基于hfl/rbt3模型的情感分析学习研究——文本挖掘
参考书籍《HuggingFace自然语言处理详解 》
什么是文本挖掘
文本挖掘(Text mining)有时也被称为文字探勘、文本数据挖掘等,大致相当于文字分析,一般指文本处理过程中产生高质量的信息。高质量的信息通常通过分类和预测来产生,如模式识别。文本挖掘通常涉及输入文本的处理过程(通常进行分析,同时加上一些派生语言特征以及消除杂音,随后插入到数据库中) ,产生结构化数据,并最终评价和解释输出。典型的文本挖掘方法包括文本分类,文本聚类,概念/实体挖掘,生产精确分类,观点分析,文档摘要和实体关系模型 。^[1]^
自然语言处理的基本流程
准备数据集
数据集是进行NLP研究的基础,包含了大量文本数据和标注信息。数据集的质量和多样性对NLP的模型性能有着重要影响。本次作业主要是对预训练的语言模型进行微调,准备训练数据集是为了让模型能够学习到文本数据的特征和规律以更好的理解和处理自然语言。
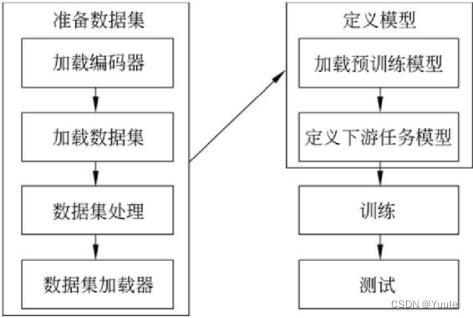 |
| 图 1 基本开发流程 |
编码器
本次作业选择的模型是 hfl/rbt3,所以使用匹配的 rbt3编码工具。
编码器主要作用是将语料库中的文本数据转化为计算机可读的编码格式。编码器可对文本数据进行清洗、预处理、分词、标注等操作,提取文本中关键信息。
数据集
数据集经过不断试错,从 wikipedia, bookcorpus, billsum等等中,最终确定选择为chn_senti_corp。
数据集经过编码器处理后,转化成了计算机可处理的数据形式,此时可以对数据集进行后续的数据处理,如缩小训练数据的规模、处理超过512个词长度的数据等等。
定义模型
预训练模型选择 hfl/rbt3,此模型是 HFL 实验室分享至HG模型。
超参数是指模型训练过程中需要预先设定的参数,参数的设定需要一定的实验经验,本次超参数设置主要参考《HuggingFace自然语言处理详解》。
训练及评估
在模型训练过程中为了方便观察模型新能变化,需要定义一个评价函数。在情感分析任务中,正确率指标是重点。
微调hfl/rbt3模型的代码实现
# -*- coding:GB2312 -*-
# %%
from transformers import AutoTokenizer,TrainingArguments,Trainer,
from transformers.data.data_collator import DataCollatorWithPadding
from transformers import AutoModelForSequenceClassification
from datasets import load_from_disk, Dataset, load_metric
import numpy as np
import torch
# %%
tokenizer = AutoTokenizer.from_pretrained('hfl/rbt3')
tokenizer.batch_encode_plus(
['一曲青溪一曲山', '鸟飞鱼跃白云间'],
truncation=True,
)
# %%
# 加载数据集
dataset_train = Dataset.from_file('./data/chn_senti_corp/chn_senti_corp-train.arrow')
dataset_test = Dataset.from_file('./data/chn_senti_corp/chn_senti_corp-test.arrow')
dataset_valid = Dataset.from_file('./data/chn_senti_corp/chn_senti_corp-validation.arrow')
# %%
# 缩小数据规模,便于测试
dataset_train= dataset_train.shuffle().select(range(3000))
dataset_test= dataset_test.shuffle().select(range(200))
# %%
#编码
def f(data):return tokenizer.batch_encode_plus(data['text'],truncation=True)
dataset_train=dataset_train.map(f,
batched=True,
batch_size=100,
# num_proc=4,
remove_columns=['text'])
# %%
dataset_test=dataset_test.map(f,
batched=True,
batch_size=100,
remove_columns=['text'])
