【Apache-StreamPark】Flink 开发利器 StreamPark 的介绍、安装、使用
【Apache-StreamPark】Flink 开发利器 StreamPark 的介绍、安装、使用
- 1)框架介绍与引入
- 1.1.🚀 什么是 StreamPark
- 1.2.🎉 Features
- 1.3.🏳🌈 组成部分
- 1.4.引入 StreamPark
- 2)安装部署
- 2.1.环境要求
- 2.2.Hadoop
- 2.3.Kubernetes
- 2.4.安装
- 2.5.启动
- 2.6.系统登录
- 2.7.系统配置
- 2.7.1.System Setting
- 2.7.2.Alert Setting
- 2.7.3.Flink Home
- 2.7.4.Flink Cluster
- 3)StreamPark 使用
1)框架介绍与引入

1.1.🚀 什么是 StreamPark

1.2.🎉 Features

1.3.🏳🌈 组成部分
StreamPark 核心由 streampark-core 和 streampark-console 组成


1.4.引入 StreamPark
之前我们写 Flink SQL 基本上都是使用 Java 包装 SQL,打 jar 包,提交到服务器上。通过命令行方式提交代码,但这种方式始终不友好,流程繁琐,开发和运维成本太大。我们希望能够进一步简化流程,将 Flink TableEnvironment 抽象出来,有平台负责初始化、打包运行 Flink 任务,实现 Flink 应用程序的构建、测试和部署自动化。StreamPark 对 Flink 的支持比较完善且强大。
2)安装部署
StreamPark 总体组件栈架构如下, 由 streampark-core 和 streampark-console 两个大的部分组成 , streampark-console 是一个非常重要的模块, 定位是一个综合实时数据平台,流式数仓平台, 低代码 ( Low Code ),Flink & Spark 任务托管平台,可以较好的管理 Flink 任务,集成了项目编译、发布、参数配置、启动、savepoint,火焰图 ( flame graph ),Flink SQL,监控等诸多功能于一体,大大简化了 Flink 任务的日常操作和维护,融合了诸多最佳实践。其最终目标是打造成一个实时数仓,流批一体的一站式大数据解决方案

