Redis 越来越慢?常见延迟问题定位与分析
Redis作为内存数据库,拥有非常高的性能,单个实例的QPS能够达到10W左右。但我们在使用Redis时,经常时不时会出现访问延迟很大的情况,如果你不知道Redis的内部实现原理,在排查问题时就会一头雾水。
很多时候,Redis出现访问延迟变大,都与我们的使用不当或运维不合理导致的。
这篇文章我们就来分析一下Redis在使用过程中,经常会遇到的延迟问题以及如何定位和分析。
使用复杂度高的命令
如果在使用Redis时,发现访问延迟突然增大,如何进行排查?
首先,第一步,建议你去查看一下Redis的慢日志。Redis提供了慢日志命令的统计功能,我们通过以下设置,就可以查看有哪些命令在执行时延迟比较大。
首先设置Redis的慢日志阈值,只有超过阈值的命令才会被记录,这里的单位是微秒,例如设置慢日志的阈值为5毫秒,同时设置只保留最近1000条慢日志记录:
# 命令执行超过5毫秒记录慢日志
CONFIG SET slowlog-log-slower-than 5000
# 只保留最近1000条慢日志
CONFIG SET slowlog-max-len 1000设置完成之后,所有执行的命令如果延迟大于5毫秒,都会被Redis记录下来,我们执行SLOWLOG get 5查询最近5条慢日志
127.0.0.1:6379> SLOWLOG get5
1)1)(integer)32693# 慢日志ID
2)(integer)1593763337# 执行时间
3)(integer)5299# 执行耗时(微秒)
4)1)"LRANGE"# 具体执行的命令和参数
2)"user_list_2000"
3)"0"
4)"-1"
2)1)(integer)32692
2)(integer)1593763337
3)(integer)5044
4)1)"GET"
2)"book_price_1000"
...通过查看慢日志记录,我们就可以知道在什么时间执行哪些命令比较耗时,如果你的业务经常使用O(n)以上复杂度的命令,例如sort、sunion、zunionstore,或者在执行O(n)命令时操作的数据量比较大,这些情况下Redis处理数据时就会很耗时。
如果你的服务请求量并不大,但Redis实例的CPU使用率很高,很有可能是使用了复杂度高的命令导致的。
解决方案就是,不使用这些复杂度较高的命令,并且一次不要获取太多的数据,每次尽量操作少量的数据,让Redis可以及时处理返回。
存储大key
如果查询慢日志发现,并不是复杂度较高的命令导致的,例如都是SET、DELETE操作出现在慢日志记录中,那么你就要怀疑是否存在Redis写入了大key的情况。
Redis在写入数据时,需要为新的数据分配内存,当从Redis中删除数据时,它会释放对应的内存空间。
如果一个key写入的数据非常大,Redis在分配内存时也会比较耗时。同样的,当删除这个key的数据时,释放内存也会耗时比较久。
你需要检查你的业务代码,是否存在写入大key的情况,需要评估写入数据量的大小,业务层应该避免一个key存入过大的数据量。
那么有没有什么办法可以扫描现在Redis中是否存在大key的数据吗?
Redis也提供了扫描大key的方法:
redis-cli -h $host -p $port --bigkeys -i 0.01使用上面的命令就可以扫描出整个实例key大小的分布情况,它是以类型维度来展示的。
需要注意的是当我们在线上实例进行大key扫描时,Redis的QPS会突增,为了降低扫描过程中对Redis的影响,我们需要控制扫描的频率,使用-i参数控制即可,它表示扫描过程中每次扫描的时间间隔,单位是秒。
使用这个命令的原理,其实就是Redis在内部执行scan命令,遍历所有key,然后针对不同类型的key执行strlen、llen、hlen、scard、zcard来获取字符串的长度以及容器类型(list/dict/set/zset)的元素个数。
而对于容器类型的key,只能扫描出元素最多的key,但元素最多的key不一定占用内存最多,这一点需要我们注意下。不过使用这个命令一般我们是可以对整个实例中key的分布情况有比较清晰的了解。
针对大key的问题,Redis官方在4.0版本推出了lazy-free的机制,用于异步释放大key的内存,降低对Redis性能的影响。即使这样,我们也不建议使用大key,大key在集群的迁移过程中,也会影响到迁移的性能,这个后面在介绍集群相关的文章时,会再详细介绍到
集中过期
有时你会发现,平时在使用Redis时没有延时比较大的情况,但在某个时间点突然出现一波延时,而且报慢的时间点很有规律,例如某个整点,或者间隔多久就会发生一次。
如果出现这种情况,就需要考虑是否存在大量key集中过期的情况。
如果有大量的key在某个固定时间点集中过期,在这个时间点访问Redis时,就有可能导致延迟增加。
Redis的过期策略采用主动过期+懒惰过期两种策略:
•主动过期:Redis内部维护一个定时任务,默认每隔100毫秒会从过期字典中随机取出20个key,删除过期的key,如果过期key的比例超过了25%,则继续获取20个key,删除过期的key,循环往复,直到过期key的比例下降到25%或者这次任务的执行耗时超过了25毫秒,才会退出循环
•懒惰过期:只有当访问某个key时,才判断这个key是否已过期,如果已经过期,则从实例中删除
