【深度学习】注意力机制(二)
本文介绍一些注意力机制的实现,包括EA/MHSA/SK/DA/EPSA。
【深度学习】注意力机制(一)
【深度学习】注意力机制(三)
目录
一、EA(External Attention)
二、Multi Head Self Attention
三、SK(Selective Kernel Networks)
四、DA(Dual Attention)
五、EPSA(Efficient Pyramid Squeeze Attention)
一、EA(External Attention)
EA可以关注全局的空间信息,论文:论文地址
如下图:

代码如下(代码连接):
import numpy as np
import torch
from torch import nn
from torch.nn import initclass External_attention(nn.Module):'''Arguments:c (int): The input and output channel number.'''def __init__(self, c):super(External_attention, self).__init__()self.conv1 = nn.Conv2d(c, c, 1)self.k = 64self.linear_0 = nn.Conv1d(c, self.k, 1, bias=False)self.linear_1 = nn.Conv1d(self.k, c, 1, bias=False)self.linear_1.weight.data = self.linear_0.weight.data.permute(1, 0, 2) self.conv2 = nn.Sequential(nn.Conv2d(c, c, 1, bias=False),norm_layer(c)) for m in self.modules():if isinstance(m, nn.Conv2d):n = m.kernel_size[0] * m.kernel_size[1] * m.out_channelsm.weight.data.normal_(0, math.sqrt(2. / n))elif isinstance(m, nn.Conv1d):n = m.kernel_size[0] * m.out_channelsm.weight.data.normal_(0, math.sqrt(2. / n))elif isinstance(m, _BatchNorm):m.weight.data.fill_(1)if m.bias is not None:m.bias.data.zero_()def forward(self, x):idn = xx = self.conv1(x)b, c, h, w = x.size()n = h*wx = x.view(b, c, h*w) # b * c * n attn = self.linear_0(x) # b, k, nattn = F.softmax(attn, dim=-1) # b, k, nattn = attn / (1e-9 + attn.sum(dim=1, keepdim=True)) # # b, k, nx = self.linear_1(attn) # b, c, nx = x.view(b, c, h, w)x = self.conv2(x)x = x + idnx = F.relu(x)return x二、Multi Head Self Attention
注意力机制的经典,Transformer的基石。论文:论文地址
如下图:
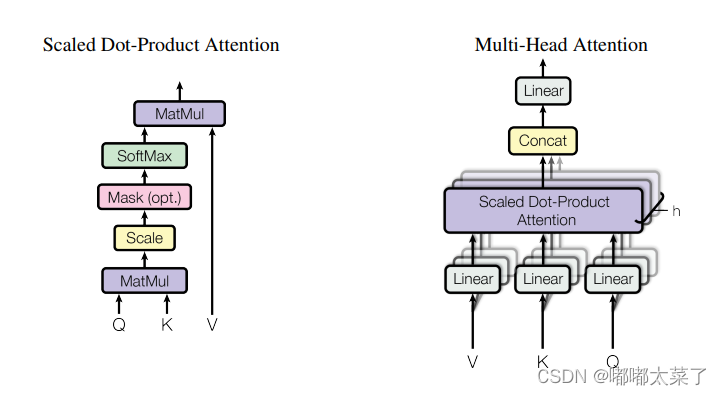
代码如下(代码连接):
import numpy as np
import torch
from torch import nn
from torch.nn import initclass ScaledDotProductAttention(nn.Module):'''Scaled dot-product attention'''def __init__(self, d_model, d_k, d_v, h,dropout=.1):''':param d_model: Output dimensionality of the model:param d_k: Dimensionality of queries and keys:param d_v: Dimensionality of values:param h: Number of heads'''super(ScaledDotProductAttention, self).__init__()self.fc_q = nn.Linear(d_model, h * d_k)self.fc_k = nn.Linear(d_model, h * d_k)self.fc_v = nn.Linear(d_model, h * d_v)self.fc_o = nn.Linear(h * d_v, d_model)self.dropout=nn.Dropout(dropout)self.d_model = d_modelself.d_k = d_kself.d_v = d_vself.h = hself.init_weights()def init_weights(self):for m in self.modules():if isinstance(m, nn.Conv2d):init.kaiming_normal_(m.weight, mode='fan_out')if m.bias is not None:init.constant_(m.bias, 0)elif isinstance(m, nn.BatchNorm2d):init.constant_(m.weight, 1)init.constant_(m.bias, 0)elif isinstance(m, nn.Linear):init.normal_(m.weight, std=0.001)if m.bias is not None:init.constant_(m.bias, 0)def forward(self, queries, keys, values, attention_mask=None, attention_weights=None):'''Computes:param queries: Queries (b_s, nq, d_model):param keys: Keys (b_s, nk, d_model):param values: Values (b_s, nk, d_model):param attention_mask: Mask over attention values (b_s, h, nq, nk). True indicates masking.:param attention_weights: Multiplicative weights for attention values (b_s, h, nq, nk).:return:'''b_s, nq = queries.shape[:2]nk = keys.shape[1]q = self.fc_q(queries).view(b_s, nq, self.h, self.d_k).permute(0, 2, 1, 3) # (b_s, h, nq, d_k)k = self.fc_k(keys).view(b_s, nk, self.h, self.d_k).permute(0, 2, 3, 1) # (b_s, h, d_k, nk)v = self.fc_v(values).view(b_s, nk, self.h, self.d_v).permute(0, 2, 1, 3) # (b_s, h, nk, d_v)att = torch.matmul(q, k) / np.sqrt(self.d_k) # (b_s, h, nq, nk)if attention_weights is not None:att = att * attention_weightsif attention_mask is not None:att = att.masked_fill(attention_mask, -np.inf)att = torch.softmax(att, -1)att=self.dropout(att)out = torch.matmul(att, v).permute(0, 2, 1, 3).contiguous().view(b_s, nq, self.h * self.d_v) # (b_s, nq, h*d_v)out = self.fc_o(out) # (b_s, nq, d_model)return out三、SK(Selective Kernel Networks)
SK是通道注意力机制。论文地址:论文连接
如下图:

代码如下(代码连接):
import numpy as np
import torch
from torch import nn
from torch.nn import init
from collections import OrderedDictclass SKAttention(nn.Module):def __init__(self, channel=512,kernels=[1,3,5,7],reduction=16,group=1,L=32):super().__init__()self.d=max(L,channel//reduction)self.convs=nn.ModuleList([])for k in kernels:self.convs.append(nn.Sequential(OrderedDict([('conv',nn.Conv2d(channel,channel,kernel_size=k,padding=k//2,groups=group)),('bn',nn.BatchNorm2d(channel)),('relu',nn.ReLU())])))self.fc=nn.Linear(channel,self.d)self.fcs=nn.ModuleList([])for i in range(len(kernels)):self.fcs.append(nn.Linear(self.d,channel))self.softmax=nn.Softmax(dim=0)def forward(self, x):bs, c, _, _ = x.size()conv_outs=[]### splitfor conv in self.convs:conv_outs.append(conv(x))feats=torch.stack(conv_outs,0)#k,bs,channel,h,w### fuseU=sum(conv_outs) #bs,c,h,w### reduction channelS=U.mean(-1).mean(-1) #bs,cZ=self.fc(S) #bs,d### calculate attention weightweights=[]for fc in self.fcs:weight=fc(Z)weights.append(weight.view(bs,c,1,1)) #bs,channelattention_weughts=torch.stack(weights,0)#k,bs,channel,1,1attention_weughts=self.softmax(attention_weughts)#k,bs,channel,1,1### fuseV=(attention_weughts*feats).sum(0)return V
四、DA(Dual Attention)
DA融合了通道注意力和空间注意力机制。论文:论文地址
如下图:
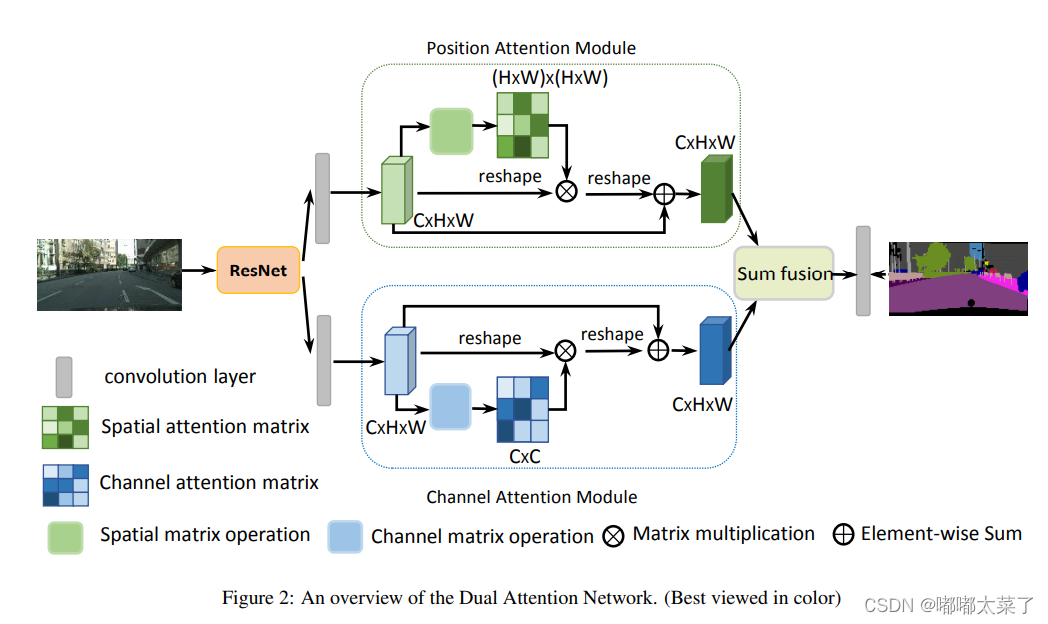
代码(代码连接):
import numpy as np
import torch
from torch import nn
from torch.nn import init
from model.attention.SelfAttention import ScaledDotProductAttention
from model.attention.SimplifiedSelfAttention import SimplifiedScaledDotProductAttentionclass PositionAttentionModule(nn.Module):def __init__(self,d_model=512,kernel_size=3,H=7,W=7):super().__init__()self.cnn=nn.Conv2d(d_model,d_model,kernel_size=kernel_size,padding=(kernel_size-1)//2)self.pa=ScaledDotProductAttention(d_model,d_k=d_model,d_v=d_model,h=1)def forward(self,x):bs,c,h,w=x.shapey=self.cnn(x)y=y.view(bs,c,-1).permute(0,2,1) #bs,h*w,cy=self.pa(y,y,y) #bs,h*w,creturn yclass ChannelAttentionModule(nn.Module):def __init__(self,d_model=512,kernel_size=3,H=7,W=7):super().