【Hadoop_06】MapReduce的概述与wc案例
- 1、MapReduce概述
- 1.1 MapReduce定义
- 1.2 MapReduce优点
- 1.3 MapReduce缺点
- 1.4 MapReduce核心思想
- 1.5 MapReduce进程
- 1.6 常用数据序列化类型
- 1.7 源码与MapReduce编程规范
- 2、WordCount案例实操
- 2.1 本地测试
- 2.2 提交到集群测试
1、MapReduce概述
1.1 MapReduce定义
MapReduce是一个分布式运算程序的编程框架,是用户开发“基于Hadoop的数据分析应用”的核心框架。
MapReduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个Hadoop集群上。
1.2 MapReduce优点
1)MapReduce易于编程
==它简单的实现一些接口,就可以完成一个分布式程序,===这个分布式程序可以分布到大量廉价的PC机器上运行。也就是说你写一个分布式程序,跟写一个简单的串行程序是一模一样的。就是因为这个特点使得MapReduce编程变得非常流行。
2)良好的扩展性
当你的计算资源不能得到满足的时候,你可以通过简单的增加机器来扩展它的计算能力。
3)高容错性
MapReduce设计的初衷就是使程序能够部署在廉价的PC机器上,这就要求它具有很高的容错性。比如其中一台机器挂了,它可以把上面的计算任务转移到另外一个节点上运行,不至于这个任务运行失败,而且这个过程不需要人工参与,而完全是由Hadoop内部完成的。
4)适合PB级以上海量数据的离线处理
可以实现上千台服务器集群并发工作,提供数据处理能力。
1.3 MapReduce缺点
1)不擅长实时计算
MapReduce无法像MySQL一样,在毫秒或者秒级内返回结果。
2)不擅长流式计算
流式计算的输入数据是动态的,而MapReduce的输入数据集是静态的,不能动态变化。这是因为MapReduce自身的设计特点决定了数据源必须是静态的。
3)不擅长DAG(有向无环图)计算
多个应用程序存在依赖关系,后一个应用程序的输入为前一个的输出。在这种情况下,MapReduce并不是不能做,而是使用后,每个MapReduce作业的输出结果都会写入到磁盘,会造成大量的磁盘IO,导致性能非常的低下。
1.4 MapReduce核心思想
现在有一个需求:要统计一个文件当中每一个单词出现的总次数(并将查询结果a-p字母保存一个文件,q-z字母保存一个文件),则可以按照图示步骤
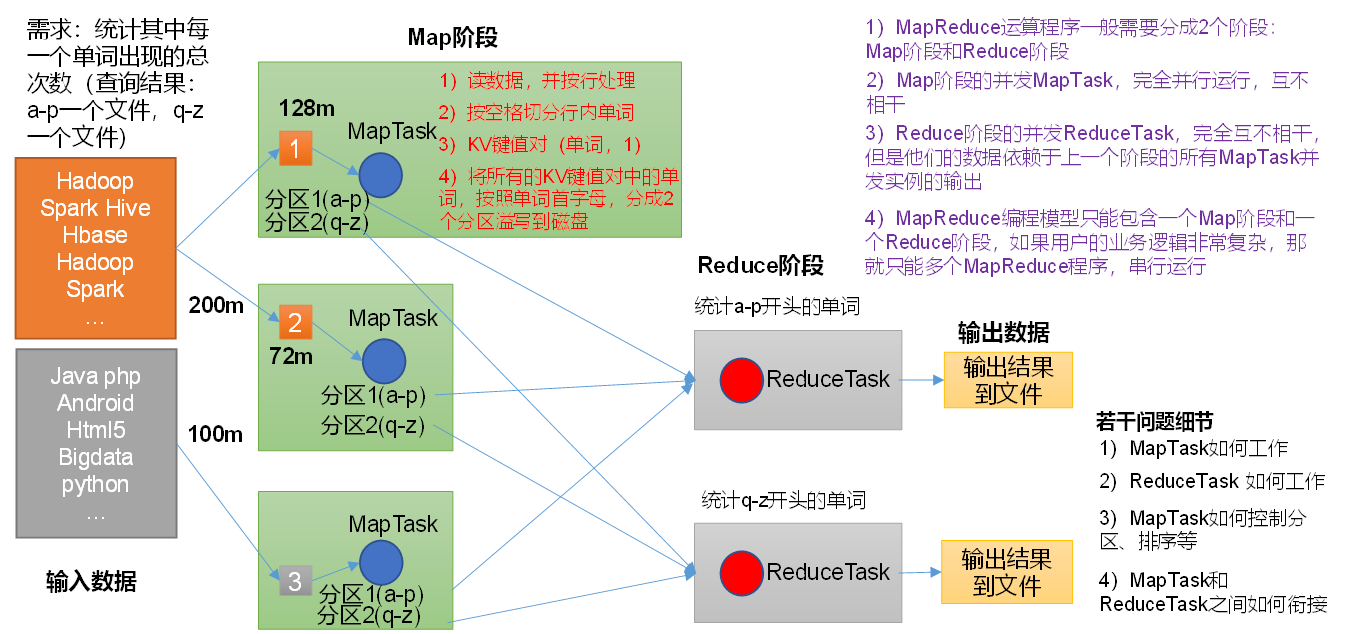
(1)分布式的运算程序往往需要分成至少2个阶段。map+reduce
(2)第一个阶段的MapTask并发实例,完全并行运行,互不相干。统计次数,形成键值对,<H,1>、<S,1>、<H,1>,但是次数之间不相加。
(3)第二个阶段的ReduceTask并发实例互不相干,但是他们的数据依赖于上一个阶段的所有MapTask并发实例的输出。将统计的次数相加求和。
(4)MapReduce编程模型只能包含一个Map阶段和一个Reduce阶段,如果用户的业务逻辑非常复杂,那就只能多个MapReduce程序,串行运行。
总结:分析WordCount数据流走向深入理解MapReduce核心思想。
1.5 MapReduce进程
mr、job、任务指的都是一个应用程序。例如:跑一个wordcount,可以说这是一个job或者任务。
未来在运行MapReduce程序的时候,会启动哪些进程呢?
一个完整的MapReduce程序在分布式运行时有三类实例进程:
(1)MrAppMaster:负责整个程序的过程调度及状态协调。
(2)MapTask:负责Map阶段的整个数据处理流程。
(3)ReduceTask:负责Reduce阶段的整个数据处理流程。
1.6 常用数据序列化类型
| Java类型 | Hadoop Writable类型 |
|---|---|
| Boolean | BooleanWritable |
| Byte | ByteWritable |
| Int | IntWritable |
| Float | FloatWritable |
| Long | LongWritable |
| Double | DoubleWritable |
| String | Text |
| Map | MapWritable |
| Array | ArrayWritable |
| Null | NullWritable |
- 除了string,其他的都是在java类型的基础上加上writable
1.7 源码与MapReduce编程规范
用户编写的程序分成三个部分:Mapper、Reducer和Driver。
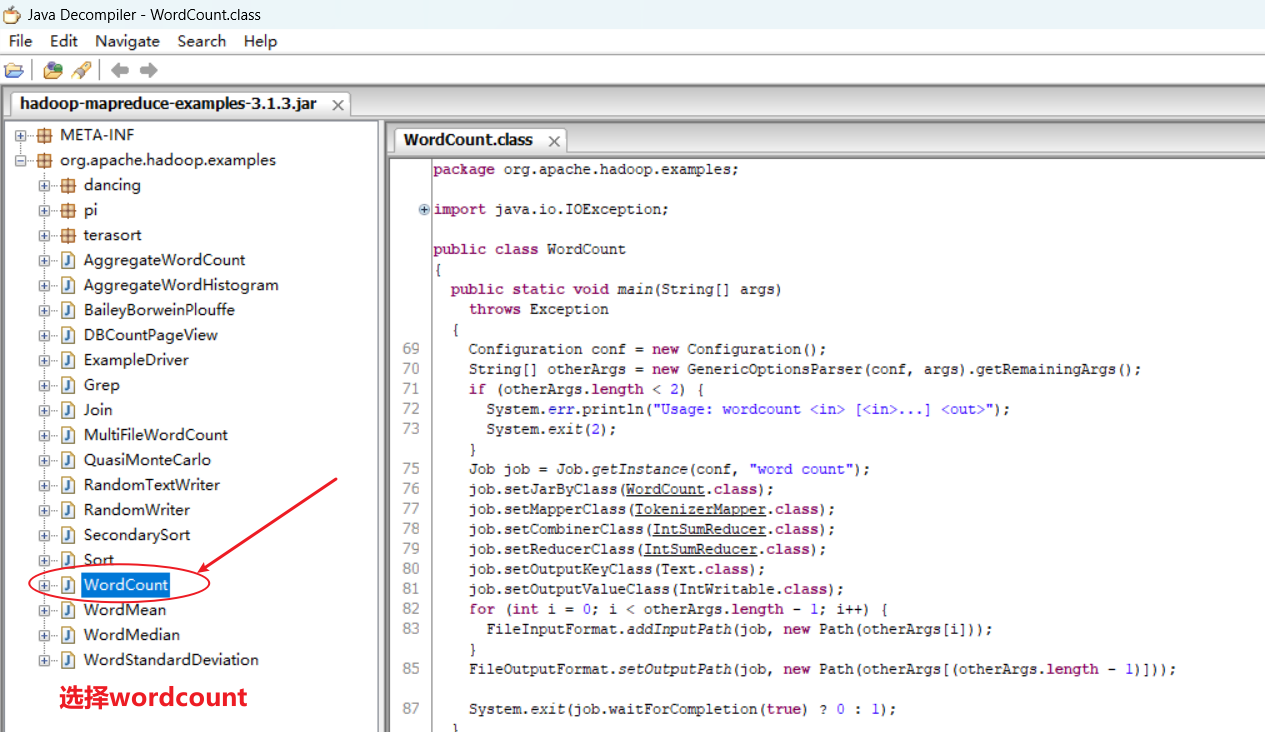
源码如下:
package org.apache.hadoop.examples;import java.io.IOException;
import java.io.PrintStream;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Mapper.Context;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.Reducer.Context;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;public class WordCount
{public static void main(String[] args)throws Exception{Configuration conf = new Configuration();String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();if (otherArgs.length < 2) {System.err.println("Usage: wordcount <in> [<in>...] <out>");System.exit(2);}Job job = Job.getInstance(conf, "word count");job.setJarByClass(WordCount.class);job.setMapperClass(TokenizerMapper.class);job.setCombinerClass(IntSumReducer.class);job.setReducerClass(IntSumReducer.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);for (int i = 0; i < otherArgs.length - 1; i++) {FileInputFormat.addInputPath(job, new Path(otherArgs[i]));}FileOutputFormat.setOutputPath(job, new Path(otherArgs[(otherArgs.length - 1)]));System.exit(job.waitForCompletion(true) ? 0 : 1);}public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable>{private IntWritable result = new IntWritable();public void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context)throws IOException, InterruptedException{int sum = 0;for (IntWritable val : values) {sum += val.get();}this.result.set(sum);context.write(key, this.result);}}public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>{private static final IntWritable one = new IntWritable(1);private Text word = new Text();public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException{StringTokenizer itr = new StringTokenizer(value.toString());while (itr.hasMoreTokens()) {this.word.set(itr.nextToken());context.write(this.word, one);}}}
}
- 上面一共有三个方法,分别是main方法,map方法和reduce方法。
- 定义一个类,继承mapper,之后重写里面的mapper方法,实现自己的业务逻辑。


