ES-组合与聚合
ES组合查询
1 must
满足两个match才会被命中
GET /mergeindex/_search
{"query": {"bool": {"must": [{"match": {"name": "liyong"}},{"match_phrase": {"desc": "liyong"}}]}}
}
2 must 可以换成filter,这样可以不用计算score 这样性能更好。
GET /mergeindex/_search
{"query": {"bool": {"filter": [{"match": {"name": "liyong"}},{"match_phrase": {"desc": "liyong"}}]}}
}
3 should 类似于SQL中的 or
GET /mergeindex/_search
{"query": {"bool": {"should": [{"match": {"name": "liyong"}},{"match_phrase": {"desc": "liyong"}}]}}
}
bool 支持嵌套但是不推荐。
4 must 与 filter 组合使用
这个时候会限制性filter然后再执行must,也就是预处理,先过滤掉一部分数据。
GET /mergeindex/_search
{"query": {"bool": {"must": [{"match": {"name": "liyong"}},{"match_phrase": {"desc": "liyong"}}],"filter": [{"range": {"salary": {"gte": 0,"lte": 190000}}}]}}
}
5 filter 和 should 一起使用
有可能会有一个问题,就是should不工作,需要加上一个兜底条件minimum_should_match : 1 最好是加上。
GET /mergeindex/_search
{"query": {"bool": {#should 至少要匹配一个"minimum_should_match" : 1, "should": [{"match": {"name": "liyong"}},{"match_phrase": {"desc": "liyong"}}]}}
}
ES聚合
GET /demo/_search
{"size" : 0, #不返回hints 减少数据量"aggs": { #固定语法"age": { #自定义名字"terms": {"field": "age", #根据年龄进行聚合"size": 10}}}
}

