第七章.集成学习(Ensemble Learning)—袋装(bagging),随机森林(Random Forest)
第七章.集成学习 (Ensemble Learning)
7.1 集成学习—袋装(bagging),随机森林(Random Forest)
集成学习就是组合多个学习器,最后得到一个更好的学习器。
1.常见的4种集成学习算法
- 个体学习器之间不存在强依赖关系,袋装(bagging)
- 随机森林(Random Forest)
- 个体学习器之间存在强依赖关系,提升(boosting)
- Stacking
2.袋装(bagging)
bagging也叫bootstrap aggregating,是原始数据集选择S次后得到S个新数据集的一种技术,是一种有放回的抽样。
1).示例:
①.原始训练数据集:{0,1,2,3,4,5,6,7,8,9}
②.Bootstrap采样:
{7,2,6,7,5,4,8,8,1,0}—未采样3,9
{1,3,8,0,3,5,8,0,1,9}—未采样2,4,6,7
{2,9,4,2,7,9,3,0,1,0}—未采样5,6,8
③.图像
- 从数据D中抽样K组新的数据集,每个数据集可以应用不同的算法进行建模(KNN,神经网络),共有K个模型,引入的新数据使用K个模型进行预测,然后组合投票决定最终输出结果。
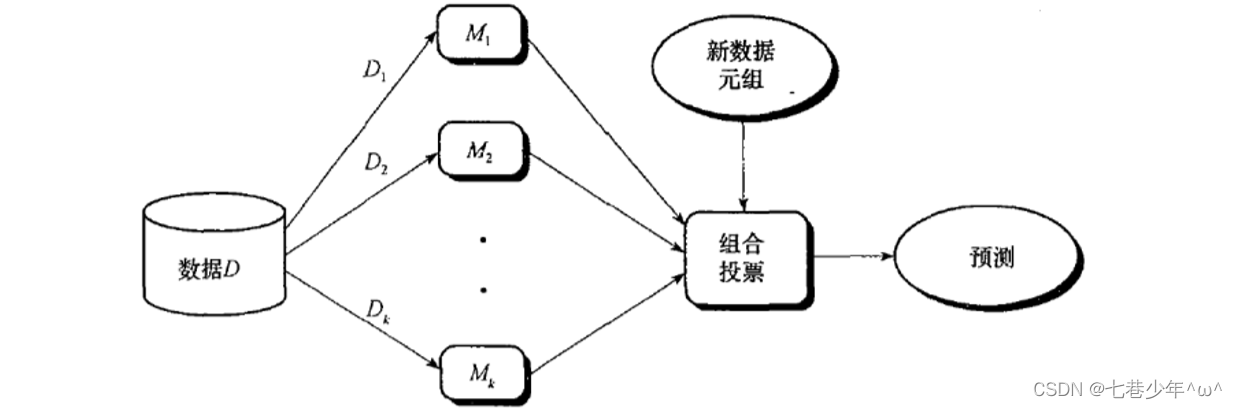
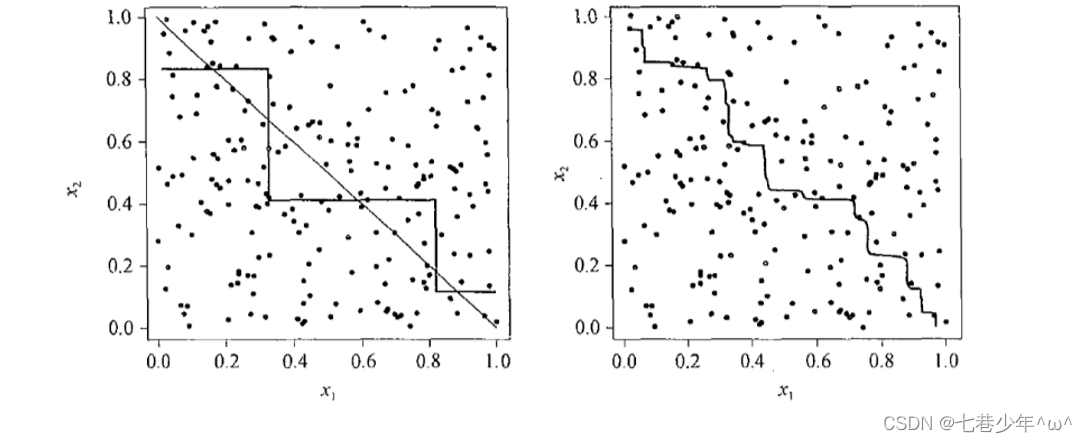
- 假设图中是分类模型,左图有两个分类模型,两个分类模型组合起来可能是右图的决策边界
2).代码实现:
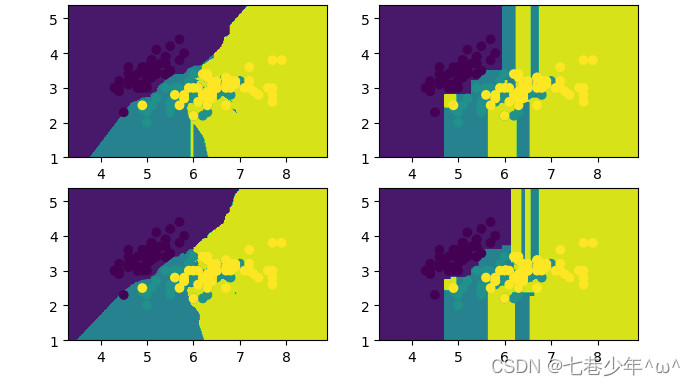
使用bagging后的测试结果有可能有提升,有可能不变,也有可能下降,在数据集比较复杂的情况下,建议使用bagging。
from sklearn import tree
from sklearn import neighbors
from sklearn import datasets
from sklearn.ensemble import BaggingClassifier
from sklearn.model_selection import train_test_split
import numpy as np
import matplotlib.pyplot as plt# 绘图
def plot(model):x_min, x_max = x_data[:, 0].min() - 1, x_data[:, 0].max() + 1y_min, y_max = x_data[:, 1].min() - 1, x_data[:, 1].max() + 1# 生成网格矩阵xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02), np.arange(y_min, y_max, 0.02))z = model.predict(np.c_[xx.ravel(), yy.ravel()])z = z.reshape(xx.shape)# 绘制等高线cs = plt.contourf(xx, yy, z)# 加载数据