MapReduce的编程规范如下:


2、WordCount案例实操
2.1 本地测试
1)需求
在给定的文本文件中统计输出每一个单词出现的总次数
(1)输入数据
(2)期望输出数据
wenxin 2
banzhang 1
cls 2
hadoop 1
jiao 1
ss 2
xue 1
- 可以发现上面的数据涉及首字母排序的问题。
2)需求分析
按照MapReduce编程规范,分别编写Mapper,Reducer,Driver。

(1)创建maven工程,MapReduceDemo
(2)在pom.xml文件中添加如下依赖
<dependencies><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.1.3</version></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.12</version></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>1.7.30</version></dependency>
</dependencies>
(2)在项目的src/main/resources目录下,新建一个文件,命名为“log4j.properties”,在文件中填入。
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
(3)创建包名:com.wenxin.mapreduce.wordcount
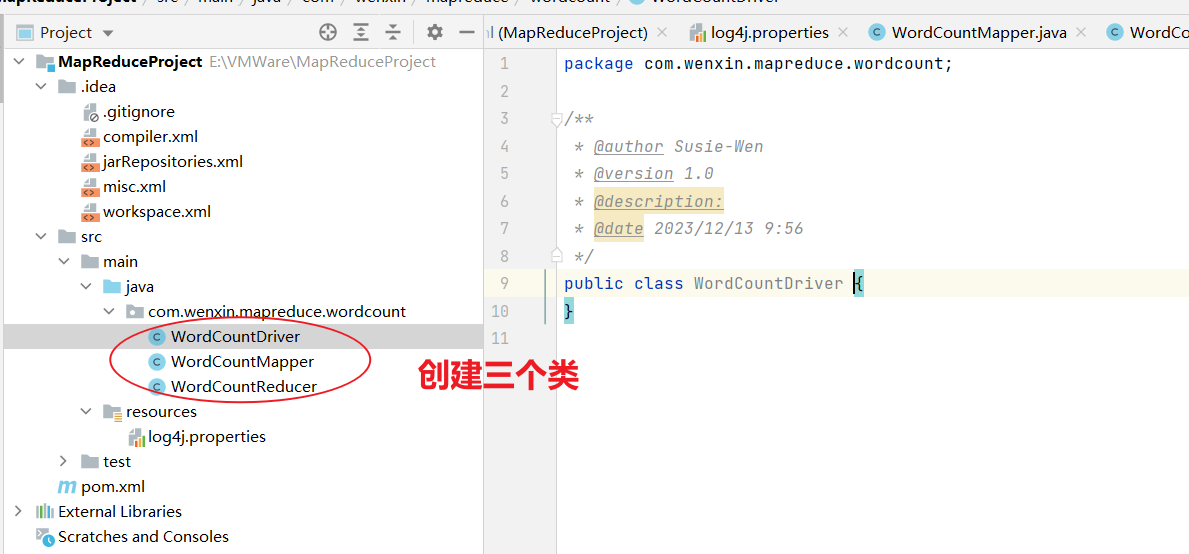
Mapper的源码:
@Public
@Stable
public class Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {public Mapper() {}protected void setup(Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>.Context context) throws IOException, InterruptedException {}protected void map(KEYIN key, VALUEIN value, Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>.Context context) throws IOException, InterruptedException {context.write(key, value);}protected void cleanup(Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>.Context context) throws IOException, InterruptedException {}public void run(Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>.Context context) throws IOException, InterruptedException {this.setup(context);try {while(context.nextKeyValue()) {this.map(context.getCurrentKey(), context.getCurrentValue(), context);}} finally {this.cleanup(context);}}public abstract class Context implements MapContext<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {public Context() {}}
}

