Spark编程实验一:Spark和Hadoop的安装使用
目录
一、目的与要求
二、实验内容
三、实验步骤
1、安装Hadoop和Spark
2、HDFS常用操作
3、Spark读取文件系统的数据
四、结果分析与实验体会
一、目的与要求
1、掌握在Linux虚拟机中安装Hadoop和Spark的方法;
2、熟悉HDFS的基本使用方法;
3、掌握使用Spark访问本地文件和HDFS文件的方法。
二、实验内容
1、安装Hadoop和Spark
进入Linux系统,完成Hadoop伪分布式模式的安装。完成Hadoop的安装以后,再安装Spark(Local模式)。
2、HDFS常用操作
使用Hadoop提供的Shell命令完成如下操作:
(1)启动Hadoop,在HDFS中创建用户目录“/user/你的名字的拼音”。以张三同学为例,创建 /user/zhangsan ,下同;
(2)在Linux系统的本地文件系统的“/home/zhangsan”目录下新建一个文本文件test.txt,并在该文件中至少十行英文语句,然后上传到HDFS的“/user/zhangsan”目录下;
(3)把HDFS中“/user/zhangsan”目录下的test.txt文件,下载到Linux系统的本地文件系统中的“/tmp”目录下;
(4)将HDFS中“/user/zhangsan”目录下的test.txt文件的内容输出到终端中进行显示;
(5)在HDFS中的“/”目录下,创建子目录input,把HDFS中“/user/zhangsan”目录下的test.txt文件,复制到“/input”目录下;
(6)删除HDFS中“/user/zhangsan”目录下的test.txt文件;
(7)查找HDFS中所有的 .txt文件;
(8)使用hadoop-mapreduce-examples-3.1.3.jar程序对/input目录下的文件进行单词个数统计,写出运行命令,并验证运行结果。
3、Spark读取文件系统的数据
(1)在pyspark中读取Linux系统本地文件“/home/zhangsan/test.txt”,然后统计出文件的行数;
(2)在pyspark中读取HDFS系统文件“/user/zhangsan/test.txt”,然后统计出文件的行数;
(3)编写独立应用程序,读取HDFS系统文件“/user/zhangsan/test.txt”,然后统计出文件的行数;通过 spark-submit 提交到 Spark 中运行程序。
三、实验步骤
1、安装Hadoop和Spark
进入Linux系统,完成Hadoop伪分布式模式的安装。完成Hadoop的安装以后,再安装Spark(Local模式)。具体安装步骤可以参照我前面写的博客:
大数据存储技术(1)—— Hadoop简介及安装配置-CSDN博客![]() https://blog.csdn.net/Morse_Chen/article/details/134833801Spark环境搭建和使用方法-CSDN博客
https://blog.csdn.net/Morse_Chen/article/details/134833801Spark环境搭建和使用方法-CSDN博客![]() https://blog.csdn.net/Morse_Chen/article/details/134979681
https://blog.csdn.net/Morse_Chen/article/details/134979681
2、HDFS常用操作
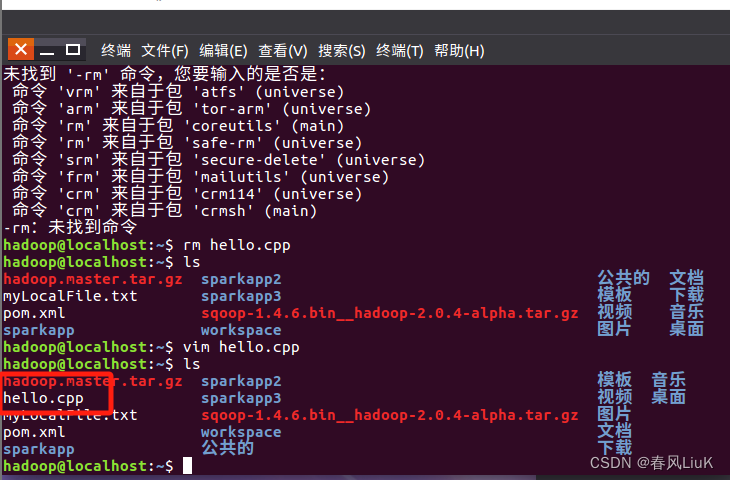
(1)启动Hadoop,在HDFS中创建用户目录“/user/你的名字的拼音”。以张三同学为例,创建 /user/zhangsan ,下同;
[root@bigdata zhc]# start-dfs.sh
[root@bigdata zhc]# jps
[root@bigdata zhc]# hdfs dfs -mkdir -p /user/zhc
[root@bigdata zhc]# hdfs dfs -ls /user 
(2)在Linux系统的本地文件系统的“/home/zhangsan”目录下新建一个文本文件test.txt,并在该文件中至少十行英文语句,然后上传到HDFS的“/user/zhangsan”目录下;
[root@bigdata zhc]# cd /home/zhc
[root@bigdata zhc]# vi test.txt
[root@bigdata zhc]# hdfs dfs -put /home/zhc/test.txt /user/zhctest.txt 文件内容如下:
welcome to linux
hello hadoop
spark is fast
hdfs is good
start pyspark
use python
scala and R
great success
I love spark
ten

