【云原生kubernets】Service 的功能与应用
一、Service介绍
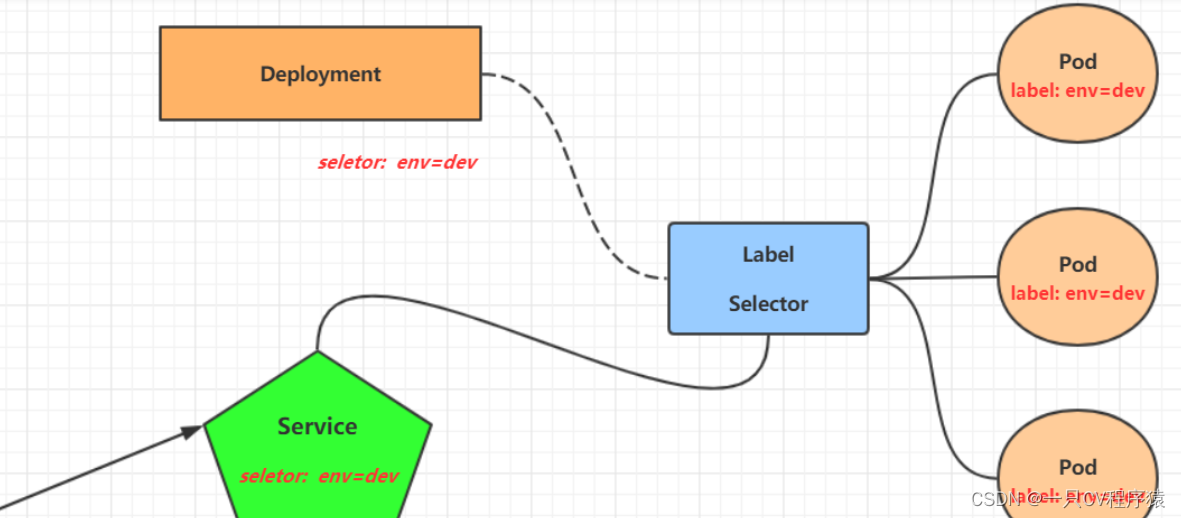
在kubernetes中,pod是应用程序的载体,我们可以通过pod的ip来访问应用程序,但是pod的ip地址不是固定的,这也就意味着不方便直接采用pod的ip对服务进行访问。为了解决这个问题,kubernetes提供了Service资源,Service会对提供同一个服务的多个pod进行聚合,并且提供一个统一的入口地址。通过访问Service的入口地址就能访问到后面的pod服务。
Service在很多情况下只是一个概念,真正起作用的其实是kube-proxy服务进程,每个Node节点上都运行着一个kube-proxy服务进程。当创建Service的时候会通过api-server向etcd写入创建的service的信息,而kube-proxy会基于监听的机制发现这种Service的变动,然后它会将最新的Service信息转换成对应的访问规则。