__init__()self.cnn=nn.Conv2d(d_model,d_model,kernel_size=kernel_size,padding=(kernel_size-1)//2)self.pa=SimplifiedScaledDotProductAttention(H*W,h=1)def forward(self,x):bs,c,h,w=x.shapey=self.cnn(x)y=y.view(bs,c,-1) #bs,c,h*wy=self.pa(y,y,y) #bs,c,h*wreturn yclass DAModule(nn.Module):def __init__(self,d_model=512,kernel_size=3,H=7,W=7):super().__init__()self.position_attention_module=PositionAttentionModule(d_model=512,kernel_size=3,H=7,W=7)self.channel_attention_module=ChannelAttentionModule(d_model=512,kernel_size=3,H=7,W=7)def forward(self,input):bs,c,h,w=input.shapep_out=self.position_attention_module(input)c_out=self.channel_attention_module(input)p_out=p_out.permute(0,2,1).view(bs,c,h,w)c_out=c_out.view(bs,c,h,w)return p_out+c_out五、EPSA(Efficient Pyramid Squeeze Attention)
论文:论文地址
如下图:
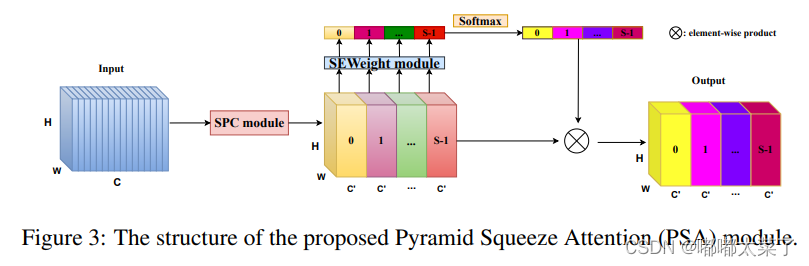
代码如下(代码连接):
import torch.nn as nnclass SEWeightModule(nn.Module):def __init__(self, channels, reduction=16):super(SEWeightModule, self).__init__()self.avg_pool = nn.AdaptiveAvgPool2d(1)self.fc1 = nn.Conv2d(channels, channels//reduction, kernel_size=1, padding=0)self.relu = nn.ReLU(inplace=True)self.fc2 = nn.Conv2d(channels//reduction, channels, kernel_size=1, padding=0)self.sigmoid = nn.Sigmoid()def forward(self, x):out = self.avg_pool(x)out = self.fc1(out)out = self.relu(out)out = self.fc2(out)weight = self.sigmoid(out)return weightdef conv(in_planes, out_planes, kernel_size=3, stride=1, padding=1, dilation=1, groups=1):"""standard convolution with padding"""return nn.Conv2d(in_planes, out_planes, kernel_size=kernel_size, stride=stride,padding=padding, dilation=dilation, groups=groups, bias=False)def conv1x1(in_planes, out_planes, stride=1):"""1x1 convolution"""return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False)class PSAModule(nn.Module):def __init__(self, inplans, planes, conv_kernels=[3, 5, 7, 9], stride=1, conv_groups=[1, 4, 8, 16]):super(PSAModule, self).