需要注意点是如果是文本则不能直接聚合,需要使用keyworkd
GET /product/_search
{"size": 0, "aggs": {"age": {"terms": {"field": "tags.keyword", # 这里不能填 tags 因为默认会被拆分,然后每个元素都是text类型"size": 10 #限制桶的数量 如果填1 就只返回一个聚合结果}}}
}
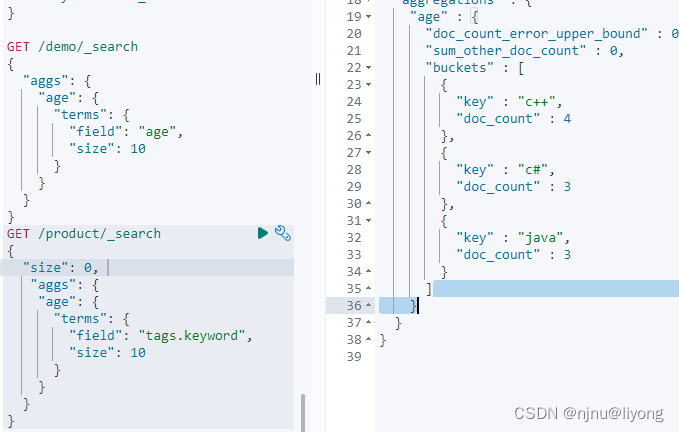
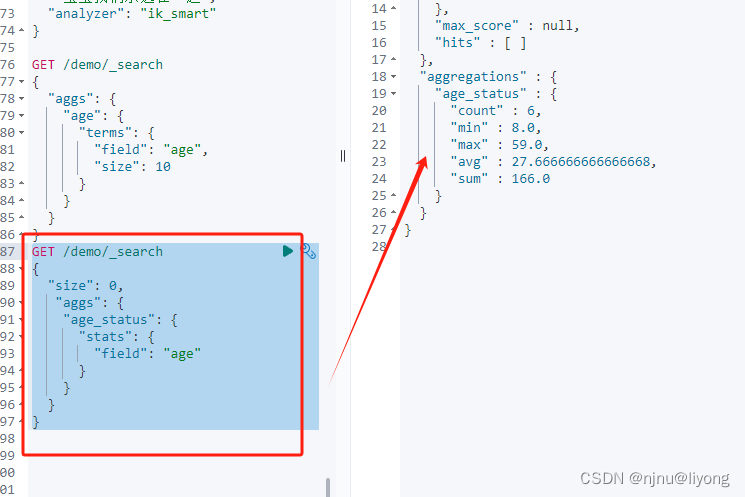
status 可以一下统计常见的数值
GET /demo/_search
{"size": 0, "aggs": {"age_status": {"stats": {"field": "age"}}}
}
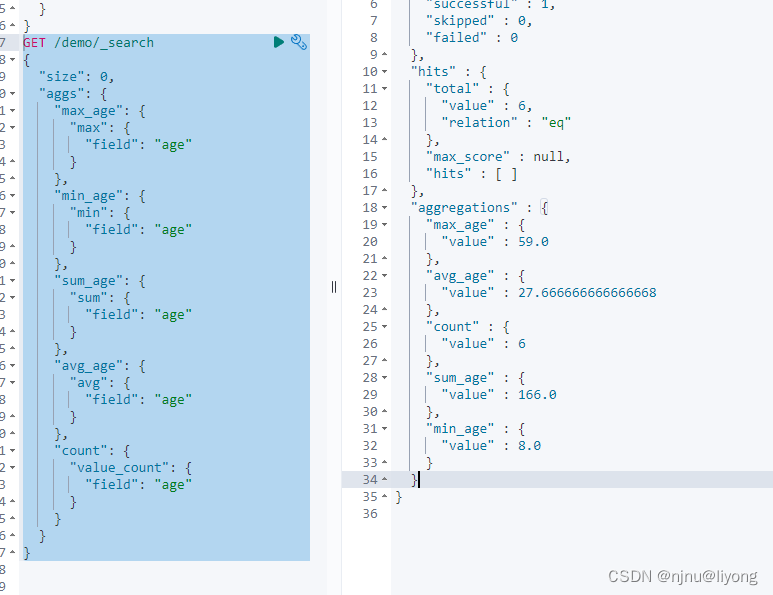
也可以分开来写
GET /demo/_search
{"size": 0,"aggs": {"max_age": {"max": {"field": "age"}},"min_age": {"min": {"field": "age"}},"sum_age": {"sum": {"field": "age"}},"avg_age": {"avg": {"field": "age"}},"count": {"value_count": {"field": "age"}}}
}
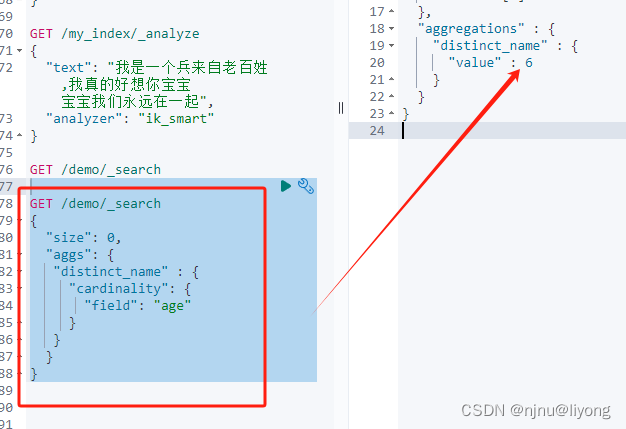
去重
GET /demo/_search
{"size": 0,"aggs": {"distinct_name" : {"cardinality": {"field": "age" #去除重复的年龄有几个种类}}}
}
聚合嵌套
GET demo/_search
{"size": 0,"aggs": {"age_bucket": {"terms": {"field": "name.keyword"},"aggs": { #这个案例演示aggs是可以嵌套的"age_bulk": {"avg": {"field": "age"}}}},"min_bucket": {"min_bucket": {"buckets_path": "age_bucket>age_bulk" #固定语法 直接筛选出了 年龄最小的}}}
}
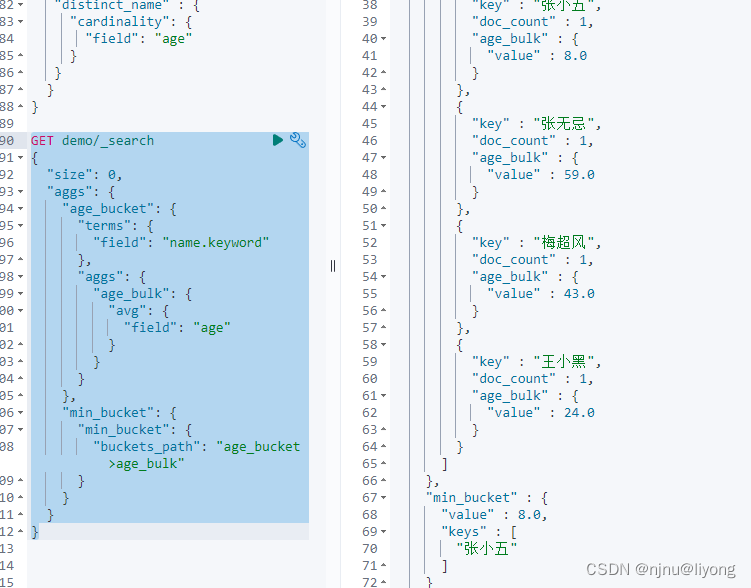
先筛选再聚合
GET product/_search
{"query": {"range": {"price": {"gte": 1000}}}, # 先筛选出数据 在进行聚合"aggs": {"type_bucket": {"terms": {"field": "type.keyword" #根据type进行分组}}}