注意,Redis的主动过期的定时任务,也是在Redis**主线程**中执行的,也就是说如果在执行主动过期的过程中,出现了需要大量删除过期key的情况,那么在业务访问时,必须等这个过期任务执行结束,才可以处理业务请求。此时就会出现,业务访问延时增大的问题,最大延迟为25毫秒。
而且这个访问延迟的情况,不会记录在慢日志里。慢日志中只记录真正执行某个命令的耗时,Redis主动过期策略执行在操作命令之前,如果操作命令耗时达不到慢日志阈值,它是不会计算在慢日志统计中的,但我们的业务却感到了延迟增大。
此时你需要检查你的业务,是否真的存在集中过期的代码,一般集中过期使用的命令是expireat或pexpireat命令,在代码中搜索这个关键字就可以了。
如果你的业务确实需要集中过期掉某些key,又不想导致Redis发生抖动,有什么优化方案?
解决方案是,在集中过期时增加一个`随机时间`,把这些需要过期的key的时间打散即可。
伪代码可以这么写:
# 在过期时间点之后的5分钟内随机过期掉
redis.expireat(key, expire_time + random(300))这样Redis在处理过期时,不会因为集中删除key导致压力过大,阻塞主线程。
另外,除了业务使用需要注意此问题之外,还可以通过运维手段来及时发现这种情况。
做法是我们需要把Redis的各项运行数据监控起来,执行info可以拿到所有的运行数据,在这里我们需要重点关注expired_keys这一项,它代表整个实例到目前为止,累计删除过期key的数量。
我们需要对这个指标监控,当在很短时间内这个指标出现突增时,需要及时报警出来,然后与业务报慢的时间点对比分析,确认时间是否一致,如果一致,则可以认为确实是因为这个原因导致的延迟增大。
实例内存达到上限
有时我们把Redis当做纯缓存使用,就会给实例设置一个内存上限maxmemory,然后开启LRU淘汰策略。
当实例的内存达到了maxmemory后,你会发现之后的每次写入新的数据,有可能变慢了。
导致变慢的原因是,当Redis内存达到maxmemory后,每次写入新的数据之前,必须先踢出一部分数据,让内存维持在maxmemory之下。
这个踢出旧数据的逻辑也是需要消耗时间的,而具体耗时的长短,要取决于配置的淘汰策略:
•allkeys-lru:不管key是否设置了过期,淘汰最近最少访问的key
•volatile-lru:只淘汰最近最少访问并设置过期的key
•allkeys-random:不管key是否设置了过期,随机淘汰
•volatile-random:只随机淘汰有设置过期的key
•allkeys-ttl:不管key是否设置了过期,淘汰即将过期的key
•noeviction:不淘汰任何key,满容后再写入直接报错
•allkeys-lfu:不管key是否设置了过期,淘汰访问频率最低的key(4.0+支持)
•volatile-lfu:只淘汰访问频率最低的过期key(4.0+支持)
备注:allkeys-xxx表示从所有的键值中淘汰数据,而volatile-xxx表示从设置了过期键的键值中淘汰数据。
具体使用哪种策略,需要根据业务场景来决定。
我们最常使用的一般是allkeys-lru或volatile-lru策略,它们的处理逻辑是,每次从实例中随机取出一批key(可配置),然后淘汰一个最少访问的key,之后把剩下的key暂存到一个池子中,继续随机取出一批key,并与之前池子中的key比较,再淘汰一个最少访问的key。以此循环,直到内存降到maxmemory之下。
如果使用的是allkeys-random或volatile-random策略,那么就会快很多,因为是随机淘汰,那么就少了比较key访问频率时间的消耗了,随机拿出一批key后直接淘汰即可,因此这个策略要比上面的LRU策略执行快一些。
但以上这些逻辑都是在访问Redis时,真正命令执行之前执行的,也就是它会影响我们访问Redis时执行的命令。
另外,如果此时Redis实例中有存储大key,那么在淘汰大key释放内存时,这个耗时会更加久,延迟更大,这需要我们格外注意。
如果你的业务访问量非常大,并且必须设置maxmemory限制实例的内存上限,同时面临淘汰key导致延迟增大的的情况,要想缓解这种情况,除了上面说的避免存储大key、使用随机淘汰策略之外,也可以考虑拆分实例的方法来缓解,拆分实例可以把一个实例淘汰key的压力分摊到多个实例上,可以在一定程度降低延迟。
fork耗时严重
如果你的Redis开启了自动生成RDB和AOF重写功能,那么有可能在后台生成RDB和AOF重写时导致Redis的访问延迟增大,而等这些任务执行完毕后,延迟情况消失。
遇到这种情况,一般就是执行生成RDB和AOF重写任务导致的。
生成RDB和AOF都需要父进程fork出一个子进程进行数据的持久化,在fork执行过程中,父进程需要拷贝**内存页表**给子进程,如果整个实例内存占用很大,那么需要拷贝的内存页表会比较耗时,此过程会消耗大量的CPU资源,在完成fork之前,整个实例会被阻塞住,无法处理任何请求,如果此时CPU资源紧张,那么fork的时间会更长,甚至达到秒级。这会严重影响Redis的性能。
我们可以执行info命令,查看最后一次fork执行的耗时latest_fork_usec,单位微秒。这个时间就是整个实例阻塞无法处理请求的时间。
除了因为备份的原因生成RDB之外,在主从节点第一次建立数据同步时,主节点也会生成RDB文件给从节点进行一次全量同步,这时也会对Redis产生性能影响。
要想避免这种情况,我们需要规划好数据备份的周期,建议在从节点上执行备份,而且最好放在**低峰期**执行。如果对于丢失数据不敏感的业务,那么不建议开启AOF和AOF重写功能。
