Pelee: A Real-Time Object Detection System on Mobile Devices(CVPR 2019)

文章目录
- 年三十
- Abstract
- Introduction
- PeleeNet:一个高效的特征提取网络
- 架构
- 消融实验
- 数据集
- 不同设计选择对性能的影响
- 在ImageNet ILSVRC 2012上的结果
- 真实设备上的速度
- Pelee:实时目标检测系统
- Overview
- 在VOC 2007上的结果
- 不同设计选择的影响
- 与其他框架的比较
- 真实设备上的速度
- 在COCO上的结果
- Conclusion
原文链接
源代码
年三十
Abstract
由现实问题出发:在计算能力和内存资源有限的移动设备上运行卷积神经网络(CNN)模型的需求日益增加,对高效模型设计进行研究
指出此前提出的高效体系结构存在的问题:如MobileNet、ShuffleNet和MobileNetV2等严重依赖于深度可分离卷积,这在大多数深度学习框架中缺乏有效的实现,而将高效模型与快速目标检测算法相结合的研究很少
基于此,作者提出了一种用传统卷积来构建的高效的PeleeNet架构
在ImageNet ILSVRC 2012数据集上,我们提出的PeleeNet实现了更高的精度,速度比NVIDIA TX2上的MobileNet和MobileNetV2快1.8倍以上。同时,PeleeNet只有MobileNet模型大小的66%。然后,我们将PeleeNet与单镜头多盒检测器(Single Shot MultiBox Detector, SSD)方法相结合,提出了一种实时目标检测系统Pelee,并对结构进行了优化,以提高速度。我们提出的检测系统名为Pelee,在PAS- CAL VOC2007上达到76.4%的mAP(平均精度),在MS COCO数据集上达到22.4 mAP,在iPhone 8上达到23.6 FPS,在NVIDIA TX2上达到125 FPS。COCO的结果优于YOLOv2,考虑到更高的精度,13.6倍的计算成本和11.3倍的模型尺寸
Introduction
人们对在严格限制内存和计算预算的情况下运行高质量的CNN模型越来越感兴趣。重复:近几年提出了一些新颖的架构,然而它们严重依赖于深度可分离卷积,缺乏有效的实现。同时,将高效模型与快速目标检测算法相结合的研究很少。
本研究尝试为图像分类任务和目标检测任务探索一种高效的CNN架构设计
主要贡献如下:
We propose a variant of DenseNet Huang et al. (2016a) architecture called PeleeNet for mobile devices.
-
我们提出了一种专为移动设备设计的DenseNet Huang等人(2016a)变体架构,称为PeleeNet
PeleeNet的一些关键特性是:• 双向致密层
