Flink系列之:Elasticsearch SQL 连接器
Flink系列之:Elasticsearch SQL 连接器
- 一、Elasticsearch SQL 连接器
- 二、创建 Elasticsearch表
- 三、连接器参数
- 四、Key 处理
- 五、动态索引
- 六、数据类型映射
一、Elasticsearch SQL 连接器
- Sink: Batch
- Sink: Streaming Append & Upsert Mode
- Elasticsearch 连接器允许将数据写入到 Elasticsearch 引擎的索引中。本文档描述运行 SQL 查询时如何设置 Elasticsearch 连接器。
- 连接器可以工作在 upsert 模式,使用 DDL 中定义的主键与外部系统交换 UPDATE/DELETE 消息。
- 如果 DDL 中没有定义主键,那么连接器只能工作在 append 模式,只能与外部系统交换 INSERT 消息。
二、创建 Elasticsearch表
以下示例展示了如何创建 Elasticsearch sink 表:
CREATE TABLE myUserTable (user_id STRING,user_name STRING,uv BIGINT,pv BIGINT,PRIMARY KEY (user_id) NOT ENFORCED
) WITH ('connector' = 'elasticsearch-7','hosts' = 'http://localhost:9200','index' = 'users'
);
三、连接器参数
| 参数 | 是否必选 | 默认值 | 数据类型 | 描述 |
|---|---|---|---|---|
| connector | 必选 | (none) | String | 指定要使用的连接器,有效值为:elasticsearch-6:连接到 Elasticsearch 6.x 的集群。elasticsearch-7:连接到 Elasticsearch 7.x 及更高版本的集群。 |
| hosts | 必选 | (none) | String | 要连接到的一台或多台 Elasticsearch 主机,例如 ‘http://host_name:9092;http://host_name:9093’。 |
| index | 必选 | (none) | String | Elasticsearch 中每条记录的索引。可以是一个静态索引(例如 ‘myIndex’)或一个动态索引(例如 'index-{log_ts |
| document-type | 6.x 版本中必选 | (none) | String | Elasticsearch 文档类型。在 elasticsearch-7 中不再需要。 |
| document-id.key-delimiter | 可选 | - | String | 复合键的分隔符(默认为"_“),例如,指定为” " 将导致文档 I D 为 " K E Y 1 "将导致文档 ID 为"KEY1 "将导致文档ID为"KEY1KEY2$KEY3"。 |
| username | 可选 | (none) | String | 用于连接 Elasticsearch 实例的用户名。请注意,Elasticsearch 没有预绑定安全特性,但你可以通过如下指南启用它来保护 Elasticsearch 集群。 |
| password | 可选 | (none) | String | 用于连接 Elasticsearch 实例的密码。如果配置了username,则此选项也必须配置为非空字符串。 |
| failure-handler | 可选 | fail | String | 对 Elasticsearch 请求失败情况下的失败处理策略。有效策略为:fail:如果请求失败并因此导致作业失败,则抛出异常。ignore:忽略失败并放弃请求。retry-rejected:重新添加由于队列容量饱和而失败的请求。自定义类名称:使用 ActionRequestFailureHandler 的子类进行失败处理。 |
| sink.delivery-guarantee | 可选 | AT_LEAST_ONCE | String | 承诺时可选择交付保证。有效值为:EXACTLY_ONCE:在故障转移情况下,记录也仅传递一次。AT_LEAST_ONCE:确保记录被传递,但可能会发生同一条记录被传递多次的情况。NONE:尽力提供记录。 |
| sink.flush-on-checkpoint | 可选 | true | Boolean | 在进行 checkpoint 时是否保证刷出缓冲区中的数据。如果关闭这一选项,在进行checkpoint时 sink 将不再为所有进行 中的请求等待 Elasticsearch 的执行完成确认。因此,在这种情况下 sink 将不对至少一次的请求的一致性提供任何保证。 |
| sink.bulk-flush.max-actions | 可选 | 1000 | Integer | 每个批量请求的最大缓冲操作数。 可以设置为’0’来禁用它。 |
| sink.bulk-flush.max-size | 可选 | 2mb | MemorySize | 每个批量请求的缓冲操作在内存中的最大值。单位必须为 MB。 可以设置为’0’来禁用它。 |
| sink.bulk-flush.interval | 可选 | 1s | Duration | flush 缓冲操作的间隔。 可以设置为’0’来禁用它。注意,'sink.bulk-flush.max-size’和’sink.bulk-flush.max-actions’都设置为’0’的这种 flush 间隔设置允许对缓冲操作进行完全异步处理。 |
| sink.bulk-flush.backoff.strategy | 可选 | DISABLED | String | 指定在由于临时请求错误导致任何 flush 操作失败时如何执行重试。有效策略为:DISABLED:不执行重试,即第一次请求错误后失败。CONSTANT:等待重试之间的回退延迟。EXPONENTIAL:先等待回退延迟,然后在重试之间指数递增。 |
