LLM微调(四)| 微调Llama 2实现Text-to-SQL,并使用LlamaIndex在数据库上进行推理
Llama 2是开源LLM发展的一个巨大里程碑。最大模型及其经过微调的变体位居Hugging Face Open LLM排行榜(https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)前列。多个基准测试表明,就性能而言,它正在接近GPT-3.5(在某些情况下甚至超过它)。所有这些都意味着,对于从RAG系统到Agent的复杂LLM应用程序,开源LLM是一种越来越可行和可靠的选择。

一、Llama-2–7B不擅长从文本到SQL
最小的Llama 2模型(7B参数)有一个缺点是它不太擅长生成SQL,因此它不适用于结构化分析示例。例如,我们尝试在给定以下提示模板的情况下提示Llama 2生成正确的SQL语句:
You are a powerful text-to-SQL model. Your job is to answer questions about a database. You are given a question and context regarding one or more tables.You must output the SQL query that answers the question.### Input:{input}### Context:{context}### Response:
在这里,我们使用sqlcreatecontext数据集(https://huggingface.co/datasets/b-mc2/sql-create-context)的一个示例来测试一下效果:
input: In 1981 which team picked overall 148?context: CREATE TABLE table_name_8 (team VARCHAR, year VARCHAR, overall_pick VARCHAR)
同时,这里是生成的输出与正确输出的对比:
Generated output: SELECT * FROM `table_name_8` WHERE '1980' = YEAR AND TEAM = "Boston Celtics" ORDER BY OVERALL_PICK DESC LIMIT 1;Correct output: SELECT team FROM table_name_8 WHERE year = 1981 AND overall_pick = "148"
这显然并不理想。与ChatGPT和GPT-4不同,原始的Llama 2不能生成期望的的格式和正确的SQL。
这正是微调的作用所在——如果有一个合适的文本到SQL数据的语料库,我们可以教Llama 2更好地从自然语言生成SQL输出。微调有不同的方法,可以更新模型的所有参数(比如:全量微调),也可以冻结大模型参数仅微调附加参数(比如:LoRA)。
二、微调Llama-2–7B,使其可以从文本生成SQL
接下来,我们将展示如何在文本到SQL数据集上微调Llama 2,然后使用LlamaIndex的功能对任何SQL数据库进行结构化分析。
准备工作:
微调数据集:来自Hugging Face的b-mc2/sql-create-context(https://huggingface.co/datasets/b-mc2/sql-create-context)
base模型:OpenLLaMa 的open_lama_7b_v2(https://github.com/openlm-research/open_llama)
步骤1:加载微调LLaMa的训练数据
PS:1)以下代码来自doppel-bot:https://github.com/modal-labs/doppel-bot;2)许多Python代码都包含在src目录中;3)需要设置一个Modal帐户,并生成token。
!pip install -r requirements.txt首先,我们使用Modal加载b-mc2/sql-create-context数据集,并将其格式化为.jsonl文件。
modal run src.load_data_sql --data-dir "data_sql"结果如下所示:
# Modal stubs allow our function to run remotely@stub.function(retries=Retries(max_retries=3,initial_delay=5.0,backoff_coefficient=2.0,),timeout=60 * 60 * 2,network_file_systems={VOL_MOUNT_PATH.as_posix(): output_vol},cloud="gcp",)def load_data_sql(data_dir: str = "data_sql"):from datasets import load_datasetdataset = load_dataset("b-mc2/sql-create-context")dataset_splits = {"train": dataset["train"]}out_path = get_data_path(data_dir)out_path.parent.mkdir(parents=True, exist_ok=True)for key, ds in dataset_splits.items():with open(out_path, "w") as f:for item in ds:newitem = {"input": item["question"],"context": item["context"],"output": item["answer"],}f.write(json.dumps(newitem) + "\n")
步骤2:运行微调脚本
在微调数据集微调llama2模型,代码如下:
modal run src.finetune_sql --data-dir "data_sql" --model-dir "model_sql"微调脚本会执行以下步骤:
将数据集拆分为训练和验证拆分
train_val = data["train"].train_test_split(test_size=val_set_size, shuffle=True, seed=42)train_data = train_val["train"].shuffle().map(generate_and_tokenize_prompt)val_data = train_val["test"].shuffle().map(generate_and_tokenize_prompt)
将每个拆分为元组的格式(输入Prompt、标签):输入query和上下文被格式化为输入Prompt,然后对输入Prompt和标签进行 tokenize,模型采用自回归的方法预测下一个token来进行训练。
def generate_and_tokenize_prompt(data_point):full_prompt = generate_prompt_sql(data_point["input"],data_point["context"],data_point["output"],)tokenized_full_prompt = tokenize(full_prompt)if not train_on_inputs:raise NotImplementedError("not implemented yet")return tokenized_full_prompt
PS:输入Prompt与开始测试llama2的格式完全相同。
运行微调脚本时,模型将保存在model_dir指定的远程云目录中(如果未指定,则设置为默认值)。
步骤3:评估微调后模型
该模型已经进行了微调,可以从云端提供服务。下面我们使用b-mc2/sql-create-context中的示例数据进行一些基本评估,比较微调后模型与原始Llama 2模型的性能。
modal run src.eval_sql::main结果表明,微调后的模型有了巨大的改进:
Input 1: {'input': 'Which region (year) has Abigail at number 7, Sophia at number 1 and Aaliyah at number 5?', 'context': 'CREATE TABLE table_name_12 (region__year_ VARCHAR, no_5 VARCHAR, no_7 VARCHAR, no_1 VARCHAR)', 'output': 'SELECT region__year_ FROM table_name_12 WHERE no_7 = "abigail" AND no_1 = "sophia" ANDno_5 = "aaliyah"'}Output 1 (finetuned model): SELECT region__year_ FROM table_name_12 WHERE no_7 = "abigail" AND no_1 = "aaliyah" AND no_5 = "sophia"Output 1 (base model): SELECT * FROM table_name_12 WHERE region__year = '2018' AND no_5 = 'Abigail' AND