# %%
def filter_func(data):return [len(i)<=512 for i in data['input_ids']]
dataset_train=dataset_train.filter(filter_func, batched=True, batch_size=100)
dataset_test=dataset_test.filter(filter_func, batched=True, batch_size=100)
# %%
model=AutoModelForSequenceClassification.from_pretrained('hfl/rbt3',num_labels=2)
# %%
#加载评价指标
metric = load_metric('accuracy')
#定义评价函数
from transformers.trainer_utils import EvalPrediction
def compute_metrics(eval_pred):logits, labels = eval_predlogits = logits.argmax(axis=1)return metric.compute(predictions=logits, references=labels)
# %%
#定义训练参数
args = TrainingArguments(output_dir='./output_dir/third/',evaluation_strategy='steps',eval_steps=30,save_strategy='steps',save_steps=30,num_train_epochs=2,learning_rate=1e-4,#定义学习率weight_decay=1e-2,per_device_eval_batch_size=16,per_device_train_batch_size=16,no_cuda=False,
)
# %%
#定义训练器
trainer = Trainer(
model=model,
args=args,
train_dataset=dataset_train,
eval_dataset=dataset_test,
compute_metrics=compute_metrics,
data_collator=DataCollatorWithPadding(tokenizer),
)
#评价模型
trainer.evaluate()
trainer.train()
trainer.evaluate()
结果展示
从训练前后的评价函数结果可以明显的看到微调训练的结果,见下表。
表 1 训练前后评价结果
| 模型 | eval_loss | eval_accuracy | eval_runtime | epoch |
|---|---|---|---|---|
| before | 0.698 | 0.522 | 22.22 | - |
| after | 0.239 | 0.923 | 51.68 | 2 |
训练过程中损失函数与正确率的变化可见下图。
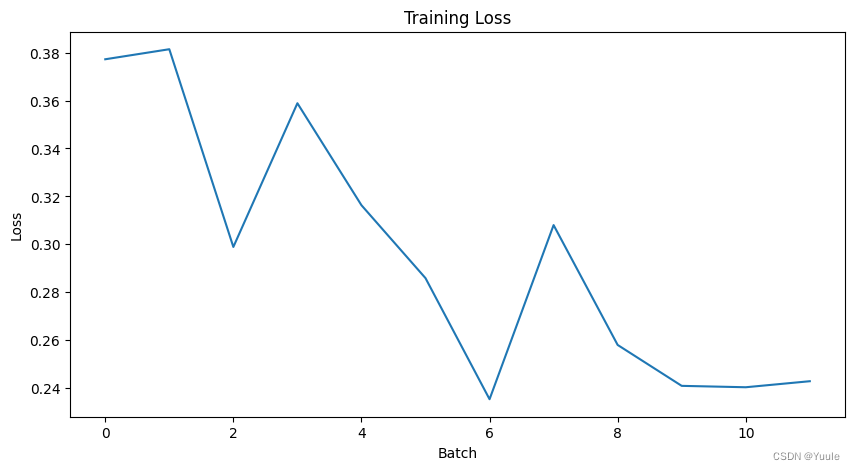 | 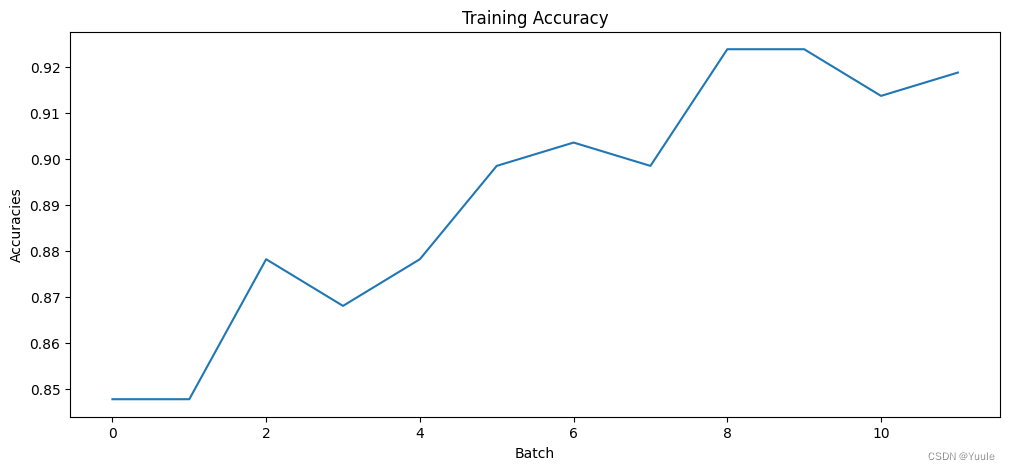 |
| 图 2 loss | 图 3 accuracy |
结语
学习初期走过不少弯路,有尝试自己挖掘文本和数据,计划整个大工程,实际操作时却遇到种种难题,网站防爬、检索数据不符合规范、不同网站私有定义太多等等。缺乏相关经验导致的结果是动手时在作业初期就遇到太多问题,作业进度缓慢,信心与耐心也逐渐下降。
在准备数据集时也走过一些误区。以下说几个遇到的问题:一是准备的数据集没有标注且与模型不匹配,导致模型训练时配置出错,无法执行训练。二是数据集过大,执行操作时对笔记本的负担很大,硬盘和存在在训练几小时后直接爆满导致训练失败。其他种种,所以准备一个合适的数据集是重中之重。
实际动手做一个新接触的作业,不能眼高手低或投机取巧让ChatGPT完成整个项目,还是需要找到一份合适的指导资料,静下心熟悉每一个操作。感谢老师及同学们的帮助,《HuggingFace自然语言处理详解》让我真正入门了NLP。
参考文献:
[1] 维基百科编者.文本挖掘[G/OL].维基百科,2019(2019-5-9) [2023-12-15]. https://zh.wikipedia.org/wiki/文本挖掘.
相关文章:
基于hfl/rbt3模型的情感分析学习研究——文本挖掘
参考书籍《HuggingFace自然语言处理详解 》 什么是文本挖掘 文本挖掘(Text mining)有时也被称为文字探勘、文本数据挖掘等,大致相当于文字分析,一般指文本处理过程中产生高质量的信息。高质量的信息通常通过分类和预测来产生&…...