受GoogLeNet(2015)的启发,我们使用双向密集层来获得不同规模的感受野。该层的一侧使用3x3的内核大小,另一侧是使用两个堆叠的3x3卷积来学习大型目标的视觉模式
• Stem Block
在Inception-v4(2017)和DSOD(2017)的激励下,我们在第一致密层之前设计了一个高效的Stem块。Stem Block可以有效地提高特征表达能力,而不会增加太多的计算成本,优于其他更昂贵的方法(例如增加第一卷积层的通道数或提高增长率)
• 瓶颈层的动态通道数
另一个亮点是瓶颈层中的通道数量根据输入形状而变化,而不是像原来的DenseNet那样固定的4倍增长率。在DenseNet中,我们观察到,对于前几个密集层,瓶颈通道的数量远远大于其输入通道的数量,这意味着对于这些层,瓶颈层增加了计算成本,而不是降低了成本• 过渡层没有压缩
我们的实验表明,DenseNet提出的压缩因子对特征表达式有损害。在过渡层中,我们总是保持输出通道的数量与输入通道的数量相同• 复合函数
为了提高实际速度,我们使用传统的后激活(卷积-批处理归一化-Relu)作为我们的复合函数,而不是DenseNet中使用的预激活(卷积+Relu+BN)。
对于后激活,可以在推理阶段将所有批处理归一化层与卷积层合并,大大加快了推理速度。为了补偿这种变化对精度造成的负面影响,我们使用了浅而宽的网络结构。我们还在最后一个密集块之后增加了1x1卷积层,以获得更强的表示能力
2. 我们对SSD的网络架构进行了速度加速优化,然后将其与PeleeNet相结合
我们提出的系统名为Pelee,在PASCAL VOC 2007上实现了76.4%的mAP,在COCO上实现了22.4的mAP。它在准确性、速度和模型大小方面优于YOLOv2 。为平衡速度和准确性而提出的主要改进包括:
• 特征映射选择
我们以一种不同于原始SSD的方式构建目标检测网络,精心选择了5个尺度特征映射(19 × 19、10 × 10、5 × 5、3 × 3和1 × 1)。为了减少计算成本,我们没有使用38 × 38特征映射。
• 残差预测块
我们遵循Lee等人(2017)提出的设计思想,鼓励特征沿着特征提取网络传递(特征重用)。对于用于检测的每个特征映射,我们在进行预测之前构建了一个残差He等(2016)块(ResBlock)
• 用于预测的小卷积核
残差预测块使我们能够应用1x1卷积核来预测类别分数和框偏移量。我们的实验表明,使用1x1核的模型与使用3x3核的模型的精度几乎相同。然而,1x1内核减少了21.5%的计算成本
- 我们在NVIDIA TX2嵌入式平台和iPhone 8上对不同的高效分类模型和不同的单阶段目标检测方法进行了基准测试(这也算?)
PeleeNet:一个高效的特征提取网络
架构
我们提出的PeleeNet的体系结构如下表1所示,四级结构是大型模型设计中常用的结构形式。ShuffleNet 使用三阶段结构,并在每个阶段开始时缩小特征图的大小。尽管这可以有效地降低计算成本,但我们认为早期特征对于视觉任务非常重要,过早减小特征映射大小会损害表征能力。因此,我们仍然保持四阶段结构。前两个阶段的层数被特别控制在一个可接受的范围内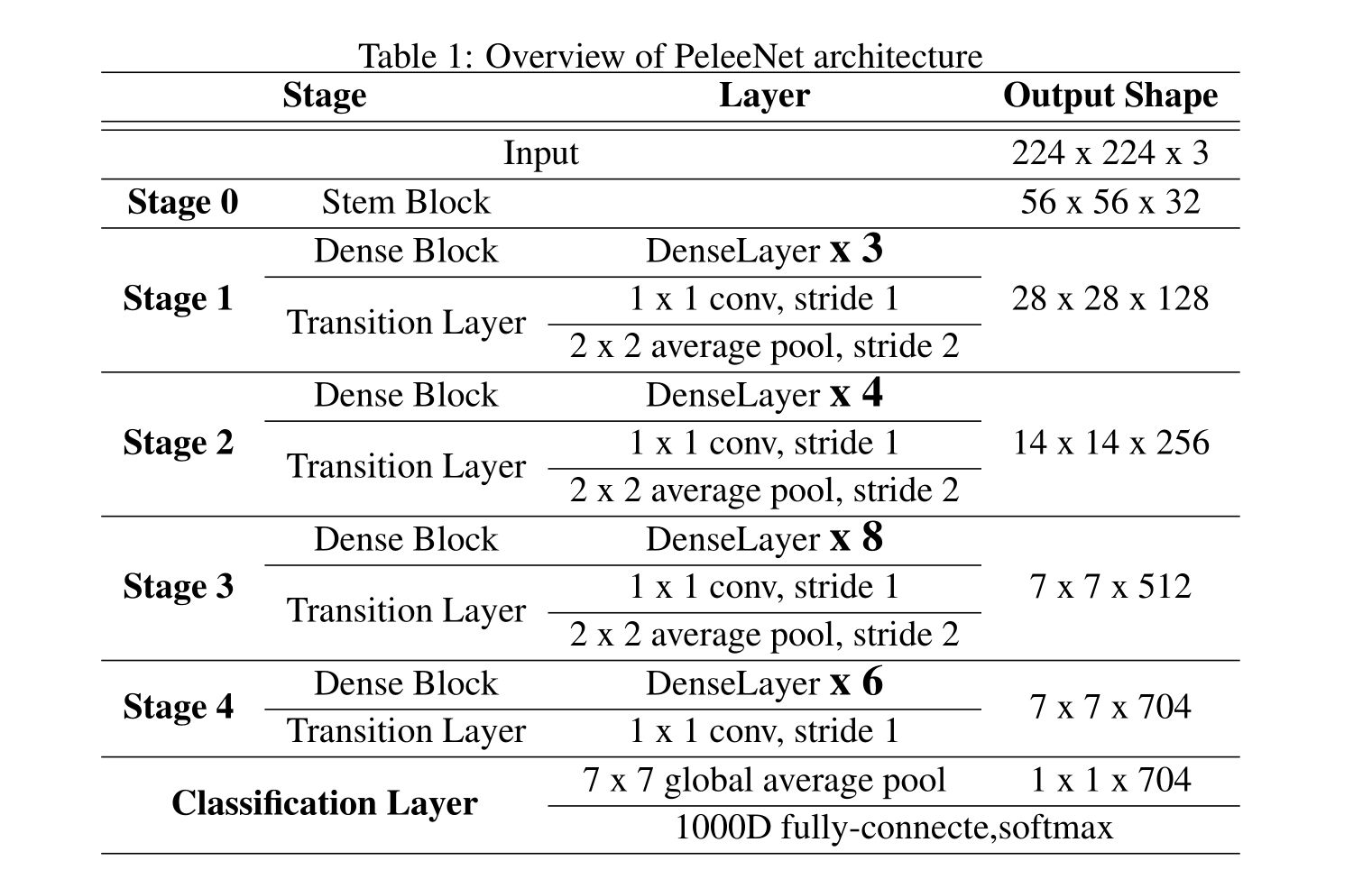