}
排序
GET /product/_search?size=0
{"aggs": {"tags_aggs": {"terms": {"field": "tags.keyword","size": 10,"order": {"_key": "asc" #根据_count来排序 通过数量来排序}}}}
}嵌套排序
#不返回hits中的数据
GET /product/_search?size=0
{"aggs": {"first_sort": {"terms": {"field": "tags.keyword","order": {"_count": "desc"}},"aggs": {"second_sort": {"terms": {"field": "type.keyword","order": {"_count": "desc"}}}}}}
}自定义排序
GET /product/_search?size=0 #指定不返回hints
{"aggs": {"type_price": {"terms": {"field": "type.keyword","order": {#过滤的名字 第二个过滤器有多个止值可以用.来指定#指定聚合那个字段排在前面"agg_stats>stats.min": "asc" }},"aggs": {"agg_stats": {"filter": {"terms": {"tags.keyword": ["88vip","tmall"]}},"aggs": {"stats": {"stats": {"field": "price"}}}}}}}
}
#先根据type分类然后 根据tags 筛选 再 根据最小值进行排序
直方图
首先来看这样一个例子
GET /product/_search?size=0
{"aggs": {"price_range": {"range": {"field": "salary","ranges": [{"from": 0,"to": 1000},{"from": 1000,"to": 2000},{"from": 2000,"to": 3000},{"from": 3000,"to": 4000}]}}}
}
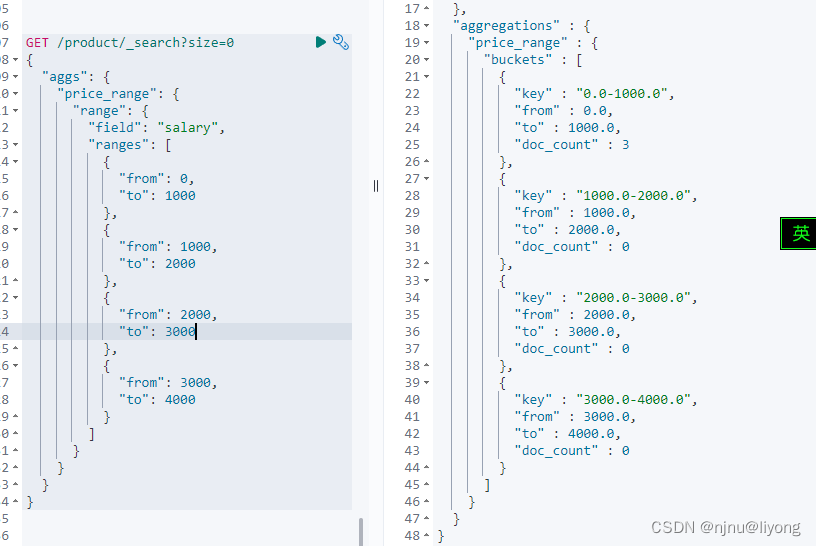
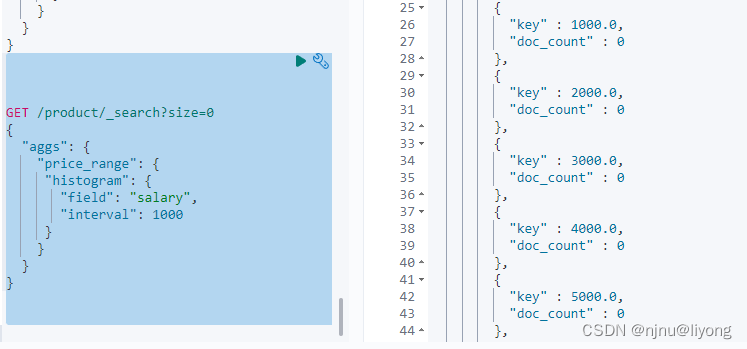
这里相当于做一个统计,但是需要一个一个定义,类似于坐标轴x,可以有更简单的写法
GET /product/_search?size=0
{"aggs": {"price_range": {"histogram": {"field": "salary","interval": 1000 #坐标间距}}}