| sink.bulk-flush.backoff.max-retries | 可选 | (none) | Integer | 最大回退重试次数。 |
| sink.bulk-flush.backoff.delay | 可选 | (none) | Duration | 每次退避尝试之间的延迟。对于 CONSTANT 退避策略,该值是每次重试之间的延迟。对于 EXPONENTIAL 退避策略,该值是初始的延迟。 |
| connection.path-prefix | 可选 | (none) | String | 添加到每个 REST 通信中的前缀字符串,例如,‘/v1’。 |
| connection.request-timeout | 可选 | (none) | Duration | 从连接管理器请求连接的超时时间。超时时间必须大于或者等于 0,如果设置为 0 则是无限超时。 |
| connection.timeout | 可选 | (none) | Duration | 建立请求的超时时间 。超时时间必须大于或者等于 0 ,如果设置为 0 则是无限超时。 |
| socket.timeout | 可选 | (none) | Duration | 等待数据的 socket 的超时时间 (SO_TIMEOUT)。超时时间必须大于或者等于 0,如果设置为 0 则是无限超时。 |
| format | 可选 | json | String | Elasticsearch 连接器支持指定格式。该格式必须生成一个有效的 json 文档。 默认使用内置的 ‘json’ 格式。 |
四、Key 处理
- Elasticsearch sink 可以根据是否定义了一个主键来确定是在 upsert 模式还是 append 模式下工作。 如果定义了主键,Elasticsearch sink 将以 upsert 模式工作,该模式可以消费包含 UPDATE/DELETE 消息的查询。 如果未定义主键,Elasticsearch sink 将以 append 模式工作,该模式只能消费包含 INSERT 消息的查询。
- 在 Elasticsearch 连接器中,主键用于计算 Elasticsearch 的文档 id,文档 id 为最多 512 字节且不包含空格的字符串。 Elasticsearch 连接器通过使用 document-id.key-delimiter 指定的键分隔符按照 DDL 中定义的顺序连接所有主键字段,为每一行记录生成一个文档 ID 字符串。 某些类型不允许作为主键字段,因为它们没有对应的字符串表示形式,例如,BYTES,ROW,ARRAY,MAP 等。 如果未指定主键,Elasticsearch 将自动生成文档 id。
五、动态索引
- Elasticsearch sink 同时支持静态索引和动态索引。
- 如果你想使用静态索引,则 index 选项值应为纯字符串,例如 ‘myusers’,所有记录都将被写入到 “myusers” 索引中。
- 如果你想使用动态索引,你可以使用 {field_name} 来引用记录中的字段值来动态生成目标索引。 你也可以使用 ‘{field_name|date_format_string}’ 将 TIMESTAMP/DATE/TIME 类型的字段值转换为 date_format_string 指定的格式。 date_format_string 与 Java 的 DateTimeFormatter 兼容。 例如,如果选项值设置为 ‘myusers-{log_ts|yyyy-MM-dd}’,则 log_ts 字段值为 2020-03-27 12:25:55 的记录将被写入到 “myusers-2020-03-27” 索引中。
- 你也可以使用 ‘{now()|date_format_string}’ 将当前的系统时间转换为 date_format_string 指定的格式。now() 对应的时间类型是 TIMESTAMP_WITH_LTZ 。 在将系统时间格式化为字符串时会使用 session 中通过 table.local-time-zone 中配置的时区。 使用 NOW(), now(), CURRENT_TIMESTAMP, current_timestamp 均可以。
- 注意: 使用当前系统时间生成的动态索引时, 对于 changelog 的流,无法保证同一主键对应的记录能产生相同的索引名, 因此使用基于系统时间的动态索引,只能支持 append only 的流。
六、数据类型映射
Elasticsearch 将文档存储在 JSON 字符串中。因此数据类型映射介于 Flink 数据类型和 JSON 数据类型之间。 Flink 为 Elasticsearch 连接器使用内置的 ‘json’ 格式。
下表列出了 Flink 中的数据类型与 JSON 中的数据类型的映射关系。
| Flink SQL类型 | JSON类型 |
|---|---|
| CHAR/VARCHAR/STRING | string |
| BOOLEAN | boolean |
| BINARY/VARBINARY | string with encoding: base64 |
| DECIMAL | number |
| TINYINT | number |
| SMALLINT | number |
| INT | number |
| BIGINT | number |
| FLOAT | number |
| DOUBLE | number |
| DATE | string with format: date |
| TIME | string with format: time |
| TIMESTAMP | string with format: date-time |
| TIMESTAMP_WITH_LOCAL_TIME_ZONE | string with format: date-time (with UTC time zone) |
| INTERVAL | number |
| ARRAY | array |
| MAP / MULTISET | object |
| ROW | object |
相关文章:

Flink系列之:Elasticsearch SQL 连接器
Flink系列之:Elasticsearch SQL 连接器 一、Elasticsearch SQL 连接器二、创建 Elasticsearch表三、连接器参数四、Key 处理五、动态索引六、数据类型映射 一、Elasticsearch SQL 连接器 Sink: BatchSink: Streaming Append & Upsert ModeElasticsearch 连接器…...

java中将Map集合、对象、字符串转换为JSON对象
1、Map集合转JSON对象 创建一个Map集合; 新建json对象,并将Map引入json中。 public void demo1(){ //创建一个Map集合Map<String, String> map new HashMap<>();map.put("1729210001","zhangsan");map.put("17292…...
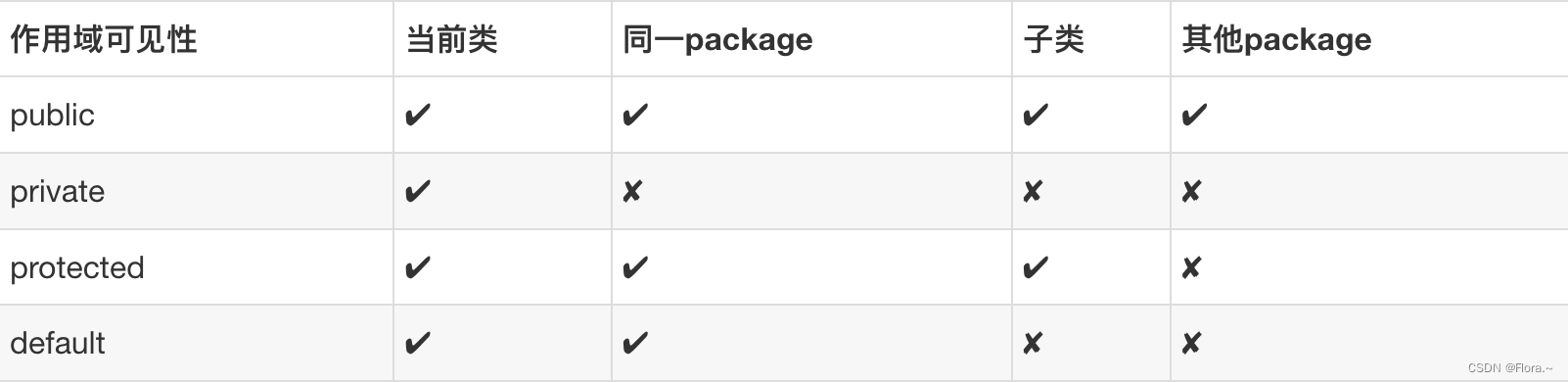
理解Spring中bean的作用域
singleton:Spring Ioc容器中只会存在一个共享的Bean实例,无论有多少个Bean引用它,始终指向同一个对象,作用域为Spring中的缺省(同一package)作用域 prototype:每次通过Spring容器获取prototype定义的bean时,…...

