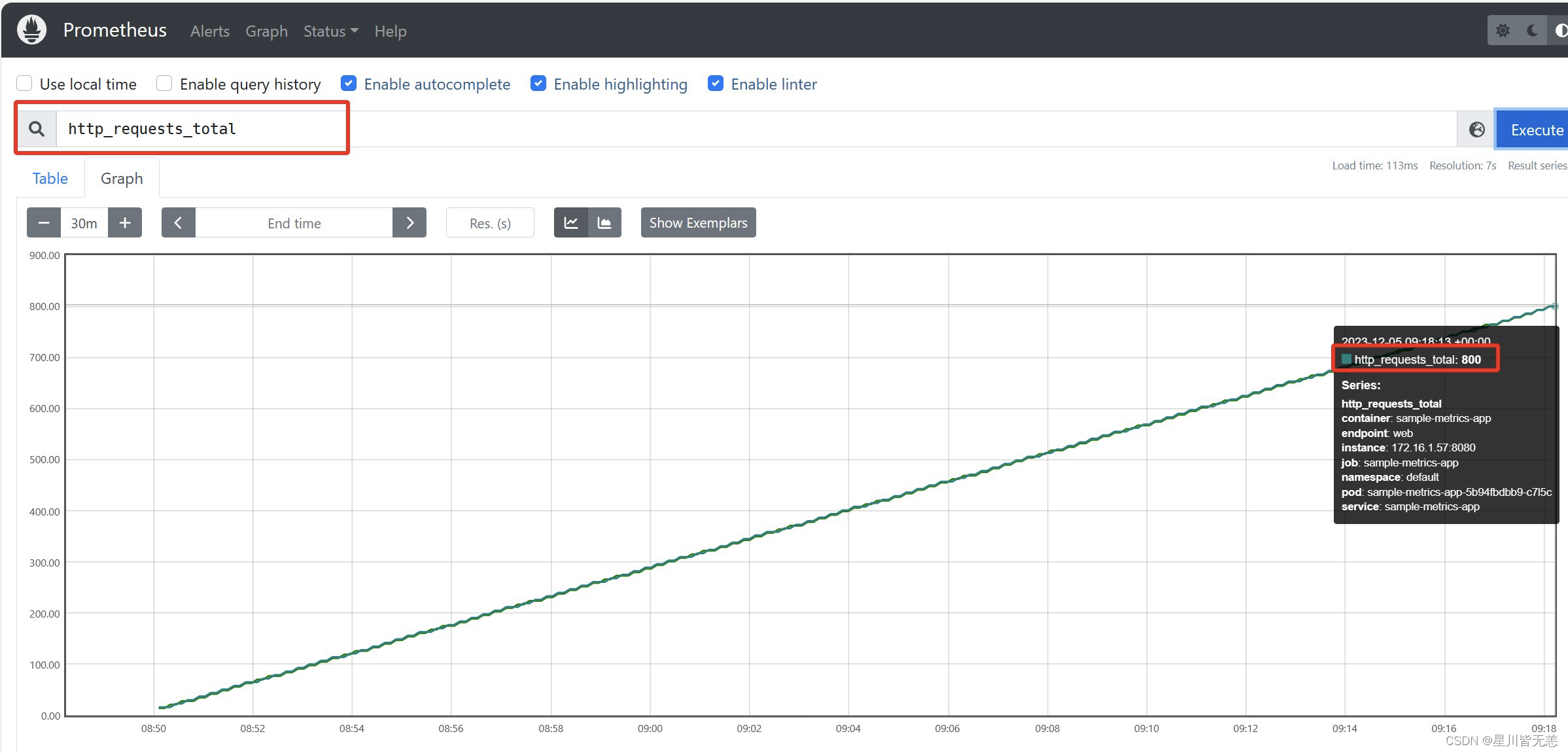
大数据云计算——使用Prometheus-Operator进行K8s集群监控
大数据云计算——使用Prometheus-Operator进行K8s集群监控 一、 背景 在非operator配置的普罗中我们监控k8s集群都是通过配置configmap进行服务发现和指标拉取。切换到prometheus-operator难免会有些使用问题。不少用户已经习惯底层配置自动发现的方式。当过渡到servicemonit…...

[蓝桥杯刷题]合并区间、最长不连续子序列、最长不重复数组长度
前言 ⭐Hello!这里是欧_aita的博客。 ⭐今日语录: 成功的关键在于对目标的持久追求。 ⭐个人主页:欧_aita ψ(._. )>⭐个人专栏: 数据结构与算法 数据库 文章目录 前言合并区间问题📕现实应用大致思路代码实现代码讲解 最长不连续子序列&a…...
Hazel引擎学习(十二)
我自己维护引擎的github地址在这里,里面加了不少注释,有需要的可以看看 参考视频链接在这里 这是这个系列的最后一篇文章,Cherno也基本停止了Games Engine视频的更新,感觉也差不多了,后续可以基于此项目开发自己想要…...