2.1.环境要求
streampark-console 提供了开箱即用的安装包,安装之前对环境有些要求,具体要求如下:
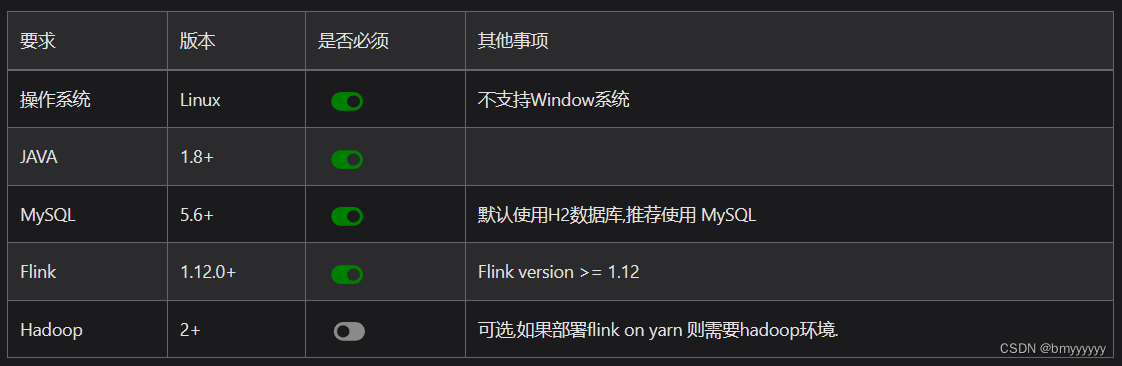
目前 StreamPark 对 Flink 的任务发布,同时支持 Flink on YARN 和 Flink on Kubernetes 两种模式。
2.2.Hadoop
使用 Flink on YARN,需要部署的集群安装并配置 Hadoop 的相关环境变量,如你是基于CDH 安装的 hadoop 环境, 相关环境变量可以参考如下配置:
export HADOOP_HOME=/opt/cloudera/parcels/CDH/lib/hadoop #hadoop 安装目录
export HADOOP_CONF_DIR=/etc/hadoop/conf
export HIVE_HOME=$HADOOP_HOME/../hive
export HBASE_HOME=$HADOOP_HOME/../hbase
export HADOOP_HDFS_HOME=$HADOOP_HOME/../hadoop-hdfs
export HADOOP_MAPRED_HOME=$HADOOP_HOME/../hadoop-mapreduce
export HADOOP_YARN_HOME=$HADOOP_HOME/../hadoop-yarn
2.3.Kubernetes
使用 Flink on Kubernetes,需要额外部署/或使用已经存在的 Kubernetes 集群,请参考条目: StreamPark Flink-K8s 集成支持。
2.4.安装
1、下载 streampark 安装包,解包后安装目录如下
.
streampark-console-service-1.2.1
├── bin
│ ├── startup.sh //启动脚本
│ ├── setclasspath.sh //java 环境变量相关的脚本 ( 内部使用,用户无需关注 )
│ ├── shutdown.sh //停止脚本
│ ├── yaml.sh //内部使用解析 yaml 参数的脚本 ( 内部使用,用户无需关注 )
├── conf
│ ├── application.yaml //项目的配置文件 ( 注意不要改动名称 )
│ ├── flink-application.template //flink 配置模板 ( 内部使用,用户无需关注 )
│ ├── logback-spring.xml //logback
│ └── ...
├── lib
│ └── *.jar //项目的 jar 包
├── client
│ └── streampark-flink-sqlclient-1.0.0.jar //Flink SQl 提交相关功能 ( 内部使用,用户无需关注 )
├── script
│ ├── schema
│ │ ├── mysql-schema.sql // mysql的ddl建表sql
│ │ └── pgsql-schema.sql // pgsql的ddl建表sql
│ ├── data
│ │ ├── mysql-data.sql // mysql的完整初始化数据
│ │ └── pgsql-data.sql // pgsql的完整初始化数据
│ ├── upgrade
│ │ ├── 1.2.3.sql //升级到 1.2.3版本需要执行的升级sql
│ │ └── 2.0.0.sql //升级到 2.0.0版本需要执行的升级sql
│ │ ...
├── logs //程序 log 目录
├── temp //内部使用到的临时路径,不要删除
2、初始化表结构
目前支持 mysql、pgsql、h2(默认,不需要执行任何操作),sql 脚本目录如下:
├── script
│ ├── schema
│ │ ├── mysql-schema.sql // mysql的ddl建表sql
│ │ └── pgsql-schema.sql // pgsql的ddl建表sql
│ ├── data
│ │ ├── mysql-data.sql // mysql的完整初始化数据
│ │ └── pgsql-data.sql // pgsql的完整初始化数据
│ ├── upgrade
│ │ ├── 1.2.3.sql //升级到 1.2.3版本需要执行的升级sql
│ │ └── 2.0.0.sql //升级到 2.0.0版本需要执行的升级sql
如果是初次安装,需要连接对应的数据库客户端依次执行 schema 和 data 目录下对应数据库的脚本文件即可,如果是升级,则执行对应的版本号的sql即可。
3、修改配置
安装解包已完成,接下来准备数据相关的工作
- 修改连接信息
进入到 conf 下,修改 conf/application.yml,找到 spring 这一项,找到 profiles.active 的配置,修改成对应的信息即可,如下:
spring:profiles.active: mysql #[h2,pgsql,mysql]application.name: StreamParkdevtools.restart.enabled: falsemvc.pathmatch.matching-strategy: ant_path_matcherservlet:multipart:enabled: truemax-file-size: 500MBmax-request-size: 500MBaop.proxy-target-class: truemessages.encoding: utf-8jackson:date-format: yyyy-MM-dd HH:mm:sstime-zone: GMT+8main:allow-circular-references: truebanner-mode: off
在修改完 conf/application.yml 后, 还需要修改 config/application-mysql.yml 中的数据库连接信息:
Tips: 由于Apache 2.0许可与Mysql Jdbc驱动许可的不兼容,用户需要自行下载驱动jar包并放在 $STREAMPARK_HOME/lib 中,推荐使用8.x版本,下载地址 apache maven repository
spring:datasource:username: rootpassword: xxxxdriver-class-name: com.mysql.cj.jdbc.Driver # 请根据mysql-connector-java版本确定具体的路径,例如:使用5.x则此处的驱动名称应该是:com.mysql.jdbc.Driverurl: jdbc:mysql://localhost:3306/streampark?useSSL=false&useUnicode=true&characterEncoding=UTF-8&allowPublicKeyRetrieval=false&useJDBCCompliantTimezoneShift=true&useLegacyDatetimeCode=false&serverTimezone=GMT%2B8
- 修改workspace
进入到 conf 下,修改 conf/application.yml,找到 streampark 这一项,找到 workspace 的配置,修改成一个用户有权限的目录
streampark:# HADOOP_USER_NAME 如果是on yarn模式( yarn-prejob | yarn-application | yarn-session)则需要配置 hadoop-user-namehadoop-user-name: hdfs# 本地的工作空间,用于存放项目源码,构建的目录等.workspace:local: /opt/streampark_workspace # 本地的一个工作空间目录(很重要),用户可自行更改目录,建议单独放到其他地方,用于存放项目源码,构建的目录等.remote: hdfs:///streampark # support hdfs:///streampark/ 、 /streampark 、hdfs://host:ip/streampark/
2.5.启动
进入到 bin 下直接执行 startup.sh 即可启动项目,默认端口是10000,如果没啥意外则会启动成功,打开浏览器 输入http://$host:10000 即可登录
cd streampark-console-service-1.0.0/bin
bash startup.sh
相关的日志会输出到 streampark-console-service-1.0.0/logs/streampark.out 里
2.6.系统登录
经过以上步骤,即可部署完成,可以直接登录系统