计算机网络基础——常用的中英文网络述语大全,强烈建议收藏
系统网络体系结构(System Network Architecture,SNA) 国际标准化组织(International Organization for Standardization,ISO) 开放系统互连基本参考模型(Open System Interconnection Reference Model。OSI/RM) 物理层(Physical Layer) 数据终端设备…...

c++如何自定义类及成员函数
#include <iostream>using namespace std;class Box {public:double length; // 长度double breadth; // 宽度double height; // 高度// 成员函数声明double get(void);void set( double len, double bre, double hei ); }; // 成员函数定义 double Box::get(void) …...

100G云数据中心网络建设解决方案
随着数据和流量的快速增长,近年来数据中心已经进入了一个全新的100G时代。为了更高效地提供包括人工智能、虚拟现实、4K视频等在内的云计算服务,全球范围内正在大规模建设众多大型100G数据中心,如云数据中心。作为一种新型高效的基础设施&…...

Zoho Desk为何受到跨境电商企业青睐:优势与特点解析
现如今,跨境电商已成为中国外贸发展的一支重要力量,正从一种新业态成长为外贸的新常态。越来越多的国内电商玩家加入了跨境电商这个战场。跨境电商自有其特殊性,海外客户服务不好一样惨遭投诉,Zoho Desk可以帮助您赢得客户满意度&…...

git 删除仓库中多余的文件或者文件夹
目录 问题 解决方案 第一步:同步代码 第二步:删除文件 第三步:提交 第四步:推送远端 问题 在项目开发测试阶段,将无意间将本地敏感的、或无用的文件或目录不小心提交到远程仓库,该怎么解决呢。 解决方…...
)
搭建git服务器(本地局域网)
搭建git服务器(本地局域网) 创建仓库 (假定在/home/git目录下创建仓库) git init --bare sample.git克隆远程仓库到本地 git clone git192.168.0.100:/home/git/sample.git已有项目,绑定远程仓库 # 查看远程仓库绑定 git remote -v# 解除…...

如何让营销更生动,更有效!
作为专业的营销人员,我们深知在当今竞争激烈的市场环境中,如何让自己的产品或服务脱颖而出,吸引更多的潜在客户,是企业成功的关键。而中昱维信视频短信平台,正是您实现这一目标的得力助手。 一、视频短信,…...

RestTemplate请求参数需要转义 处理
项目需求 iam的token鉴权 需要带转义的回调http路径 用以下处理参数 接口仍然返回异常: public String authBack(String backUrl){ // backUrl http://192.168.1.156:sdm/String state URLEncoder.encode(state, "UTF-8"); }查了一下,Rest…...
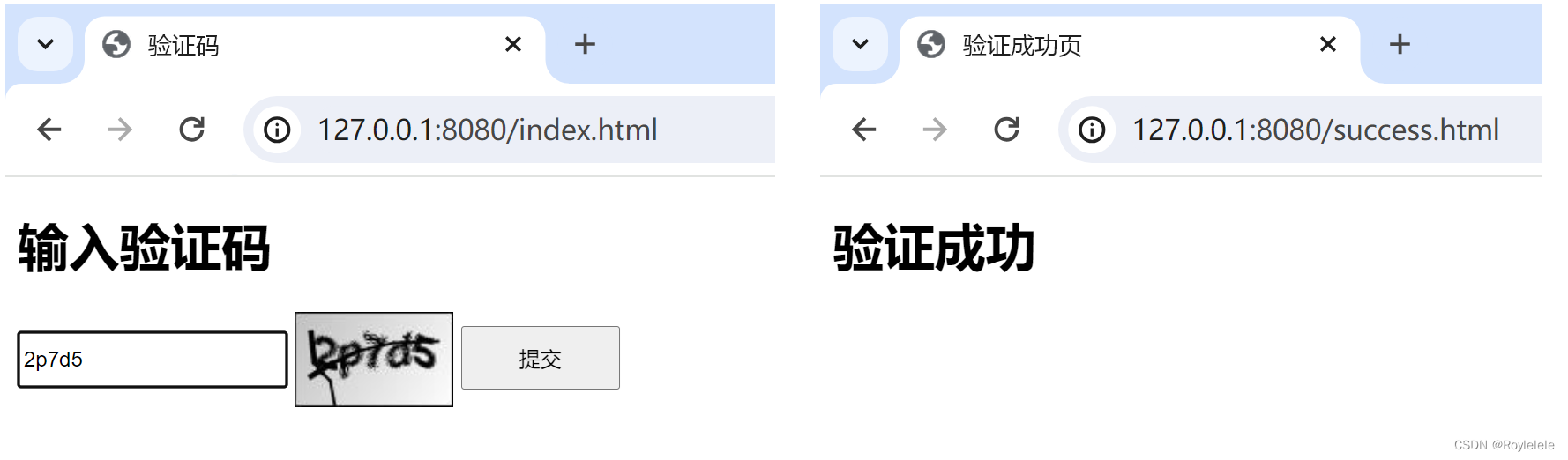
使用Kaptcha实现的验证码功能
目录 一.需求 二.验证码功能实现步骤 验证码 引入kaptcha依赖 完成application.yml配置文件 浏览器显示验证码 前端页面 登录页面 验证成功页面 后端 此验证码功能是以SpringBoot框架下基于kaptcha插件来实现的。 一.需求 1.页面生成验证码 2.输入验证码ÿ…...