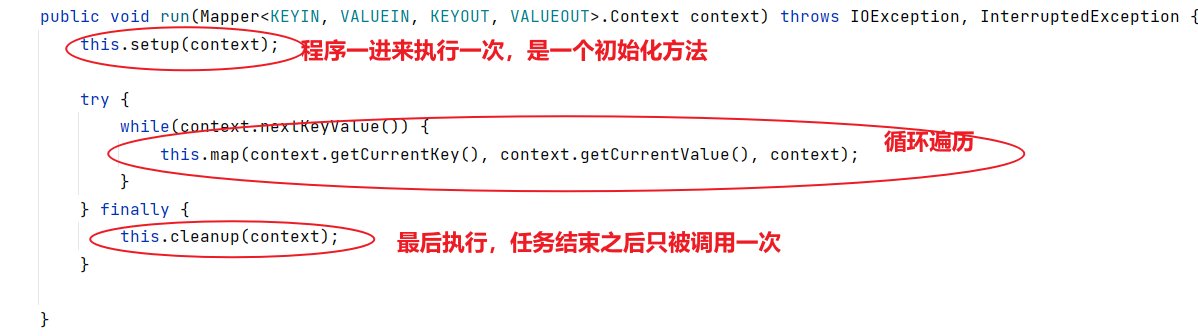
4)编写程序
(1)编写Mapper类
package com.wenxin.mapreduce.wordcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;/*** @author Susie-Wen* @version 1.0* @description:* @date 2023/12/13 9:56*/
/*
KEYIN,map阶段输入的key的类型:LongWritable
VALUEINT,map阶段输入的value的类型:Text
KEYOUT,map阶段输出的Key的类型:Text
VALUEOUT,map阶段输出的value类型:IntWritable*/
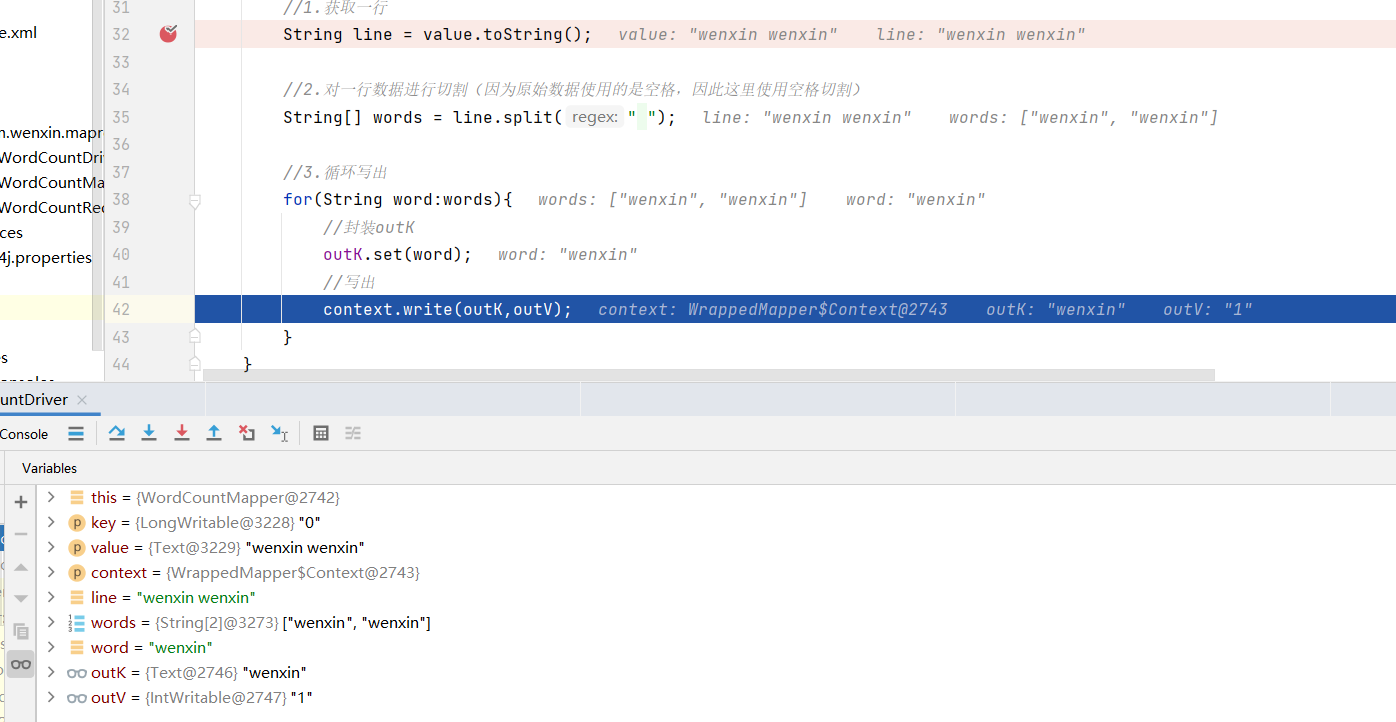
public class WordCountMapper<map> extends Mapper<LongWritable, Text,Text, IntWritable> {//private Text outK=new Text();private IntWritable outV=new IntWritable(1);@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {/*LongWritable key,输入的key,偏移量Text value,输入的valueContext context,对应的上下文*///1.获取一行String line = value.toString();//2.对一行数据进行切割(因为原始数据使用的是空格,因此这里使用空格切割)String[] words = line.split(" ");//3.循环写出for(String word:words){//封装outKoutK.set(word);//写出context.write(outK,outV);}}
}



