AlexNet(pytorch)
AlexNet是2012年ISLVRC 2012(ImageNet Large Scale Visual Recognition Challenge)竞赛的冠军网络,分类准确率由传统的 70%+提升到 80%+
该网络的亮点在于:
(1)首次利用 GPU 进行网络加速训练。
(2)使用了 ReLU 激活函数,而不是传统的 Sigmoid 激活函数以及 Tanh 激活函数。
(3)使用了 LRN 局部响应归一化。
(4)在全连接层的前两层中使用了 Dropout 随机失活神经元操作,以减少过拟合。
模型:
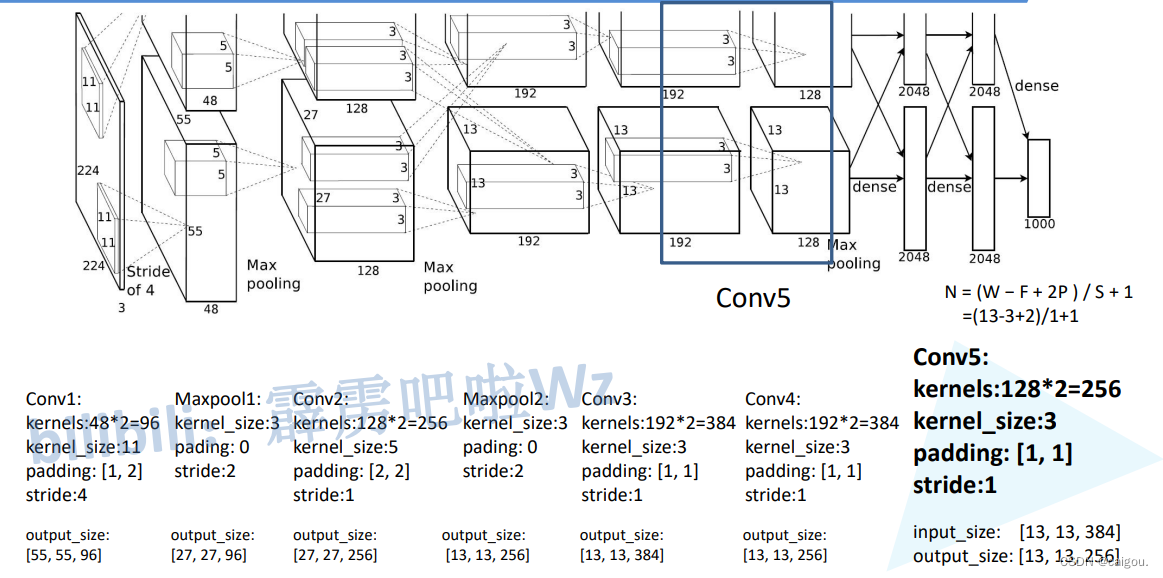
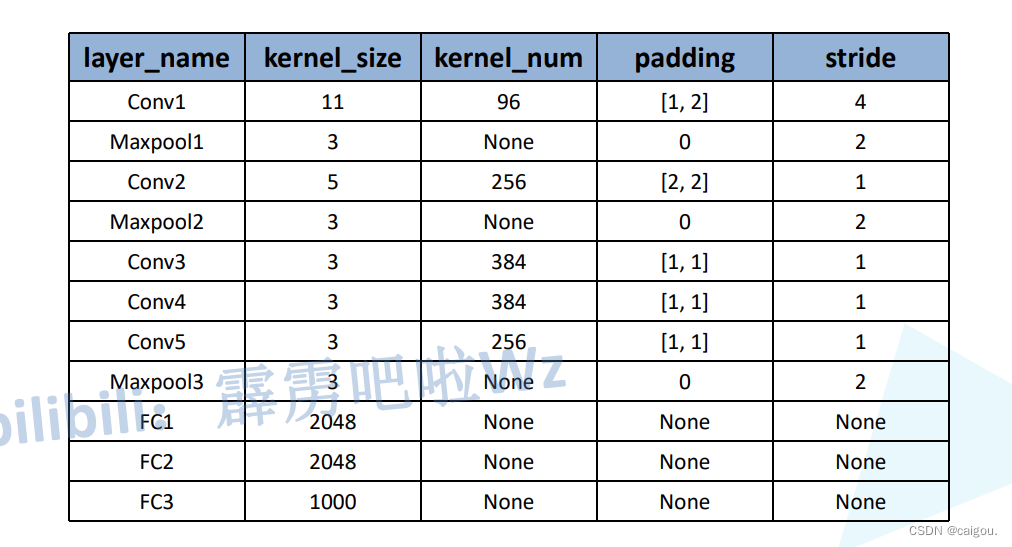
模型参数表:
model.py
import torch.nn as nn
import torchclass AlexNet(nn.Module):def __init__(self, num_classes=1000, init_weights=False):super(AlexNet, self).__init__()self.features = nn.Sequential(nn.Conv2d(3, 48, kernel_size=11, stride=4, padding=2), # input[3, 224, 224] output[48, 55, 55]nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3, stride=2), # output[48, 27, 27]: (55-3+0)/4 + 1=27nn.Conv2d(48, 128, kernel_size=5, padding=2), # output[128, 27, 27]nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 13, 13]nn.Conv2d(128, 192, kernel_size=3, padding=1), # output[192, 13, 13]nn.ReLU(inplace=True),nn.Conv2d(192, 192, kernel_size=3, padding=1), # output[192, 13, 13]nn.ReLU(inplace=True),nn.Conv2d(192, 128, kernel_size=3, padding=1), # output[128, 13, 13]nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 6, 6])self.classifier = nn.Sequential(nn.Dropout(p=0.5),nn.Linear(128 * 6 * 6, 2048),nn.ReLU(inplace=True),nn.Dropout(p=0.5),nn.Linear(2048, 2048),nn.ReLU(inplace=True),nn.Linear(2048, num_classes),)if init_weights:self._initialize_weights()def forward(self, x):x = self.features(x)x = torch.flatten(x, start_dim=1)x = self.classifier(x)return xdef _initialize_weights(self):for m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')if m.bias is not None:nn.init.constant_(m.bias, 0)elif isinstance(m, nn.Linear):nn.init.normal_(m.weight, 0, 0.01)nn.init.constant_(m.bias, 0)
train.py
import os
import sys
import jsonimport torch
import torch.nn as nn
from torchvision import transforms, datasets, utils
import matplotlib.pyplot as plt
import numpy as np
import torch.optim as optim
from tqdm import tqdmfrom model import AlexNetdef main():device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")print("using {} device.".format(device))#前期的网络还是用的Normalize标准化,之后的网络会用到BN批标准化data_transform = {"train": transforms.Compose([transforms.RandomResizedCrop(224),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),"val": transforms.Compose([transforms.Resize((224, 224)), # cannot 224, must (224, 224)transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}data_root = os.path.abspath(os.path.join(os.getcwd(), "../../")) # get