no_7 = 'Sophia' AND no_1 = 'Aaliyah';Input 2: {'input': 'Name the result/games for 54741', 'context': 'CREATE TABLE table_21436373_11 (result_games VARCHAR, attendance VARCHAR)', 'output': 'SELECT result_games FROM table_21436373_11 WHERE attendance = 54741'}Output 2 (finetuned model): SELECT result_games FROM table_21436373_11 WHERE attendance = "54741"Output 2 (base model): SELECT * FROM table_21436373_11 WHERE result_games = 'name' AND attendance > 0;
步骤4:将微调模型与LlamaIndex集成
我们现在可以在LlamaIndex中使用这个模型,在任何数据库上进行文本到SQL。
我们首先定义一个测试SQL数据库,然后可以使用该数据库来测试模型的推理能力。
我们创建了一个玩具city_stats表,其中包含城市名称、人口和国家信息,并用几个示例城市填充它。
db_file = "cities.db"engine = create_engine(f"sqlite:///{db_file}")metadata_obj = MetaData()# create city SQL tabletable_name = "city_stats"city_stats_table = Table(table_name,metadata_obj,Column("city_name", String(16), primary_key=True),Column("population", Integer),Column("country", String(16), nullable=False),)metadata_obj.create_all(engine)
这存储在cities.db文件中。
然后,我们可以使用Modal将微调后的模型和该数据库文件加载到LlamaIndex中的NLSQLTableQueryEngine中——该查询引擎允许用户轻松地开始在给定的数据库上执行文本到SQL。
modal run src.inference_sql_llamaindex::main --query "Which city has the highest population?" --sqlite-file-path "nbs/cities.db" --model-dir "model_sql" --use-finetuned-model True我们得到如下回复:
SQL Query: SELECT MAX(population) FROM city_stats WHERE country = "United States"Response: [(2679000,)]
三、结论
本文提供了一种非常高级的方法来开始微调生成SQL语句的Llama 2模型,并展示了如何使用LlamaIndex将其端到端插入到文本到SQL工作流中。
参考文献:
[1] https://blog.llamaindex.ai/easily-finetune-llama-2-for-your-text-to-sql-applications-ecd53640e10d
[2] https://github.com/run-llama/modal_finetune_sql
[3] https://github.com/run-llama/modal_finetune_sql/blob/main/tutorial.ipynb
相关文章:
LLM微调(四)| 微调Llama 2实现Text-to-SQL,并使用LlamaIndex在数据库上进行推理
Llama 2是开源LLM发展的一个巨大里程碑。最大模型及其经过微调的变体位居Hugging Face Open LLM排行榜(https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)前列。多个基准测试表明,就性能而言,它正在接近GPT-3.5…...
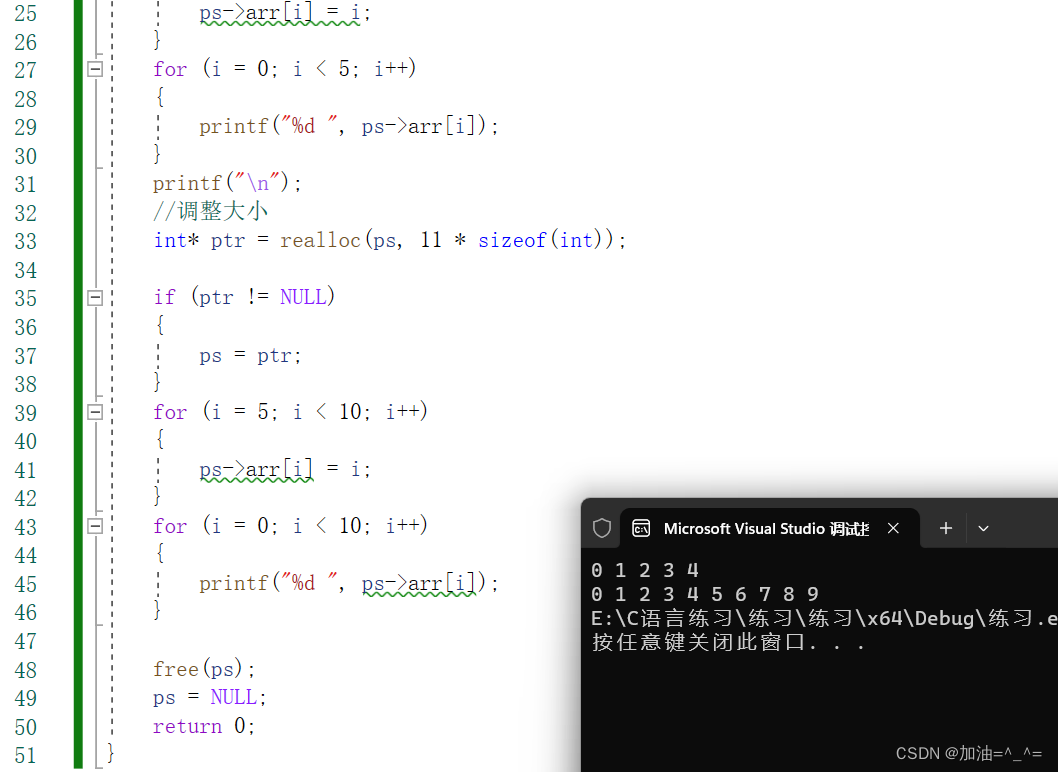
柔性数组(结构体成员)
目录 前言: 柔性数组: 给柔性数组分配空间: 调整柔性数组大小: 柔性数组的好处: 前言: 柔性数组?可能你从未听说,但是确实有这个概念。听名字,好像就是柔软的数…...

