Keras使用sklearn中的交叉验证和网格搜索
Keras是Python在深度学习领域非常受欢迎的第三方库,但Keras的侧重点是深度学习,而不是所以的机器学习。事实上,Keras力求极简主义,只专注于快速、简单地定义和构建深度学习模型所需要的内容。Python中的scikit-learn是非常受欢迎的机器学习库,它基于Scipy,用于高效的数值计算。scikit-learn是一个功能齐全的通用机器学习库,并提供了许多在开发深度学习过程中非常有帮助的方法。例如scikit-learn提供了很多用于选择模型和对模型调参的方法,这些方法同样适用于深度学习。
Keras提供了一个Wrapper,将Keras的深度学习模型包装成scikit-learn中的分类模型或回归模型,以便于使用scikit-learn中的方法和函数。对于深度学习模型的包装是通过KerasClassifier(分类模型)和KerasRegressor(回归模型)来实现的。KerasClassifier和KerasRegressor类使用参数build_fn,指定用来创建模型的函数的名称。
Keras的一般构建流程:
model = Sequential() # 定义模型
model.add(Dense(units=64, activation='relu', input_dim=100)) # 定义网络结构
#第一层网络:输出尺寸64,输入尺寸100,activation激活函数relu
model.add(Dense(units=10, activation='softmax')) # 定义网络结构
#第二层网络:输出尺寸10,输入是上一层的输出尺寸64,activation激活函数softmax
model.compile(loss='categorical_crossentropy', # 定义loss函数、优化方法、评估标准optimizer='sgd',metrics=['accuracy'])
#输入训练样本和标签,迭代5次,每次迭代32个数据
model.fit(x_train, y_train, epochs=5, batch_size=32) # 训练模型
loss_and_metrics = model.evaluate(x_test, y_test, batch_size=128) # 评估模型
classes = model.predict(x_test, batch_size=128) # 使用训练好的数据进行预测参数意义:
keras.layers.Dense(units, activation=None, use_bias=True, kernel_initializer='glorot_uniform', bias_initializer='zeros', kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, bias_constraint=None)
units: 正整数,输出空间维度。
activation: 激活函数。 若不指定,则不使用激活函数 (即,「线性」激活: a(x) = x)。
use_bias: 布尔值,该层是否使用偏置向量。
kernel_initializer: kernel 权值矩阵的初始化器。
bias_initializer: 偏置向量的初始化器。
kernel_regularizer: 运用到 kernel 权值矩阵的正则化函数 。
bias_regularizer: 运用到偏置向的的正则化函数 。
activity_regularizer: 运用到层的输出的正则化函数 。
kernel_constraint: 运用到 kernel 权值矩阵的约束函数 。
bias_constraint: 运用到偏置向量的约束函数。
Keras调用scikit-learn实现交叉验证:
from keras.models import Sequential
from keras.layers import Dense
import numpy as np
import pandas as pd
from sklearn.model_selection import cross_val_score, KFold
from keras.wrappers.scikit_learn import KerasClassifierdef creat_model():# 构建模型model = Sequential()model.add(Dense(units=12, input_dim=11, activation='relu'))model.add(Dense(units=8, activation='relu'))model.add(Dense(units=1, activation='sigmoid'))# 模型编译model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])return model# 导入数据
data = pd.read_csv('data.csv',encoding='gbk')# 删除id列
data.drop('客户编号',axis=1,inplace=True)X, Y = data.values[:,:-1], data.values[:,-1] # Keras调用sklearn
model = KerasClassifier(build_fn=creat_model, epochs=150, batch_size=10, verbose=0)# 10折交叉验证
kfold = KFold(n_splits=10, shuffle=True, random_state=10)
result = cross_val_score(model, X, Y, cv=kfold)Keras调用scikit-learn实现模型调参
在构建深度学习模型时,如何配置一个最优模型一直是进行一个项目的重点。在机器学习中,可以通过算法自动调优这些配置参数,在这里将通过Keras的包装类,借助scikit-learn的网格搜索算法评估神经网络模型的不同配置,并找到最佳评估性能的参数组合。creat_model()函数被定义为具有两个默认值的参数(optimizer和init)的函数,创建模型后,定义要搜索的参数的数值数组,包括优化器(optimizer)、权重初始化方案(init)、epochs和batch_size。
在scikit-learn中的GridSearchCV需要一个字典类型的字段作为需要调整的参数,默认采用3折交叉验证来评估算法,由于4个参数需要进行调参,因此将会产生4✖️3个模型。
Keras调用scikit-learn实现GridSearchCV网格搜索:
from keras.models import Sequential
from keras.layers import Dense
import numpy as np
import pandas as pd
from sklearn.model_selection import GridSearchCV
from keras.wrappers.scikit_learn import KerasClassifierdef creat_model(optimizer='adam,init='glorot_uniform'):# 构建模型model = Sequential()model.add(Dense(units=12, input_dim=11,kernel_initializer=init, activation='relu'))model.add(Dense(units=8, kernel_initializer=init, activation='relu'))model.add(Dense(units=1, kernel_initializer=init, activation='sigmoid'))# 模型编译model.compile(loss='binary_crossentropy', optimizer=optimizer, metrics=['accuracy'])return model# 导入数据
data = pd.read_csv('data.csv',encoding='gbk')# 删除id列
data.drop('客户编号',axis=1,inplace=True)X, Y = data.values[:,:-1], data.values[:,-1] # Keras调用sklearn
model = KerasClassifier(build_fn=creat_model, verbose=0)# 构建需要调整的参数
param_gird = {}
param_grid['optimizer'] = ['rmsprop','adam']
param_grid['init'] = ['glorot_uniform', 'normal', 'uniform']
param_gird['epochs'] = [50, 100, 150, 200]
param_gird['batch_size'] = [5, 10, 20]# 调参
grid = GridSearchCV(estimator=model, param_gird=param_grid)
result = grid.fit(X, Y)# 输出结果
print('Best: %f using %s' % (result.best_score_, result.best_params_))关于Epochs和batch_size的解释?
Epochs是神经网络训练过程中的一个重要超参数,定义为向前和向后传播中所有批次的单次训练迭代。简单说,一个Epoch是将所有的数据输入网络完成一次向前计算及反向传播。在训练过程中,数据会被“轮”多少次,即应当完整遍历数据集多少次(一次为一个Epoch)。如果Epoch数量太少,网络有可能发生欠拟合(即对于定型数据的学习不够充分);如果Epoch数量太多,则有可能发生过拟合(即网络对定型数据中的“噪声”而非信号拟合)。所以,选择适当的Epoch数量需要在充分训练和避免过拟合之间找到平衡。
假设我们有1000个数据样本,每次我们送入10个数据进行训练(也就是batch_size为10)。那么完成一个Epoch,我们需要进行100次迭代(也就是100次前向传播和100次反向传播)。具体来说,我们需要将所有的数据都送入神经网络进行一次前向传播和反向传播,所以一次Epoch相当于所有数据集/batch size=N次迭代。
相关文章:

Keras使用sklearn中的交叉验证和网格搜索
Keras是Python在深度学习领域非常受欢迎的第三方库,但Keras的侧重点是深度学习,而不是所以的机器学习。事实上,Keras力求极简主义,只专注于快速、简单地定义和构建深度学习模型所需要的内容。Python中的scikit-learn是非常受欢迎的…...

docker--Prometheus、Grafana、node_exporter的安装配置及Springboot集成Prometheus示例
1. 安装Prometheus Prometheus一个系统和服务监控系统。它以给定的时间间隔从配置的目标收集指标,计算规则表达式,显示结果,并在观察到某些条件为真时触发警报。 可观察性侧重于根据系统产生的数据了解系统的内部状态,这有助于确定基础设施是否健康。Prometheus是用于监视…...
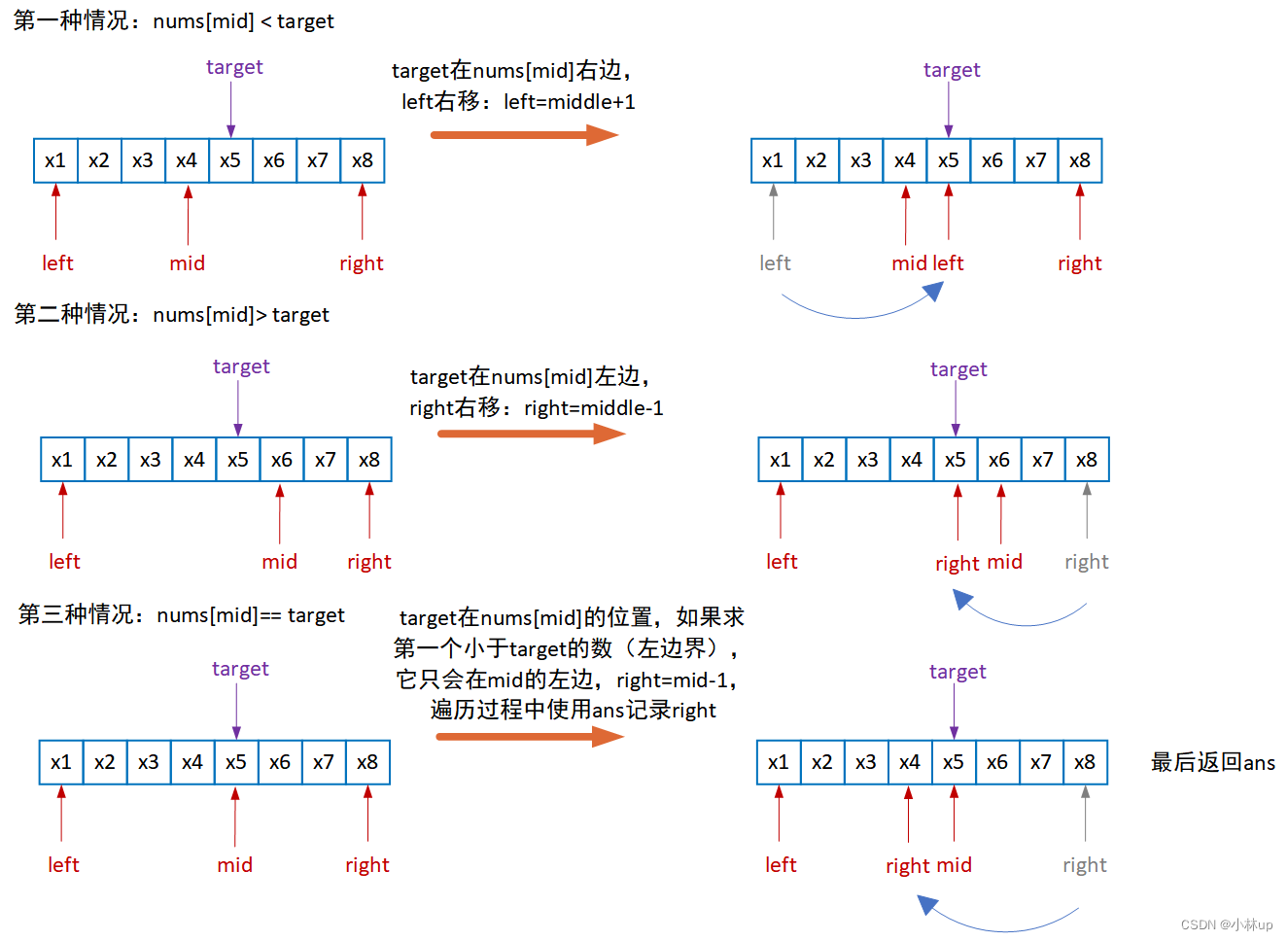
数据结构和算法笔记2:二分法
二分法网上有两种写法,一种左闭右闭,一种左闭右开,个人习惯左闭右闭的写法, 有序数组查找数 这是标准二分法,对应力扣的704. 二分查找: 求值为target的索引 int search(vector<int>& nums, i…...
