十六、YARN和MapReduce配置
1、部署前提
(1)配置前提
已经配置好Hadoop集群。
配置内容:

(2)部署说明

(3)集群规划

2、修改配置文件
MapReduce
(1)修改mapred-env.sh配置文件
export JAVA_HOME=/export/server/jdk
export HADOOP_JOB_HISTORYSERVER_HEAPSIZE=1000
export HADOOP_MAPRED_ROOT_LOGGER=INFO,RFA(2)修改mapred-site.xml配置文件
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value><description></description></property><property><name>mapreduce.jobhistory.address</name><value>node1:10020</value><description></description></property><property><name>mapreduce.jobhistory.webapp.address</name><value>node1:19888</value><description></description></property><property><name>mapreduce.jobhistory.intermediate-done-dir</name><value>/data/mr-history/tmp</value><description></description></property><property><name>mapreduce.jobhistory.done-dir</name><value>/data/mr-history/done</value><description></description></property><property><name>yarn.app.mapreduce.am.env</name><value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value></property><property><name>mapreduce.map.env</name><value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value></property><property><name>mapreduce.reduce.env</name><value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value></property>
</configuration>
yarn
(1)修改yarn-env.sh文件
export JAVA_HOME=/export/server/jdk
export HADOOP_HOME=/export/server/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
# export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
# export YARN_LOG_DIR=$HADOOP_HOME/logs/yarn
export HADOOP_LOG_DIR=$HADOOP_HOME/logs
(2)修改yarn-site.xml文件
<configuration><!-- Site specific YARN configuration properties -->
<property><name>yarn.log.server.url</name><value>http://node1:19888/jobhistory/logs</value><description></description>
</property><property><name>yarn.web-proxy.address</name><value>node1:8089</value><description>proxy server hostname and port</description></property><property><name>yarn.log-aggregation-enable</name><value>true</value><description>Configuration to enable or disable log aggregation</description></property><property><name>yarn.nodemanager.remote-app-log-dir</name><value>/tmp/logs</value><description>Configuration to enable or disable log aggregation</description></property><!-- Site specific YARN configuration properties --><property><name>yarn.resourcemanager.hostname</name><value>node1</value><description></description></property><property><name>yarn.resourcemanager.scheduler.class</name><value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value><description></description></property><property><name>yarn.nodemanager.local-dirs</name><value>/data/nm-local</value><description>Comma-separated list of paths on the local filesystem where intermediate data is written.</description></property><property><name>yarn.nodemanager.log-dirs</name><value>/data/nm-log</value><description>Comma-separated list of paths on the local filesystem where logs are written.</description></property><property><name>yarn.nodemanager.log.retain-seconds</name><value>10800</value><description>Default time (in seconds) to retain log files on the NodeManager Only applicable if log-aggregation is disabled.</description></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value><description>Shuffle service that needs to be set for Map Reduce applications.</description></property>
</configuration>
分发配置文件

3、开启YARN服务器集群
(1)node1节点,以Hadoop用户,执行如下语句:
//开启Hadoop集群
start-dfs.sh
//开启yarn集群
start-yarn.sh
//因为代理服务器已经在配置文件中配置完毕,但历史服务器需要手动开启
//开启历史服务器
mapred --daemon start historyserver(2)执行结果展示、
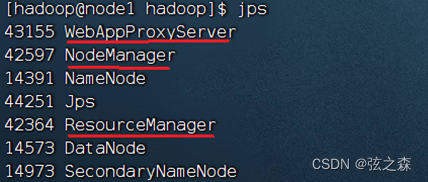

(3)查看YARN的Web-UI页面
打开本地浏览器,输入node1:8088,即可打开本地YARN的Web-UI页面。

4、总结

相关文章:
十六、YARN和MapReduce配置
1、部署前提 (1)配置前提 已经配置好Hadoop集群。 配置内容: (2)部署说明 (3)集群规划 2、修改配置文件 MapReduce (1)修改mapred-env.sh配置文件 export JAVA_HOM…...

