MySQL数据库 索引
目录
索引概述
索引结构
二叉树
B-Tree
B+Tree
Hash
索引分类
索引语法
慢查询日志
索引概述
索引 (index)是帮助MySQL高效获取数据的数据结构(有序)。在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法,这种数据结构就是索引。

演示:表结构数据如下
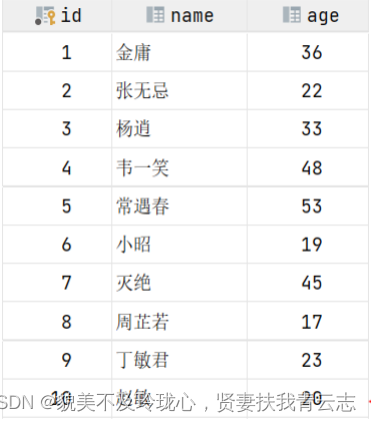
假如我们要执行的sor语句为: select * from user where age = 45;、
无索引i情况:
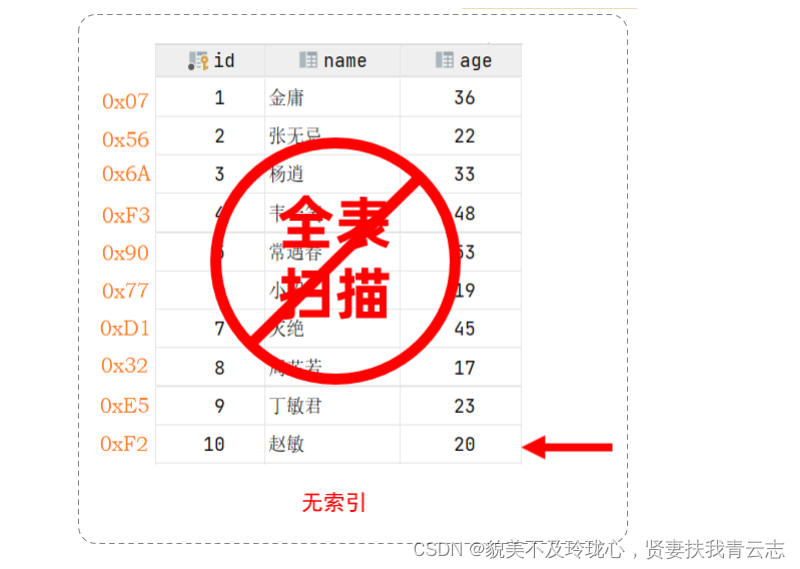
在无索引情况下,就需要从第一行开始扫描,一直扫描到最后一行,我们称之为全表扫描,性能很低。
有索引情况:
如果我们针对于这张表建立了索引,假设索引结构就是二叉树,那么也就意味着,会对age这个字段建立一个二叉树的索引结构。

此时我们在进行查询时,只需要扫描三次就可以找到数据了,极大的提高的查询的效率。
备注:这里我们只是假设索引的结构是二叉树,介绍一下索引的大概原理,只是一个示意图,并不是索引的真实结构,索引的真实结构,后面会详细介绍。
特点:

索引结构
MysQL的索引是在存储引擎层实现的,不同的存储引擎有不同的索引结构,主要包含以下几种:
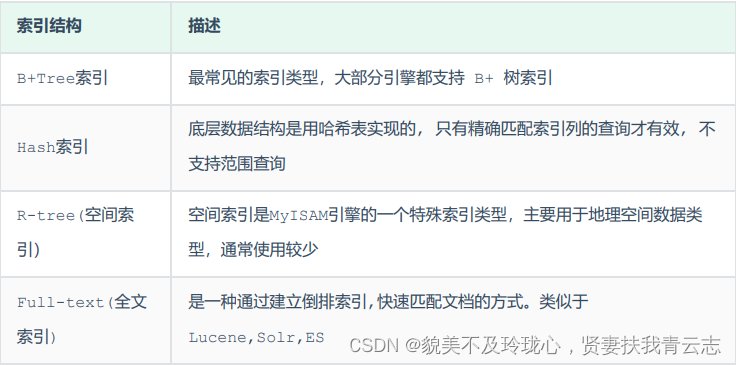
上述是MysQL中所支持的所有的索引结构,接下来,我们再来看看不同的存储引擎对于索引结构的支持情况。
二叉树
假如说MySQL的索引结构采用二叉树的数据结构,比较理想的结构如下:

如果主键是顺序插入的,则会形成一个单向链表,结构如下:

所以,如果选择二叉树作为索引结构,会存在以下缺点:
- 顺序插入时,会形成一个链表,查询性能大大降低。
- 大数据量情况下,层级较深,检索速度慢。
此时大家可能会想到,我们可以选择红黑树,红黑树是一颗自平衡二叉树,那这样即使是顺序插入数据,最终形成的数据结构也是一颗平衡的二叉树,结构如下:
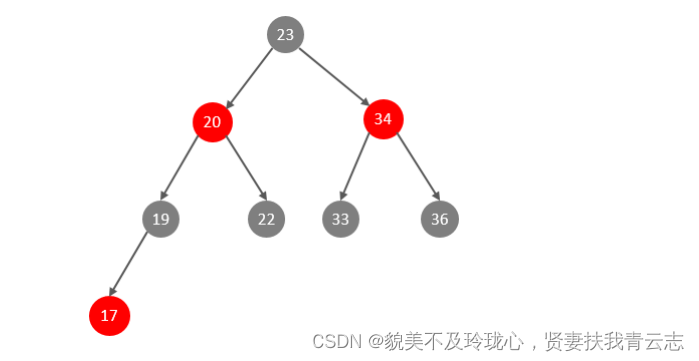
但是,即使如此,由于红黑树也是一颗二叉树,所以也会存在一个缺点:
大数据量情况下,层级较深,检索速度慢。
所以,在MySQL的索引结构中,并没有选择二叉树或者红黑树,而选择的是B+Tree,那么什么是B+Tree呢?在详解B+Tree之前,先来介绍一个B-Tree。
B-Tree
B一Tree,z树是一种多叉路衡查找树,相对于二叉树,z树每个节点可以有多个分支,即多叉。
以一颗最大度数(max-degree)为5 (5阶)的b-tree为例,那这个B树每个节点最多存储4个key,5个指针:

树的度数指的是一个节点的子节点个数。
插入一组数据: 100 65 169 368 900 556 780 35 215 1200 234 888 158 90 1000 88120 268 250 然后观察一些数据插入过程中,节点的变化情况。

特点:
- 5阶的B树,每一个节点最多存储4个key,对应5个指针。
- 一旦节点存储的key数量到达5,就会裂变,中间元素向上分裂。
- 在B+树中,非叶子节点和叶子节点都会存放数据。
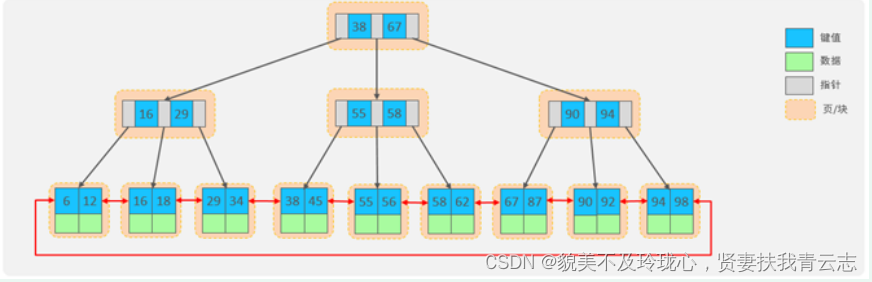
B+Tree
B+Tree是B-Tree的变种,我们以一颗最大度数(max-degree)为4(4阶)的b+tree为例,来看一下其结构示意图:

我们可以看到,两部分:
- 绿色框框起来的部分,是索引部分,仅仅起到索引数据的作用,不存储数据。
- 红色框框起来的部分,是数据存储部分,在其叶子节点中要存储具体的数据。
插入一组数据: 100 65 169 368 900 556 780 35 215 1200 234 888 158 90 1000 88120 268 250 。然后观察一些数据插入过程中,节点的变化情况。
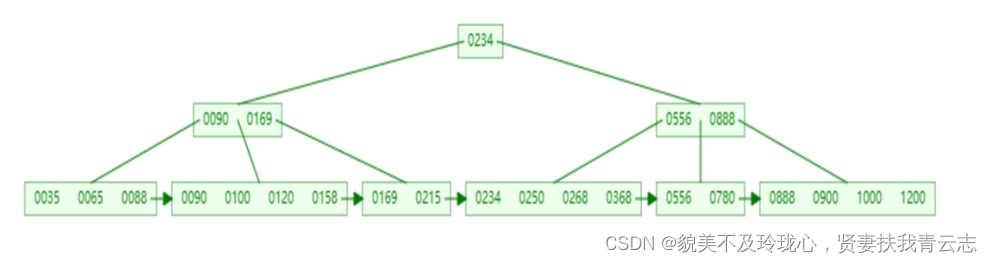
最终我们看到,B+Tree 与B一Tree相比,主要有以下三点区别:
- 所有的数据都会出现在叶子节点。
- 叶子节点形成一个单向链表
- 非叶子节点仅仅起到索引数据作用,具体的数据都是在叶子节点存放的。
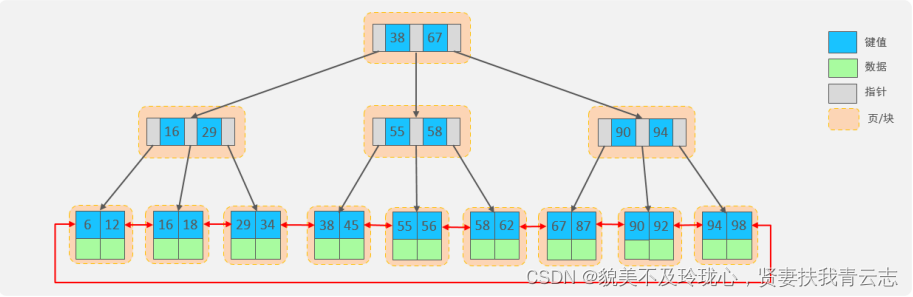
上述我们所看到的结构是标准的B+Tree的数据结构,接下来,我们再来看看MysQL中优化之后的
B+Tree。
MySQL索引数据结构对经典的B+Tree进行了优化。在原B+Tree的基础上,增加一个指向相邻叶子节点的链表指针,就形成了带有顺序指针的B+Tree,提高区间访问的性能,利于排序。
Hash
MySQL中除了支持B+Tree索引,还支持一种索引类型---Hash索引。
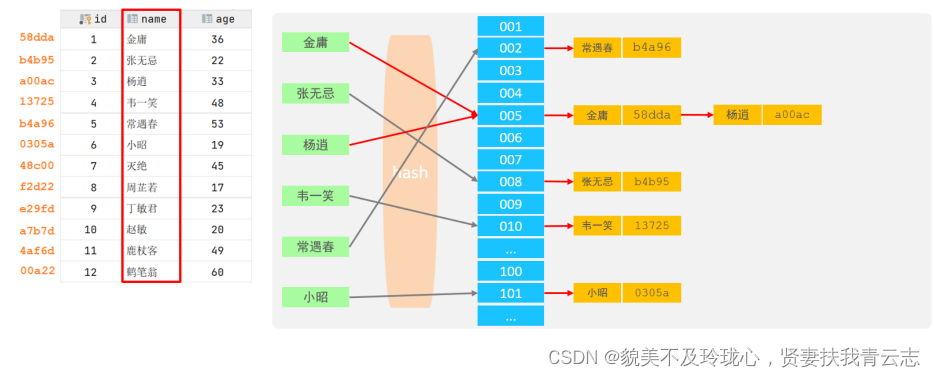
结构:哈希索引就是采用一定的hash算法,将键值换算成新的hash值,映射到对应的槽位上,然后存储在hash表中。

如果两个(或多个)键值,映射到一个相同的槽位上,他们就产生了hash冲突(也称为hash碰撞),可以通过链表来解决。
特点
- Hash索引只能用于对等比较(=, in),不支持范围查询(between,>,< ,...)
- 无法利用索引完成排序操作
- 查询效率高,通常(不存在hash冲突的情况)只需要一次检索就可以了,效率通常要高于B+tree索引
存储引擎支持:在MySQL中,支持hash索引的是Memory存储引擎。而InnoDB中具有自适应hash功能,hash索引是InnoDB存储引擎根据B+Tree索引在指定条件下自动构建的。
为什么InnoDB存储引擎选择使用B+tree索引结构?
- 相对于二叉树,层级更少,搜索效率高;
- 对于B-tree,无论是叶子节点还是非叶子节点,都会保存数据,这样导致一页中存储的键值减少,指针跟着减少,要同样保存大量数据,只能增加树的高度,导致性能降低;
- 相对Hash索引,B+tree支持范围匹配及排序操作;
索引分类
在MySQL数据库,将索引的具体类型主要分为以下几类:主键索引、唯一索引、常规索引、全文索引。

而在在InnoDB存储引擎中,根据索引的存储形式,又可以分为以下两种

聚集索引选取规则:
- 如果存在主键,主键索引就是聚集索引。
- 如果不存在主键,将使用第一个唯一(UNIQUE)索引作为聚集索引。
- 如果表没有主键,或没有合适的唯一索引,则InnoDB会自动生成一个rowid作为隐藏的聚集索引。
聚集索引和二级索引的具体结构如下:
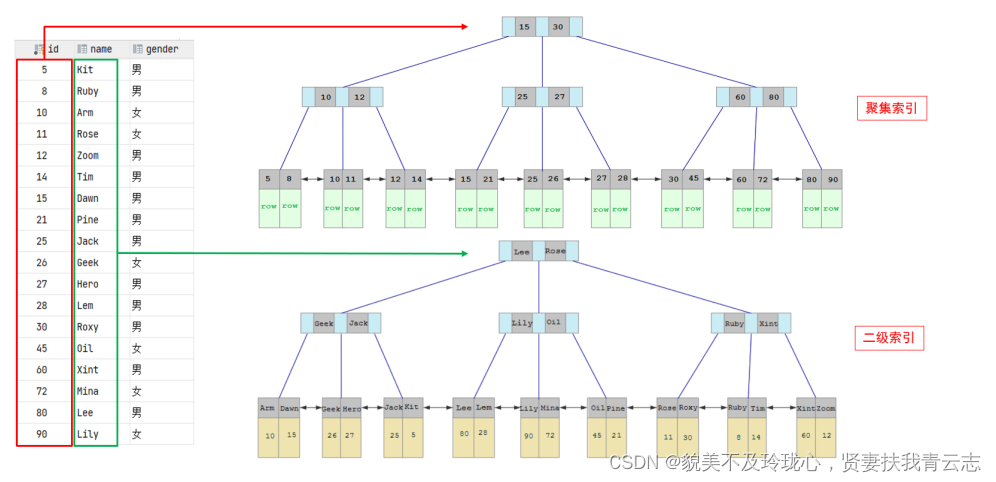
- 聚集索引的叶子节点下挂的是这一行的数据。
- 二级索引的叶子节点下挂的是该字段值对应的主键值。
接下来,我们来分析一下,当我们执行如下的 SQL 语句时,具体的查找过程是什么样子的。

