selenium学习
前期准备
pip install selenium
获取浏览器驱动
我使用的浏览器是Chrome,所以这里只介绍关于Chrome获取浏览器驱动的方法:
需要注意的是:selenium 4.x 对之前版本的部分API调用方式进行了调整,这里就包括关于浏览器获取驱动的方式,最新版本获取驱动的方式如下:
1.在Chrome浏览器的设置页面查看自己浏览的版本
2.在如下页面获取对应的驱动:
人机验证
API如下:
# 获取驱动并打开网页
service = Service(executable_path=r"/Users/liujianlei/Downloads/mopi/chromedriver-mac-arm64/chromedriver")
driver = webdriver.Chrome(service=service)常用API
selenium常用引入的包如下:
from bs4 import BeautifulSoup
import requests
import openpyxl
from fake_useragent import UserAgent
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC常用api如下:
获取元素
新版本对获取元素的api调用方式,新的api使用方式如下:
# inputTag = driver.find_element_by_id("value") # 利用ID查找
# 改为:
inputTag = driver.find_element(By.ID, "value")# inputTags = driver.find_element_by_class_name("value") # 利用类名查找
# 改为:
inputTag = driver.find_element(By.CLASS_NAME, "value")# inputTag = driver.find_element_by_name("value") # 利用name属性查找
# 改为:
inputTag = driver.find_element(By.NAME, "value")# inputTag = driver.find_element_by_tag_name("value") # 利用标签名查找
# 改为:
inputTag = driver.find_element(By.TAG_NAME, "value")# inputTag = driver.find_element_by_xpath("value") # 利用xpath查找
# 改为:
inputTag = driver.find_element(By.XPATH, "value")# inputTag = driver.find_element_by_css_selector("value") # 利用CSS选择器查找
# 改为:
inputTag = driver.find_element(By.CSS_SELECTOR, "value")
控制浏览器操作
- 控制浏览器窗口大小
driver.set_window_size(480, 800)
- 浏览器后退,前进
# 后退 driver.back()
# 前进 driver.forward()
- 刷新
driver.refresh() # 刷新
鼠标操作
- perform(): 执行所有 ActionChains 中存储的行为;
- context_click(): 右击;
- double_click(): 双击;
- drag_and_drop(): 拖动;
- move_to_element(): 鼠标悬停。
- 需要注意的是:鼠标操作完之后,一定要紧跟perform(),不然这
键盘操作
- send_keys(Keys.BACK_SPACE) 删除键(BackSpace)
- send_keys(Keys.SPACE) 空格键(Space)
- send_keys(Keys.TAB) 制表键(Tab)
- send_keys(Keys.ESCAPE) 回退键(Esc)
- send_keys(Keys.ENTER) 回车键(Enter)
- send_keys(Keys.CONTROL,'a') 全选(Ctrl+A)
- send_keys(Keys.CONTROL,'c') 复制(Ctrl+C)
- send_keys(Keys.CONTROL,'x') 剪切(Ctrl+X)
- send_keys(Keys.CONTROL,'v') 粘贴(Ctrl+V)
- send_keys(Keys.F1) 键盘 F1
- ……
- send_keys(Keys.F12) 键盘 F12
获取断言信息
text = driver.page_source # 获取当前页面的源码:需要注意的是:
动态加载:driver.page_source 获取的源码是当前浏览器渲染后的完整页面源码,包括通过 JavaScript 动态加载的内容。而 requests 获取的源码是初始的静态页面源码,不包含 JavaScript 动态加载的内容。AJAX 请求:如果页面中通过 AJAX 请求加载内容,requests 获取的源码可能不包含这部分内容,而 driver.page_source 获取的源码会包含通过 AJAX 请求加载的内容。JavaScript 渲染:requests 不能执行 JavaScript,因此无法获取 JavaScript 渲染后的页面内容,而 driver.page_source 获取的源码是经过 JavaScript 渲染后的页面内容。综上所述,如果网站通过 JavaScript 动态加载内容或进行 AJAX 请求,那么 driver.page_source 获取的源码和 requests 获取的源码可能会有所不同。在实际应用中,您需要根据具体的需求和情况选择合适的获取源码的方法。
由于以上等原因,最终使用requests获取的网页源码可能和selenium获取的源码有所缺失,一般我们直接使用selenium获取网页的源码
title = driver.title # 打印当前页面title
now_url = driver.current_url # 打印当前页面URL等待页面加载完成
- 显示等待
显式等待使WebdDriver等待某个条件成立时继续执行,否则在达到最大时长时抛出超时异常(TimeoutException)。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as ECdriver = webdriver.Firefox()
driver.get("http://www.baidu.com")element = WebDriverWait(driver, 5, 0.5).until(EC.presence_of_element_located((By.ID, "kw")))
element.send_keys('selenium')
driver.quit()WebDriverWait类是由WebDirver 提供的等待方法。在设置时间内,默认每隔一段时间检测一次当前页面元素是否存在,如果超过设置时间检测不到则抛出异常。具体格式如下:
WebDriverWait(driver, timeout, poll_frequency=0.5, ignored_exceptions=None)
- driver :浏览器驱动。
- timeout :最长超时时间,默认以秒为单位。
- poll_frequency :检测的间隔(步长)时间,默认为0.5S。
- ignored_exceptions :超时后的异常信息,默认情况下抛NoSuchElementException异常。
- WebDriverWait()一般由until()或until_not()方法配合使用,下面是until()和until_not()方法的说明。
- until(method, message=‘’) 调用该方法提供的驱动程序作为一个参数,直到返回值为True。
- until_not(method, message=‘’) 调用该方法提供的驱动程序作为一个参数,直到返回值为False。
在本例中,通过as关键字将expected_conditions 重命名为EC,并调用presence_of_element_located()方法判断元素是否存在。
- EC对应的不同方法如下:
- presence_of_element_located:等待直到某个元素出现在DOM中。
- visibility_of_element_located:等待直到某个元素在页面上可见。
