SpringBoot+OCR 实现PDF 内容识别
一、SpringBoot+OCR对pdf文件内容识别提取
1、在 Spring Boot 中,您可以结合 OCR(Optical Character Recognition)库来实现对 PDF 文件内容的识别和提取。
一种常用的 OCR 库是 Tesseract,而 pdf2image 是一个用于将 PDF 转换为图像的工具,可以与 Tesseract 配合使用。
以下是一个简单的 Spring Boot 示例,演示如何使用 Tesseract 和 pdf2image 对 PDF 文件进行 OCR 识别和提取:
- 添加 Maven 依赖:
在您的 Spring Boot 项目中,添加以下依赖:
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency><groupId>org.apache.pdfbox</groupId><artifactId>pdfbox</artifactId><version>2.0.30</version> <!-- 使用最新版本 -->
</dependency>
<dependency><groupId>net.sourceforge.tess4j</groupId><artifactId>tess4j</artifactId><version>4.5.5</version> <!-- 使用最新版本 -->
</dependency>
<dependency><groupId>org.apache.pdfbox</groupId><artifactId>pdfbox-tools</artifactId><version>2.0.30</version> <!-- 使用最新版本 -->
</dependency>
<dependency><groupId>org.apache.pdfbox</groupId><artifactId>pdfbox-debugger</artifactId><version>2.0.30</version> <!-- 使用最新版本 -->
</dependency>
<dependency><groupId>org.apache.pdfbox</groupId><artifactId>pdfbox-app2</artifactId><version>2.0.30</version> <!-- 使用最新版本 -->
</dependency>
<dependency><groupId>org.bouncycastle</groupId><artifactId>bcprov-jdk15on</artifactId><version>1.68</version> <!-- 使用最新版本 -->
</dependency>
- 编写代码:
import net.sourceforge.tess4j.ITesseract;
import net.sourceforge.tess4j.Tesseract;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.text.PDFTextStripper;
import org.apache.pdfbox.tools.PDFToImage;
import org.springframework.stereotype.Service;import java.awt.image.BufferedImage;
import java.io.File;
import java.util.ArrayList;
import java.util.List;@Service
public class OCRService {public String extractTextFromPDF(String pdfFilePath) {try {// Convert PDF to imagesList<BufferedImage> images = convertPDFToImages(pdfFilePath);// Use OCR to extract text from imagesStringBuilder extractedText = new StringBuilder();for (BufferedImage image : images) {extractedText.append(performOCR(image)).append("\n");}return extractedText.toString();} catch (Exception e) {e.printStackTrace();return "Error extracting text from PDF.";}}private List<BufferedImage> convertPDFToImages(String pdfFilePath) throws Exception {List<BufferedImage> images = new ArrayList<>();try (PDDocument document = PDDocument.load(new File(pdfFilePath))) {PDFToImage pdfToImage = new PDFToImage();pdfToImage.setStartPage(1);pdfToImage.setEndPage(document.getNumberOfPages());pdfToImage.setOutputPrefix("outputImage");pdfToImage.processPages(document);for (int i = 1; i <= document.getNumberOfPages(); i++) {BufferedImage image = pdfToImage.getImage(i - 1);images.add(image);}}return images;}private String performOCR(BufferedImage image) throws Exception {ITesseract tesseract = new Tesseract();return tesseract.doOCR(image);}
}
在这个例子中,OCRService 类包含了两个方法。convertPDFToImages 方法将 PDF 文件转换为图像,而 performOCR 方法使用 Tesseract 对图像执行 OCR。最后,extractTextFromPDF 方法将这两个步骤结合在一起,对 PDF 中的每个页面执行 OCR,并返回提取的文本。
请注意,为了使这个示例运行,您需要在系统上安装 Tesseract OCR,并配置其环境变量,以便 Java 可以找到 Tesseract 的执行文件。此外,也需要配置 pdf2image 的相关依赖。
以上代码示例仅供参考,实际项目中可能需要根据具体情况进行适当的调整和优化。
2、Tesseract OCR
Tesseract OCR 是一个开源的光学字符识别引擎,由 Google 开发和维护。它能够识别图像中的文本并将其转换为可编辑的文本格式。以下是一些关于 Tesseract OCR 的关键信息:
主要特点:
- 多语言支持: Tesseract 支持多种语言的文本识别,包括但不限于英语、中文、西班牙语、法语等。
- 开源: Tesseract 是开源的,可以在 GitHub 上找到其源代码。这使得开发人员可以自由使用、修改和分发它。
- 灵活性: Tesseract 可以处理不同字体和样式的文本,并在一定程度上适应图像质量的变化。
- 训练自定义字体: 如果您有特定的字体需要识别,Tesseract 允许您使用训练数据来训练模型,以提高对这些字体的识别能力。
如何使用 Tesseract OCR:
- 安装 Tesseract OCR: 在您的系统上安装 Tesseract。它支持多个操作系统,包括 Windows、Linux 和 macOS。您可以从 Tesseract GitHub Releases 页面下载预编译的二进制文件。
- 配置环境变量: 将 Tesseract 可执行文件所在的目录添加到系统的 PATH 环境变量中,以便在命令行中直接调用 Tesseract。
- 使用 Tesseract: 您可以通过命令行或通过编程语言的接口使用 Tesseract。对于 Java,您可以使用 Tesseract 的 Java API(Tess4J)。
Tess4J(Java API for Tesseract):
Tess4J 是 Tesseract 的 Java 封装库,它允许您在 Java 应用程序中使用 Tesseract OCR。以下是一个简单的 Java 示例:
import net.sourceforge.tess4j.ITesseract;
import net.sourceforge.tess4j.Tesseract;
import java.io.File;public class TesseractExample {public static void main(String[] args) {ITesseract tesseract = new Tesseract();try {File imageFile = new File("path/to/your/image.png");String result = tesseract.doOCR(imageFile);System.out.println("OCR Result:\n" + result);} catch (Exception e) {e.printStackTrace();}}
}
确保您在项目中添加了 Tess4J 的依赖:
<dependency><groupId>net.sourceforge.tess4j</groupId><artifactId>tess4j</artifactId><version>4.5.5</version> <!-- 使用最新版本 -->
</dependency>
此示例演示了如何使用 Tess4J 从图像文件中提取文本。请根据您的实际需求进行适当的配置和扩展。
3、SpringBoot+pdf2image
在Spring Boot中使用pdf2image库进行PDF到图像的转换通常涉及以下几个步骤:
-
添加 Maven 依赖:
在您的 Spring Boot 项目的