data root pathimage_path = os.path.join(data_root, "data_set", "flower_data") # flower data set pathassert os.path.exists(image_path), "{} path does not exist.".format(image_path)#注意这里的数据加载还是直接用的torchvision.datasets.ImageFolder加载,#并不需要定义数据加载的脚本,可能是数据比较简单吧#定义数据集时候直接定义数据处理方法,之后torch.utils.data.DataLoader加载数据集加载时候直接调用这里定义的数据处理参数的方法#train文件夹下还有五种花的文件夹,这个具体处理看下面的代码,可能是ImageFolder直接加载文件夹里的图片文件train_dataset = datasets.ImageFolder(root=os.path.join(image_path, "train"),transform=data_transform["train"])#训练集图片的个数train_num = len(train_dataset)#train_dataset.class_to_idx 是一个字典,将类别名称映射到相应的索引。#下行注释就是flower_list具体内容# {'daisy':0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulips':4}# cla_dict是一个反转字典,将原始字典 flower_list 的键和值进行交换flower_list = train_dataset.class_to_idxcla_dict = dict((val, key) for key, val in flower_list.items())# json.dumps() 将 cla_dict 转换为格式化的 JSON 字符串。# 最后,将 JSON 字符串写入名为 class_indices.json 的文件中# indent 参数表示有几类json_str = json.dumps(cla_dict, indent=4)with open('class_indices.json', 'w') as json_file:json_file.write(json_str)batch_size = 32#这个代码片段的目的是为了确定在并行计算时使用的最大工作进程数,并确保不超过系统的逻辑 CPU 核心数量和其他限制nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workersprint('Using {} dataloader workers every process'.format(nw))train_loader = torch.utils.data.DataLoader(train_dataset,batch_size=batch_size, shuffle=True,num_workers=nw)validate_dataset = datasets.ImageFolder(root=os.path.join(image_path, "val"),transform=data_transform["val"])val_num = len(validate_dataset)validate_loader = torch.utils.data.DataLoader(validate_dataset,batch_size=4, shuffle=False,num_workers=nw)print("using {} images for training, {} images for validation.".format(train_num,val_num))# test_data_iter = iter(validate_loader)# test_image, test_label = test_data_iter.next()## def imshow(img):# img = img / 2 + 0.5 # unnormalize# npimg = img.numpy()# plt.imshow(np.transpose(npimg, (1, 2, 0)))# plt.show()## print(' '.join('%5s' % cla_dict[test_label[j].item()] for j in range(4)))# imshow(utils.make_grid(test_image))net = AlexNet(num_classes=5, init_weights=True)net.to(device)loss_function = nn.CrossEntropyLoss()# pata = list(net.parameters())optimizer = optim.Adam(net.parameters(), lr=0.0002)epochs = 10save_path = './AlexNet.pth'best_acc = 0.0#一个epoch训练多少批次的数据,一批数据32个CWH,即32张图片train_steps = len(train_loader)for epoch in range(epochs):# trainnet.train()running_loss = 0.0#这段代码使用了 tqdm 库来创建一个进度条,用于迭代训练数据集 train_loader 中的批次数据#file=sys.stdout 的作用是将进度条的输出定向到标准输出流,即将进度条显示在终端窗口中train_bar = tqdm(train_loader, file=sys.stdout)for step, data in enumerate(train_bar):images, labels = dataoptimizer.zero_grad()outputs = net(images.to(device))loss = loss_function(outputs, labels.to(device))loss.backward()optimizer.step()# print statisticsrunning_loss += loss.item()#更新进度条的描述信息,显示当前训练的轮数、总轮数和损失值#这个loss是批次损失,在进度条上显示出来train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1,epochs,loss)# 验证是训练完一个epoch后进行在验证集上验证,验证准确率net.eval()acc = 0.0 # accumulate accurate number / epochwith torch.no_grad():val_bar = tqdm(validate_loader, file=sys.stdout)for val_data in val_bar:#val_bar 的类型是 tqdm.tqdm,它是 tqdm 库中的一个类。该类提供了迭代器的功能,# 可以用于包装迭代器对象,并在循环中显示进度条和相关信息val_images, val_labels = val_dataoutputs = net(val_images.to(device)) #outputs:[batch_size,num_classes]predict_y = torch.max(outputs, dim=1)[1] #torch.max 返回的第一个元素是张量数值,第二个是对应的索引acc += torch.eq(predict_y, val_labels.to(device)).sum().item()#验证完后计算验证集里所有的正确个数/总个数val_accurate = acc / val_num#总损失/训练总批次,求得平均每批的损失print('[epoch %d] train_loss: %.3f val_accuracy: %.3f' %(epoch + 1, running_loss / train_steps, val_accurate))if val_accurate > best_acc:best_acc = val_accuratetorch.save(net.state_dict(), save_path)print('Finished Training')if __name__ == '__main__':main()
训练过程:
using cuda:0 device.
Using 8 dataloader workers every process
using 3306 images for training, 364 images for validation.
train epoch[1/10] loss:1.215: 100%|██████████| 104/104 [00:23<00:00, 4.38it/s]
100%|██████████| 91/91 [00:15<00:00, 5.73it/s]
[epoch 1] train_loss: 1.342 val_accuracy: 0.478
train epoch[2/10] loss:1.111: 100%|██████████| 104/104 [00:19<00:00, 5.30it/s]
100%|██████████| 91/91 [00:15<00:00, 5.75it/s]
[epoch 2] train_loss: 1.183 val_accuracy: 0.533
train epoch[3/10] loss:1.252: 100%|██████████| 104/104 [00:19<00:00, 5.30it/s]
100%|██████████| 91/91 [00:15<00:00, 5.75it/s]
[epoch 3] train_loss: 1.097 val_accuracy: 0.604
train epoch[4/10] loss:0.730: 100%|██████████| 104/104 [00:19<00:00, 5.32it/s]
100%|██████████| 91/91 [00:15<00:00, 5.74it/s]
[epoch 4] train_loss: 1.025 val_accuracy: 0.607
train epoch[5/10] loss:0.961: 100%|██████████| 104/104 [00:19<00:00, 5.28it/s]
100%|██████████| 91/91 [00:16<00:00, 5.65it/s]
[epoch 5] train_loss: 0.941 val_accuracy: 0.676
train epoch[6/10] loss:0.853: 100%|██████████| 104/104 [00:19<00:00, 5.31it/s]
100%|██████████| 91/91 [00:15<00:00, 5.82it/s]
[epoch 6] train_loss: 0.915 val_accuracy: 0.659
train epoch[7/10] loss:1.032: 100%|██████████| 104/104 [00:19<00:00, 5.34it/s]
100%|██████████| 91/91 [00:15<00:00, 5.82it/s]