接下来,我们来分析一下,当我们执行如下的soz语句时,具体的查找过程是什么样子的
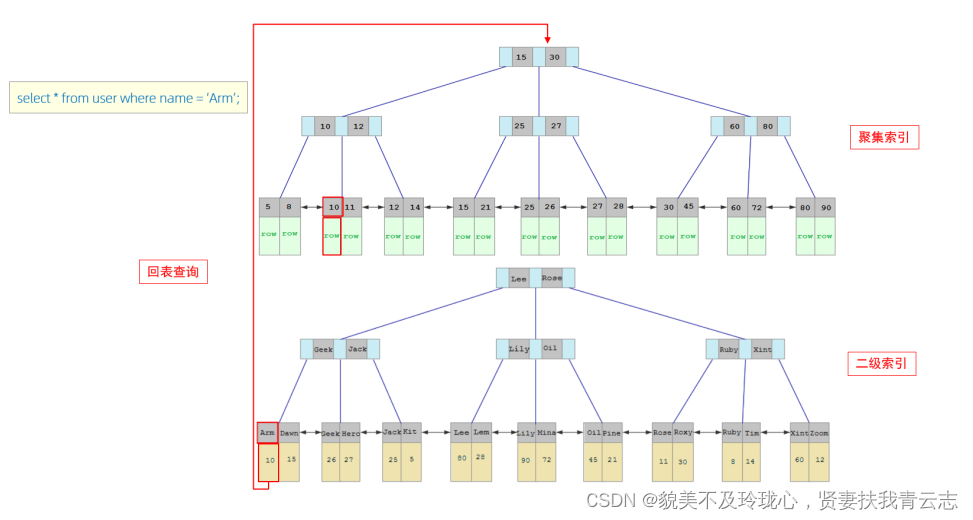
具体过程如下:
- 由于是根据name字段进行查询,所以先根据name='Arm '到name字段的二级索引中进行匹配查找。但是在二级索引中只能查找到Arm对应的主键值10。
- 由于查询返回的数据是*,所以此时,还需要根据主键值10,到聚集索引中查找10对应的记录,最终找到1o对应的行row。
- 最终拿到这一行的数据,直接返回即可。
回表查询:这种先到二级索引中查找数据,找到主键值,然后再到聚集索引中根据主键值,获取数据的方式,就称之为回表查询。
InnoDB主键索引的B+tree高度为多高呢?
一行数据大小为1k,一页中可以存储16行这样的数据。工nnoDB的指针占用6个字节的空间,主键即使为bigint,占用字节数为8。
高度为2:
n *8 +(n + 1)* 6= 16*1024,算出n约为1170 ; 1171* 16= 18736
也就是说,如果树的高度为2,则可以存储18000多条记录。
高度为3:
1171 *1171 *16=21939856
也就是说,如果树的高度为3,则可以存储 2200w左右的记录。
索引语法
创建索引
CREATE [ UNIQUE | FULLTEXT ] INDEX index_name ON table_name (index_col_name,... ) ;查看索引
SHOW INDEX FROM table_name ;删除索引
DROP INDEX index_name ON table_name ;先来创建一张表 tb_user,并且查询测试数据。
create table tb_user(id int primary key auto_increment comment '主键',name varchar(50) not null comment '用户名',phone varchar(11) not null comment '手机号',email varchar(100) comment '邮箱',profession varchar(11) comment '专业',age tinyint unsigned comment '年龄',gender char(1) comment '性别 , 1: 男, 2: 女',status char(1) comment '状态',createtime datetime comment '创建时间'
) comment '系统用户表';INSERT INTO tb_user (name, phone, email, profession, age, gender, status,createtime) VALUES ('吕布', '17799990000', 'lvbu666@163.com', '软件工程', 23, '1','6', '2001-02-02 00:00:00');INSERT INTO tb_user (name, phone, email, profession, age, gender, status,createtime) VALUES ('曹操', '17799990001', 'caocao666@qq.com', '通讯工程', 33,'1', '0', '2001-03-05 00:00:00');INSERT INTO tb_user (name, phone, email, profession, age, gender, status,createtime) VALUES ('赵云', '17799990002', '17799990@139.com', '英语', 34, '1','2', '2002-03-02 00:00:00');INSERT INTO tb_user (name, phone, email, profession, age, gender, status,createtime) VALUES ('孙悟空', '17799990003', '17799990@sina.com', '工程造价', 54,'1', '0', '2001-07-02 00:00:00');INSERT INTO tb_user (name, phone, email, profession, age, gender, status,createtime) VALUES ('花木兰', '17799990004', '19980729@sina.com', '软件工程', 23,'2', '1', '2001-04-22 00:00:00');INSERT INTO tb_user (name, phone, email, profession, age, gender, status,createtime) VALUES ('大乔', '17799990005', 'daqiao666@sina.com', '舞蹈', 22, '2','0', '2001-02-07 00:00:00');INSERT INTO tb_user (name, phone, email, profession, age, gender, status,createtime) VALUES ('露娜', '17799990006', 'luna_love@sina.com', '应用数学', 24,'2', '0', '2001-02-08 00:00:00');INSERT INTO tb_user (name, phone, email, profession, age, gender, status,createtime) VALUES ('程咬金', '17799990007', 'chengyaojin@163.com', '化工', 38,'1', '5', '2001-05-23 00:00:00');INSERT INTO tb_user (name, phone, email, profession, age, gender, status,createtime) VALUES ('项羽', '17799990008', 'xiaoyu666@qq.com', '金属材料', 43,'1', '0', '2001-09-18 00:00:00');INSERT INTO tb_user (name, phone, email, profession, age, gender, status,createtime) VALUES ('白起', '17799990009', 'baiqi666@sina.com', '机械工程及其自动化', 27, '1', '2', '2001-08-16 00:00:00');INSERT INTO tb_user (name, phone, email, profession, age, gender, status,createtime) VALUES ('韩信', '17799990010', 'hanxin520@163.com', '无机非金属材料工程', 27, '1', '0', '2001-06-12 00:00:00');INSERT INTO tb_user (name, phone, email, profession, age, gender, status,createtime) VALUES ('荆轲', '17799990011', 'jingke123@163.com', '会计', 29, '1','0', '2001-05-11 00:00:00');INSERT INTO tb_user (name, phone, email, profession, age, gender, status,createtime) VALUES ('兰陵王', '17799990012', 'lanlinwang666@126.com', '工程造价',44, '1', '1', '2001-04-09 00:00:00');INSERT INTO tb_user (name, phone, email, profession, age, gender, status,createtime) VALUES ('狂铁', '17799990013', 'kuangtie@sina.com', '应用数学', 43,'1', '2', '2001-04-10 00:00:00');INSERT INTO tb_user (name, phone, email, profession, age, gender, status,createtime) VALUES ('貂蝉', '17799990014', '84958948374@qq.com', '软件工程', 40,'2', '3', '2001-02-12 00:00:00');INSERT INTO tb_user (name, phone, email, profession, age, gender, status,createtime) VALUES ('妲己', '17799990015', '2783238293@qq.com', '软件工程', 31,'2', '0', '2001-01-30 00:00:00');INSERT INTO tb_user (name, phone, email, profession, age, gender, status,createtime) VALUES ('芈月', '17799990016', 'xiaomin2001@sina.com', '工业经济', 35,'2', '0', '2000-05-03 00:00:00');INSERT INTO tb_user (name, phone, email, profession, age, gender, status,createtime) VALUES ('嬴政', '17799990017', '8839434342@qq.com', '化工', 38, '1','1', '2001-08-08 00:00:00');INSERT INTO tb_user (name, phone, email, profession, age, gender, status,createtime) VALUES ('狄仁杰', '17799990018', 'jujiamlm8166@163.com', '国际贸易',30, '1', '0', '2007-03-12 00:00:00');INSERT INTO tb_user (name, phone, email, profession, age, gender, status,createtime) VALUES ('安琪拉', '17799990019', 'jdodm1h@126.com', '城市规划', 51,'2', '0', '2001-08-15 00:00:00');INSERT INTO tb_user (name, phone, email, profession, age, gender, status,createtime) VALUES ('典韦', '17799990020', 'ycaunanjian@163.com', '城市规划', 52,'1', '2', '2000-04-12 00:00:00');INSERT INTO tb_user (name, phone, email, profession, age, gender, status,createtime) VALUES ('廉颇', '17799990021', 'lianpo321@126.com', '土木工程', 19,'1', '3', '2002-07-18 00:00:00');INSERT INTO tb_user (name, phone, email, profession, age, gender, status,createtime) VALUES ('后羿', '17799990022', 'altycj2000@139.com', '城市园林', 20,'1', '0', '2002-03-10 00:00:00');INSERT INTO tb_user (name, phone, email, profession, age, gender, status,createtime) VALUES ('姜子牙', '17799990023', '37483844@qq.com', '工程造价', 29,'1', '4', '2003-05-26 00:00:00');数据准备好了之后,接下来,我们就来完成如下需求:
# name字段为姓名字段,该字段的值可能会重复,为该字段创建索引。
1CREATE INDEX idx_user_name ON tb_user (name ) ;# phone手机号字段的值,是非空,且唯一的,为该字段创建唯一索引。
CREATE UNIQUE INDEX idx_user_phone ON tb_user(phone);# 为profession、age、status创建联合索引。
CREATE 工NDEX idx_user_pro_age_sta 0N tb_user(profession, age,status);# 为email建立合适的索引来提升查询效率。
CREATE 工NDEX idx_email ON tb_user (email);完成上述的需求之后,我们再查看tb_user表的所有的索引数据。
show index from tb_user;