C#合并多个Word文档(微软官方免费openxml接口)
g /// <summary>/// 合并多个word文档(合并到第一文件)/// </summary>/// <param name"as_word_paths">word文档完整路径</param>/// <param name"breakNewPage">true(默认值),合并下一个…...

MySQL 5.7依赖的软件包和下载地址
yum install ncurses-devel openssl openssl-devel gcc gcc-c ncurses ncurses-devel bison make -y mysql下载地址 下载地址...

图论 | 网络流的基本概念
文章目录 流网路残留网络增广路径割最大流最小割定理最大流Edmonds-Karp 算法算法步骤程序代码时间复杂度 流网路 流网络: G ( V , E ) G (V, E) G(V,E) 有向图,不考虑反向边s:源点t:汇点 c ( u , v ) c(u, v) c(u,v)ÿ…...

【音视频 | AAC】AAC音频编码详解
😁博客主页😁:🚀https://blog.csdn.net/wkd_007🚀 🤑博客内容🤑:🍭嵌入式开发、Linux、C语言、C、数据结构、音视频🍭 🤣本文内容🤣&a…...
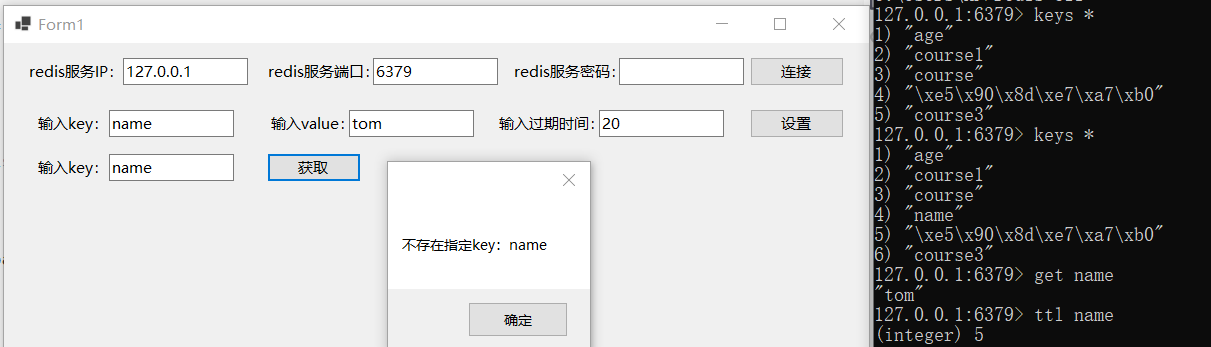
redis基本用法学习(C#调用NRedisStack操作redis)
redis官网文档中推荐C#中使用NRedisStack包连接并操作redis,本文学习C#调用NRedisStack操作redis的基本方式。 新建Winform项目,在Nuget包管理器中搜索并安装NRedisStack包,如下图所示: 主要调用StackExchange.Redis命名空间下…...