}GET /product/_search?size=0
{"aggs": {"price_range": {"histogram": {"field": "salary","interval": 1000,"missing": 0, #如果为空值就为0"min_doc_count": 1 #小于1的不展示 依据doc_count属性}}}
}
时间直方图
GET /product/_search
{"aggs": {"price_range": {"date_histogram": {"field": "date",#看月度数据"calendar_interval": "month", #year day#看2023-01 - 06的数据"extended_bounds": {"min": "2023-01","max": "2023-06"}}}}
}
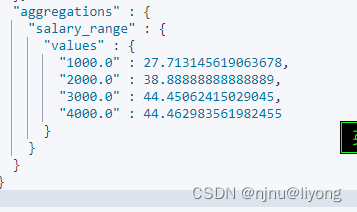
水位
GET /product/_search
{"size" : 0,"aggs": {"salary_range": {"percentile_ranks": {"field": "salary","values": [1000,2000,3000,4000]}}}
}它的意思是,有27%的数据薪水不超过1000, 有38%的薪水不超过2000,以此类推吧
相关文章:
ES-组合与聚合
ES组合查询 1 must 满足两个match才会被命中 GET /mergeindex/_search {"query": {"bool": {"must": [{"match": {"name": "liyong"}},{"match_phrase": {"desc": "liyong"}}]}}…...
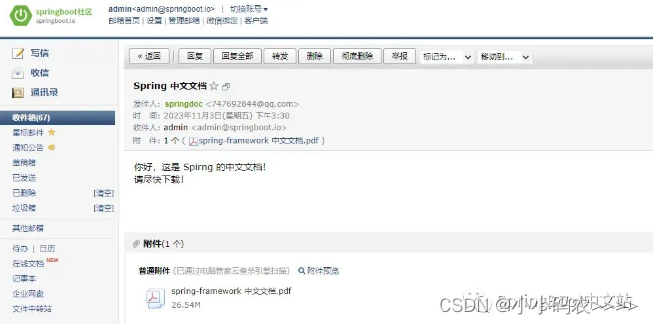
在 Spring Boot 中发送邮件简单实现
Spring Boot 对于发送邮件这种常用功能也提供了开箱即用的 Starter:spring-boot-starter-mail。 通过这个 starter,只需要简单的几行配置就可以在 Spring Boot 中实现邮件发送,可用于发送验证码、账户激活等等业务场景。 本文将通过实际的案…...
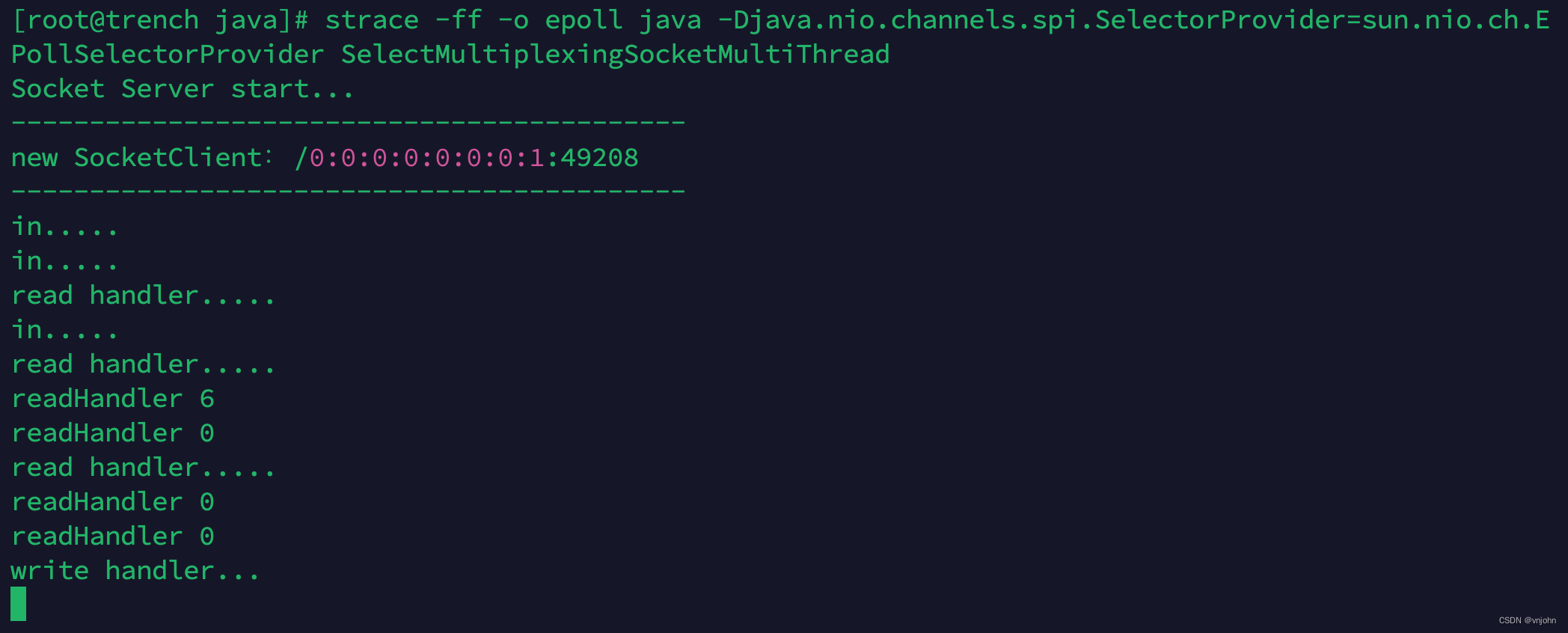
深入理解网络 I/O:单 Selector 多线程|单线程模型
🔭 嗨,您好 👋 我是 vnjohn,在互联网企业担任 Java 开发,CSDN 优质创作者 📖 推荐专栏:Spring、MySQL、Nacos、Java,后续其他专栏会持续优化更新迭代 🌲文章所在专栏&…...