另外,fork的耗时也与系统有关,如果把Redis部署在虚拟机上,那么这个时间也会增大。所以使用Redis时建议部署在物理机上,降低fork的影响。
绑定CPU
很多时候,我们在部署服务时,为了提高性能,降低程序在使用多个CPU时上下文切换的性能损耗,一般会采用进程绑定CPU的操作。
但在使用Redis时,我们不建议这么干,原因如下:
绑定CPU的Redis,在进行数据持久化时,fork出的子进程,子进程会继承父进程的CPU使用偏好,而此时子进程会消耗大量的CPU资源进行数据持久化,子进程会与主进程发生CPU争抢,这也会导致主进程的CPU资源不足访问延迟增大。
所以在部署Redis进程时,如果需要开启RDB和AOF重写机制,一定不能进行CPU绑定操作!
开启AOF
上面提到了,当执行AOF文件重写时会因为fork执行耗时导致Redis延迟增大,除了这个之外,如果开启AOF机制,设置的策略不合理,也会导致性能问题。
开启AOF后,Redis会把写入的命令实时写入到文件中,但写入文件的过程是先写入内存,等内存中的数据超过一定阈值或达到一定时间后,内存中的内容才会被真正写入到磁盘中。
AOF为了保证文件写入磁盘的安全性,提供了3种刷盘机制:
•appendfsync always:每次写入都刷盘,对性能影响最大,占用磁盘IO比较高,数据安全性最高
•appendfsync everysec:1秒刷一次盘,对性能影响相对较小,节点宕机时最多丢失1秒的数据
•appendfsync no:按照操作系统的机制刷盘,对性能影响最小,数据安全性低,节点宕机丢失数据取决于操作系统刷盘机制
当使用第一种机制appendfsync always时,Redis每处理一次写命令,都会把这个命令写入磁盘,而且这个操作是在主线程中执行的。
内存中的的数据写入磁盘,这个会加重磁盘的IO负担,操作磁盘成本要比操作内存的代价大得多。如果写入量很大,那么每次更新都会写入磁盘,此时机器的磁盘IO就会非常高,拖慢Redis的性能,因此我们不建议使用这种机制。
与第一种机制对比,appendfsync everysec会每隔1秒刷盘,而appendfsync no取决于操作系统的刷盘时间,安全性不高。因此我们推荐使用appendfsync everysec这种方式,在最坏的情况下,只会丢失1秒的数据,但它能保持较好的访问性能。
当然,对于有些业务场景,对丢失数据并不敏感,也可以不开启AOF。
使用Swap
如果你发现Redis突然变得非常慢,每次访问的耗时都达到了几百毫秒甚至秒级,那此时就检查Redis是否使用到了Swap,这种情况下Redis基本上已经无法提供高性能的服务。
我们知道,操作系统提供了Swap机制,目的是为了当内存不足时,可以把一部分内存中的数据换到磁盘上,以达到对内存使用的缓冲。
但当内存中的数据被换到磁盘上后,访问这些数据就需要从磁盘中读取,这个速度要比内存慢太多!
尤其是针对Redis这种高性能的内存数据库来说,如果Redis中的内存被换到磁盘上,对于Redis这种性能极其敏感的数据库,这个操作时间是无法接受的。
我们需要检查机器的内存使用情况,确认是否确实是因为内存不足导致使用到了Swap。
如果确实使用到了Swap,要及时整理内存空间,释放出足够的内存供Redis使用,然后释放Redis的Swap,让Redis重新使用内存。
释放Redis的Swap过程通常要重启实例,为了避免重启实例对业务的影响,一般先进行主从切换,然后释放旧主节点的Swap,重新启动服务,待数据同步完成后,再切换回主节点即可。
可见,当Redis使用到Swap后,此时的Redis的高性能基本被废掉,所以我们需要提前预防这种情况。
我们需要对Redis机器的内存和Swap使用情况进行监控,在内存不足和使用到Swap时及时报警出来,及时进行相应的处理
网卡负载过高
如果以上产生性能问题的场景,你都规避掉了,而且Redis也稳定运行了很长时间,但在某个时间点之后开始,访问Redis开始变慢了,而且一直持续到现在,这种情况是什么原因导致的?
之前我们就遇到这种问题,特点就是从某个时间点之后就开始变慢,并且一直持续。这时你需要检查一下机器的网卡流量,是否存在网卡流量被跑满的情况。
网卡负载过高,在网络层和TCP层就会出现数据发送延迟、数据丢包等情况。Redis高性能除了内存之外,就在于网络IO,请求量突增会导致网卡负载变高。
如果出现这种情况,你需要排查这个机器上的哪个Redis实例的流量过大占满了网络带宽,然后确认流量突增是否属于业务正常情况,如果属于那就需要及时扩容或迁移实例,避免这个机器的其他实例受到影响。
运维层面,我们需要对机器的各项指标增加监控,包括网络流量,在达到阈值时提前报警,及时与业务确认并扩容。
总结
以上我们总结了Redis中常见的可能导致延迟增大甚至阻塞的场景,这其中既涉及到了业务的使用问题,也涉及到Redis的运维问题。
可见,要想保证Redis高性能的运行,其中涉及到CPU、内存、网络,甚至磁盘的方方面面,其中还包括操作系统的相关特性的使用。
作为开发人员,我们需要了解Redis的运行机制,例如各个命令的执行时间复杂度、数据过期策略、数据淘汰策略等,使用合理的命令,并结合业务场景进行优化。
作为DBA运维人员,需要了解数据持久化、操作系统fork原理、Swap机制等,并对Redis的容量进行合理规划,预留足够的机器资源,对机器做好完善的监控,才能保证Redis的稳定运行。
相关文章:

