【python学习笔记】:Excel 数据的封装函数
对比其它编程语言,我们都知道Python最大的优势是代码简单,有丰富的第三方开源库供开发者使用。伴随着近几年数据分析的热度,Python也成为最受欢迎的编程语言之一。而对于数据的读取和存储,对于普通人来讲,除了数据库之外,最常见的就是微软的Excel。
初识Excel
Microsoft Excel是Microsoft为使用Windows和Apple Macintosh操作系统的电脑编写的一款电子表格软件。
格式区别
Excel中有xls和xlsx两种格式,它们之间的区别是:
-
文件格式不同。xls是一个特有的二进制格式,其核心结构是复合文档类型的结构,而xlsx的核心结构是XML类型的结构,采用的是基于 XML的压缩方式,使其占用的空间更小。xlsx 中最后一个 x 的意义就在于此。
-
版本不同。xls是Excel2003及以前版本生成的文件格式,而xlsx是Excel2007及以后版本生成的文件格式。
-
兼容性不同。xlsx格式是向下兼容的,可兼容xls格式。
库的使用
Python自带的模块中有针对xls格式的xlrd和xlwt模块,但这两个库仅仅是针对xls的操作,当我们要操作xlsx格式文件时,则需要使用到openpyxl第三方库。

整体思路
当使用以上几个模块的时候,从理论上我们就可以完全操作不同格式的Excel的读和写,很多人就疑惑,那这篇文章的作用是什么?我们直接学习对应的这三个模块不就好了吗?
答案就是:虽然这几个库已经把Excel的文件、表、行、列的概念完全转换为Python中的对象,但每次操作都需要遍历每一个单元格,甚至很多时候我们要花费大量的时间在思考循环单元格的边界上,这本身就是在重复造轮子,因此我花了半天时间整理了以下六个函数。
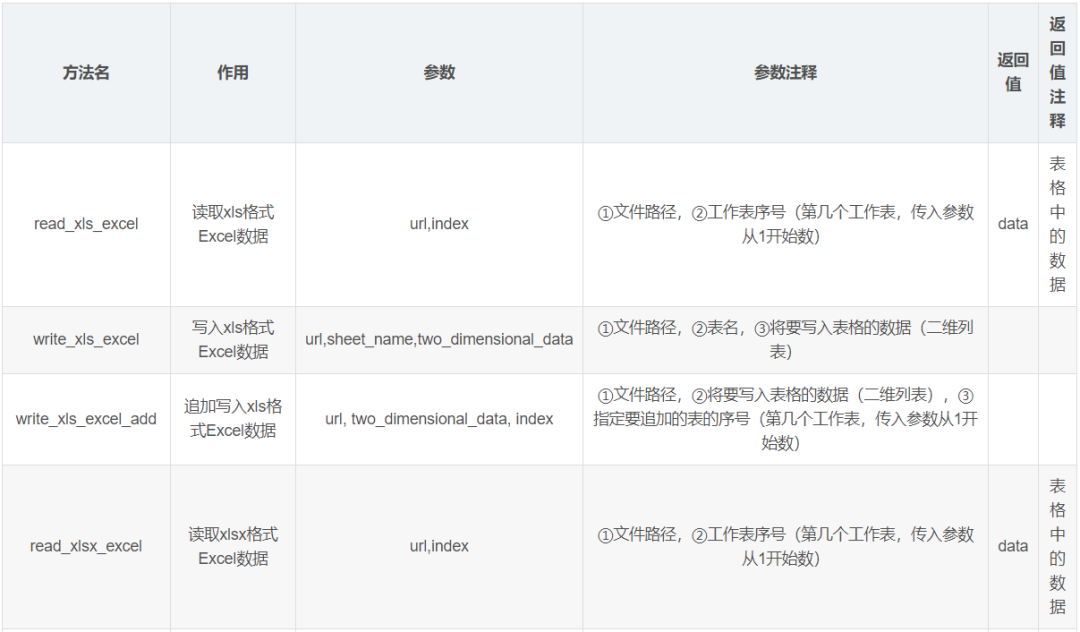