消融实验
数据集
我们为消融研究建立了一个定制的斯坦福犬数据集。Stanford Dogs的数据集包含来自世界各地的120个品种的狗的图像。该数据集使用来自ImageNet的图像和注释构建,用于细粒度图像分类任务。我们认为用于这类任务的数据集足够复杂,足以评估网络架构的性能。然而,在最初的斯坦福狗数据集中,只有14580张训练图像,每个类大约120张图像,这不足以从头开始训练模型。我们没有使用原始的斯坦福狗,而是根据斯坦福狗使用的ImageNet模型构建了ILSVRC 2012的子集。训练数据和验证数据都是从ILSVRC 2012数据集中精确复制的。本数据集的内容:
• 类别数量:120
• 训练图像数量:150,466
• 验证图像数量:6,000
不同设计选择对性能的影响
我们建立了一个类似DenseNet的网络,称为DenseNet-41作为我们的基线模型,它和最初的DenseNet有两个不同:
-
第一个卷积层的通道数改为24而不是64,卷积核大小也由77改为33
-
调整每个密集块的层数以满足计算预算
本节中的所有模型都是由PyTorch训练的,小批量大小为256,epoch为120。我们在ILSVRC 2012上遵循ResNet中使用的大多数训练设置和超参数。
表2显示了各种设计选择对性能的影响。可以看到的是后激活降低了精度,但最后仍然采用是为了减少计算成本,提高速度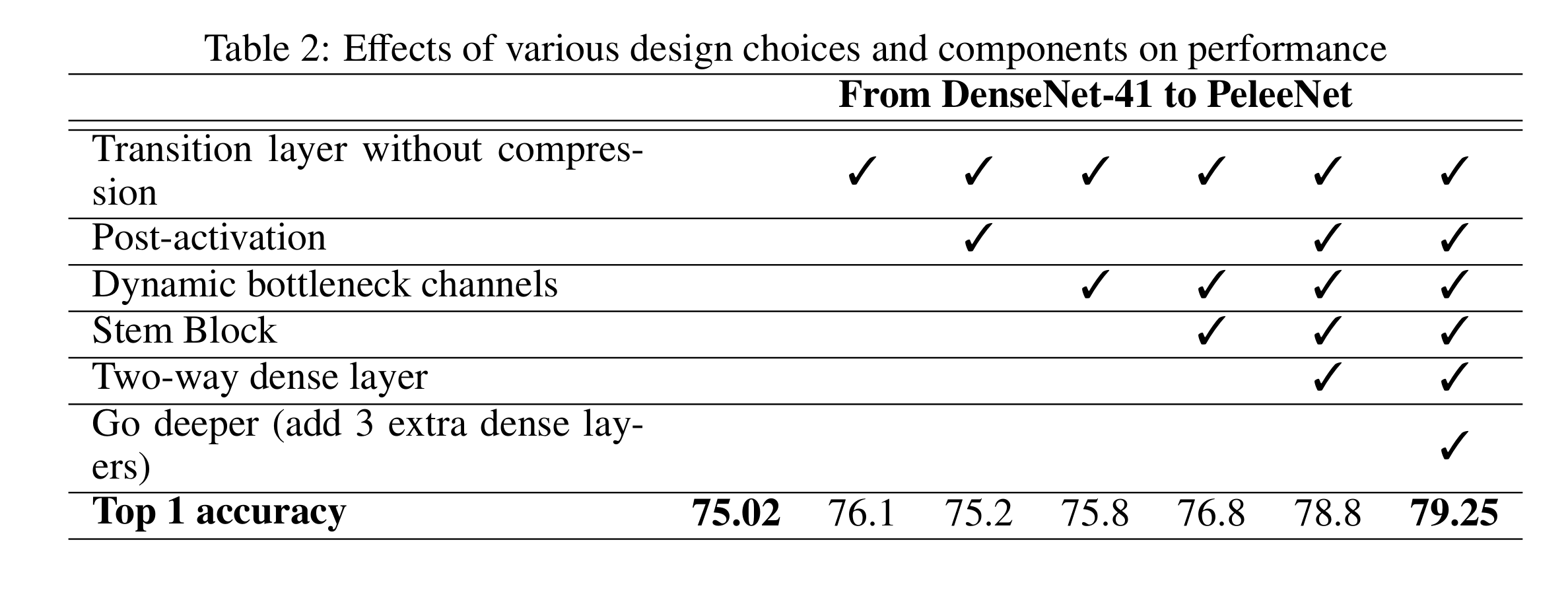
在ImageNet ILSVRC 2012上的结果
PeleeNet是由PyTorch训练的,在两个gpu上的小批处理大小为512,该模型是用余弦学习率退火计划训练的
初始学习率设置为0.25,总次数为120 epoch。然后,对模型进行微调,初始学习率为5e-3,共20 epoch。其他超参数与斯坦福狗数据集上使用的参数相同
余弦学习率退火:
表示学习率以余弦形状衰减(epoch t (t <= 120)的学习率设为0.5∗lr∗(cos(π∗t/120) + 1)。
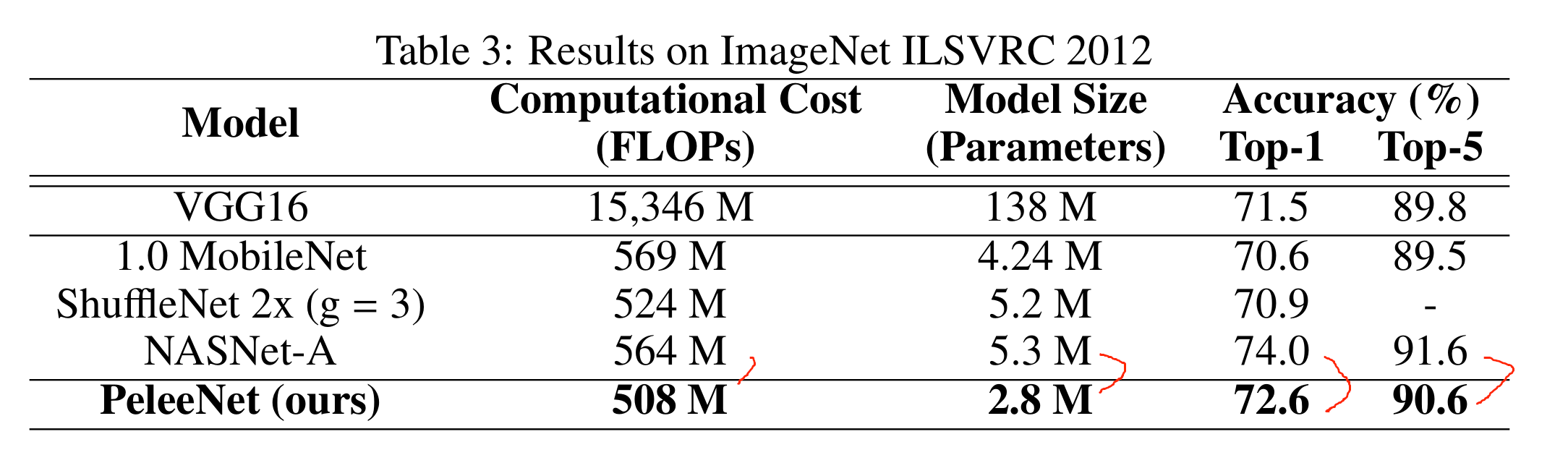
从表三可以看出:PeleeNet计算成本低,模型小,精度略不如NASNet-A
真实设备上的速度
计算FLOPs(乘法累加的个数)被广泛用于衡量计算成本。然而,它不能取代在真实设备上的速度测试,因为还有许多其他因素可能会影响实际的时间成本,例如缓存、I/O、硬件优化等。本节将对高效机型在iPhone 8和NVIDIA TX2嵌入式平台上的性能进行评估。速度是通过处理100张图片的平均时间来计算的。我们对100张图片分别进行10次处理,取平均时间
从表4可以看出,在TX2上,PeleeNet比mobilenet和MobileNetV2要快得多。虽然MobileNetV2以300 FLOPs达到了很高的精度,但该模型的实际速度比569 FLOPs的MobileNet慢。