- element_to_be_clickable:等待直到某个元素可被点击。
- text_to_be_present_in_element:等待直到某个元素包含特定的文本。
- 隐式等待
隐式等待:通过设置隐式等待时间,可以让WebDriver在查找元素或执行操作时等待一定的时间。如果在规定的时间内找到了元素,就会立即执行后续的操作;如果超过了设定的时间而没有找到元素,就会抛出NoSuchElementException异常。隐式等待对整个WebDriver的生命周期都起作用,只需要设置一次即可。
driver.implicitly_wait(10)切换模块
切换窗口
handles = driver.window_handles
print("handles的类型为:",type(handles))
print("handles = ",handles)
print("title的值为:",title)
# 切换具柄
driver.switch_to.window(handles[1])切换实例:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
# 获取驱动并打开网页
service = Service(executable_path=r"/Users/liujianlei/Downloads/mopi/chromedriver-mac-arm64/chromedriver")
driver = webdriver.Chrome(service=service)
# 打开网页
url = "https://login.anjuke.com/login/form"
driver.get(url)
# 等待元素加载出来
wait = WebDriverWait(driver,10,0.5).until(EC.presence_of_element_located((By.XPATH,"//*[@id=\"iframeLoginIfm\"]")))
# 查找对应的iframe元素
iframe = driver.find_element(By.XPATH,"//*[@id=\"iframeLoginIfm\"]")
# 切换为iframe
driver.switch_to.frame(iframe)
# 点击切换为账号密码登录
element = driver.find_element(By.XPATH,"//*[@id=\"pwdTab\"]")
# 点击元素
element.click()
# 输入用户名
user_element = driver.find_element(By.ID,"pwdUserNameIpt")
user_element.send_keys("123")
# 输入密码
pwd_element = driver.find_element(By.ID,"pwdIpt")
pwd_element.send_keys("123")
# 勾选我已同意
element_agree = driver.find_element(By.ID,"checkagree")
element_agree.click()
# 点击登录
login_element =driver.find_element(By.ID,"pwdSubmitBtn")
login_element.click()
# 切换为上一层的图层
driver.switch_to.parent_frame()
# 点击家居网进行页面跳转,查看当前是哪个窗口
element_web = driver.find_element(By.XPATH,"/html/body/div[1]/a[1]/i")
element_web.click()
# 获取当前的window
window_name = driver.title
print("{}为当前的title".format(window_name))
time.sleep(100)
# element = driver.find_element(By.XPATH,"//*[@id=\"phoneIpt\"]")
# element.send_keys("13153382278")
# 切换新的元素
切换iframe
# 切换为iframe
driver.switch_to.frame(iframe)
# 点击切换为账号密码登录
element = driver.find_element(By.XPATH,"//*[@id=\"pwdTab\"]")
# 点击元素
element.click()
# 输入用户名
user_element = driver.find_element(By.ID,"pwdUserNameIpt")
user_element.send_keys("123")
# 输入密码
pwd_element = driver.find_element(By.ID,"pwdIpt")
pwd_element.send_keys("123")
# 勾选我已同意
element_agree = driver.find_element(By.ID,"checkagree")
element_agree.click()
# 点击登录
login_element =driver.find_element(By.ID,"pwdSubmitBtn")
login_element.click()
# 切换为上一层的图层
driver.switch_to.parent_frame()切换实例:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
# 练习:访问聚合,点击“开发者”
url = "https://www.juhe.cn/"
service = Service(executable_path=r"/Users/liujianlei/Downloads/mopi/chromedriver-mac-arm64/chromedriver")
driver = webdriver.Chrome(service= service)
driver.get(url)
driver.find_element(By.LINK_TEXT,"开发者").click()
# 查看是哪个窗口
title = driver.title
# 获取所有的窗口具柄
handles = driver.window_handles
print("handles的类型为:",type(handles))
print("handles = ",handles)
print("title的值为:",title)
# 切换具柄
driver.switch_to.window(handles[1])
# 点击新页面的元素
element = driver.find_element(By.XPATH,"//*[@id=\"__layout\"]/div/div[1]/div[1]/div/div/div[1]/div/a[2]").click()
# 切换回原来的具柄
driver.switch_to.window(handles[0])
#点击新的元素
driver.find_element(By.XPATH,"/html/body/div[3]/header/div/div[1]/ul/li[2]/a").click()
time.sleep(200)警告框处理
alert = driver.switch_to_alert()
- text:返回 alert/confirm/prompt 中的文字信息。
- accept():接受现有警告框。
- dismiss():解散现有警告框。
- send_keys(keysToSend):发送文本至警告框。keysToSend:将文本发送至警告框。
下拉框选择
from selenium import webdriver
from selenium.webdriver.support.select import Select
from time import sleepdriver = webdriver.Chrome()
driver.implicitly_wait(10)
driver.get('http://www.baidu.com')
sel = driver.find_element_by_xpath("//select[@id='nr']")
Select(sel).select_by_value('50') # 显示50条文件上传
driver.find_element_by_name("file").send_keys('D:\\upload_file.txt') # # 定位上传按钮,添加本地文件cookie操作