Redis 越来越慢?常见延迟问题定位与分析
Redis作为内存数据库,拥有非常高的性能,单个实例的QPS能够达到10W左右。但我们在使用Redis时,经常时不时会出现访问延迟很大的情况,如果你不知道Redis的内部实现原理,在排查问题时就会一头雾水。很多时候,R…...
【python】python-socketio+firecamp使用踩坑指南
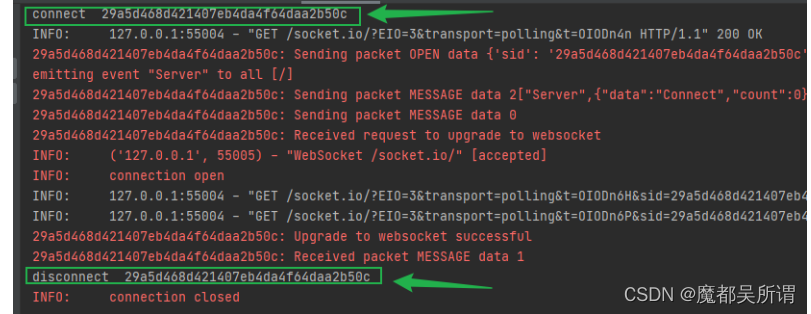
server.py: import eventlet import asyncioeventlet.monkey_patch()import socketio import eventlet.wsgisio socketio.Server(async_modeeventlet, cors_allowed_origins*) # 指明在evenlet模式下sio.event def connect(sid, environ):print(f"connect, sid{sid}, e…...
【OJ比赛日历】快周末了,不来一场比赛吗? #03.04-03.10 #12场
CompHub 实时聚合多平台的数据类(Kaggle、天池…)和OJ类(Leetcode、牛客…)比赛。本账号同时会推送最新的比赛消息,欢迎关注!更多比赛信息见 CompHub主页 或 点击文末阅读原文以下信息仅供参考,以比赛官网为准目录2023-03-04&…...