使用半精度浮点数(FP16)代替单精度浮点数(FP32)是一种被广泛使用的加速深度学习推理的方法。如图5所示,PeleeNet在FP16模式下的运行速度是FP32模式下的1.8倍。相比之下,使用深度可分离卷积构建的网络很难从TX2半精度(FP16)推理引擎中获益,例如:在FP16模式下运行的MobileNet和MobileNetV2的速度与在FP32模式下运行的速度几乎相同
在iPhone 8上,PeleeNet在小输入维度上比MobileNet慢,但在大输入维度上比MobileNet快。iPhone上的不利结果可能有两个原因:第一个原因与基于apple Metal API构建的CoreML有关。Metal是一个3D图形API,最初不是为cnn设计的。它只能保存4个通道的数据(最初用于保存RGBA数据)。高级API必须将通道分成4个切片,并缓存每个切片的结果。与传统的卷积相比,可分离卷积从这种机制中获益更多。第二个原因是PeleeNet的体系结构,PeleeNet以多分支和窄通道风格构建,具有113个卷积层。我们最初的设计被FLOPs计数误导,并且涉及不必要的复杂性
Pelee:实时目标检测系统
Overview
本节介绍了目标检测系统及针对SSD的优化。我们优化的主要目的是在可接受的精度下提高速度。除了上一小节提出的高校特征提取网络,我们还构建了一个有别于SSD的目标检测网络,并精心选择了一组5个比例的特征图。
同时,对于每个用于检测的特征映射,我们先构建残差块,然后再进行预测。我们还使用小卷积核来预测对象类别和边界框位置,以减少计算成本(Introduction中有介绍),此外,我们使用完全不同的训练超参数。
虽然这些贡献可能看起来很小,但我们注意到最终系统在PASCAL VOC2007上实现了70.9%的mAP,在MS COCO数据集上实现了22.4 mAP。COCO的结果优于YOLOv2,考虑到更高的精度,13.6倍的计算成本和11.3倍的模型尺寸。
我们的系统中用于预测的特征地图有5种尺度:19 × 19、10 × 10、5 × 5、3 × 3和1 × 1。我们没有使用38 x 38的特征地图层,以确保在速度和精度之间达到平衡**。19x19特征图被组合成两个不同比例的默认框,其他4个特征图被组合成一个比例的默认框**。
在VOC 2007上的结果
我们的目标检测系统基于SSD的源代码,批量大小设置为32,最初将学习率设置为0.005,然后分别在80k和100k迭代时降低10倍。总迭代次数为120K
不同设计选择的影响
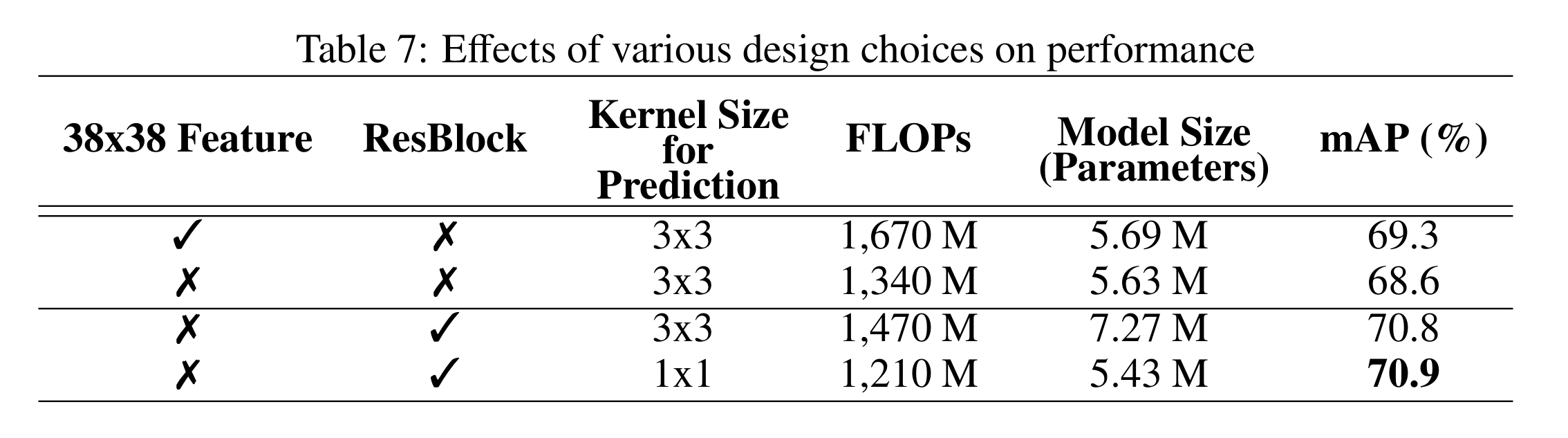
从下表我们可以看到残差预测块可以有效地提高预测精度。使用1x1核进行预测的模型与使用3x3核进行预测的模型的精度几乎相同,然而,1x1核减少了21.5%的计算成本和33.9%的模型大小,使用38*38的特征输入虽然能提升精度,但带来了过高的计算成本
与其他框架的比较
从表8我们可以看到Pelee不论丛计算成本、模型大小还是mAP都取得了非常不错的结果

