【Spark精讲】Spark存储原理
目录
类比HDFS的存储架构
Spark的存储架构
存储级别
RDD的持久化机制
RDD缓存的过程
Block淘汰和落盘
类比HDFS的存储架构
HDFS集群有两类节点以管理节点-工作节点模式运行,即一个NameNode(管理节点)和多个DataNode(工作节点)。
- Namenode管理文件系统的命名空间。它维护着文件系统树及整棵树内的所有文件和目录。这些信息以两个文件形式永久保存在本地磁盘上:命名空间镜像文件和编辑日志文件。Namenode也记录着每个文件中各个块所在的数据节点信息,但是它并不会永久保存块的位置信息,因为这些信息会在系统启动时根据数据节点信息重建。
- DataNode负责数据块的读写操作。DataNode在存储数据的时候是按照block为单位读写数据的。block是hdfs读写数据的基本单位。 一个数据块在datanode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳。

Spark的存储架构
Spark的存储模块类似HDFS的架构,分为BlockManager和BlockManagerMaster。
BlockManager负责本节点的数据块的读写操作。BlockManagerMaster负责记录每个节点的元数据信息,如每个数据块都存在于哪些节点上。BlockManager也可以接收BlockManagerMaster发来的信息对本节点的数据进行删除等操作。
BlockManager和BlockManagerMaster之间通过RPC的Endpoint通信。BlockManagerMaster只存在于Driver节点中,BlockManager存在于Driver节点和每个Executor节点。每个Executor中有且仅有一个BlockManager。
Spark将存储的数据进行抽象,每个存储的数据都称为一个Block,每个Block都对应着唯一的id,称为BlockId。在BlockManager中,对数据进行读写都是根据BlockId进行的。如果某个BlockManager中存储了一份数据,BlockManager会将该数据的BlockId和数据的存储状态(BlockStatus)发送至BlockManagerMaster中,从而BlockManagerMaster中即可知道每个BlockId对应的数据都存放在哪些节点中。此外BlockManagerMaster还记录了同一个BlockId都在哪些节点上进行了存储。其中存储的位置信息是使用BlockManagerId表示的,因为根据BlockManagerId即可找到相应的BlockManager。

根据存储的数据分类的不同,使用不同类型的BlockId进行表示:
- RDDBlockId:存储RDD某个分区数据,根据RDD的id和分区来确定唯一值。
- ShuffleBlockId:存储Shuffle过程Map端生成的数据,使用ShuffleId、Map端分区、Reduce端分区确定唯一值。
- BroadcastBlockId:存储广播变量数据。
- TaskResultBlockId:存储Task结果。
存储级别
对于同一个Block而已,存到内存还是磁盘只能二居其一,对于RDD而言,由于存在多个分区,缓存时会产生多个Block,有可能有的在内存有的在磁盘。
- NONE
- DISK_ONLY
- MEMORY_ONLY
- MEMORY_ONLY_2
- MEMORY_ONLY_SER
- MEMORY_AND_DISK
- MEMORY_AND_DISK_SER
- OFF_HEAP
RDD的持久化机制
弹性分布式数据集(RDD)作为 Spark 最根本的数据抽象,是只读的分区记录(Partition)的集合,只能基于在稳定物理存储中的数据集上创建,或者在其他已有的 RDD 上执行转换(Transformation)操作产生一个新的 RDD。转换后的 RDD 与原始的 RDD 之间产生的依赖关系,构成了血统(Lineage)。凭借血统,Spark 保证了每一个 RDD 都可以被重新恢复。但 RDD 的所有转换都是惰性的,即只有当一个返回结果给 Driver 的行动(Action)发生时,Spark 才会创建任务读取 RDD,然后真正触发转换的执行。
Task 在启动之初读取一个分区时,会先判断这个分区是否已经被持久化,如果没有则需要检查 Checkpoint 或按照血统重新计算。所以如果一个 RDD 上要执行多次行动,可以在第一次行动中使用 persist 或 cache 方法,在内存或磁盘中持久化或缓存这个 RDD,从而在后面的行动时提升计算速度。事实上,cache 方法是使用默认的 MEMORY_ONLY 的存储级别将 RDD 持久化到内存,故缓存是一种特殊的持久化。 堆内和堆外存储内存的设计,便可以对缓存 RDD 时使用的内存做统一的规划和管理 (存储内存的其他应用场景,如缓存 broadcast 数据,暂时不在此讨论范围之内)。
RDD 的持久化由 Spark 的 Storage 模块负责,实现了 RDD 与物理存储的解耦合。Storage 模块负责管理 Spark 在计算过程中产生的数据,将那些在内存或磁盘、在本地或远程存取数据的功能封装了起来。在具体实现时 Driver 端和 Executor 端的 Storage 模块构成了主从式的架构,即 Driver 端的 BlockManager 为 Master,Executor 端的 BlockManager 为 Slave。Storage 模块在逻辑上以 Block 为基本存储单位,RDD 的每个 Partition 经过处理后唯一对应一个 Block(BlockId 的格式为 rdd_RDD-ID_PARTITION-ID )。Master 负责整个 Spark 应用程序的 Block 的元数据信息的管理和维护,而 Slave 需要将 Block 的更新等状态上报到 Master,同时接收 Master 的命令,例如新增或删除一个 RDD。
Storage 模块示意图:

在对 RDD 持久化时,Spark 规定了 MEMORY_ONLY、MEMORY_AND_DISK 等 7 种不同的存储级别 ,而存储级别是以下 5 个变量的组合:
class StorageLevel private(
private var _useDisk: Boolean, //磁盘
private var _useMemory: Boolean, //这里其实是指堆内内存
private var _useOffHeap: Boolean, //堆外内存
private var _deserialized: Boolean, //是否为非序列化
private var _replication: Int = 1 //副本个数
)
通过对数据结构的分析,可以看出存储级别从三个维度定义了 RDD 的 Partition(同时也就是 Block)的存储方式:
- 存储位置:磁盘/堆内内存/堆外内存。如 MEMORY_AND_DISK 是同时在磁盘和堆内内存上存储,实现了冗余备份。OFF_HEAP 则是只在堆外内存存储,目前选择堆外内存时不能同时存储到其他位置。
- 存储形式:Block 缓存到存储内存后,是否为非序列化的形式。如 MEMORY_ONLY 是非序列化方式存储,OFF_HEAP 是序列化方式存储。
- 副本数量:大于 1 时需要远程冗余备份到其他节点。如 DISK_ONLY_2 需要远程备份 1 个副本。
RDD缓存的过程
RDD 在缓存到存储内存之前,Partition 中的数据一般以迭代器(Iterator)的数据结构来访问,这是 Scala 语言中一种遍历数据集合的方法。通过 Iterator 可以获取分区中每一条序列化或者非序列化的数据项(Record),这些 Record 的对象实例在逻辑上占用了 JVM 堆内内存的 other 部分的空间,同一 Partition 的不同 Record 的空间并不连续。
RDD 在缓存到存储内存之后,Partition 被转换成 Block,Record 在堆内或堆外存储内存中占用一块连续的空间。将Partition由不连续的存储空间转换为连续存储空间的过程,Spark称之为"展开"(Unroll)。Block 有序列化和非序列化两种存储格式,具体以哪种方式取决于该 RDD 的存储级别。