WebDriver操作cookie的方法:
- get_cookies(): 获得所有cookie信息。
- get_cookie(name): 返回字典的key为“name”的cookie信息。
- add_cookie(cookie_dict) : 添加cookie。“cookie_dict”指字典对象,必须有name 和value 值。
- delete_cookie(name,optionsString):删除cookie信息。“name”是要删除的cookie的名称,“optionsString”是该cookie的选项,目前支持的选项包括“路径”,“域”。
- delete_all_cookies(): 删除所有cookie信息
调用JavaScript代码
js="window.scrollTo(100,450);"
driver.execute_script(js) # 通过javascript设置浏览器窗口的滚动条位置通过execute_script()方法执行JavaScripts代码来移动滚动条的位置。
窗口截图
driver.get_screenshot_as_file("D:\\baidu_img.jpg") # 截取当前窗口,并指定截图图片的保存位置关闭浏览器
- close() 关闭单个窗口
- quit() 关闭所有窗口
练习
爬取关于cxk的b站视频数据
from bs4 import BeautifulSoup
import requests
import openpyxl
from fake_useragent import UserAgent
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
# 创建excel表格
wb = openpyxl.Workbook()
ws = wb.active
ws.append(["名称","视频地址","观看次数","弹幕数量","发布时间"])
output_file = "./cxk-with-basketball-video.xlsx"
# 创建虚拟ua
ua = UserAgent()
headers = {"user-agent":ua.random}
# 打开b站官网
url = "https://www.bilibili.com/"
# 创建service
service = Service(executable_path=r"/Users/liujianlei/Downloads/mopi/chromedriver-mac-arm64/chromedriver")
driver = webdriver.Chrome(service= service)
# 打开b站
driver.get(url)
# 定位输入框并输入内容
content = "蔡徐坤 篮球"
driver.find_element(By.CLASS_NAME,"nav-search-input").send_keys(content)
# 获取按钮
driver.find_element(By.CLASS_NAME,"nav-search-btn").click()
# 进行页面的跳转
time.sleep(1)
handles = driver.window_handles
driver.switch_to.window(handles[-1])
# 显示等待直到元素加载完成
#wait = WebDriverWait(driver,10,0.5).until(EC.presence_of_element_located((By.XPATH,"//*[@id=\"bili-header-container\"]/div/div/ul[1]/li[8]/a/span")))
# 获取对应的URL并进行访问
# new_url = driver.current_url
# response = requests.get(new_url,headers=headers)
text = driver.page_source
soup = BeautifulSoup(text,"html.parser")
# 获取当前共有多少页
buttons = soup.find_all("button",{"class":"vui_button vui_button--no-transition vui_pagenation--btn vui_pagenation--btn-num"})
last_index = int(buttons[-1].text)
# 使用bs进行内容的读取
# for i in range(1,34):
# print("当前是第{}页".format(i))tags = soup.find_all(class_="bili-video-card__wrap __scale-wrap")for tag in tags:contents = tag.find_all("span", {"class": "bili-video-card__stats--item"})view_num = contents[0].textlang_num = contents[1].texttitle = tag.find("h3", {"class": "bili-video-card__info--tit"}).get("title")time = tag.find("span", {"class": "bili-video-card__info--date"}).texthref = tag.find("a", attrs={"data-idx": "all"}).get("href")# 将结果进行保存ws.append([title, href, view_num, lang_num, time])# 浏览器页面定位到下面# driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")# print("已经滑动到最底部了")driver.implicitly_wait(10)#WebDriverWait(driver,20,0.5).until(EC.element_to_be_clickable((By.CLASS_NAME,"vui_button vui_pagenation--btn vui_pagenation--btn-side")))# 定位下一页元素并进行点击
# 最后将excel表格进行保存
driver.find_element(By.CSS_SELECTOR,"#i_cecream > div > div:nth-child(2) > div.search-content--gray.search-content > div > div > div > div.flex_center.mt_x50.mb_x50 > div > div > button:nth-child(11)").click()wb.save(output_file)
# 关闭driver
driver.close()notes:
元素定位不到的可能原因:
如果在使用Selenium时无法定位到下一页按钮,可能有几种原因。以下是一些可能的解决方法:
等待页面加载完成:确保页面已经完全加载,有时下一页按钮可能需要一些时间才会出现在DOM中。您可以使用隐式等待或显式等待确保页面加载完成后再进行定位。
使用合适的定位方法:尝试使用不同的定位方法来寻找下一页按钮,比如通过ID、CSS选择器、XPath等。
查看页面源代码:查看页面源代码,确认下一页按钮的HTML结构和属性,以便更好地定位它。
检查是否在iframe中:如果下一页按钮位于iframe中,您需要先切换到该iframe,然后再进行定位。
使用JavaScript点击:如果其他方法无法定位到下一页按钮,可以尝试使用JavaScript来模拟点击操作。
以下是一个示例,演示了如何使用Selenium和JavaScript模拟点击下一页按钮:
# 导入需要的模块 from selenium import webdriver# 启动浏览器 driver = webdriver.Chrome()# 打开网页 driver.get("https://www.example.com")# 使用JavaScript点击下一页按钮 next_button = driver.find_element_by_xpath("//button[@id='next']") driver.execute_script("arguments[0].click();", next_button)如果这些方法仍然不能解决问题,那么可能需要对具体的网页和定位情况进行更深入的分析和调试。
相关文章:

selenium学习
前期准备 pip install selenium 获取浏览器驱动 我使用的浏览器是Chrome,所以这里只介绍关于Chrome获取浏览器驱动的方法: 需要注意的是:selenium 4.x 对之前版本的部分API调用方式进行了调整,这里就包括关于浏览器获取驱动的方式…...
前端开发新趋势:Web3、区块链和虚拟现实
目录 前言 Web3:下一代互联网 区块链技术 去中心化应用程序(DApps) 区块链:重塑数字世界 数字钱包 NFT(非同质化代币) 虚拟现实:沉浸式体验 WebVR和WebXR 三维图形 新挑战与机会 性…...
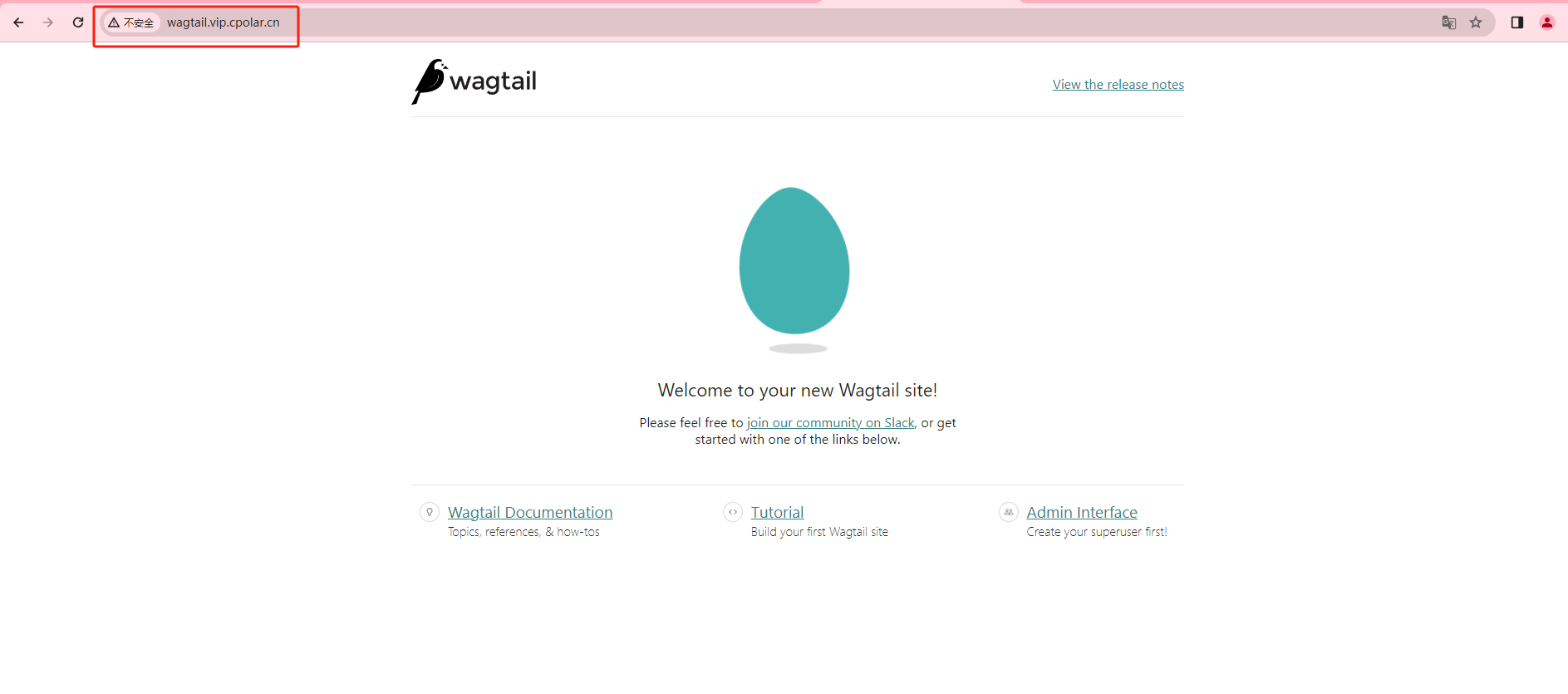
如何安装运行Wagtail并结合cpolar内网穿透实现公网访问网站界面
文章目录 前言1. 安装并运行Wagtail1.1 创建并激活虚拟环境 2. 安装cpolar内网穿透工具3. 实现Wagtail公网访问4. 固定的Wagtail公网地址 前言 Wagtail是一个用Python编写的开源CMS,建立在Django Web框架上。Wagtail 是一个基于 Django 的开源内容管理系统…...
: fatal error RC1022: expected ‘#endif‘】)
【>D:\10\Debug\RCa00828(34): fatal error RC1022: expected ‘#endif‘】
1>D:\10\Debug\RCa00828(34): fatal error RC1022: expected ‘#endif’ The error message you’re seeing, fatal error RC1022: expected ‘#endif’, indicates that the resource compiler encountered an issue when processing a resource script file (typically w…...