真实设备上的速度
然后,我们在实际设备上评估了Pelee的实际推理速度。通过基准工具处理100张图像的平均时间计算速度。这个时间包括图像预处理时间,但不包括后处理部分(解码边界框和执行非最大抑制)的时间。通常,后处理是在CPU上完成的,它可以与在移动GPU上执行的其他部分异步执行。因此,实际速度应该非常接近我们的测试结果。
尽管在Pelee中使用残差预测块增加了计算成本,但Pelee的实际运行速度仍优于MobileNet,在FP16模式下尤其明显
在COCO上的结果
Pelee不仅比SSD+MobileNet更准确,而且在mAP[0.5:0.95]和mAP0.75上也比YOLOv2 更准确。与此同时,Pelee的速度比YOLOv2快3.7倍,模型尺寸比YOLOv2小11.3倍
总的来说,Pelee在速度和精度之间取得了最佳权衡
Conclusion
深度可分离卷积并不是建立高效模型的唯一方法,我们提出的PeleeNet和Pelee使用常规卷积构建,并在ILSVRC 2012, VOC 2007和COCO上取得了令人信服的结果
通过将高效的架构设计与移动GPU和硬件指定的优化运行库相结合,我们能够对移动设备上的图像分类和目标检测任务进行实时预测。例如,我们提出的目标检测系统Pelee在iPhone 8上可以运行23.6 FPS,在NVIDIA TX2上可以运行125 FPS,并且精度很高
相关文章:
Pelee: A Real-Time Object Detection System on Mobile Devices(CVPR 2019)
文章目录 年三十AbstractIntroductionPeleeNet:一个高效的特征提取网络架构消融实验数据集不同设计选择对性能的影响 在ImageNet ILSVRC 2012上的结果真实设备上的速度 Pelee:实时目标检测系统Overview在VOC 2007上的结果不同设计选择的影响与其他框架的比较真实设备…...
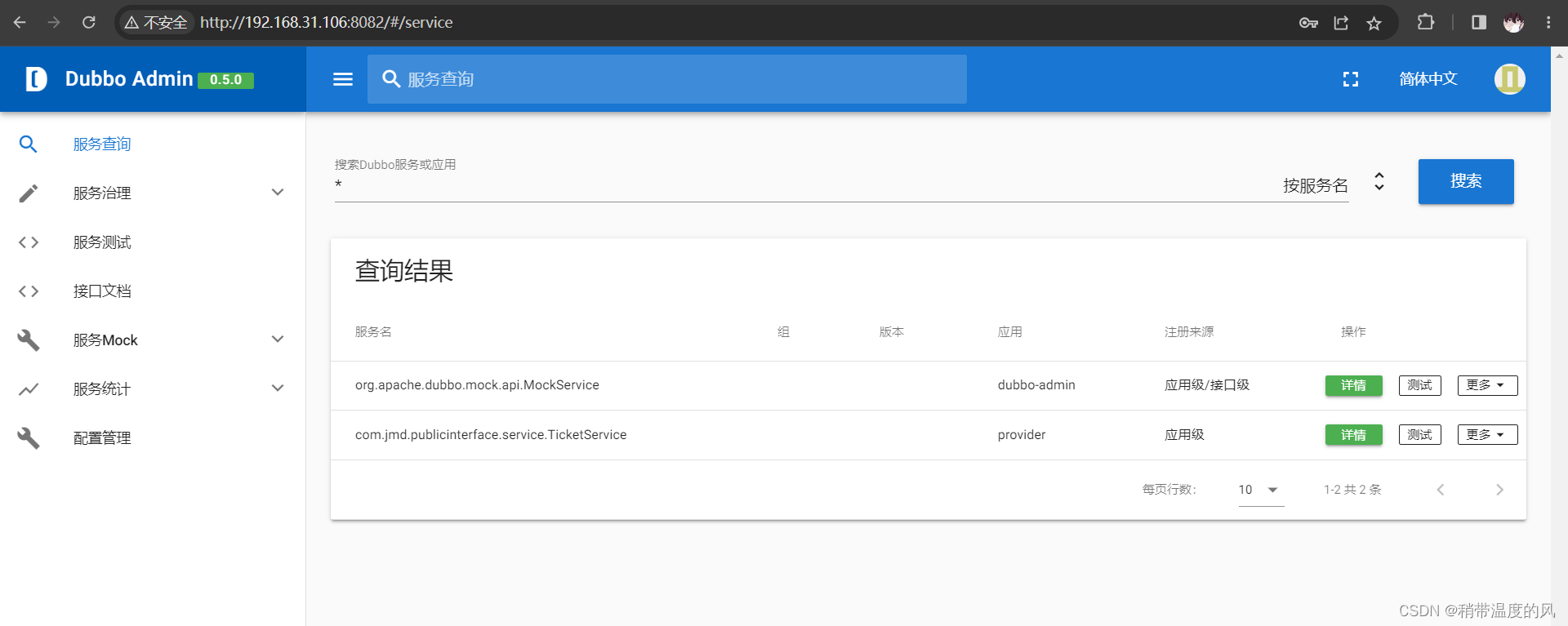
分布式理论 | RPC | Spring Boot 整合 Dubbo + ZooKeeper
一、基础 分布式理论 什么是分布式系统? 在《分布式系统原理与范型》一书中有如下定义:“分布式系统是若干独立计算机的集合,这些计算机对于用户来说就像单个相关系统”; 分布式系统是由一组通过网络进行通信、为了完成共同的…...
局域网其他pc如何访问宿主机虚拟机IP?
文章目录 背景贝瑞蒲公英设置虚拟机网络连接测试 背景 使用贝瑞蒲公英异地组网,将家里的pc作为pgsql服务器在公司使用,但是虚拟机的ip和端口访问不了 贝瑞蒲公英 设置虚拟机网络 就是添加端口转发规则 连接测试 公网内其他pc连接测试 可以看到已经连接成…...