这里可以看到上传成功了。
(3)把HDFS中“/user/zhangsan”目录下的test.txt文件,下载到Linux系统的本地文件系统中的“/tmp”目录下;
[root@bigdata zhc]# hdfs dfs -get /user/zhc/test.txt /tmp/
(4)将HDFS中“/user/zhangsan”目录下的test.txt文件的内容输出到终端中进行显示;
[root@bigdata zhc]# hdfs dfs -cat /user/zhc/test.txt
(5)在HDFS中的“/”目录下,创建子目录input,把HDFS中“/user/zhangsan”目录下的test.txt文件,复制到“/input”目录下;
[root@bigdata zhc]# hdfs dfs -cp /user/zhc/test.txt /input/
(6)删除HDFS中“/user/zhangsan”目录下的test.txt文件;
[root@bigdata zhc]# hdfs dfs -rm -f /user/zhc/test.txt
(7)查找HDFS中所有的 .txt文件;
[root@bigdata zhc]# hdfs dfs -ls -R / | grep -i '\.txt$'
(8)使用hadoop-mapreduce-examples-3.1.3.jar程序对/input目录下的test.txt文件进行单词个数统计,写出运行命令,并验证运行结果。
注意:在做这一步之前,要先启动yarn进程;
指定输出结果的路径/output,该路径不能已存在。
先切换到 /usr/local/servers/hadoop/share/hadoop/mapreduce 路径下,然后再开始统计单词个数。
[root@bigdata zhc]# cd /usr/local/servers/hadoop/share/hadoop/mapreduce
[root@bigdata mapreduce]# hadoop jar hadoop-mapreduce-examples-3.1.3.jar wordcount /input/test.txt /output
输入命令查看HDFS文件系统中/output目录下的结果。
[root@bigdata mapreduce]# hdfs dfs -ls /output
[root@bigdata mapreduce]# hdfs dfs -cat /output/part-r-00000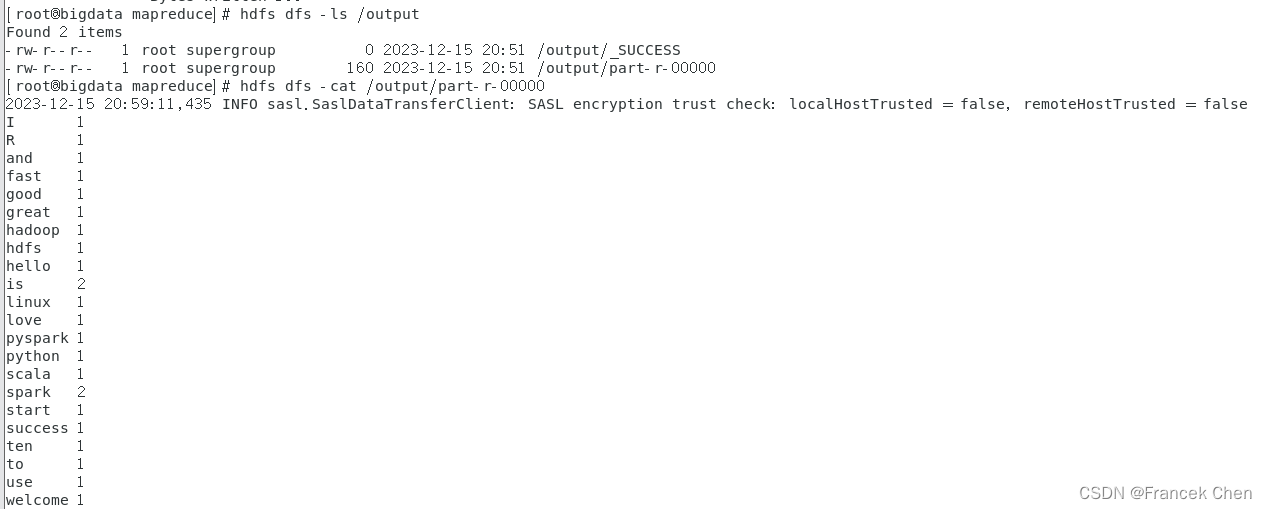
3、Spark读取文件系统的数据
先在终端启动Spark。
[root@bigdata zhc]# pyspark
(1)在pyspark中读取Linux系统本地文件“/home/zhangsan/test.txt”,然后统计出文件的行数;
>>> textFile=sc.textFile("file:///home/zhc/test.txt")
>>> linecount=textFile.count()
>>> print(linecount)
(2)在pyspark中读取HDFS系统文件“/user/zhangsan/test.txt”(如果该文件不存在,请先创建),然后统计出文件的行数;
注意:由于在第2题的(6)问中,已经删除了HDFS中“/user/zhangsan”目录下的test.txt文件,所以这里要重新将test.txt文件从本地系统上传到HDFS中。
[root@bigdata zhc]# hdfs dfs -put /home/zhc/test.txt /user/zhc
>>> textFile=sc.textFile("hdfs://localhost:9000/user/zhc/test.txt")
>>> linecount=textFile.count()
>>> print(linecount)