edge中以右键“打印”的方式“保存”当前页面的pdf形式,下载过程中卡进度的问题
目录 问题描述: 可能的问题: 解决: 问题描述: 特殊情况下需要保存网页的pdf形式,但页面没有类似“导出pdf”的功能按钮,可以通过页面右键“打印”的方式“保存”当前页面的pdf形式。在pdf文件下载过程中出…...

c# 使用OpenCV
C#和OpenCV的结合主要通过一个名为OpenCVSharp的库实现。OpenCVSharp是一个C#包装器,它提供了对OpenCV(一个开源的计算机视觉和机器学习库)功能的访问。 安装OpenCVSharp NuGet包: 在Visual Studio中,右键点击你的项目…...

数据库连接问题 - ChatGPT对自身的定位
1.一段关于数据库连接的技术性对话 sweetie,连接数据库的时候,需要在每次读写数据后就把连接释放吗? 亲爱的,连接数据库后,通常会在每次读写数据后将连接释放。这是为了确保数据库连接的及时释放和有效管理。如果不及…...
常见可视化大屏编辑器有哪些?
前言: 在当今数字化时代,可视化大屏编辑器成为了数据展示和决策支持的重要工具。大屏编辑器不仅仅是数据的呈现,更是数据背后的故事的讲述者。它通过图表、图形和实时数据的呈现,为用户提供了全面的信息视图,帮助用户更…...

利用ffmpeg cv2取h265码流视频(转换图片灰屏问题解决)
利用海康威视相机拍出来的视频是H265格式的,相比于常规的H264编码,压缩率更高,但因此如果直接用正常取流方法读取,会出现无法读取的情况 1. 如图h265码流取出图片为灰屏 2 、解决灰屏问题 import subprocess import cv2# 将h265流…...

Android Uri scheme协议file转content
一、Uri的介绍 在Android开发中,Uri(Uniform Resource Identifier)是用于标识和访问各种资源的核心概念。这些资源可能包括文件、网络URL、数据库记录等。在处理这些资源时,我们可能会遇到不同的Uri协议,如file和conte…...
【Jenkins】远程API接口:Java 包装接口使用示例
jenkins-rest 库是一个面向对象的 Java 项目,它通过编程方式提供对 Jenkins REST API 的访问,以访问 Jenkins 提供的一些远程 API。它使用 jclouds 工具包构建,可以轻松扩展以支持更多 REST 端点。其功能集不断发展,用户可以通过拉…...

未能加载工具箱项问题的解决
解决办法是项目属性要设置成any cpu 在解决方案里的所有项目上右键,属性,生成,看目标平台是不是都设置成了any cpu...