中文字符串逆序输出
今天碰到这个题,让我逆序输出中文字符串,可给我烦死了,之前没有遇到过,也是查了资料才知道,让我太汗颜了。 英文字符串逆序输出很容易,开辟一块空间用来存放逆序后的字符串,从后往前遍历原字符串…...

MySQL BinLog 数据还原恢复
博文目录 文章目录 查看状态查看 binlog 开关及存储路径查看 binlog 配置 如 存储格式 binlog_format查看当前还存在的日志查看当前正在使用的日志 切换日志确定日志确定日志文件日志格式改写日志简要说明确定日志位置以事件为单位查看日志分析日志 还原数据 查看状态 查看 b…...
)
从电机控制到无刷驱动:STM32高级定时器TIM1互补PWM带死区配置全流程(附逻辑分析仪实测)
STM32高级定时器TIM1互补PWM与死区控制实战指南 在工业电机驱动和电源逆变领域,精确的PWM信号控制是系统可靠运行的核心。许多工程师在初次接触STM32高级定时器的互补PWM功能时,往往会被其复杂的参数配置所困扰——特别是当涉及到H桥电路的安全驱动时&am…...

初创公司如何通过Taotoken统一管理多个AI模型的调用与开销
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初创公司如何通过Taotoken统一管理多个AI模型的调用与开销 对于资源有限的初创技术团队而言,在产品中集成多种AI能力是…...
可视化图)
基于R语言与MatchIt包实战:绘制多方法对比的标准化平均差(SMD)可视化图
1. 标准化平均差(SMD)是什么?为什么需要可视化? 标准化平均差(Standardized Mean Difference, SMD)是衡量两组间协变量差异的常用指标。简单来说,它告诉我们两组数据在某个特征上的差距有多大&…...

Obsidian笔记一键发布:soulmatesmd.singles静态网站生成器实战
1. 项目概述与核心价值最近在折腾个人数字资产管理的时候,偶然间发现了一个挺有意思的项目,叫tfpickard/soulmatesmd.singles。乍一看这个标题,可能会有点摸不着头脑,它不像常见的“个人博客系统”或者“笔记工具”那么直白。但如…...

STM32 IAP方案怎么选?内置DFU vs 自写Bootloader,从F1到F4系列实战对比
STM32 IAP方案深度对比:从芯片选型到实战落地 当产品需要支持远程固件更新时,工程师们往往面临一个关键抉择:是采用ST官方内置的DFU方案,还是自行开发Bootloader?这个看似简单的选择背后,实则牵涉到芯片选型…...

突破性仓库管理革命:TQVaultAE如何彻底改变你的《泰坦之旅》游戏体验
突破性仓库管理革命:TQVaultAE如何彻底改变你的《泰坦之旅》游戏体验 【免费下载链接】TQVaultAE Extra bank space for Titan Quest Anniversary Edition 项目地址: https://gitcode.com/gh_mirrors/tq/TQVaultAE 还在为《泰坦之旅》周年纪念版中那些堆积如…...

ETS2LA终极指南:三步开启《欧洲卡车模拟2》自动驾驶新时代
ETS2LA终极指南:三步开启《欧洲卡车模拟2》自动驾驶新时代 【免费下载链接】Euro-Truck-Simulator-2-Lane-Assist Plugin based interface program for ETS2/ATS. 项目地址: https://gitcode.com/gh_mirrors/eur/Euro-Truck-Simulator-2-Lane-Assist 你是否梦…...

硬件工程师差旅数据安全与设备防护全攻略
1. 一次旅行噩梦引发的硬件工程师深度思考那次在曼彻斯特机场洗手间里,背包从门上一个简陋的金属挂钩上滑落,发出那声令人心悸的“咔嚓”声时,我脑子里闪过的第一个念头不是“我的电脑完了”,而是“完了,我所有的设计文…...

如何用XiaoMusic让小爱音箱变身你的私人音乐管家:5个超实用场景解析
如何用XiaoMusic让小爱音箱变身你的私人音乐管家:5个超实用场景解析 【免费下载链接】xiaomusic 使用小爱音箱播放音乐,音乐使用 yt-dlp 下载。 项目地址: https://gitcode.com/GitHub_Trending/xia/xiaomusic 还在为小爱音箱只能播放特定平台的音…...

如何在matlab中调用taotoken聚合大模型api的详细教程
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 如何在 MATLAB 中调用 Taotoken 聚合大模型 API 的详细教程 对于使用 MATLAB 进行科学计算、数据分析或工程开发的用户而言&#x…...