慢查询日志
慢查询日志记录了所有执行时间超过指定参数(long_query_time,单位:秒,默认10秒)的所有
SQL语句的日志。MySQL的慢查询日志默认没有开启,我们可以查看一下系统变量slow_query_log。

如果要开启慢查询日志,需要在MySQL的配置文件(/etc/my.cnf)中配置如下信息:
# 开启MySQL慢日志查询开关
slow_query_log=1
# 设置慢日志的时间为2秒,SQL语句执行时间超过2秒,就会视为慢查询,记录慢查询日志
long_query_time=2配置完毕之后,通过以下指令重新启动MySQL服务器进行测试,查看慢日志文件中记录的信息 /var/lib/mysql/localhost-slow.log。
systemctl restart mysqld然后,再次查看开关情况,慢查询日志就已经打开了。

测试:
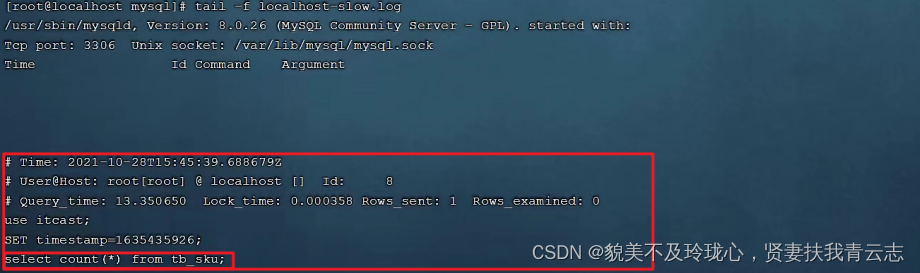
执行如下SQL语句 :
select * from tb_user; -- 这条SQL执行效率比较高, 执行耗时 0.00sec
select count(*) from tb_sku; -- 由于tb_sku表中, 预先存入了1000w的记录, count一次,耗时
13.35sec
检查慢查询日志 :
最终我们发现,在慢查询日志中,只会记录执行时间超多我们预设时间(2s)的SQL,执行较快的SQL 是不会记录的。
那这样,通过慢查询日志,就可以定位出执行效率比较低的SQL,从而有针对性的进行优化。
相关文章:
MySQL数据库 索引
目录 索引概述 索引结构 二叉树 B-Tree BTree Hash 索引分类 索引语法 慢查询日志 索引概述 索引 (index)是帮助MySQL高效获取数据的数据结构(有序)。在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种…...

ES 错误码
2xx状态码(如200)表示请求成功处理,并且不需要重试。 400状态码表示客户端发送了无效的请求,例如请求的语法有误或缺少必需的参数。在这种情况下,重试相同的请求很可能会导致相同的错误。因此,应该先检查并…...

听GPT 讲Rust源代码--src/tools(18)
File: rust/src/tools/rust-analyzer/crates/ide-ssr/src/from_comment.rs 在Rust源代码中的from_comment.rs文件位于Rust分析器(rust-analyzer)工具的ide-ssr库中,它的作用是将注释转换为Rust代码。 具体来说,该文件实现了从注…...

如何实现设备远程控制?
在工业自动化领域,设备远程控制是一项非常重要的技术。它使得设备可以在远离现场的情况下进行远程操作和维护,大大提高了设备的可用性和效率。 设备远程控制的应用场景有哪些? 远程故障排除:当设备出现故障时,工程师…...

百度侯震宇详解:大模型将如何重构云计算?
12月20日,在2023百度云智大会智算大会上,百度集团副总裁侯震宇以“大模型重构云计算”为主题发表演讲。他强调,AI原生时代,面向大模型的基础设施体系需要全面重构,为构建繁荣的AI原生生态筑牢底座。 侯震宇表示&…...

[Java]FileOutputStream的换行/续写/一次性写出一个字符串的方法
1.续写:FileOutputStream这个io流中的write方法默认情况下是覆盖写入的,如果需要追加写入,需要添加一个参数true 2.虽然write只能一个字符一个字符写入 但是我们可以把想输入的字符串放在str 再将str转化成byte数组 import java.io.FileOutp…...

VM进行TCP/IP通信
OK就变成这样 vm充当服务端的话也是差不多的操作 点击连接 这里我把端口号换掉了因为可能被占用报错了,如果有报错可以尝试尝试换个端口号 注: 还有一个点在工作中要是充当服务器,要去网络这边看下他的ip地址 拉到最后面...

剑指Offer 队列栈题目集合
目录 用两个栈实现队列 用两个栈实现队列 刷题链接: https://www.nowcoder.com/practice/54275ddae22f475981afa2244dd448c6 题目描述 思路一: 使用两个栈来实现队列的功能。栈 1 用于存储入队的元素,而栈 2 用于存储出队的元素。 1.push…...

grafana基本使用
一、安装grafana 1.下载 官网下载地址: https://grafana.com/grafana/download官网包的下载地址: yum install -y https://dl.grafana.com/enterprise/release/grafana-enterprise-10.2.2-1.x86_64.rpm官网下载速度非常慢,这里选择清华大…...
备份至关重要!如何解决iCloud的上次备份无法完成的问题
将iPhone和iPad备份到iCloud对于在设备发生故障或丢失时确保数据安全至关重要。但iOS用户有时会收到一条令人不安的消息,“上次备份无法完成。”下面我们来看看可能导致此问题的原因,如何解决此问题,并使你的iCloud备份再次顺利运行。 这些故…...

