Hudi Clustering
核心概念
Hudi Clustering对于在数据写入和读取提供一套相对完善的解决方案。它的核心思想就是: 在数据写入时,运行并发写入多个小文件,从而提升写入的性能;同时通过一个异步(也可以配置同步,但不推荐)进程或者周期性调度来执行小文件合并成大文件在这个过程中hudi还考虑到对数据按照特定的列进行重排序,这样在解决小文件问题的同时还优化了查询性能,可谓是“两全其美”。对于Clustering的手法其实是一种比较通用的优化数据重新布局的手段。其中在Hive/Spark SQL中都有类似的操作cluster by,只是在hudi中更加追求完美,多了一项合并小文件工作。关于cluster的几个配置参数:
| 配置项 | 默认值 | 说明 |
|---|---|---|
| hoodie.clustering.inline | false | |
| hoodie.clustering.schedule.inline | false | |
| hoodie.clustering.async.enabled | false | |
| hoodie.clustering.inline.max.commits | 4 | |
| hoodie.clustering.async.max.commits | 4 | |
| hoodie.clustering.plan.strategy.small.file.limit | 314572800 ( 300MB ) | 只有小于该值的文件才会被视为小文件,从而参与到 Clustering 中。 |
| hoodie.clustering.plan.strategy.target.file.max.bytes | 1073741824 ( 1GB ) | 限制 Clustering 生成的文件大小,默认是 1GB。合并后的最大文件不会超过该值。 |
| hoodie.clustering.plan.strategy.sort.columns | -- | 针对哪个列重新进行排序。对于该字段过滤条件的查询有很大性能提高。 |
计划与执行
Clustering 的执行机制和compaction的机制类似,都是分为Schedule和execute两个阶段。计划的阶段主要是规划哪些文件参与Clusetring,然后生成一个计划Clusetring Plan保存到Timeline,Timeline中的Instant会有一个replacecommit的值,状态是REQUESTED ;执行阶段主要工作是读取Timeline中的计划,执行完毕,最后将replace commit改为COMPLETED状态。
同步与异步
和compaction一样。Clustering运行模式分为:同步、异步、半异步(为本文的一种叫法,在hudi官网没有体现。)他们之前的差异主要体现在从提交到计划到执行的的三个阶段的推进上。
同步模式(Inline schedule, Inline execute)
同步模式可概括为:立即计划,立即执行(Inline Schedule,Inline Execute)。在该模式下,当累积的提交(Commit)次数到达一个阈值时,会立即触发 Clustering 的计划与执行(计划和执行是连在一起的),而这个阈值是由配置项 hoodie.clustering.inline.max.commits 控制的,默认值是 4,即:默认情况下,每提交 4 次就(有可能)会触发并执行一次 Clustering。锁定同步模式的配置是:
| 配置项 | 参数 |
|---|---|
| hoodie.clustering.inline | true |
| hoodie.clustering.schedule.inline | false |
| hoodie.clustering.async.enabled | False |
异步模式(offline)
异步模式可概括为:另行计划,另行执行(Offline Schedule,Offline Execute)。在该模式下,任何提交都不会直接触发和执行 Clustering,除非使用支持异步 Clustering 的 Writer,否则用户需要自己保证有一个独立的进程或线程负责定期执行 Clustering 操作。在异步模式下,由于发起计划和提交之间没有必然的协同关系,所以在发起计划时,Timeline 中可能尚未积累到足够数量的提交,或者提交数量已经超过了规定阈值,如果是前者,不会产生计划计划,如果是后者,计划计划会将所有累积的提交涵盖进来,在这一点上,Clustering 和 Compaction 的处理方式是一致的。锁定异步模式的配置是:
| 配置项 | 设定值 |
|---|---|
| hoodie.clustering.inline | false |
| hoodie.clustering.schedule.inline | false |
| hoodie.clustering.async.enabled | true |
半异步(Inline Schedule,Offline Execute)
半异步模式可概括为:立即计划,另行执行(Inline Schedule,Offline Execute),即:计划会伴随提交自动触发,但执行还是通过前面介绍的三种异步方式之一去完成。简单总结一下半异步的设计思想:它在每次提交时都会尝试生成计划,如果此前已经生成了计划且尚未执行,则放弃计划,等待其被执行,当异步进程或线程完成执行作业时,紧接着的下一次提交会立即生成新的计划,这样,整个 Clustering 的“节奏”就由异步的执行程序来掌控了。锁定半异步模式的配置是:
| 配置项 | 设定值 |
|---|---|
| hoodie.clustering.inline | False |
| hoodie.clustering.schedule.inline | true |
| hoodie.clustering.async.enabled | false |
计划策略