__init__()self.conv_1 = conv(inplans, planes//4, kernel_size=conv_kernels[0], padding=conv_kernels[0]//2,stride=stride, groups=conv_groups[0])self.conv_2 = conv(inplans, planes//4, kernel_size=conv_kernels[1], padding=conv_kernels[1]//2,stride=stride, groups=conv_groups[1])self.conv_3 = conv(inplans, planes//4, kernel_size=conv_kernels[2], padding=conv_kernels[2]//2,stride=stride, groups=conv_groups[2])self.conv_4 = conv(inplans, planes//4, kernel_size=conv_kernels[3], padding=conv_kernels[3]//2,stride=stride, groups=conv_groups[3])self.se = SEWeightModule(planes // 4)self.split_channel = planes // 4self.softmax = nn.Softmax(dim=1)def forward(self, x):batch_size = x.shape[0]x1 = self.conv_1(x)x2 = self.conv_2(x)x3 = self.conv_3(x)x4 = self.conv_4(x)feats = torch.cat((x1, x2, x3, x4), dim=1)feats = feats.view(batch_size, 4, self.split_channel, feats.shape[2], feats.shape[3])x1_se = self.se(x1)x2_se = self.se(x2)x3_se = self.se(x3)x4_se = self.se(x4)x_se = torch.cat((x1_se, x2_se, x3_se, x4_se), dim=1)attention_vectors = x_se.view(batch_size, 4, self.split_channel, 1, 1)attention_vectors = self.softmax(attention_vectors)feats_weight = feats * attention_vectorsfor i in range(4):x_se_weight_fp = feats_weight[:, i, :, :]if i == 0:out = x_se_weight_fpelse:out = torch.cat((x_se_weight_fp, out), 1)return out
相关文章:
【深度学习】注意力机制(二)
本文介绍一些注意力机制的实现,包括EA/MHSA/SK/DA/EPSA。 【深度学习】注意力机制(一) 【深度学习】注意力机制(三) 目录 一、EA(External Attention) 二、Multi Head Self Attention 三、…...
学习黑马vue
项目分析 项目下载地址:vue-admin-template-master: 学习黑马vue 项目下载后没有环境可参考我的篇文章,算是比较详细:vue安装与配置-CSDN博客 安装这两个插件可格式化代码,vscode这个软件是免费的,官网:…...
gdb本地调试版本移植至ARM-Linux系统
移植ncurses库 本文使用的ncurses版本为ncurses-5.9.tar.gz 下载地址:https://ftp.gnu.org/gnu/ncurses/ncurses-5.9.tar.gz 1. 将ncurses压缩包拷贝至Linux主机或使用wget命令下载并解压 tar-zxvf ncurses-5.9.tar.gz 2. 解压后进入到ncurses-5.9目录…...
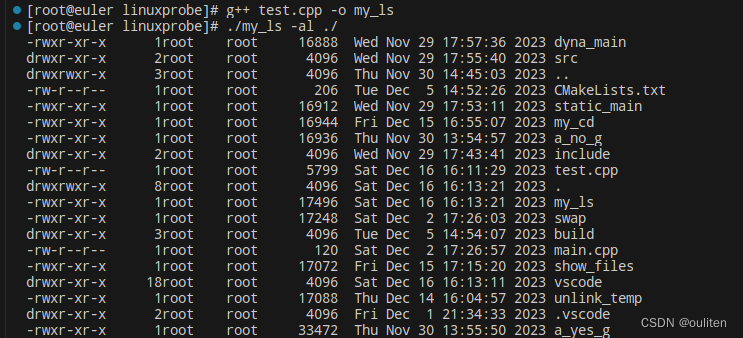
《Linux C编程实战》笔记:实现自己的ls命令
关键函数的功能及说明 1.void display_attribute(struct stat buf,char *name) 函数功能:打印文件名为name的文件信息,如 含义分别为:文件的类型和访问权限,文件的链接数,文件的所有者,文件所有者所属的组…...
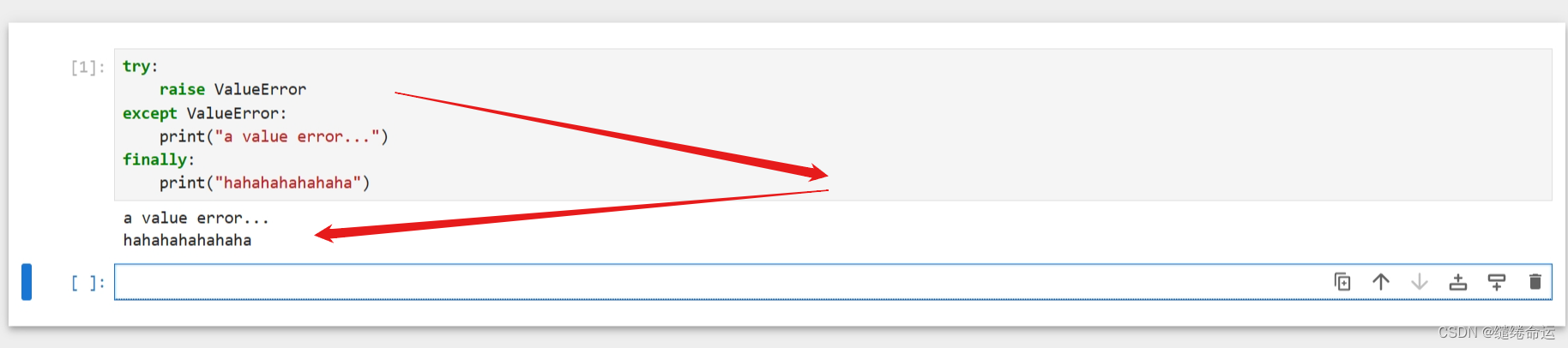
Python个人代码随笔(观看无益,请跳过)
异常抛错:一般来说,在程序中,遇到异常时,会从这一层逐层往外抛错,一直抛到最外层,由最外层把错误显示在用户终端。 try:raise ValueError("A value error...") except ValueError:print("V…...