二、kube-proxy的三种工作模式
(1)userspace 模式
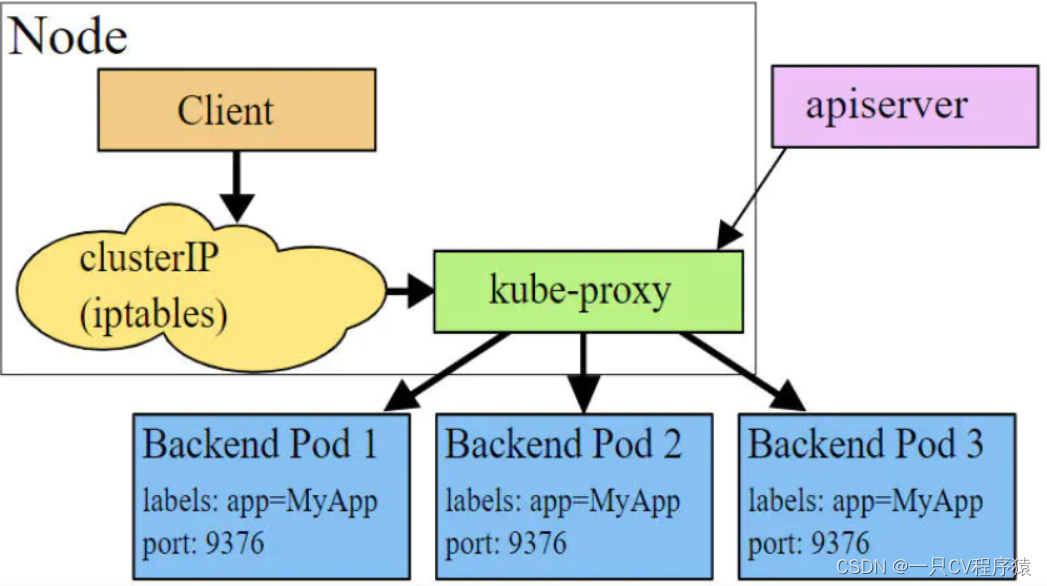
userspace模式下,kube-proxy会为每一个Service创建一个监听端口,发向Cluster IP的请求被Iptables规则重定向到kube-proxy监听的端口上,kube-proxy根据LB算法选择一个提供服务的Pod并和其建立链接,以将请求转发到Pod上。该模式下,kube-proxy充当了一个四层负载均衡器的角色。由于kube-proxy运行在userspace中,在进行转发处理时会增加内核和用户空间之间的数据拷贝,虽然比较稳定,但是效率比较低。
(2)iptables 模式
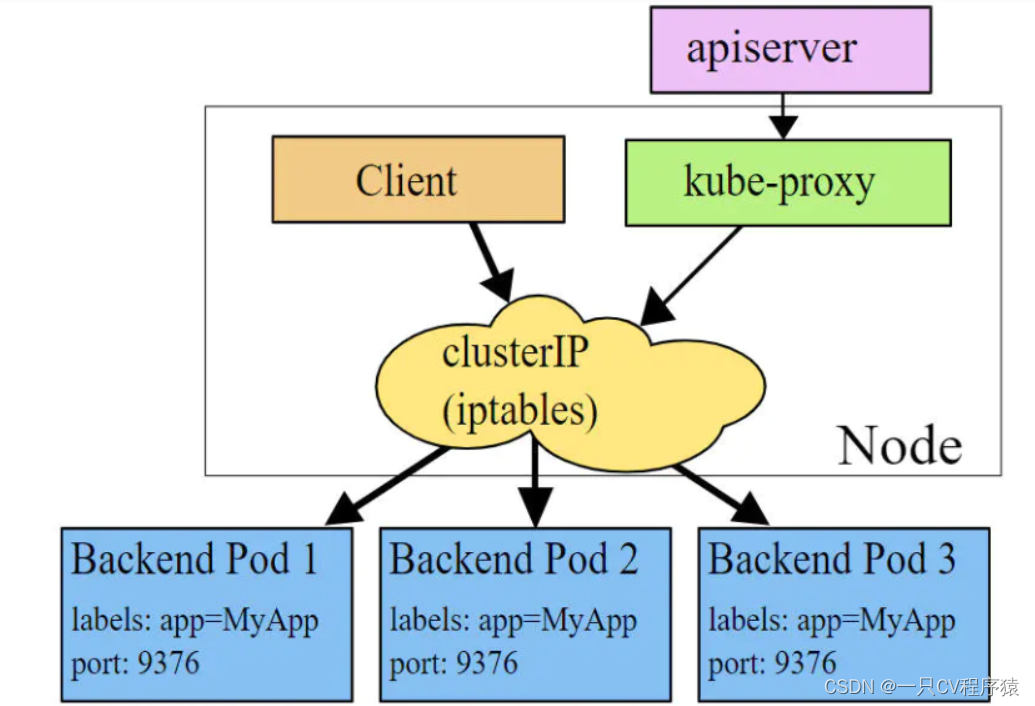
iptables模式下,kube-proxy为service后端的每个Pod创建对应的iptables规则,直接将发向Cluster IP的请求重定向到一个Pod IP。该模式下kube-proxy不承担四层负责均衡器的角色,只负责创建iptables规则。该模式的优点是较userspace模式效率更高,但不能提供灵活的LB策略,当后端Pod不可用时也无法进行重试。
(3)ipvs 模式
ipvs模式和iptables类似,kube-proxy监控Pod的变化并创建相应的ipvs规则。ipvs相对iptables转发效率更高。除此以外,ipvs支持更多的LB算法。

三、Service资源清单
kind: Service # 资源类型
apiVersion: v1 # 资源版本
metadata: # 元数据name: service # 资源名称namespace: dev # 命名空间
spec: # 描述selector: # 标签选择器,用于确定当前service代理哪些podapp: nginxtype: # Service类型,指定service的访问方式clusterIP: # 虚拟服务的ip地址sessionAffinity: # session亲和性,支持ClientIP、None两个选项ports: # 端口信息- protocol: TCP port: 3017 # service端口targetPort: 5003 # pod端口nodePort: 31122 # 主机端口(1)ClusterIP:默认值,它是Kubernetes系统自动分配的虚拟IP,只能在集群内部访问
(2)NodePort:将Service通过指定的Node上的端口暴露给外部,通过此方法,就可以在集群外部访问服务。
(3)LoadBalancer:使用外接负载均衡器完成到服务的负载分发,此模式需要外部云环境支持
(4)ExternalName: 把集群外部的服务引入集群内部,直接使用
四、Endpoint 的功能
4.1.Endpoint的作用
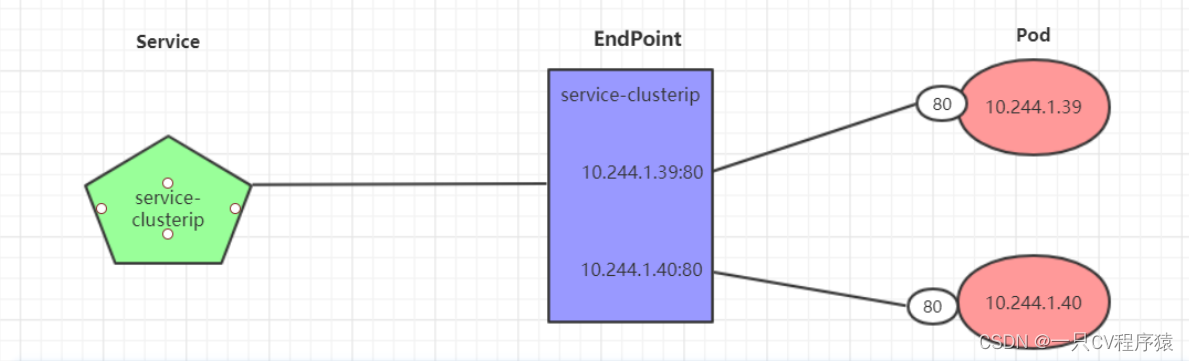
Endpoint是kubernetes中的一个资源对象,存储在etcd中,用来记录一个service对应的所有pod的访问地址,它是根据service配置文件中selector描述产生的。 一个Service由一组Pod组成,这些Pod通过Endpoints暴露出来,Endpoints是实现实际服务的端点集合。换句话说,service和pod之间的联系是通过endpoints实现的。如果 Service 中没有配 selector ,则就不会默认产生相应的 Endpoints 。
4.2.负载分发策略
Service的访问被分发到了后端的Pod上去,目前kubernetes提供了两种负载分发策略:
(1)如果不定义,默认使用kube-proxy的策略,比如随机、轮询。
(2)基于客户端地址的会话保持模式,即来自同一个客户端发起的所有请求都会转发到固定的一个Pod上。此模式可以使在spec中添加sessionAffinity:ClientIP选项
4.3.查看ipvs的映射规则:

4.4.循环访问进行测试:
 4.5.修改分发策略,在进行测试:
4.5.修改分发策略,在进行测试:
五、Service的类型
5.1.HeadLiness类型的Service
在某些场景中,开发人员可能不想使用Service提供的负载均衡功能,而希望自己来控制负载均衡策略,针对这种情况,kubernetes提供了HeadLiness Service,这类Service不会分配Cluster IP,如果想要访问service,只能通过service的域名进行查询。
创建service-headliness.yaml
apiVersion: v1
kind: Service
metadata:name: service-headlinessnamespace: dev
spec:selector:app: nginx-podclusterIP: None # 将clusterIP设置为None,即可创建headliness Servicetype: ClusterIPports:- port: 80 targetPort: 80创建对应的服务,并查询服务相关的信息:
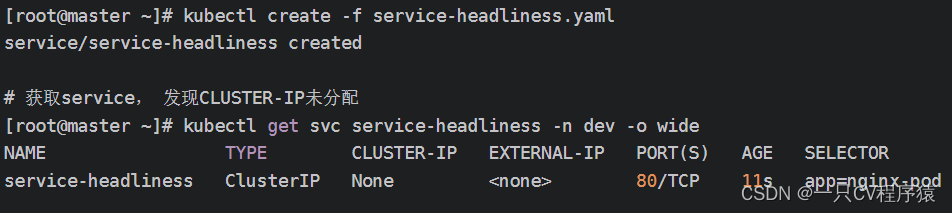
指定DNS服务器地址,解析域名获得IP:

5.2.NodePort类型的Service
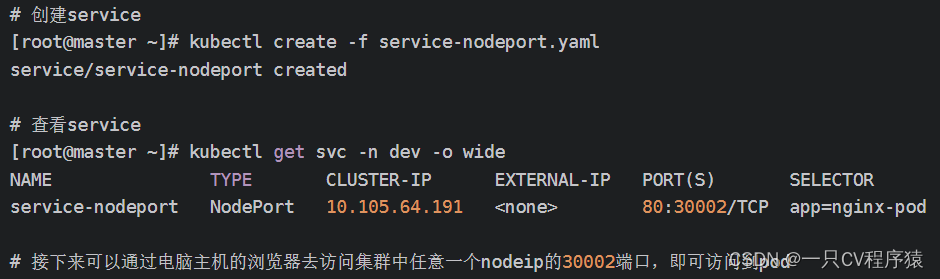
在之前的样例中,创建的Service的ip地址只有集群内部才可以访问,如果希望将Service暴露给集群外部使用,那么就要使用到另外一种类型的Service,称为NodePort类型。NodePort的工作原理其实就是将service的端口映射到Node的一个端口上,然后就可以通过NodeIp:NodePort来访问service了。
创建service-nodeport.yaml
apiVersion: v1
kind: Service
metadata:name: service-nodeportnamespace: dev
spec:selector:app: nginx-podtype: NodePort # service类型ports:- port: 80nodePort: 30002 # 指定绑定的node的端口(默认的取值范围是:30000-32767), 如果不指定,会默认分配targetPort: 80创建Service,并查看Service的详细信息:
 5.3.LoadBalancer类型的Service
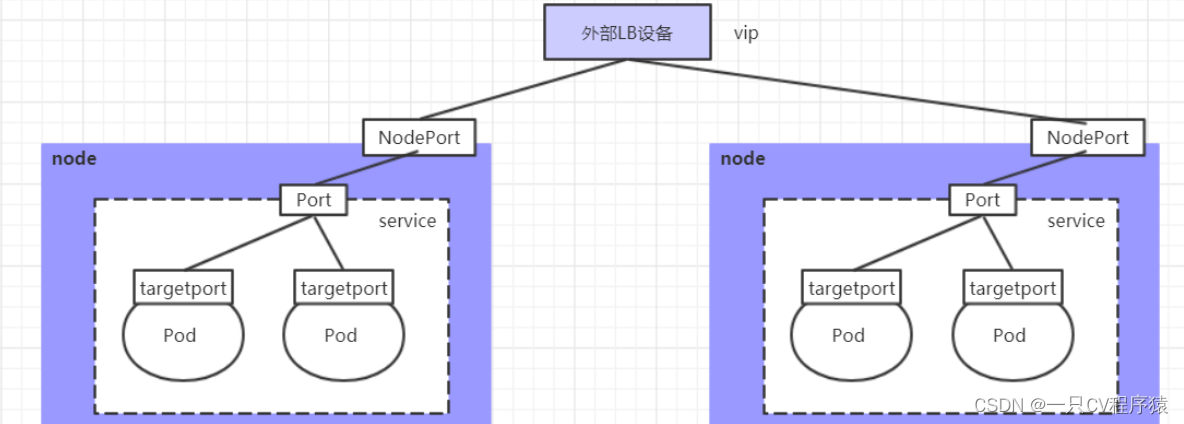
5.3.LoadBalancer类型的Service
LoadBalancer和NodePort很相似,目的都是向外部暴露一个端口,区别在于LoadBalancer会在集群的外部再来做一个负载均衡设备,而这个设备需要外部环境支持的,外部服务发送到这个设备上的请求,会被设备负载之后转发到集群中。
5.4.ExternalName类型的Service
ExternalName类型的Service用于引入集群外部的服务,它通过externalName属性指定外部一个服务的地址,然后在集群内部访问此service就可以访问到外部的服务了,他本质就是使用Service来代理外部的一个服务。