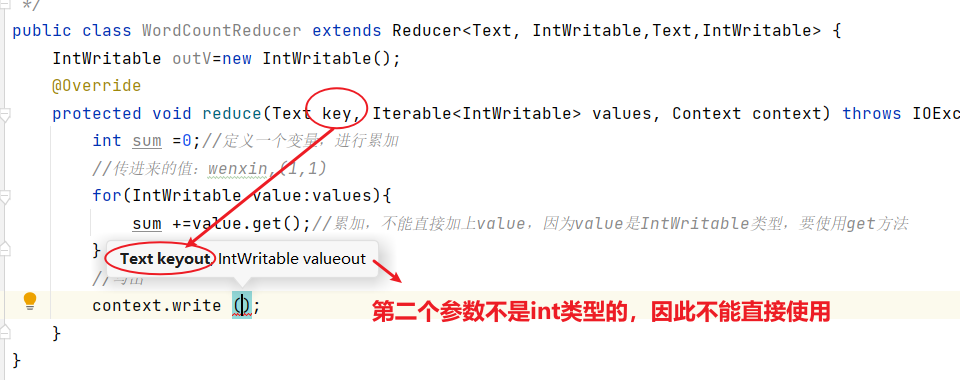
(2)编写Reducer类
package com.wenxin.mapreduce.wordcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/*** @author Susie-Wen* @version 1.0* @description:* @date 2023/12/13 9:56*/
/*
KEYIN,reduce阶段输入的key的类型:Text
VALUEINT,reduce阶段输入的value的类型:IntWritable
KEYOUT,reduce阶段输出的Key的类型:Text
VALUEOUT,reduce阶段输出的value类型:IntWritable*/
public class WordCountReducer extends Reducer<Text, IntWritable,Text,IntWritable> {IntWritable outV=new IntWritable();@Overrideprotected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {int sum =0;//定义一个变量,进行累加//传进来的值:wenxin,(1,1)for(IntWritable value:values){sum +=value.get();//累加,不能直接加上value,因为value是IntWritable类型,要使用get方法}outV.set(sum);//写出context.write(key,outV);}
}
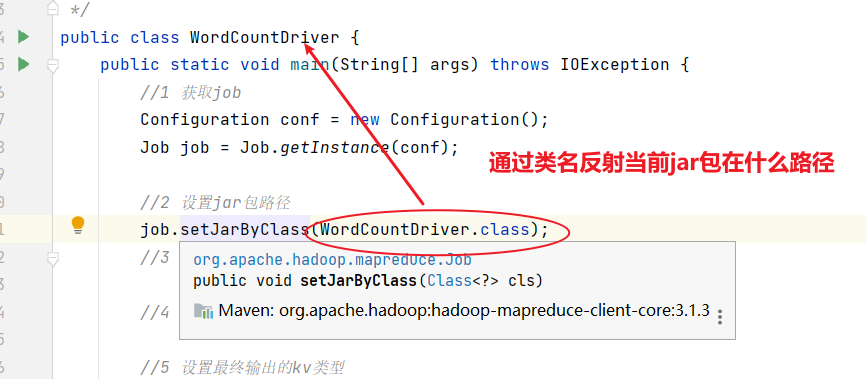
(3)编写Driver驱动类
- driver当中有7步,都是固定的;其次需要注意不要导错包了!
package com.atguigu.mapreduce.wordcount;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;public class WordCountDriver {public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {// 1 获取配置信息以及获取job对象Configuration conf = new Configuration();Job job = Job.getInstance(conf);// 2 关联本Driver程序的jarjob.setJarByClass(WordCountDriver.class);// 3 关联Mapper和Reducer的jarjob.setMapperClass(WordCountMapper.class);job.setReducerClass(WordCountReducer.class);// 4 设置Mapper输出的kv类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(IntWritable.class);// 5 设置最终输出kv类型job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);// 6 设置输入和输出路径FileInputFormat.setInputPaths(job, new Path(args[0]));FileOutputFormat.setOutputPath(job, new Path(args[1]));// 7 提交jobboolean result = job.waitForCompletion(true);System.exit(result ? 0 : 1);}
}
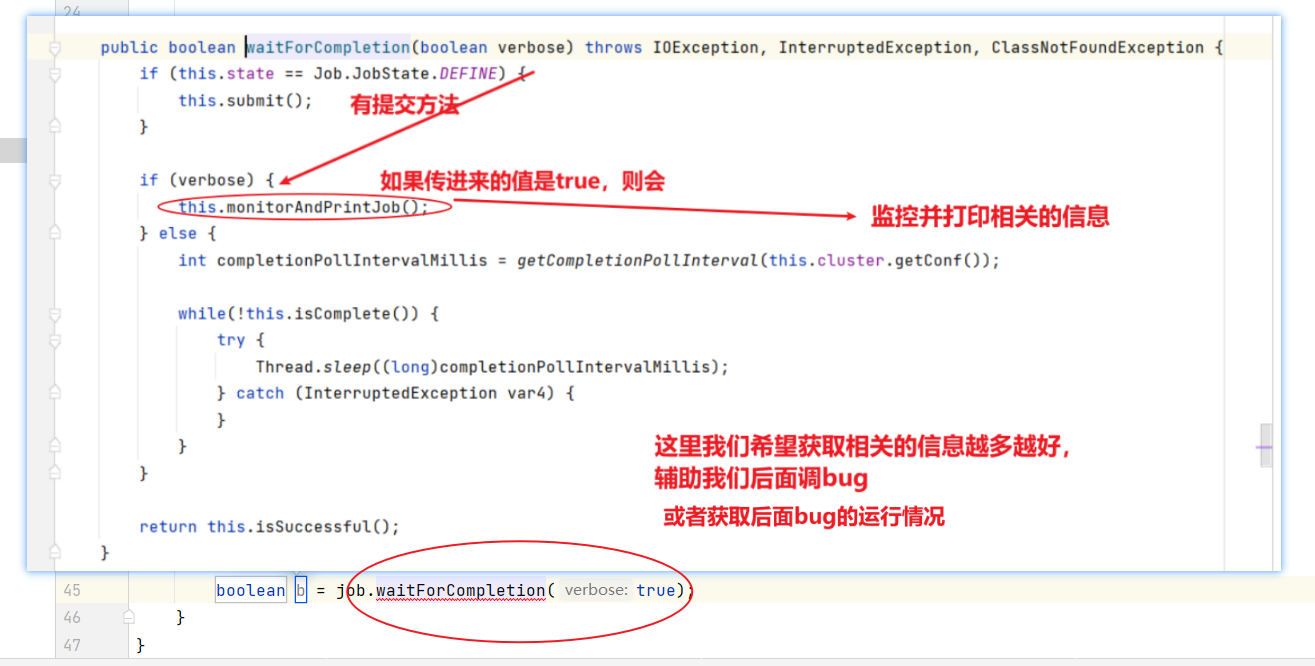
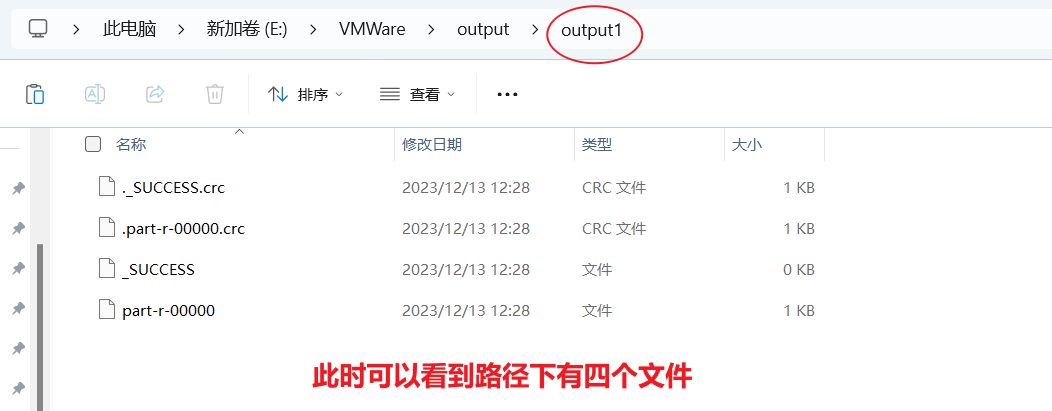
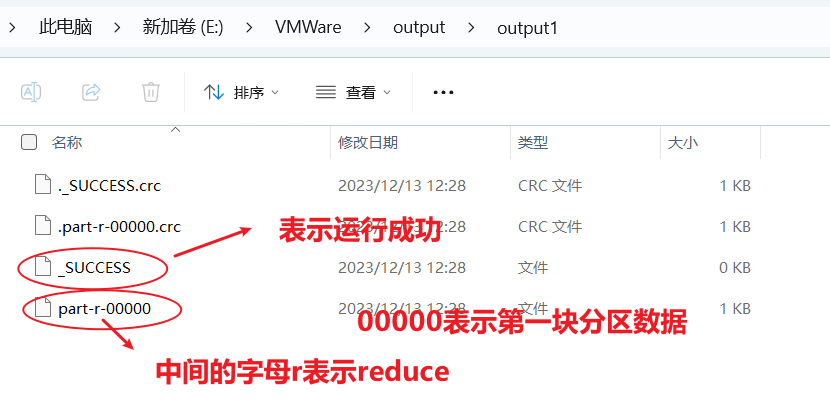