Kafka Avro序列化之三:使用Schema Register实现
为什么需要Schema Register 注册表 无论是使用传统的Avro API自定义序列化类和反序列化类 还是 使用Twitter的Bijection类库实现Avro的序列化与反序列化,这两种方法都有一个缺点:在每条Kafka记录里都嵌入了schema,这会让记录的大小成倍地增加。但是不管怎样,在读取记录时…...

EasyExcel
概述 GitHub - alibaba/easyexcel: 快速、简洁、解决大文件内存溢出的java处理Excel工具 EasyExcel官方文档 - 基于Java的Excel处理工具 | Easy Excel EasyExcel是一个基于Java的、快速、简洁、解决大文件内存溢出的Excel处理工具。 他能让你在不用考虑性能、内存的等因素的…...

java 探针两种模式实战
分为两种 程序运行前的agent:premain 程序运行中的agent:agentmain 在程序运行前的agent javaagent是java命令的一个参数,所以需要通过-javaagent 来指定一个jar包(就是我们要做的代理包)能够实现在主程序运行前来执行…...
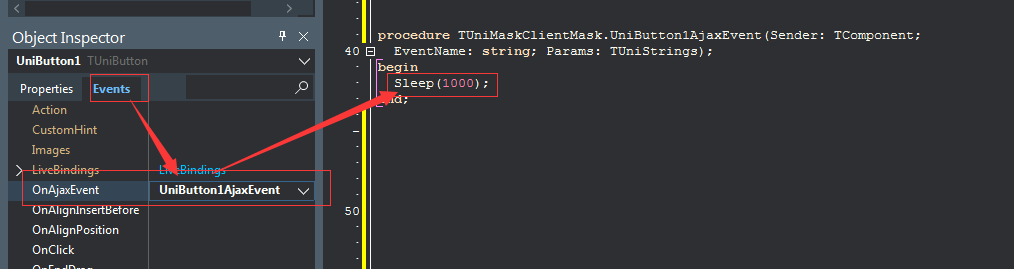
uniGUI之MASK遮罩
在页面进行后台数据库操作的时候,不想 用户再进行 页面上的 其他操作,这时候就要 将页面 遮罩。例如UniDBGrid有LoadMask属性。 1]使用ScreenMask函数 2]JS调用 3]一个控件控制遮罩另一个控件(如Button遮罩UniDBGrid) //很简单,本例子就是告…...
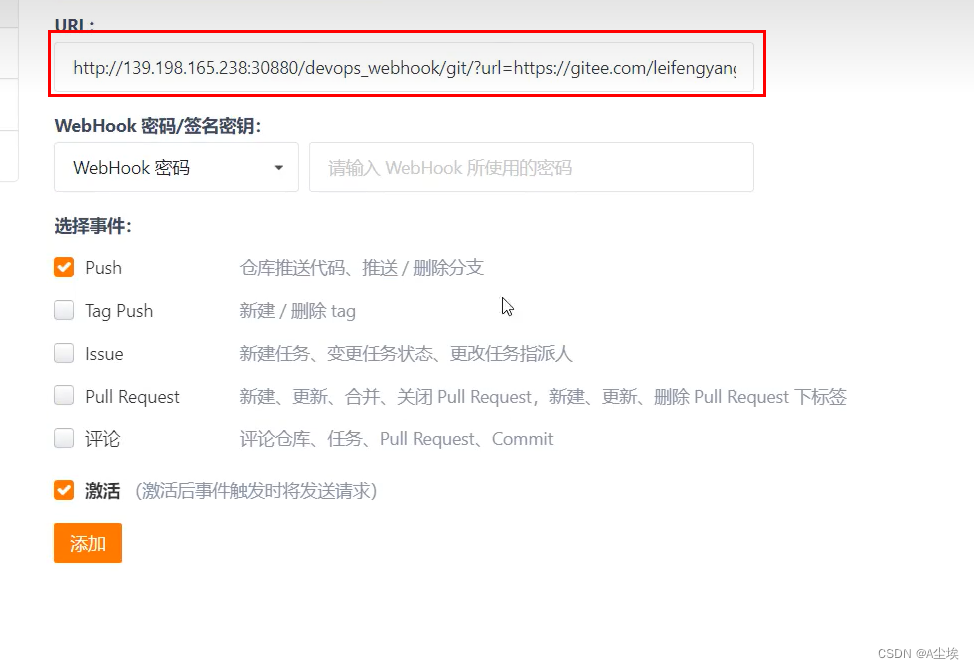
DevOps云原生创建devops流水线(微服务项目上传git,打包镜像,部署k8s)
开发和运维人员的解决方案 一、中间件的部署(Sentinel/MongoDB/MySQL) 二、创建DevOps工程 邀请成员 三、创建流水线 四、编辑流水线 ①、拉取代码(若失败,则将制定容器改为maven) 若失败,则将命令改…...

【vim 学习系列文章 13.1 -- 自动命令autocmd 根据文件类型设置vim参数】
文章目录 autocmd 根据文件类型配置vim参数vim 文本类型 autocmd 根据文件类型配置vim参数 在 Vim 中,你可以使用 autocmd (自动命令)来根据文件类型自动执行特定的函数。首先,你需要定义这些函数,然后使用 autocmd 与…...