提示:
默认密码: admin / streampark
2.7.系统配置
进入系统之后,第一件要做的事情就是修改系统配置,在菜单**/StreamPark/Setting** 下,操作界面如下:
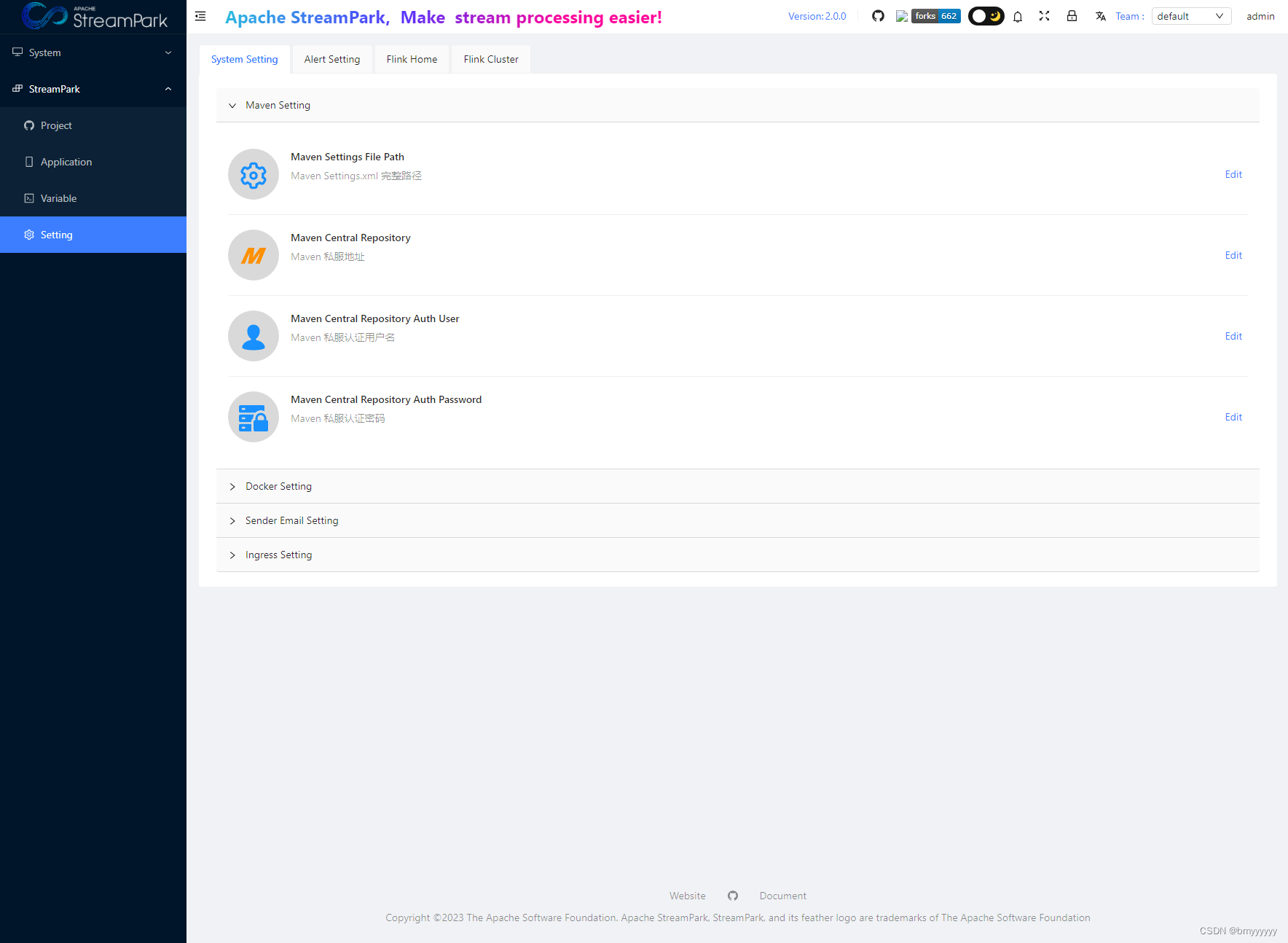
主要配置项分为以下几类:
System Setting
Alert Setting
Flink Home
Flink Cluster
2.7.1.System Setting
当前系统配置包括:
-
Maven配置
-
Docker环境配置
-
警告邮箱配置
-
k8s Ingress 配置
2.7.2.Alert Setting
Alert Email 相关的配置是配置发送者邮件的信息,具体配置请查阅相关邮箱资料和文档进行配置
2.7.3.Flink Home
这里配置全局的 Flink Home,此处是系统唯一指定 Flink 环境的地方,会作用于所有的作业
提示:
特别提示: 最低支持的 Flink 版本为 1.12.0, 之后的版本都支持
2.7.4.Flink Cluster
Flink 当前支持的集群模式包括:
-
Standalone 集群
-
Yarn 集群
-
Kubernetes 集群
3)StreamPark 使用
详细使用请参考 StreamPark 中文官网
相关文章:
【Apache-StreamPark】Flink 开发利器 StreamPark 的介绍、安装、使用
【Apache-StreamPark】Flink 开发利器 StreamPark 的介绍、安装、使用 1)框架介绍与引入1.1.🚀 什么是 StreamPark1.2.🎉 Features1.3.🏳🌈 组成部分1.4.引入 StreamPark 2)安装部署2.1.环境要求2.2.Hado…...