非序列化的 Block 以一种 DeserializedMemoryEntry 的数据结构定义,用一个数组存储所有的对象实例,序列化的 Block 则以 SerializedMemoryEntry的数据结构定义,用字节缓冲区(ByteBuffer)来存储二进制数据。每个 Executor 的 Storage 模块用一个链式 Map 结构(LinkedHashMap)来管理堆内和堆外存储内存中所有的 Block 对象的实例,对这个 LinkedHashMap 新增和删除间接记录了内存的申请和释放。
因为不能保证存储空间可以一次容纳 Iterator 中的所有数据,当前的计算任务在 Unroll 时要向 MemoryManager 申请足够的 Unroll 空间来临时占位,空间不足则 Unroll 失败,空间足够时可以继续进行。对于序列化的 Partition,其所需的 Unroll 空间可以直接累加计算,一次申请。而非序列化的 Partition 则要在遍历 Record 的过程中依次申请,即每读取一条 Record,采样估算其所需的 Unroll 空间并进行申请,空间不足时可以中断,释放已占用的 Unroll 空间。如果最终 Unroll 成功,当前 Partition 所占用的 Unroll 空间被转换为正常的缓存 RDD 的存储空间,如下图所示。
Spark Unroll 示意图:
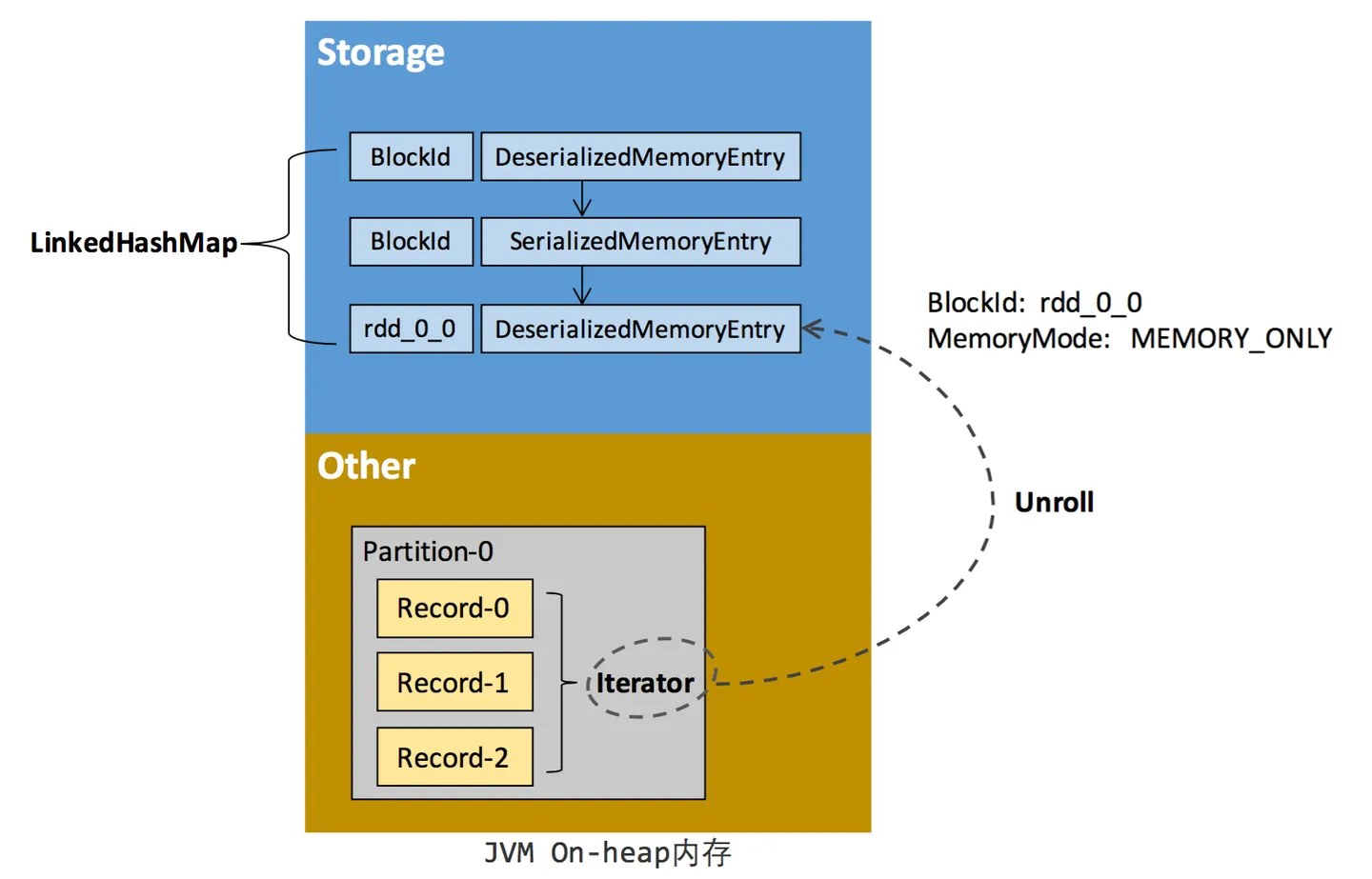
在上篇的静态内存管理小节可以看到,在静态内存管理时,Spark 在存储内存中专门划分了一块 Unroll 空间,其大小是固定的,统一内存管理时则没有对 Unroll 空间进行特别区分,当存储空间不足时会根据动态占用机制进行处理。
Block淘汰和落盘
由于同一个 Executor 的所有的计算任务共享有限的存储内存空间,当有新的 Block 需要缓存但是剩余空间不足且无法动态占用时,就要对 LinkedHashMap 中的旧 Block 进行淘汰(Eviction),而被淘汰的 Block 如果其存储级别中同时包含存储到磁盘的要求,则要对其进行落盘(Drop),否则直接删除该 Block。
存储内存的淘汰规则为:
- 被淘汰的旧 Block 要与新 Block 的 MemoryMode 相同,即同属于堆外或堆内内存
- 新旧 Block 不能属于同一个 RDD,避免循环淘汰
- 旧 Block 所属 RDD 不能处于被读状态,避免引发一致性问题