[epoch 7] train_loss: 0.864 val_accuracy: 0.684
train epoch[8/10] loss:0.704: 100%|██████████| 104/104 [00:19<00:00, 5.32it/s]
100%|██████████| 91/91 [00:15<00:00, 5.80it/s]
[epoch 8] train_loss: 0.842 val_accuracy: 0.706
train epoch[9/10] loss:1.279: 100%|██████████| 104/104 [00:19<00:00, 5.30it/s]
100%|██████████| 91/91 [00:15<00:00, 5.83it/s]
[epoch 9] train_loss: 0.825 val_accuracy: 0.714
train epoch[10/10] loss:0.796: 100%|██████████| 104/104 [00:19<00:00, 5.31it/s]
100%|██████████| 91/91 [00:15<00:00, 5.82it/s]
[epoch 10] train_loss: 0.801 val_accuracy: 0.703
Finished TrainingProcess finished with exit code 0predict.py:
import os
import jsonimport torch
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as pltfrom model import AlexNetdef main():device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")data_transform = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])# load imageimg_path = "./test.jpg"assert os.path.exists(img_path), "file: '{}' dose not exist.".format(img_path)img = Image.open(img_path)plt.imshow(img)# [N, C, H, W]img = data_transform(img)# expand batch dimensionimg = torch.unsqueeze(img, dim=0)# read class_indictjson_path = './class_indices.json'assert os.path.exists(json_path), "file: '{}' dose not exist.".format(json_path)with open(json_path, "r") as f:class_indict = json.load(f)# create modelmodel = AlexNet(num_classes=5).to(device)# load model weightsweights_path = "./AlexNet.pth"assert os.path.exists(weights_path), "file: '{}' dose not exist.".format(weights_path)#torch.load() 函数会根据路径加载模型的权重,并返回一个包含模型参数的字典#load_state_dict() 函数将加载的模型参数字典应用到 model 中,从而将预训练模型的参数加载到 model 中model.load_state_dict(torch.load(weights_path))model.eval()with torch.no_grad():# predict classoutput = torch.squeeze(model(img.to(device))).cpu()predict = torch.softmax(output, dim=0)predict_cla = torch.argmax(predict).numpy()print_res = "class: {} prob: {:.3}".format(class_indict[str(predict_cla)],predict[predict_cla].numpy())plt.title(print_res)for i in range(len(predict)):print("class: {:10} prob: {:.3}".format(class_indict[str(i)],predict[i].numpy()))plt.show()if __name__ == '__main__':main()
预测结果:
我感觉pycharm的plt显示并不是特别明了
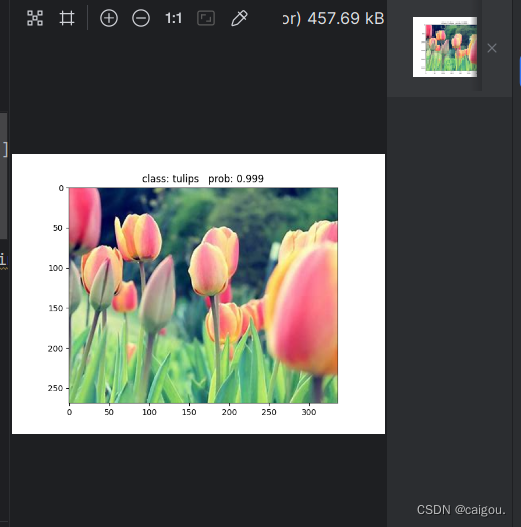
class: daisy prob: 4.2e-06
class: dandelion prob: 9.61e-07
class: roses prob: 0.000773
class: sunflowers prob: 1.28e-05
class: tulips prob: 0.999相关文章:
AlexNet(pytorch)
AlexNet是2012年ISLVRC 2012(ImageNet Large Scale Visual Recognition Challenge)竞赛的冠军网络,分类准确率由传统的 70%提升到 80% 该网络的亮点在于: (1)首次利用 GPU 进行网络加速训练。 ÿ…...