【STM32】STM32学习笔记-LED闪烁 LED流水灯 蜂鸣器(06-2)
00. 目录 文章目录 00. 目录01. GPIO之LED电路图02. GPIO之LED接线图03. LED闪烁程序示例04. LED闪烁程序下载05. LED流水灯接线图06. LED流水灯程序示例07. 蜂鸣器接线图08. 蜂鸣器程序示例09. 下载10. 附录 01. GPIO之LED电路图 电路图示例1 电路图示例2 02. GPIO之LED接线图…...

docker服务启动报错docker.service holdoff time over, scheduling restart.
docker服务启动报错docker.service holdoff time over, scheduling restart. 卸载docker 卸载安装包 yum remove -y docker docker-client docker-client-latest docker-ce-cli docker-common docker-latest docker-latest-logrotate docker-logrotate docker-selinu…...
)
cfa一级考生复习经验分享系列(八)
先分析一下CFA Level 1内容,考试总体难度并不大,每门课程都比大学本科开设的对应课程简单,但是因为有十门课综合在一起,知识点相对算比较多,内容较多。但对知识点的掌握要求不高,理解即可。比如财报&#x…...

React中的事件处理
React中的事件处理 亲爱的同学们,今天我们将一起探索React中的一个非常实用的话题:事件处理。当我们谈论事件处理,我们指的是在用户与我们的应用程序交互时发生的各种情况,比如点击一个按钮或是提交一个表单。这些动作是我们如何让…...