算法基础概念之数据结构
邻接表 每个点作为头节点接一条链表 链表中元素均为该头节点指向的点 优先队列 参数: ①储存元素类型 ②底层使用的存储结构(一般为vector) ③比较方式(默认小于)...
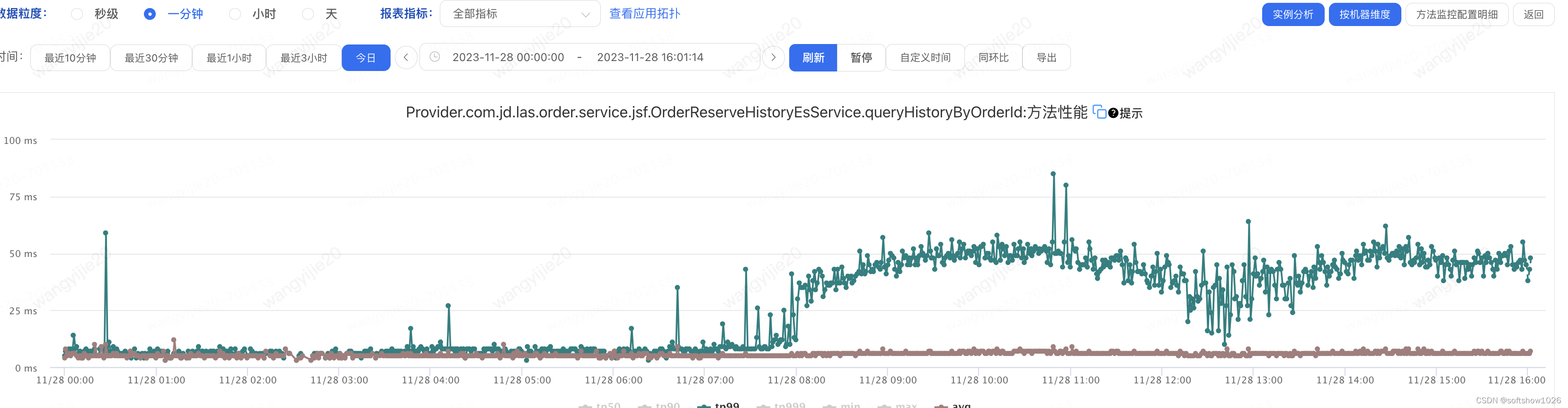
解决ES伪慢查询
一、问题现象 服务现象 服务接口的TP99性能降低 ES现象 YGC:耗时极其不正常, 峰值200次,耗时7sFULL GC:不正常,次数为1但是频繁,STW 5s慢查询:存在慢查询5 二 解决过程 1、去除干扰因素 从现象上看应用是由于某种…...
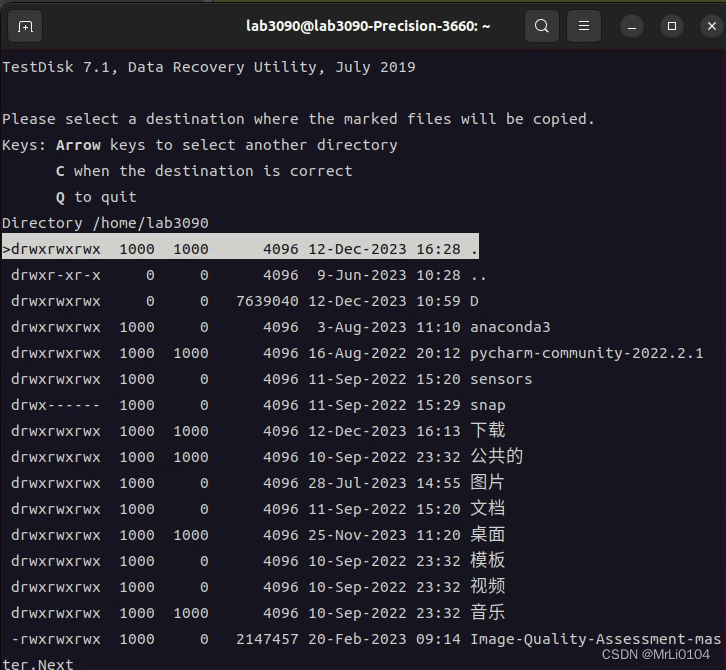
关于Ubuntu22.04恢复误删文件的记录
挂载在Ubuntu22.04下的固态盘有文件被误删了,该固态盘是ntfs格式的。 在网上找了很多教程,最后决定用TestDisk工具进行恢复。 现记录如下: Ubuntu安装testdisk sudo apt-get install testdisk运行testdisk sudo testdisk得到 我选择的是…...

Docker笔记:Docker Swarm, Consul, Gateway, Microservices 集群部署
关于 Consul 服务 Consul是Go语言写的开源的服务发现软件Consul具有服务发现、健康检查、 服务治理、微服务熔断处理等功能 Consul 部署方式1: 直接在linux 上面部署 consul 集群 1 )下载 在各个服务器上 下载 consul 后解压并将其目录配置到环境变量中ÿ…...
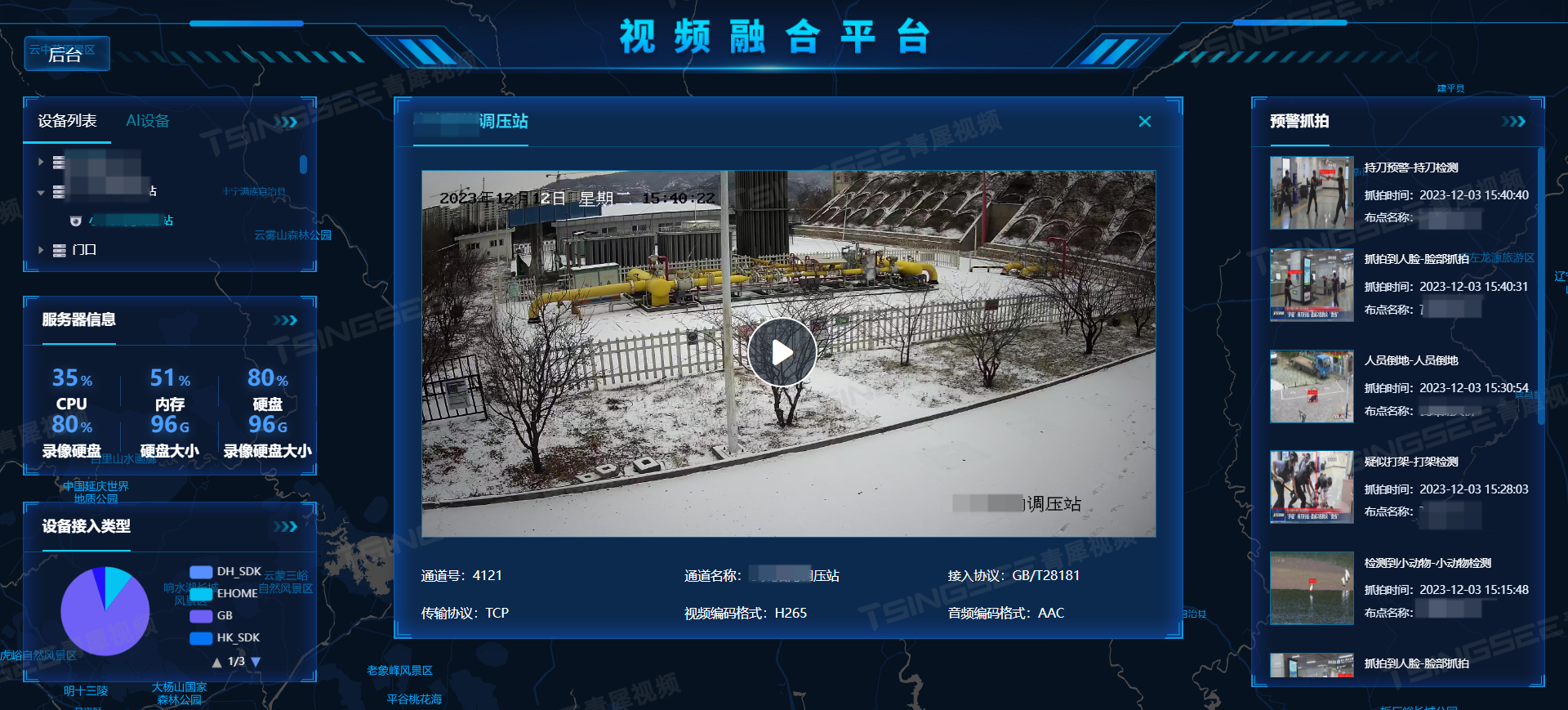
浅析AI视频分析与视频管理系统EasyCVR平台及场景应用
人工智能的战略重要性导致对视频智能分析的需求不断增加。鉴于人工智能视觉技术的巨大潜力,人们的注意力正在从传统的视频监控转移到计算机视觉的监控过程自动化。 1、什么是视频分析? 视频分析或视频识别技术,是指从视频片段中提取有用信息…...