(3)编写独立应用程序,读取HDFS系统文件“/user/zhangsan/test.txt”,然后统计出文件的行数;通过 spark-submit 提交到 Spark 中运行程序。
[root@bigdata mycode]# vi CountLines_hdfs.py
[root@bigdata mycode]# spark-submit CountLines_hdfs.py CountLines_hdfs.py文件内容如下:
from pyspark import SparkContext
FilePath = "hdfs://localhost:9000/user/zhc/test.txt"
sc = SparkContext("local","Simple App")
data = sc.textFile(FilePath).cache( )
print("文件行数:",data.count())
四、结果分析与实验体会
通过本次Spark实验,学会了如何安装、启动Hadoop和Spark,并掌握了HDFS的基本使用方法,使用Spark访问本地文件和HDFS文件的方法。在Linux系统的本地文件系统和在HDFS中分别进行各种文件操作,然后在Spark中读取文件系统的数据,并能统计文件的行数。
在做第三题(2)时,在pyspark中读取HDFS系统文件“/user/zhangsan/test.txt”,要将第二题(6)中删除的test.txt文件重新上传到HDFS中,注意文件路径要写正确, file_path=“hdfs:///user/zhc/test.txt”。在第三题(3)中,可以修改如下路径中的文件 /usr/local/spark/conf/log4j.properties.template,将文件中内容 “log4j.rootCategory=INFO” 改为 “log4j.rootCategory=ERROR”,这样在输出结果时,就不会显示大量的INFO信息,使得结果更简化。
相关文章:
Spark编程实验一:Spark和Hadoop的安装使用
目录 一、目的与要求 二、实验内容 三、实验步骤 1、安装Hadoop和Spark 2、HDFS常用操作 3、Spark读取文件系统的数据 四、结果分析与实验体会 一、目的与要求 1、掌握在Linux虚拟机中安装Hadoop和Spark的方法; 2、熟悉HDFS的基本使用方法; 3、掌…...

代理和AOP
一:java代理 整体分为两种:静态代理和动态代理 静态代理:23种设计模式里面有个代理模式,那个就是静态代理。 动态代理:分为编译时增强(AspectJ)和运行时增强(JDK动态代理和CGLIB动态代理) 1:静态代理 这种代理在我们日常生活中其…...