iris = datasets.load_iris()
x_data = iris.data[:, :2]
y_data = iris.target# 数据切分
x_train, x_test, y_train, y_test = train_test_split(x_data, y_data)# KNN模型
knn = neighbors.KNeighborsClassifier()
knn.fit(x_train, y_train)
knn_accuracy = knn.score(x_test, y_test)
print('knn_accuracy:', knn_accuracy)# DicisionTree模型
dtree = tree.DecisionTreeClassifier()
dtree.fit(x_train, y_train)
dtree_accuracy = dtree.score(x_test, y_test)
print('dtree_accuracy:', dtree_accuracy)# 绘制bagging_knn分类模型
bagging_knn = BaggingClassifier(knn, n_estimators=100)
bagging_knn.fit(x_train, y_train)
bagging_knn_accuracy = bagging_knn.score(x_test, y_test)
print('bagging_knn_accuracy:', bagging_knn_accuracy)# 绘制bagging_dtree分类模型
bagging_dtree = BaggingClassifier(dtree, n_estimators=100)
bagging_dtree.fit(x_train, y_train)
bagging_dtree_accuracy = bagging_dtree.score(x_test, y_test)
print('bagging_dtree_accuracy:', bagging_dtree_accuracy)# 绘制knn分类模型
plt.subplot(2, 2, 1)
plot(knn)
plt.scatter(x_data[:, 0], x_data[:, 1], c=y_data)# 绘制决策树分类模型
plt.subplot(2, 2, 2)
plot(dtree)
plt.scatter(x_data[:, 0], x_data[:, 1], c=y_data)# 绘制bagging_knn分类模型
plt.subplot(2, 2, 3)
plot(bagging_knn)
plt.scatter(x_data[:, 0], x_data[:, 1], c=y_data)# 绘制bagging_dtree分类模型
plt.subplot(2, 2, 4)
plot(bagging_dtree)
plt.scatter(x_data[:, 0], x_data[:, 1], c=y_data)plt.show()3).结果展示:
- 数据结果