【无标题】CTF之SQLMAP
拿这一题来说 抓个包 复制报文 启动我们的sqlmap kali里边 sqlmap -r 文件路径 --dump --dbs 数据库 --tables 表...
【Qt之Quick模块】1. 概述及Quick应用程序创建流程
概述 Qt的Quick模块是用于创建现代化、动态和响应式用户界面的工具集。它是基于QML(Qt Meta-Object Language)和JavaScript的。 QML是一种声明性的语言,用于描述用户界面的结构和行为。它使用层叠样式表(CSS)的语法来…...

C语言-数组指针笔试题讲解(1)-干货满满!!!
文章目录 ▶️1.sizeof和strlen的对比💯➡️1.1 sizeof是什么?💯➡️1.2sizeof用法举例💯▶️1.3strlen是什么?💯▶️1.4 strlen函数用法举例:💯▶️1.5 strlen和sizeof的对比&#…...
springboot整合vue,将vue项目整合到springboot项目中
将vue项目打包后,与springboot项目整合。 第一步,使用springboot中的thymeleaf模板引擎 导入依赖 <!-- thymeleaf 模板 --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-t…...
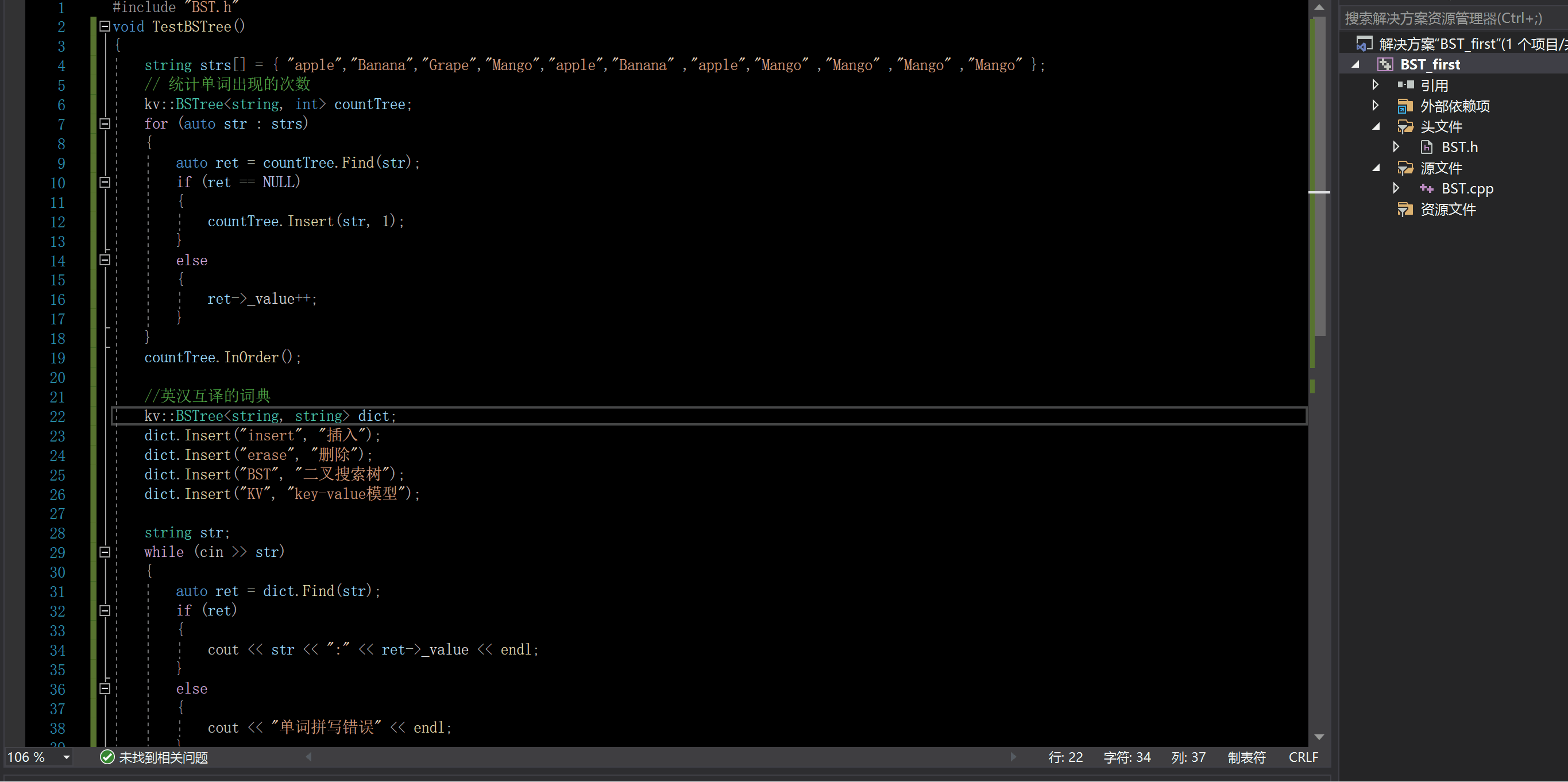