[CVPR 2023:3D Gaussian Splatting:实时的神经场渲染]
文章目录 前言小结 原文地址:https://blog.csdn.net/qq_45752541/article/details/132854115 前言 mesh 和点是最常见的3D场景表示,因为它们是显式的,非常适合于快速的基于GPU/CUDA的栅格化。相比之下,最近的神经辐射场…...
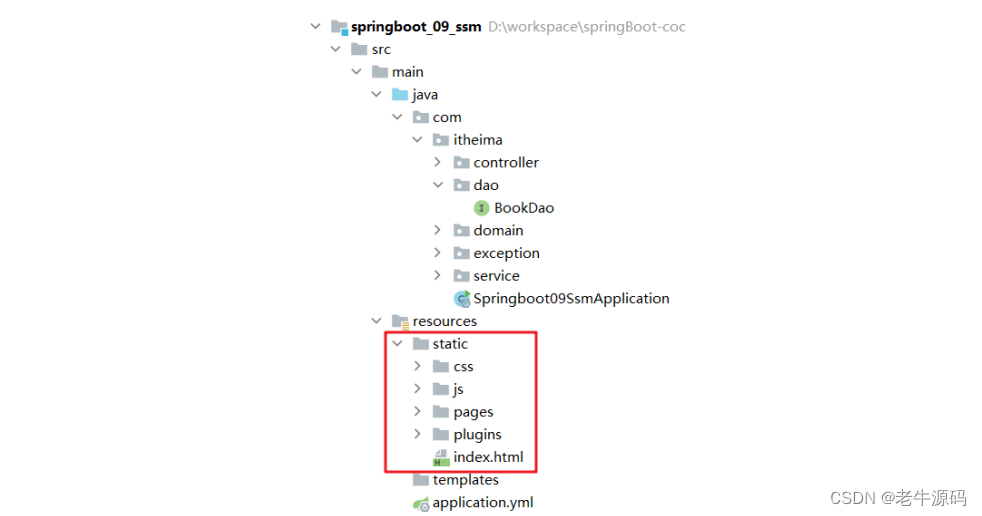
【SpringBoot快速入门】(4)SpringBoot项目案例代码示例
目录 1 创建工程3 配置文件4 静态资源 之前我们已经学习的Spring、SpringMVC、Mabatis、Maven,详细讲解了Spring、SpringMVC、Mabatis整合SSM的方案和案例,上一节我们学习了SpringBoot的开发步骤、工程构建方法以及工程的快速启动,从这一节开…...
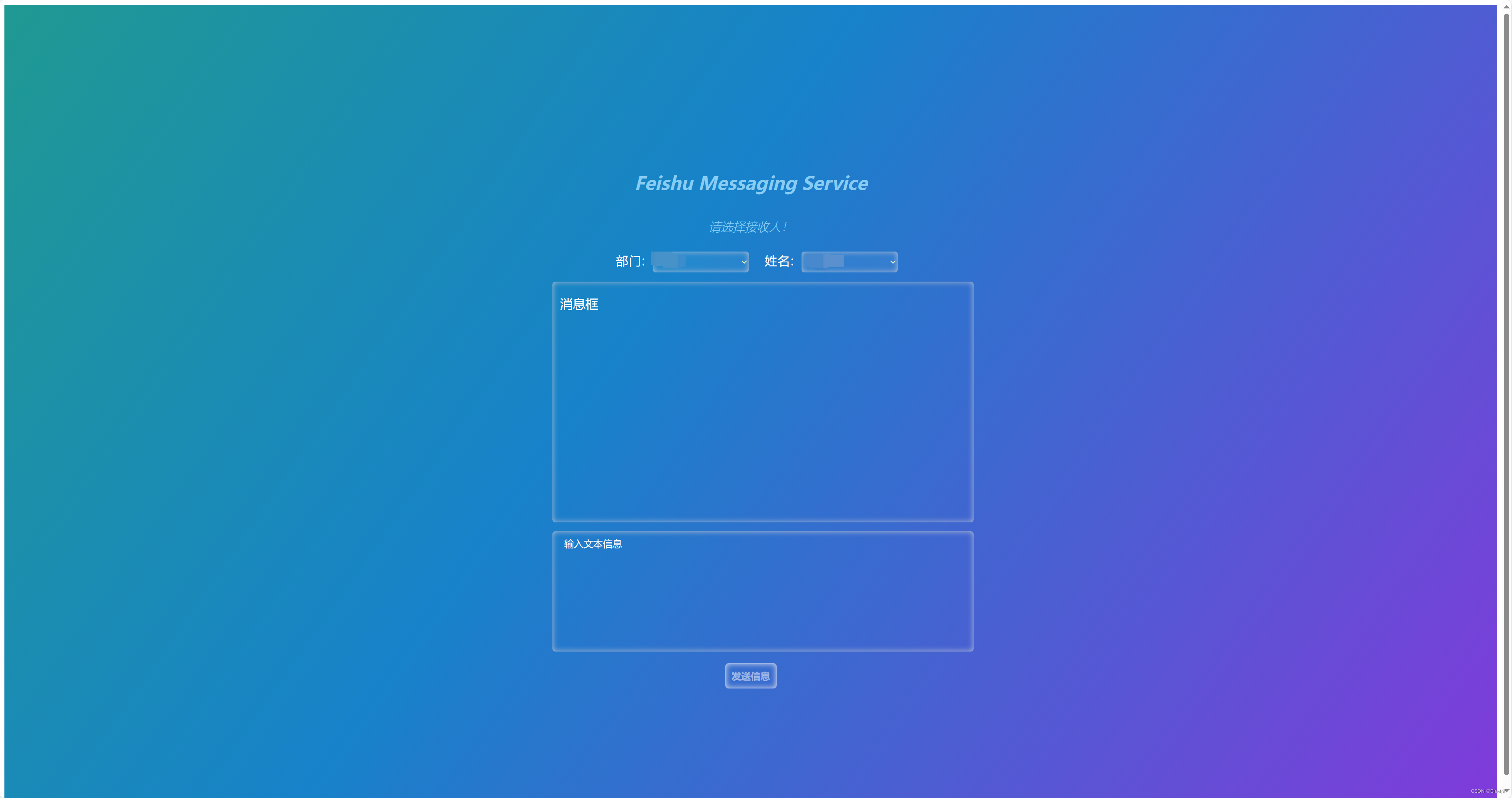
Linux服务器 部署飞书信息发送服务
项目介绍: 飞书信息发送服务是指将飞书信息发送服务部署到一个Linux服务器上。飞书是一款企业级的即时通讯和协作工具,支持发送消息给飞书的功能。通过部署飞书信息发送服务,可以方便内网发送信息给外网飞书。 项目代码结构展示: …...
用C#也能做机器学习?
前言✨ 说到机器学习,大家可能都不陌生,但是用C#来做机器学习,可能很多人还第一次听说。其实在C#中基于ML.NET也是可以做机器学习的,这种方式比较适合.NET程序员在项目中集成机器学习模型,不太适合专门学习机器学习&a…...