Clustering 在排期和执行上都有可插拔的策略,以及在执行期间如何应对数据更新也有相应的更新策略,执行策略和更新策略较为简单,使用默认配置即可,本文不再赘述,详情可参考官方文档。本文着重介绍一下排期策略。Hudi 有三种 Clustering 排期策略可供选择:
-
SparkSizeBasedClusteringPlanStrategy:该策略为默认的排期策略,它会筛选出符合条件的小文件(就是看文件大小,小于 clustering.plan.strategy.small.file.limit 规定值的文件就是小文件),然后将选出的小文件分成多个 Group,Group 的数量和大小都是可配置的,划分 Group 的目的是提升 Clustering 的并行度。注意:该策略将会扫描全部分区。
-
SparkRecentDaysClusteringPlanStrategy:该策略会在此前 N 天的分区内查找小文件,对于使用日期作分区,且数据增量是可预期的数据表来说,这种策略是非常适合的。如果在这种情况下使用默认排期策略,就会扫描全部分区,给系统带来没有必要的负载。
-
SparkSelectedPartitionsClusteringPlanStrategy:该策略允许我们针对特定的分区进行 Clustering,这可能会应用在运维或某些具有独特业务特征的数据表上。
排序列
hoodie.clustering.plan.strategy.sort.columns 用于指定在 Clustering 过程中针对哪个列重新进行排序,这也是前文重点解释的 Clustering 能提升数据读取性能的关键。该列的选择对提升查询效率非常重要,通常会选择查询频率最高的条件列。尽管该配置项支持多列,但如果配置了两个或更多列的话,对于那些排在第一列后面的列来说,以它们为条件的查询并不能从中获得太多收益,这和在 HBase 中拼接列值到 Rowkey 中以提升检索性能是一样的。不过,Hudi 提供了以 z-order 和 hilbert 为代表的空间填充曲线技术用于解决多列排序问题。
关闭小文件检查
关闭parquet小文件检查;将hoodie.parquet.small.file.limit置为0。这样做hudi将会把所有的文件认为是大文件。任何数据在写入的时候都不在发生copy-on-write的copy的操作。而是直接写入新的文件,这样减少了写入操作的负担。所以产生的小文件就是Clustering就要去解决的事情。
同步Clustering
参数配置
| 配置项 | 默认值 | 设定值 |
|---|---|---|
| hoodie.clustering.inline | false | True |
| hoodie.clustering.schedule.inline | false | false |
| hoodie.clustering.async.enabled | False | False |
| hoodie.clustering.async.enabled | 4 | 2 |
| hoodie.clustering.async.enabled | 314572800 ( 300MB ) | 314572800 ( 300MB ) |
| hoodie.clustering.async.enabled | 1073741824 ( 1GB ) | 1073741824 ( 1GB ) |
| hoodie.parquet.small.file.limit | 104857600 ( 100MB ) | 0 |
建表语句
create table small_file_hudi_cow (id int,name string,age int,city STRING,date_str STRING
) using hudi
tblproperties (type = 'cow',primaryKey = 'id',preCombineField = 'id','hoodie.clustering.inline' = true,'hoodie.clustering.schedule.inline' = false,'hoodie.clustering.async.enabled' = false,'hoodie.clustering.inline.max.commits' = 2,'hoodie.clustering.plan.strategy.small.file.limit' = 314572800,'hoodie.clustering.plan.strategy.target.file.max.bytes' = 1073741824,'hoodie.parquet.small.file.limit' = '0'
)
partitioned by (date_str);执行计划
| 步骤 | 操作 | 文件系统 | 导入或者更新操作 |
|---|---|---|---|
| 1 | insert | base file | INSERT INTO small_file_hudi_cow SELECT id, name, age, city, event_date FROM sample_data_partitioned where event_date='2023-11-02'; |
| 2 | update | base file | INSERT INTO small_file_hudi_cow SELECT id, name, age, city, event_date FROM sample_data_partitioned where event_date='2023-11-02'; |
| 3 | update | clustering +base file | INSERT INTO small_file_hudi_cow SELECT id, name, age, city, event_date FROM sample_data_partitioned where event_date='2023-11-02'; |
第一步:insert
Hudi 将其写入到一个 Parquet 文件中,第一组 File Group 随之产生。其文件信息及时间线如下:

第二步:
由于全量更新第一次的所有数据文件,更新后添加对应的一组 file 信息。其文件信息及时间线如下:

第三步:
在做一次全量的数据更新,同时设置了clustering 模式的最大提交次数为2,所以此次提交触发clustering 机制。自动发起了名为 replacecommit 提交,然后预计合并后的数据进行更新的commit 信息。其文件信息及时间线如下:

相关文章:
Hudi Clustering
核心概念 Hudi Clustering对于在数据写入和读取提供一套相对完善的解决方案。它的核心思想就是: 在数据写入时,运行并发写入多个小文件,从而提升写入的性能;同时通过一个异步(也可以配置同步,但不推荐&…...

通过与 Team Finance 整合,Casper Network 让 Token 的创建、部署更加高效
随着 Team Finance 整合到 Casper 系统中,Token 创建的过程变得更加迅速而简便。Casper Network 的方案正在使代币的创建变得易于访问与调整,这将让任何有创意和业务理念的人能够以高效、可信的方式,更快速、安全地在 Casper 上推出他们的项目…...

Linux软件管理rpm和yum
rpm方式管理 rpm软件包名称: 软件名称 版本号(主版本、次版本、修订号) 操作系统 -----90%的规律 #有依赖关系,不能自动解决依赖关系。 举例:openssh-6.6.1p1-31.el7.x86_64.rpm 数字前面的是名称 数字是版本号:第一位主版本号,第二位次版本…...