算法模板之栈图文详解
🌈个人主页:聆风吟 🔥系列专栏:算法模板、数据结构 🔖少年有梦不应止于心动,更要付诸行动。 文章目录 📋前言一. ⛳️模拟栈1.1 🔔用数组模拟实现栈1.1.1 👻栈的定义1.1.…...
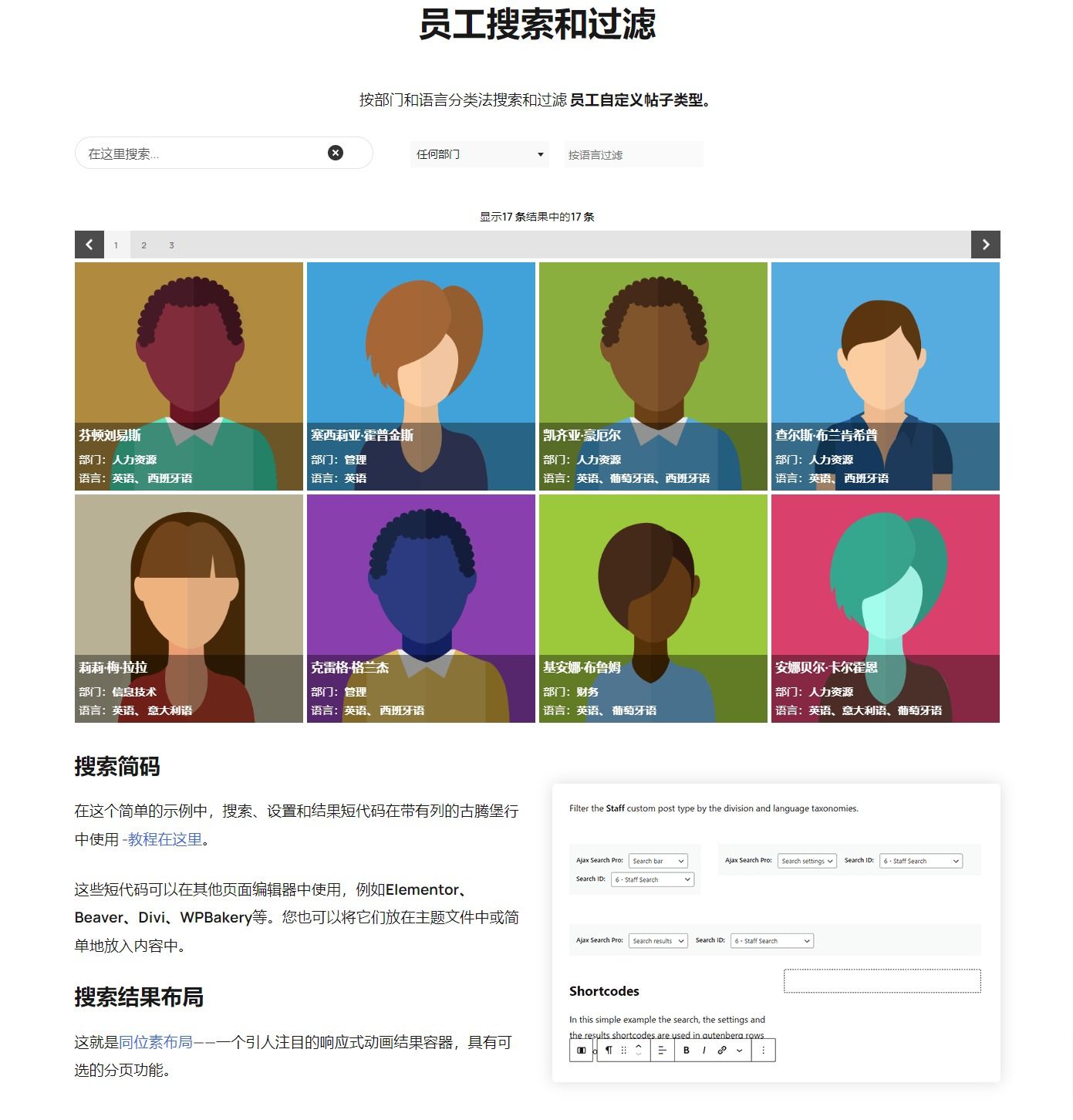
Ajax Search Pro Live WordPress网站内容实时搜索插件
点击阅读Ajax Search Pro Live WordPress网站内容实时搜索插件原文 Ajax Search Pro Live WordPress网站内容实时搜索插件是 WordPress 最好的实时搜索引擎插件。高度可定制,具有许多功能和选项,可提供最佳结果!用更美观、更高效的搜索引擎替…...
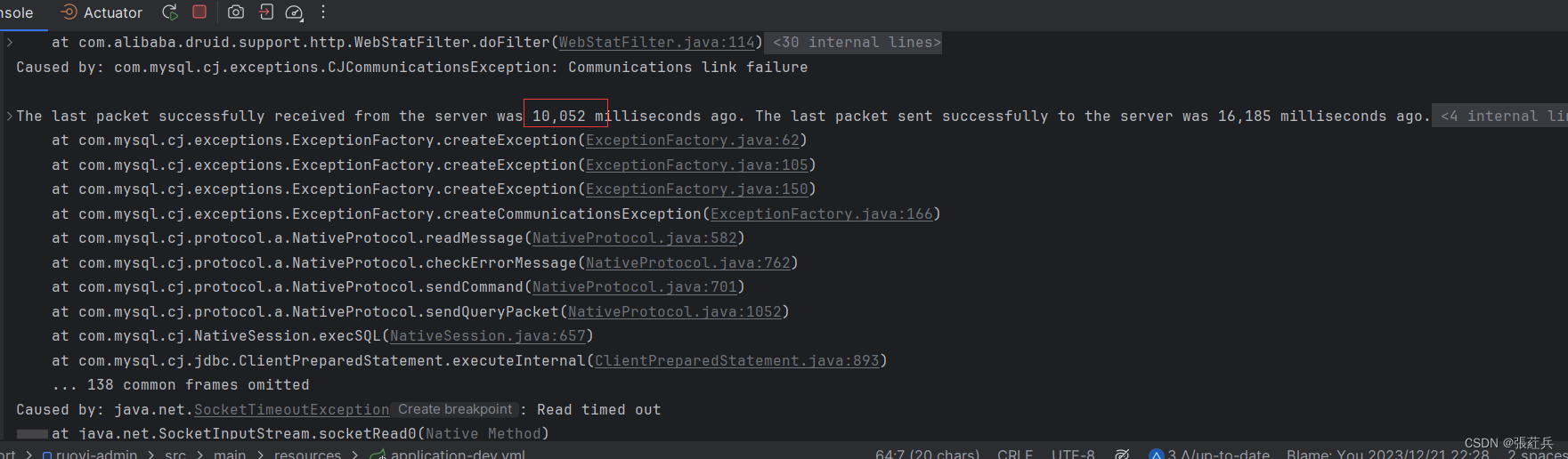
mysql SQL执行超时问题
show variables like max_execution_time 使用这个命令查看了,没有设置sql执行超时时间,那么大概率问题就出在阿里的Druid数据库连接池出了问题 尝试着socketTimeout由60000毫秒改成10000毫秒,果然执行了十几秒就超时报错了 socketTime…...