pom.xml文件中添加以下依赖:<dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter</artifactId></dependency><dependency><groupId>org.apache.pdfbox</groupId><artifactId>pdfbox</artifactId><version>2.0.30</version></dependency><dependency><groupId>org.apache.pdfbox</groupId><artifactId>pdfbox-tools</artifactId><version>2.0.30</version></dependency><dependency><groupId>org.apache.pdfbox</groupId><artifactId>pdfbox-debugger</artifactId><version>2.0.30</version></dependency><dependency><groupId>org.apache.pdfbox</groupId><artifactId>pdfbox-app2</artifactId><version>2.0.30</version></dependency><dependency><groupId>org.bouncycastle</groupId><artifactId>bcprov-jdk15on</artifactId><version>1.68</version></dependency><dependency><groupId>org.apache.pdfbox</groupId><artifactId>pdfbox-graphics2d</artifactId><version>2.0.30</version></dependency><dependency><groupId>org.apache.pdfbox</groupId><artifactId>pdfbox-font2d</artifactId><version>2.0.30</version></dependency><dependency><groupId>com.github.jai-imageio</groupId><artifactId>jai-imageio-core</artifactId><version>1.4.0</version></dependency><dependency><groupId>com.github.jai-imageio</groupId><artifactId>jai-imageio-jpeg2000</artifactId><version>1.3.0</version></dependency> </dependencies> -
编写代码:
创建一个服务类或控制器类,用于处理 PDF 到图像的转换。以下是一个简单的示例:
import org.apache.pdfbox.pdmodel.PDDocument; import org.apache.pdfbox.rendering.PDFRenderer; import org.apache.pdfbox.tools.imageio.ImageIOUtil; import org.springframework.stereotype.Service;import java.awt.image.BufferedImage; import java.io.File; import java.io.IOException;@Service public class PdfToImageService {public void convertPdfToImages(String pdfFilePath, String outputFolderPath) {try {PDDocument document = PDDocument.load(new File(pdfFilePath));PDFRenderer pdfRenderer = new PDFRenderer(document);for (int page = 0; page < document.getNumberOfPages(); ++page) {BufferedImage image = pdfRenderer.renderImageWithDPI(page, 300); // 300 DPIImageIOUtil.writeImage(image, outputFolderPath + "page_" + (page + 1) + ".png", 300);}document.close();} catch (IOException e) {e.printStackTrace();}} } -
使用服务类:
在您的控制器类或其他需要的地方使用
PdfToImageService:import org.springframework.beans.factory.annotation.Autowired; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.PathVariable; import org.springframework.web.bind.annotation.RestController;@RestController public class PdfToImageController {@Autowiredprivate PdfToImageService pdfToImageService;@GetMapping("/convertPdfToImages/{pdfFileName}")public String convertPdfToImages(@PathVariable String pdfFileName) {String pdfFilePath = "path/to/pdf/files/" + pdfFileName + ".pdf";String outputFolderPath = "path/to/output/folder/";pdfToImageService.convertPdfToImages(pdfFilePath, outputFolderPath);return "PDF to images conversion complete.";} }这是一个简单的示例,您可以根据实际需求进行扩展和修改。确保您的项目中有适当的文件读取和写入权限,并根据需要添加错误处理。
二、SpringBoot+OCR对pdf文件内指定区域的内容识别提取
在Spring Boot中使用OCR对PDF文件的指定区域进行内容识别和提取,您需要结合PDF处理库和OCR库。以下是一个基本的步骤,其中使用了Apache PDFBox作为PDF处理库,Tesseract作为OCR库。
1. 添加 Maven 依赖:
<dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter</artifactId></dependency><dependency><groupId>org.apache.pdfbox</groupId><artifactId>pdfbox</artifactId><version>2.0.30</version></dependency><dependency><groupId>net.sourceforge.tess4j</groupId><artifactId>tess4j</artifactId><version>4.5.5</version></dependency><!-- 其他可能需要的依赖 -->
</dependencies>
2. 编写服务类:
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.text.PDFTextStripper;
import net.sourceforge.tess4j.ITesseract;
import net.sourceforge.tess4j.Tesseract;
import org.springframework.stereotype.Service;import java.awt.Rectangle;
import java.io.File;
import java.io.IOException;@Service
public class PdfOcrService {public String extractTextFromPdfRegion(String pdfFilePath, Rectangle region) {try {PDDocument document = PDDocument.load(new File(pdfFilePath));PDFTextStripper pdfStripper = new PDFTextStripper();pdfStripper.setSortByPosition(true);String pdfText = pdfStripper.getText(document);String extractedText = performOCR(pdfText, region);document.close();return extractedText;} catch (IOException e) {e.printStackTrace();return "Error extracting text from PDF.";}}private String performOCR(String pdfText, Rectangle region) {ITesseract tesseract = new Tesseract();String extractedText = "";try {extractedText = tesseract.doOCR(pdfText, region);} catch (Exception e) {e.printStackTrace();}return extractedText;}
}
3. 使用服务类:
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RestController;import java.awt.Rectangle;@RestController
public class PdfOcrController {@Autowiredprivate PdfOcrService pdfOcrService;@GetMapping("/extractText/{pdfFileName}")public String extractTextFromPdfRegion(@PathVariable String pdfFileName) {String pdfFilePath = "path/to/pdf/files/" + pdfFileName + ".pdf";// Define the region you want to extract (x, y, width, height)Rectangle region = new Rectangle(100, 100, 300, 200);return pdfOcrService.extractTextFromPdfRegion(pdfFilePath, region);}
}
在上述代码中,PdfOcrService 类加载PDF文档并使用PDFBox提取文本。然后,它调用performOCR 方法,该方法使用Tesseract OCR库对指定区域的文本进行识别。
请注意,这只是一个基本示例,您可能需要根据实际需求进行调整。确保在生产环境中处理异常和错误,以确保应用程序的稳定性。
相关文章:

SpringBoot+OCR 实现PDF 内容识别
一、SpringBootOCR对pdf文件内容识别提取 1、在 Spring Boot 中,您可以结合 OCR(Optical Character Recognition)库来实现对 PDF 文件内容的识别和提取。 一种常用的 OCR 库是 Tesseract,而 pdf2image 是一个用于将 PDF 转换为图…...

Go和Java实现抽象工厂模式
Go和Java实现抽象工厂模式 本文通过简单数据库操作案例来说明抽象工厂模式的使用,使用Go语言和Java语言实现。 1、抽象工厂模式 抽象工厂模式是围绕一个超级工厂创建其他工厂。该超级工厂又称为其他工厂的工厂。这种类型的设计模式属于创 建型模式,它…...

深入理解Java虚拟机---内存分配
深入理解Java虚拟机---内存分配 GC日志内存分配与回收策略对象优先在Eden分配大对象直接进入老年代长期存活的对象将进入老年代动态对象年龄判定空间分配担保 GC日志 以下两段典型的GC日志: 33.125: [GC [DefNew: 3324K->152K(3712K), 0.0025925 secs] 3324K-&…...

计算机网络2
OSI参考模型七层: 1.应用层 2.表示层 3.会话层 4.传输层 5.网络层 6.数据链路层 7.物理层 TCP/IP模型 5层参考模型...

jenkins-Generic Webhook Trigger指定分支构建
文章目录 1 需求分析1.1 关键词 : 2、webhooks 是什么?3、配置步骤3.1 github 里需要的仓库配置:3.2 jenkins 的主要配置3.3 option filter配置用于匹配目标分支 实现指定分支构建 1 需求分析 一个项目一般会开多个分支进行开发,测试&#x…...