- 图像结果
3.随机森林(Random Forest)
1).公式:
RF = 决策树 + Bagging + 随机属性选择
2).图像表示:
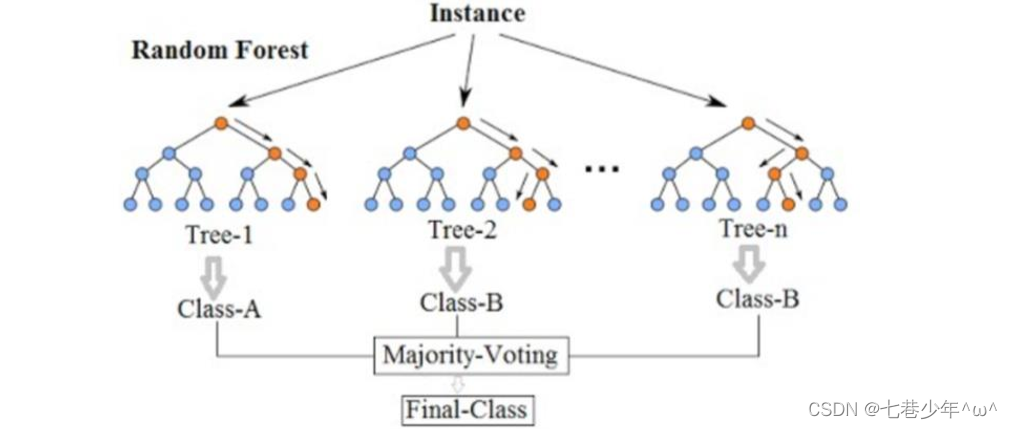
3).RF算法流程
①.样本的随机:从样本集中用bagging的方式,随机选择n个样本。
②.特征的随机:从所有属性d中随机选择k个属性(k<d),然后从k个属性中选择最佳分割属性作为节点建立CART决策树。
③.重复以上两个步骤m次。建立m颗CART决策树
④.这m颗CART决策树形成随机森林,通过投票表决结果,决定数据属于哪一类。
4).代码实现:
from sklearn import tree
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
import numpy as np
import matplotlib.pyplot as plt# 绘制图像
def plot(model):x_min, x_max = x_data[:, 0].min() - 1, x_data[:, 0].max() + 1y_min, y_max = x_data[:, 1].min() - 1, x_data[:, 1].max() + 1# 生成网格矩阵xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02), np.arange(y_min, y_max, 0.02))z = model.predict(np.c_[xx.ravel(), yy.ravel()])z = z.reshape(xx.shape)cs = plt.contourf(xx, yy, z)# 加载数据
data = np.genfromtxt('D:\\Data\\LR-testSet2.txt', delimiter=',')# 数据切分
x_data = data[:, :-1]
y_data = data[:, -1]# 测试集和训练集切分
x_train, x_test, y_train, y_test = train_test_split(x_data, y_data, test_size=0.5)# 决策树模型
dtree = tree.DecisionTreeClassifier()
dtree.fit(x_train, y_train)
dtree_accuracy = dtree.score(x_test, y_test)
print('dtree_accuracy:', dtree_accuracy)# 随机森林
RF = RandomForestClassifier(n_estimators=50)
RF.fit(x_train, y_train)
RF_accuracy = RF.score(x_test, y_test)
print('RF_accuracy:', RF_accuracy)# 绘制决策树模型
plt.subplot(1, 2, 1)
plot(dtree)
plt.scatter(x_data[:, 0], x_data[:, 1], c=y_data)# 绘制随机森林模型
plt.subplot(1, 2, 2)
plot(RF)
plt.scatter(x_data[:, 0], x_data[:, 1], c=y_data)plt.show()5).结果展示:
- 数据展示:
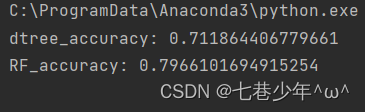
- 图像展示:
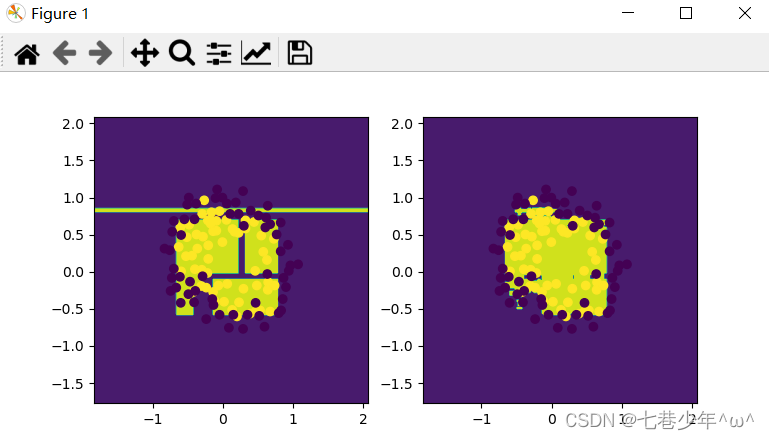
相关文章:
第七章.集成学习(Ensemble Learning)—袋装(bagging),随机森林(Random Forest)
第七章.集成学习 (Ensemble Learning) 7.1 集成学习—袋装(bagging),随机森林(Random Forest) 集成学习就是组合多个学习器,最后得到一个更好的学习器。 1.常见的4种集成学习算法 个体学习器之间不存在强依赖关系,袋装(bagging)…...
Java_面向对象
Java_面向对象 1.面向对象概述 面向对象是一种符合人类思想习惯的编程思想。显示生活中存在各种形态的不同事物,这些食物存在着各种各样的联系。在程序中使用对象来映射现实中的事物,使用对象的关系来描述事物之间的关系,这种思想就是面…...