Unity中实现ShaderToy卡通火(总结篇)
文章目录 前言一、把卡通火修改为后处理效果1、在Shader属性面板定义属性接收帧缓存纹理2、在片元着色器对其纹理采样后,与卡通火相加输出请添加图片描述 二、我们自定义卡通火1、修改 _CUTOFF 使卡通火显示在屏幕两侧2、使火附近屏幕偏红色 前言 在之前的文章中&a…...

等保2.0的变化
1法律地位得到确认 《中华人民共和国网络安全法》第21条规定“国家实行网络安全等级保护制度”,要求“网络运营者应当按照网络安全等级保护制度要求,履行安全保护义务”;第31条规定“对于国家关键信息基础设施,在网络安全等级保护…...
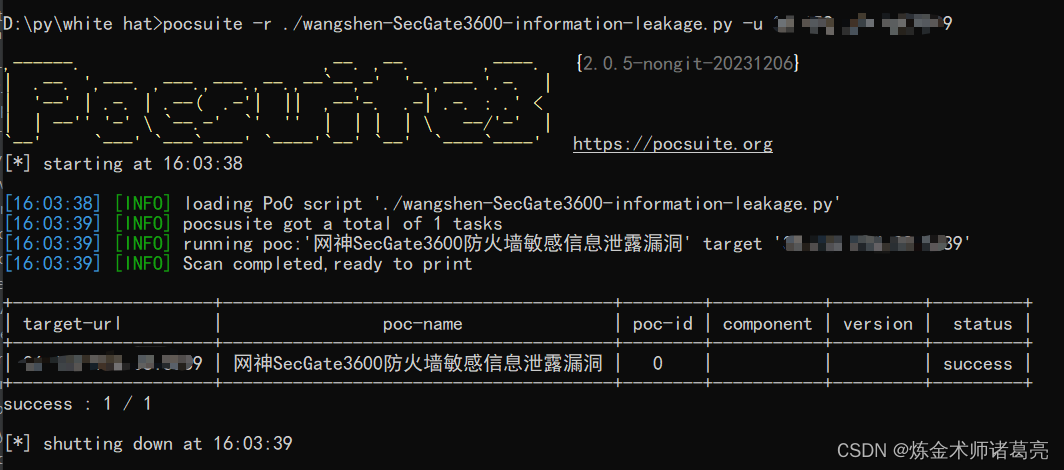
漏洞复现-网神SecGate3600防火墙敏感信息泄露漏洞(附漏洞检测脚本)
免责声明 文章中涉及的漏洞均已修复,敏感信息均已做打码处理,文章仅做经验分享用途,切勿当真,未授权的攻击属于非法行为!文章中敏感信息均已做多层打马处理。传播、利用本文章所提供的信息而造成的任何直接或者间接的…...