- 可以看到hadoop默认会对数据进行排序
- 如果此时再次点击运行的话,会报错,显示输出路径存在;因此对于mapreduce程序,如果输出路径存在了,就会报错。
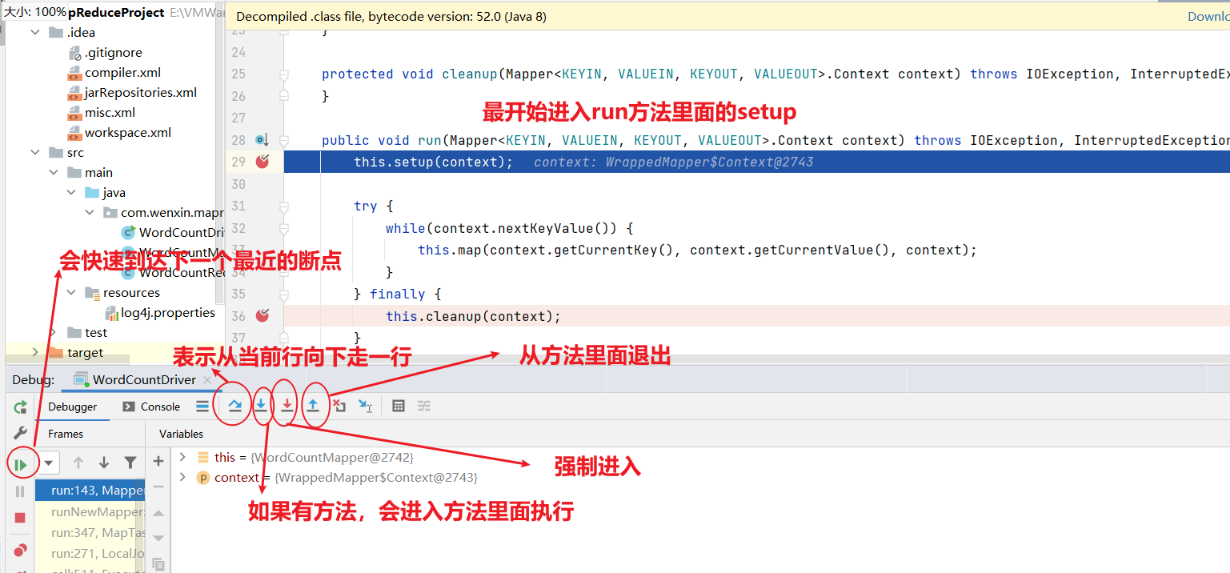
5)本地测试
(1)需要首先配置好HADOOP_HOME变量以及Windows运行依赖
(2)在IDEA/Eclipse上运行程序
2.2 提交到集群测试
集群上测试
(1)用maven打jar包,需要添加的打包插件依赖
<build><plugins><plugin><artifactId>maven-compiler-plugin</artifactId><version>3.6.1</version><configuration><source>1.8</source><target>1.8</target></configuration></plugin><plugin><artifactId>maven-assembly-plugin</artifactId><configuration><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs></configuration><executions><execution><id>make-assembly</id><phase>package</phase><goals><goal>single</goal></goals></execution></executions></plugin></plugins>
</build>
注意:如果工程上显示红叉。在项目上右键->maven->Reimport刷新即可。
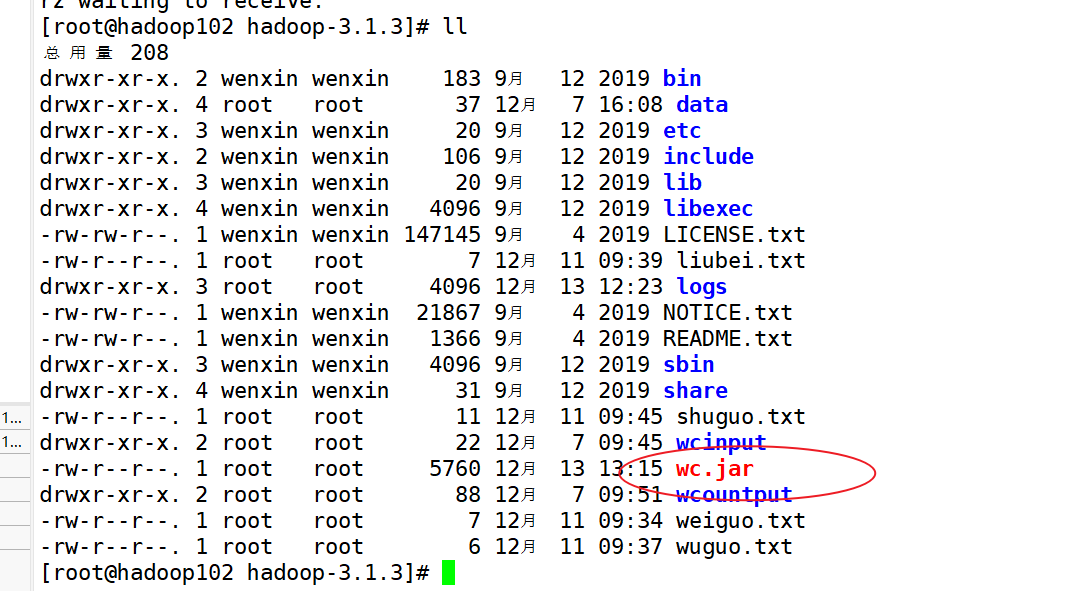
(2)将程序打成jar包


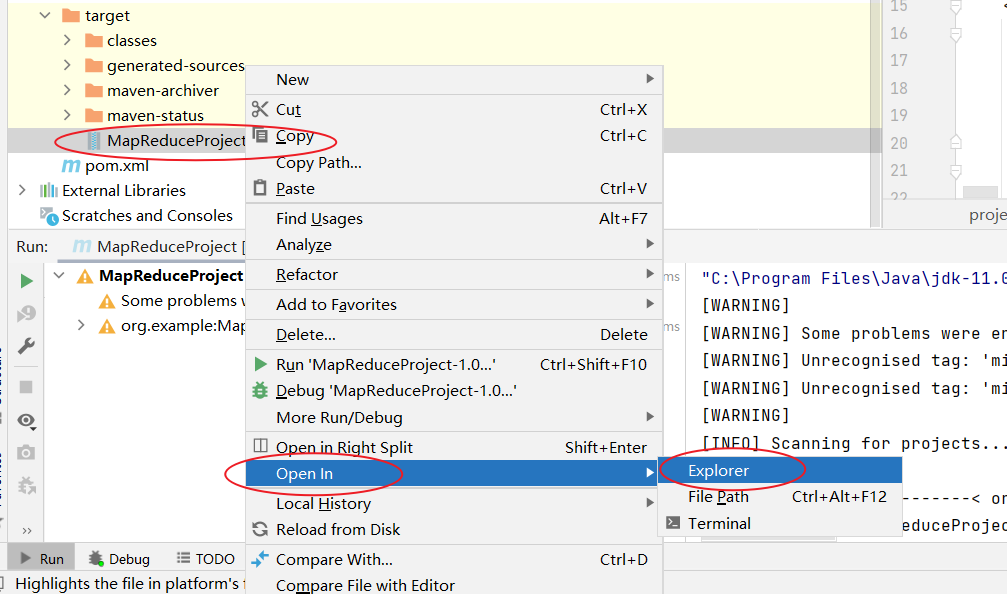
(3)修改不带依赖的jar包名称为wc.jar,并拷贝该jar包到Hadoop集群的/home/wenxin/module/hadoop-3.1.3路径。
(4)启动Hadoop集群
[root@hadoop102 hadoop-3.1.3]sbin/start-dfs.sh
[root@hadoop103 hadoop-3.1.3]$ sbin/start-yarn.sh
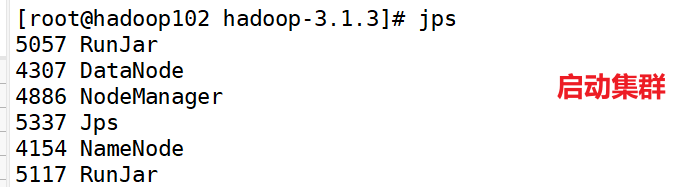
(5)执行WordCount程序
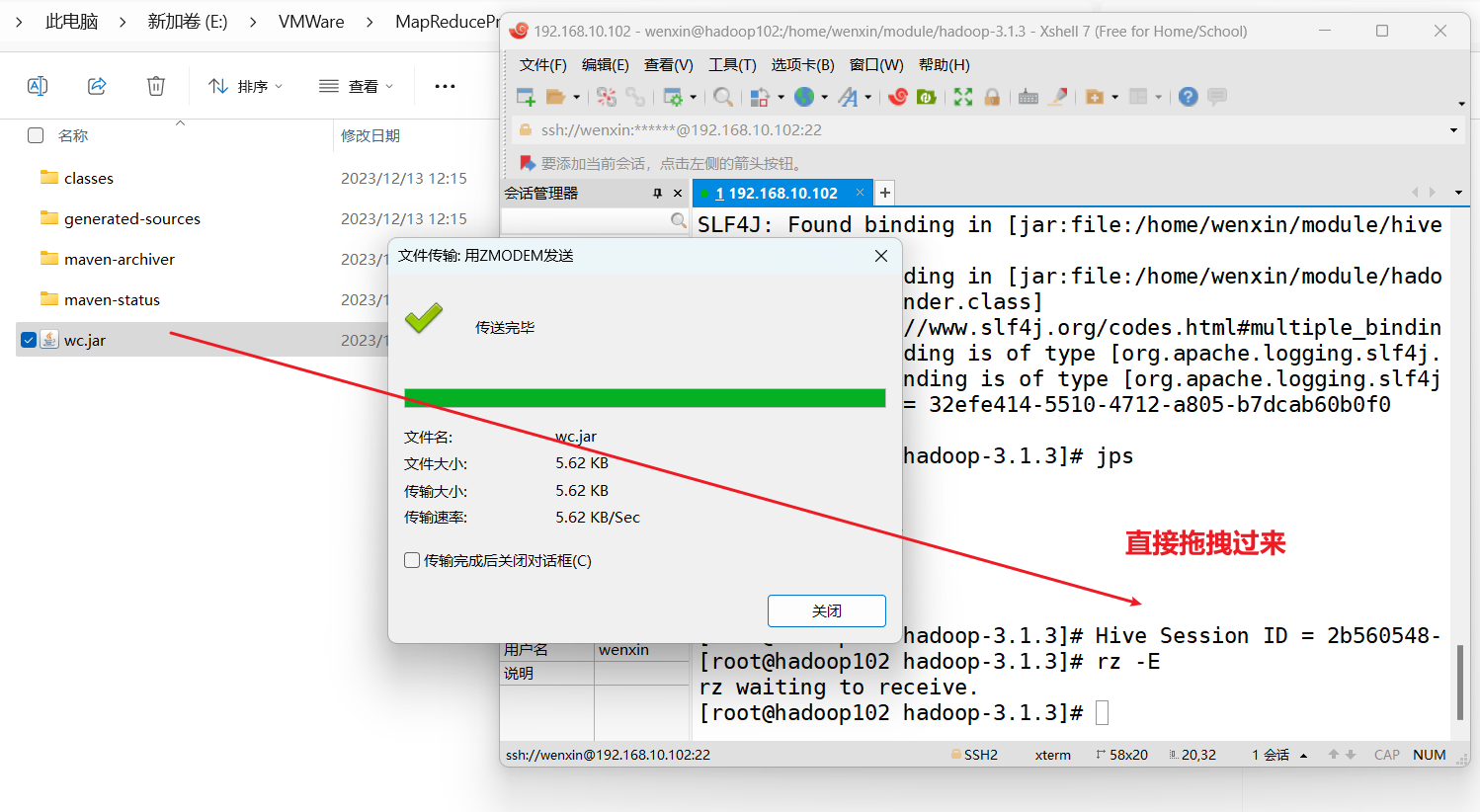
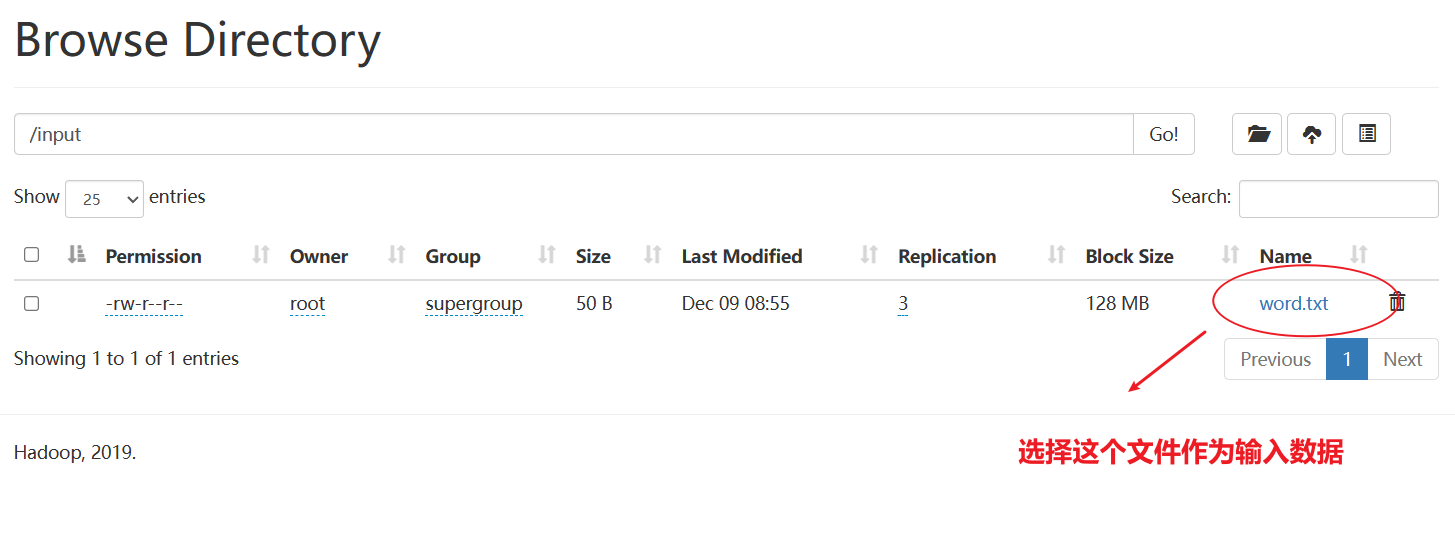
[root@hadoop102 hadoop-3.1.3]$ hadoop jar wc.jarcom.wenxin.mapreduce.wordcount.WordCountDriver /user/wenxin/input /user/wenxin/output