Solidity-3-类型
Solidity 是一种静态类型语言,这意味着每个变量(状态变量和局部变量)都需要在编译时指定变量的类型。 “undefined”或“null”值的概念在Solidity中不存在,但是新声明的变量总是有一个 默认值 ,具体的默认值跟类型相…...

【mask转json】文件互转
mask图像转json文件 当只有mask图像时,可使用下面代码得到json文件 import cv2 import os import json import sysdef func(file:str) -> dict:png cv2.imread(file)gray cv2.cvtColor(png, cv2.COLOR_BGR2GRAY)_, binary cv2.threshold(gray,10,255,cv2.TH…...
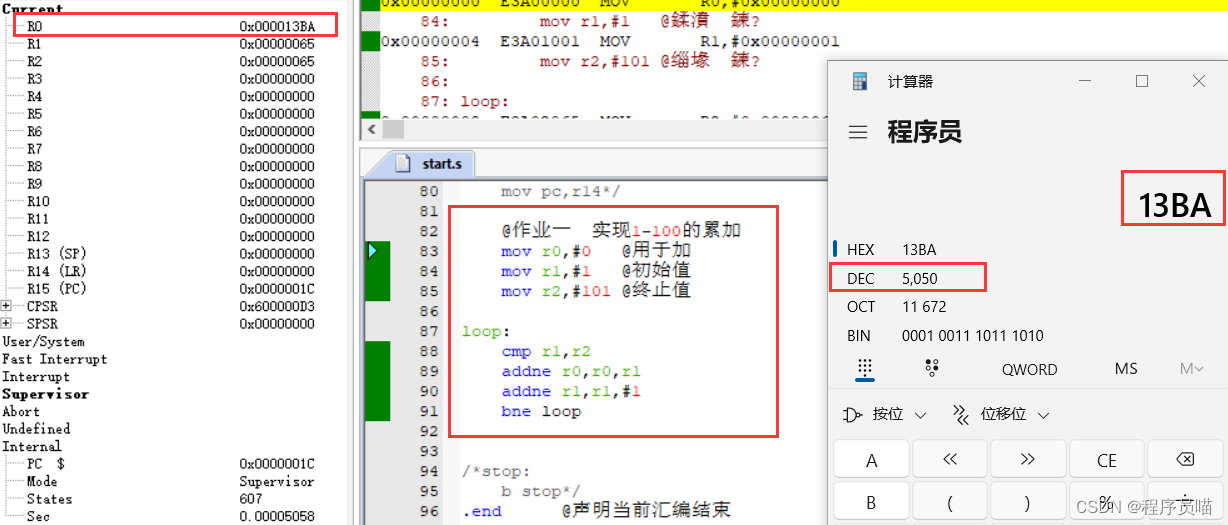
华清远见嵌入式学习——ARM——作业1
要求: 代码: mov r0,#0 用于加mov r1,#1 初始值mov r2,#101 终止值loop: cmp r1,r2addne r0,r0,r1addne r1,r1,#1bne loop 效果:...

如何在公网环境使用固定域名远程访问内网BUG管理系统协同办公
文章目录 前言1. 本地安装配置BUG管理系统2. 内网穿透2.1 安装cpolar内网穿透2.2 创建隧道映射本地服务3. 测试公网远程访问4. 配置固定二级子域名4.1 保留一个二级子域名5.1 配置二级子域名6. 使用固定二级子域名远程 前言 BUG管理软件,作为软件测试工程师的必备工具之一。在…...

k8s pod网络排查教程
1、背景 背景:在日常的k8s运维中,经常会遇到pod之间网络无法访问,域名无法解释的情况。且容器中网络排查命令不全,导致无法准确定位问题。 2、nsenter介绍 #Centos 下载方式 $ yum install util-linux -ynsenter 是一个 Linux …...

Apollo Planning——换道:LANE_CHANGE_DECIDER
LaneChangeDecider 是lanefollow 场景下,所调用的第一个task,它的作用主要有两点:判断当前是否进行变道,以及变道的状态,并将结果存在变量lane_change_status中;变道过程中将目标车道的reference line放置到…...