【项目问题解决】% sql注入问题
目录 【项目问题解决】% sql注入问题 1.问题描述2.问题原因3.解决思路4.解决方案1.前端限制传入特殊字符2.后端拦截特殊字符-正则表达式3.后端拦截特殊字符-拦截器 5.总结6.参考 文章所属专区 项目问题解决 1.问题描述 在处理接口入参的一些sql注入问题,虽然通过M…...
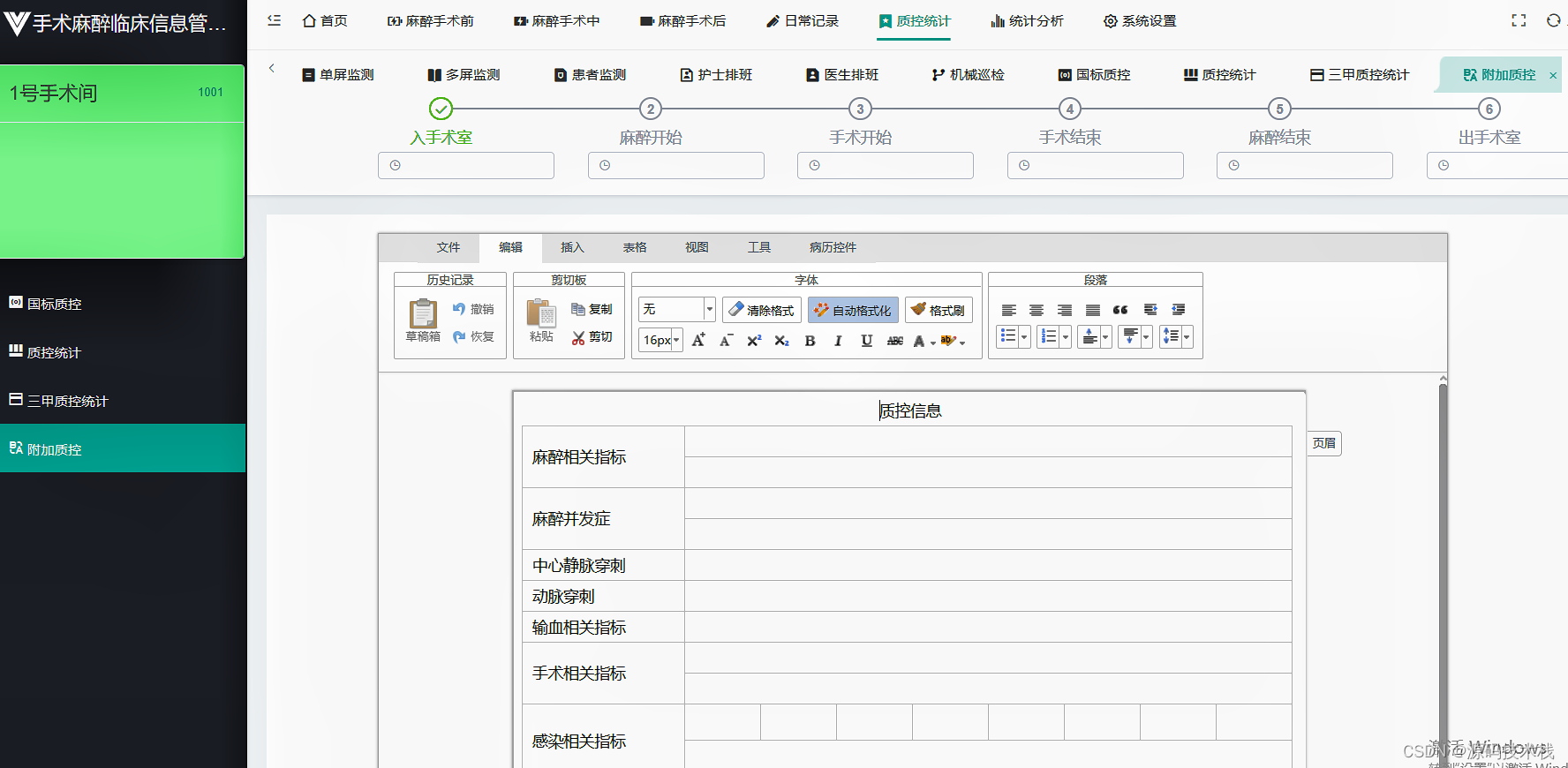
B/S医院手术麻醉临床管理系统源码 手术申请、手术安排
手术麻醉系统概述 手术室是医院各个科室工作交叉汇集的一个重要中心,在时间、空间、设备、药物、材料、人员调配的科学管理、高效运作、安全质控、绩效考核,都十分重要。手术麻醉管理系统(Operation Anesthesia Management System࿰…...

解锁高效工作!5款优秀工时管理软件推荐
工时管理,一直是让许多企业和团队头疼的问题。传统的纸质工时表、复杂的电子表格,不仅操作繁琐,还容易出错。幸好,随着科技的进步,我们迎来了工时管理软件的春天。今天,就让我们一起走进这个新时代…...

ICLR 2024 高分论文 | Step-Back Prompting 使大语言模型通过抽象进行推理
文章目录 一、前言二、主要内容三、总结🍉 CSDN 叶庭云:https://yetingyun.blog.csdn.net/ 一、前言 ICLR 2024 高分论文:《Step-Back Prompting Enables Reasoning Via Abstraction in Large Language Models》 论文地址:https://openreview.net/forum?id=3bq3jsvcQ1 …...
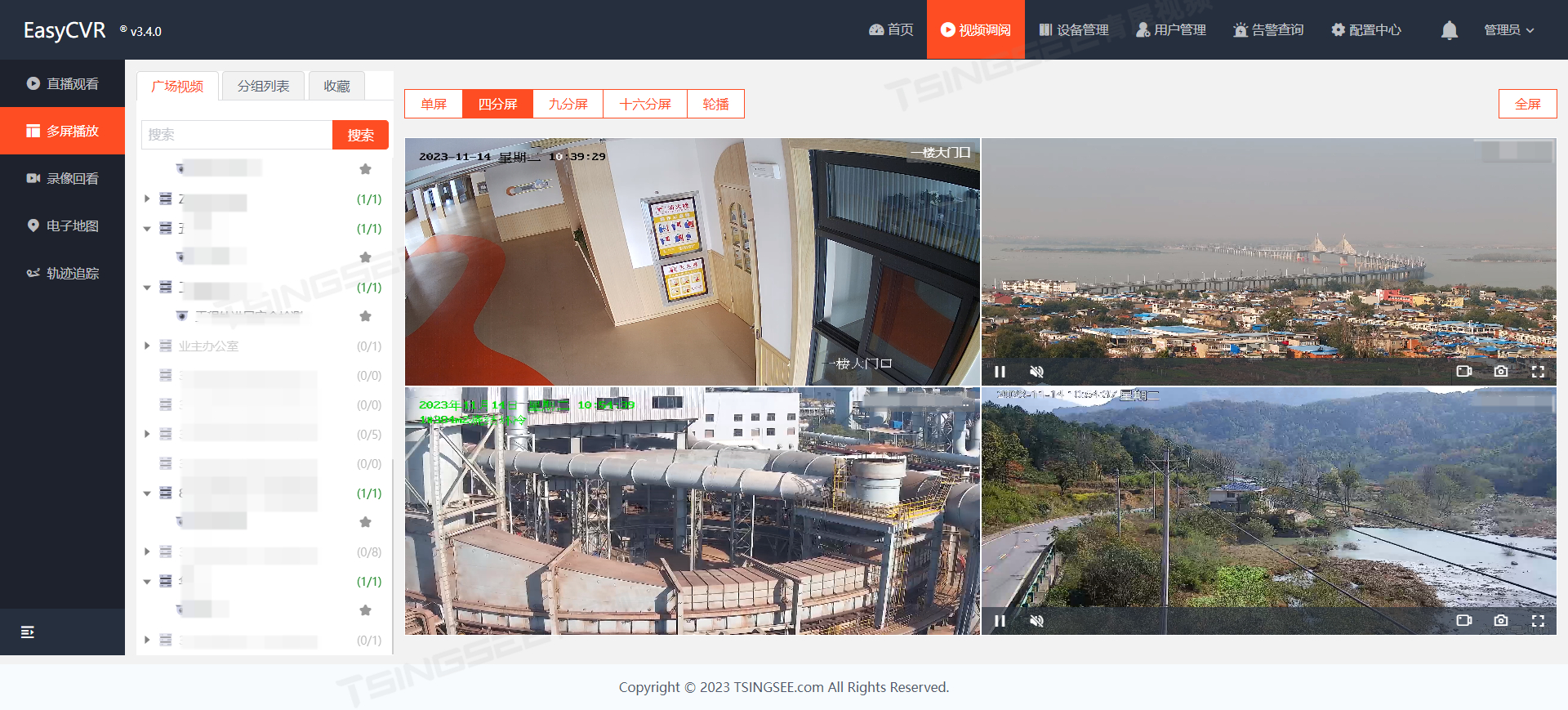
边缘计算有哪些常用场景?TSINGSEE边缘AI视频分析技术行业解决方案
随着ChatGPT生成式人工智能的爆发,AI技术在业界又掀起一波新浪潮。值得关注的是,边缘AI智能也在AI人工智能技术进步的基础上得到了快速发展。IDC跟踪报告数据显示,2021年我国的边缘计算服务器整体市场规模达到33.1亿美元,预计2020…...

