Llama 架构分析
从代码角度进行Llama 架构分析
- Llama 架构分析
- 前言
- Llama 架构分析
- 分词
- 网络主干
- DecoderLayer
- Attention
- MLP
- 下游任务
- 因果推理
- 文本分类
Llama 架构分析
前言
Meta 开发并公开发布了 Llama系列大型语言模型 (LLM),这是一组经过预训练和微调的生成文本模型,参数规模从 70 亿到 700 亿不等。
在大多数任务中,LLaMA-13B要比GPT-3(175B)的性能要好,LLaMA-65B和组好的模型Chinchilla-70B以及PaLM-540B的实力相当。
Llama 架构分析
分词
分词部分主要做的是利用文本分词器对文本进行分词

tokenizer = AutoTokenizer.from_pretrained(PATH_TO_CONVERTED_TOKENIZER)
text = "Hey, are you conscious? Can you talk to me?"
inputs = tokenizer(text, return_tensors="pt")
网络主干
主干网络部分主要是将分词得到的input_ids输入到embedding层中进行文本向量化,得到hidden_states(中间结果),然后输入到layers层中,得到hidden_states(中间结果),用于下游任务。
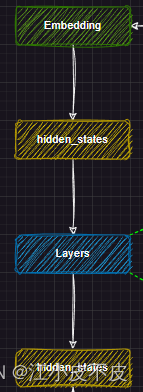
self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size, self.padding_idx)self.layers = nn.ModuleList([MixtralDecoderLayer(config, layer_idx) for layer_idx in range(config.num_hidden_layers)])self._use_flash_attention_2 = config._attn_implementation == "flash_attention_2"self.norm = MixtralRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
DecoderLayer
主干网络的layers层就是由多个DecoderLayer组成的,由num_hidden_layers参数决定,一般我们说的模型量级就取决于这个数量,7b的模型DecoderLayer层的数量是32。
DecoderLayer层中又包含了Attention层和MLP层,主要的一个思想是利用了残差结构。
如下图所示,分为两个部分
第一部分
- 首先,将hidden_states(文本向量化的结构)进行复制,即残差
- 归一化
- 注意力层
- 残差相加
第二部分
- 首先将第一部分得到的hidden_states进行复制,即残差
- 归一化
- MLP层
- 残差相加
外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传
#复制一份
residual = hidden_states
#归一化
hidden_states = self.input_layernorm(hidden_states)#注意力层
hidden_states, self_attn_weights, present_key_value = self.self_attn(hidden_states=hidden_states,attention_mask=attention_mask,position_ids=position_ids,past_key_value=past_key_value,output_attentions=output_attentions,use_cache=use_cache,padding_mask=padding_mask,
)
#加上残差
hidden_states = residual + hidden_states#复制一份
residual = hidden_states
#归一化
hidden_states = self.post_attention_layernorm(hidden_states)
#mlp
hidden_states = self.mlp(hidden_states)
#加上残差