源码解析8-QSS原理-案例-Qt的qss特殊设置多个子控件的颜色与伪状态
Qt源码解析 索引 源码解析8-QSS原理-案例-Qt的qss特殊设置多个子控件的颜色与伪状态 有些时候我们想特殊设置QSS,比如某一类标题栏目,某一个窗口中的颜色。 重要的是我们需要同时设置多个特殊的按钮等。 统一设置所有 单一按钮全局设置 QPushButton…...
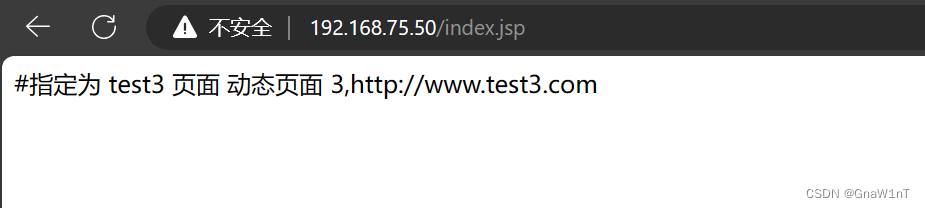
Nginx+Tomcat实现负载均衡和动静分离
目录 前瞻 动静分离和负载均衡原理 实现方法 实验(七层代理) 部署Nginx负载均衡服务器(192.168.75.50:80) 部署第一台Tomcat应用服务器(192.168.75.60:8080) 多实例部署第二台Tomcat应用服务器(192.168.75.70:80…...
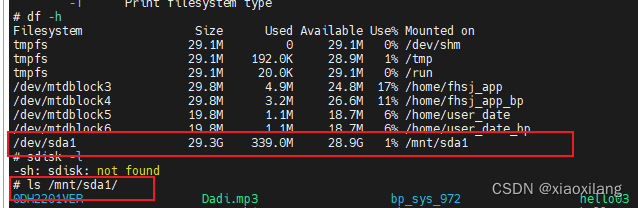
linux系统的u盘/mmc/sd卡等的支持热插拔和自动挂载行为
1.了解mdev mdev是busybox自带的一个简化版的udev。udev是从Linux 2.6 内核系列开始的设备文件系统(DevFS)的替代品,是 Linux 内核的设备管理器。总的来说,它取代了 devfs 和 hotplug,负责管理 /dev 中的设备节点。同时…...