C++11:继承
目录 继承的基本概念 继承方式 基类和派生类对象赋值转换/切片 继承中的作用域 派生类的四个成员函数: 构造函数 拷贝构造函数 赋值重载 析构函数 静态成员 继承与友元 多继承 菱形继承 多继承的指针偏移问题 组合 继承的基本概念 继承出现的契机是某一…...
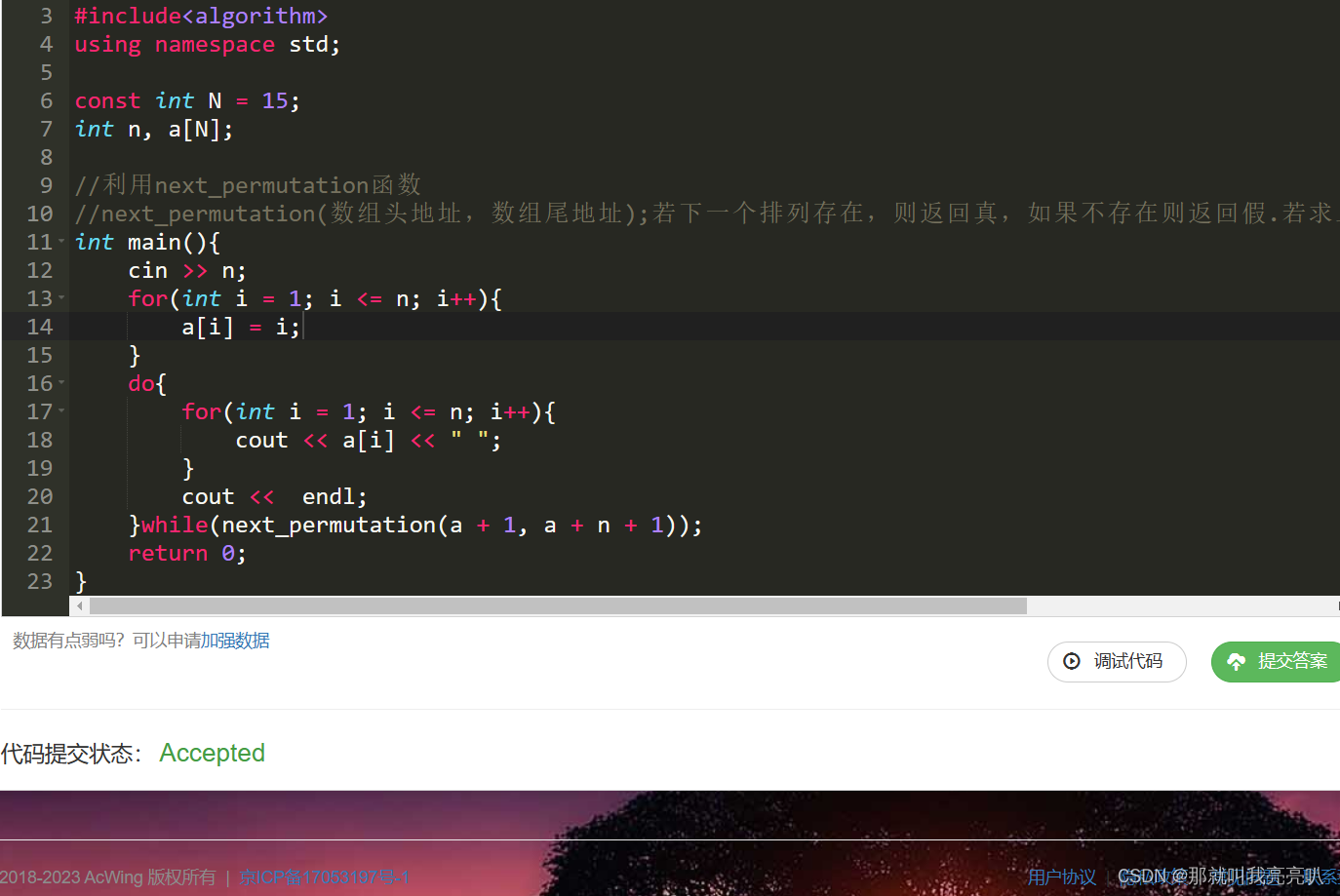
【蓝桥杯试题】递归实现排列型枚举
💃🏼 本人简介:男 👶🏼 年龄:18 🤞 作者:那就叫我亮亮叭 📕 专栏:蓝桥杯试题 文章目录1. 题目描述2. 代码展示法一:dfs法二:next_perm…...
入职字节测试岗外包一个月,我离职了...
有一种打工人的羡慕,叫做“大厂”。真是年少不知大厂香,错把青春插稻秧。但是,在深圳有一群比大厂员工更庞大的群体,他们顶着大厂的“名”,做着大厂的工作,还可以享受大厂的伙食,却没有大厂的“…...