Python 爬虫之简单的爬虫(三)
爬取动态网页(上) 文章目录 爬取动态网页(上)前言一、大致内容二、基本思路三、代码编写1.引入库2.加载网页数据3.获取指定数据 总结 前言 之前的两篇写的是爬取静态网页的内容,比较简单。接下来呢给大家讲一下如何去…...

为突发事件提供高现势性数据支撑!大势智慧助力中山市2023应急测绘保障演练举行
12月14日,2023年度中山市应急测绘保障演练在中山树木园举行,市自然资源局总工程师邓宇文出席本次演练活动。来自全市自然资源、应急管理部门和部分测绘单位的近70人现场观摩了演练。本次演练由中山市自然资源局主办、中山市自然资源信息中心承办…...

图片速览 OOD用于零样本 OOD 检测的 CLIPN:教 CLIP 说不
PAPERCODEhttps://arxiv.org/pdf/2308.12213v2.pdfhttps://github.com/xmed-lab/clipn 文章创新 以往由CLIP驱动的零样本OOD检测方法,只需要ID的类名,受到的关注较少。 本文提出了一种新的方法,即CLIP说“不”(CLIPN)…...

a16z:加密行业2024趋势“无缝用户体验”
近日,知名加密投资机构a16z发布了“Big ideas 2024”,列出了加密行业在 2024 年几个具备趋势的“大想法”,其中 Seamless UX(无缝用户体验)赫然在列。 从最为直观的理解上,Seamless UX 是在强调用户在使用产…...
C# WPF上位机开发(属性页面的设计)
【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing 163.com】 在软件开发中,属性或者参数设置是很重要的一个部分。这个时候如果不想通过动态添加控件的方法来处理的话,那么可以通过tab控…...
macOS 安装 oh-my-zsh 后 node 报错 command not found : node
最近为了让终端中显示 git 分支的名称,安装了 oh-my-zsh ,安装之后呢,我原先安装的 Volta、 node 都没法用了,报错如下: 这时候粗略判断应该是系统变量出了问题,oh-my-zsh 的变量文件是 ~/.zshrc࿰…...

AI 绘画 | Stable Diffusion 视频数字人
前言 本篇文章教会你如何利用Stable Diffusion WEB UI,使用一个人物图片转换成为一个口播视频。本篇内容的教程以WINDOWS系统为例,教你如何安装使用。 先看视频效果 彭于晏图片生成口播视频 安装 首先需要在windows电脑上安装ffmpeg,按照本教程《在 Windows PC 上轻松下载并…...

《代码随想录》--二叉树(一)
《代码随想录》--二叉树 第一部分 1、二叉树的递归遍历2、二叉树的迭代遍历3、统一风格的迭代遍历代码4、二叉树的层序遍历226.翻转二叉树 1、二叉树的递归遍历 前序遍历 中序遍历 后序遍历 代码 前序遍历 class Solution {public List<Integer> preorderTraversal(T…...
)
shell编程-数组与运算符详解(超详细)
文章目录 前言一、 Shell数组1. 声明和初始化数组2. 访问数组元素3. 数组长度4. 遍历数组5. 修改数组元素6. 删除数组元素7. 示例 二、Shell运算符1. 算术运算符1.1 加法运算符 ()1.2 减法运算符 (-)1.3 乘法运算符 (*)1.4 除法运算符 (/)1.5 取余运算符 (%) 2. 关系运算符2.1 …...
Vim入门
Vim使用入门 1.Vim编辑器的三种常用模式 一般模式:刚打开文件是它,从编辑模式按“ESC”退回的模式也是它。可以执行各种编辑操作,如移动光标、复制、粘贴、删除、查找替换等 ; 编辑模式:在一般模式下按下 i、I、a、A、o、O 等键…...

动态加载库
no_mangle 不要改标识符 首先是认识这个标注:mangle,英文的含义“撕裂、碾压”。我第一次把这个单次误以为是manage,说实话两个单词还挺像的。 RUS中函数或静态变量使用#[no_mangle]这个标注属性后,编译器就不会修改它们的名字了…...