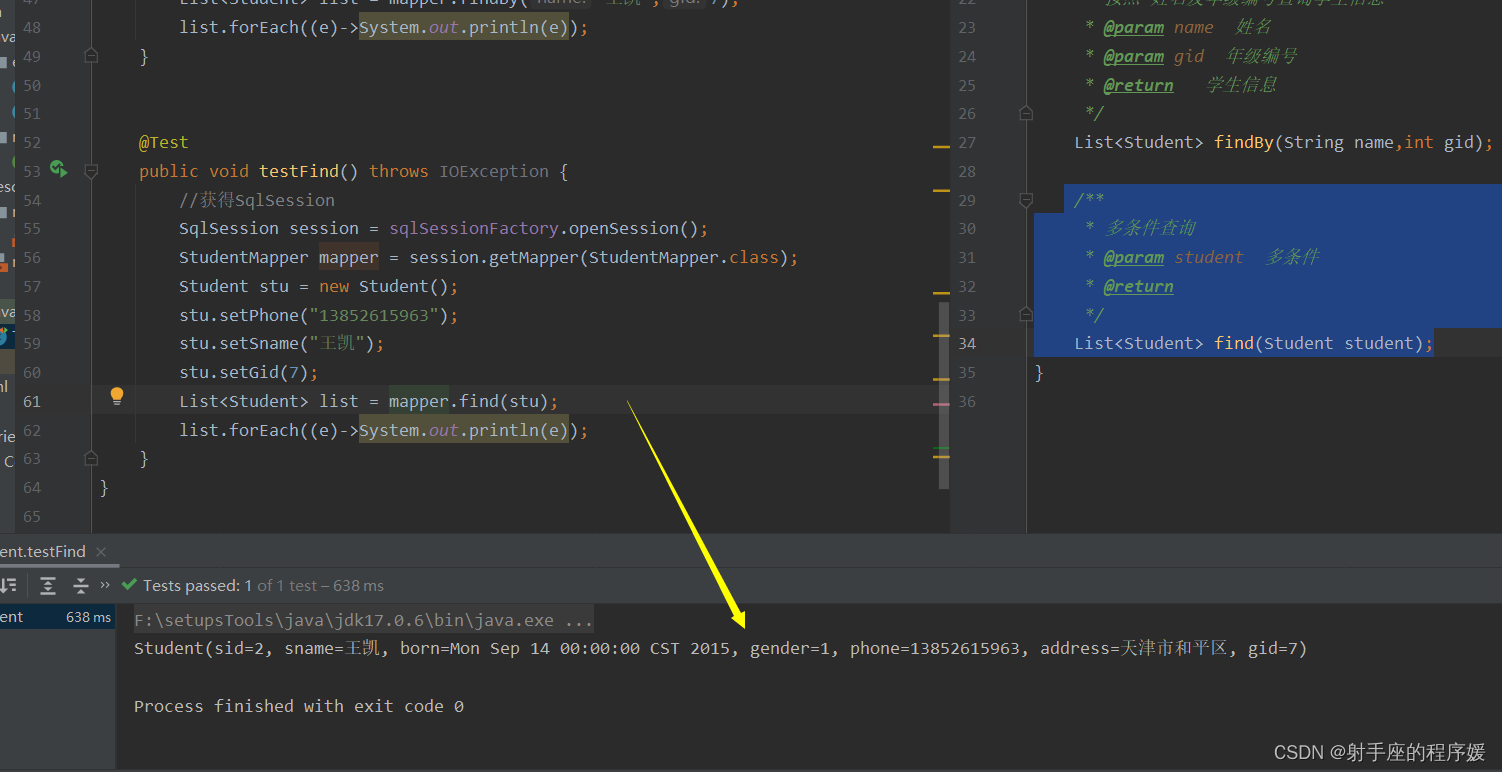
Mybatis3系列课程8-带参数查询
简介 上节课内容中讲解了查询全部, 不需要带条件查, 这节我们讲讲 带条件查询 目标 1. 带一个条件查询-基本数据类型 2.带两个条件查询-连个基本数据类型 3.带一个对象类型查询 为了实现目标, 我们要实现 按照主键 查询某个学生信息, 按照姓名和年级编号查询学生信息 按照学生…...
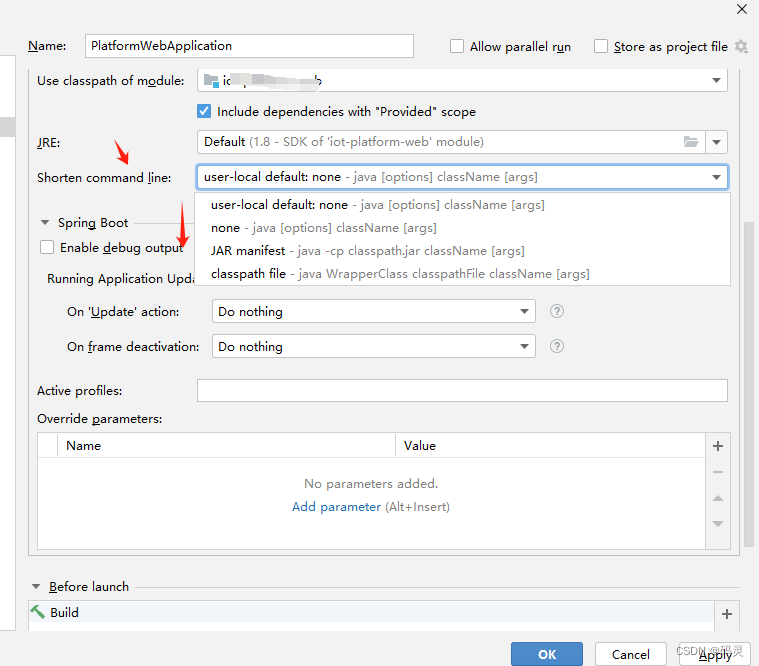
IDEA shorten command line介绍和JAR manifest 导致mybatis找不到接口类处理
如果类路径太长,或者有许多VM参数,程序就无法启动。原因是大多数操作系统都有命令行长度限制。在这种情况下,IntelliJIDEA将试图缩短类路径。最好选中 classpath file模式。 shorten command line 选项提供三种选项缩短类路径。 none&#x…...