【单调栈 】LeetCode321:拼接最大数
作者推荐 【动态规划】【广度优先搜索】LeetCode:2617 网格图中最少访问的格子数 本文涉及的知识点 单调栈 题目 给定长度分别为 m 和 n 的两个数组,其元素由 0-9 构成,表示两个自然数各位上的数字。现在从这两个数组中选出 k (k < m n) 个数字…...

TikTok与虚拟现实的完美交融:全新娱乐时代的开启
TikTok,这个风靡全球的短视频平台,与虚拟现实(VR)技术的深度结合,为用户呈现了一场全新的娱乐盛宴。虚拟现实技术为TikTok带来了更丰富、更沉浸的用户体验,标志着全新娱乐时代的开启。本文将深入探讨TikTok…...

PXI/PCIe/VPX机箱 ARM|x86 + FPGA测试测量板卡解决方案
PXI便携式测控系统是一种基于PXI总线的便携式测试测控系统,它填补了现有台式及机架式仪器在外场测控和便携测控应用上的空白,在军工国防、航空航天、兵器电子、船舶舰载等各个领域的外场测控场合和科学试验研究场合都有广泛的应用。由于PXI便携式测控系统…...

ES6 面试题 | 12.精选 ES6 面试题
🤍 前端开发工程师(主业)、技术博主(副业)、已过CET6 🍨 阿珊和她的猫_CSDN个人主页 🕠 牛客高级专题作者、在牛客打造高质量专栏《前端面试必备》 🍚 蓝桥云课签约作者、已在蓝桥云…...

【linux】Debian不能运行sudo的解决
一、问题: sudo: 没有找到有效的 sudoers 资源,退出 sudo: 初始化审计插件 sudoers_audit 出错 二、可用的方法: 出现 "sudo: 没有找到有效的 sudoers 资源,退出" 和 "sudo: 初始化审计插件 sudoers_audit 出错&q…...

讲解ThinkPHP的链式操作
数据库提供的链式操作方法,可以有效的提高数据存取的代码清晰度和开发效率,并且支持所有的CURD操作。 使用也比较简单,假如我们现在要查询一个User表的满足状态为1的前10条记录,并希望按照用户的创建时间排序 Db::table(think_u…...
Java技术栈 —— 微服务框架Spring Cloud —— Ruoyi-Cloud 学习(二)
RuoYi项目开发过程 一、登录功能(鉴权模块)1.1 后端部分1.1.1 什么是JWT?1.1.2 什么是Base64?为什么需要它?1.1.3 SpringBoot注解解析1.1.4 依赖注入和控制反转1.1.5 什么是Restful?1.1.6 Log4j 2、Logpack、SLF4j日志框架1.1.7 如何将项目打包成指定bytecode字节…...
?)
如何进行软件测试和测试驱动开发(TDD)?
1. 软件测试概述 1.1 什么是软件测试? 软件测试是一种评估系统的过程,目的是发现潜在的错误或缺陷。通过对软件进行测试,开发者和测试人员可以确定软件是否符合预期的需求、功能是否正常运行,以及系统是否足够稳定和可靠。 1.2…...
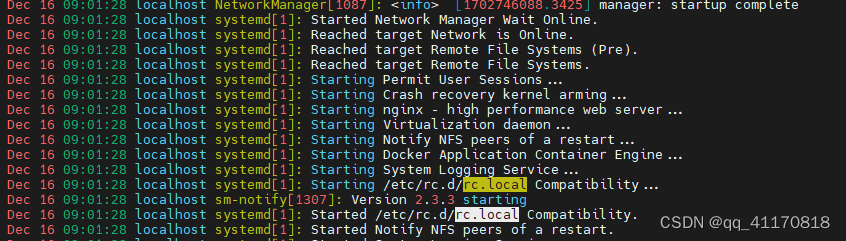
linux 开机启动流程
1.打开电源 2.BIOS 有时间和启动方式 3.启动Systemd 其pid为1 4.挂载引导分区 /boot 5.启动各种服务 如rc.local...
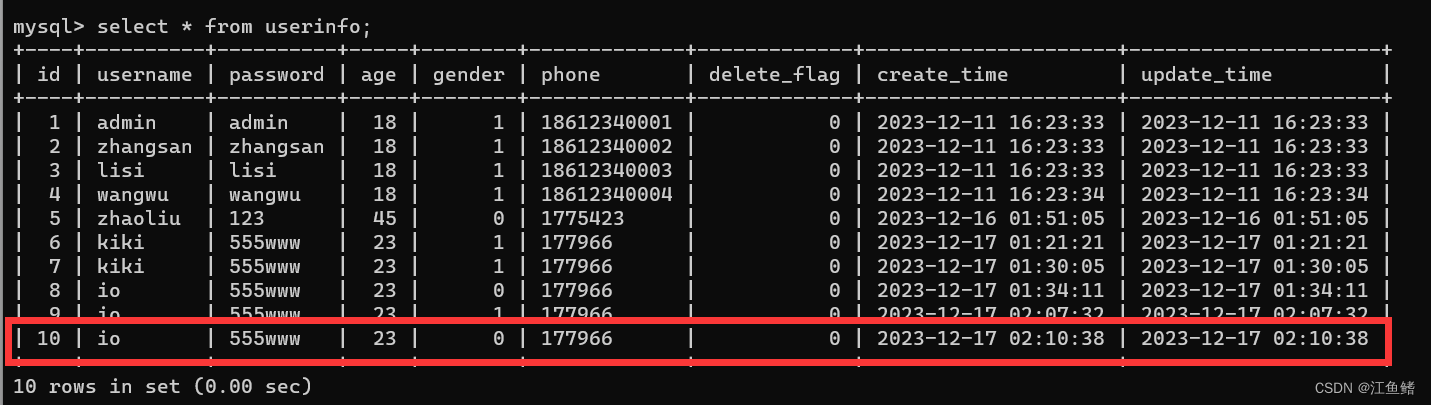
Mybatis 动态SQL的插入操作
需求 : 根据用户的输入情况进行插入 动态SQL:根据需求动态拼接SQL 用户往表中插入数据,有的数据可能不想插入,比如不想让别人知道自己的性别,性别就为空 insert into userinfo(username,password,age,gender,phone) values(?,?,?,?,?); insert into userinfo(username,…...