使用vite搭建项目时,在启动vite后,浏览器显示页面:找不到localhost的网页
现象 在使用前端工具vite(版本5),搭建vue3项目时,启动vite,浏览器显示页面:找不到localhost的网页, 起初怀疑是 未加参数 --host0.0.0.0,导致,后加上该参数后问题依旧 解决 将index.html页面…...
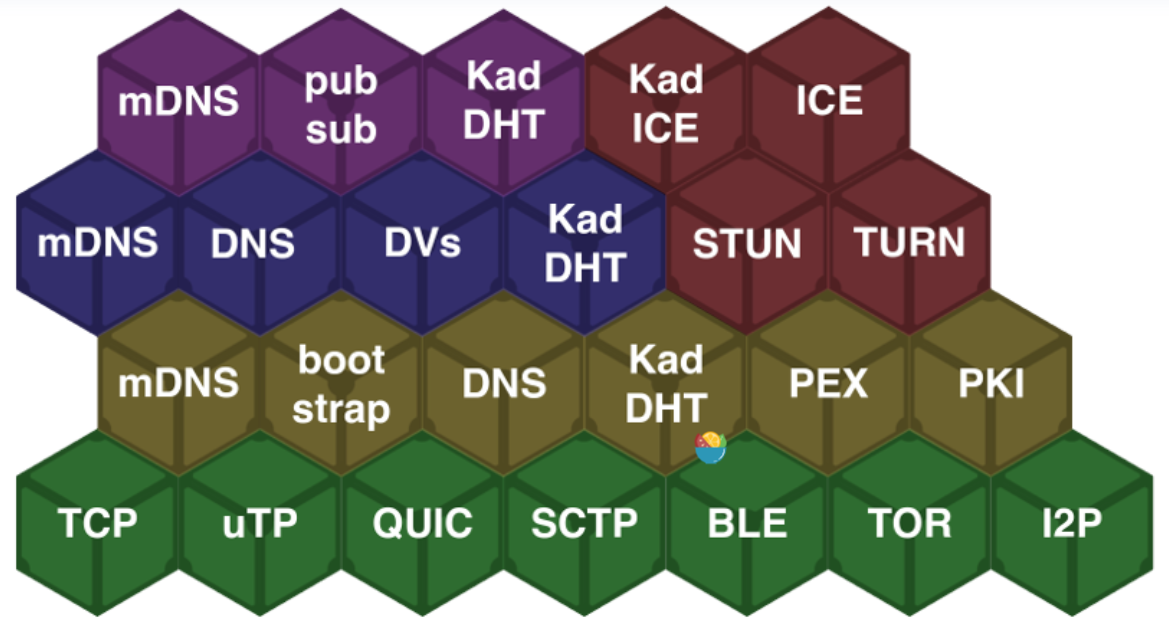
libp2p 快速开始
文章目录 第一部分:libp2p 快速入门一、什么是libp2plibp2p 发展历程libp2p的特性p2p 网络和我们熟悉的 client/server 网络的区别: 二、Libp2p的实现目标三、Libp2p的用途四、运行 Libp2p 协议流程libp2p 分为三层libp2p 还有一个局域网节点发现协议 mD…...