Python PDF格式转PPT格式
要将PDF文件转换为PPT,我实在python3.9 环境下转成功的,python3.11不行。 需要 pip install PyMuPDF代码说话 # -*- coding: utf-8 -*-""" author: 赫凯 software: PyCharm file: xxx.py time: 2023/12/21 11:20 """im…...
搭建知识付费平台?明理信息科技为你提供全程解决方案
明理信息科技saas知识付费平台 在当今数字化时代,知识付费已经成为一种趋势,越来越多的人愿意为有价值的知识付费。然而,公共知识付费平台虽然内容丰富,但难以满足个人或企业个性化的需求和品牌打造。同时,开发和维护…...

漫谈UNIX、Linux、UNIX-Like
漫谈UNIX、Linux、UNIX-Like 使用了这么多年Redhat、Ubuntu等Linux、Windows、Solaris操作系统,你是否对UNIX、Unix-Like(类UNIX)还是不太清楚?我以前一直认为Unix-Like就等于Linux。其实,由UNIX派生出来而没有取得UN…...

Netty Review - Netty与Protostuff:打造高效的网络通信
文章目录 概念PrePomServer & ClientProtostuffUtil 解读测试小结 概念 Pre 每日一博 - Protobuf vs. Protostuff:性能、易用性和适用场景分析 Pom <dependency><groupId>com.dyuproject.protostuff</groupId><artifactId>protostuff-…...
在ClickHouse数据库中启用预测功能
在这篇博文中,我们将介绍如何将机器学习支持的预测功能与 ClickHouse 数据库集成。ClickHouse 是一个快速、开源、面向列的 SQL 数据库,对于数据分析和实时分析非常有用。该项目由 ClickHouse, Inc. 维护和支持。我们将探索它在需要数据准备以…...
)
目标检测YOLO实战应用案例100讲-树上果实识别与跟踪计数(续)
目录 3.2 损失函数优化 3.3 实验过程 3.3.1 果实图像采集 3.3.2 数据扩增...
Docker 文件和卷 权限拒绝
一 创作背景 再复制Docker影像文件或访问Docker容器内已安装卷上的文件时我们常常会遇到:“权限被拒绝”的错误,在此,您将了解到为什么会出现“权限被拒绝”的错误以及如何解决这个问题。 二 目的 在深入探讨 Docker 容器中的 Permission De…...
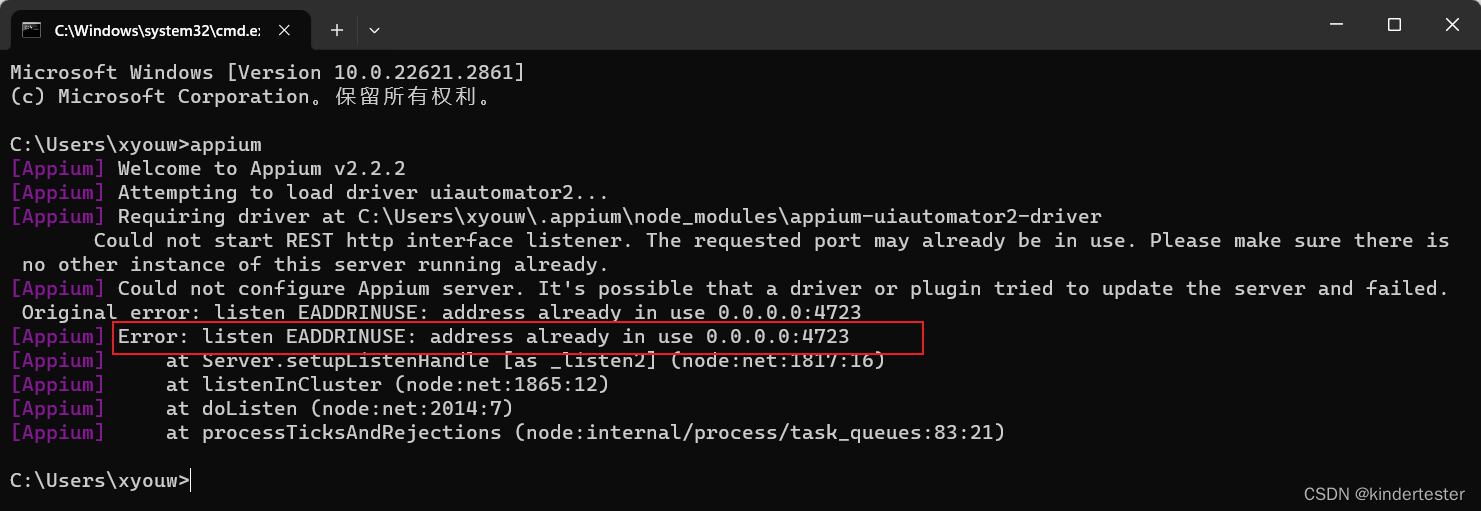
Appium Server 启动失败常见原因及解决办法
Error: listen EADDRINUSE: address already in use 0.0.0.0:4723 如下图: 错误原因:Appium 默认的4723端口被占用 解决办法: 出现该提示,有可能是 Appium Server 已启动,关闭已经启动的 Appium Server 即可。472…...
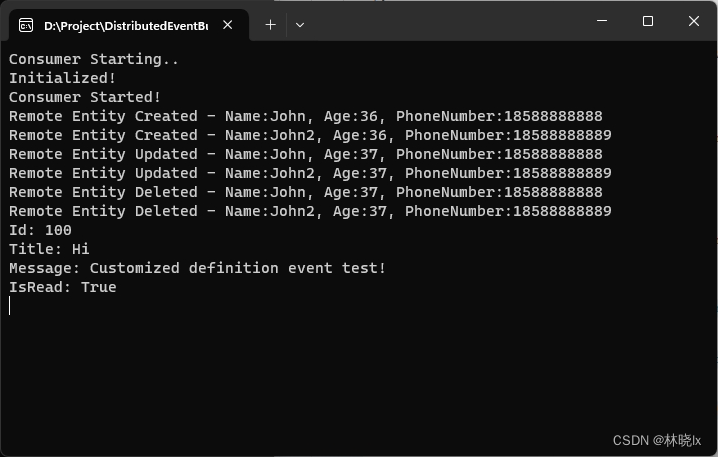
将Abp默认事件总线改造为分布式事件总线
文章目录 原理创建分布式事件总线实现自动订阅和事件转发 使用启动Redis服务配置传递Abp默认事件传递自定义事件 项目地址 原理 本地事件总线是通过Ioc容器来实现的。 IEventBus接口定义了事件总线的基本功能,如注册事件、取消注册事件、触发事件等。 Abp.Events…...