自己动手写编译器:语法解析的基本原理
在前面系列章节中我们完成了词法解析。词法解析的基本任务就是判断给定字符串是否符合特定规则,如果符合那么就给这个字符串分配一个标签(token)。词法解析完成后接下来的工作就要分配给语法解析,后者的任务就是判断一系列标签的组合是否符合特定规范。 …...
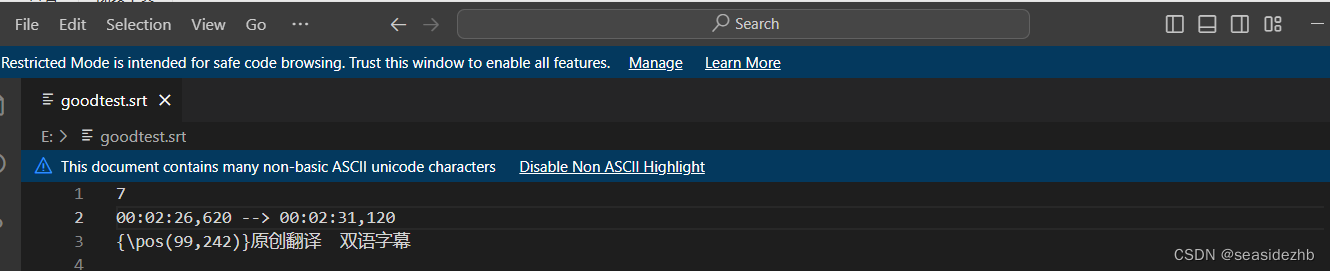
VS Code解决乱码
在上边搜索栏输入“>Change File Encoding”,更改编码格式,解决乱码格式。 VS Code会帮助确认编码格式,然后选择就好。 最后完成如下:...
宝塔Linux:部署His医疗项目通过jar包的方式
📚📚 🏅我是默,一个在CSDN分享笔记的博主。📚📚 🌟在这里,我要推荐给大家我的专栏《Linux》。🎯🎯 🚀无论你是编程小白,还是有…...

Vim命令大全(超详细,适合反复阅读学习)
Vim命令大全 Vim简介Vim中的模式光标移动命令滚屏与跳转文本插入操作文本删除操作文本复制、剪切与粘贴文本的修改与替换文本的查找与替换撤销修改、重做与保存编辑多个文件标签页与折叠栏多窗口操作总结 Vim是一款文本编辑器,是Vi编辑器的增强版。Vim的特点是快速、…...

爬虫持久化保存
## open方法- 方法名称及参数markdown **open(file, moder, bufferingNone, encodingNone, errorsNone, newlineNone, closefdTrue)****file** 文件的路径,需要带上文件名包括文件后缀(c:\\1.txt)**mode** 打开的方式(r,w,a,x,b,t…...
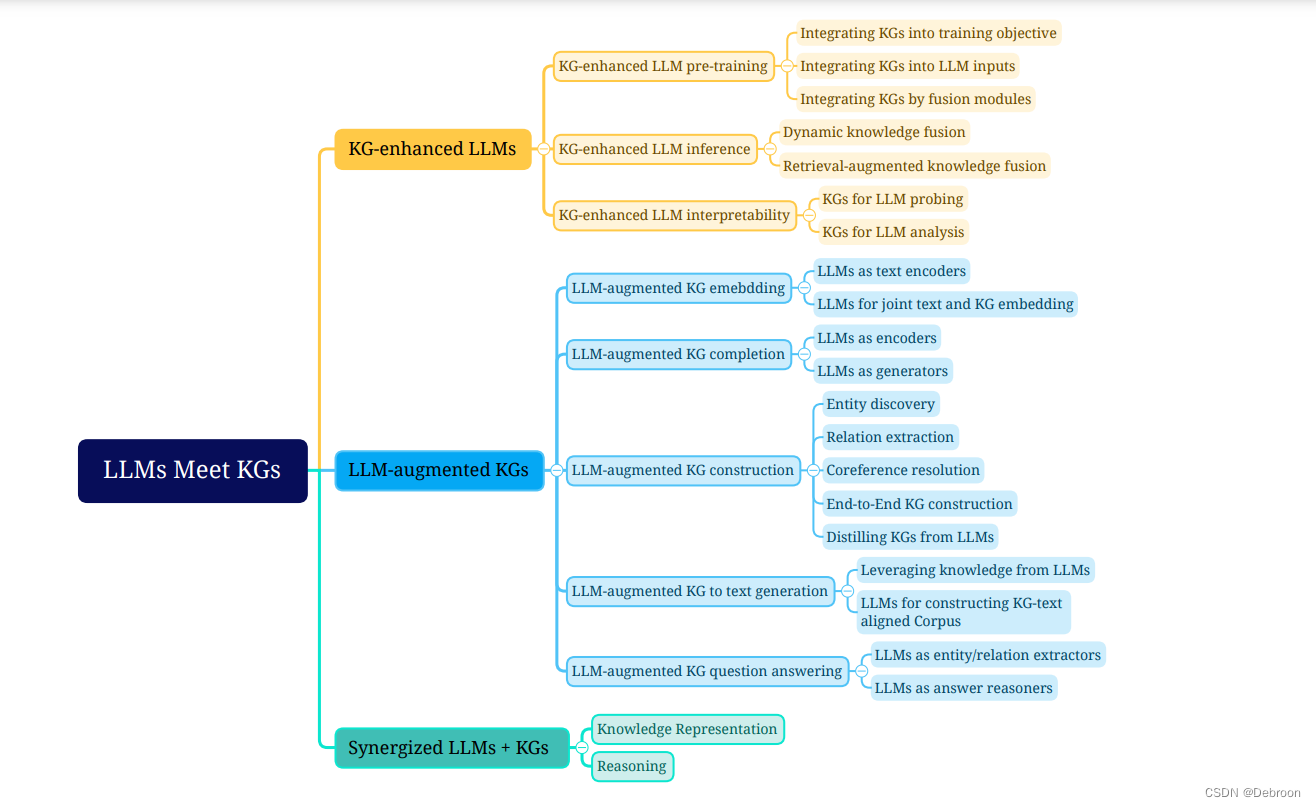
统一大语言模型和知识图谱:如何解决医学大模型-问诊不充分、检查不准确、诊断不完整、治疗方案不全面?
统一大语言模型和知识图谱:如何解决医学大模型问诊不充分、检查不准确、诊断不完整、治疗方案不全面? 医学大模型问题如何使用知识图谱加强和补足专业能力?大模型结构知识图谱增强大模型的方法 医学大模型问题 问诊。偏离主诉和没抓住核心。…...