泽攸科技SEM台式扫描电子显微镜
泽攸科技是一家国产的科学仪器公司,专注于研发、生产和销售原位电镜解决方案、扫描电镜整机、台阶仪、探针台等仪器。目前台式扫描电镜分为三个系列:ZEM15、ZEM18、ZEM20。 ZEM15台式扫描电镜: ZEM18台式扫描电镜: ZEM20台式扫描…...
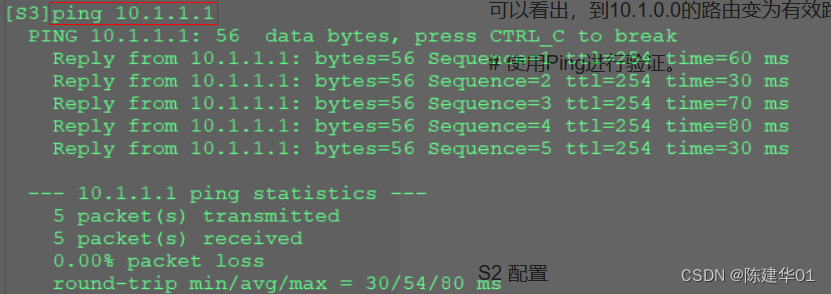
华为交换机配置BGP的基本示例
BGP简介 定义 边界网关协议BGP(Border Gateway Protocol)是一种实现自治系统AS(Autonomous System)之间的路由可达,并选择最佳路由的距离矢量路由协议。早期发布的三个版本分别是BGP-1(RFC1105࿰…...