hidden_states = residual + hidden_statesoutputs = (hidden_states,)if output_attentions:outputs += (self_attn_weights,)if use_cache:outputs += (present_key_value,)return outputs
Attention
进行位置编码,让模型更好的捕捉上下文信息
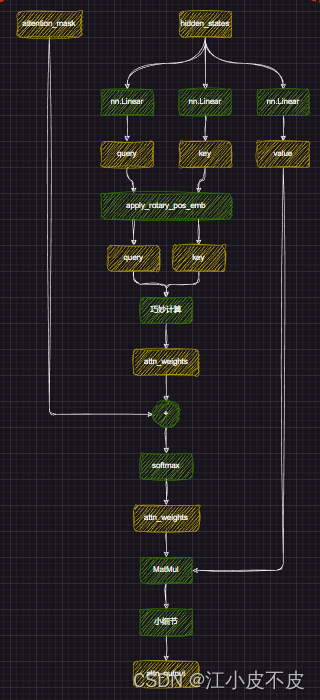
#经过线性层
query_states = self.q_proj(hidden_states)
key_states = self.k_proj(hidden_states)
value_states = self.v_proj(hidden_states)#多头注意力形状变换
query_states = query_states.view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
key_states = key_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
value_states = value_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
kv_seq_len = key_states.shape[-2]#计算cos、sin
#计算旋转位置嵌入
cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids)#计算权重
key_states = repeat_kv(key_states, self.num_key_value_groups)
value_states = repeat_kv(value_states, self.num_key_value_groups)
attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim)#加上掩码
attn_weights = attn_weights + attention_mask
#计算softmax
attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query_states.dtype)
attn_output = torch.matmul(attn_weights, value_states)attn_output = self.o_proj(attn_output)MLP
mlp层的主要作用是应用非线性激活函数和线性投影。
- 首先将attention层得到的结果经过两个线性层得到gate_proj和up_proj
- gate_proj经过激活函数,再和up_proj相乘
- 最后经过一个线性层得到最后的结果
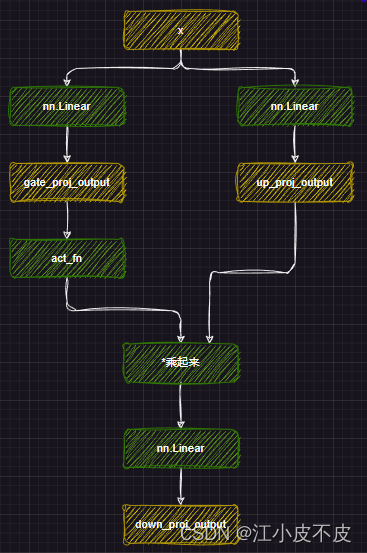
self.gate_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
self.up_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
self.down_proj = nn.Linear(self.intermediate_size, self.hidden_size, bias=False)
self.act_fn = ACT2FN[config.hidden_act]
down_proj = self.down_proj(self.act_fn(self.gate_proj(x)) * self.up_proj(x))
下游任务
因果推理
所谓因果推理,就是回归任务。
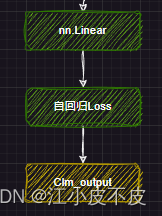
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
文本分类
即分类任务
self.score = nn.Linear(config.hidden_size, self.num_labels, bias=False)相关文章:
Llama 架构分析
从代码角度进行Llama 架构分析 Llama 架构分析前言Llama 架构分析分词网络主干DecoderLayerAttentionMLP 下游任务因果推理文本分类 Llama 架构分析 前言 Meta 开发并公开发布了 Llama系列大型语言模型 (LLM),这是一组经过预训练和微调的生成文本模型,参…...