uart和usart的区别
UART 通用异步收发器,一般来说,在单片机上,名为UART的接口只能用于异步串行通信。 USART 名为USART的接口既可用于同步串行通信,也可用于异步串行通信。...
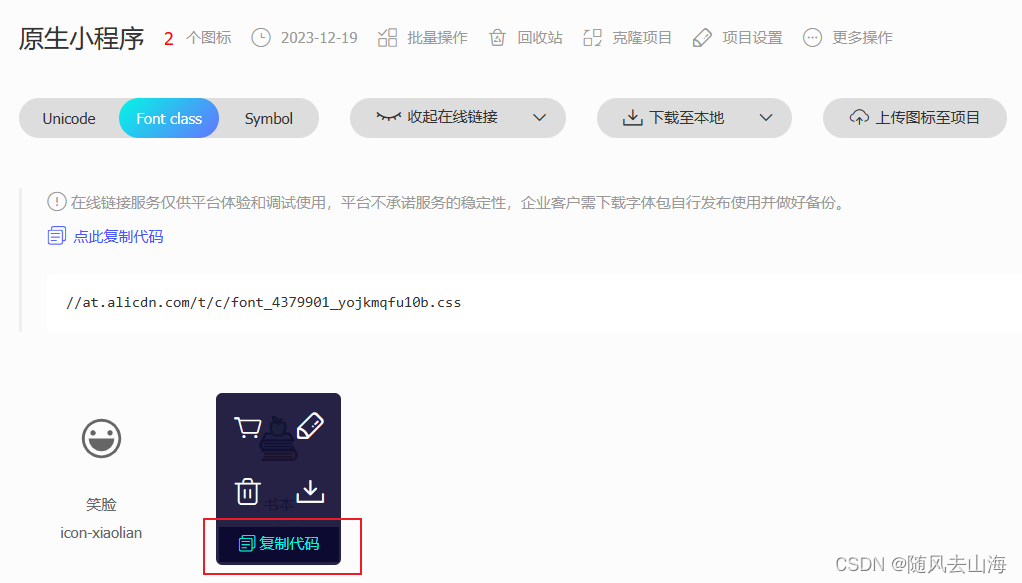
原生微信小程序-使用 阿里字体图标 详解
步骤一 1、打开阿里巴巴矢量图标库 网址:iconfont-阿里巴巴矢量图标库 2、搜索字体图标,鼠标悬浮点击添加入库 3、按如下步骤添加到自己的项目 步骤二 进入微信开发者工具 1、创建 fonts文件夹 > iconfont.wxss 文件,将刚才的代码复制…...
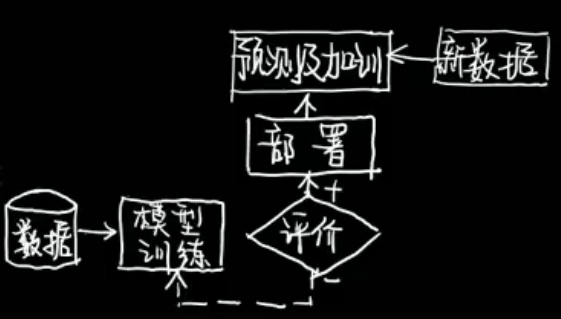
机器学习 | 机器学习基础知识
一、机器学习是什么 计算机从数据中学习规律并改善自身进行预测的过程。 二、数据集 1、最常用的公开数据集 2、结构化数据与非结构化数据 三、任务地图 1、分类任务 Classification 已知样本特征判断样本类别二分类、多分类、多标签分类 二分类:垃圾邮件分类、图像…...
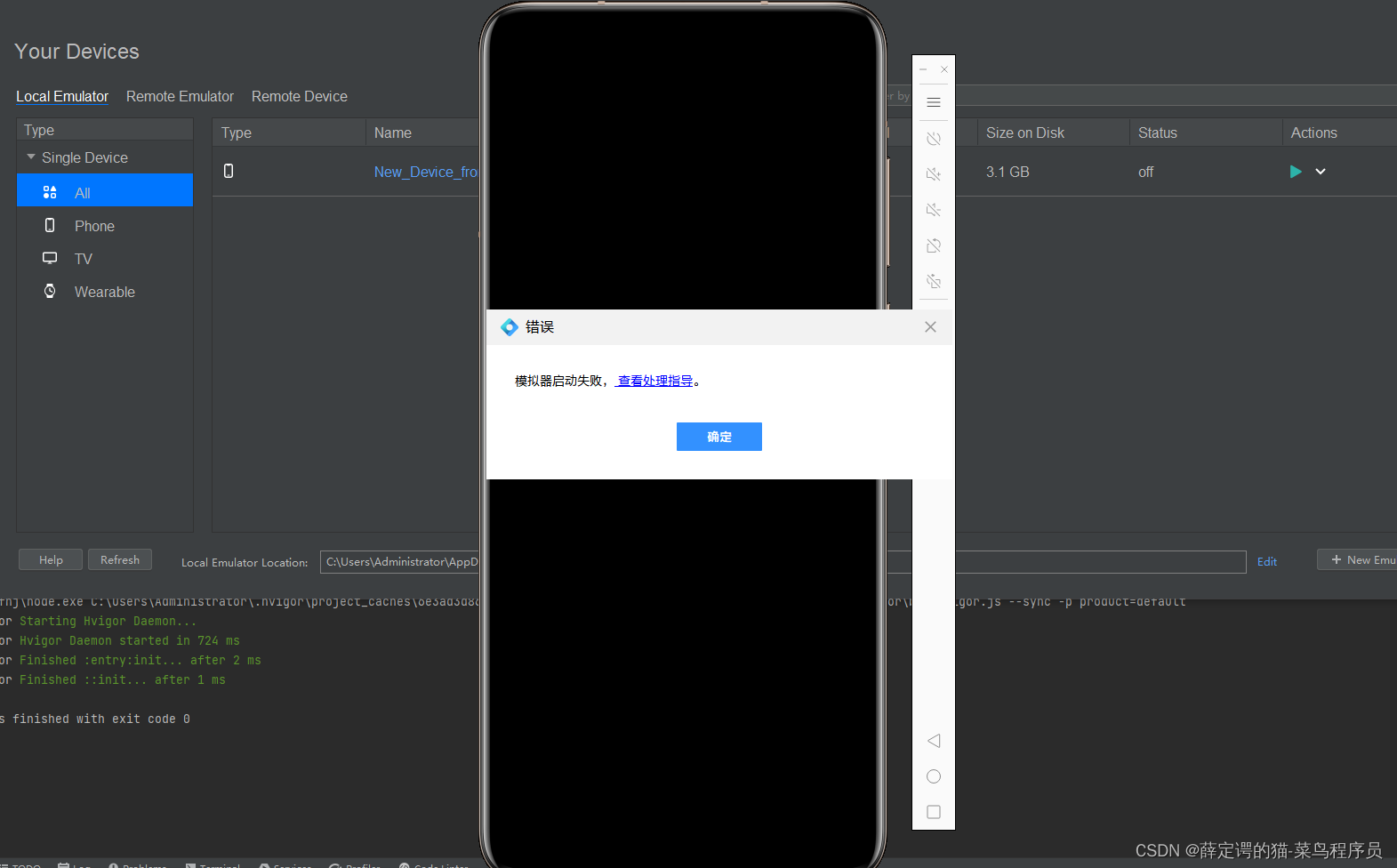
OpenHarmony鸿蒙原生应用开发,ArkTS、ArkUI学习踩坑学习笔记,持续更新中。
一、AMD处理器win10系统下,DevEco Studio模拟器启动失败解决办法。 结论:在BIOS里面将Hyper-V打开,DevEco Studio模拟器可以成功启动。 二、ArkTS自定义组件导出、引用实现。 如果在另外的文件中引用组件,需要使用export关键字导…...
二)
RHCE8 资料整理(十)二
RHCE8 资料整理 第 31 章 变量的使用(一)31.1 手动定义变量31.2 变量文件31.3 字典变量31.4 列表变量31.5 数字变量的运算31.6 注册变量31.7 facts变量 第 31 章 变量的使用(一) 31.1 手动定义变量 通过vars来定义变量ÿ…...