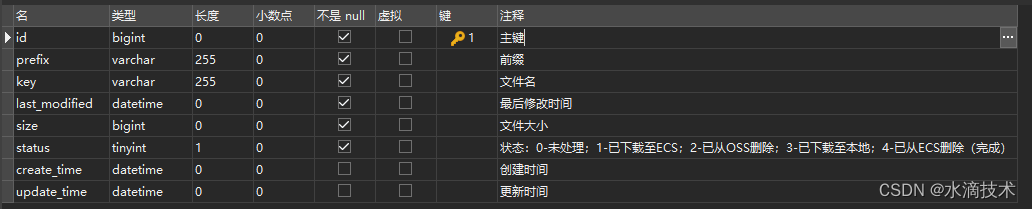
使用Python将OSS文件免费下载到本地:项目分析和准备工作
大家好,我是水滴~~ 本文将介绍如何使用Python编程语言将OSS(对象存储服务)中的文件免费下载到本地计算机。我们先进行项目分析和准备工作,为后续的编码及实施提供基础。 《Python入门核心技术》专栏总目录・点这里 文章目录 1. 前…...
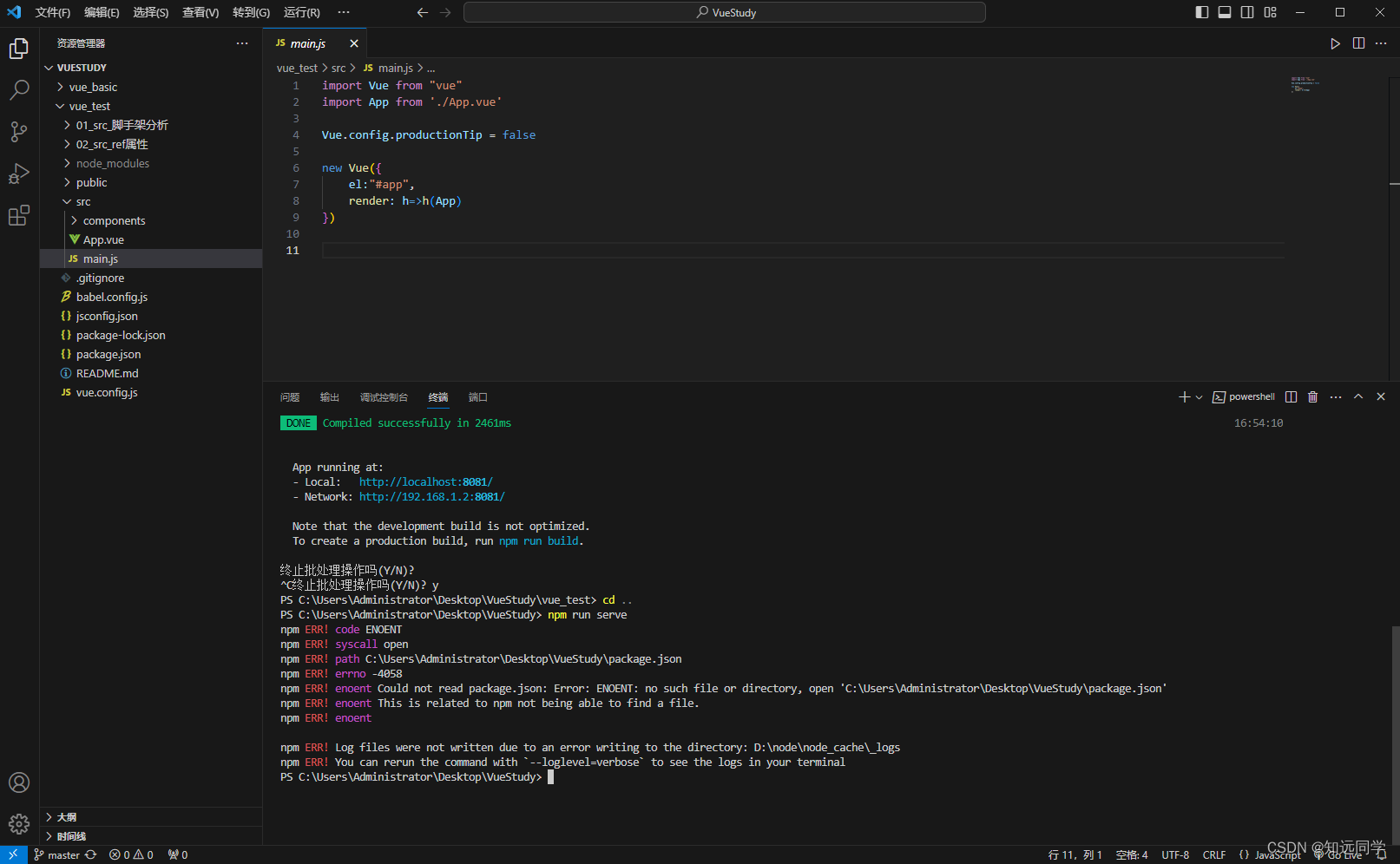
从Gitee克隆项目、启动方法
从gitee克隆VUE项目到本地后,不能直接运行,需要进行npm install安装node_modules文件夹里面的内容,因为在git上传的时候,一般都会过滤到node_modules中的依赖文件。 安装依赖以后,启动通过npm run serve启动项目出错。…...
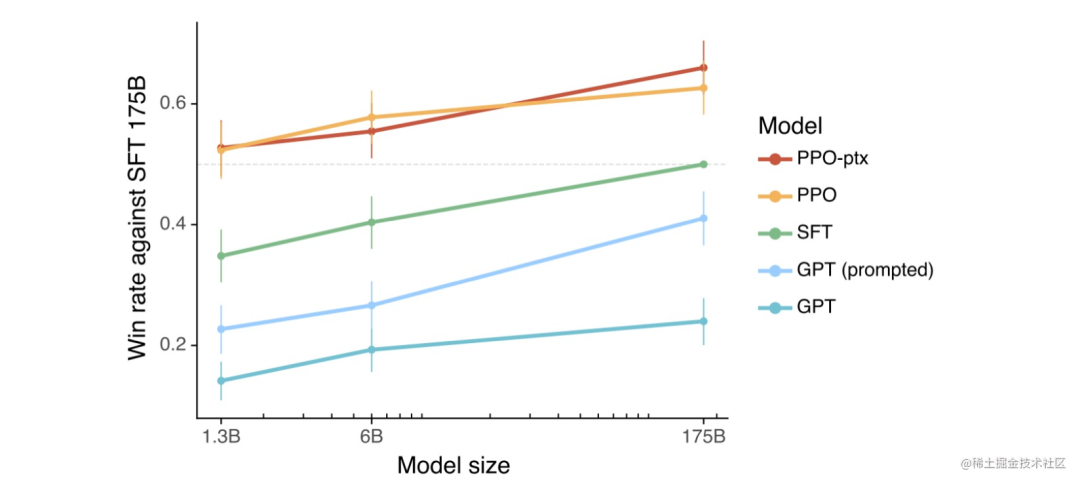
不用再找了,这是大模型实践最全的总结
随着ChatGPT的迅速出圈,加速了大模型时代的变革。对于以Transformer、MOE结构为代表的大模型来说,传统的单机单卡训练模式肯定不能满足上千(万)亿级参数的模型训练,这时候我们就需要解决内存墙和通信墙等一系列问题&am…...