weak学习入门-01
作用:集中在特征提取、算法选择和参数调优上 本篇几乎是汇总了大佬的参考 官网https://www.cs.waikato.ac.nz/ml/weka 大佬的入门教程:初试weka数据挖掘 - 加拿大小哥哥 - 博客园 (cnblogs.com) 参考书:数据挖掘实用机器学习技术(原书第2版)...

线程池中shutdown()和shutdownNow()方法的区别
线程池中shutdown()和shutdownNow()方法的区别 一般情况下,当我们频繁的使用线程的时候,为了节约资源快速响应需求,我们都会考虑使用线程池,线程池使用完毕都会想着关闭,关闭的时候一般情况下会用到shutdown和shutdow…...
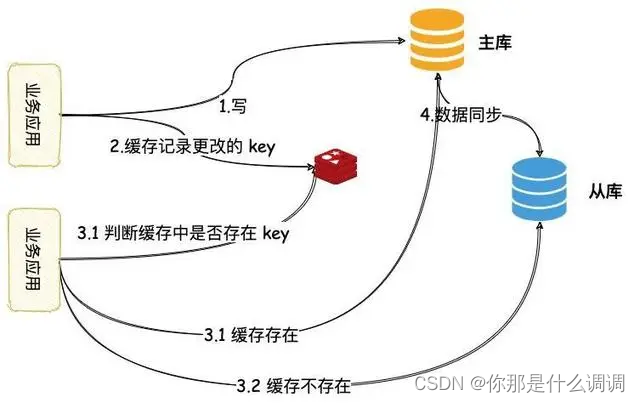
高可用/性能
文章目录1.数据库系统架构发展(1)单库架构(2)主备架构(3)主从架构2.主从复制主从同步配置主从复制模式(1)异步复制(2)半同步复制(3)全…...