CUDA 学习记录2
1.是否启用一级缓存有什么影响: 启用一级缓存(缓存加载操作经过一级缓存):一次内存十五操作以128字节的粒度进行。 不启用一级缓存(没有缓存的加载不经过一级缓存):在内存段的粒度上ÿ…...

探索Qt 6.3:了解基本知识点和新特性
学习目标: 理解Qt6.3的基本概念和框架:解释Qt是什么,它的核心思想和设计原则。学会安装和配置Qt6.3开发环境:提供详细的步骤,让读者能够顺利安装和配置Qt6.3的开发环境。掌握Qt6.3的基本编程技巧:介绍Qt6.…...
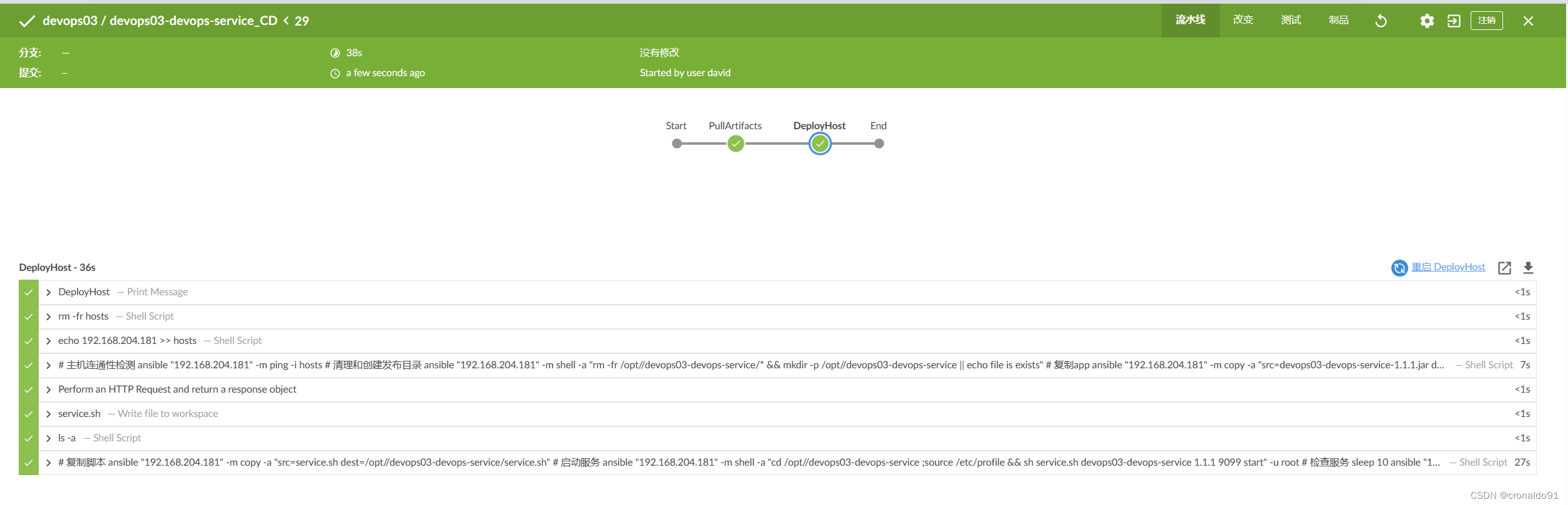
持续集成交付CICD:基于 GitLabCI 与 JenkinsCD 实现后端项目发布
目录 一、实验 1. GitLabCI环境设置 2.优化GitLabCI共享库代码 3.JenkinsCD 发布后端项目 4.再次优化GitLabCI共享库代码 5.JenkinsCD 再次发布后端项目 一、实验 1. GitLabCI环境设置 (1)GitLab给后端项目添加CI配置路径 (2…...