代码展示
读取xls格式文件
def read_xls_excel(url,index):'''读取xls格式文件参数:url:文件路径index:工作表序号(第几个工作表,传入参数从1开始数)返回:data:表格中的数据'''# 打开指定的工作簿workbook = xlrd.open_workbook(url)# 获取工作簿中的所有表格sheets = workbook.sheet_names()# 获取工作簿中所有表格中的的第 index 个表格worksheet = workbook.sheet_by_name(sheets[index-1])# 定义列表存储表格数据data = []# 遍历每一行数据for i in range(0, worksheet.nrows):# 定义表格存储每一行数据da = []# 遍历每一列数据for j in range(0, worksheet.ncols):# 将行数据存储到da列表da.append(worksheet.cell_value(i, j))# 存储每一行数据data.append(da)# 返回数据return data
写入xls格式文件
def write_xls_excel(url,sheet_name,two_dimensional_data):'''写入xls格式文件参数:url:文件路径sheet_name:表名two_dimensional_data:将要写入表格的数据(二维列表)'''# 创建工作簿对象workbook = xlwt.Workbook()# 创建工作表对象sheet = workbook.add_sheet(sheet_name)# 遍历每一行数据for i in range(0,len(two_dimensional_data)):# 遍历每一列数据for j in range(0,len(two_dimensional_data[i])):# 写入数据sheet.write(i,j,two_dimensional_data[i][j])# 保存workbook.save(url)print("写入成功")
追加写入xls格式文件
def write_xls_excel_add(url, two_dimensional_data, index):'''追加写入xls格式文件参数:url:文件路径two_dimensional_data:将要写入表格的数据(二维列表)index:指定要追加的表的序号(第几个工作表,传入参数从1开始数)'''# 打开指定的工作簿workbook = xlrd.open_workbook(url)# 获取工作簿中的所有表格sheets = workbook.sheet_names()# 获取指定的表worksheet = workbook.sheet_by_name(sheets[index-1])# 获取表格中已存在的数据的行数rows_old = worksheet.nrows# 将xlrd对象拷贝转化为xlwt对象new_workbook = copy(workbook)# 获取转化后工作簿中的第index个表格new_worksheet = new_workbook.get_sheet(index-1)# 遍历每一行数据for i in range(0, len(two_dimensional_data)):# 遍历每一列数据for j in range(0, len(two_dimensional_data[i])):# 追加写入数据,注意是从i+rows_old行开始写入new_worksheet.write(i+rows_old, j, two_dimensional_data[i][j])# 保存工作簿new_workbook.save(url)print("追加写入成功")
读取xlsx格式文件