ArkTS入门
代码结构分析 struct Index{ } 「自定义组件:可复用的UI单元」 xxx 「装饰器:用来装饰类结构、方法、变量」 Entry 标记当前组件是入口组件(该组件可被独立访问,通俗来讲:它自己就是一个页面)Component 用…...

JS中for循环之退出循环
我为大家介绍一下退出循环的两种方法 1.continue 退出本次循环,一般用于排除或者跳过某一个选项的时候,可以使用continue for(let i 0;i<5;i){if(i 3){continue}// 跳过了3console.log(i) //0 1 2 4}2.break 退出整个for循环,一般用于…...
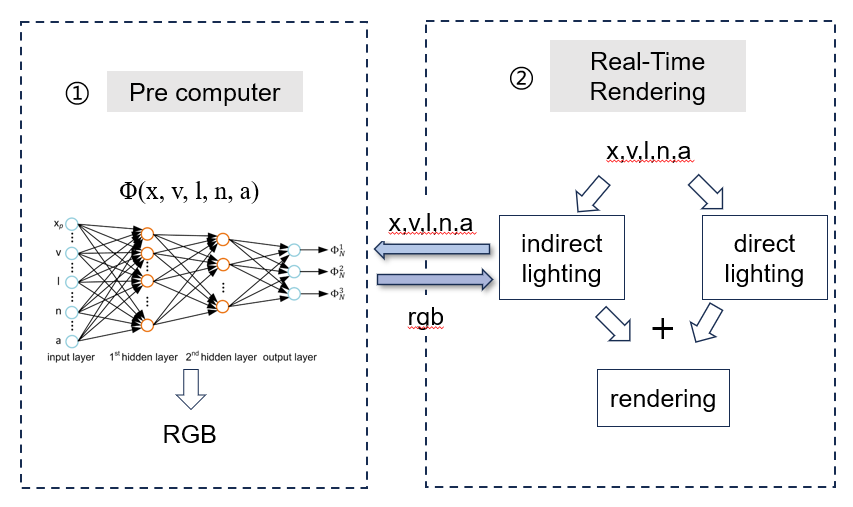
《Global illumination with radiance regression functions》
总结一下最近看的这篇结合神经网络的全局光照论文。 论文的主要思想是利用了神经网络的非线性特性去拟合全局光照中的间接光照部分,采用了基础的2层MLP去训练,最终能实现一些点光源、glossy材质的光照渲染。为了更好的理解、其输入输出表示如下。 首先…...