一些好用的VSCode扩展
可以在扩展这里直接搜索需要的扩展,点击安装即可。 1.Chinese 中文扩展,就是说虽然咱们懂点英语,但还是中文看着方便 2.Auto Rename Tag 当你重命名一个HTML 标签时,会自动重命名与他配对的HTML 标签 当你选择h4这个标签时&…...
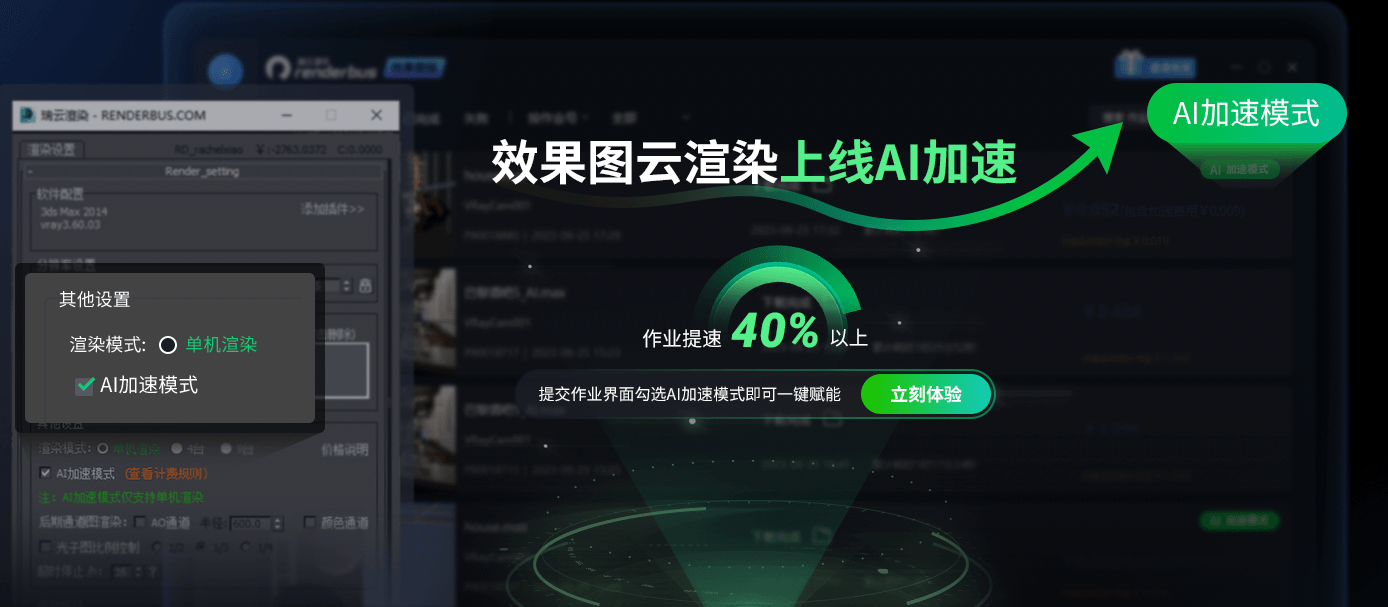
3dsmax渲染太慢,用云渲染农场多少钱?
对于许多从事计算机图形设计的创作者来说,渲染速度慢是一个常见问题,尤其是对于那些追求极致出图效果的室内设计师和建筑可视化师,他们通常使用3ds Max这样的工具,而高质量的渲染经常意味着长时间的等待。场景复杂、细节丰富&…...
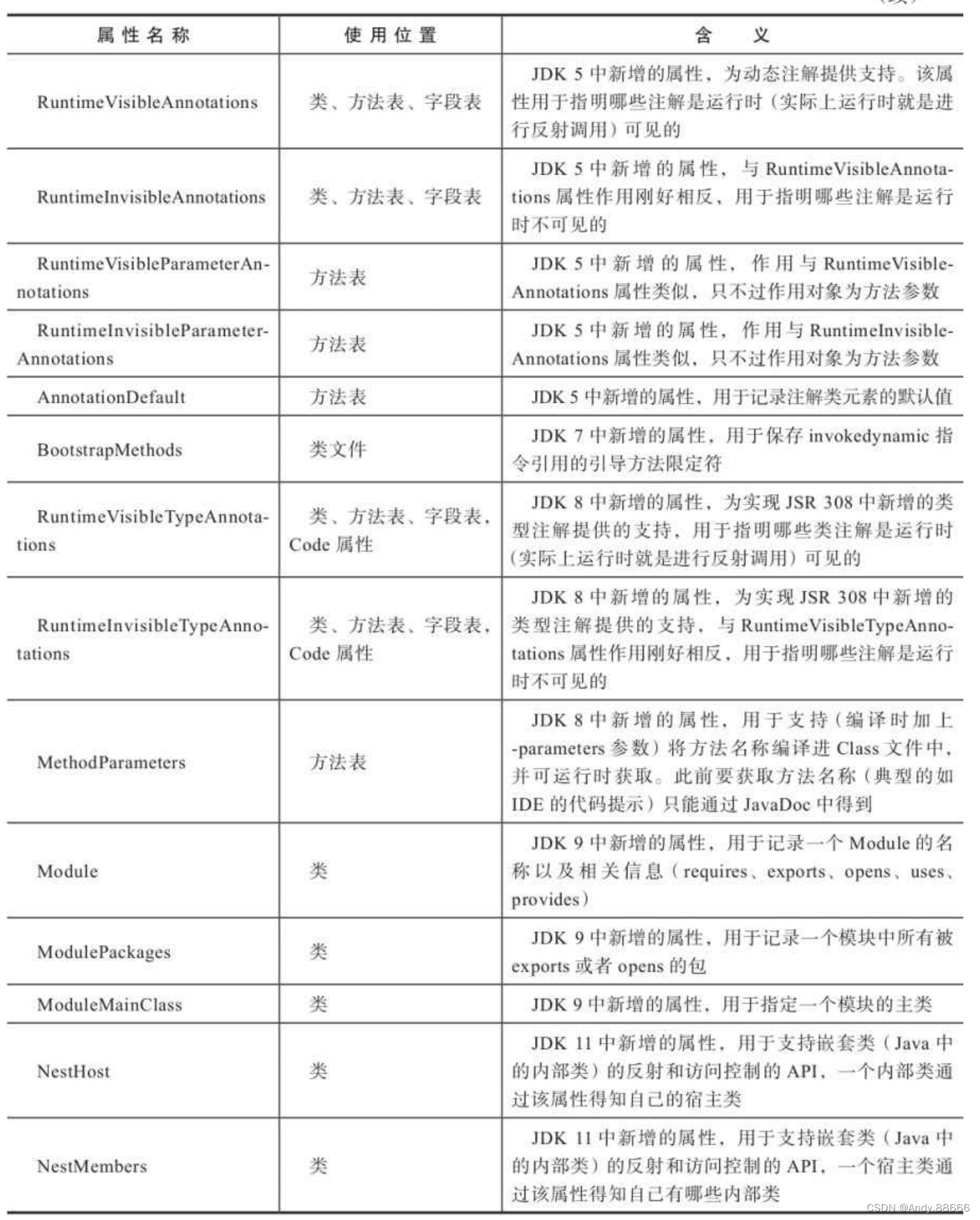
JVM-9-Class类文件的结构
Java技术能够一直保持着非常良好的向后兼容性,Class文件结构的稳定功不可没。 Class文件是一组以8个字节为基础单位的二进制流,各个数据项目严格按照顺序紧凑地排列在文件之中。 Class文件格式采用一种类似于C语言结构体的伪结构来存储数据,…...