def read_xlsx_excel(url, sheet_name):'''读取xlsx格式文件参数:url:文件路径sheet_name:表名返回:data:表格中的数据'''# 使用openpyxl加载指定路径的Excel文件并得到对应的workbook对象workbook = openpyxl.load_workbook(url)# 根据指定表名获取表格并得到对应的sheet对象sheet = workbook[sheet_name]# 定义列表存储表格数据data = []# 遍历表格的每一行for row in sheet.rows:# 定义表格存储每一行数据da = []# 从每一行中遍历每一个单元格for cell in row:# 将行数据存储到da列表da.append(cell.value)# 存储每一行数据data.append(da)# 返回数据return data
写入xlsx格式文件
def write_xlsx_excel(url, sheet_name, two_dimensional_data):'''写入xlsx格式文件参数:url:文件路径sheet_name:表名two_dimensional_data:将要写入表格的数据(二维列表)'''# 创建工作簿对象workbook = openpyxl.Workbook()# 创建工作表对象sheet = workbook.active# 设置该工作表的名字sheet.title = sheet_name# 遍历表格的每一行for i in range(0, len(two_dimensional_data)):# 遍历表格的每一列for j in range(0, len(two_dimensional_data[i])):# 写入数据(注意openpyxl的行和列是从1开始的,和我们平时的认知是一样的)sheet.cell(row=i + 1, column=j + 1, value=str(two_dimensional_data[i][j]))# 保存到指定位置workbook.save(url)print("写入成功")
追加写入xlsx格式文件
def write_xlsx_excel_add(url, sheet_name, two_dimensional_data):'''追加写入xlsx格式文件参数:url:文件路径sheet_name:表名two_dimensional_data:将要写入表格的数据(二维列表)'''# 使用openpyxl加载指定路径的Excel文件并得到对应的workbook对象workbook = openpyxl.load_workbook(url)# 根据指定表名获取表格并得到对应的sheet对象sheet = workbook[sheet_name]for tdd in two_dimensional_data:sheet.append(tdd)# 保存到指定位置workbook.save(url)print("追加写入成功")读取结果测试
先准备两个Excel文件,如图所示。
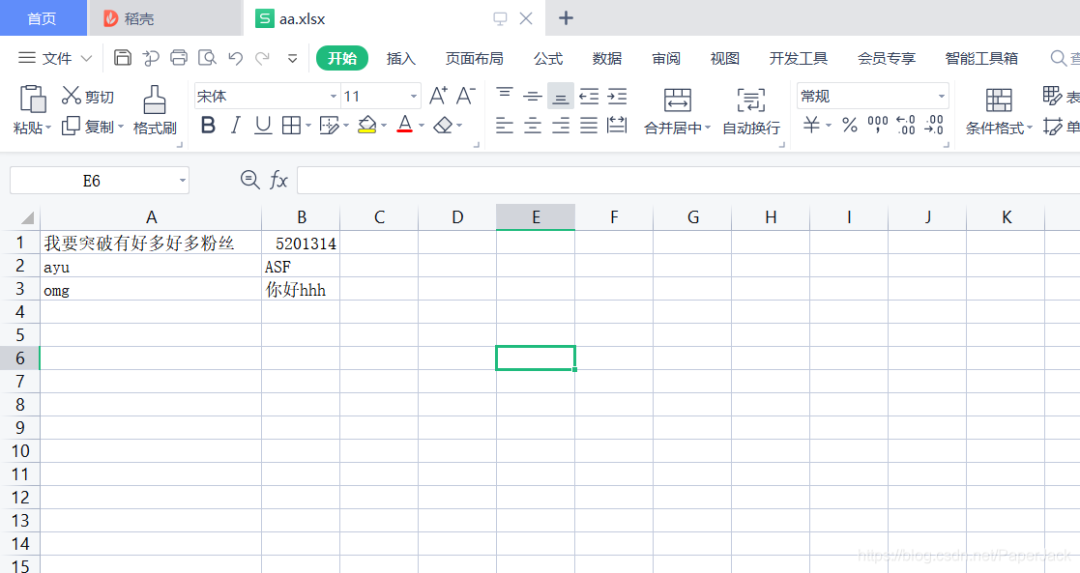
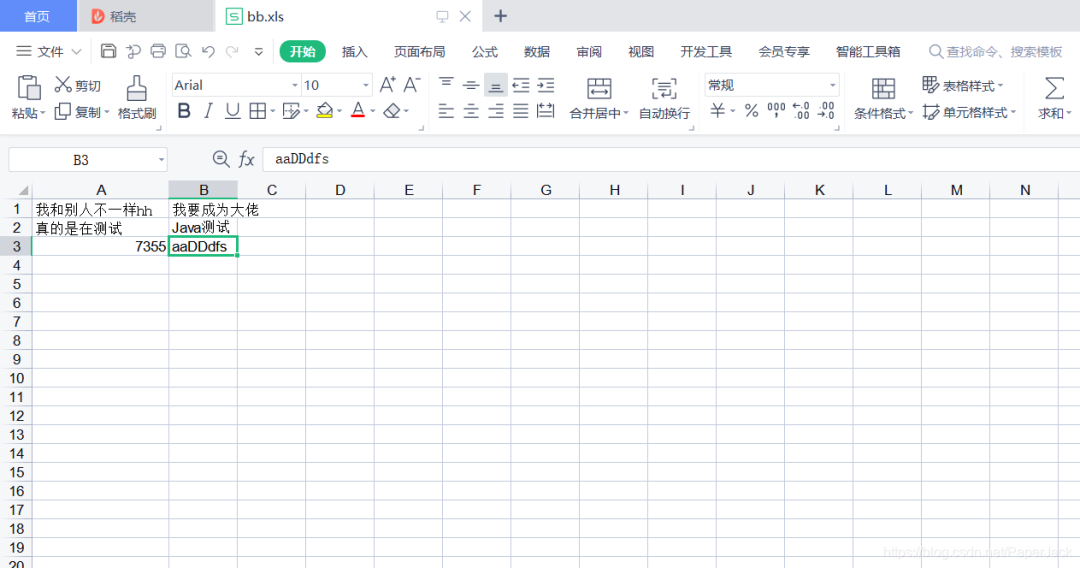
其内容如下:
测试代码:
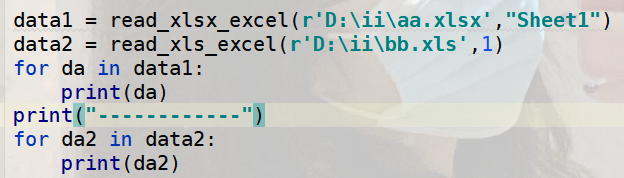
输出结果:
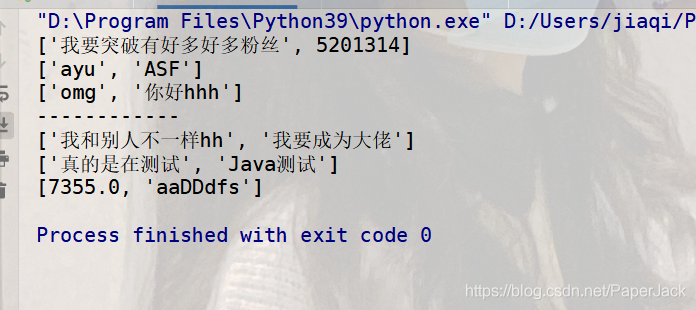
结论:表明读取并没有问题!!!接下来测试写入
写入测试
测试代码:
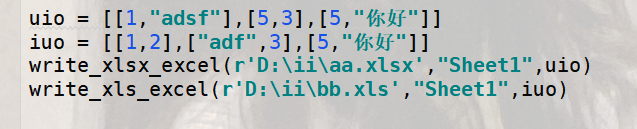
结果输出:
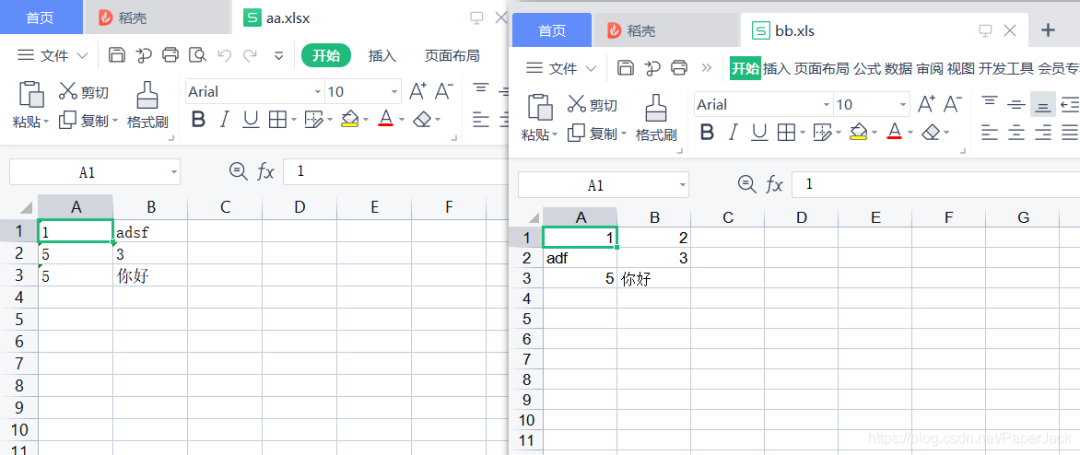
看到数据被覆盖了!接下来在上面修改后的数据的基础上测试追加写入。
追加写入测试
测试代码:
结果输出:
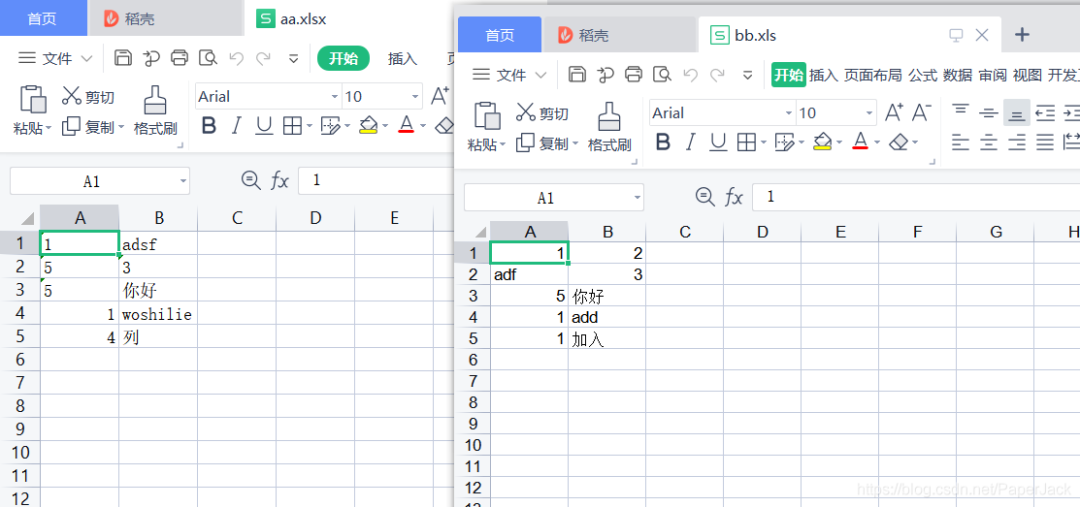
追加也没有问题。
相关文章:
【python学习笔记】:Excel 数据的封装函数
对比其它编程语言,我们都知道Python最大的优势是代码简单,有丰富的第三方开源库供开发者使用。伴随着近几年数据分析的热度,Python也成为最受欢迎的编程语言之一。而对于数据的读取和存储,对于普通人来讲,除了数据库之…...