读写分离之同步延迟测试
背景 读写分离是快速提高数据库性能的手段,主库只负责写入,从库负责查询。但在性能得到提升的同时,编程的复杂度就会提升。由其碰到主从同步延迟的情况,在数据写入后,在从库无法读取到最新数据,会对业务逻…...

SpringBoot+OCR 实现PDF 内容识别
一、SpringBootOCR对pdf文件内容识别提取 1、在 Spring Boot 中,您可以结合 OCR(Optical Character Recognition)库来实现对 PDF 文件内容的识别和提取。 一种常用的 OCR 库是 Tesseract,而 pdf2image 是一个用于将 PDF 转换为图…...

Go和Java实现抽象工厂模式
Go和Java实现抽象工厂模式 本文通过简单数据库操作案例来说明抽象工厂模式的使用,使用Go语言和Java语言实现。 1、抽象工厂模式 抽象工厂模式是围绕一个超级工厂创建其他工厂。该超级工厂又称为其他工厂的工厂。这种类型的设计模式属于创 建型模式,它…...

深入理解Java虚拟机---内存分配
深入理解Java虚拟机---内存分配 GC日志内存分配与回收策略对象优先在Eden分配大对象直接进入老年代长期存活的对象将进入老年代动态对象年龄判定空间分配担保 GC日志 以下两段典型的GC日志: 33.125: [GC [DefNew: 3324K->152K(3712K), 0.0025925 secs] 3324K-&…...

计算机网络2
OSI参考模型七层: 1.应用层 2.表示层 3.会话层 4.传输层 5.网络层 6.数据链路层 7.物理层 TCP/IP模型 5层参考模型...

jenkins-Generic Webhook Trigger指定分支构建
文章目录 1 需求分析1.1 关键词 : 2、webhooks 是什么?3、配置步骤3.1 github 里需要的仓库配置:3.2 jenkins 的主要配置3.3 option filter配置用于匹配目标分支 实现指定分支构建 1 需求分析 一个项目一般会开多个分支进行开发,测试&#x…...