配置BGP的基本示例
目录 BGP简介 BGP定义 配置BGP目的 受益 实验 实验拓扑 编辑 组网需求 配置思路 配置步骤 配置各接口所属的VLAN 配置各Vlanif的ip地址 配置IBGP连接 配置EBGP 查看BGP对等体的连接状态 配置SwitchA发布路由10.1.0.0/16 配置BGP引入直连路由 BGP简介 BGP定义 …...
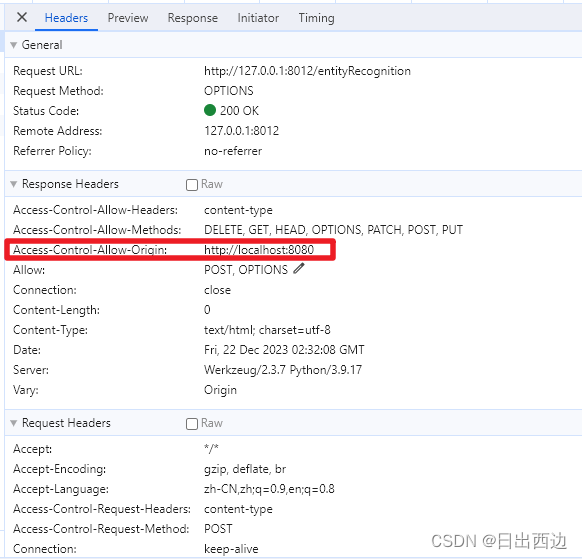
Flask解决接口跨域问题
1、什么是跨域CROS CORS(Cross-Origin Resource Sharing,跨域资源共享)是一种浏览器安全策略,用于控制在一个网页应用中如何让一个域的Web页面能够请求另一个域的资源。在Web开发中,由于同源策略(Same-Ori…...
数据恢复工具推荐!这3款堪称删除文件恢复大师!
“快看看我!经常都会莫名奇妙丢失各种电脑文件,但是又无法通过简单的方法找回重要的数据,有没有什么简单的操作可以帮助我快速恢复数据的呀?非常感谢!” 在我们的日常生活中,无论是工作还是学习,…...