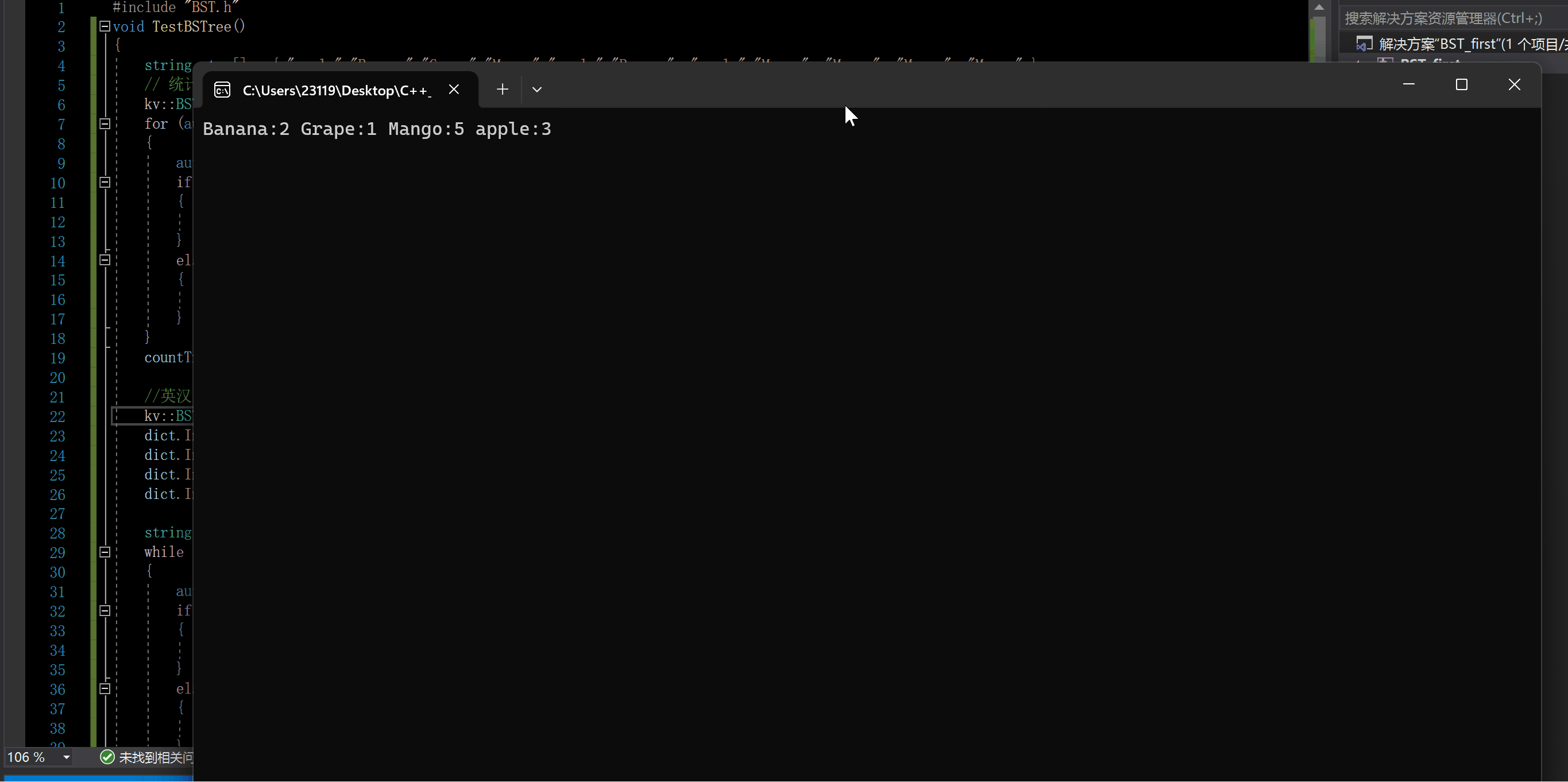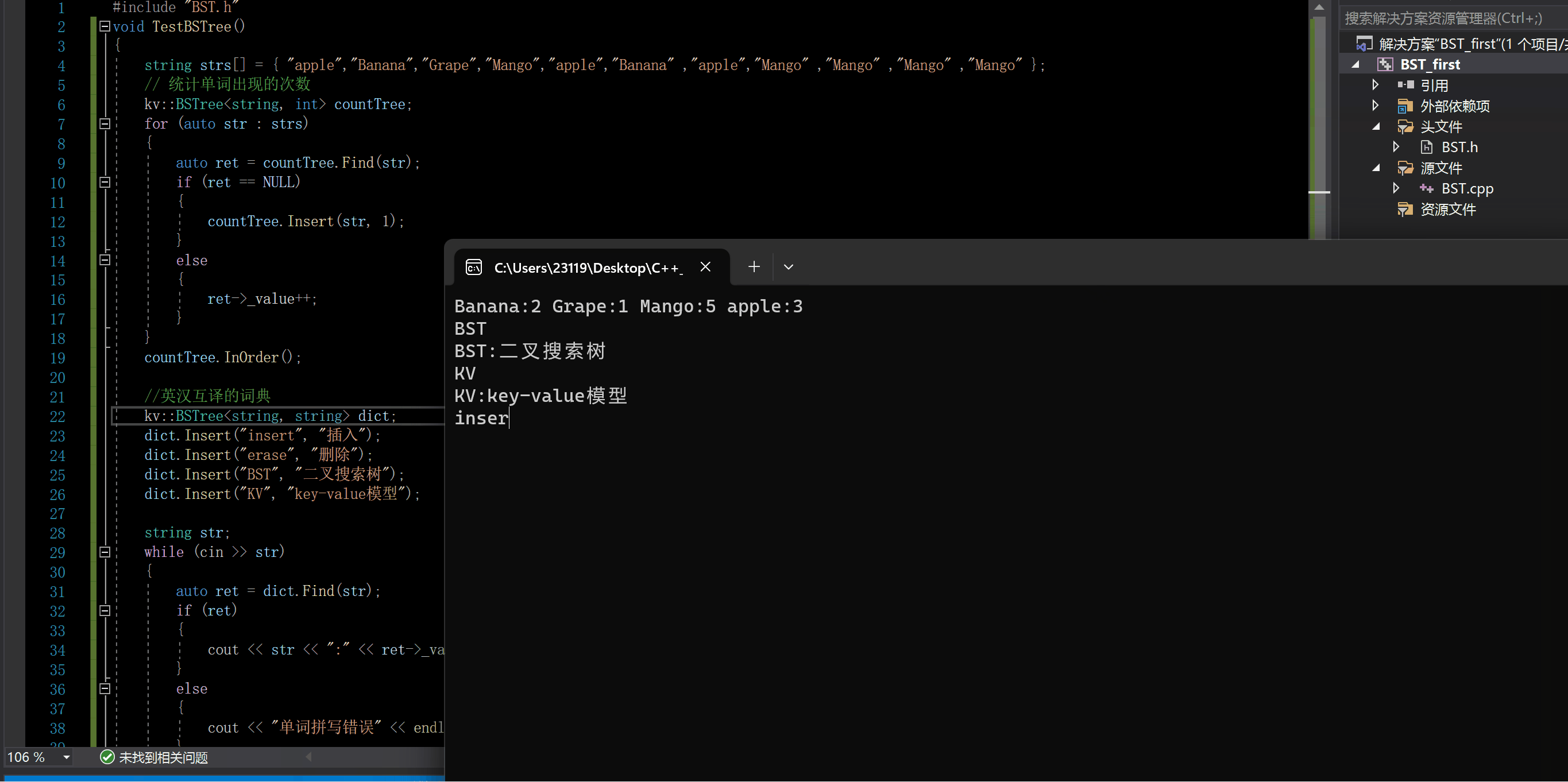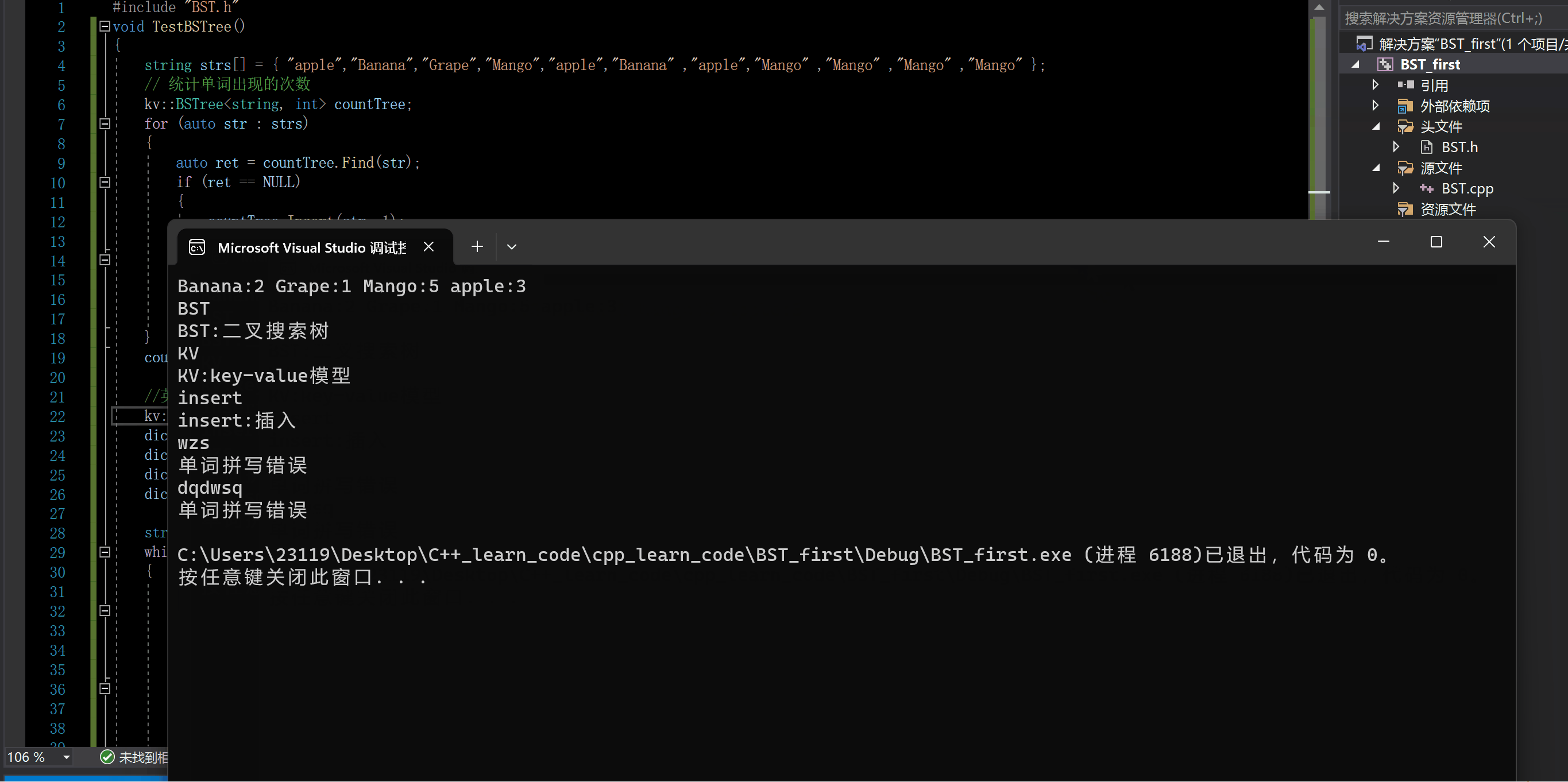
C++ 二叉搜索树(BST)的实现(非递归版本与递归版本)与应用
C 二叉搜索树的实现与应用 一.二叉搜索树的特点二.我们要实现的大致框架三.Insert四.InOrder和Find1.InOrder2.Find 五.Erase六.Find,Insert,Erase的递归版本1.FindR2.InsertR3.EraseR 七.析构,拷贝构造,赋值运算符重载1.析构2.拷贝构造3.赋值运算重载 八.Key模型完整代码九.二…...