51单片机基于时间片轮转的简单rtos
早就想写写这个了,正好赶上有点时间,写了一下基于51单片机的时间片轮转调度系统,简单的rtos,呵呵。直接上代码。 //基于51单片机时间片轮转的简单rtos。 #include"reg52.h" sbit led1 P2^7; sbit led2 P2^0; sbit key…...

python pycurl 安装使用
python pycurl 安装使用 本文主要讲下pycurl 安装使用. 1.安装 首先使用 pip 命令安装. pip install pycurl 输出如下: Collecting pycurlUsing cached pycurl-7.45.2.tar.gz (234 kB)ERROR: Command errored out with exit status 1:command: /usr/bin/python3 -c impor…...
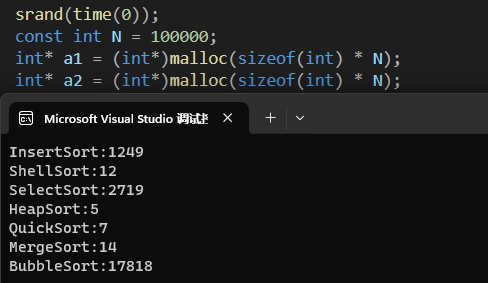
C语言数据结构-排序
文章目录 1 排序的概念及运用1.1 排序的概念1.2 排序的应用 2 插入排序2.1 直接插入排序2.2 希尔排序2.3 直接排序和希尔排序对比 3 选择排序3.1 堆排序3.2 直接选择排序 4 交换排序4.1 冒泡排序4.2 快速排序4.2.1 挖坑法14.2.2 挖坑法24.2.3 挖坑法3 5 并归排序6 十万级别数据…...
Spring AOP入门指南:轻松掌握面向切面编程的基础知识
面向切面编程 1,AOP简介1.1 什么是AOP?1.2 AOP作用1.3 AOP核心概念 2,AOP入门案例2.1 需求分析2.2 思路分析2.3 环境准备2.4 AOP实现步骤步骤1:添加依赖步骤2:定义接口与实现类步骤3:定义通知类和通知步骤4:定义切入点步骤5:制作切面步骤6:将通知类配给…...

【顶级快刊】IEEE(Trans),审稿快仅2个月录用,入选CCF-B,现在投最快!
计算机类 • 好刊解读 今天小编带来IEEE旗下计算机领域顶刊,顶级快刊,CCF-B类推荐,如您有投稿需求,可作为重点关注!后文有相关领域真实发表案例,供您投稿参考~ 01 期刊简介 IEEE Transactions on Affect…...