U8 语法制导翻译技术
文章目录 一、总述二、翻译文法1、概念 三、语法制导翻译1、概念2、带属性的翻译文法3)综合属性4)继承属性5)举例 3、 L-属性翻译文法(L-ATG)1)概念2)求值规则 4、简单赋值形式的L-ATGÿ…...

剑指offer A + B
剑指offer A B 题目 输入两个整数,求这两个整数的和是多少。 输入格式 输入两个整数A,B,用空格隔开,0≤A,B≤10的8次幂 输出格式 输出一个整数,表示这两个数的和 样例输入: 3 4样例输出: 7参考答…...
gitlab(gitlab-ce)下载,离线安装
目录 1.下载 2.安装 3.配置 4.启动 5.登录 参考: 1.下载 根据服务器操作系统版本,下载对应的RPM包。 gitlab官网: The DevSecOps Platform | GitLab rpm包官网下载地址: gitlab/gitlab-ce - Results in gitlab/gitlab-ce 国内镜像地…...
Jmeter接口测试断言
一、响应断言 对服务器的响应接口进行断言校验,来判断接口测试得到的接口返回值是否正确。 二、添加断言 1、apply to: 通常发出一个请求只触发一个请求,所以勾选“main sampie only”就可以;若发一个请求可以触发多个服务器请…...

Temu、Shein、OZON测评自养号,IP和指纹浏览器的优缺点分析
随着全球电子商务的飞速发展,跨境电商环境展现出巨大的潜力和机遇。然而,跨境卖家们也面临着更激烈的竞争、更严格的规定和更高的运营成本等挑战。为了在这个环境中脱颖而出,一些卖家尝试使用自动脚本程序进行浏览和下单。然而,这…...

亚信科技AntDB数据库——深入了解AntDB-M元数据锁的相关概念
AntDB-M在架构上分为两层,服务层和存储引擎层。元数据的并发管理集中在服务层,数据的存储访问在存储引擎层。为了保证DDL操作与DML操作之间的一致性,引入了元数据锁(MDL)。 AntDB-M提供了丰富的元数据锁功能ÿ…...
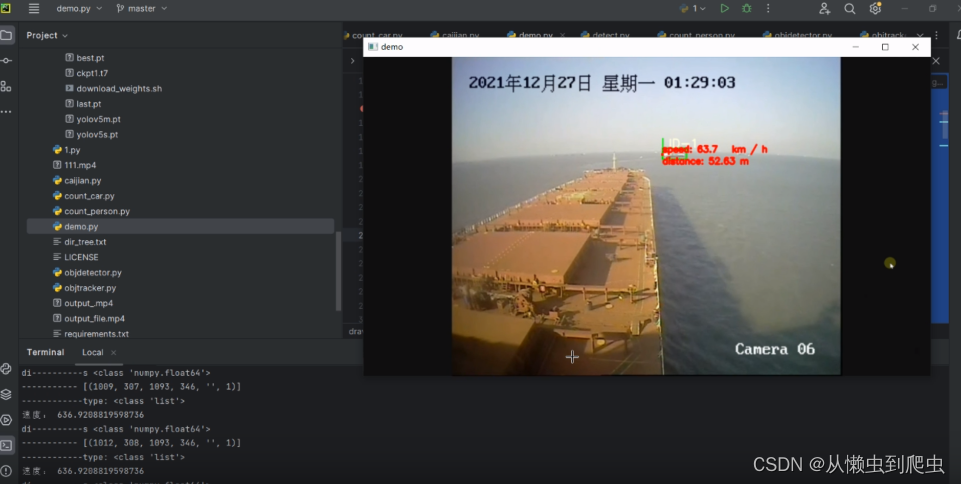
yolov5 deepsort-船舶目标检测+目标跟踪+单目测距+速度测量
目标跟踪是一种计算机视觉技术,通过分析图像或视频数据中的目标,实时追踪目标的位置和运动轨迹。在本文中,我们将详细介绍目标跟踪的原理、方法和应用,并探讨其在各个领域中的潜在价值。 1. 目标跟踪技术的基本原理 目标跟踪技术的…...

Wireshark与其他工具的整合
第一章:Wireshark基础及捕获技巧 1.1 Wireshark基础知识回顾 1.2 高级捕获技巧:过滤器和捕获选项 1.3 Wireshark与其他抓包工具的比较 第二章:网络协议分析 2.1 网络协议分析:TCP、UDP、ICMP等 2.2 高级协议分析:HTTP…...