创建代理外部应用的Service的yaml文件:
apiVersion: v1
kind: Service
metadata:name: service-externalnamenamespace: dev
spec:type: ExternalName # service类型externalName: www.baidu.com #改成ip地址也可以 创建Service,使用域名解析进行验证: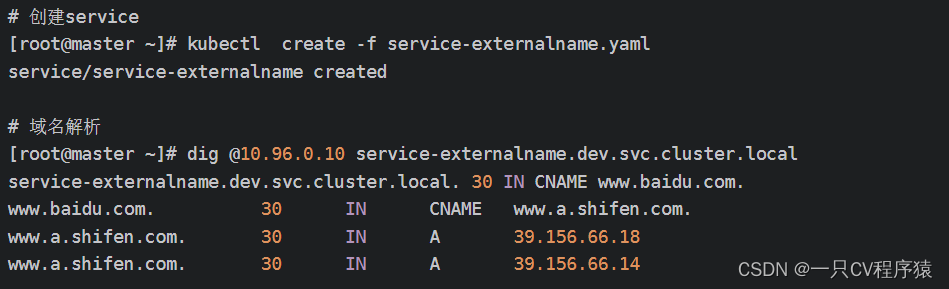
六、实验应用
4.1.利用Deployment创建出3个pod,并为pod设置app=nginx-pod的标签
apiVersion: apps/v1
kind: Deployment
metadata:name: pc-deploymentnamespace: dev
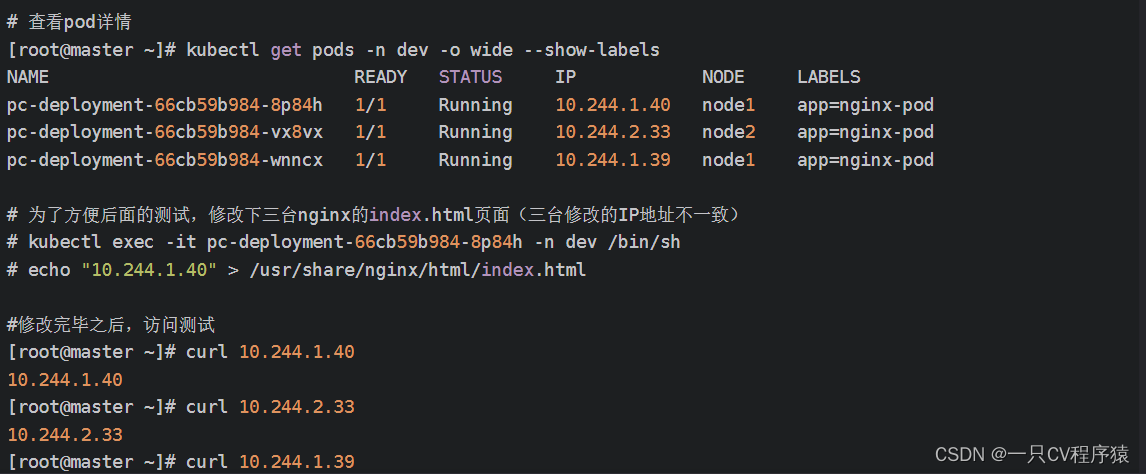
spec: replicas: 3selector:matchLabels:app: nginx-podtemplate:metadata:labels:app: nginx-podspec:containers:- name: nginximage: nginx:1.17.1ports:- containerPort: 804.2.查看Pod的详情,修改三台Pod内的nginx页面为对应的IP地址:
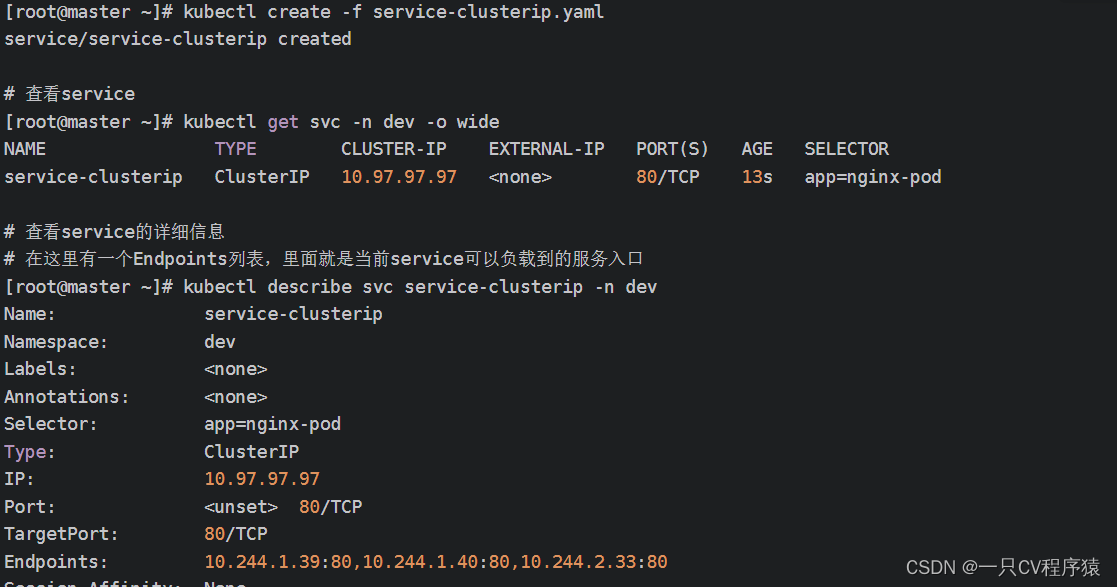
4.3.创建ClusterIP类型的Service:service-clusterip.yaml文件
apiVersion: v1
kind: Service
metadata:name: service-clusteripnamespace: dev
spec:selector:app: nginx-podclusterIP: 10.97.97.97 # service的ip地址,如果不写,默认会生成一个type: ClusterIPports:- port: 80 # Service端口 targetPort: 80 # pod端口使用yaml文件来创建service:
使用curl 访问服务的IP:

相关文章:
【云原生kubernets】Service 的功能与应用
一、Service介绍 在kubernetes中,pod是应用程序的载体,我们可以通过pod的ip来访问应用程序,但是pod的ip地址不是固定的,这也就意味着不方便直接采用pod的ip对服务进行访问。为了解决这个问题,kubernetes提供了Service资…...
docker安装Prometheus
docker安装Prometheus Docker搭建Prometheus监控系统 环境准备(这里的环境和版本是经过测试没有问题,并不是必须这个版本) 主机名IP配置系统说明localhost随意2核4gCentOS7或者Ubuntu20.0.4docker版本23.0.1或者24.0.5,docker-compose版本1.29 安装Docker Ubuntu20.0.4版本…...

了解 Flutter 3.16 功能更新
作者 / Kevin Chisholm 我们在季度 Flutter 稳定版发布会上带来了 Flutter 3.16,此版本包含诸多更新: Material 3 成为新的默认主题、为 Android 带来 Impeller 的预览版、允许添加适用于 DevTools 的扩展程序等等,以及同步推出 Flutter 休闲游戏工具包重…...

python之画动态图 gif效果图
import pandas as pd import matplotlib import matplotlib.pyplot as plt import os# set up matplotlib is_ipython inline in matplotlib.get_backend() if is_ipython:from IPython import displayplt.ion()def find_csv_files(directory):csv_files [] # 用于存储找到的…...

【JavaWeb】用注解代替配置文件
WebServlet("/query") public class QueryServlet extends HttpServlet {...}在Servlet类上写WebServlet("query"),就相当于在配置文件里写了↓ <servlet><servlet-name>query</servlet-name><servlet-class>QueryServlet</se…...

SpringBoot 3.0 升级之 Swagger 升级
文章目录 SpringFox3.0.0openapi3Swagger 注解迁移ApiApiOperationApiImplicitParamApiModelApiModelProperty 最近想尝试一下最新的 SpringBoot 项目,于是将自己的开源项目进行了一些升级。 JDK 版本从 JDK8 升级至 JDK17。SpringBoot 版本从 SpringBoot 2.7.3 升…...