- 遍历 LinkedHashMap 中 Block,按照最近最少使用(LRU)的顺序淘汰,直到满足新 Block 所需的空间。其中 LRU 是 LinkedHashMap 的特性。
- 落盘的流程则比较简单,如果其存储级别符合_useDisk 为 true 的条件,再根据其_deserialized 判断是否是非序列化的形式,若是则对其进行序列化,最后将数据存储到磁盘,在 Storage 模块中更新其信息。
相关文章:
【Spark精讲】Spark存储原理
目录 类比HDFS的存储架构 Spark的存储架构 存储级别 RDD的持久化机制 RDD缓存的过程 Block淘汰和落盘 类比HDFS的存储架构 HDFS集群有两类节点以管理节点-工作节点模式运行,即一个NameNode(管理节点)和多个DataNode(工作节点)。 Namenode管理文件系统的命名空…...
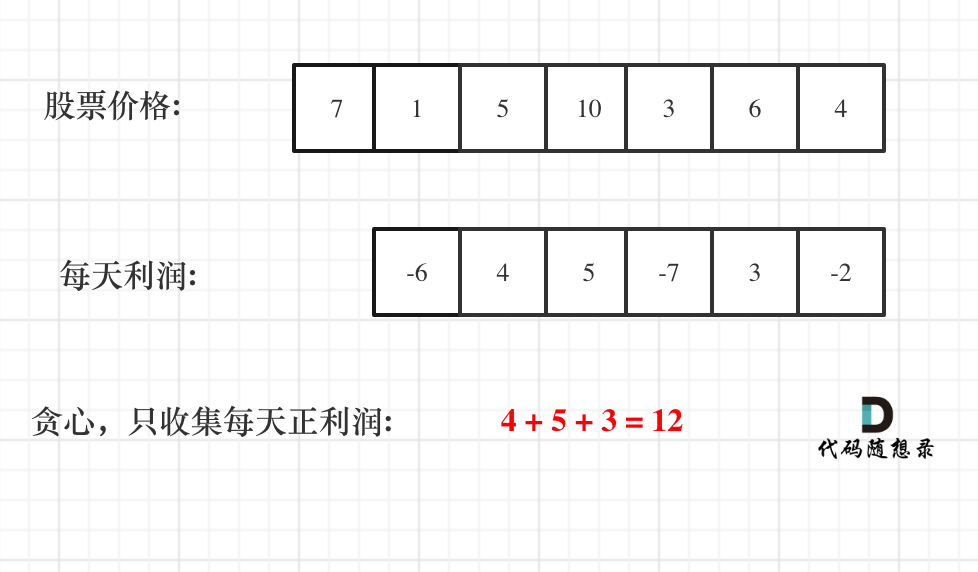
贪心算法:买卖股票的最佳时机II 跳跃游戏 跳跃游戏II
122.买卖股票的最佳时机II 思路: 想要获得利润,至少要以两天为一个交易单元,因为两天才会有股价差。因此可以将最终利润进行分解,如prices[3] - prices[0] (prices[3] - prices[2]) (prices[2] - prices[1]) (prices[1] - pr…...
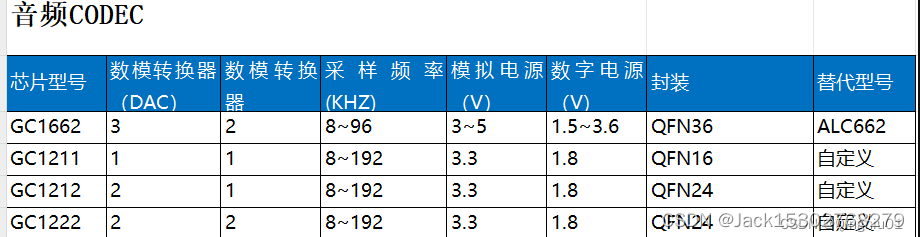
音频DAC,ADC,CODEC的选型分析,高性能立体声
想要让模拟信号和数字信号顺利“交往”,就需要一座像“鹊桥”一样的中介,将两种不同的语言转变成统一的语言,消除无语言障碍。这座鹊桥就是转换器芯片,也就是ADC芯片。ADC芯片的全称是Analog-to-Digital Converter, 即模拟数字转换…...
python 连接SQL server 请用pymssql连接,千万别用pyodbc
pymssql官方介绍文档 python 使用 pymssql连接 SQL server 代码示例: 安装pymssql包: pip install pymssql代码: import pymssqldef conn_sqlserver_demo():# 连接字符串示例(根据您的配置进行修改)conn Nonetry:co…...