华南理工C++试卷
诚信应考 , 考试作弊将带来严重后果! 《C程序设计试卷》 注意事项:1. 考前请将密封线内填写清楚; 2. 所有答案请答在试卷的答案栏上; 3.考试形式:闭卷 4. 本试卷共 五 大题,满分100分ÿ…...
0001.WIN7(64位)安装ADS1.2出现L6218错误
用了十多年的笔记本电脑系统出现问题,硬件升级重装以后安装ADS1.2。在编译代码的时候出现L6218错误。如下: 图片是从网上找的,我编译出错的界面没有保留下来。 首先,代码本身没有任何问题 ,代码在win7(32位)下编译没有…...
HBuilderX 配置 夜神模拟器 详细图文教程
在电脑端查看App的效果,不用真机调试,下载一个模拟器就可以了 --- Nox Player,夜神模拟器,是一款 Android 模拟器。他的使用非常安全,最重要的是完全免费。 一. 安装模拟器 官网地址: (yeshen.com) 二.配…...
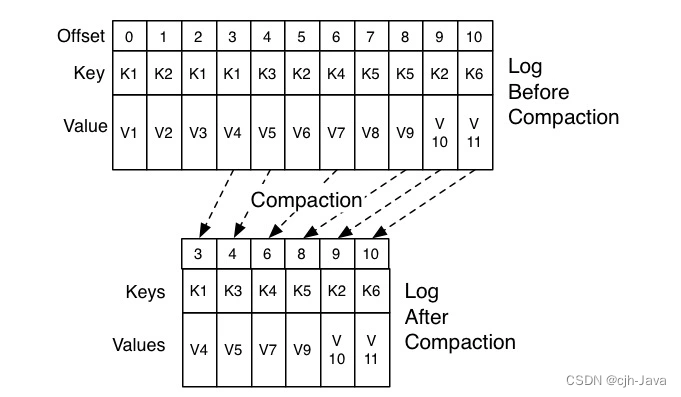
10、神秘的“位移主题”
神秘的“位移主题” 1、什么是位移主题2、位移主题的消息格式3、位移主题是怎么被创建的4、什么地方会用到位移主题5、位移主题的删除机制 本章主题是:Kafka 中的内部主题(Internal Topic)__consumer_offsets。 __consumer_offsets 在 Kafka …...

【Linux】dump命令使用
dump命令 dump命令用于备份文件系统。使用dump命令可以检查ext2/3/4文件系统上的文件,并确定哪些文件需要备份。这些文件复制到指定的磁盘、磁带或其他存储介质保管。 语法 dump [选项] [目录|文件系统] bash: dump: 未找到命令... 安装dump yum -y install …...

使用 TensorFlow 创建生产级机器学习模型(基于数据流编程的符号数学系统)——学习笔记
资源出处:初学者的 TensorFlow 2.0 教程 | TensorFlow Core (google.cn) 前言 对于新框架的学习,阅读官方文档是一种非常有效的方法。官方文档通常提供了关于框架的详细信息、使用方法和示例代码,可以帮助你快速了解和掌握框架的使用。 如…...

vue实现悬浮窗拖动的自定义指令
首先在自己的项目根目录下建一个 src --> config --> drag.js 然后在main.js中全局引入 //鼠标拖动 import drag from /config/drag; Vue.use(drag); drag.js文件相关代码 import Vue from vue; //使用Vue.directive()定义一个全局指令 //1.参数一:指令的…...
gitee(ssh)同步本地
一、什么是码云 gitee Git的”廉价平替” > 服务器在国内,运行不费劲 在国内也形成了一定的规模 git上的一些项目插件等在码云上也可以找得到 二、创建仓库 三、删除仓库 四、仓库与本地同步 > 建立公钥 五、把仓库同步到本地 六、在本地仓库中创建vue项目…...