AR游戏开发
增强现实(Augmented Reality,AR)游戏是一种整合了虚拟和现实元素的游戏体验。玩家通过使用AR设备(如智能手机、AR眼镜或平板电脑)来与真实世界互动,游戏中的数字内容与真实环境相结合。以下是一些关于AR游戏…...
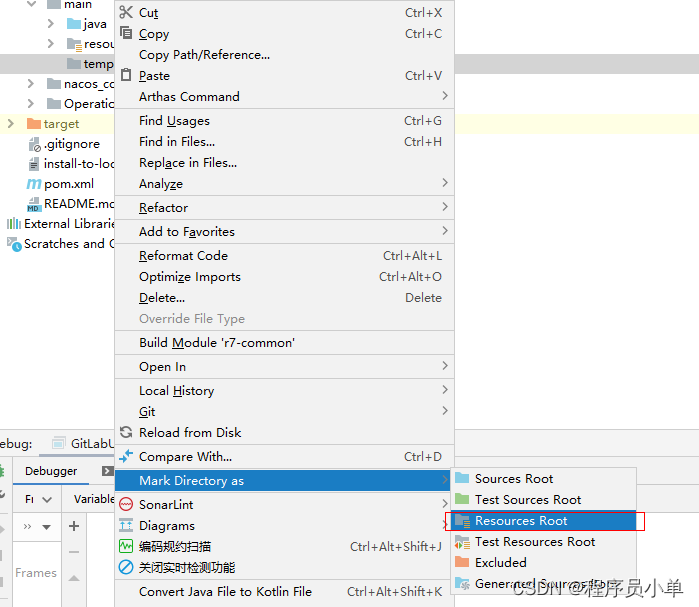
Easy Excel生成复杂下Excel模板(下拉框)给用户下载
引言 文件的下载是一个非常常见的功能,也有一些非常好的框架可以使用,这里我们就介绍一种比较常见的场景,下载Excel模版,导入功能通常会配有一个模版下载的功能,根据下载的模版,填充数据然后再上传。 需求…...
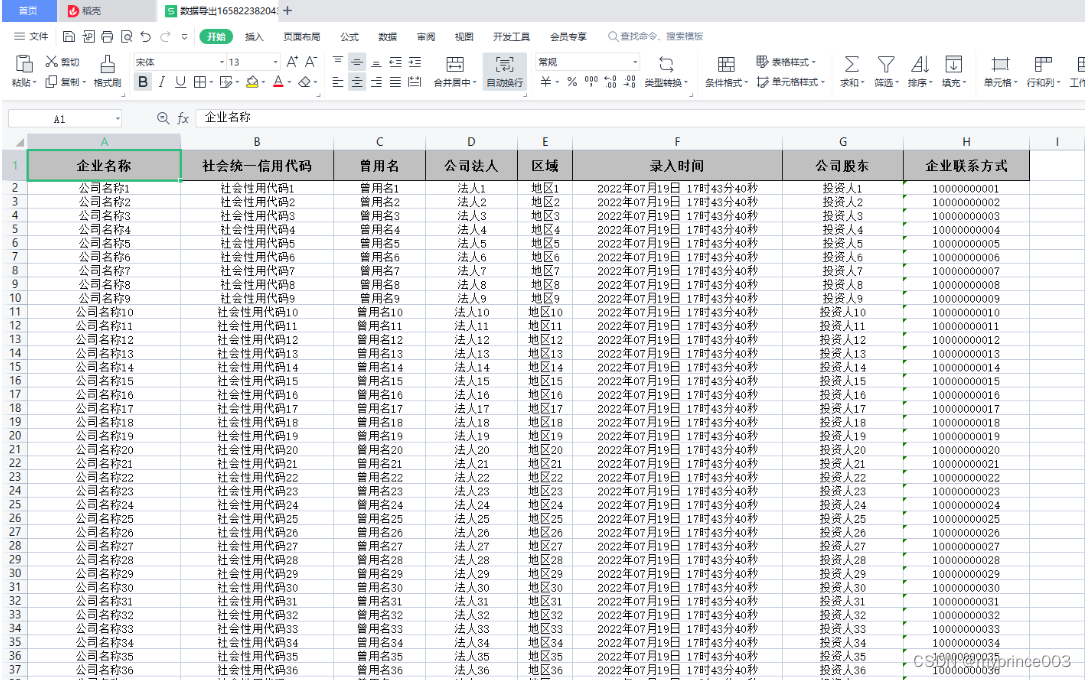
基于EasyExcel的数据导入导出
前言: 代码复制粘贴即可用,主要包含的功能有Excel模板下载、基于Excel数据导入、Excel数据导出。 根据实际情况修改一些细节即可,最后有结果展示,可以先看下结果,是否是您想要的。 台上一分钟,台下60秒&a…...