IntelliJ IDEA 自带HTTP Client接口插件上传文件示例
如何使用IntelliJ IDEA自带的HTTP Client接口插件进行文件上传的示例。在这个示例中,我们将关注Controller代码、HTTP请求文件(xxx.http),以及文件的上传和处理。 Controller代码 首先,让我们看一下处理文件上传的Co…...

C++中的接口有什么用
2023年12月13日,周三上午 今天上午在适配器模式,我发现如果想真正理解适配器模式,就必须学会使用C中的接口,就必须明白为什么要在C中使用接口,所以重新学习了一下C中的接口 目录 C中的接口有什么用用代码说明“实现多…...
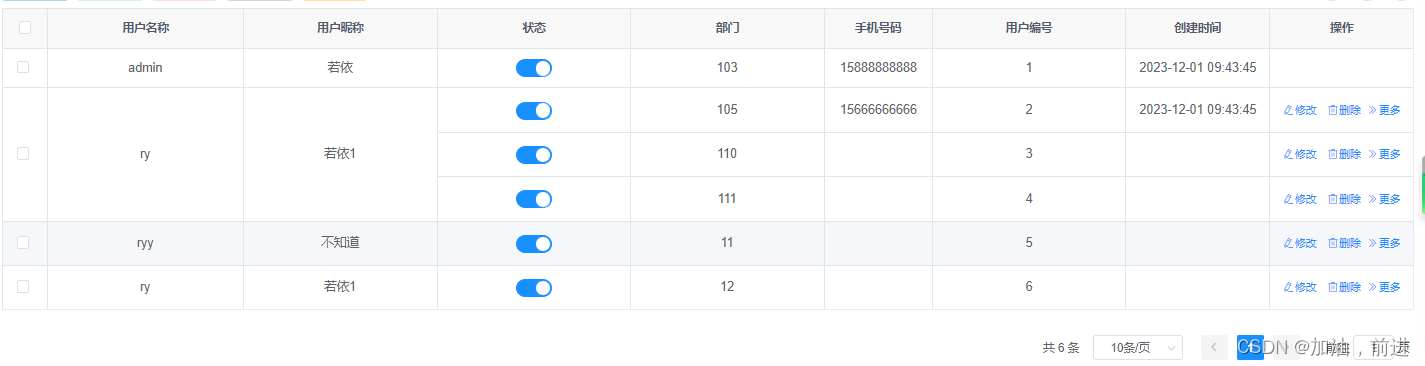
el-table合并相同数据的单元格
相同的数据合并单元格 <el-table :data"userList" :span-method"objectSpanMethod" border><el-table-column type"selection" width"50" align"center" /><el-table-column label"用户名称" a…...