【数据结构】——排序算法简答题模板
目录 一、内排序和外排序二、排序算法的稳定性三、插入排序(一)直接插入排序的步骤(二)直接插入排序的稳定性(三)折半插入排序的步骤(四)希尔排序的步骤 四、交换排序(一…...

vue3.0基础
1. setup函数 vue单页面使用到的变量和方法都定义在setup函数中,return后才能被页面引用 export default {setup(){const name 张三const person {name,age:30}function goWork(){consle.log(工作)}return {name,person,goWork}} } 注意:直接定义的变量修改不会…...

Kafka本地安装⭐️(Windows)并测试生产消息以及消费消息的可用性
2023.12.17 天气晴 温度较低 十点半,不是不想起实在是阳光浴太nice了日常三连,喂,刷,肝刷会儿博客,看会儿设计模式冷冷冷 进被窝 刷视频 睡觉看看kafka的本地部署 》》实践》》成功写会儿博客,…...

生产环境_Spark解析JSON字符串并插入到MySQL数据库
业务背景: 最近开发有一个需求,是这样的 我需要将一段从前端传过来的JSON字符串进行解析,并从中提取出所需的数据,然后将这些数据插入到MySQL数据库中。 json格式样例如下 { \"区域编号\": \"001\", …...

WEB渗透—PHP反序列化(四)
Web渗透—PHP反序列化 课程学习分享(课程非本人制作,仅提供学习分享) 靶场下载地址:GitHub - mcc0624/php_ser_Class: php反序列化靶场课程,基于课程制作的靶场 课程地址:PHP反序列化漏洞学习_哔哩…...
LVS-DR模式部署
实验准备: 节点服务器 192.168.116.20 #web1 192.168.116.30 #web2 1.部署NFS共享存储 2.部署Web节点服务器 将两台服务器的网关注释掉 #重启网卡 systemctl restart network 修改节点服务器的内核参数|vim /etc/sysctl.conf net.ipv4.conf.lo.arp_ign…...
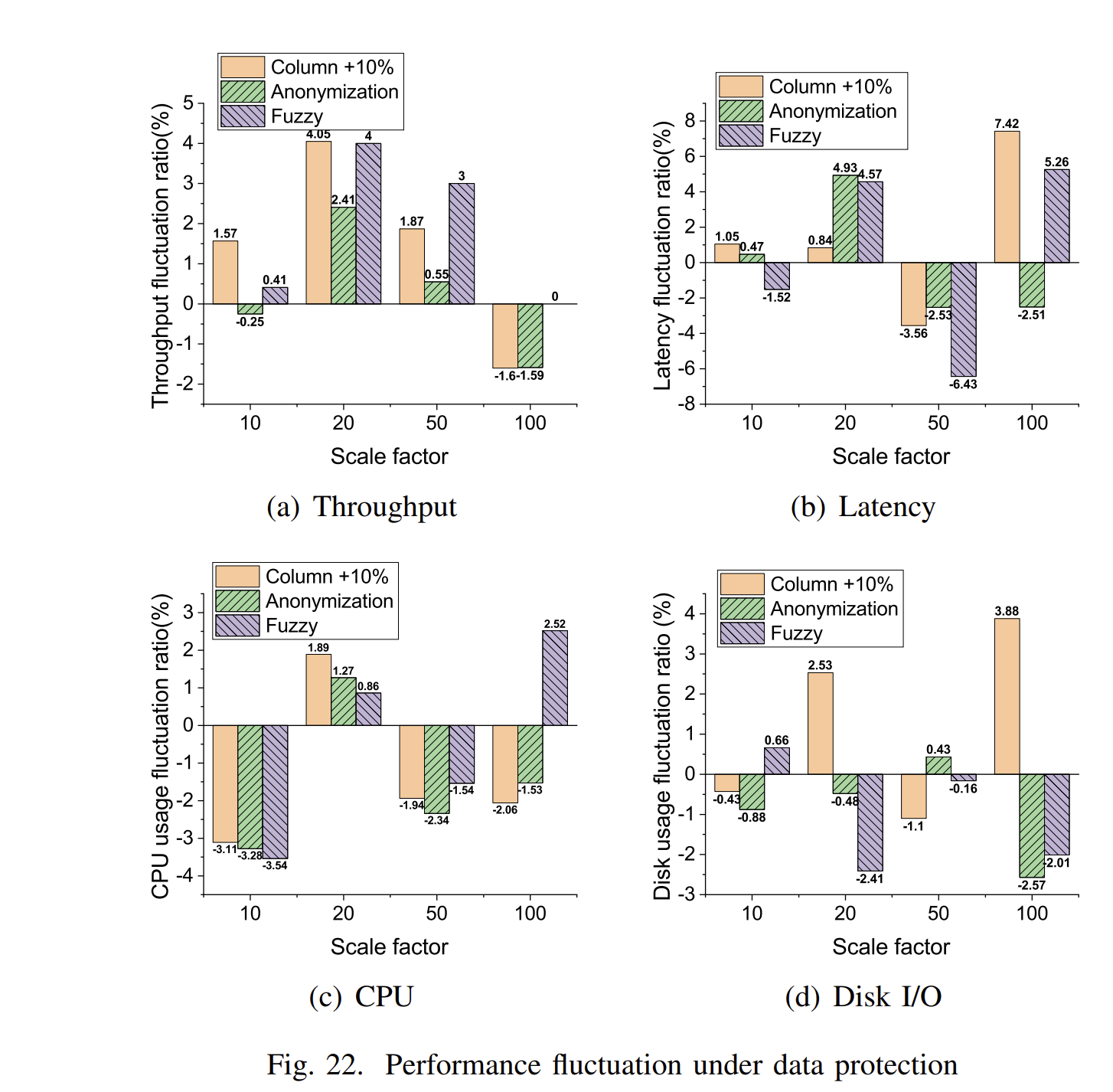
Oracle的学习心得和知识总结(三十)| OLTP 应用程序的合成工作负载生成器Lauca论文翻译及学习
目录结构 注:提前言明 本文借鉴了以下博主、书籍或网站的内容,其列表如下: 1、参考书籍:《Oracle Database SQL Language Reference》 2、参考书籍:《PostgreSQL中文手册》 3、EDB Postgres Advanced Server User Gui…...