跨站点分布式多活存储建设方案概述
1-伴随着私有云、海量非结构数据的爆炸性增长,软件定义存储已经成为用户构建“敏捷IT” 架构的数据基石,同时越来越多的关键业务接入“敏捷IT” 架构。在分布式软件定义存储的产品架构下,怎样既保证对爆炸数据量的平稳承接,又能对…...

Github 2023-12-16开源项目日报Top10
根据Github Trendings的统计,今日(2023-12-16统计)共有10个项目上榜。根据开发语言中项目的数量,汇总情况如下: 开发语言项目数量Python项目2非开发语言项目2TypeScript项目1Jupyter Notebook项目1Go项目1PHP项目1JavaScript项目1C#项目1 精…...

c++ 中多线程的相关概念与多线程类的使用
1、多线程相关概念 1.1 并发、并行、串行 并发(Concurrent):并发是指两个或多个事件在同一时间间隔内运行。在操作系统中,是指一个时间段中有几个程序都处于已启动运行到运行完毕之间,且这几个程序都是在同一个处理机…...

深入理解 hash 和 history:网页导航的基础(下)
🤍 前端开发工程师(主业)、技术博主(副业)、已过CET6 🍨 阿珊和她的猫_CSDN个人主页 🕠 牛客高级专题作者、在牛客打造高质量专栏《前端面试必备》 🍚 蓝桥云课签约作者、已在蓝桥云…...

腾讯文档助力CRM集成:无代码连接电商与广告
腾讯文档API的简介与优势 腾讯文档API是一个强大的工具,它允许企业通过简单的无代码开发来实现与电商平台和客服系统的智能连接。这种连接不仅提高了工作效率,还优化了数据管理。使用腾讯文档智能表,商家可以享受多样的列类型、多维视图展示…...
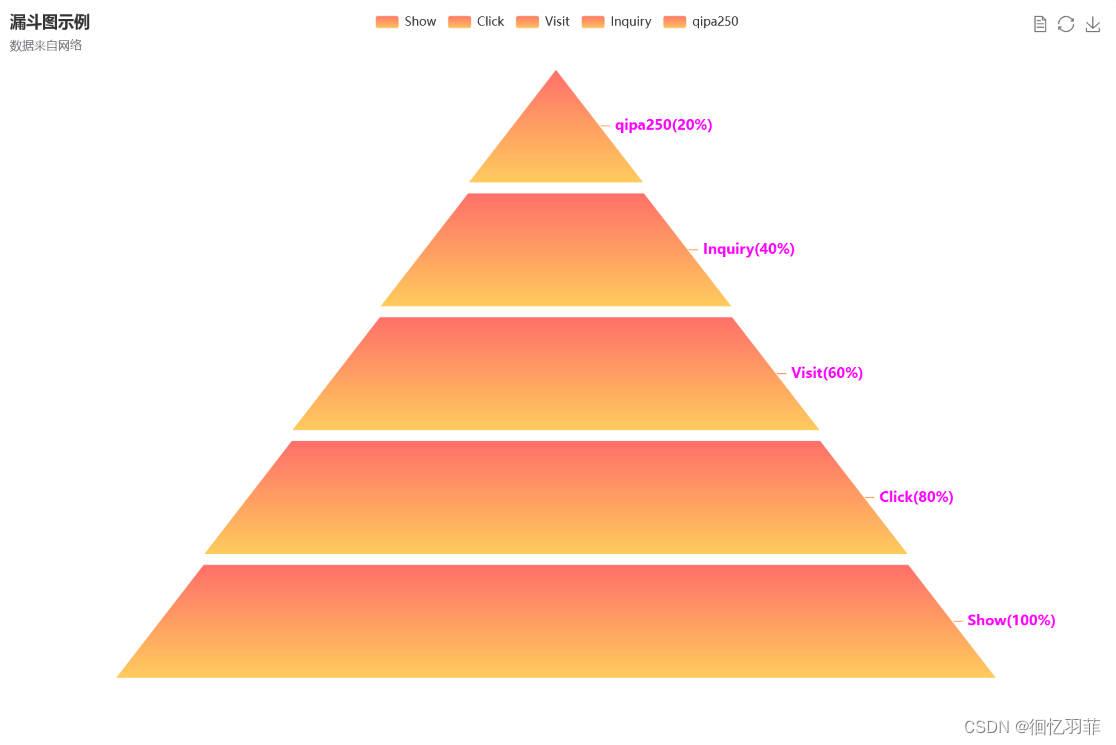
学习使用echarts漏斗图的参数配置和应用场景
学习使用echarts漏斗图的参数配置和应用场景 前言什么是漏斗图漏斗图的特点及应用场景漏斗图的特点漏斗图常见的的应用场景: echarts中漏斗的常用属性echart漏斗代码美化漏斗图样式1、设置标题字体大小2、设置标签样式3、设置漏斗图为渐变颜色4、设置高亮效果5、设置…...
)
简化环境配置:OpenClaw v2.7.1 部署与实操教学(新手适用)
🚀 Windows 极速部署 OpenClaw v2.7.1 教程|5 分钟搭建本地 AI 智能体 在开源 AI 智能体快速普及的当下,OpenClaw(小龙虾)凭借本地运行、零代码操控、全场景自动化能力,成为办公与技术人群的效率工具&…...