共建开源新里程:北京航空航天大学OpenHarmony技术俱乐部正式揭牌成立
12月11日,由OpenAtom OpenHarmony(以下简称“OpenHarmony”)项目群技术指导委员会(以下简称“TSC”)和北京航空航天大学共同举办的“OpenHarmony软件工程研讨会暨北京航空航天大学OpenHarmony技术俱乐部成立仪式”在京圆满落幕。 现场大合影 活动当天,多位重量级嘉宾出席了此次…...

企业微信机器人发送文本、图片、文件、markdown、图文信息
import requests import base64 import hashlib import json # 机器人地址的key值 key"811a1652-60e8-4f51-a1d9-231783399ad2" def path2base64(path):"""文件转换为base64:param path: 文件路径:return:"""with open(path, "rb…...

智能优化算法应用:基于天牛须算法3D无线传感器网络(WSN)覆盖优化 - 附代码
智能优化算法应用:基于天牛须算法3D无线传感器网络(WSN)覆盖优化 - 附代码 文章目录 智能优化算法应用:基于天牛须算法3D无线传感器网络(WSN)覆盖优化 - 附代码1.无线传感网络节点模型2.覆盖数学模型及分析3.天牛须算法4.实验参数设定5.算法结果6.参考文…...

【Hive】【Hadoop】工作中常操作的笔记-随时添加
文章目录 1、Hive 复制一个表:2、字段级操作3、hdfs 文件统计 1、Hive 复制一个表: 直接Copy文件 create table new_table like table_name;hdfs dfs -get /apps/hive/warehouse/ods.db/table_nameload data local inpath /路径 into table new_table;修复表: m…...

DIY电脑装机机箱风扇安装方法
作为第一次自己diy一台电脑主机的我,在经历了众多的坑中今天来说一下如何安装机箱风扇的问题 一、风扇的数量 1、i3 xx50显卡 就用一个cpu散热风扇即可 2、i5 xx60 一个cpu散热风扇 一个风扇即可 3、i7 xx70 一个cpu散热 4个风扇即可 4、i9 xx80 就需要7个以…...

基础算法(4):排序(4)冒泡排序
1.冒泡排序(BubbleSort)实现 算法步骤:比较相邻的元素。如果第一个比第二个大,就交换。 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。 这步做完后,最后的元素会是最大的数。 针对所有的元素重复以上的步骤&#…...