深入浅出堆排序: 高效算法背后的原理与性能
🎬 鸽芷咕:个人主页 🔥 个人专栏: 《linux深造日志》 《高效算法》 ⛺️生活的理想,就是为了理想的生活! 📋 前言 🌈堆排序一个基于二叉堆数据结构的排序算法,其稳定性和排序效率在八大排序中也…...

2026年5月14隔夜暗盘挂单排行榜
推荐好文:每年节约五六千交易费不香吗如何获取龙虎榜是否有量化参与如何获取股东减持信息大A有5400多只股票, 这里面只有不到10%, 约500只由资金投票, 剩余的都是杂毛, 炒股看龙头找主线. 从隔夜挂单里选择, 再叠加我们之前分享的如何判断是否有大股东减持, 是否有融资融券参与…...

基础教程通过Taotoken CLI一键配置开发环境与API密钥
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 基础教程:通过Taotoken CLI一键配置开发环境与API密钥 对于开发团队而言,让新成员快速、统一地接入大模型服…...

从EGO-Planner到集群协同:分布式轨迹优化在无人机编队中的应用
1. 项目概述:从单机到集群的自主飞行进化如果你玩过无人机,或者关注过机器人领域,大概会知道让一台机器在空中自主规划路径、避开障碍物已经是个不小的挑战。那么,想象一下,让一群无人机像鸟群一样,在复杂、…...

树莓派Pico W到手后,除了Wi-Fi,这几点硬件细节和Pico真不一样
树莓派Pico W硬件深度解析:超越Wi-Fi的工程细节 当我第一次拿到树莓派Pico W时,表面看起来它只是Pico的无线版本——同样的RP2040芯片、相似的引脚布局和几乎一致的尺寸。但当我开始实际项目开发时,才发现这些"看似相同"背后隐藏着…...

当比你资历浅的人成了你的上级,技术人的心态调整指南
阶段一:缺陷定位——从审视“测试用例”开始当问题出现时,优秀的测试工程师不会立刻指责开发,而是先检查自己的测试环境、数据和步骤。面对年轻领导的晋升,我们同样需要运用这套严谨的思维,进行一次彻底的“根因分析”…...

开源APM探针bee-apm:无侵入式Java应用性能监控与链路追踪实战
1. 项目概述:从“蜜蜂”视角重新审视应用性能在分布式系统和微服务架构成为主流的今天,一个用户请求的背后,可能串联着十几个甚至几十个不同的服务。当线上出现一个性能瓶颈或一个诡异的错误时,定位问题的过程就像在漆黑的迷宫里寻…...

spoof 与网络安全:如何利用 MAC 地址伪造增强企业安全防护
spoof 与网络安全:如何利用 MAC 地址伪造增强企业安全防护 【免费下载链接】spoof Easily spoof your MAC address in macOS, Windows, & Linux! 项目地址: https://gitcode.com/gh_mirrors/sp/spoof 在当今数字化时代,网络安全已成为企业运营…...

基于Gemini CLI的深度研究工具:命令行AI助手的架构与实战
1. 项目概述:当命令行遇上深度研究如果你和我一样,是个常年泡在终端里的开发者或研究者,那么“allenhutchison/gemini-cli-deep-research”这个项目标题,光是扫一眼,就能让人心跳加速。它精准地戳中了我们这类人的两个…...

职得Offer校园求职助手Pro深度评测:一个AI Agent陪你跑完求职全流程
一、 职得Offer是什么?—— 不止是工具,更是全程陪伴的AI求职伙伴 在AI应用爆发的今天,面对市面上众多的简历模板、面经题库和招聘平台,求职者尤其是学生群体,依然会陷入“信息过载却无从下手”的困境。“职得Offer校…...

开源、有文档、能上线的 .NET + Vue 通用权限系统
前言在日常项目开发中,权限管理几乎是每个系统都绕不开的基础模块。从用户登录、菜单控制到数据隔离,一套稳定、灵活、可扩展的权限体系,往往决定了整个项目的成败。然而,从零开始搭建这样的平台,不仅耗时耗力…...