Verilog Systemverilog define宏定义
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 文章前情预告一、define是个啥?二、为什么要使用define三、怎么使用define四、define的横向拓展五、define思想在生活中的体现!六、结论七、参考资料八、…...

51单片机应用从零开始(十一)·数组函数、指针函数
51单片机应用从零开始(九)数组-CSDN博客 51单片机应用从零开始(十)指针-CSDN博客 目录 1. 用数组作函数参数控制流水花样 2. 用指针作函数参数控制 P0 口 8 位 LED 流水点亮 1. 用数组作函数参数控制流水花样 要在51单片机中…...
PostgreSQL-数据库PSQL元命令)
【PostgreSQL】从零开始:(八)PostgreSQL-数据库PSQL元命令
元命令 postgres# \? General\bind [PARAM]... set query parameters\copyright show PostgreSQL usage and distribution terms\crosstabview [COLUMNS] execute query and display result in crosstab\errverbose show most recent error…...

02 使用Vite创建Vue3项目
概述 A Vue project is structured similarly to a lot of modern node-based apps and contains the following: A package.json fileA node_modules folder in the root of your projectVarious other configuration files are usually contained at the root level, such …...
)
Shell三剑客:sed(简介)
一、前言 Stream EDitor:流编辑 sed 是一种在线的、非交互式的编辑器,它一次处理一行内容。处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”(pattern space),接着用sed命令处理缓冲区中的内容,处理完成后&…...

tp连接数据库
ThinkPHP内置了抽象数据库访问层,把不同的数据库操作封装起来,我们只需要使用公共的Db类进行操作,而无需针对不同的数据库写不同的代码和底层实现,Db类会自动调用相应的数据库驱动来处理。采用PDO方式,目前包含了Mysql…...
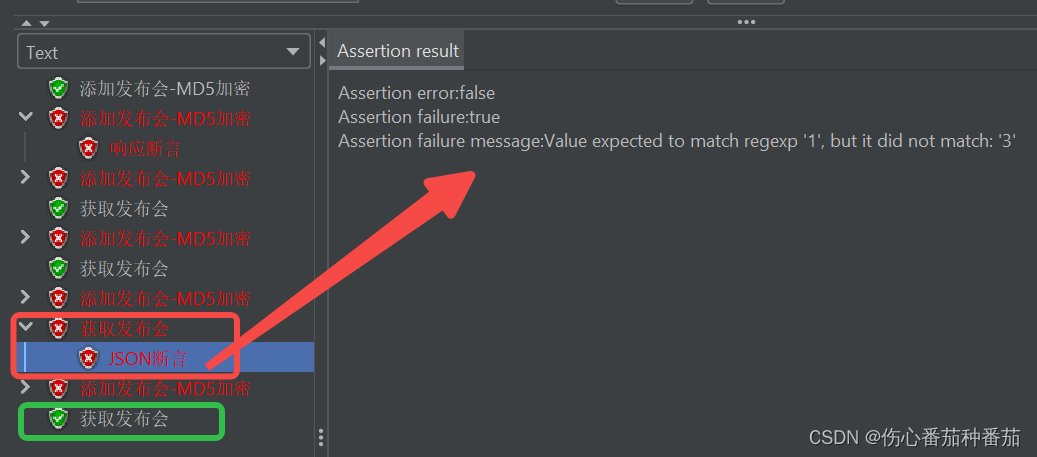
jmeter,断言:响应断言、Json断言
一、响应断言 接口A请求正常返回值如下: {"status": 10013, "message": "user sign timeout"} 在该接口下创建【响应断言】元件,配置如下: 若断言成功,则查看结果树的接口显示绿色,若…...

dockerfite创建镜像---INMP+wordpress
搭建dockerfile---lnmp 在192.168.10.201 使用 Docker 构建 LNMP 环境并运行 Wordpress 网站平台 [rootdocker1 opt]# mkdir nginx mysql php [rootdocker1 opt]# ls #分别拖入四个包: nginx-1.22.0.tar.gz mysql-boost-5.7.20.tar.gz php-7.1.10.tar.bz2 wor…...
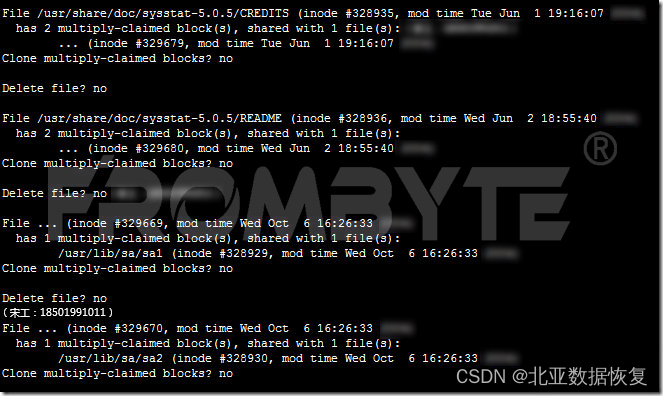
服务器数据恢复—raid5热备盘未激活崩溃导致上层oracle数据丢失的数据恢复案例
服务器数据恢复环境: 某品牌X系列服务器,4块SAS硬盘组建了一组RAID5阵列,还有1块磁盘作为热备盘使用。服务器上层安装的linux操作系统,操作系统上部署了一个基于oracle数据库的OA(oracle已经不再为该OA系统提供后续服务…...