相关文章:
【Hadoop_06】MapReduce的概述与wc案例
1、MapReduce概述1.1 MapReduce定义1.2 MapReduce优点1.3 MapReduce缺点1.4 MapReduce核心思想1.5 MapReduce进程1.6 常用数据序列化类型1.7 源码与MapReduce编程规范 2、WordCount案例实操2.1 本地测试2.2 提交到集群测试 1、MapReduce概述 1.1 MapReduce定义 MapReduce是一…...

Qt点击子窗口时父窗口标题栏高亮设计思路
父窗口调用findChildren得到其子孙窗口的列表,列表元素统一为QWidget*,遍历列表元素,每个元素调用installEventFilter,过滤QEvent::FocusIn和QEvent::FocusOut事件,做相应处理即可: QWidget* parent; QLis…...
掌握iText:轻松处理PDF文档-高级篇-添加水印
前言 iText作为一个功能强大、灵活且广泛应用的PDF处理工具,在实际项目中发挥着重要作用。通过这些文章,读者可以深入了解如何利用iText进行PDF的创建、编辑、加密和提取文本等操作,为日常开发工作提供了宝贵的参考和指导。 掌握iText&…...
深度学习基本概念
1.全连接层 全连接层就是该层的所有节点与输入节点全部相连,如图所 示。假设输入节点为X1, X 2, X 3,输出节点为 Y 1, Y 2, Y 3, Y 4。令 矩阵 W 代表全连接层的权重, W 12也就代表 …...

2023年最详细的:本地Linux服务器安装宝塔面板,并内网穿透实现公网远程登录
📚📚 🏅我是默,一个在CSDN分享笔记的博主。📚📚 🌟在这里,我要推荐给大家我的专栏《Linux》。🎯🎯 🚀无论你是编程小白,还是有一…...

基于ssm金旗帜文化培训学校网站的设计与开发论文
摘 要 互联网发展至今,无论是其理论还是技术都已经成熟,而且它广泛参与在社会中的方方面面。它让信息都可以通过网络传播,搭配信息管理工具可以很好地为人们提供服务。针对培训学校展示信息管理混乱,出错率高,信息安全…...