React中渲染html结构---dangerouslySetInnerHTML
dangerouslySetInnerHTML胡子{}语法绑定的内容全部作为普通文本渲染,渲染html结构基于---dangerouslySetInnerHTMLdangerouslySetInnerHTML是React标签的一个属性,类似于vue的v-html有2个{{}},第一个{}代表jsx语法开始,第二个是代表dangerous…...
✅)
计算机毕业设计:Python二手车市场数据分析与价格预测系统 Django框架 随机森林 可视化 数据分析 汽车 车辆 大数据 hadoop(建议收藏)✅
1、项目介绍 技术栈 Python、Django、MySQL、机器学习随机森林算法、Echarts可视化、HTML、阿里云天池数据集 功能模块 注册登录界面不同车龄平均价格柱状图分析不同车龄数量分布饼图二手车售价分布饼图不同地区二手车平均价格柱状图分析里程价格折线图分析特征值和价格相关性分…...

UI-TARS-desktop效果实测:内置Qwen3-4B模型响应速度有多快
UI-TARS-desktop效果实测:内置Qwen3-4B模型响应速度有多快 在当今AI应用日益普及的背景下,响应速度已成为衡量模型实用性的关键指标。本文将带您实测UI-TARS-desktop内置的Qwen3-4B-Instruct-2507模型在实际使用中的响应表现,通过多场景测试…...

typedef用法
将为你介绍typedef 4 种应用方式。应用一、为基本数据类型定义新的类型名用uint32_t替代unsigned int声明变量/* 变量名重定义 */typedef unsigned int uint32_t;/* 定义一个unsigned int类型的变量 */uint32_t count 0;应用二、为自定义数据类型(结构体、共用体和…...

LIN Switch Method:从硬件革新到软件流程,揭秘车内氛围灯自动寻址的完整闭环
1. 为什么车内氛围灯需要自动寻址技术 十年前的车内照明还停留在基础功能阶段,而现在的高端车型已经将氛围灯玩出了新花样。想象一下,当你打开车门时,迎宾灯像流水一样从车头滑向车尾;调节空调温度时,出风口周围的灯光…...

YOLO X Layout实战:商业报告智能解析,快速提取表格与图表数据
YOLO X Layout实战:商业报告智能解析,快速提取表格与图表数据 1. 商业文档处理的痛点与解决方案 在金融分析、市场研究等专业领域,我们经常需要处理大量商业报告。这些PDF或扫描件文档中包含大量有价值的数据表格和图表,但手动提…...

G-Helper:华硕笔记本色彩配置一键恢复指南
G-Helper:华硕笔记本色彩配置一键恢复指南 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops. Control tool for ROG Zephyrus G14, G15, G16, M16, Flow X13, Flow X16, TUF, Strix, Scar and other models 项目地址: https://…...

交叉调整率差的5大根源—变压器、绕组、反馈、拓扑、元件
Q1:导致交叉调整率差的第一大根源是什么?变压器漏感与绕组耦合不良。漏感使能量不能完全传递到辅路,各绕组漏感不一致,负载变化时电压漂移更明显。耦合系数越接近 1,交叉调整率越好。Q2:绕组绕制方式对交叉…...

突破国际漫游限制:Nrfr免Root工具的终极解决方案
突破国际漫游限制:Nrfr免Root工具的终极解决方案 【免费下载链接】Nrfr 🌍 免 Root 的 SIM 卡国家码修改工具 | 解决国际漫游时的兼容性问题,帮助使用海外 SIM 卡获得更好的本地化体验,解锁运营商限制,突破区域限制 …...

Anthropic泄露新一代Claude Mythos 模型,具备网络安全漏洞检测优势
配置错误曝光新模型Anthropic PBC 内容管理系统的一处配置错误意外泄露了其正在测试的新型大语言模型 Claude Mythos。该公司周四向《财富》杂志证实,工程师已完成该模型的训练工作,目前正与早期客户进行试点测试。Anthropic 强调这是其"迄今为止构…...
)
保姆级教程:手把手教你为Jetson Orin Nano刷入R36.4.4系统(从下载到开机)
从零开始:Jetson Orin Nano开发者套件系统刷入全流程实战指南 当你第一次拿到NVIDIA Jetson Orin Nano开发者套件时,那种兴奋感可能很快会被"我该如何开始"的困惑所取代。这款性能强大的边缘计算设备确实令人着迷,但如果没有正确的…...