分类预测 | Matlab实现AOA-SVM算术优化支持向量机的数据分类预测【23年新算法】
分类预测 | Matlab实现AOA-SVM算术优化支持向量机的数据分类预测【23年新算法】 目录 分类预测 | Matlab实现AOA-SVM算术优化支持向量机的数据分类预测【23年新算法】分类效果基本描述程序设计参考资料 分类效果 基本描述 1.Matlab实现AOA-SVM算术优化支持向量机的数据分类预测…...

代码随想录算法训练营第七天 | 454.四数相加II、383. 赎金信、15. 三数之和 、18. 四数之和
454.四数相加II 题目链接:454.四数相加II 给你四个整数数组 nums1、nums2、nums3 和 nums4 ,数组长度都是 n ,请你计算有多少个元组 (i, j, k, l) 能满足: 0 < i, j, k, l < nnums1[i] nums2[j] nums3[k] nums4[l] 0…...
SpringBoot 3.2.0 版本 mysql 依赖下载错误
最近想尝试一下最新的 SpringBoot 项目,于是将自己的开源项目进行了一些升级。 JDK 版本从 JDK8 升级至 JDK17。SpringBoot 版本从 SpringBoot 2.7.3 升级到 SpringBoot 3.2.0 其中 JDK 的升级比较顺利,毕竟 JDK 的旧版本兼容性一直非常好。 但是在升级…...
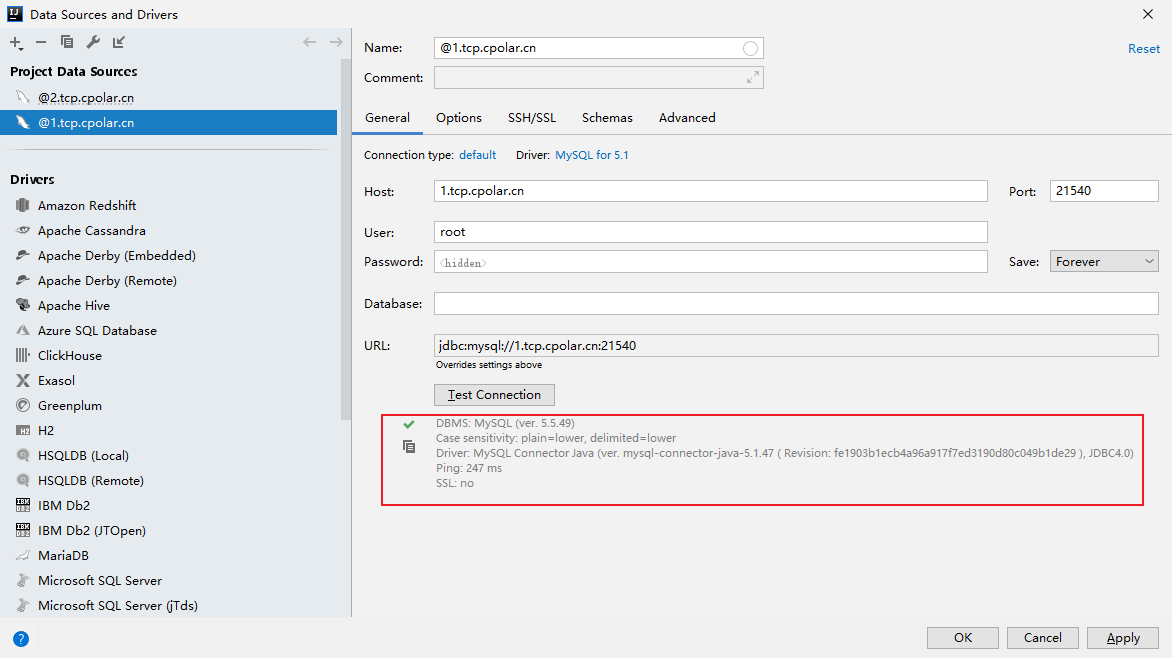
内网穿透的应用-如何结合Cpolar内网穿透工具实现在IDEA中远程访问家里或者公司的数据库
文章目录 1. 本地连接测试2. Windows安装Cpolar3. 配置Mysql公网地址4. IDEA远程连接Mysql小结 5. 固定连接公网地址6. 固定地址连接测试 IDEA作为Java开发最主力的工具,在开发过程中需要经常用到数据库,如Mysql数据库,但是在IDEA中只能连接本…...
ElasticSearch单机或集群未授权访问漏洞
漏洞处理方法: 1、可以使用系统防火墙 来做限制只允许ES集群和Server节点的IP来访问漏洞节点的9200端口,其他的全部拒绝。 2、在ES节点上设置用户密码 漏洞现象:直接访问9200端口不需要密码验证 修复过程 2.1 生成认证文件 必须要生成…...