QT 记录
qml 移动窗口会闪烁 int main(int argc, char *argv[]) {QCoreApplication::setAttribute(Qt::AA_UseOpenGLES);//orQCoreApplication::setAttribute(Qt::AA_UseSoftwareOpenGL); }window 拉取qml程序依赖文件 打开QT自带的命令窗口,转到exe程序目录: …...
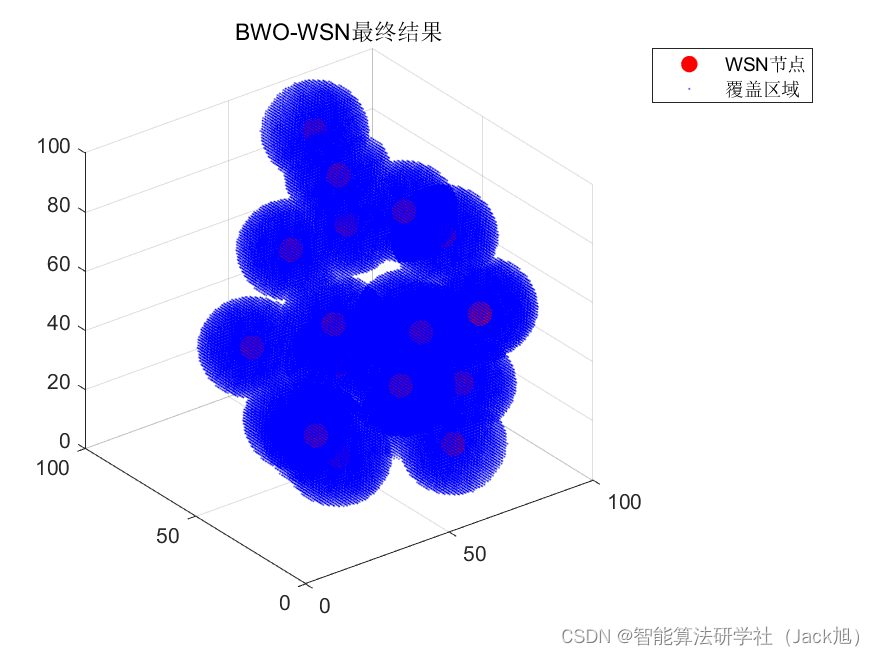
智能优化算法应用:基于黑寡妇算法3D无线传感器网络(WSN)覆盖优化 - 附代码
智能优化算法应用:基于黑寡妇算法3D无线传感器网络(WSN)覆盖优化 - 附代码 文章目录 智能优化算法应用:基于黑寡妇算法3D无线传感器网络(WSN)覆盖优化 - 附代码1.无线传感网络节点模型2.覆盖数学模型及分析3.黑寡妇算法4.实验参数设定5.算法结果6.参考文…...
VSCode 常用的快捷键和技巧系列(2)
一、如何让VSCode工程树显示图标 第一步:安装 快捷键 CtrlP ,输入 ext install vscode-icons ,然后点击安装插件 第二步:配置 安装成功后,点击Reload重新加载。 然后配置,当前图标使用VsCode-Icons Go…...
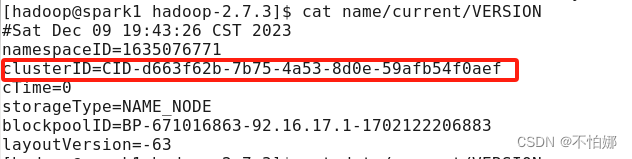
【Hadoop】执行start-dfs.sh启动hadoop集群时,datenode没有启动怎么办
执行start-dfs.sh后,datenode没有启动,很大一部分原因是因为在第一次格式化dfs后又重新执行了格式化命令(hdfs namenode -format),这时主节点namenode的clusterID会重新生成,而从节点datanode的clusterID 保持不变。 在…...