生产派工自动化:MES系统的关键作用
随着制造业的数字化转型和智能化发展,生产派工自动化成为了提高生产效率、降低成本,并实现优质产品生产的关键要素之一。制造执行系统(MES)在派工自动化中发挥着重要作用,通过实时数据采集和智能调度,优化生…...
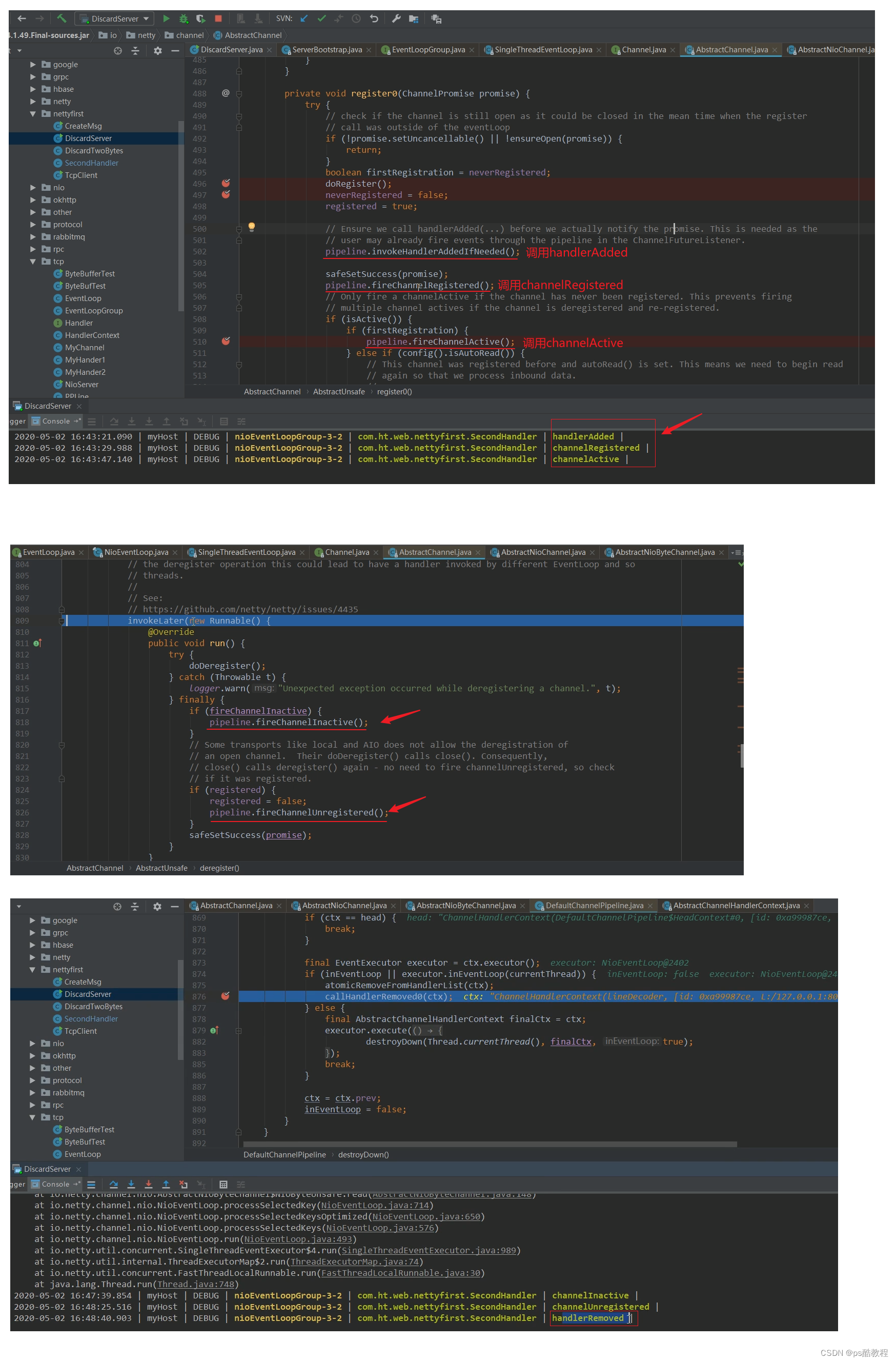
netty-daxin-2(netty常用事件讲解)
文章目录 netty常用事件讲解ChannelHandler接口ChannelHandler适配器类ChannelInboundHandler 子接口Channel 的状态调用时机ChannelHandler 生命周期示例NettServer&CustomizeInboundHandlerNettyClient测试分析 ChannelInboundHandlerAdapter适配器类SimpleChannelInboun…...