数据分析基础之《numpy(4)—ndarry运算》
一、逻辑运算 当我们要操作符合某一条件的数据时,需要用到逻辑运算 1、运算符 满足条件返回true,不满足条件返回false # 重新生成8只股票10个交易日的涨跌幅数据 stock_change np.random.normal(loc0, scale1, size(8, 10))# 获取前5行前5列的数据 s…...
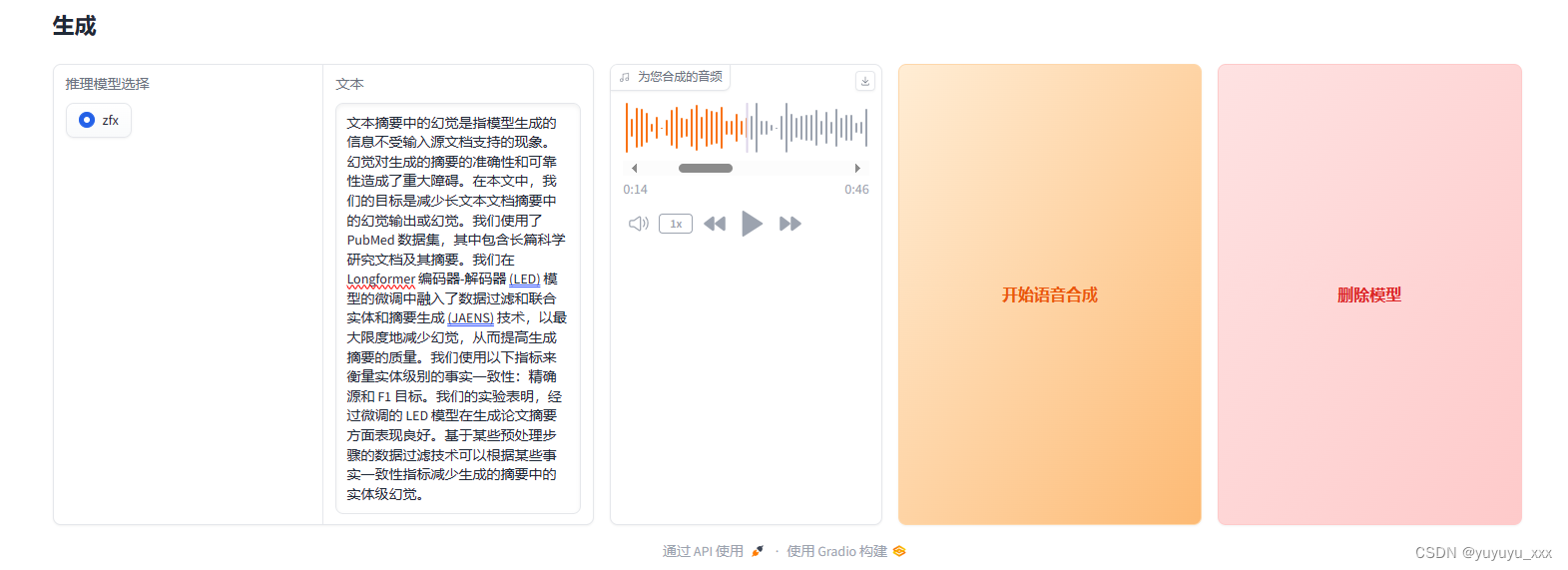
分享一个项目——Sambert UI 声音克隆
文章目录 前言一、运行ipynb二、数据标注三、训练四、生成总结 前言 原教程视频 项目链接 运行一个ipynb,就可操作 总共四步 1)运行ipynb 2)数据标注 3)训练 4)生成 一、运行ipynb 等运行完毕后,获得该…...