DDD架构实践
ddd架构浅析 背景介绍 什么是ddd架构,是以ddd思想为参考,做出一份符合ddd思想的框架。 随着技术的迭代升级,越来越多的瓶颈暴露出来,性能瓶颈,系统复杂度瓶颈,这些都逐一被迭代出的技术产物解决。最终的…...
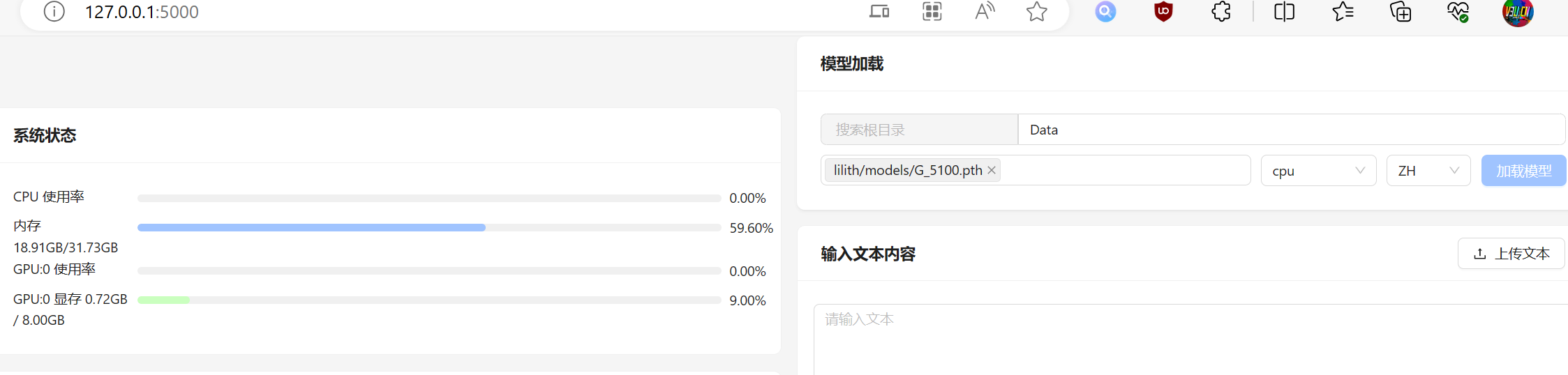
Bert-vits2-v2.2新版本本地训练推理整合包(原神八重神子英文模型miko)
近日,Bert-vits2-v2.2如约更新,该新版本v2.2主要把Emotion 模型换用CLAP多模态模型,推理支持输入text prompt提示词和audio prompt提示语音来进行引导风格化合成,让推理音色更具情感特色,并且推出了新的预处理webuI&am…...

认识缓存,一文读懂Cookie,Session缓存机制。
🏆作者简介,普修罗双战士,一直追求不断学习和成长,在技术的道路上持续探索和实践。 🏆多年互联网行业从业经验,历任核心研发工程师,项目技术负责人。 🎉欢迎 👍点赞✍评论…...

关于react native项目中使用react-native-wechat-lib@3.0.4
关于react native项目中使用react-native-wechat-lib3.0.4 插件官网安装依赖包(Android和iOS下载插件完成后记得更新依赖,)Android中配置1.在项目文件夹下面创建文件夹wxapi(如上图)2.在文件MainApplication.java中如下…...
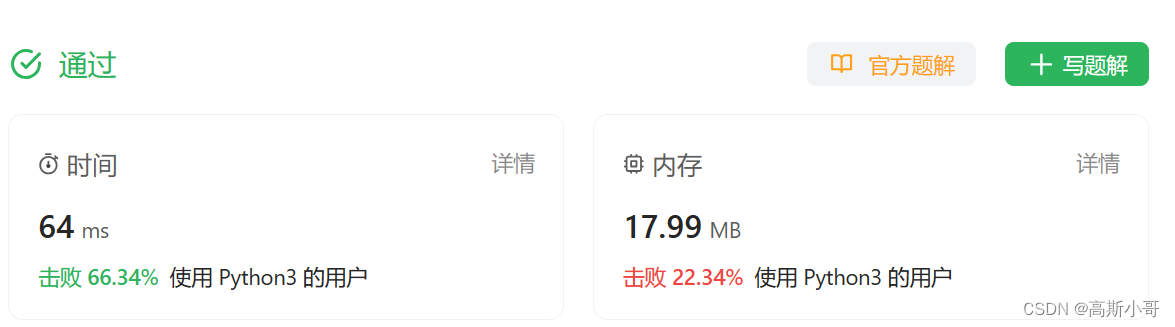
【LeetCode刷题笔记(8-1)】【Python】【接雨水】【动态规划】【困难】
文章目录 引言接雨水题目描述提示 解决方案1:【动态规划】结束语 接雨水 引言 编写通过所有测试案例的代码并不简单,通常需要深思熟虑和理性分析。虽然这些代码能够通过所有的测试案例,但如果不了解代码背后的思考过程,那么这些代…...
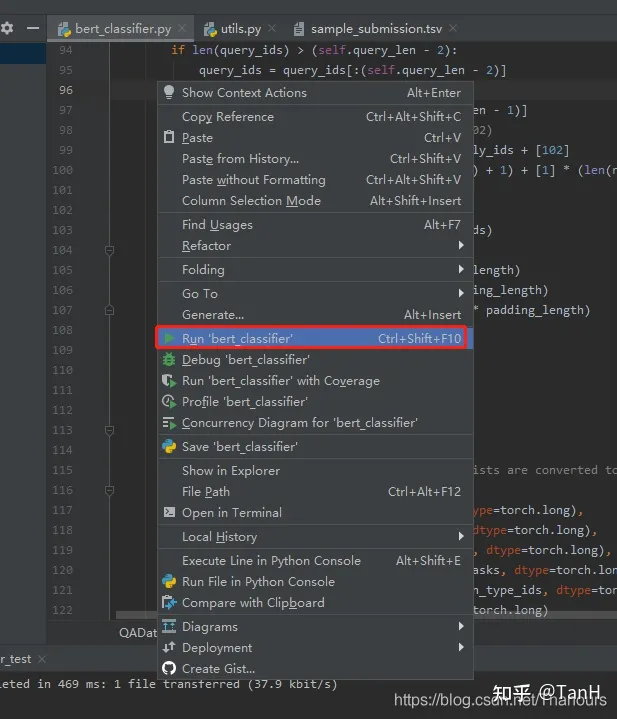
pycharm通过ssh连接远程服务器的docker容器进行运行和调试代码
pycharm连接远程服务器的docker容器通常有两种方法: 第一种:pycharm通过ssh连接已在运行中的docker容器 第二种:pycharm连接docker镜像,pycharm运行代码再自动创建容器 第一种方法比较通用简单,作者比较推崇。 条件…...
Chrome2023新版收藏栏UI改回旧版
版本 120.0.6099.109(正式版本)Chrome浏览器菜单新版、旧版的差异 想要将书签、功能内容改回旧版的朋友可以网址栏输入:「chrome://flags」,接着搜寻「Chrome Refresh 2023」。 最后将 Chrome Refresh 2023、Chrome Refresh 2023…...