使用playbook部署k8s集群
1.部署ansible集群 使用python脚本一个简单的搭建ansible集群-CSDN博客 2.ansible命令搭建k8s: 1.主机规划: 节点IP地址操作系统配置server192.168.174.150centos7.92G2核client1192.168.174.151centos7.92G2核client2192.168.174.152centos7.92G2 …...

Python基础入门第四节,第五节课笔记
第四节 第一个条件语句 if 条件: 条件成立执行的代码1 条件成立执行的代码2 ...... else: 条件不成立执行的代码1 条件不成立执行的代码2 …… 代码如下: 身高 float(input("请输入您的身高(米):")) if 身高 >1.3:print(f您的身高是{身高},已经超过1.3米,您需…...

Python通达信数据获取终极指南:如何免费获取A股市场数据
Python通达信数据获取终极指南:如何免费获取A股市场数据 【免费下载链接】mootdx 通达信数据读取的一个简便使用封装 项目地址: https://gitcode.com/GitHub_Trending/mo/mootdx 还在为金融数据分析而烦恼数据源问题吗?每次想要分析A股市场数据&a…...

终极性能优化指南:如何让环世界从卡顿到丝滑的5大秘诀
终极性能优化指南:如何让环世界从卡顿到丝滑的5大秘诀 【免费下载链接】Performance-Fish Performance Mod for RimWorld 项目地址: https://gitcode.com/gh_mirrors/pe/Performance-Fish 还在为环世界后期卡顿而烦恼吗?当你的殖民地发展到100人以…...

C++ 显式类型转换详解
C 显式类型转换详解一、C 显示类型转换详解1、static_cast2、dynamic_cast3、const_cast4、reinterpret_cast5、C 风格转换6、总体注意事项7、总结二、代码示例1、示例代码2、运行结果一、C 显示类型转换详解 在 C 中,类型转换是编程的核心概念之一。显示类型转换&…...

利用Taotoken统一管理多个AI项目的API密钥与访问权限
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用Taotoken统一管理多个AI项目的API密钥与访问权限 对于同时维护多个AI应用或为不同客户部署服务的开发者与团队而言,…...

如何用XiaoMusic让小爱音箱变身你的私人音乐管家:5个超实用场景解析
如何用XiaoMusic让小爱音箱变身你的私人音乐管家:5个超实用场景解析 【免费下载链接】xiaomusic 使用小爱音箱播放音乐,音乐使用 yt-dlp 下载。 项目地址: https://gitcode.com/GitHub_Trending/xia/xiaomusic 还在为小爱音箱只能播放特定平台的音…...

工程师背包线缆管理实战:从Cord Hog到DIY收纳方案全解析
1. 项目概述:从“线缆地狱”到个人收纳方案的探索作为一名常年与各种开发板、调试器、电源适配器和数据线打交道的硬件工程师,我的背包简直就是个微缩版的电子实验室。每天通勤,包里除了笔记本电脑,必然塞满了USB线、串口线、JTAG…...

Axure RP中文界面完整汉化指南:3分钟免费安装全系列版本
Axure RP中文界面完整汉化指南:3分钟免费安装全系列版本 【免费下载链接】axure-cn Chinese language file for Axure RP. Axure RP 简体中文语言包。支持 Axure 11、10、9。不定期更新。 项目地址: https://gitcode.com/gh_mirrors/ax/axure-cn 对于中文用户…...
)
收藏 | 从零开始学大模型:6个月完整开发路线图(附免费资源)
本文提供一份从Python基础到企业级大模型应用开发的6-8个月学习路线图,涵盖API调用、提示词工程、RAG知识库问答、Agent智能体开发及模型微调部署。结合近百份招聘需求及专家建议,适合初学者快速构建AI技能体系,附有前沿拓展方向与免费学习资…...

开发AI应用时借助Taotoken模型广场快速进行模型选型与测试
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 开发AI应用时借助Taotoken模型广场快速进行模型选型与测试 在开发基于大语言模型的应用或功能时,一个常见的挑战是如何…...

爱搜索 GEO 营销系统实效展示与能力验证
在当前的数字营销环境中,许多企业发现传统的 SEO 手段在应对 AI 驱动的搜索场景时显得力不从心。当潜在客户向大模型提问“哪家装修公司更靠谱”或“推荐几家铝板输送机厂家”时,如果品牌未能出现在 AI 生成的答案中,就意味着失去了最精准的流…...