Redis持久化,性能管理
Redis高可用主要通过以下几种方式来实现:单机、主从复制、哨兵模式、和集群模式。这些方式都旨在提高系统的稳定性和可用性,特别是在面对服务器故障或其他问题时。 持久化: 在数据库和缓存系统中,持久化是指将数据保存在存储介质&…...

linux(centos7)离线安装mysql-5.7.35-1.el7.x86_64.rpm-bundle.tar
1. 卸载mariadb相关rpm # 查找 rpm -qa|grep mariadb rpm -qa|grep mysql# 卸载 rpm -e --nodeps mariadb... rpm -e --nodeps mysql...2. 删除mysql相关文件 # 查找 find / -name mysql# 删除 rm -rf /var/lib/mysql...3. 查看是否有相关依赖,没有需安装 rpm -q…...

【lesson17】MySQL表的基本操作--表去重、聚合函数和group by
文章目录 MySQL表的基本操作介绍插入结果查询(表去重)建表插入数据操作 聚合函数建表插入数据操作 group by(分组)建表插入数据操作 MySQL表的基本操作介绍 CRUD : Create(创建), Retrieve(读取),Update(更新)&#x…...
【Qt】【华清远见西安中心】)
面试题总结(十二)【Qt】【华清远见西安中心】
Qt是什么? Qt是一个跨平台的应用程序开发框架,最初由挪威的Trolltech公司开发。它提供了一套丰富的工具和类库,用于开发图形用户界面(GUI)应用程序、网络应用程序和嵌入式应用程序等。 Qt框架基于C语言编写,…...
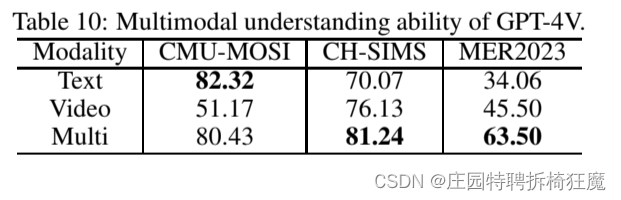
GPT-4V with Emotion:A Zero-shot Benchmark forMultimodal Emotion Understanding
GPT-4V with Emotion:A Zero-shot Benchmark forMultimodal Emotion Understanding GPT-4V情感:多模态情感理解的zero-shot基准 1.摘要 最近,GPT-4视觉系统(GPT-4V)在各种多模态任务中表现出非凡的性能。然而,它在情感识别方面的功效仍然是个问题。本文定…...
CogVLM与CogAgent:开源视觉语言模型的新里程碑
引言 随着机器学习的快速发展,视觉语言模型(VLM)的研究取得了显著的进步。今天,我们很高兴介绍两款强大的开源视觉语言模型:CogVLM和CogAgent。这两款模型在图像理解和多轮对话等领域表现出色,为人工智能的…...