【IoT】智能烟雾报警器
设计简介 硬件设计由AT89C51单片机、DS18B20温度传感器、4位共阳数码管、电源模块、报警模块、按键模块、MQ-2烟雾检测模块和ADC0832模数转换模块组成。 烟雾传感器MQ-2检测空气中的烟雾气体,通过ADC0832进行数据转换,经过单片机的运算处理后在数码管上…...
)
Python实现定时执行脚本(5)
前言 本文是该专栏的第17篇,后面会持续分享python的各种干货知识,值得关注。 笔者在前面有详细介绍过几种使用python实现定时执行任务的方法,可以说都是简单易上手的那种。而本文,再来详细介绍另外一种定时方法,那就是利用任务框架APScheduler(advanceded python schedu…...
JavaSe第4次笔记
1.转义字符和编程语言无关。 2.斜杠(\)需要转义,反斜杠(/)不需要转义。 3.不能做switch的参数的数据类型:long float double boolean( String可以)。 4.输入的写法:Scanner(回车自动带头文件(import java.util.Scanner;)) Scanner scan …...

epoll机制
预备知识 文件描述符file descriptor 文件描述符是Linux系统中对文件、套接字等I/O资源的抽象,每个打开的文件或套接字都有一个唯一的文件描述符。应用程序可以使用文件描述符来读写文件或进行网络通信。 epoll允许程序监控多个文件描述符,以便在这些…...
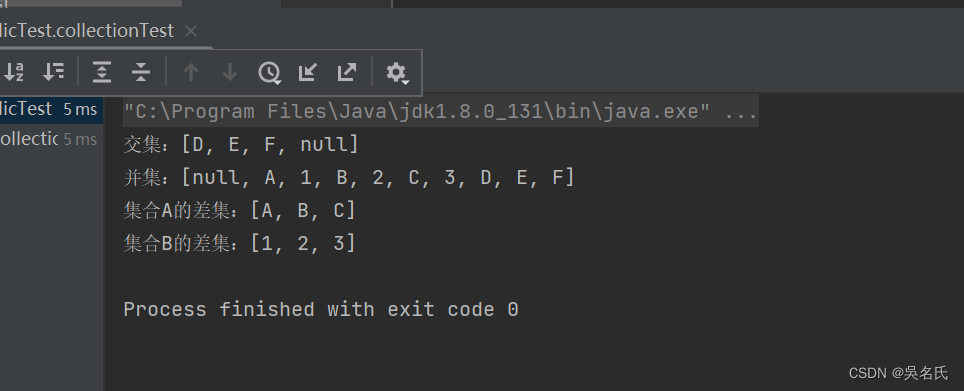
Java使用不同方式获取两个集合List的交集、补集、并集(相加)、差集(相减)
1 明确概念首先知道几个单词的意思:并集 union交集 intersection补集 complement析取 disjunction减去 subtract1.1 并集对于两个给定集合A、B,由两个集合所有元素构成的集合,叫做A和B的并集。记作:AUB 读作“A并B”例&#…...