源码解析8-QSS原理-案例-Qt的qss特殊设置多个子控件的颜色与伪状态
Qt源码解析 索引 源码解析8-QSS原理-案例-Qt的qss特殊设置多个子控件的颜色与伪状态 有些时候我们想特殊设置QSS,比如某一类标题栏目,某一个窗口中的颜色。 重要的是我们需要同时设置多个特殊的按钮等。 统一设置所有 单一按钮全局设置 QPushButton…...
Nginx+Tomcat实现负载均衡和动静分离
目录 前瞻 动静分离和负载均衡原理 实现方法 实验(七层代理) 部署Nginx负载均衡服务器(192.168.75.50:80) 部署第一台Tomcat应用服务器(192.168.75.60:8080) 多实例部署第二台Tomcat应用服务器(192.168.75.70:80…...
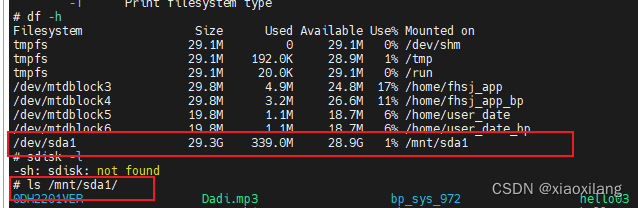
linux系统的u盘/mmc/sd卡等的支持热插拔和自动挂载行为
1.了解mdev mdev是busybox自带的一个简化版的udev。udev是从Linux 2.6 内核系列开始的设备文件系统(DevFS)的替代品,是 Linux 内核的设备管理器。总的来说,它取代了 devfs 和 hotplug,负责管理 /dev 中的设备节点。同时…...