PriorityQueues优先队列
优先队列优先队列(priority queue)是计算机科学中的一类抽象数据类型。优先队列中的每个元素都有各自的优先级,优先级最高的元素最先得到服务;优先级相同的元素按照其在优先队列中的顺序得到服务。优先队列通常使用“堆”…...

arm 堆栈
先转一篇 stm32 堆和栈(stm32 Heap & Stack)【worldsing笔记】_stm32堆栈_slj_win的博客-CSDN博客 关于堆和栈已经是程序员的一个月经话题,大部分有是基于os层来聊的。 那么,在赤裸裸的单片机下的堆和栈是什么样的分布呢?以下是网摘&…...

leetcode-面试题 05.02. Binary Number to String LCCI
Description Given a real number between 0 and 1 (e.g., 0.72) that is passed in as a double, print the binary representation. If the number cannot be represented accurately in binary with at most 32 characters, print “ERROR”. Example1: Input: 0.625Outpu…...

C语言函数阐述
C 函数 函数是一组一起执行一个任务的语句。每个 C 程序都至少有一个函数,即主函数 main() ,所有简单的程序都可以定义其他额外的函数。 您可以把代码划分到不同的函数中。如何划分代码到不同的函数中是由您来决定的,但在逻辑上,…...
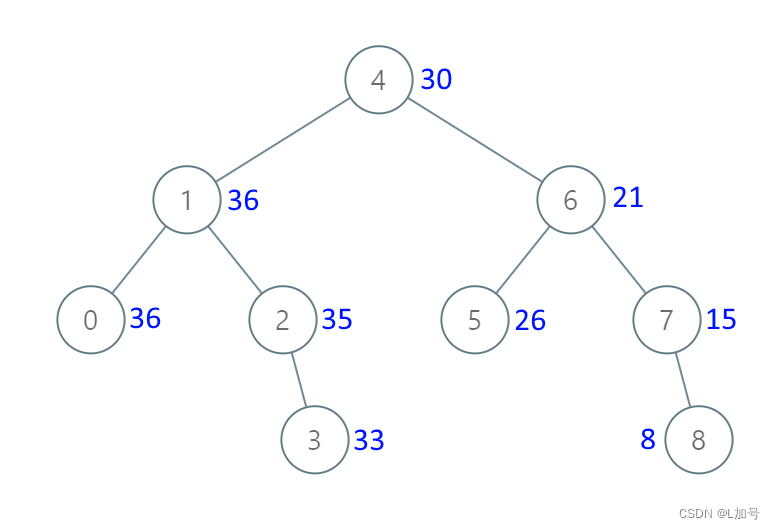
二叉树——把二叉搜索树转换为累加树
538. 把二叉搜索树转换为累加树 链接 给出二叉 搜索 树的根节点,该树的节点值各不相同,请你将其转换为累加树(Greater Sum Tree),使每个节点 node 的新值等于原树中大于或等于 node.val 的值之和。 提醒一下…...
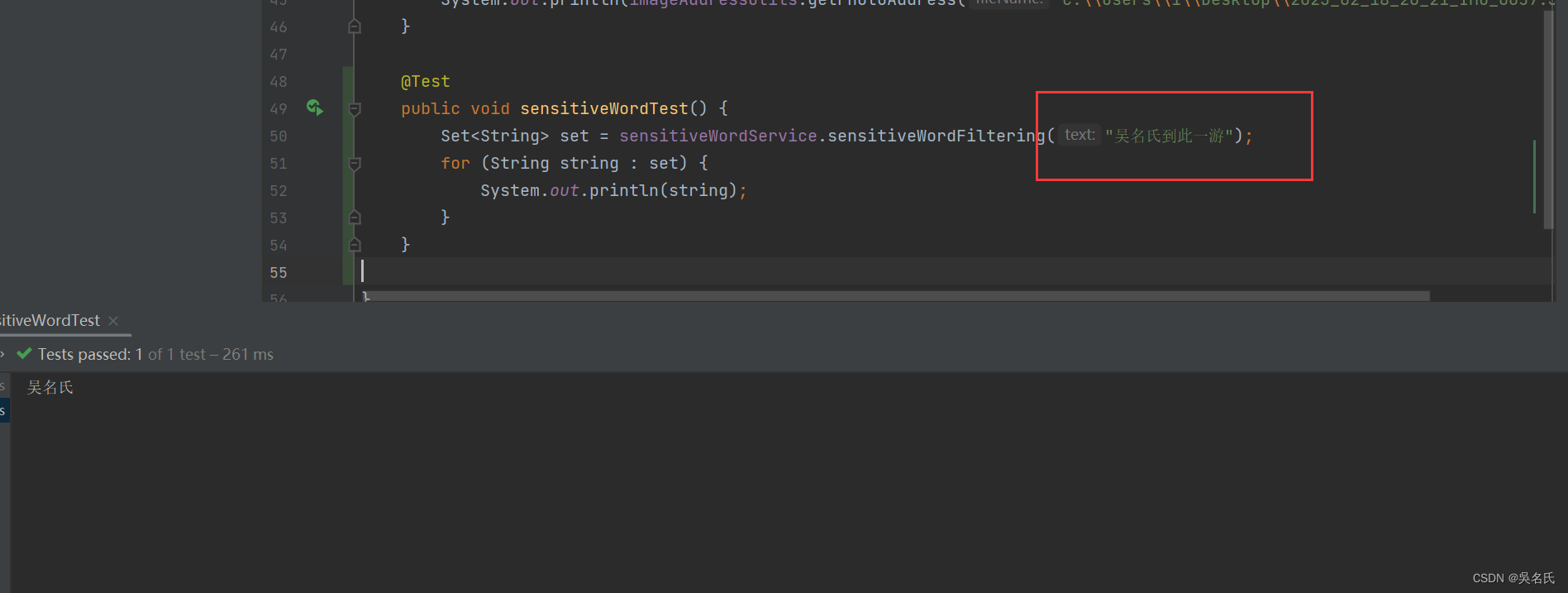
Java使用DFA算法实现敏感词过滤
1 前言敏感词过滤就是你在项目中输入某些字(比如输入xxoo相关的文字时)时要能检测出来,很多项目中都会有一个敏感词管理模块,在敏感词管理模块中你可以加入敏感词,然后根据加入的敏感词去过滤输入内容中的敏感词并进行…...
-外挂 - 配置文件说明(.men文件/.rtb文件/.trb文件))
UG NX二次开发(C#)-外挂 - 配置文件说明(.men文件/.rtb文件/.trb文件)
文章目录 1、前言2、UG NX菜单说明2.1UG NX的Ribbon样式说明2.2 UG NX的Ribbon配置文件3、外挂的加载配置文件说明3.1 创建配置文件夹3.2 填写.men文件3.2 填写.rtb文件3.2 填写.tbr文件4、将外挂加载到UG NX菜单中5、重启UG NX,就可以实现外挂加载了。1、前言 UG NX二次开发…...