【Android笔记80】Android之Retrofit适配器和文件上传下载
这篇文章,主要介绍Android之Retrofit适配器和文件上传下载。 目录 一、Retrofit适配器 1.1、Retrofit适配器 (1)引入RxJava依赖 (2)定义接口...

Nodejs模块化
1.模块化 1.1.模块化的基本概念 模块化是指解决一个复杂问题时,自顶向下逐层把系统划分为若干模块的过程。对于整个系统而言,模块是可组合、分解和更换的单元。 1.2 编程中的模块化 编程领域的模块化就是把一个大文件拆成独立并相互依赖的多个小模块…...

C++STL基础
STL基础 诞生 cpp的面向对象和泛型编程的思想本质就是提高复用性诞生了STL库 基本概念 STL标准模板库STL从广义上分为容器、算法及迭代器容器和算法之间通过迭代器进行连接STL几乎所有的代码都采用了模板类或者模板函数 基本组件 容器、算法、迭代器、仿函数、适配器、空间配置…...

数学建模经验【更新中】
数学建模简单入门 一、 分工 3人,1人论文,1人代码主力,1人论文代码(前一半时间主代码,后一半时间主论文) Tips: 不养闲人,论文必须要在对代码和题目极其了解并且能跟上队友思路的情况下才能写…...
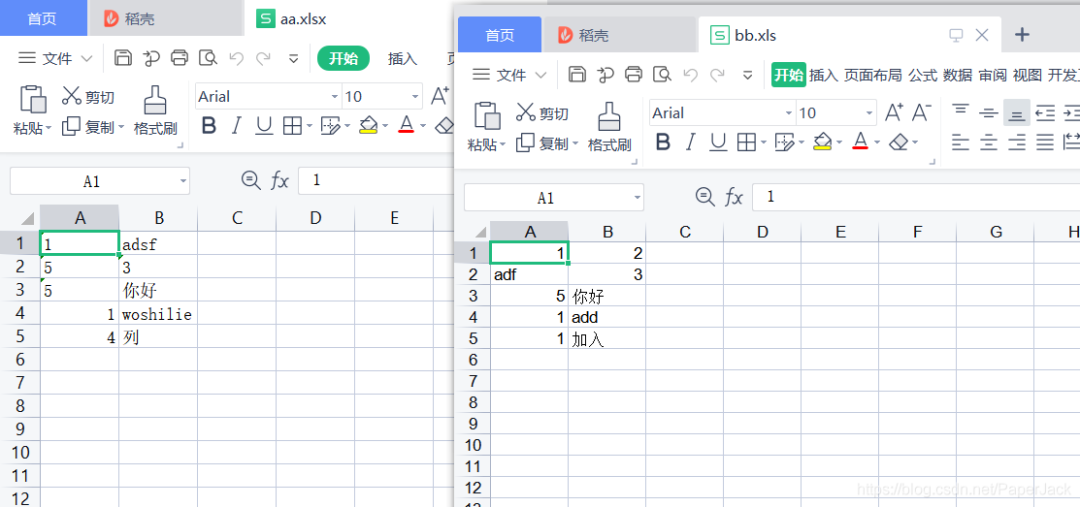
【python学习笔记】:Excel 数据的封装函数
对比其它编程语言,我们都知道Python最大的优势是代码简单,有丰富的第三方开源库供开发者使用。伴随着近几年数据分析的热度,Python也成为最受欢迎的编程语言之一。而对于数据的读取和存储,对于普通人来讲,除了数据库之…...