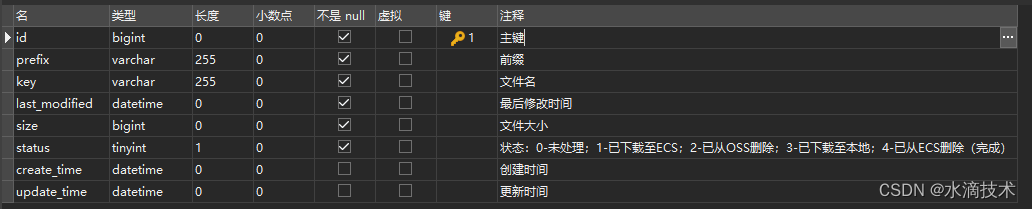
使用Python将OSS文件免费下载到本地:项目分析和准备工作
大家好,我是水滴~~ 本文将介绍如何使用Python编程语言将OSS(对象存储服务)中的文件免费下载到本地计算机。我们先进行项目分析和准备工作,为后续的编码及实施提供基础。 《Python入门核心技术》专栏总目录・点这里 文章目录 1. 前…...
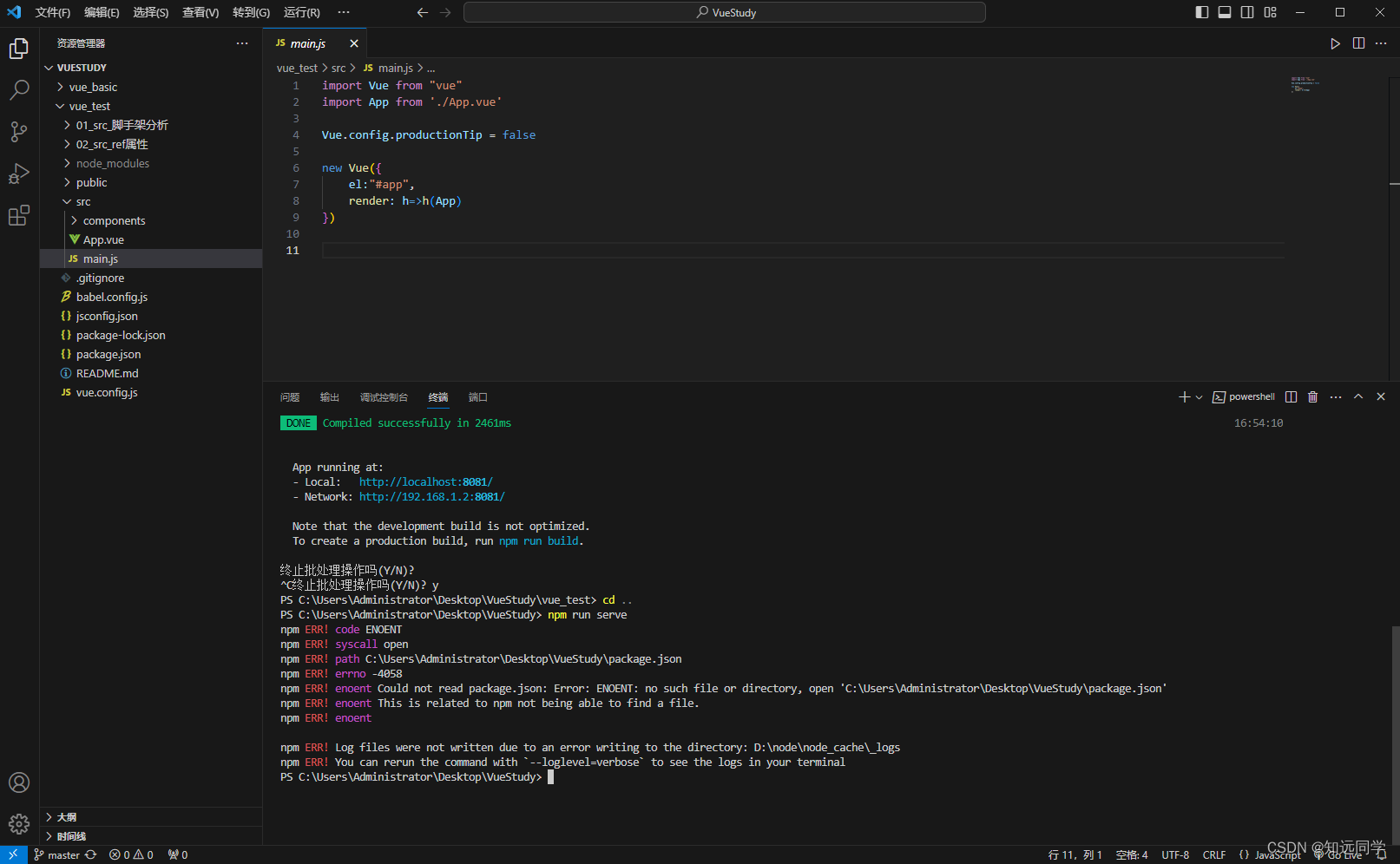
从Gitee克隆项目、启动方法
从gitee克隆VUE项目到本地后,不能直接运行,需要进行npm install安装node_modules文件夹里面的内容,因为在git上传的时候,一般都会过滤到node_modules中的依赖文件。 安装依赖以后,启动通过npm run serve启动项目出错。…...
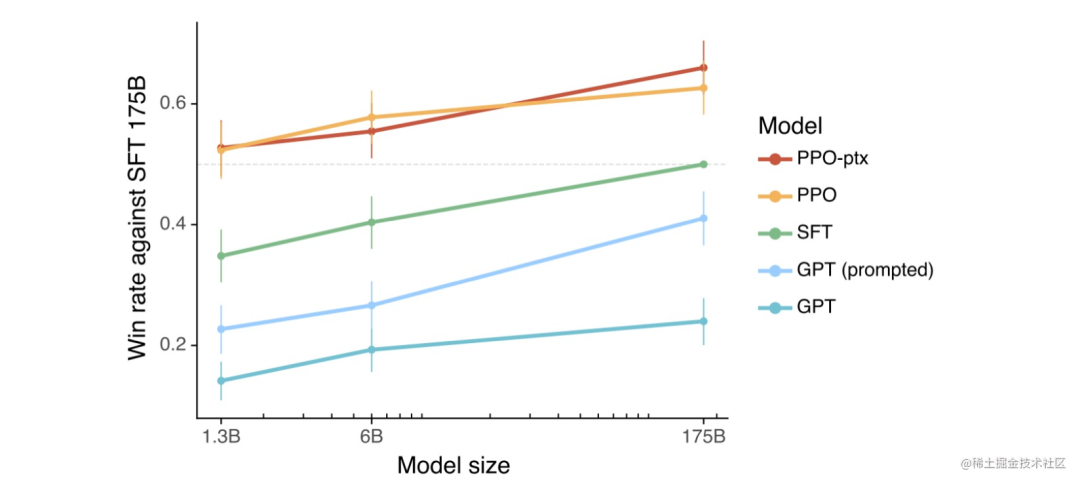
不用再找了,这是大模型实践最全的总结
随着ChatGPT的迅速出圈,加速了大模型时代的变革。对于以Transformer、MOE结构为代表的大模型来说,传统的单机单卡训练模式肯定不能满足上千(万)亿级参数的模型训练,这时候我们就需要解决内存墙和通信墙等一系列问题&am…...