vLLM-v0.11.0快速入门:用OpenAI接口调用本地大模型,5分钟出结果
vLLM-v0.11.0快速入门:用OpenAI接口调用本地大模型,5分钟出结果 1. 为什么选择vLLM? 1.1 什么是vLLM? vLLM是伯克利大学LMSYS组织开源的高性能大语言模型推理框架。它通过创新的内存管理技术,显著提升了模型推理的效…...

BACnet4j实战:从模拟设备到点位数据采集的完整流程解析
1. BACnet4j与工业物联网数据采集入门 第一次接触BACnet协议时,我被各种专业术语搞得晕头转向。直到用BACnet4j成功读取到第一个温度传感器的数据,才真正理解这个协议的价值。BACnet/IP就像工业设备间的普通话,而BACnet4j就是让Java程序能说这…...

释放创意:Mi-Create让智能表盘设计触手可及
释放创意:Mi-Create让智能表盘设计触手可及 【免费下载链接】Mi-Create Unofficial watchface creator for Xiaomi wearables ~2021 and above 项目地址: https://gitcode.com/gh_mirrors/mi/Mi-Create 问题发现:智能表盘设计的三重困境 在智能穿…...

像素皇城·灵蛇贺岁实战案例:高校AI课程中像素春联生成器教学项目设计
像素皇城灵蛇贺岁实战案例:高校AI课程中像素春联生成器教学项目设计 1. 项目背景与教学价值 在高校AI课程教学中,如何将传统文化与现代技术相结合,设计出既有教育意义又富有趣味性的实践项目,一直是教学设计的难点。"像素皇…...

为什么选择ODB++格式?Cadence与HyperLynx数据交换的最佳实践
为什么选择ODB格式?Cadence与HyperLynx数据交换的最佳实践 在高速PCB设计领域,数据格式的选择直接影响着设计到制造的整个流程效率。当工程师需要在Cadence Allegro和HyperLynx之间传递设计数据时,ODB正逐渐成为行业首选。这种智能数据格式不…...

Phi-3-mini-4k-instruct-gguf开发者案例:为微信小程序后端提供的轻量API服务
Phi-3-mini-4k-instruct-gguf开发者案例:为微信小程序后端提供的轻量API服务 1. 项目背景与需求 在开发微信小程序时,我们经常需要为前端提供智能文本处理能力,比如自动生成商品描述、智能客服回复、内容摘要等。传统方案要么需要调用第三方…...

【花雕学编程】Arduino BLDC 之使用互补滤波进行姿态控制的机器人
从专业工程视角来看,基于Arduino、使用互补滤波进行姿态控制的BLDC(无刷直流电机)机器人,是一个典型的嵌入式实时闭环控制系统。它集成了传感器数据融合、控制算法和电机驱动,广泛应用于对姿态稳定性有要求的场景。 1、…...

深入理解SAP RAP中的语义依赖:从/DMO测试数据看BTP应用的数据建模精髓
解密SAP RAP语义依赖:从/DMO测试数据到企业级数据建模实战 在SAP BTP应用开发领域,数据建模的质量直接决定了系统的健壮性和可维护性。当我们在/DMO/CONNECTION表开发中遇到"DISTANCE字段具有单位量转换和EDM类型int32"的元数据错误时…...

短视频创作新利器:Sonic数字人工作流生成口型自然的表情包视频
短视频创作新利器:Sonic数字人工作流生成口型自然的表情包视频 1. 数字人视频创作新趋势 在短视频内容爆炸式增长的今天,创作者们面临着一个共同挑战:如何高效产出高质量视频内容。传统视频制作需要专业设备、复杂后期和大量时间投入&#…...

ArcGIS PRO布局视图避坑指南:地图框添加与专题图制作的5个关键步骤
ArcGIS PRO布局视图避坑指南:地图框添加与专题图制作的5个关键步骤 在专业地理信息系统中,布局视图是将数据分析成果转化为出版级图纸的核心环节。许多城市规划师和地质工程师常陷入这样的困境:明明数据框中的地图效果完美,切换到…...