vue3前端 md5工具类
工具类 /*** Namespace for hashing and other cryptographic functions* Copyright (c) Andrew Valums* Licensed under the MIT license, http://valums.com/mit-license/*/var V V || {}; V.Security V.Security || {};(function () {// for faster accessvar S V.Secur…...

Unity触摸 射线穿透UI解决
unity API 之EventSystem.current.IsPointerOverGameObject() 命名空间 :UnityEngine.EventSystems 官方描述: public bool IsPointerOverGameObject(); public bool IsPointerOverGameObject(int pointerId); //触摸屏时需要的参数ÿ…...
基于QTreeWidget实现带Checkbox的多级组织结构选择树
基于QTreeWidget实现带Checkbox的多级组织结构选择树 采用基于QWidgetMingw实现的原生的组织结构树 通过QTreeWidget控件实现的带Checkbox多级组织结构树。 Qt相关系列文章: 一、Qt实现的聊天画面消息气泡 二、基于QTreeWidget实现多级组织结构 三、基于QTreeWidget…...

探索 Vim:一个强大的文本编辑器
引言: Vim(Vi IMproved)是一款备受推崇的文本编辑器,拥有强大的功能和高度可定制性,提供丰富的编辑和编程体验。本文将探讨 Vim 的基本概念、使用技巧以及为用户带来的独特优势。 简介和发展 1. Vim 的简介和历史 V…...
—容器探针)
K8S(十)—容器探针
这里写目录标题 容器探针(probe)检查机制探测结果探测类型何时该使用存活态探针?何时该使用就绪态探针?何时该使用启动探针? 使用exechttptcpgrpc使用命名端口 使用启动探针保护慢启动容器定义就绪探针配置探针HTTP 探测TCP 探测探针层面的…...

[C错题本]
1.int,short,long都是signed的 但是char可能是signed 也可能是unsigned的——《C Primer》 2.在16位的PC中 char类型占1个字节 int占2个字节 long int占4个字节 float占四个字节 double占八个字节 3.自增运算符和自减运算符即使是在判断条件中使用也会实际生效 int i 1; int…...
tomcat启动异常:子容器启动失败(a child container failed during start)
最近在使用eclipse启动Tomcat时,发现一个问题,启动以前的项目突然报子容器启动异常。 异常信息如下: 严重: 子容器启动失败 java.util.concurrent.ExecutionException: org.apache.catalina.LifecycleException: 无法启动组件[org.apache.…...
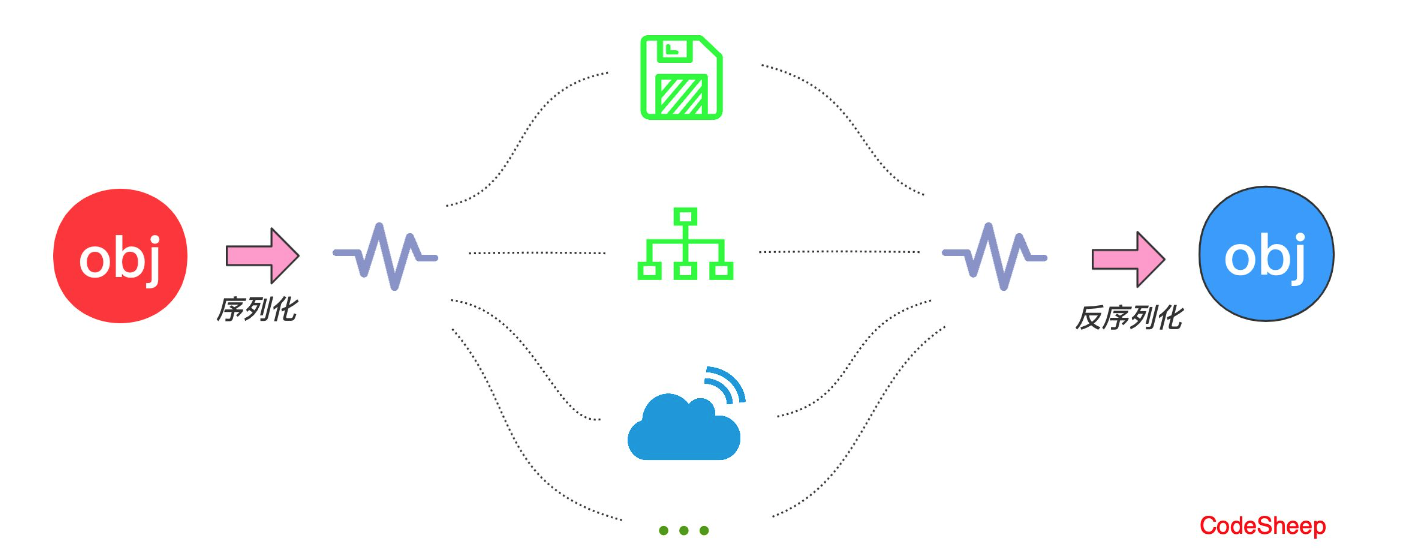
JAVA序列化(创建可复用的 Java 对象)
JAVA 序列化(创建可复用的 Java 对象) 保存(持久化)对象及其状态到内存或者磁盘 Java 平台允许我们在内存中创建可复用的 Java 对象,但一般情况下,只有当 JVM 处于运行时,这些对象才可能存在,即,这些对象的生命周期不…...