ES6 语法精粹简读
本文旨在记录 ES6 的核心常用语法,略去一些细节。 文章目录 1 var 函数作用域与 let/const 块作用域2 解构赋值数组结构赋值对象结构赋值3 ES6 中字符串的新语法模板字符串模板编译标签模板4 ES6 中的函数默认值rest 参数箭头函数this 指向问题部署管道机制尾调用优化...

uniapp整合echarts(目前性能最优、渲染最快方案)
本文echarts示例如上图,可扫码体验渲染速度及loading效果,下文附带本小程序uniapp相关代码 实现代码 <template><view class="source...

解决Electron应用中的白屏问题的实用方法
在使用Electron构建应用程序时,一些开发者可能会面临窗口加载过程中出现的白屏问题。这种问题主要分为两个方面: Electron未加载完毕HTML: 这时Electron自身产生的白色背景可能导致用户在启动应用时看到一片空白。HTML加载渲染过程中的短暂白…...

大数据---34.HBase数据结构
一、HBase简介 HBase是一个开源的、分布式的、版本化的NoSQL数据库(即非关系型数据库),依托Hadoop分布式文件系统HDFS提供分布式数据存储,利用MapReduce来处理海量数据,用Zookeeper作为其分布式协同服务,一…...
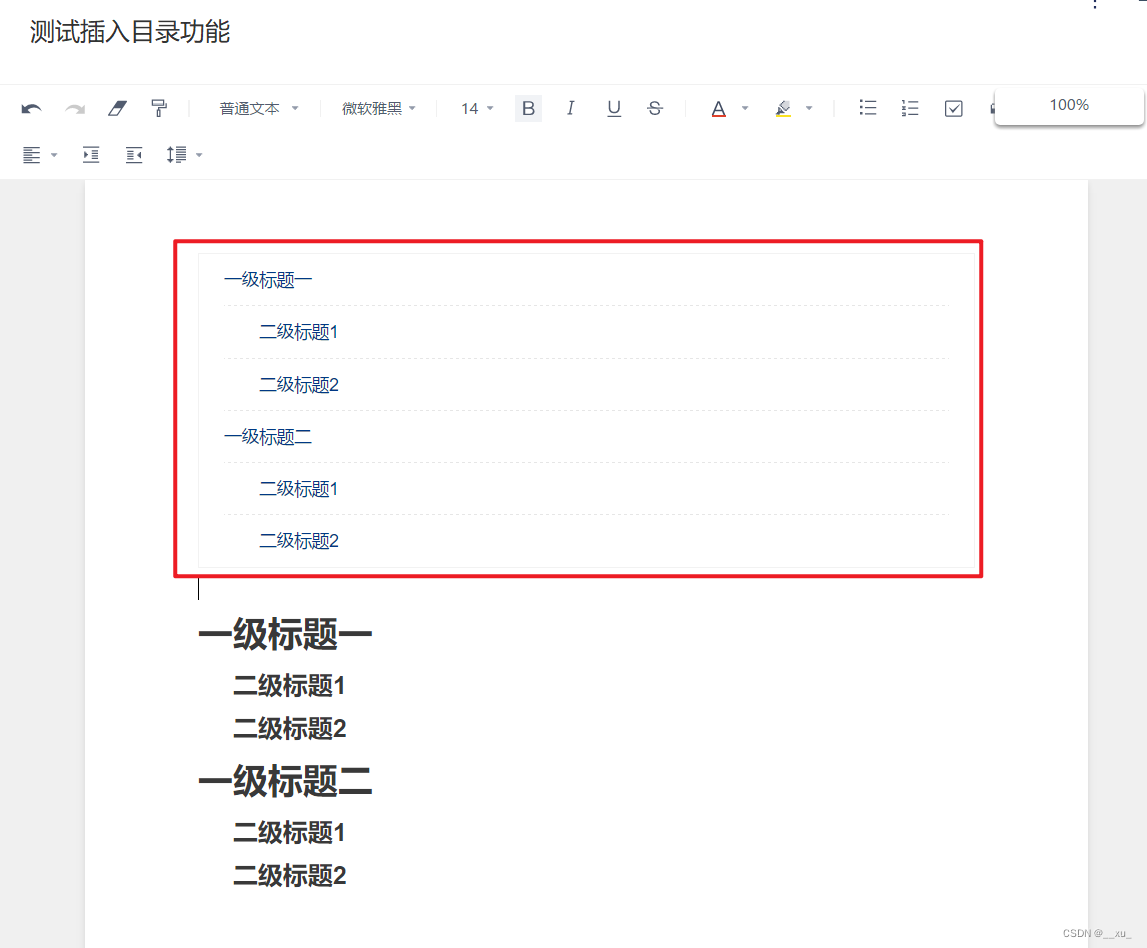
【工具使用-有道云笔记】如何在有道云笔记中插入目录
一,简介 本文主要介绍如何在有道云笔记中插入目录,方便后续笔记的查看,供参考。 二,具体步骤 分为两个步骤:1,设置标题格式;2,插入标题。非常简单~ 2.1 设置标题格式 鼠标停在标…...
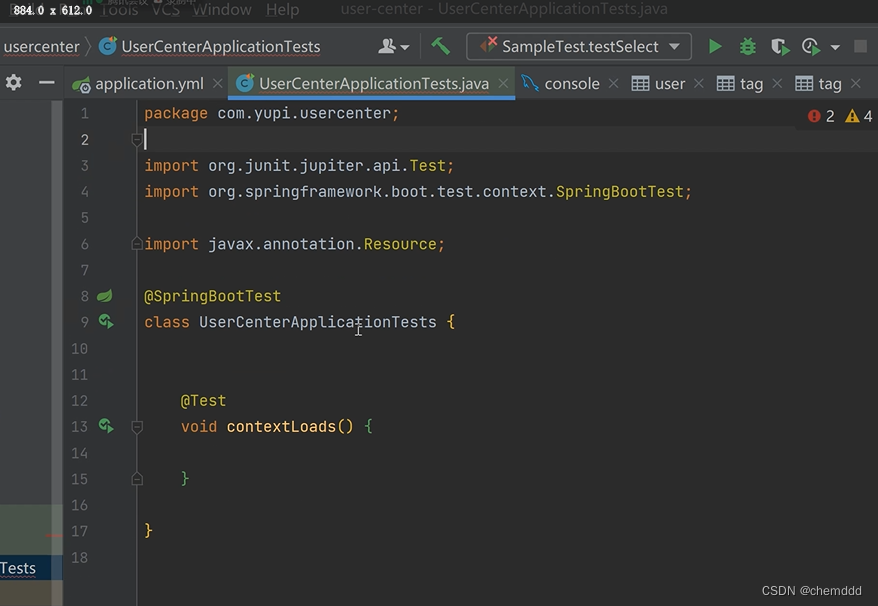
用户管理第2节课-idea 2023.2 后端一删除表,从零开始---【本人】
一、清空model文件夹下,所有文件 1.1.1效果如下: 1.1代码内容 package com.daisy.usercenter.model;import lombok.Data;Data public class User {private Long id;private String name;private Integer age;private String email; }二、清空mapper文件…...