如何获取或设置CANoe以太网网卡信息(GET篇)
CAPL提供了一系列函数用来操作CANoe网卡。但是,但是,首先需要明确一点,不管是获取网卡信息,还是设置网卡信息,只能访问CAPL程序所在的节点下的网卡,而不是节点所在的以太网通道下的所有网卡 关于第一张图中,Class节点下,有三个网卡:Ethernet1、VLAN 1.100、VLAN 1.200…...
“终于我从字节离职了...“一个年薪50W的测试工程师的自白...
我递上了我的辞职信,不是因为公司给的不多,也不是因为公司待我不好,但是我觉得,我每天看中我憔悴的面容,每天晚上拖着疲惫的身体躺在床上,我都不知道人生的意义,是赚钱吗?是为了更好…...
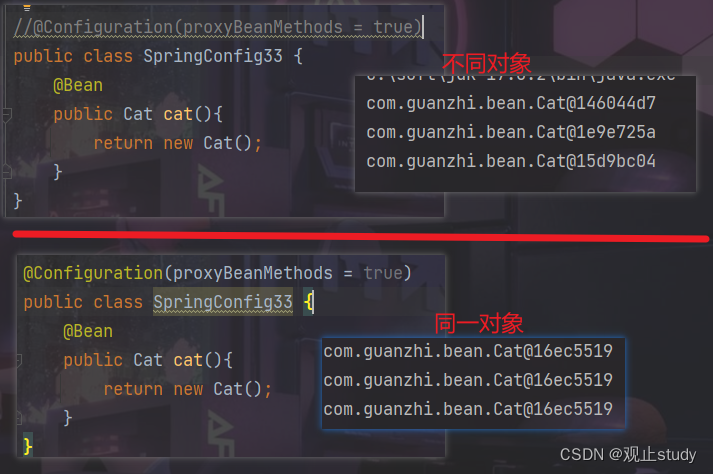
【Spring】八种常见Bean加载方式
🚩本文已收录至专栏:Spring家族学习 一.引入 (1) 概述 关于bean的加载方式,spring提供了各种各样的形式。因为spring管理bean整体上来说就是由spring维护对象的生命周期,所以bean的加载可以从大的方面划分成2种形式ÿ…...