QT 记录
qml 移动窗口会闪烁 int main(int argc, char *argv[]) {QCoreApplication::setAttribute(Qt::AA_UseOpenGLES);//orQCoreApplication::setAttribute(Qt::AA_UseSoftwareOpenGL); }window 拉取qml程序依赖文件 打开QT自带的命令窗口,转到exe程序目录: …...

Unity游戏模组加载效率提升指南:从零开始掌握MelonLoader
Unity游戏模组加载效率提升指南:从零开始掌握MelonLoader 【免费下载链接】MelonLoader The Worlds First Universal Mod Loader for Unity Games compatible with both Il2Cpp and Mono 项目地址: https://gitcode.com/gh_mirrors/me/MelonLoader 一、问题引…...

构建智能游戏AI的理想训练场:腾讯王者荣耀AI开放环境全解析
构建智能游戏AI的理想训练场:腾讯王者荣耀AI开放环境全解析 【免费下载链接】hok_env Honor of Kings AI Open Environment of Tencent 项目地址: https://gitcode.com/gh_mirrors/ho/hok_env 强化学习研究如何突破理论到实践的鸿沟?如何在真实游…...

终极指南:如何用F3工具快速检测U盘和SD卡真实容量
终极指南:如何用F3工具快速检测U盘和SD卡真实容量 【免费下载链接】f3 F3 - Fight Flash Fraud 项目地址: https://gitcode.com/gh_mirrors/f3/f3 在数字时代,存储设备容量造假已成为普遍问题,许多U盘、SD卡通过软件修改显示虚假容量&…...

终极指南:如何用Docker快速部署opencommit AI提交工具
终极指南:如何用Docker快速部署opencommit AI提交工具 【免费下载链接】opencommit Auto-generate impressive commits with AI in 1 second 🤯🔫 项目地址: https://gitcode.com/gh_mirrors/op/opencommit opencommit是一款AI驱动的提…...
)
告别模拟信号烦恼:手把手教你用51单片机驱动DAC0832输出正弦波(附Proteus仿真)
51单片机实战:用DAC0832打造完美正弦波发生器 在电子设计领域,能够精确生成模拟信号是一项基础却至关重要的技能。想象一下,当你亲手搭建的电路在示波器上显示出光滑的正弦波形时,那种成就感是无与伦比的。本文将带你从零开始&…...

Z-Image-GGUF实战:为Android应用集成AI头像生成功能
Z-Image-GGUF实战:为Android应用集成AI头像生成功能 最近在做一个社交类的Android应用,产品经理提了个需求,想加入一个“AI生成个性头像”的功能。用户上传一张自己的照片,选择喜欢的风格(比如动漫风、油画感、像素艺…...

Marker:突破PDF转换瓶颈的革新性文档处理工具
Marker:突破PDF转换瓶颈的革新性文档处理工具 【免费下载链接】marker 一个高效、准确的工具,能够将 PDF 和图像快速转换为 Markdown、JSON 和 HTML 格式,支持多语言和复杂布局处理,可选集成 LLM 提升精度,适用于学术文…...

永磁同步电机矢量控制进阶:电流环前馈补偿的5个关键点与避坑指南
永磁同步电机矢量控制进阶:电流环前馈补偿的5个关键点与避坑指南 在工业伺服系统与新能源驱动领域,永磁同步电机(PMSM)凭借其高功率密度和动态响应特性占据主导地位。而电流环作为矢量控制的内环,其性能直接影响整个系…...

3分钟上手AnyKernel3:打造跨设备兼容的Android内核刷机包
3分钟上手AnyKernel3:打造跨设备兼容的Android内核刷机包 【免费下载链接】AnyKernel3 项目地址: https://gitcode.com/gh_mirrors/an/AnyKernel3 在Android内核开发领域,如何让一个内核兼容多种设备和ROM版本一直是个挑战。AnyKernel3正是为解决…...

SQLite向量检索实战指南:Java开发者的嵌入式AI能力集成落地教程
SQLite向量检索实战指南:Java开发者的嵌入式AI能力集成落地教程 【免费下载链接】sqlite-vec Work-in-progress vector search SQLite extension that runs anywhere. 项目地址: https://gitcode.com/GitHub_Trending/sq/sqlite-vec 一、技术价值:…...