德人合科技 | 公司电脑文件加密系统
公司电脑文件加密系统是一种可以对电脑文件进行加密的保护机制。它使用驱动层透明加密技术,能够在用户无感知的情况下对文件进行加密,从源头上保障数据安全和使用安全。 PC端访问地址: www.drhchina.com 此类系统主要有以下几个特点和功能&a…...
FinalShell的下载、安装及基本使用
一:引言 FinalShell 是一体化的的服务器,网络管理软件,不仅是 ssh 客户端,还是功能强大的开发,运维工具,充分满足开发,运维需求. 主要特性: 1.多平台支持 Windows,macOS,Linux 2.多标签,批量服务器管理. 3.支持登录 ssh 和 Windows 远程桌面. 4.漂亮的…...

华为实训课笔记 2023
华为实训 12/1312/1412/1812/19 12/13 ping 基于ICMP协议,用来进行可达性测试 ping 目的IP地址/设备域名(主机名) 如果能收到 reply 回复,则表示双方可以正常通信。一次正常的数据通信必须是有去有回。 <Huawei>用户视图&a…...

图灵日记之Leetcode链表中间结点牛客链表中倒数第k个结点Leetcode合并两个有序链表leetcode反转链表
题目 链表的中间结点原题入口题目内容题目解析思路一代码实现一思路二代码实现二 链表中倒数第k个结点题目链接题目内容思路代码实现 合并两个有序链表原题入口题目内容思路代码实现 反转链表题目传送入口题目内容思路一代码复现一思路二代码实现二 链表的中间结点 原题入口 …...
条款5:了解c++默默编写并调用了哪些函数
如果你不自己声明,编译器会替你声明(编译器版本的)拷贝构造函数、拷贝赋值运算符和析构函数。此外,如果你没有声明任何构造函数,编译器会为你声明一个默认构造函数。 class Empty{};本质上和写成下面这样是一样的: c…...
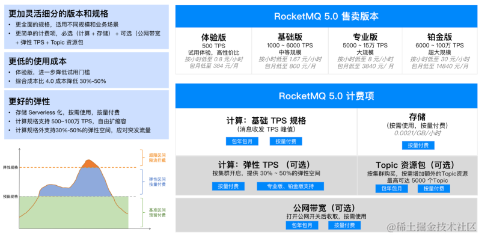
Apache RocketMQ 5.0 腾讯云落地实践
Apache RocketMQ 发展历程回顾 RocketMQ 最早诞生于淘宝的在线电商交易场景,经过了历年双十一大促流量洪峰的打磨,2016年捐献给 Apache 社区,成为 Apache 社区的顶级项目,并在国内外电商,金融,互联网等各行…...

FIFO的Verilog设计(三)——最小深度计算
文章目录 前言一、FIFO的最小深度写速度快于读速度写速度等于或慢于读速度 二、 举例说明1. FIFO写时钟为100MHz,读时钟为80Mhz情况一:一共需要传输2000个数据,求FIFO的最小深度情况二:100个时钟写入80个数据,1个时钟读…...