计算机网络(四)
九、网络安全 (一)什么是网络安全? A、网络安全状况 分布式反射攻击逐渐成为拒绝攻击的重要形式 涉及重要行业和政府部门的高危漏洞事件增多。 基础应用和通用软硬件漏洞风险凸显(“心脏出血”,“破壳”等&#x…...
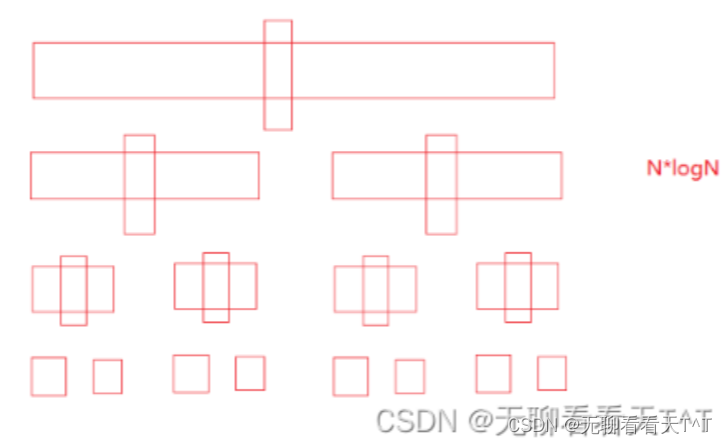
非递归实现的快速排序
目录 序列文章 前言 学前补充 非递归快速排序 注意事项(重要) 实现步骤 代码实现 时空复杂度 快速排序的特性 栈的相关代码 序列文章 非递归实现的快速排序:http://t.csdnimg.cn/UEcL6 快速排序的挖坑法与双指针法:ht…...
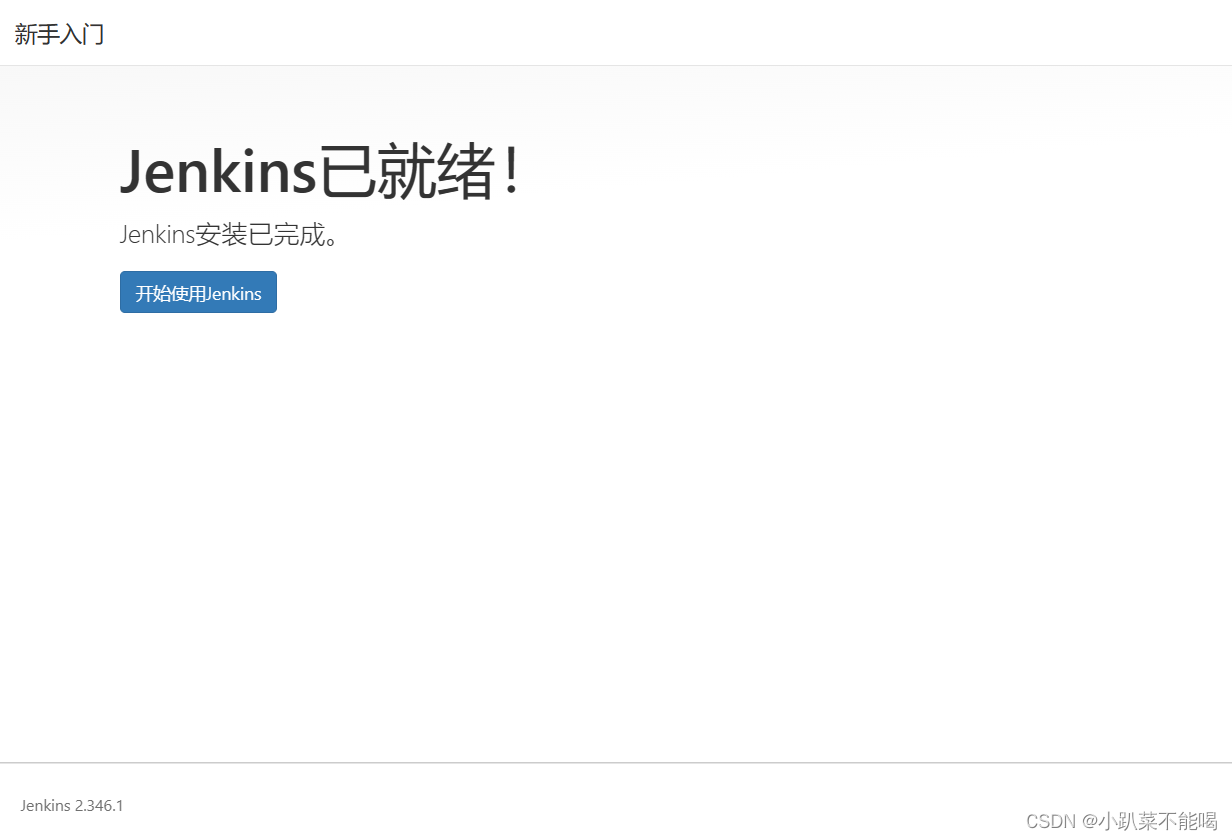
windows 安装jenkins
下载jenkins 官方下载地址:Jenkins 的安装和设置 清华源下载地址:https://mirrors.tuna.tsinghua.edu.cn/jenkins/windows-stable/ 最新支持java8的版本时2.346.1版本,在清华源中找不到,在官网中没找到windows的下载历史ÿ…...
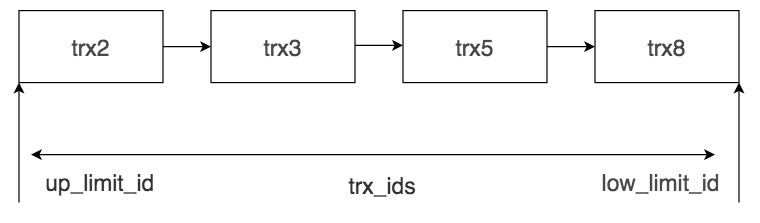
SQL进阶理论篇(十二):InnoDB中的MVCC是如何实现的?
文章目录 简介事务版本号行记录的隐藏列Undo LogRead View的工作流程总结参考文献 简介 在不同的DBMS里,MVCC的实现机制是不同的。本节我们会以InnoDB举例,讲解InnoDB里MVCC的实现机制。 我们需要掌握这么几个概念: 事务版本号行记录的隐藏…...