鸿蒙开发之网络请求
//需要导入http头文件 import http from ohos.net.http//请求地址url: string http://apis.juhe.cn/simpleWeather/queryText(this.message).maxFontSize(50).minFontSize(10).fontWeight(FontWeight.Bold).onClick(() > {console.log(请求开始)let req http.createHttp()…...
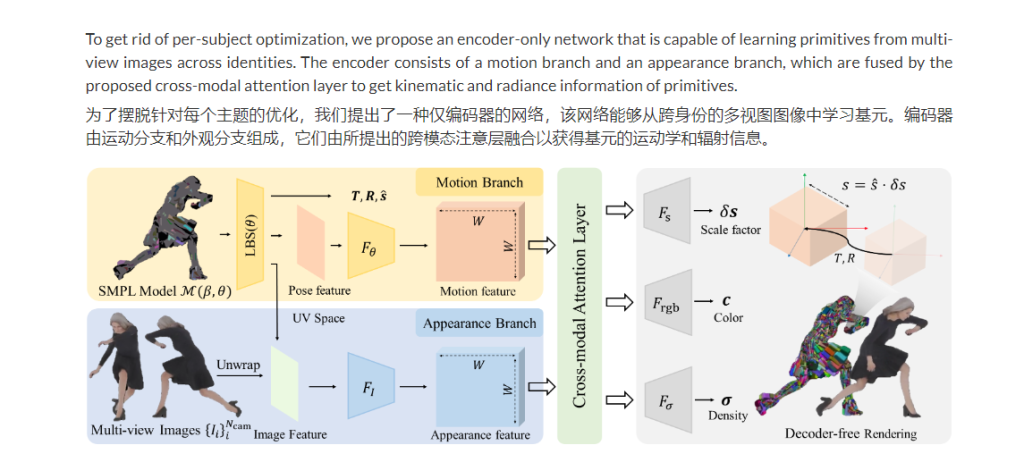
PrimDiffusion:3D 人类生成的体积基元扩散模型NeurIPS 2023
NeurIPS2023 ,这是一种用于 3D 人体生成的体积基元扩散模型,可通过离体拓扑实现明确的姿势、视图和形状控制。 PrimDiffusion 对一组紧凑地代表 3D 人体的基元执行扩散和去噪过程。这种生成建模可以实现明确的姿势、视图和形状控制,并能够在…...
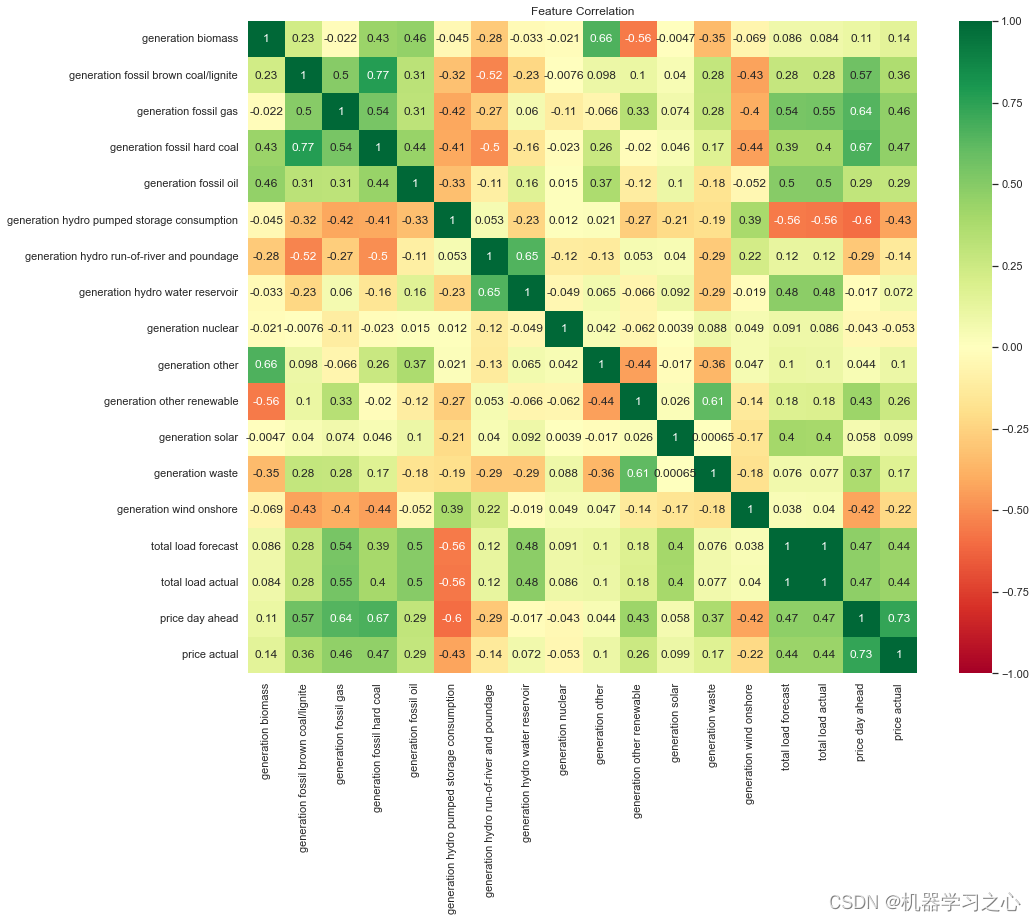
时序预测 | Python实现LSTM-Attention-XGBoost组合模型电力需求预测
时序预测 | Python实现LSTM-Attention-XGBoost组合模型电力需求预测 目录 时序预测 | Python实现LSTM-Attention-XGBoost组合模型电力需求预测预测效果基本描述程序设计参考资料预测效果 基本描述 该数据集因其每小时的用电量数据以及 TSO 对消耗和定价的相应预测而值得注意,从…...