JavaWeb笔记之JavaWeb JDBC
//Author 流云 //Version 1.0 一. 引言 1.1 如何操作数据库 使用客户端工具访问数据库,需要手工建立连接,输入用户名和密码登录,编写 SQL 语句,点击执行,查看操作结果(结果集或受影响行数)。…...
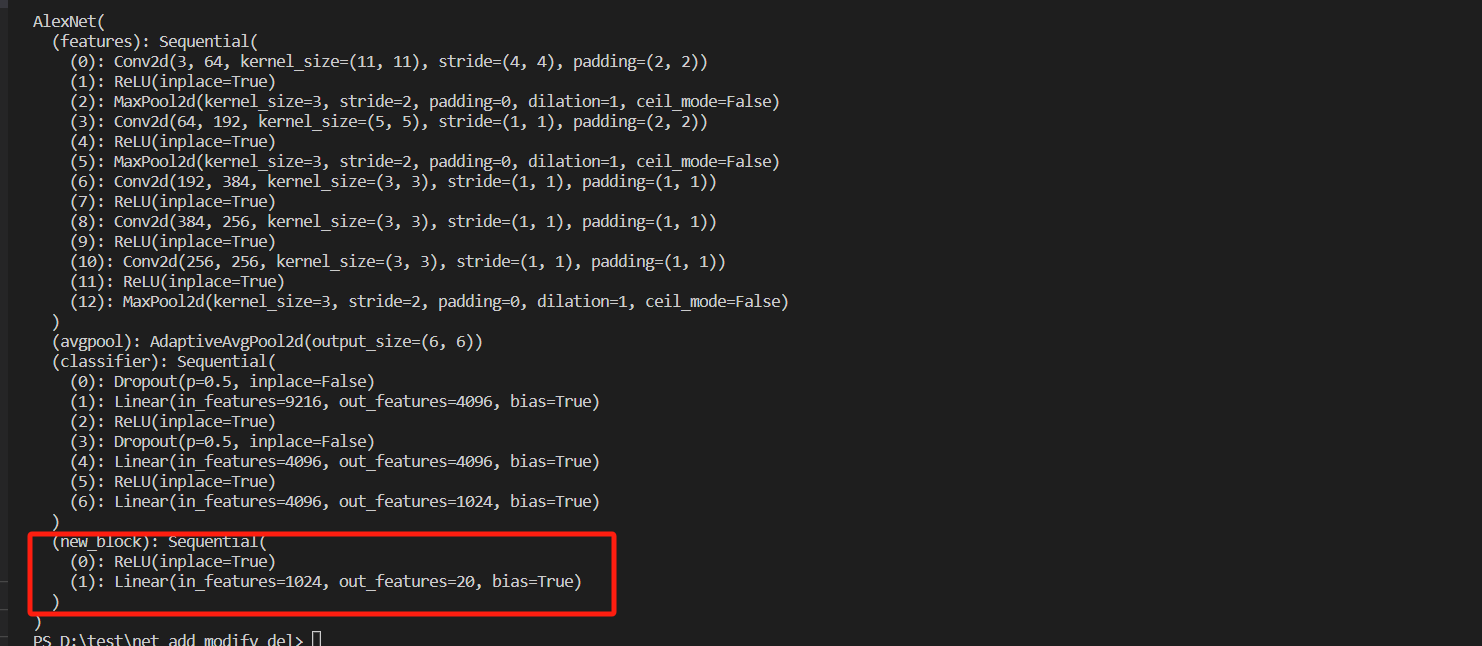
pytorch网络的增删改
本文介绍对加载的网络的层进行增删改, 以alexnet网络为例进行介绍。 1. 加载网络 import torchvision.models as models alexnet models.alexnet(weightsmodels.AlexNet_Weights.DEFAULT) print(alexnet)2. 删除网络 在做迁移学习的时候,我们通常是在分类网络的…...
详解全集)
Tomcat (Linux系统)详解全集
点击标题进入对应模块学习,你也可以完全拿捏Tomcat! 1 Tomcat及JDK下载安装(Linux系统) 2 Tomcat目录介绍 3 Tomcat的启动关闭及日志说明 4 完美解决Tomcat启动慢的三种方法 5 Tomcat管理功能使用 6 Tomcat主配置文件(…...

[德人合科技]——设计公司 \ 设计院图纸文件数据 | 资料透明加密防泄密软件
国内众多设计院都在推进信息化建设,特别是在异地办公、应用软件资产规模、三维设计技术推广应用以及协同办公等领域,这些加快了业务的发展,也带来了更多信息安全挑战,尤其是对于以知识成果为重要效益来源的设计院所,防…...

数字化转型中的6S管理
在当今竞争激烈的制造业中,数字化转型已经成为企业保持竞争力和实现可持续发展的关键。科技的飞速发展,数字化已经成为推动制造业变革的引擎。在这个信息时代,数字化转型不仅仅是追求效率和成本节约的问题,更是企业在市场中生存和…...
Linux学习(1)——初识Linux
目录 一、Linux的哲学思想 1.1 基础知识 1.2 根目录下的文件夹 二、Shell 1、Shell的定义 2、Shell的作用 三、Linux命令行 1、Linux通用命令行使用格式 四、Linux命令的分类 1、内部命令和外部命令的理解 2、内部命令和外部命令的区别 3、命令的执行过程 五、编辑…...

2.5 - 网络协议 - HTTP协议工作原理,报文格式,抓包实战
「作者主页」:士别三日wyx 「作者简介」:CSDN top100、阿里云博客专家、华为云享专家、网络安全领域优质创作者 「推荐专栏」:对网络安全感兴趣的小伙伴可以关注专栏《网络安全入门到精通》 HTTP协议 1、HTTP协议工作原理2、HTTP协议报文3、HTTP请求方法4、HTTP响应状态码5、…...