【Java】猜数字小游戏
规则 游戏开始随机生成4位数字符串,每个数字从0到9各不相同,比如0123玩家10次猜数机会,输入4位数字符串,每个数字从0到9各不相同游戏判断玩家输入与所猜谜底数,给出结果nAnB,A表示位置和数字都猜对的个数&…...
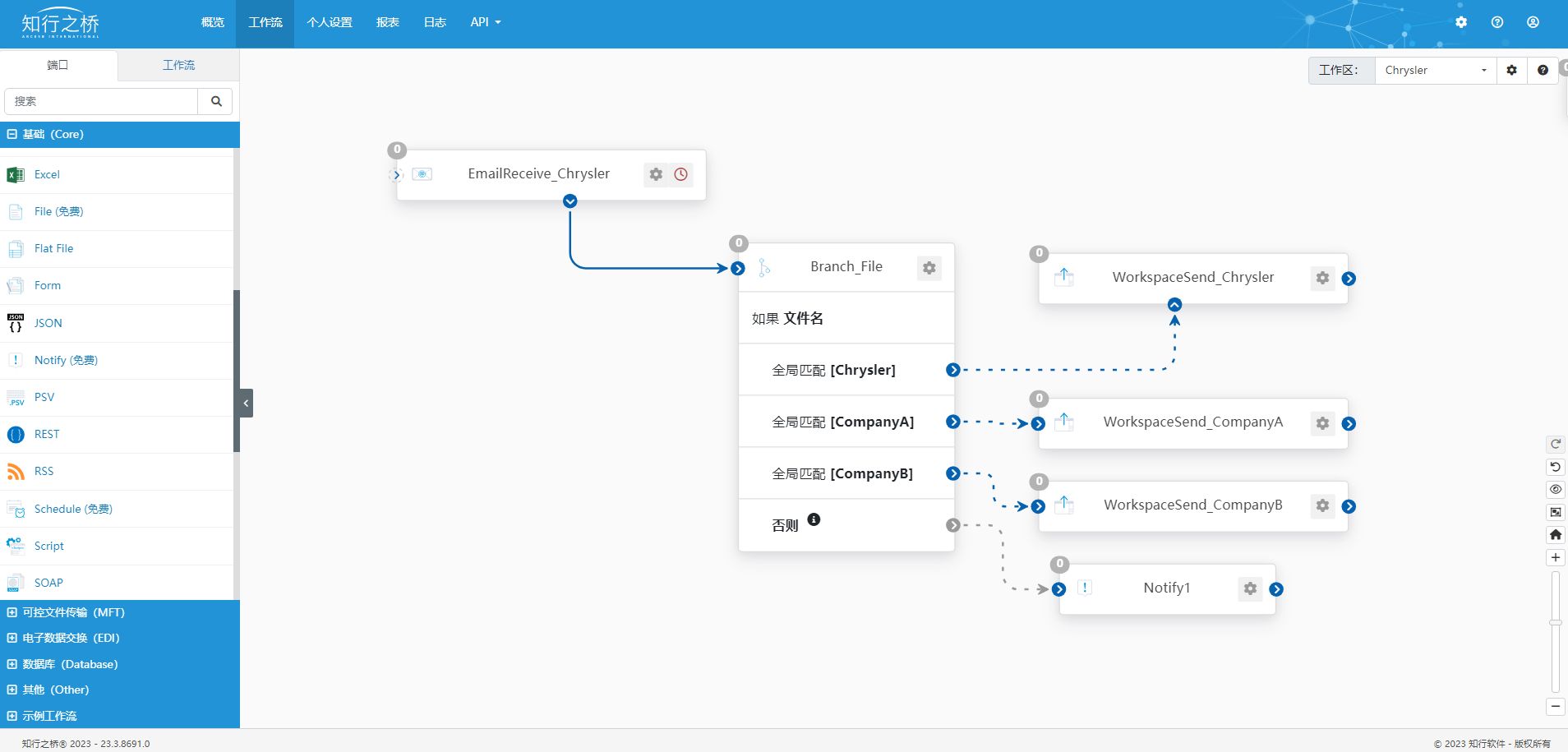
汽车EDI:Chrysler EDI项目案例
菲亚特克莱斯勒汽车Fiat Chrysler Automobiles(FCA)是一家全球性汽车制造商,主营产品包括轿车、SUV、皮卡车、商用车和豪华车等多种车型。其旗下品牌包括菲亚特、克莱斯勒、道奇、Jeep、Ram、阿尔法罗密欧和玛莎拉蒂等。 Chrysler通过EDI来优化订单处理、交付通知、…...
Locust:可能是一款最被低估的压测工具
01、Locust介绍 开源性能测试工具https://www.locust.io/,基于Python的性能压测工具,使用Python代码来定义用户行为,模拟百万计的并发用户访问。每个测试用户的行为由您定义,并且通过Web UI实时监控聚集过程。 压力发生器作为性能…...
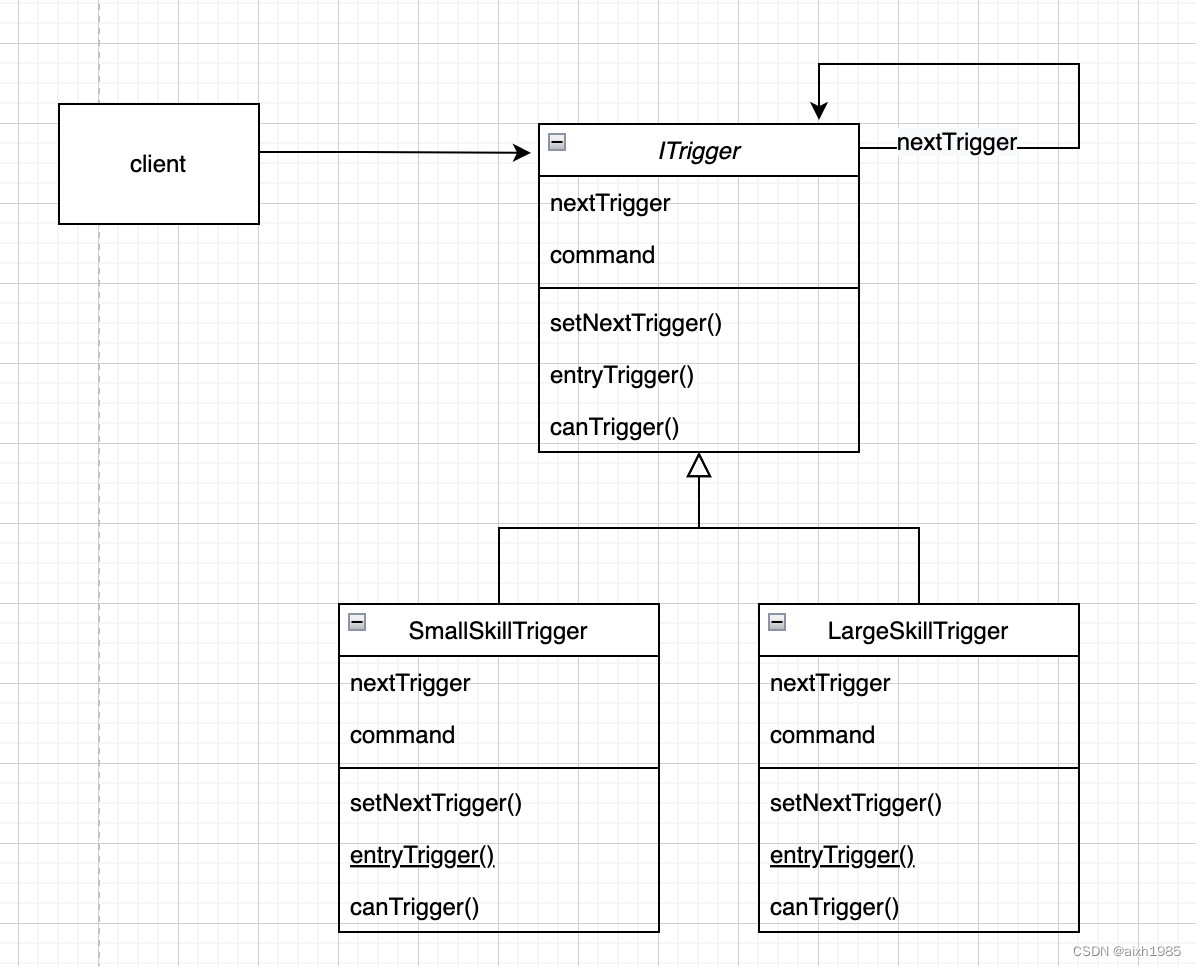
用23种设计模式打造一个cocos creator的游戏框架----(十八)责任链模式
1、模式标准 模式名称:责任链模式 模式分类:行为型 模式意图:使多个对象都有机会处理请求,从而避免请求的发送者和接收者之间的耦合关系。将这些对象连成一条链,并沿着这条链传递该请求,直到有一个对象处…...
——第9天:风控建模中为什么需要特征工程?)
100天精通风控建模(原理+Python实现)——第9天:风控建模中为什么需要特征工程?
风控模型已在各大银行和公司都实际运用于业务,用于营销和风险控制等。本文以视频的形式阐述风控建模中为什么需要特征工程。并提供风控建模原理和Python实现文章清单。 之前已经阐述了100天精通风控建模(原理+Python实现)——第1天:什么是风控建模? 100天精通风控…...