量子网络模拟器SeQUeNCe的并行化设计与性能优化
1. 量子网络模拟的工程挑战与SeQUeNCe的定位量子网络正逐步从理论走向工程实践,其核心价值在于利用量子纠缠特性实现传统通信无法企及的安全性和计算能力。但在实际部署前,工程师们面临一个关键问题:如何验证包含数百个量子节点的网络设计方案…...

从零构建企业级API客户端:设计模式、类型安全与工程实践
1. 项目概述与核心价值最近在对接一个名为“Seedance2”的第三方API服务时,我遇到了一个不大不小的麻烦。这个服务本身功能强大,提供了从数据同步、事件处理到复杂业务逻辑编排等一系列能力,但它的官方SDK要么文档语焉不详,要么在…...
)
手把手教你用PyTorch 0.4.1复现D-LinkNet道路分割(附完整代码与数据集)
从零复现D-LinkNet道路分割:PyTorch 0.4.1实战指南 当你在GitHub上发现一个两年前的热门道路分割项目D-LinkNet,却发现它依赖PyTorch 0.4.1和CUDA 8.0这种"古董级"环境时,是否感到无从下手?本文将带你穿越时空…...

FPGA阵列信号处理矩阵算子高性能实现【附代码】
✨ 长期致力于自动驾驶、阵列信号处理、矩阵特征值分解、Jacobi旋转、三角矩阵求逆、序列排序、序列部分排序研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1&…...

理想汽车AI组织架构重组
把公司拆成心脏、大脑和手脚——理想汽车这波AI组织架构重组到底在赌什么? 导读:李想用一场2小时的全员会,把一家年营收千亿的公司按人体器官逻辑重新组装。这不是比喻,这是组织结构图上的真实节点。从造车到"造人"&…...

如何让PT下载像点外卖一样简单?3个场景教你玩转PT-Plugin-Plus
如何让PT下载像点外卖一样简单?3个场景教你玩转PT-Plugin-Plus 【免费下载链接】PT-Plugin-Plus PT 助手 Plus,为 Microsoft Edge、Google Chrome、Firefox 浏览器插件(Web Extensions),主要用于辅助下载 PT 站的种子。…...

计算机专业不想“敲代码”,都来冲这个行业
计算机专业不想“敲代码”,都来冲这个行业 在这个信息爆炸的时代,计算机专业作为热门选择之一,吸引了无数学子的目光。但与此同时,也有相当一部分同学心存疑虑:自己是计算机专业的,却对写代码提不起兴趣&a…...

扰动补偿自触发MPC控制器设计【附代码】
✨ 长期致力于永磁同步电机、模型预测控制、扰动补偿、死区时间优化、自触发控制研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)基于预测误差驱动的扰…...

ARM设备运行x86_64程序:Box64高效兼容方案深度解析
ARM设备运行x86_64程序:Box64高效兼容方案深度解析 【免费下载链接】box64 Box64 - Linux Userspace x86_64 Emulator with a twist, targeted at ARM64, RV64 and LoongArch Linux devices 项目地址: https://gitcode.com/gh_mirrors/bo/box64 你是否曾在AR…...

收藏!2026大厂AI招聘火爆:日薪5000抢博士,普通岗简历石沉大海?小白程序员必看生存指南
2026年大厂招聘季AI岗位需求暴涨215%,字节日薪5000抢清北博士,阿里AI岗占offer六成。AI核心岗位年薪可达百万,供需比仅0.15。非AI岗位受冲击,但AIGC产品经理、AI运营等潜力岗位升温。求职者需注重顶会论文、开源贡献等加分项&…...