如何使用自动化工具编写测试用例?
以下为作者观点,仅供参考: 在快速变化的软件开发领域,保证应用程序的可靠性和质量至关重要。随着应用程序复杂性和规模的不断增加,仅手动测试无法满足行业需求。 这就是测试自动化发挥作用的地方,它使软件测试人员能…...

redis底层数据结构之skiplist实现
skiplist实现 skiplist跳跃表,是一种有序数据结构,通过在每个节点中维持多个指向其他节点的指针,来达到快速访问节点的目的,redis使用skiplist作为zsort的底层实现之一 结构很像树形结构 typedef struct zskiplistNode { // 对象…...
mjpg-streamer配置其它端口访问视频
环境 树莓派4B ubuntu 20.04 U口摄像头 确认摄像头可访问 lsusb查看 在dev下可查看到video* sudo mplayer tv://可打开摄像头并访问到视频 下载mjpg-streamer并编译安装 在github下载zip包,下载的源码,需要编译安装 unzip解压 cd mjpg-streamer/mjp…...

C++相关闲碎记录(15)
1、string字符串 #include <iostream> #include <string> using namespace std;int main (int argc, char** argv) {const string delims(" \t,.;");string line;// for every line read successfullywhile (getline(cin,line)) {string::size_type beg…...
汽车IVI中控开发入门及进阶(十一):ALSA音频
前言 汽车中控也被称为车机、车载多媒体、车载娱乐等,其中音频视频是非常重要的部分,音频比如播放各种格式的音乐文件、播放蓝牙接口的音乐、播放U盘或TF卡中的音频文件,如果有视频文件也可以放出音频,看起来很简单,在windows下音乐播放器很多,直接打开文件就能播放各…...
Gradle 之初体验
文章目录 1.安装1)检查 JDK2)下载 Gradle3)解压 Gradle4)环境变量5)验证安装 2.优势总结 Gradle 是一款强大而灵活的构建工具,用于自动化构建、测试和部署项目。它支持多语言、多项目和多阶段的构建&#x…...
【Spark精讲】Spark内存管理
目录 前言 Java内存管理 Java运行时数据区 Java堆 新生代与老年代 永久代 元空间 垃圾回收机制 JVM GC的类型和策略 Minor GC Major GC 分代GC Full GC Minor GC 和 Full GC区别 Executor内存管理 内存类型 堆内内存 堆外内存 内存管理模式 静态内存管理 …...

C语言实现Hoare版快速排序(递归版)
Hoare版 快速排序是由Hoare发明的,所以我们先来讲创始人的想法。我们直接切入主题,Hoare版快速排序的思想是将一个值设定为key,这个值不一定是第一个,如果你选其它的值作为你的key,那么你的思路也就要转换一下…...

git 避免输入用户名 密码 二进制/文本 文件冲突解决
核心概念介绍 工作区是你当前正在进行编辑和修改的文件夹,可见的。 暂存区位于.git/index(git add放入)。 代码库(工作树)位于.git(git commit将暂存区中的更改作为一个提交保存到代码库中,并清空暂存区) 避免输入用户 密码: 方式一: ht…...

[OpenWrt]RAX3000一根线实现上网和看IPTV
背景: 1.我家电信宽带IPTV 2.入户光猫,桥接模式 3.光猫划分vlan,将上网信号IPTV信号,通过lan口(问客服要光猫超级管理员密码,具体教程需要自行查阅,关键是要设置iptv在客户侧的vlan id&#…...
最新50万字312道Java经典面试题52道场景题总结(附答案PDF)
最近有很多粉丝问我,有什么方法能够快速提升自己,通过阿里、腾讯、字节跳动、京东等互联网大厂的面试,我觉得短时间提升自己最快的手段就是背面试题;花了3个月的时间将市面上所有的面试题整理总结成了一份50万字的300道Java高频面…...