Redis新数据类型-Bitmaps
目录 Bitmaps 简介 命令 1. setbit (1) 格式 (2) 实例 2. getbit (1) 格式 (2) 实例 3. bitcount (1) 格式 (2) 实例 4. bitop (1) 格式 (2) 实例 我的其他博客 Bitmaps 简介 Bitmaps 是 Redis 的一种新数据类型,它是一种用于存储位信息的数据结构&…...

HsMod:炉石传说终极模改插件完整指南 - 300%游戏体验提升方案
HsMod:炉石传说终极模改插件完整指南 - 300%游戏体验提升方案 【免费下载链接】HsMod Hearthstone Modification Based on BepInEx 项目地址: https://gitcode.com/GitHub_Trending/hs/HsMod HsMod是一款基于BepInEx框架开发的炉石传说模改插件,为…...

数据库查询语句的封装思路
import yamldef yamlread(path): # 打开并读取YAML文件with open(path, r, encodingutf-8) as file:config yaml.safe_load(file)return configc创建一个文件操作方法读取文件信息class dboperations:def __init__(self, config_pathrD:\PycharmProjects\PythonProject\config…...

深度解析 Gemini CLI:架构剖析、高级配置与自动化工作流的高级使用技巧报告
深度解析 Gemini CLI:架构剖析、高级配置与自动化工作流的高级使用技巧报告 Gemini Command Line Interface (CLI) 代表了终端环境下人工智能辅助开发的根本性范式转变。该工具并非仅仅是一个简单的应用程序接口(API)封装,而是一…...

多项目并行开发时借助 Taotoken 统一管理各模型 API 密钥的实践
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 多项目并行开发时借助 Taotoken 统一管理各模型 API 密钥的实践 当你同时推进多个 AI 应用项目时,可能会遇到一个典型的…...

MCP协议与Personas角色:为AI助手打造专属工具箱的实践指南
1. 项目概述:当AI助手拥有“专属工具箱”如果你和我一样,每天都在和各类AI助手打交道,从ChatGPT到Claude,再到国内外的各种大模型应用,你可能会发现一个共同的痛点:这些助手虽然知识渊博,但“动…...

Arm SVE特性寄存器ID_AA64ZFR0_EL1解析与优化
1. Arm SVE特性寄存器ID_AA64ZFR0_EL1深度解析在现代处理器架构中,特性寄存器(Feature ID Registers)扮演着硬件能力标识的关键角色。作为Armv8-A架构中Scalable Vector Extension(SVE)的核心配置寄存器,ID…...

VSCode扩展一键克隆Git仓库:告别终端切换,提升开发效率
1. 项目概述:在VSCode里直接克隆仓库,告别终端切换如果你和我一样,每天的工作流都离不开Git和VSCode,那你一定经历过这个场景:在浏览器上看到一个不错的开源项目,复制它的GitHub链接,然后切到终…...

三步解锁WeMod Pro高级功能:Wand-Enhancer终极免费方案
三步解锁WeMod Pro高级功能:Wand-Enhancer终极免费方案 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 想要完全免费享受WeMod Pro的所有高级…...
)
用Python和Gurobi搞定物流配送难题:手把手教你求解带时间窗的VRP(附完整代码)
用Python和Gurobi破解物流配送难题:从理论到实战的VRPTW完整指南 当外卖骑手在午高峰穿梭于城市的大街小巷时,他们的手机导航上那些看似随机的路线,背后其实隐藏着一套精密的数学算法。这就是我们今天要探讨的带时间窗车辆路径问题࿰…...

AI应用开发利器:基于MCP协议的故障记忆与自学习系统
1. 项目概述:一个为AI应用注入“事故记忆”的MCP服务器最近在折腾AI应用开发,特别是那些需要调用外部工具和数据的智能体(Agent)时,总绕不开一个核心问题:如何让AI在调用外部API或执行复杂操作时࿰…...