第五回:样式色彩秀芳华
import matplotlib as mpl import matplotlib.pyplot as plt import numpy as np第五回详细介绍matplotlib中样式和颜色的使用,绘图样式和颜色是丰富可视化图表的重要手段,因此熟练掌握本章可以让可视化图表变得更美观,突出重点和凸显艺术性。…...

关于@Test单元测试
1、关于doReturndoReturn(new Test()).when(testService).updateStatusByLock(any(), any());在单元测试里这个方法可以执行到这里之间跳过不去执行,返回你想要的返回值2、关于givengiven(user.getName(any())).willReturn("张三");在单元测试里这个方法 …...

【项目实战】WebFlux整合r2dbc-mysql实战
一、背景 Webflux虽然是响应式的,但是没办法,JDBC是基于阻塞IO实现的,所以无法真正的威力发挥不出来。 但是,Webflux一旦整合了R2DBC之后,那么它将不再受限于数据库连接了,真正打通了响应式应用的任督二脉,性能才被释放。 当然,除了Spring推出的R2DBC协议,还有Orac…...

go版本分布式锁redsync使用教程
redsync使用教程前言redsync结构Pool结构Mutex结构acquire加锁操作release解锁操作redsync包的使用前言 在编程语言中锁可以理解为一个变量,该变量在同一时刻只能有一个线程拥有,以便保护共享数据在同一时刻只有一个线程去操作。对于高可用的分布式锁应…...

大数据之Hudi数据湖_大数据治理_简介_发展历史_特性_应用场景---大数据之Hudi数据湖工作笔记0001
支持hive spark flink 美国公司开发的~ 都在使用,这些企业都在用 支持hadoop的,更新,插入,删除 和数据增量处理 支持流式数据处理. hive是离线数仓 hive不支持事物 insert overwrite 底层后来通过这种方式支持了事物 insert overwrite处理数据很低效,因为更新是基于覆盖实现…...