Web3中文|日本元宇宙经济“狂飙”
2月27日,三菱、富士通和其它科技公司发布关于建立“日本元宇宙经济区”的协议,表示将联手从角色扮演游戏的角度创建开放的元宇宙基础设施,以推动日本的Web3战略。据了解,日本一直在努力将Web3技术纳入其国家议程,去年1…...
@Autowired和@Resource到底有什么区别
Autowired 和 Resource 都是 Spring/Spring Boot 项目中,用来进行依赖注入的注解。它们都提供了将依赖对象注入到当前对象的功能,但二者却有众多不同,并且这也是常见的面试题之一,所以我们今天就来盘它。 Autowired 和 Resource 的…...

2023年最新阿里云服务器价格表出炉(精准收费标准及配置价格表)
阿里云在全球率先宣布了基于 Intel Ice Lake 处理器的第七代云服务器ECS,性能提升的同时降低了报价,性价比更高了。进入2023年阿里云服务器价格依然是大家关心的问题,事实上阿里云服务器租用价格和最新收费标准都可以通过官方云服务器计算器来…...

ElasticSearch - SpringBoot整合ES实现文档的增删改操作
文章目录1. ElasticSearch和kibana的安装和配置2. SpringBoot 项目环境搭建3. 创建索引4. 索引文档5. 更新文档6. 删除文档https://www.elastic.co/guide/en/elasticsearch/reference/current/search-your-data.htmlhttps://www.elastic.co/guide/cn/elasticsearch/guide/curre…...

Cursor配置管理工具:开发者如何优雅管理AI编程助手的使用体验
Cursor配置管理工具:开发者如何优雅管理AI编程助手的使用体验 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached y…...

怎样轻松突破微信网页版限制:wechat-need-web开源插件实用指南
怎样轻松突破微信网页版限制:wechat-need-web开源插件实用指南 【免费下载链接】wechat-need-web 让微信网页版可用 / Allow the use of WeChat via webpage access 项目地址: https://gitcode.com/gh_mirrors/we/wechat-need-web 微信作为日常沟通的重要工具…...

Fiddler HTTPS抓包证书失败全解析:跨平台实战排障指南
1. 为什么HTTPS抓包总在“证书这关”卡死?——一个老手的切肤之痛Fiddler HTTPS抓包,听起来就该是“装个软件→勾选Decrypt HTTPS→开干”三步走的事。但现实是:90%的人卡在第一步——证书安装失败;剩下9%的人卡在第二步——浏览器…...

刚刚,马斯克第三代星舰首飞成功!
克雷西 发自 凹非寺量子位 | 公众号 QbitAI刚刚,马斯克的第十二次星舰试验,也是第三代星舰的首次飞行,顺利完成!当地时间昨天下午5点30分(北京时间今早6点30分),33台猛禽3发动机同时点火&#x…...

机器学习辅助第一性原理:高精度计算电化学氧化还原电位
1. 项目概述:当机器学习遇上第一性原理,破解电化学模拟的精度瓶颈在电化学、材料科学和计算化学的交叉领域,预测一个分子或离子在溶液中的氧化还原电位,就像试图在暴风雨中测量一滴雨滴的精确落点。这个数值,直接决定了…...

C166架构下XDATA解决全局变量内存溢出问题
1. 问题现象与背景分析在C166架构的嵌入式开发中,当程序包含大量初始化全局变量时,开发者经常会遇到两个经典错误:*** ERROR 172 IN LINE 9 OF test.c: HDATA0: length exceeded: act172032, max65536 Error 106: Section Overflow Section: …...

量子机器学习与量子炼金术:加速化学空间探索的DFT数据驱动方法
1. 项目概述:当量子化学遇见机器学习在计算化学和材料科学的日常工作中,我们这些“算分子”的人,最核心也最头疼的任务之一,就是预测一个分子或材料的能量。这听起来简单,却是理解其稳定性、反应活性乃至所有物理化学性…...

GE 和 Runtime:不是上下游,是协同决策
你以为 GE 做完融合决策,交给 Runtime 执行就行了?其实它们是一个协同系统——GE 决定"融什么",Runtime 决定"怎么跑",但 GE 的融合决策必须考虑 Runtime 的调度约束,Runtime 的调度策略也必须参考…...

LVF时序变异分析:原理、应用与EDA工具支持
1. 什么是LVF(Liberty Variance Format)?在芯片设计领域,时序分析是确保电路性能符合预期的重要环节。Liberty Variance Format(LVF)是一种用于描述时序变异的新方法,它解决了传统Stage Based O…...

MLQM:用机器学习加速量子比特映射,破解量子编译“最后一公里”难题
1. 项目概述与核心挑战量子计算这行,这几年硬件跑得飞快,但软件栈这块,尤其是怎么把咱们写的量子程序高效、保真地“烧录”到真实的量子芯片上,一直是个头疼的“最后一公里”问题。这其中的关键一步,就是量子比特映射。…...