如何获取或设置CANoe以太网网卡信息(GET篇)
CAPL提供了一系列函数用来操作CANoe网卡。但是,但是,首先需要明确一点,不管是获取网卡信息,还是设置网卡信息,只能访问CAPL程序所在的节点下的网卡,而不是节点所在的以太网通道下的所有网卡 关于第一张图中,Class节点下,有三个网卡:Ethernet1、VLAN 1.100、VLAN 1.200…...
“终于我从字节离职了...“一个年薪50W的测试工程师的自白...
我递上了我的辞职信,不是因为公司给的不多,也不是因为公司待我不好,但是我觉得,我每天看中我憔悴的面容,每天晚上拖着疲惫的身体躺在床上,我都不知道人生的意义,是赚钱吗?是为了更好…...
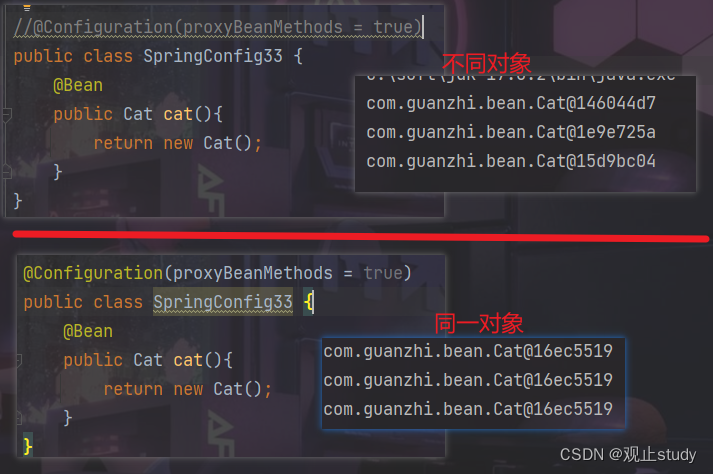
【Spring】八种常见Bean加载方式
🚩本文已收录至专栏:Spring家族学习 一.引入 (1) 概述 关于bean的加载方式,spring提供了各种各样的形式。因为spring管理bean整体上来说就是由spring维护对象的生命周期,所以bean的加载可以从大的方面划分成2种形式ÿ…...

第五回:样式色彩秀芳华
import matplotlib as mpl import matplotlib.pyplot as plt import numpy as np第五回详细介绍matplotlib中样式和颜色的使用,绘图样式和颜色是丰富可视化图表的重要手段,因此熟练掌握本章可以让可视化图表变得更美观,突出重点和凸显艺术性。…...

关于@Test单元测试
1、关于doReturndoReturn(new Test()).when(testService).updateStatusByLock(any(), any());在单元测试里这个方法可以执行到这里之间跳过不去执行,返回你想要的返回值2、关于givengiven(user.getName(any())).willReturn("张三");在单元测试里这个方法 …...

【项目实战】WebFlux整合r2dbc-mysql实战
一、背景 Webflux虽然是响应式的,但是没办法,JDBC是基于阻塞IO实现的,所以无法真正的威力发挥不出来。 但是,Webflux一旦整合了R2DBC之后,那么它将不再受限于数据库连接了,真正打通了响应式应用的任督二脉,性能才被释放。 当然,除了Spring推出的R2DBC协议,还有Orac…...

go版本分布式锁redsync使用教程
redsync使用教程前言redsync结构Pool结构Mutex结构acquire加锁操作release解锁操作redsync包的使用前言 在编程语言中锁可以理解为一个变量,该变量在同一时刻只能有一个线程拥有,以便保护共享数据在同一时刻只有一个线程去操作。对于高可用的分布式锁应…...

大数据之Hudi数据湖_大数据治理_简介_发展历史_特性_应用场景---大数据之Hudi数据湖工作笔记0001
支持hive spark flink 美国公司开发的~ 都在使用,这些企业都在用 支持hadoop的,更新,插入,删除 和数据增量处理 支持流式数据处理. hive是离线数仓 hive不支持事物 insert overwrite 底层后来通过这种方式支持了事物 insert overwrite处理数据很低效,因为更新是基于覆盖实现…...