电子学会C/C++编程等级考试2021年06月(六级)真题解析
C/C++等级考试(1~8级)全部真题・点这里 第1题:逆波兰表达式 逆波兰表达式是一种把运算符前置的算术表达式,例如普通的表达式2 + 3的逆波兰表示法为+ 2 3。逆波兰表达式的优点是运算符之间不必有优先级关系,也不必用括号改变运算次序,例如(2 + 3) * 4的逆波兰表示法为* +…...
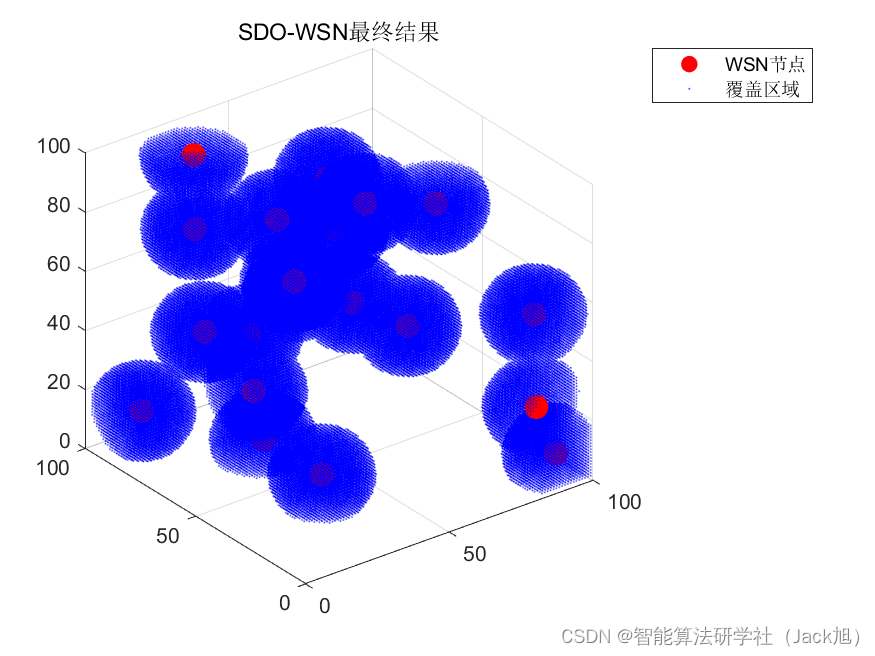
智能优化算法应用:基于供需算法3D无线传感器网络(WSN)覆盖优化 - 附代码
智能优化算法应用:基于供需算法3D无线传感器网络(WSN)覆盖优化 - 附代码 文章目录 智能优化算法应用:基于供需算法3D无线传感器网络(WSN)覆盖优化 - 附代码1.无线传感网络节点模型2.覆盖数学模型及分析3.供需算法4.实验参数设定5.算法结果6.参考文献7.MA…...

vue3 setup语法糖写法基本教程
前言 官网地址:Vue.js - 渐进式 JavaScript 框架 | Vue.js (vuejs.org)下面只讲Vue3与Vue2有差异的地方,一些相同的地方我会忽略或者一笔带过与Vue3一同出来的还有Vite,但是现在不使用它,等以后会有单独的教程使用。目前仍旧使用v…...

利用两个指针的差值求字符串长度
指针和指针也可以相加减,例如定义一个一维数组arr[10];再定义一个指针(int *p)指向数组首元素的地址,定义一个指针(int* q)指向数组最后一个元素的地址,那么q-p的结果就是整个数组的…...

ping命令的工作原理
ping,Packet Internet Groper,是一种因特网包探索器,用于测试网络连接量的程序。Ping 是工作在 TCP/IP 网络体系结构中应用层的一个服务命令, 主要是向特定的目的主机发送 ICMP(Internet Control Message Protocol 因特…...

谷歌的开源供应链安全
本内容是对Go项目负责人Russ Cox 在 ACM SCORED 活动上演讲内容[1]的摘录与整理。 SCORED 是Software Supply Chain Offensive Research and Ecosystem Defenses的简称, SCORED 23[2]于2023年11月30日在丹麦哥本哈根及远程参会形式举行。 摘要 💡 谷歌在开源软件供应…...
)
分发饼干(贪心算法)
假设你是一位很棒的家长,想要给你的孩子们一些小饼干。但是,每个孩子最多只能给一块饼干。 对每个孩子 i,都有一个胃口值 g[i],这是能让孩子们满足胃口的饼干的最小尺寸;并且每块饼干 j,都有一个尺寸 s[j]…...
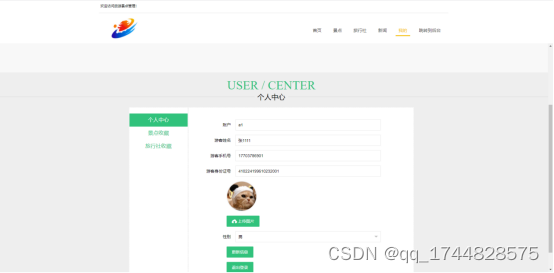
基于ssm旅游景点管理系统设计论文
摘 要 现代经济快节奏发展以及不断完善升级的信息化技术,让传统数据信息的管理升级为软件存储,归纳,集中处理数据信息的管理方式。本旅游景点管理系统就是在这样的大环境下诞生,其可以帮助管理者在短时间内处理完毕庞大的数据信息…...