射频功率放大器基于纵向导波的杆状构件腐蚀诊断方法的研究
实验名称:基于纵向导波的杆状构件腐蚀诊断方法研究方向:无损探伤测试设备:信号号发生器、安泰ATA-8202功率放大器、数据采集卡、直流电源、超声探头、钢杆、前置放大器。实验过程:图:试验装置试验装置如图3.2所示。监测…...
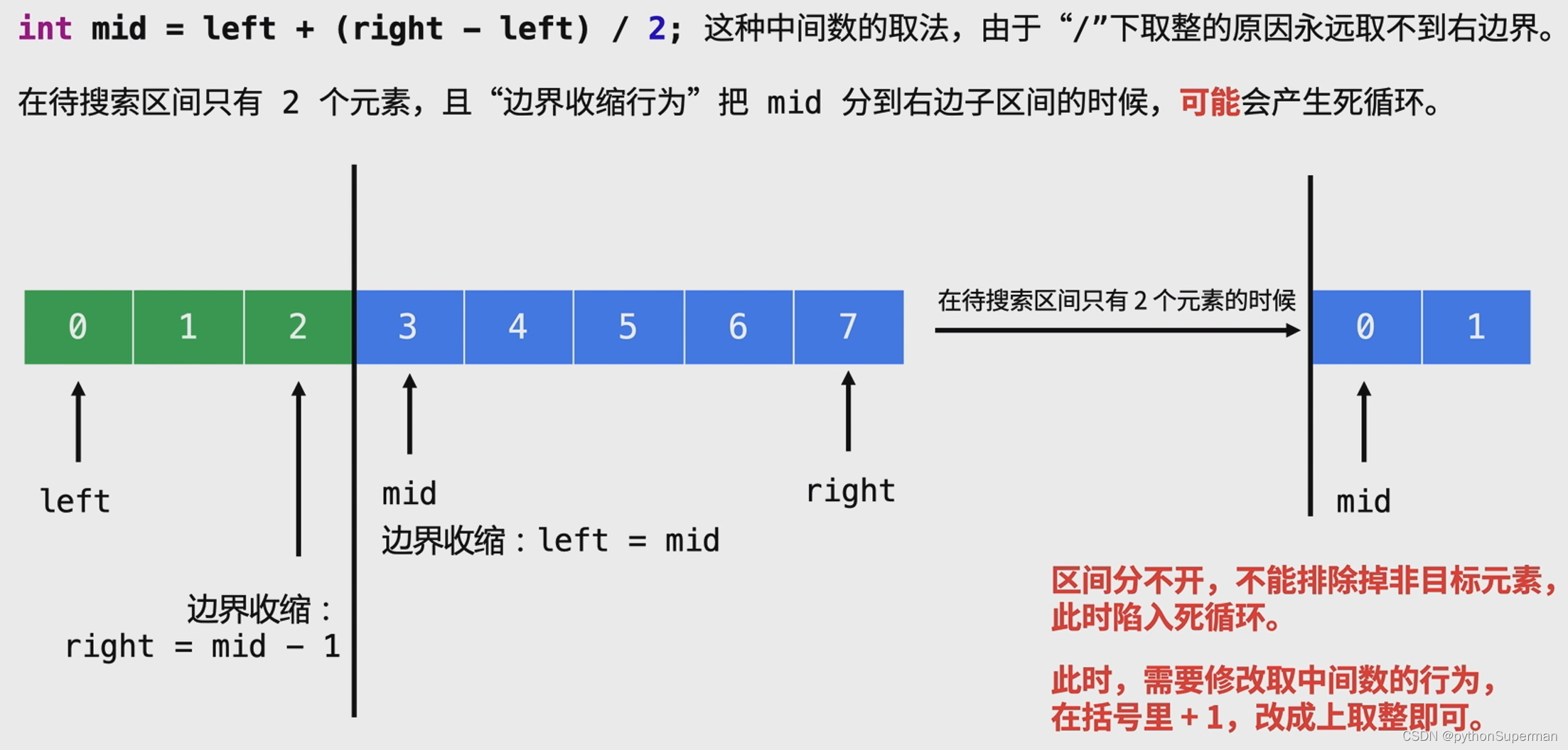
Leedcode 二分查找 理解1
一个up的理解 一、二分查找基础例题 力扣https://leetcode.cn/problems/binary-search/ 二、二分查找模板问题 带搜索区间分为3个部分: 1、[mid],直接返回 2、[left,mid-1],设置边界right mid - 1 3、[mid1,right]&#x…...

【告别篇】大家好,再见了,我转行了,在筹备创业
前言 相信大家也一直看到我的博客没有更新过了,我其实很久没有打开过博客了,也就意味着我很长一段时间都在停滞不前,没有了学习的动力。 现在我上来是想跟大家告个别 : 很多粉丝宝宝的私信我看了,但是没有回…...

Java——岛屿数量
题目链接 leetcode在线oj题——岛屿数量 题目描述 给你一个由 ‘1’(陆地)和 ‘0’(水)组成的的二维网格,请你计算网格中岛屿的数量。 岛屿总是被水包围,并且每座岛屿只能由水平方向和/或竖直方向上相…...

《代码整洁之道》笔记
1章:专业人士要有专业人士素养,要有责任心,编写代码尽可能完善没有bug,有bug也要勇于承担。坚持学习,坚持练习,保证自己的专业技能。谦虚,相互学习,与顾客达成一致2章:说…...
个人网站如何集成QQ快捷登录功能?
目录 一、网站集成QQ快捷登录的好处 二、网站接入QQ快捷登录具体步骤 (1)登录到QQ互联官网 (2)进行个人开发者认证 (3)创建网站应用 (4)填写网站资料 三、如何在本地开发环境…...
从工厂打螺丝到月薪18k测试工程师,我该满足吗?
以前我比较喜欢小米那句“永远相信美好的事情即将发生”,后来发现如果不努力不可能有美好的事情发生!01高中毕业进厂5年,创业经商多次战败,为了生计辗转奔波高中毕业后我就进了工厂,第一份工作是做模具加工。从500元一…...