HarmonyOS4.0从零开始的开发教程18后台代理提醒
HarmonyOS(十六)后台代理提醒 简介 随着生活节奏的加快,我们有时会忘记一些重要的事情或日子,所以提醒功能必不可少。应用可能需要在指定的时刻,向用户发送一些业务提醒通知。例如购物类应用,希望在指定时…...

智能优化算法应用:基于算术优化算法3D无线传感器网络(WSN)覆盖优化 - 附代码
智能优化算法应用:基于算术优化算法3D无线传感器网络(WSN)覆盖优化 - 附代码 文章目录 智能优化算法应用:基于算术优化算法3D无线传感器网络(WSN)覆盖优化 - 附代码1.无线传感网络节点模型2.覆盖数学模型及分析3.算术优化算法4.实验参数设定5.算法结果6.…...
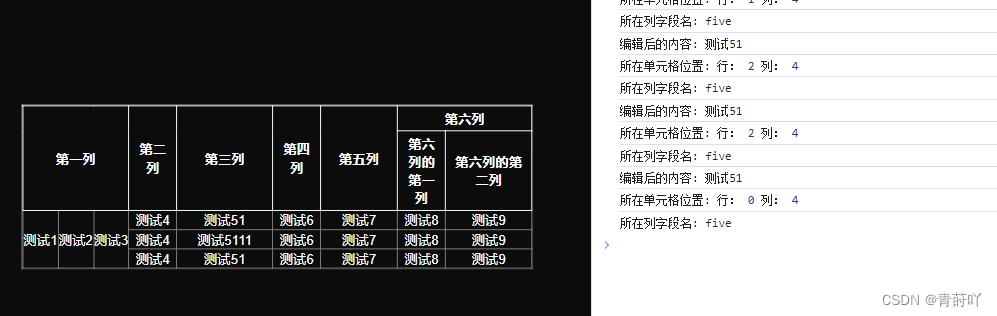
在vue中通过js动态绘制table,并且合并连续相同内容的行,支持点击编辑单元格内容
首先是vue代码 <template><div id"body-container"style"position: absolute"><div class"box-container"><div class"lsb-table-box" ><div class"table-container" id"lsb-table"&…...

输电线路定位:精确导航,确保电力传输安全
在现代社会中,电力作为生活的基石,其安全稳定运行至关重要。而输电线路作为电力传输的重要通道,其故障定位和修复显得尤为重要。恒峰智慧科技将为您介绍一种采用分布式行波测量技术的输电线路定位方法,以提高故障定位精度…...

ZKP Commitment (1)
MIT IAP 2023 Modern Zero Knowledge Cryptography课程笔记 Lecture 5: Commitment 1 (Ying Tong Lai) Overview: Modern SNARK IOP: Interactive Oracle ProofCommitment SchemeIOP “compiled by” the commitment scheme to get a non-interactive proofAn IOP is “inform…...