论文笔记 | ICLR 2023 ReAct:通过整合推理和行动来增强语言模型
文章目录 一、前言二、主要内容三、总结🍉 CSDN 叶庭云:https://yetingyun.blog.csdn.net/ 一、前言 ICLR 2023 | Accept: notable-top-5%:《ReAct: Synergizing Reasoning and Acting in Language Models》 一句话总结:ReAct 方法在问答任务中通过提示大语言模型生成与任…...
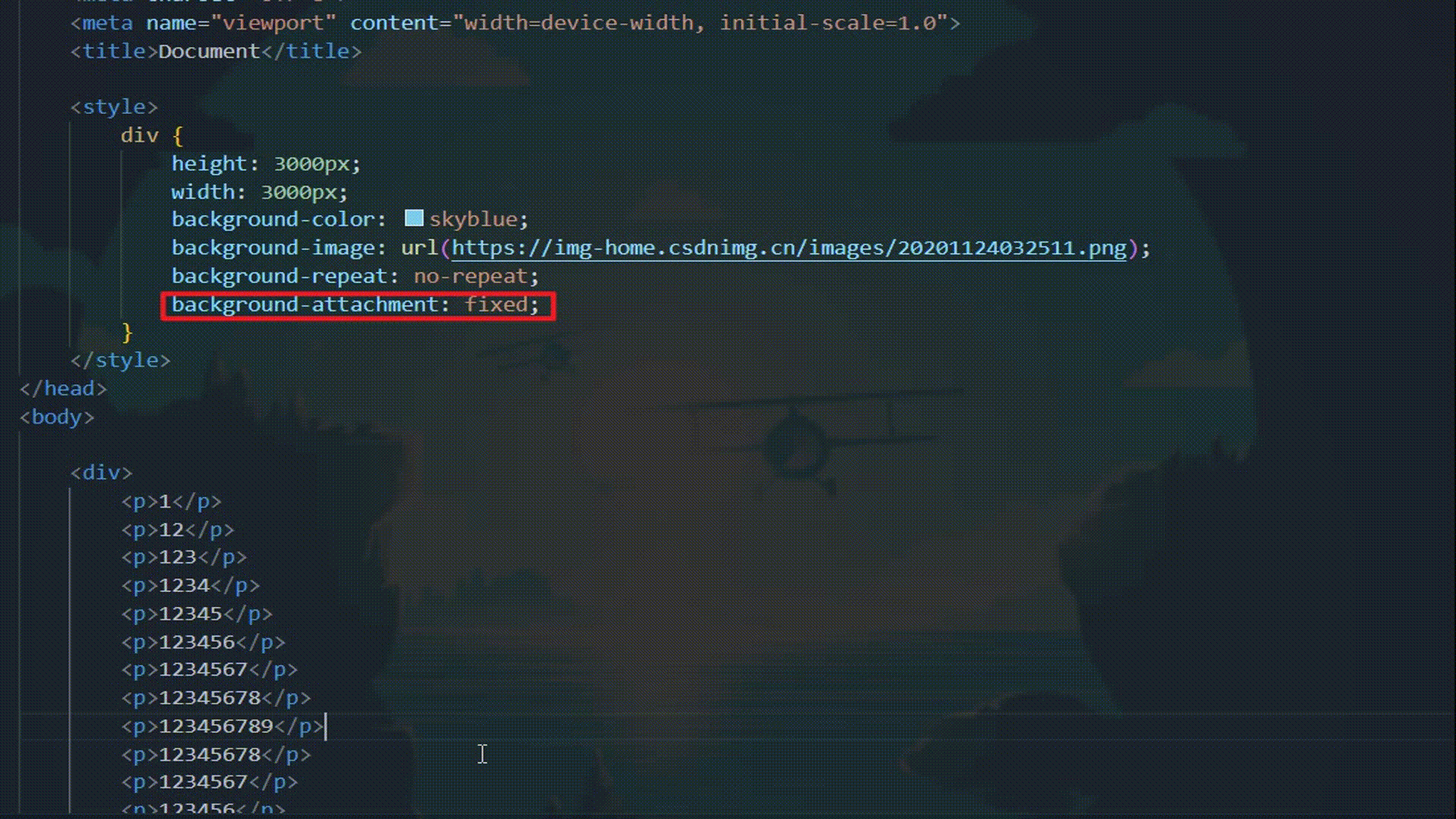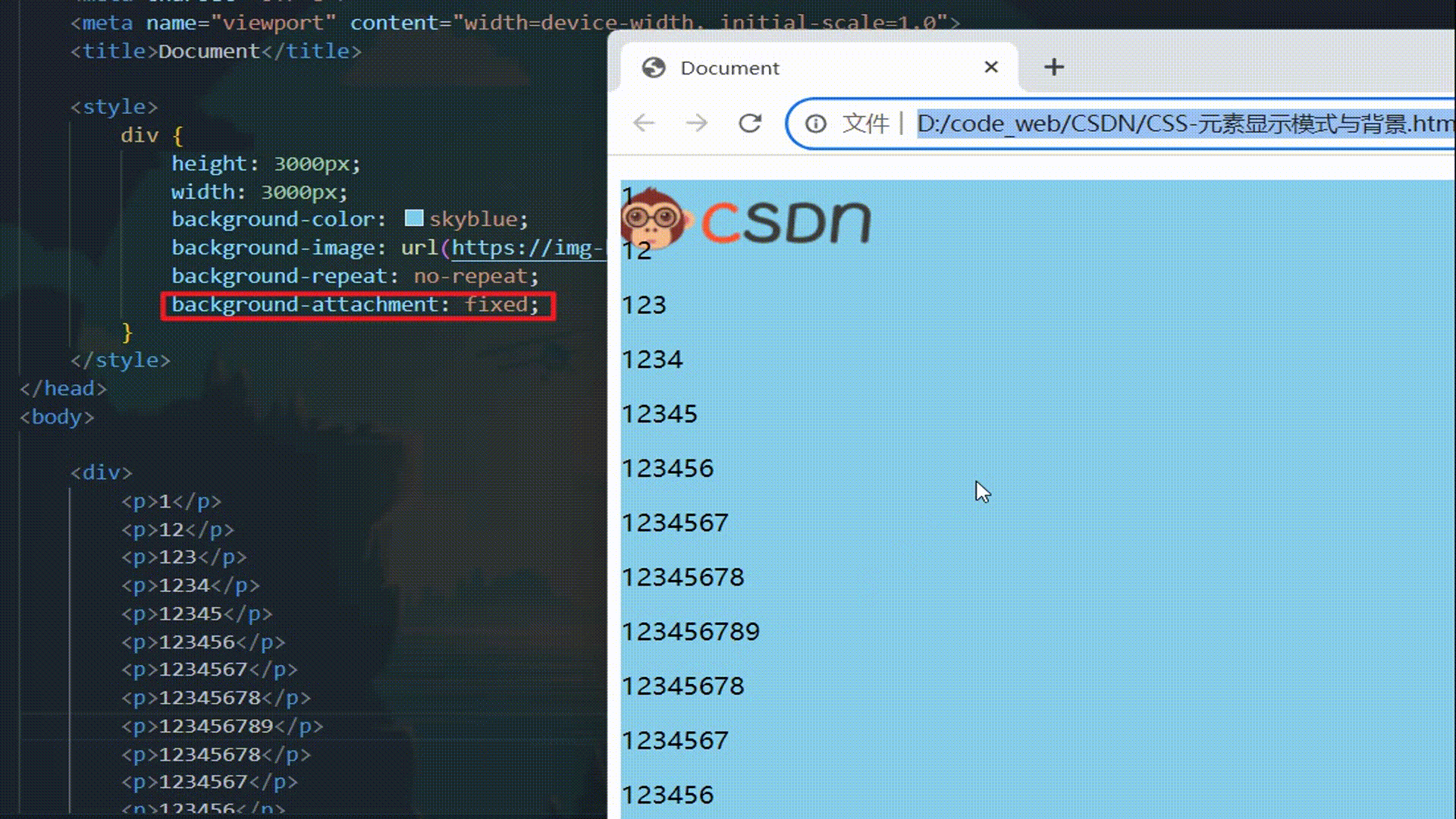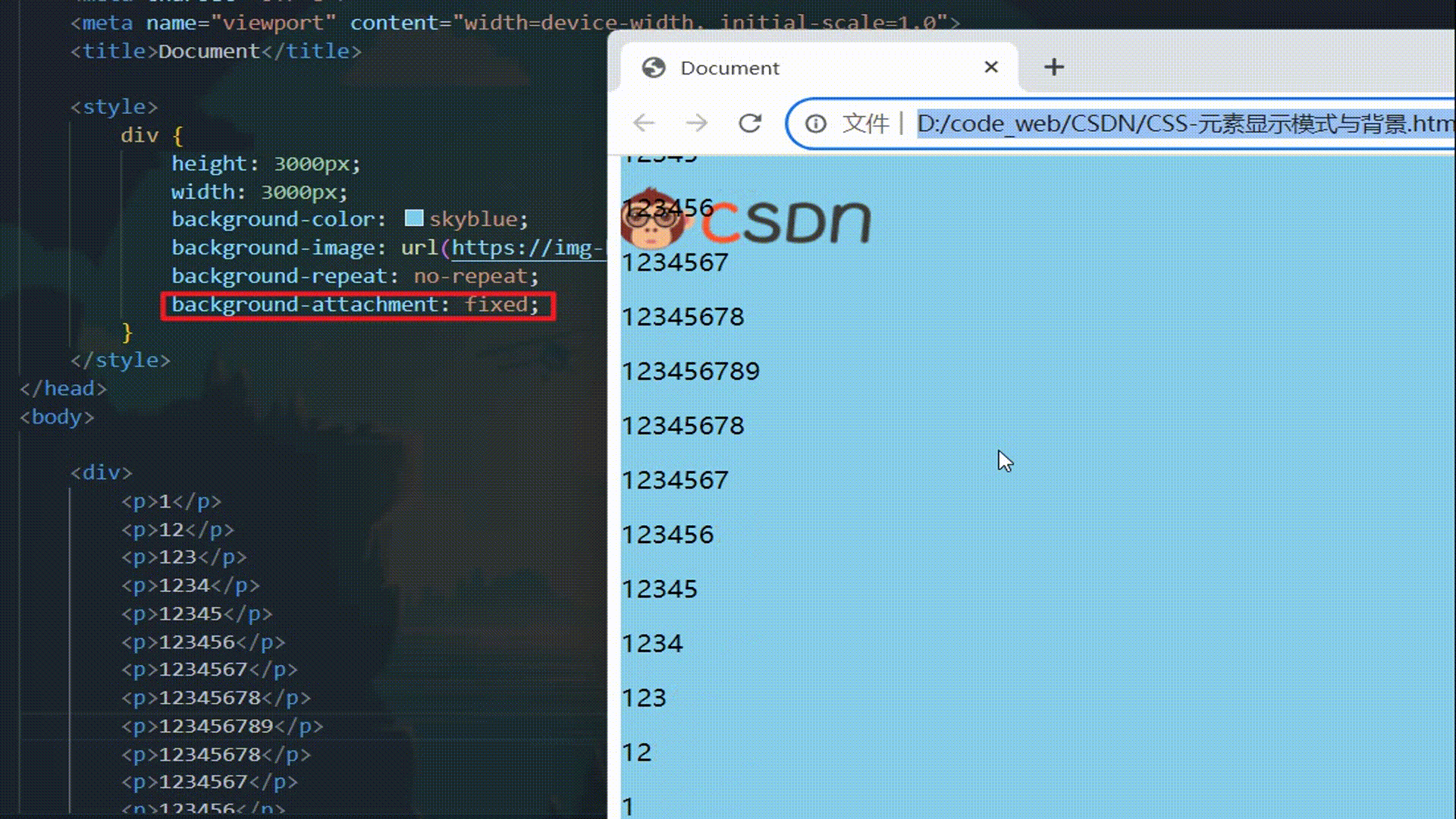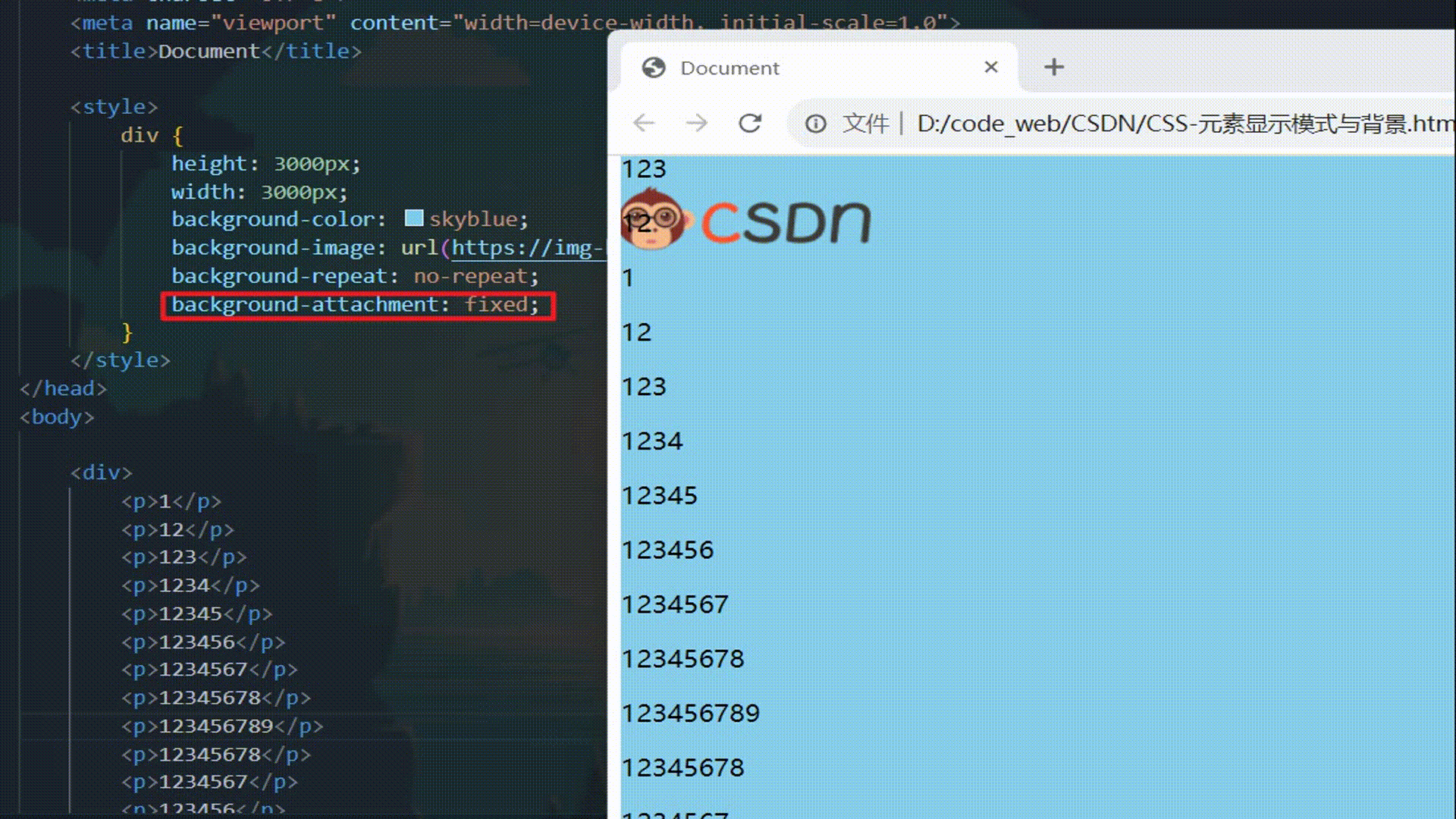
CSS:元素显示模式与背景
CSS:元素显示模式与背景 元素显示模式什么是元素显示模式块级元素 block行内元素 inline行内块元素 inline-block元素显示模式对比元素显示模式转换 display 背景背景颜色 background-color背景图片 background-image背景平铺 background-repeat背景图片位置 backgr…...