对lsof、tcpdump、strace命令的简单记录
1. lsof (List Open Files) —— “谁占用了资源?” 核心哲学:Linux 中一切皆文件(包括磁盘文件、网络 Socket、设备)。 常用操作:lsof -i :15000:查看指定端口的进程占用及连接状态(LISTEN/EST…...

混元图像3.0对话P图技术解析:本地化可控生成新范式
1. 项目概述:这不是又一个“AI修图”功能,而是本地化P图工作流的临界点“腾讯混元图像3.0图生图模型上线,元宝也支持对话P图啦!”——这句话在科技圈刷屏那天,我正用本地部署的Stable Diffusion给客户改第十版电商主图…...

Simplefolio构建优化终极指南:Tree Shaking与代码分割实战
Simplefolio构建优化终极指南:Tree Shaking与代码分割实战 【免费下载链接】simplefolio ⚡️ A minimal portfolio template for Developers 项目地址: https://gitcode.com/gh_mirrors/si/simplefolio Simplefolio是一个为开发者设计的极简个人作品集模板&…...
5分钟搞懂钢琴音区划分)
别再死记硬背了!用MIDI键盘和DAW软件(如FL Studio/Cubase)5分钟搞懂钢琴音区划分
别再死记硬背了!用MIDI键盘和DAW软件5分钟搞懂钢琴音区划分 第一次打开DAW的钢琴卷帘窗时,那些密密麻麻的C3、C4编号是否让你一头雾水?作为从乐队吉他手转型音乐制作的过来人,我完全理解这种困惑。传统教材里"小字组"&q…...

Claw-ED:基于教学风格学习的AI助教,一键生成个性化教学包
1. 项目概述:一个为教师而生的AI教学助手 如果你是一位一线教师,每天被备课、写教案、做课件、设计学生活动、准备分层材料这些繁琐工作压得喘不过气,同时又对市面上那些“通用”的AI工具生成的、充满“AI腔”的教案感到失望,那么…...

从灰度图到粉彩叙事,全程可复现:5个精准Prompt模板+3类LUT预设,零基础速产美术馆级Pastel印相
更多请点击: https://intelliparadigm.com 第一章:从灰度图到粉彩叙事:Pastel印相的美学本质与技术边界 Pastel印相并非简单的色彩叠加,而是一种基于人眼感知非线性响应与胶片化学特性的数字模拟范式。其核心在于将灰度图像的亮度…...
)
思科路由器远程管理保姆级教程:从IP配置到Telnet/SSH登录全流程(避坑line vty和密码设置)
思科路由器远程管理全流程实战指南:从基础配置到安全登录 刚接触思科设备时,最让人头疼的莫过于那一连串看似晦涩的命令行操作。记得我第一次尝试配置路由器远程访问时,明明按照教程一步步操作,却始终无法通过Telnet连接ÿ…...

英特尔将雷电3集成进CPU:如何重塑高速接口生态与USB4标准
1. 项目概述:Thunderbolt 3的十字路口与英特尔的关键抉择如果你在2017年前后关注过PC和笔记本的接口演进,一定会对那个混乱的时期记忆犹新。一边是USB 3.0/3.1 Gen 1/Gen 2各种命名让人眼花缭乱,另一边是性能强悍但曲高和寡的Thunderbolt&…...

告别格式烦恼:北航毕业论文LaTeX模板的5步终极指南
告别格式烦恼:北航毕业论文LaTeX模板的5步终极指南 【免费下载链接】BUAAthesis 北航毕设论文LaTeX模板 项目地址: https://gitcode.com/gh_mirrors/bu/BUAAthesis 还在为毕业论文格式调整而烦恼吗?想象一下,你已经花费数月时间完成了…...

芯片设计中的责任边界:从工程师素养到系统性流程构建
1. 从桥梁垮塌到芯片失效:工程师的责任边界在哪里?每次看到新闻里报道桥梁垮塌、大楼倾斜或者某个关键设备在运行中突然失效,我心里总会咯噔一下。作为一个在电子设计自动化(EDA)和半导体行业摸爬滚打了十几年的工程师…...