【PHP】计算某个特定时间戳距离现在的天数
在PHP中,你可以使用time()函数获取当前时间的时间戳,然后将它与你想要计算的过去或未来的时间戳进行比较。为了得到相差的天数,你需要先用两个时间戳相减得到秒数差,然后再除以一天的总秒数(通常是86400秒)…...
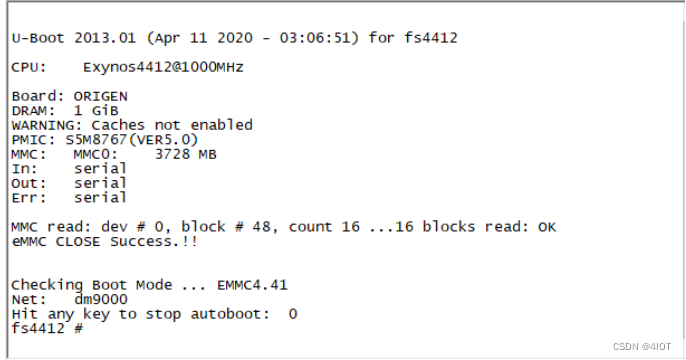
lv12 uboot移植深化 9
u-boot-2013.01移植 【实验目的】 了解u-boot 的代码结构及移植的基本方法 【实验环境】 ubuntu 14.04发行版FS4412实验平台交叉编译工具arm-none-linux-gnueabi- 【注意事项】 实验步骤中以“$”开头的命令表示在 ubuntu 环境下执行 【实验步骤】 1 建立自己的平台 1.…...

大数据与深度挖掘:如何在数字营销中与研究互动
数字营销最吸引人的部分之一是对数据的内在关注。 如果一种策略往往有积极的数据,那么它就更容易采用。同样,如果一种策略尚未得到证实,则很难获得支持进行测试。 数字营销人员建立数据信心的主要方式是通过研究。这些研究通常分为两类&…...

xtu oj 1327 字符矩阵
按照示例的规律输出字符矩阵。 比如输入字母D时,输出字符矩阵如下 ABCDCBA BBCDCBB CCCDCCC DDDDDDD CCCDCCC BBCDCBB ABCDCBA字符矩阵行首、尾都无空格。 输入 每行一个大写英文字母,如果字符为#,表示输入结束,不需要处理。 …...

讨论用于评估DREX的五种DR指标
概要 动态范围是已经使用了近一个世纪的用于评估接收机性能的参数。这里介绍五种动态有关指标的定义及测试方法,用于评估数字接收激励器(DREX,digital receiver exciters)。DREX是构成雷达的关键整部件,其瞬时带宽&am…...

基于SpringBoot的在线疫苗预防小程序
文章目录 项目介绍主要功能截图:部分代码展示设计总结项目获取方式🍅 作者主页:超级无敌暴龙战士塔塔开 🍅 简介:Java领域优质创作者🏆、 简历模板、学习资料、面试题库【关注我,都给你】 🍅文末获取源码联系🍅 项目介绍 基于SpringBoot的在线疫苗预防小程序,ja…...

Kafka使用总结
1、Kafka是何如做到高性能的? a、消息批处理减少网络通信开销,提升系统吞吐能力(先攒一波,消息以“批”为单位进行处理) 生产端:无论是同步发送还是异步发送,Kafka都不会立即就把这条消息发送出…...
2023 年山东省职业院校技能大赛(高等职业教育) “信息安全管理与评估”样题
2023 年山东省职业院校技能大赛(高等职业教育) “信息安全管理与评估”样题 目录 任务 1 网络平台搭建(50 分) 任务 2 网络安全设备配置与防护(250 分) 模块二 网络安全事件响应、数字取证调查、应用程序安…...

Apache Web 服务器监控工具
将Apache Web 服务器监控纳入 IT 基础架构管理策略有助于先发制人地识别性能瓶颈,这种主动监控方法提供必要的数据,以确保 Web 服务器能够胜任任务,并在需要时进行优化。保证客户获得流畅、无忧的用户体验可以大大有助于巩固他们对组织的信任…...

API数据与自建数据库同步:CDC+ETL的实时数据管道
在电商、跨境业务、微服务架构等实际业务场景中,系统普遍面临多平台 API 数据源杂乱、自建数据库数据滞后、手工同步易出错、批量离线同步时效性差等痛点。第三方平台开放 API、业务系统接口、供应链数据接口源源不断产生增量数据,而企业自建 MySQL、Pos…...

191k Star 的 Superpowers:把 AI 从“会写代码“改造成“守纪律的工程师“
路易乔布斯 2026-05-14 AI Daily 深度拆解 数据时间锚点:本文写作时 obra/superpowers 数据为 191k stars / v5.1.0 (2026-04-30) / 8 个编码代理平台已支持。一、那条让我点进去的 AI 日报 今早翻 AI 日报,第 9/10 条标着 🔥 重磅…...

开源工具picprose:AI驱动的图片处理与文案生成一体化解决方案
1. 项目概述与核心价值最近在折腾个人博客和内容创作时,我遇到了一个挺普遍但又很烦人的问题:手头有一堆图片,但要么尺寸不合适,要么色调不统一,要么就是缺少一个能吸引眼球的标题。手动处理吧,费时费力&am…...
)
别再乱用普通二极管了!手把手教你用BAT54S搭建20kHz小信号检波电路(附Python测试代码)
别再乱用普通二极管了!手把手教你用BAT54S搭建20kHz小信号检波电路(附Python测试代码) 在微弱信号处理领域,一个常见的误区是工程师们习惯性使用普通硅二极管进行检波。我曾在一个光电传感器项目中,发现信号经过普通二…...

CircuitPython社区贡献指南:从翻译到代码提交的完整实践
1. 项目概述:从使用者到贡献者的转变 如果你和我一样,从某个创客项目或者教育套件开始接触 CircuitPython,你可能会觉得它只是一个让硬件“动起来”的脚本语言。点亮一个LED,读取一个传感器,然后心满意足。但当你深入…...
)
【Oracle数据库指南】第36篇:Oracle用户与权限管理详解(完整版)
上一篇【第35篇】Oracle特殊对象——簇与索引组织表(IOT) 下一篇【第37篇】Oracle角色与PROFILE管理详解 摘要 Oracle数据库的用户与权限管理是安全管理的核心,建立科学的用户体系是保障数据安全的第一步。本文系统讲解Oracle用户账户的完整…...

从硬盘拷贝文件到内存,CPU真的在摸鱼吗?深入聊聊DMA背后的性能优化哲学
从硬盘拷贝文件到内存,CPU真的在摸鱼吗?深入聊聊DMA背后的性能优化哲学 当你从硬盘拷贝一个10GB的电影文件到内存时,系统监控显示CPU占用率几乎没变化——这似乎违背直觉。难道CPU真的在"摸鱼"?实际上,这背后…...

抖音开放平台实战指南:从授权码到接口调用的全链路解析
1. 抖音开放平台入门:从零开始接入 刚接触抖音开放平台的开发者可能会觉得一头雾水,其实整个流程可以简化为三个核心步骤:获取授权码、换取访问令牌、调用接口获取数据。我刚开始对接时也踩过不少坑,比如回调地址配置错误、token过…...

Hyperbrowser MCP:下一代AI原生网页自动化工具,零代码抓取与结构化数据提取
前言 2026年3月12日,全球MCP生态核心团队HyperAI正式开源Hyperbrowser MCP,这是全球首个专为AI智能体设计的浏览器自动化与网页数据提取工具。它彻底打破了传统网页抓取工具"必须写代码"的门槛,无需编写一行Selenium/Playwright脚本…...

多模态AI在移动端测试中的应用:视觉+日志+性能联合分析
一、从单点验证到全景追溯:测试范式的必然演进 移动端测试的复杂性早已超越传统Web应用。设备碎片化、网络环境多变、系统资源受限、跨应用交互频繁,这些因素使得单一维度的测试手段越来越力不从心。过去,测试工程师习惯在UI自动化、接口测试…...