【难点】【LRU】146.LRU缓存
题目 法1:基于Java的LinkedHashMap 必须掌握法1。参考链接 关于LinkedHashMap的介绍 class LRUCache {int cap;LinkedHashMap<Integer, Integer> cache new LinkedHashMap<>();public LRUCache(int capacity) { this.cap capacity;}public int get…...
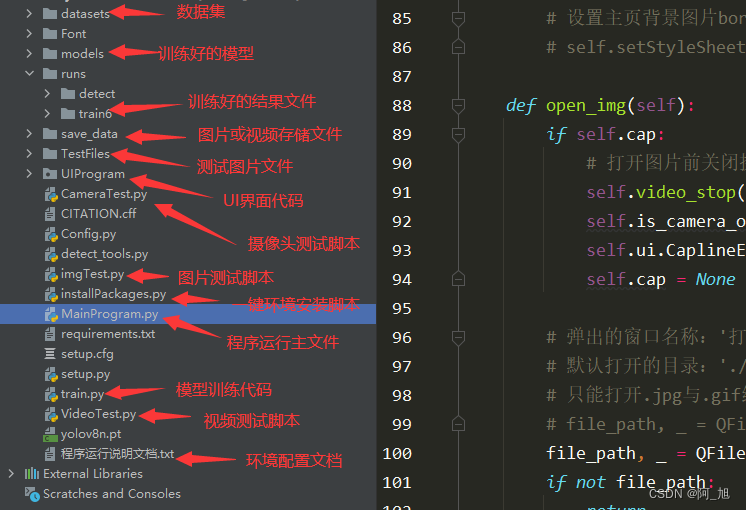
基于YOLOv8深度学习的吸烟/抽烟行为检测系统【python源码+Pyqt5界面+数据集+训练代码】目标检测、深度学习实战
《博主简介》 小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。 ✌更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~ 👍感谢小伙伴们点赞、关注! 《------往期经典推…...
)
濒危方言口述史抢救项目紧急启用NotebookLM的72小时部署方案(含田野录音→结构化叙事→GIS时空标注全流程)
更多请点击: https://intelliparadigm.com 第一章:NotebookLM考古学研究辅助 NotebookLM 是 Google 推出的基于 LLM 的研究型笔记工具,其核心能力在于对用户上传的私有文档(如 PDF、TXT)进行语义索引与上下文感知问答…...

绝地求生罗技鼠标宏终极教程:5分钟实现完美压枪
绝地求生罗技鼠标宏终极教程:5分钟实现完美压枪 【免费下载链接】logitech-pubg PUBG no recoil script for Logitech gaming mouse / 绝地求生 罗技 鼠标宏 项目地址: https://gitcode.com/gh_mirrors/lo/logitech-pubg 还在为《绝地求生》中难以控制的后坐…...

跨境直播进入“下半场”:2026年值得关注的几个新方向
很多人提到跨境直播,第一反应还是“流量”和“带货”。但如果这两年持续关注行业变化,会发现一个明显趋势:跨境直播正在从“内容竞争”转向“技术能力竞争”。尤其从2025年开始,行业越来越卷的不只是主播,而是整个直播…...

基于知识图谱与NLP技术的小说文本结构化分析实战
1. 项目概述:当小说遇见知识图谱 如果你和我一样,既是个技术爱好者,又是个小说迷,那你肯定有过这样的体验:读完一本情节复杂、人物关系盘根错节的小说后,合上书页,脑子里却一团乱麻。谁是谁的盟…...

Crustocean/conch:轻量级容器化工具,简化开发者本地环境搭建
1. 项目概述:一个面向开发者的轻量级容器化工具最近在和一些做后端开发的朋友聊天,发现大家普遍有个痛点:本地开发环境和线上环境不一致,导致“在我机器上好好的”这种经典问题频繁上演。虽然Docker已经普及,但完整的D…...

Page Assist终极指南:3步安装本地AI浏览器助手,开启智能网页浏览新时代
Page Assist终极指南:3步安装本地AI浏览器助手,开启智能网页浏览新时代 【免费下载链接】page-assist Use your locally running AI models to assist you in your web browsing 项目地址: https://gitcode.com/GitHub_Trending/pa/page-assist 想…...

亿图脑图高级技能:从思维建模到生产力提升的完整指南
1. 项目概述与核心价值最近在整理个人知识库和项目文档时,我一直在寻找一个能让我思维更清晰、协作更高效的“大脑外挂”。市面上思维导图工具不少,但要么功能臃肿、学习曲线陡峭,要么过于轻量、难以应对复杂的结构化思考。直到我深度体验并拆…...

别再只看耐压和电流了!手把手教你用SOA曲线给MOS管做‘体检’,避开炸管风险
从炸管到精准选型:动态SOA曲线在MOS管可靠性设计中的实战指南 1. 被忽视的"死亡区域":为什么静态参数无法保护你的MOS管 凌晨三点的实验室里,张工程师盯着第5块烧毁的电路板百思不得其解——明明选用了额定电流30A、耐压60V的MOS管…...

基于Gemini CLI的深度研究工具:命令行AI助手的架构与实战
1. 项目概述:当命令行遇上深度研究如果你和我一样,是个常年泡在终端里的开发者或研究者,那么“allenhutchison/gemini-cli-deep-research”这个项目标题,光是扫一眼,就能让人心跳加速。它精准地戳中了我们这类人的两个…...

轻量级包管理器LPM指南:从原理到实践,构建高效软件依赖管理方案
1. 项目概述:一个为开发者而生的轻量级包管理器指南如果你是一名开发者,尤其是经常在Linux或macOS环境下工作的开发者,那么“包管理器”这个词对你来说一定不陌生。从系统级的apt、yum、brew,到语言级的npm、pip、cargo࿰…...