WebSocket与JavaScript:实现实时获取位置
一、WebSocket介绍 WebSocket是一种在单个TCP连接上进行全双工通信的协议。与传统的HTTP请求相比,WebSocket能够在服务器和客户端之间建立持久连接,实现实时数据传输。WebSocket提供了较低的延迟和高效的数据传输。在实时舆情监测中,它能够实…...

一种解决Qt5发布release文件引发的无法定位程序输入点错误的方法
目录 本地环境问题描述分析解决方案 本地环境 本文将不会解释如何利用Qt5编译生成release类型的可执行文件以及如何利用windeployqt生成可执行的依赖库,请自行百度。 环境值操作系统Windows 10 专业版(22H2)Qt版本Qt 5.15.2Qt Creator版本5.0…...

终极GitHub加速方案:3步让你的下载速度飙升10倍
终极GitHub加速方案:3步让你的下载速度飙升10倍 【免费下载链接】Fast-GitHub 国内Github下载很慢,用上了这个插件后,下载速度嗖嗖嗖的~! 项目地址: https://gitcode.com/gh_mirrors/fa/Fast-GitHub 还在为GitHub的龟速下载…...

别再搞混了!Docker export和save到底啥区别?用busybox实战带你分清
深入解析Docker镜像与容器快照:从busybox实战看export与save的本质差异 在Docker的日常使用中,许多开发者经常对docker export和docker save这两个命令感到困惑。它们都能生成.tar文件,看似功能相似,实则针对完全不同的场景和对象…...
)
零基础转行网安:3个月学习路线+就业方向(2026最新)
零基础转行网安:3 个月学习路线 就业方向(2026 最新) 最近刷到很多小白在问: “2026 年零基础还能转行网安吗?”“没有学历、没有基础、不会代码,多久能找到工作?”“网上教程杂乱,…...

面试题详解:Agent 记忆管理全解析——历史对话获取、摘要记忆、事实记忆、知识图谱记忆一次讲透
1. 什么是 Agent 记忆管理?为什么这件事越来越重要?1.1 如果没有记忆,Agent 就只能“活在当下”很多人第一次接触 Agent 时,会觉得记忆似乎就是保存聊天记录。可一旦系统要跨多轮、多天、甚至跨任务持续工作,就会发现单…...
XUnity Auto Translator:3分钟为Unity游戏添加多语言支持的终极解决方案
XUnity Auto Translator:3分钟为Unity游戏添加多语言支持的终极解决方案 【免费下载链接】XUnity.AutoTranslator 项目地址: https://gitcode.com/gh_mirrors/xu/XUnity.AutoTranslator 你是否曾因语言障碍而放弃心爱的Unity游戏?或者作为开发者…...

开源物联网网关openclaw-gateway:架构解析与本地化智能家居部署实践
1. 项目概述与核心价值最近在折腾一些物联网和智能家居项目,发现一个挺有意思的东西,叫openclaw-gateway。这名字听起来有点“机械感”,claw是爪子,gateway是网关,合起来像是一个“开放爪子的网关”。乍一看可能有点摸…...

gomicro如何安装部暑
根据最新官方文档,以下是 go-micro(v5 最新版) 的完整安装与部署指南。目前最新稳定版本为 v5.16.0,推荐使用特定版本号安装以避免模块路径冲突。---一、环境准备 要求 说明 Go Go 1.21(建议最新版) …...

FastbootEnhance:让安卓设备调试变得简单高效的Windows工具箱
FastbootEnhance:让安卓设备调试变得简单高效的Windows工具箱 【免费下载链接】FastbootEnhance A user-friendly Fastboot ToolBox & Payload Dumper for Windows 项目地址: https://gitcode.com/gh_mirrors/fa/FastbootEnhance 你是否曾经在刷机、调试…...

PPTist:5分钟创建专业演示文稿的免费开源在线PPT制作工具终极指南
PPTist:5分钟创建专业演示文稿的免费开源在线PPT制作工具终极指南 【免费下载链接】PPTist PowerPoint-ist(/pauəpɔintist/), An online presentation application that replicates most of the commonly used features of MS PowerPoint, …...

告别手动!用Allegro Testprep脚本批量处理测试点,效率提升200%
Allegro Testprep脚本自动化:高密度PCB测试点优化实战指南 在高速PCB设计领域,测试点布局常常成为制约项目进度的隐形瓶颈。当面对超过500个网络的高密度主板时,传统手动调整测试点的方式会让工程师陷入无尽的重复劳动——据统计,…...