【相关分析-高阶绘图】MATLAB实现皮尔逊相关分析-散点直方图
虽然皮尔逊相关分析很常见,但如何更好的展现相关性、散点分布、柱状分布,以提升研究结果的美感和冲击感呢?本文拟通过MATLAB绘制包含散点分布、柱状分布、线性展示的散点直方图,有助于审稿人眼前一亮。 1、Pearson相关系数原理 Pearson相关系数(Pearson Correlation Co…...

Spark性能优化二 Shuffle机制分析
(一) 什么情况下发生shuffle 在MapReduce框架中,Shuffle是连接Map和Reduce之间的桥梁,Map阶段通过shuffle读取数据并输出到对应的Reduce;而Reduce阶段负责从Map端拉取数据并进行计算。在整个shuffle过程中,…...
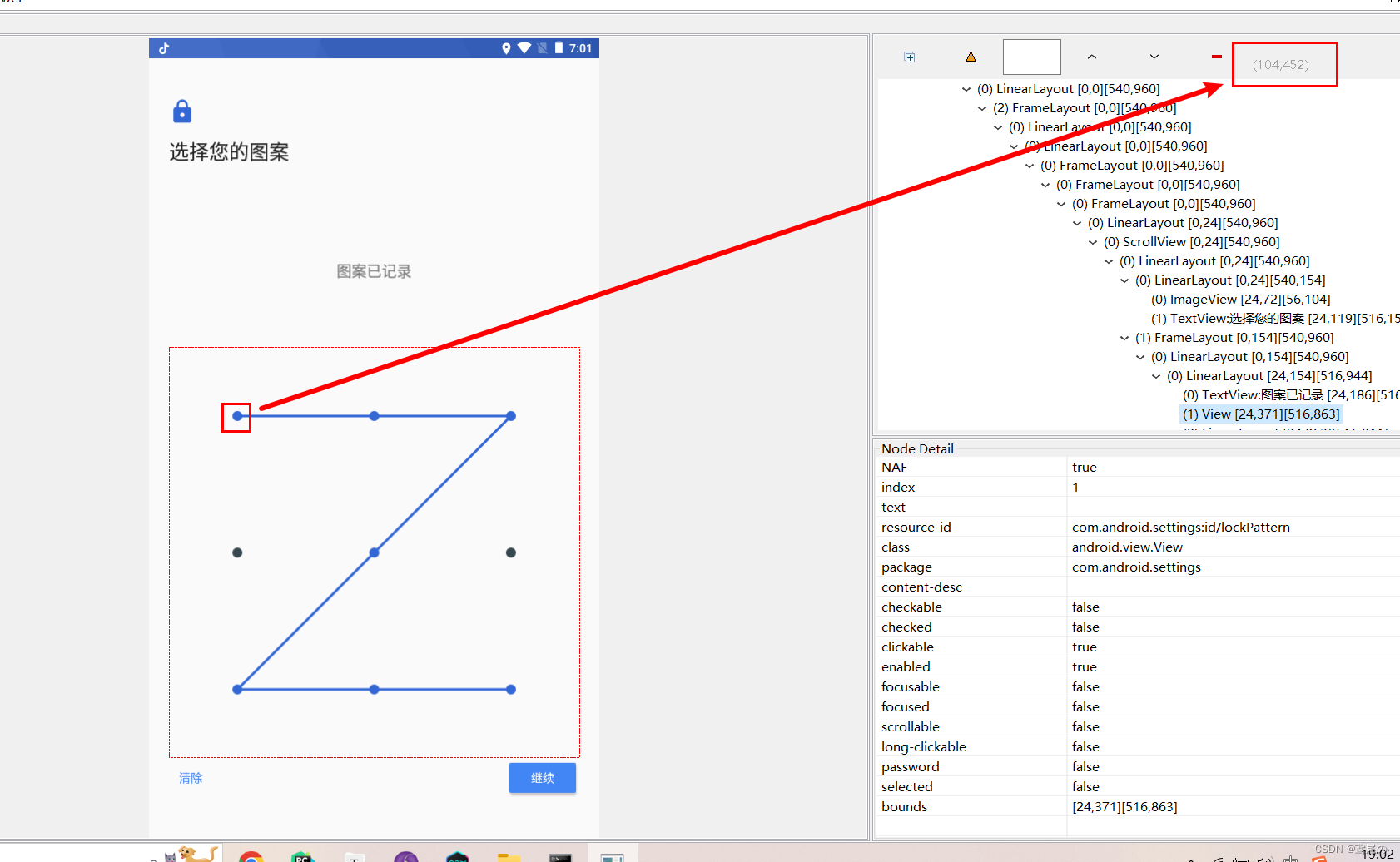
软测入门(四)Appium-APP移动测试基础
Appium 用来测试手机程序。 测试方面: 功能测试安装卸载测试升级测试兼容测试 Android系统版本不同分辨率不同网络 网络切换、中断测试使用中来电话、短信横竖屏切换 环境搭建 Java安装(查资料)Android SDK安装,配置 HOME和P…...