2026上位机开发技术栈全景:C#、Qt、Python谁才是你的最优解?
引言:上位机开发的黄金时代与技术抉择 在2026年的工业4.0浪潮中,上位机(Upper Computer)作为工业自动化系统的“大脑中枢”,正以前所未有的深度融入智能制造、能源管理、医疗设备和物联网(IoT)生…...

深入剖析PHP 7.4.21开发服务器源码泄露漏洞及其复现过程
1. PHP开发服务器源码泄露漏洞初探 最近在测试PHP 7.4.21开发服务器时,我发现一个挺有意思的漏洞——源码可以直接被读取。这可不是闹着玩的,想象一下你的网站源代码像裸奔一样暴露在外,数据库配置、加密逻辑全都一览无余。这个漏洞影响所有P…...

用Multisim 14.0和AD620/OP07,手把手教你搭建一个能用的简易心电放大电路
从零开始构建心电放大电路:Multisim 14.0与AD620/OP07实战指南 在生物医学信号处理领域,心电信号采集一直是极具挑战性的课题。想象一下,当医生将电极贴在你胸口时,那些微弱的电信号是如何被放大并转化为清晰波形图的?…...
)
别再混淆了!JavaScript与Java的10个本质区别(附常见面试题解析)
别再混淆了!JavaScript与Java的10个本质区别(附常见面试题解析) 当面试官问"Java和JavaScript有什么区别"时,超过60%的初级开发者会给出"它们就像汽车和地毯的关系"这类玩笑式回答。但真正理解这两种语言的核…...

避坑指南:OpenClaw对接nanobot镜像的3大常见错误与解决方法
避坑指南:OpenClaw对接nanobot镜像的3大常见错误与解决方法 1. 为什么需要这份避坑指南? 上周我在本地部署nanobot镜像时,原本以为半小时就能搞定的事情,硬是折腾了整整一个下午。这个超轻量级的OpenClaw镜像确实很吸引人——内…...

CRNN OCR文字识别镜像:开箱即用,轻松集成到你的项目中
CRNN OCR文字识别镜像:开箱即用,轻松集成到你的项目中 1. 项目概述 在现代数字化场景中,OCR(光学字符识别)技术已成为从图像中提取文本信息的关键工具。本镜像基于工业级CRNN(卷积循环神经网络࿰…...

PingFangSC字体实战指南:跨平台字体解决方案的最佳实践
PingFangSC字体实战指南:跨平台字体解决方案的最佳实践 【免费下载链接】PingFangSC PingFangSC字体包文件、苹果平方字体文件,包含ttf和woff2格式 项目地址: https://gitcode.com/gh_mirrors/pi/PingFangSC 行业痛点诊断 场景导入:设…...

企业级图片批量处理方案:InstructPix2Pix在电商修图中的落地实践
企业级图片批量处理方案:InstructPix2Pix在电商修图中的落地实践 1. 引言:电商修图的效率困局 想象一下,一家中型电商公司,每天要上新几百个商品。每个商品都需要一组高质量的主图、细节图、场景图。设计师团队忙得焦头烂额&…...
)
【Matlab】MATLAB教程:拟合效果评估(案例:计算R²、残差;应用:量化评估拟合质量)
MATLAB教程:拟合效果评估(案例:计算R、残差;应用:量化评估拟合质量) 在实验数据分析、工程建模、科研拟合等场景中,很多人完成曲线拟合后,仅凭肉眼观察曲线是否“贴近数据”就判断拟合效果好坏,这种方式极具主观性:看似平滑的曲线,可能存在较大隐性误差;看似贴合局…...

libtorrent会话管理终极指南:10个关键配置参数详解
libtorrent会话管理终极指南:10个关键配置参数详解 【免费下载链接】libtorrent an efficient feature complete C bittorrent implementation 项目地址: https://gitcode.com/gh_mirrors/li/libtorrent libtorrent是一个高效且功能完善的C BitTorrent实现&a…...