Openclaw案例之构建《全自动化、高适配、可定制”的AI绘画生产体系》
⚡⚡⚡ 欢迎预览,批评指正⚡⚡⚡ 文章目录一、需求&目标二、搭建基础环境2.1 环境准备2.2 OpenClaw与绘画模型部署启动2.3 核心配置(模型插件联动)三、核心操作3.1 多智能体角色配置(核心步骤)3.2 一键启动自动化…...

郭老师-悟性高的人,为何不合群?
悟性高的人,为何不合群? ——他们在独处中,与道同行“你以为他孤独, 其实—— 他正与万物对话。”🌿 不合群,不是缺陷, 而是—— 为悟性留出呼吸的空间。🧘 一、独处 ≠ 孤独&#x…...
ostringstream清空缓存的正确姿势:str()与clear()的深度解析
1. 为什么ostringstream清空缓存这么让人困惑? 第一次用ostringstream的时候,我也被它坑过。记得当时写了个日志记录功能,反复往同一个ostringstream对象里写入内容,结果发现每次输出的日志都越积越长。我本能地调用了clear()&…...

mbed OS双极性步进电机驱动库设计与应用
1. 项目概述BipoarStepperMotor 是一个面向 ARM Cortex-M 系统、专为 mbed OS 平台设计的双极性步进电机驱动库。该库不依赖特定硬件抽象层(HAL)变体,而是基于 mbed OS 提供的标准 DigitalOut 和 PwmOut 接口构建,具备良好的跨平台…...

轻量级PDF阅读器SumatraPDF核心功能与效率提升指南
轻量级PDF阅读器SumatraPDF核心功能与效率提升指南 【免费下载链接】sumatrapdf SumatraPDF reader 项目地址: https://gitcode.com/gh_mirrors/su/sumatrapdf 在数字文档处理领域,速度与资源占用往往难以平衡。SumatraPDF以其独特的轻量级设计,重…...

Rust实战:通过DLL注入与IAT Hook技术拦截Windows API调用
1. 为什么需要Hook Windows API? 在Windows系统开发中,Hook技术就像给系统功能安装了一个"监听器"。想象一下,当你点击某个按钮时,原本应该弹出标准对话框,但通过Hook技术,我们可以在这个动作发生…...

广告防欺诈与广告验证:住宅代理如何帮助监测点击欺诈
广告欺诈正在持续侵蚀企业的广告预算,并导致数据分析结果失真。常见形式包括点击欺诈、虚假流量以及域名伪造,这些问题使广告主难以准确评估真实投放效果。在实际业务中,如何获取“接近真实用户视角”的广告数据,成为广告验证的关…...

NaViL-9B多模态能力详解:从API调用到温度参数优化的完整指南
NaViL-9B多模态能力详解:从API调用到温度参数优化的完整指南 1. 平台概述与核心能力 NaViL-9B是一款原生多模态大语言模型,由专业研究机构开发。它同时具备文本理解和图像分析能力,能够处理纯文本问答和图片内容理解任务。这种双模态能力使…...

疯了!用 AI 做销售,一人能干三人活,效率直接拉满!
一、AI 秒出全场景话术,告别绞尽脑汁从破冰开场、持续跟进,到异议处理、逼单成交,AI 都能根据产品、客户、场景一键生成专业话术。新人不用死记硬背,复制粘贴就能专业沟通;老人不用反复修改,节省大把时间&a…...
)
别再死记硬背了!用Python+OpenCV动手复现计算机视觉核心算法(边缘检测/图像分割实战)
用PythonOpenCV实战复现计算机视觉核心算法:从理论到代码的跨越 计算机视觉作为人工智能领域最炙手可热的方向之一,其核心算法构成了这门学科的骨架。但很多学习者在掌握理论知识后,面对实际项目仍感到无从下手——公式记住了,原理…...