SpringCloudAliBaba篇之Seata:分布式事务组件理论与实践
1、事务简介 事务(Transaction)是访问并可能更新数据库中各种数据项的一个程序执行单元(unit)。在关系数据库中,一个事务由一组SQL语句组成,事务具有4个属性:原子性、一致性、隔离性、持久性。这四个属性通常称为ACID原则。 原子性(atomici…...

AMD笔记本性能优化与温度控制完全指南:使用G-Helper实现CPU降压调优
AMD笔记本性能优化与温度控制完全指南:使用G-Helper实现CPU降压调优 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops. Control tool for ROG Zephyrus G14, G15, G16, M16, Flow X13, Flow X16, TUF, Strix, Scar and other mod…...

别再死记硬背DAQmx流程了!LabVIEW数据采集核心逻辑拆解:以USB-6008正弦波实验为例
从设计模式视角重构LabVIEW数据采集:以USB-6008正弦波实验为例 当LabVIEW新手第一次接触DAQmx数据采集时,往往会被"创建任务→添加通道→配置时钟→开始任务→读取数据→清除任务"的固定流程所困扰。这种机械记忆不仅容易遗忘,更难…...

从七鳃鳗到潜水器:手把手教你用Python生态学模型搞定2024美赛A、B题
从七鳃鳗到潜水器:Python生态学建模实战指南 数学建模竞赛中,生态学问题往往让参赛者望而生畏——复杂的生物系统、多变的环境参数、非线性相互作用,这些要素叠加起来容易让人陷入理论推导的泥潭。但换个角度看,这正是Python科学计…...

TinyCheck开发指南:从源码结构到核心类设计,理解网络安全检测平台架构
TinyCheck开发指南:从源码结构到核心类设计,理解网络安全检测平台架构 【免费下载链接】TinyCheck TinyCheck allows you to easily capture network communications from a smartphone or any device which can be associated to a Wi-Fi access point …...

保姆级避坑指南:在Windows上用VirtualBox 6.0.24跑Ubuntu,从开机报错到完美显示的完整流程
从开机报错到完美显示:VirtualBox 6.0.24运行Ubuntu全流程实战手册 当你第一次在Windows上用VirtualBox启动Ubuntu虚拟机时,那个刺眼的报错提示可能会让你措手不及。别担心,这几乎是每个虚拟化新手都会经历的"成人礼"。本文将带你完…...
对齐工具(左对齐/居中对齐/右对齐)对齐工具(左对齐/居中对齐/右对齐)对齐工具(左对齐/居中对齐/右对齐)对齐工具(左对齐/)
《QGIS快速入门与应用基础》248:对齐工具(左对齐/居中对齐/右对齐)对齐工具(左对齐/居中对齐/右对齐)对齐工具(左对齐/居中对齐/右对齐)对齐工具(左对齐/居中对齐/右对齐)对齐工具(左对齐/
作者:翰墨之道,毕业于国际知名大学空间信息与计算机专业,获硕士学位,现任国内时空智能领域资深专家、CSDN知名技术博主。多年来深耕地理信息与时空智能核心技术研发,精通 QGIS、GrassGIS、OSG、OsgEarth、UE、Cesium、OpenLayers、Leaflet、MapBox 等主流工具与框架,兼具…...

布隆过滤器与哈希索引:两级验证模型
在高并发、大数据量的系统中,快速判断一个元素是否“已经存在”是一项基础而关键的能力。无论是防止重复提交、抵御缓存穿透,还是实现分布式去重,都需要一种高效的存在性检查机制。实践中,布隆过滤器(Bloom Filter&…...

智汇云舟亮相2026中关村论坛 联合发起“通智行业大脑”联盟
3月29日,作为中关村论坛年会的重要组成部分,“迈向通用人工智能”平行论坛在中关村国家自主创新示范区展示交易中心隆重举行。本次论坛由北京市科学技术委员会、中关村科技园区管理委员会、北京市海淀区人民政府联合主办,北京通用人工智能研究…...

嵌入式C编程挑战与防御性编程实践
1. 嵌入式C编程的核心挑战在嵌入式系统开发中,C语言因其接近硬件的特性和高效的执行效率成为首选语言。然而,嵌入式环境与通用计算环境存在显著差异,这些差异给程序员带来了独特的挑战。1.1 硬件资源的严格限制嵌入式设备通常具有:…...

万物识别镜像在内容安全场景的应用:SpringBoot集成与效果展示
万物识别镜像在内容安全场景的应用:SpringBoot集成与效果展示 1. 万物识别镜像技术解析 万物识别-中文-通用领域镜像基于cv_resnest101_general_recognition算法构建,是一个强大的视觉识别工具。这个镜像最突出的特点是能够识别超过5万类日常物体&…...