从课堂作业到项目复盘:用Proteus仿真四人抢答器,我踩过的那些‘坑’
从课堂作业到项目复盘:用Proteus仿真四人抢答器,我踩过的那些‘坑’ 第一次在Proteus里搭建四人抢答器时,我以为只要按教科书上的电路图连线就能轻松完成。直到LED灯在上电瞬间诡异地闪烁、计数器在临界值跳变时卡死、抢答信号被误判为违规……...

Shannon 没有想到的事——当信息论遇上有限算力
从一个日常经验开始你有没有过这种体验——打开一本教科书,前三页还能跟上,到第四页突然看不懂了。每个字你都认识,但连在一起就变成了噪音。你翻回去重读,还是不行。于是你合上书,换了一本"入门版"…...

3分钟掌握暗黑破坏神2存档编辑器:免费在线工具让你的游戏体验全面升级
3分钟掌握暗黑破坏神2存档编辑器:免费在线工具让你的游戏体验全面升级 【免费下载链接】d2s-editor 项目地址: https://gitcode.com/gh_mirrors/d2/d2s-editor 还在为刷不到心仪的装备而烦恼吗?想要快速体验不同职业的乐趣却不想重新练级&#x…...

开源IM机器人技能框架openclaw-skill-imsg架构解析与实战
1. 项目概述:一个面向即时通讯消息的自动化技能框架最近在折腾一个挺有意思的开源项目,叫openclaw-skill-imsg。光看这个名字,可能有点摸不着头脑,我来拆解一下。openclaw听起来像是一个开源(open)的“爪子…...

Android Studio 在 MacOS 上的完整安装与使用指南
Android Studio 在 MacOS 上的完整安装与使用指南摘要一、Android Studio 简介二、下载与安装1. 下载 Android Studio2. 安装前的依赖准备3. 安装步骤三、基础使用指南1. 创建第一个项目2. 运行应用3. 核心功能四、进阶功能配置1. 配置 SDK 和工具2. 自定义主题与插件3. Gradle…...

Excel数据分析工具库 vs. Python手动计算:手把手教你搞定一元线性回归的全部检验
Excel与Python双视角解析:一元线性回归的实战检验指南 当市场部的同事递给你一份用户行为数据,指着"页面停留时间"和"转化率"两列问你"这两个指标到底有没有关系"时,你会选择打开Excel的回归分析工具一键生成报…...

JDspyder:京东自动化抢购解决方案的技术实现与实战指南
JDspyder:京东自动化抢购解决方案的技术实现与实战指南 【免费下载链接】JDspyder 京东预约&抢购脚本,可以自定义商品链接 项目地址: https://gitcode.com/gh_mirrors/jd/JDspyder 在电商秒杀和限量商品抢购的激烈竞争中,技术手段…...

在Windows电脑上体验酷安社区:酷安UWP桌面版完全指南
在Windows电脑上体验酷安社区:酷安UWP桌面版完全指南 【免费下载链接】Coolapk-UWP 一个基于 UWP 平台的第三方酷安客户端 项目地址: https://gitcode.com/gh_mirrors/co/Coolapk-UWP 你是否曾经想过,如果能在电脑上刷酷安会是怎样的体验…...

Node.js 与前端 JavaScript 的区别:不止运行环境,底层完全不一样
很多开发者误以为 Node.js 和浏览器 JavaScript 只是运行地方不同、语法一样,实际二者虽共用 ECMAScript 语法规范,但在全局对象、API 能力、DOM/BOM、模块系统、事件循环、系统权限、应用场景等方面存在本质差异。本文从技术底层全面对比,帮…...

基于MCP协议集成AI求职助手:自动化简历优化与面试准备
1. 项目概述:将AI求职助手集成到你的工作流 如果你正在用Claude Desktop或者Cursor这类AI助手,并且恰好又在找工作或者准备职业跃迁,那你可能已经体会过那种“割裂感”——你需要手动把简历内容、职位描述、面试问题来回复制粘贴到聊天窗口&…...