Discord社群运营神器:用AI自动回复提升活跃度的完整指南
Discord社群运营神器:用AI自动回复提升活跃度的完整指南 在数字社交时代,Discord已经从一个游戏语音工具成长为全球最受欢迎的社群平台之一。无论是Web3项目、开源社区还是兴趣小组,Discord都成为了连接成员的核心枢纽。但作为社群运营者&…...

FlexRay帧格式拆解:从Header到Trailer,手把手教你读懂汽车总线的‘数据包’
FlexRay帧格式实战解析:像拆解网络包一样掌握汽车总线通信 在汽车电子系统开发中,理解总线协议就像网络工程师需要精通TCP/IP一样重要。FlexRay作为高性能车载网络的核心协议,其帧格式设计既体现了汽车电子对确定性的严苛要求,又融…...

bilibili-downloader开源工具:突破B站4K视频下载限制的全攻略
bilibili-downloader开源工具:突破B站4K视频下载限制的全攻略 【免费下载链接】bilibili-downloader B站视频下载,支持下载大会员清晰度4K,持续更新中 项目地址: https://gitcode.com/gh_mirrors/bil/bilibili-downloader 在数字内容消…...

3个突破性技术,让抖音无水印视频下载效率提升200%
3个突破性技术,让抖音无水印视频下载效率提升200% 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support. …...

Qwen3.5-9B自动化:GitHub Actions触发模型推理+PR评论生成
Qwen3.5-9B自动化:GitHub Actions触发模型推理PR评论生成 1. 项目概述 Qwen3.5-9B是一个拥有90亿参数的开源大语言模型,具备强大的逻辑推理、代码生成和多轮对话能力。最新版本还支持多模态理解(图文输入)和长达128K tokens的上…...

Nanobot技能扩展开发:自定义OpenClaw功能模块教程
Nanobot技能扩展开发:自定义OpenClaw功能模块教程 1. 引言 想给你的Nanobot智能助手添加一些个性化功能吗?比如让它帮你查天气、管理待办事项,或者连接你常用的办公软件?今天就来手把手教你如何为Nanobot开发自定义技能模块。 …...
)
告别卡顿!用MobileNetv2+MPPTSNet-EC在树莓派上跑实时语义分割(附完整配置与性能测试)
树莓派实战:MobileNetv2MPPTSNet-EC实时语义分割全流程解析 当你在树莓派上第一次看到摄像头画面被实时分割成不同语义区域时,那种成就感绝对值得记录。本文将带你完整实现从模型选择到部署优化的全流程,用MobileNetv2MPPTSNet-EC这套组合拳&…...

手把手教你用DrissionPage搭建个人新闻聚合器:自动抓取百度热搜并保存到Excel
用DrissionPage打造智能新闻聚合器:从百度热搜抓取到Excel自动化分析 每天手动刷新闻不仅耗时,还容易错过重要信息。想象一下,如果有个私人助手能自动收集全网热点,整理成结构化的报告,甚至生成直观的可视化图表——这…...
)
从MP3到微信语音:一份完整的Java音频格式转换工具链搭建指南(附FFmpeg与silk_v3_encoder配置)
Java音频处理实战:构建MP3到微信语音的高效转换工具链 引言 在即时通讯应用开发中,音频消息的处理一直是技术难点之一。特别是当我们需要将常见的MP3格式转换为微信、QQ等平台专用的SILK编码格式时,开发者往往需要跨越多个技术环节。本文将带…...

动态链接库emp.dll详解:从原理到实战修复
动态链接库emp.dll深度解析:技术原理与高效修复指南 引言:动态链接库的现代价值 在Windows系统的软件生态中,动态链接库(DLL)如同建筑中的预制构件,通过代码复用机制显著提升了开发效率和系统资源利用率。emp.dll作为其中一员&…...