新增工具箱管理功能、重构网站证书管理功能,1Panel开源面板v1.9.0发布
2023年12月18日,现代化、开源的Linux服务器运维管理面板1Panel正式发布v1.9.0版本。 在这一版本中,1Panel引入了新的工具箱管理功能,包含Swap分区管理、Fail2Ban管理等功能。此外,1Panel针对网站证书管理功能进行了全面重构&…...

量化交易工具箱全景:从数据回测到实盘部署的完整指南
1. 系统性交易资源全景图:从入门到精通的工具箱如果你对用代码和数学模型在金融市场里“掘金”感兴趣,那你来对地方了。系统性交易,或者说量化交易,早已不是华尔街大机构的专利。随着开源工具的爆发式增长,任何一个有编…...

强化学习如何优化城市洪水管理?哥本哈根项目揭示数据驱动规划新范式
1. 项目概述:当强化学习遇见城市洪水管理如果你是一位城市规划师或水务工程师,面对日益频发的极端降雨和城市内涝,传统的静态规划模型是否让你感到力不从心?气候变化带来的不确定性,让“一次性”的工程解决方案风险陡增…...

2002-2024年 人工智能发展能壮大耐心资本吗
本文基于2002-2024年上市公司数据,借鉴《人工智能发展能壮大耐心资本吗? ——来自国家新一代人工智能创新发展试验区的经验证据》一文中的变量构建与基准回归部分,探讨人工智能发展能否培育壮大耐心资本,含原始数据、处理代码、实…...
)
数据结构(哈希函数)
#pragma once //之前已经学完的,顺序表,链表等 他们总是有一个共有的特征,数据和其存储之间是没有任何关系的 //现在的需求 让查找函数的时间复杂度达到O(1); //让数据和其存储位置之间产生某种函数(映射)关系 这就是哈…...

CGRA架构与工具链:可重构计算加速技术解析
1. CGRA架构与工具链概述粗粒度可重构阵列(Coarse-Grained Reconfigurable Array, CGRA)是一种介于FPGA和ASIC之间的可重构计算架构,特别适合加速多维嵌套循环计算。与FPGA的细粒度可编程逻辑单元不同,CGRA采用粗粒度的处理单元&a…...

基于Azure SQL与Semantic Kernel的RAG应用实战:低成本实现向量搜索与智能问答
1. 项目概述:当SQL数据库遇上向量搜索如果你正在用.NET技术栈构建智能应用,并且数据已经躺在Azure SQL Database里,那么“如何低成本、高效率地实现语义搜索和RAG(检索增强生成)”很可能就是你当前最头疼的问题。传统的…...

开源无模式数据表格框架:构建自主可控SaaS应用的核心组件
1. 项目概述:一个为SaaS而生的开源数据表格框架如果你正在寻找一个能嵌入到自己SaaS产品里的数据表格组件,或者想搭建一个类似CRM、内部仪表盘的工具,并且对Airtable、Clay这类产品的闭源、云依赖和定价模式感到头疼,那么你找对地…...

AI智能体如何革新LaTeX写作:PaperDebugger深度集成Overleaf实践
1. 项目概述:当AI助手遇上LaTeX写作如果你是一名科研工作者、研究生,或者任何需要和LaTeX文档打交道的人,那么下面这个场景你一定不陌生:深夜,你对着Overleaf编辑器里密密麻麻的代码和公式,反复修改着论文的…...
)
Serverless平台为何总让人“又爱又恨”?揭秘Lovable设计的3层情感化架构(开发者体验×运维韧性×业务敏捷)
更多请点击: https://intelliparadigm.com 第一章:Serverless平台为何总让人“又爱又恨”? Serverless 架构在现代云原生开发中已成为主流选择,它承诺“无需管理服务器”,让开发者专注业务逻辑。然而,在真…...

开源提示词库:提升AI协作效率的实战指南与核心设计解析
1. 项目概述:一个开源提示词库的价值与定位如果你也经常使用大型语言模型,无论是用于编程辅助、内容创作还是日常问答,那么你一定遇到过这样的困境:面对一个空白的输入框,明明心里有明确的需求,却不知道如何…...