从CAD建模到游戏角色动画:深入浅出聊聊B样条曲线在工业与娱乐中的实战应用
从CAD建模到游戏角色动画:B样条曲线的跨领域实战解析 在工业设计与数字娱乐的交汇处,B样条曲线(B-spline Curves)正悄然重塑着两个行业的创作范式。当汽车设计师在Alias中推敲车身曲面时,游戏动画师正在Blender里调整…...

如何零安装体验Windows 12:网页版模拟器完整指南
如何零安装体验Windows 12:网页版模拟器完整指南 【免费下载链接】win12 Windows 12 网页版,在线体验 点击下面的链接在线体验 项目地址: https://gitcode.com/gh_mirrors/wi/win12 你是否想在浏览器中直接运行Windows系统?无需下载任…...
)
Claude 3 Haiku性能白皮书首发(含AWS Inferentia2 vs NVIDIA T4实测对比数据)
更多请点击: https://intelliparadigm.com 第一章:Claude 3 Haiku性能白皮书首发概览 Anthropic 正式发布 Claude 3 系列中最轻量、响应最快的基础模型——Claude 3 Haiku,并同步公开首份面向开发者与企业用户的《Claude 3 Haiku 性能白皮书…...

Kali on WSL避坑大全:从换源、装工具到解决图形界面Terminal报错,一篇搞定
Kali on WSL实战避坑指南:从基础配置到图形界面全流程解决方案 在Windows系统上运行Kali Linux一直是安全研究人员和开发者的刚需,而WSL(Windows Subsystem for Linux)的出现让这一需求变得更加便捷。然而,从安装到真正…...

毫米波雷达选型指南:HLK-LD1125H-24G vs 传统红外/超声波,在智能办公场景下怎么选?
毫米波雷达选型指南:HLK-LD1125H-24G vs 传统红外/超声波,在智能办公场景下怎么选? 在智能办公场景中,人员检测技术的选择直接影响着空间管理效率与用户体验。传统红外(PIR)和超声波传感器曾长期主导市场&…...
暨十三届第四期“麓峰”交叉科学论坛)
【湖南师范大学主办 | ACM出版,检索快且稳定 | 往届均已见刊并完成EI、Scopus检索】第三届智慧教育与计算机技术国际学术会议 (IECT 2026)暨十三届第四期“麓峰”交叉科学论坛
已通过ACM出版,ISBN号:979-8-4007-2365-0 教育方向结合:计算机、信息技术、人工智能、多媒体技术、大数据等主题均可投递 第三届智慧教育与计算机技术国际学术会议 (IECT 2026)暨十三届第四期“麓峰”交叉科学论坛 2026 3rd International…...
)
Python还是Java?小白程序员必备!收藏这份6个月大模型应用开发学习路线图(附实战项目)
本文针对大模型应用开发,为初学者提供Python/Java语言选择建议,并推出分阶段学习路线图。通过6-8个月学习,涵盖大模型基础、RAG、Agent开发、微调与部署等核心技能。强调实战项目驱动,推荐资源库,最后总结学习建议。适…...

算法23,寻找峰值
这是一道经典的二分查找应用题:寻找峰值(Find Peak Element)。笔记中已经总结了核心逻辑,我将为你梳理其背后的数学原理(二段性),并提供标准的代码实现。1. 核心原理:什么是“二段性…...

深度清理工具openclaw-uninstaller:跨平台卸载与Node.js生态清理指南
1. 项目概述:为什么我们需要一个专门的卸载工具?在软件开发和日常使用中,卸载一个应用程序听起来像是一个简单的“删除”操作,但实际情况往往复杂得多。尤其是那些功能强大、深度集成到系统中的工具,比如涉及3D重建、A…...