华为OD机试用Python实现 -【集五福】 |老题且简单
华为OD机试题 最近更新的博客华为 OD 机试 300 题大纲集五福题目描述输入描述输出描述示例一输入输出示例二输入输出代码编写思路Python 代码最近更新的博客 华为od 2023 | 什么是华为od,od 薪资待遇,od机试题清单华为OD机试真题大全,用 Python 解华为机试题 | 机试宝典...

条件生成对抗网络实现可控人脸老化建模
1. 项目概述:用条件生成对抗网络实现可控的人脸老化模拟“Face Aging Using Conditional GANs”——这个标题一出现,我就知道它不是那种调个预训练模型跑个demo的轻量级练习。它直指一个在计算机视觉与人机交互交叉领域里既经典又棘手的问题:…...

基于GAN的端到端ISP:用AI学习从RAW到RGB的图像处理革命
1. 项目概述:从“拍”到“算”的ISP革命在计算机视觉和图像处理领域,图像信号处理器(ISP)一直扮演着“幕后英雄”的角色。它负责将相机传感器捕捉到的原始、未经处理的RAW Bayer数据,转换为我们手机相册里那些色彩鲜艳…...
)
RT-Thread Sensor框架实战:5分钟搞定INA226电流电压功率监测(含I2C避坑指南)
RT-Thread Sensor框架实战:5分钟搞定INA226电流电压功率监测(含I2C避坑指南) 在嵌入式系统开发中,精准监测电流、电压和功率是许多应用场景的核心需求,无论是电池管理系统、智能硬件功耗分析,还是工业设备状…...

别再只用欧氏距离了!用Python手写曼哈顿距离,搞定KNN和聚类中的特征选择难题
曼哈顿距离实战:用Python优化KNN与聚类算法特征选择 在机器学习项目中,我们常常默认使用欧氏距离作为度量标准,却忽略了其他距离函数的独特价值。曼哈顿距离(Manhattan Distance)作为L1范数的典型代表,在处…...

【PHP】编写php扩展
【PHP】编写php扩展 第一步 下载PHP的源代码,如php-5.4.16。解压后进入php-5.4.16/ext目录。输入 ./ext/_skel –extnamemyext,myext就是扩展的名称,执行后生成myext目录。 ext/_skel是PHP官方提供的用于生成php扩展骨架代码的工具。 cd myex…...

OpenClaw 接入微信 / 企业微信完整教程
本文介绍如何通过 OpenClaw 框架,将个人微信和企业微信接入 AI Agent,实现「AI 自动回复」的功能。适用于树莓派、Mac/Windows 电脑、NAS 或云服务器等各类设备。 一、环境准备 1.1 安装 OpenClaw OpenClaw 是核心运行环境,负责加载插件、管…...

为AI智能体构建持久记忆系统:Claw Recall部署与MCP集成指南
1. 项目概述:为AI智能体构建持久、可搜索的记忆系统如果你和我一样,深度使用Claude Code、OpenClaw这类AI智能体工具进行日常开发,那你一定遇到过这个让人头疼的问题:对话上下文被压缩(Context Compaction)…...
)
AI原生多任务学习效能跃迁路径(SITS 2026工业级调参手册)
更多请点击: https://intelliparadigm.com 第一章:AI原生多任务学习:SITS 2026多目标优化实战技巧 在 SITS 2026 挑战赛中,AI 原生多任务学习(MTL)不再仅是共享底层表征的工程权衡,而是以任务语…...

Gmail只读命令行工具gcli:云端自动化邮件查询与SSH隧道授权方案
1. 项目概述:一个专为自动化场景设计的Gmail只读命令行工具 如果你和我一样,经常需要在没有图形界面的云服务器上处理邮件查询任务,那你一定对Gmail API的授权流程深恶痛绝。传统的OAuth流程要求你在浏览器里点来点去,但服务器上哪…...

一次搞清楚:Agent、Skill、Prompt、MCP
文章深入探讨了AI Agent在落地过程中面临的三大核心痛点:Prompt的临时性与不可复用性、Agent专业能力的难以沉淀与迁移、以及AI能力无法融入现有工程化流程。文章提出Agent Skills作为AI Agent的专业能力说明书,通过标准化能力描述与执行框架,…...