用go封装一下封禁功能
思路 封禁业务也是在一般项目中比较常见的业务。我们也将它封装在库中作为功能之一。 我们同样使用adapter作为底层的存储结构,将封禁标示作为k-v结构存储。 把id和服务名称service作为key,把封禁的级别level作为value,以此我们能实现一些比…...
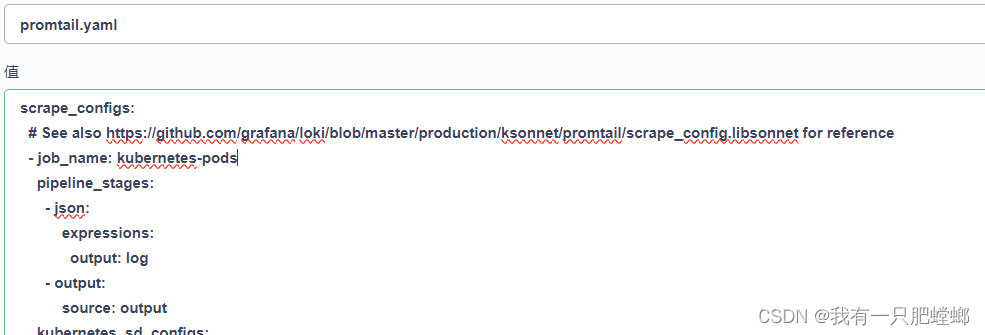
loki 如何格式化日志
部署 grafana-loki 首先介绍一下如何部署 官方文档:部署 grafana-loki 部署命令 设置集群的存储类,如果有默认可以不设置设置命名空间 helm install loki oci://registry-1.docker.io/bitnamicharts/grafana-loki --set global.storageClasslocal -n …...

在Linux上使用mysqldump备份MySQL数据库的详细步骤
MySQL数据库备份是确保数据安全性的关键步骤之一。在Linux系统上,使用mysqldump工具是一种常见、可靠的方法,它能够导出数据库的结构和数据,以便在需要时进行还原。以下是详细的备份步骤: 步骤 1:登录到MySQL服务器 …...

3个秘诀让城通网盘下载提速10倍:ctfileGet工具全解析
3个秘诀让城通网盘下载提速10倍:ctfileGet工具全解析 【免费下载链接】ctfileGet 获取城通网盘一次性直连地址 项目地址: https://gitcode.com/gh_mirrors/ct/ctfileGet ctfileGet是一款专注于获取城通网盘直连地址的开源工具,通过本地解析技术帮…...

Phi-4-mini-reasoning企业级落地:金融风控规则推理引擎构建案例
Phi-4-mini-reasoning企业级落地:金融风控规则推理引擎构建案例 1. 项目背景与模型介绍 在金融风控领域,规则推理引擎是核心决策系统的重要组成部分。传统规则引擎往往面临维护成本高、灵活性差、难以应对复杂场景等问题。Phi-4-mini-reasoning作为一款…...

Krita AI Diffusion IP-Adapter功能异常深度排查与解决方案
Krita AI Diffusion IP-Adapter功能异常深度排查与解决方案 【免费下载链接】krita-ai-diffusion Streamlined interface for generating images with AI in Krita. Inpaint and outpaint with optional text prompt, no tweaking required. 项目地址: https://gitcode.com/g…...

从仿真到实战:在CST/HFSS中如何设置周期性边界条件评估紧耦合天线阵元性能
从仿真到实战:在CST/HFSS中设置周期性边界条件评估紧耦合天线阵元性能 天线阵列设计中最具挑战性的环节之一,是如何准确预测单个阵元在阵列环境中的真实工作状态。当我在设计第一个超宽带相控阵时,曾因忽视阵元间互耦效应导致实物测试结果与仿…...

【STM32F103标准库开发】DMA+USART双剑合璧:实战环形缓冲区与空闲中断解析
1. 为什么需要DMAUSART组合方案 第一次用STM32做GPS数据采集时,我被串口中断折磨得够呛。当时用的是传统中断接收模式,每收到一个字节就触发一次中断,在115200波特率下,CPU几乎被串口中断占满,其他任务根本跑不动。后来…...

[具身智能-190]:具身智能常见的仿真平台与常见的模型算法,包括传统算法与AI算法。
在具身智能的开发中,仿真平台与模型算法是相辅相成的两个核心部分。仿真平台为算法提供了安全、高效、低成本的“练兵场”,而算法则是赋予机器人智能的“大脑”。以下为你梳理当前主流的仿真平台以及两类核心的模型算法:传统算法与AI算法。&a…...

Linux内核工程师面试高频问题解析
1. Linux内核工程师面试核心问题解析作为一名在Linux内核领域摸爬滚打多年的老手,我经历过无数次技术面试的洗礼。今天就把阿里云这类一线大厂在Linux内核工程师岗位上的高频面试题做个系统梳理,并附上我个人的解题思路和实战经验。这些题目看似基础&…...

CYBER-VISION零号协议互联网舆情智能监测与分析系统
CYBER-VISION零号协议:构建你的互联网舆情智能监测雷达 最近和几个做市场、公关的朋友聊天,他们都在抱怨同一个问题:每天花大量时间刷新闻、看社交媒体,就为了捕捉行业动态和用户反馈,生怕错过什么重要信息。人工监测…...

路由器、交换机、光猫有什么区别?网络设备基础入门
路由器、交换机、光猫有什么区别?网络设备基础入门前言一、光猫、路由器、交换机分别是干什么的二、三者最核心的区别到底是什么1.它是否直接面对运营商网络?2.它是否负责“让多台设备上网”?3.它是否主要用于扩展有线接口?三、先…...

微信小程序授权登录与权限管理的实战指南
1. 微信小程序授权登录的核心原理 微信小程序的授权登录体系是整个用户系统的基石。我第一次接触这套机制时,被它的简洁设计惊艳到了——只需要几个简单的API调用,就能建立起完整的用户身份体系。这套机制的核心在于openid,它是微信为每个用户…...