如何添加jar包到本地Maven项目中
在 Maven 中添加一个外部 JAR 包的依赖,你需要使用 Maven 的 <dependency> 元素来指定该 JAR 包的坐标信息。以下是具体的步骤: 将 JAR 包手动添加到 Maven 本地仓库: 首先,确保将外部 JAR 包手动添加到 Maven 本地仓库。可…...

智能优化算法应用:基于学校优化算法3D无线传感器网络(WSN)覆盖优化 - 附代码
智能优化算法应用:基于学校优化算法3D无线传感器网络(WSN)覆盖优化 - 附代码 文章目录 智能优化算法应用:基于学校优化算法3D无线传感器网络(WSN)覆盖优化 - 附代码1.无线传感网络节点模型2.覆盖数学模型及分析3.学校优化算法4.实验参数设定5.算法结果6.…...
【MATLAB第85期】基于MATLAB的2023年智能进化算法/元启发式算法合集(持续更新)
【MATLAB第85期】基于MATLAB的2023年智能进化算法/元启发式算法合集(持续更新) 1.海象进化算法(Walrus Optimization Algorithm) 作者:Pavel Trojovsk and Mohammad Dehghani 2.暴龙优化算法(Tyrannosa…...

[Realtek sdk-3.4.14b]RTL8197FH-VG+RTL8812F WiFi使用功率限制功能使用说明
sdk说明 ** Gateway/AP firmware v3.4.14b – Aug 26, 2019** Wireless LAN driver changes as: Refine WiFi Stability and Performance Add 8812F MU-MIMO Add 97G/8812F multiple mac-clone Add 97G 2T3R antenna diversity Fix 97G/8812F/8814B MP issu…...

Vue中为什么data属性是一个函数而不是一个对象?(看完就会了)
文章目录 一、实例和组件定义data的区别二、组件data定义函数与对象的区别三、原理分析四、结论 一、实例和组件定义data的区别 vue实例的时候定义data属性既可以是一个对象,也可以是一个函数 const app new Vue({el:"#app",// 对象格式data:{foo:&quo…...

AI智能体信用评分系统:构建可评估、可管理的多智能体协作框架
1. 项目概述:一个为AI智能体设计的信用评分系统最近在折腾AI智能体(Agent)的落地应用时,我遇到了一个挺有意思的问题:当多个智能体协同工作,或者一个智能体需要调用外部工具、API时,如何评估和追…...

人类不擅长做出复杂的决策。人工智能可以指出这些错误。
图片来源:图片由编辑团队使用人工智能生成,仅供参考。来源:https://techxplore.com/news/2026-05-humans-bad-complex-decisions-ai.html当罗列优缺点不足以解决问题时,康奈尔大学研究人员开发的一种新型决策工具可以利用人工智能…...
)
从命令行到自动化:用xrandr和Bash脚本打造你的Linux多屏工作流(附常用场景脚本)
从命令行到自动化:用xrandr和Bash脚本打造你的Linux多屏工作流 在Linux系统中管理多显示器配置,xrandr无疑是最强大的命令行工具之一。但每次手动输入复杂的xrandr命令来调整显示器布局,对于追求效率的高级用户来说,无疑是一种时间…...

OBS多路RTMP推流插件:一站式解决多平台同步直播难题
OBS多路RTMP推流插件:一站式解决多平台同步直播难题 【免费下载链接】obs-multi-rtmp OBS複数サイト同時配信プラグイン 项目地址: https://gitcode.com/gh_mirrors/ob/obs-multi-rtmp 还在为每次直播需要在不同平台间手动切换而烦恼吗?obs-multi…...

NOMA实战:从叠加编码到SIC解码的链路级仿真解析
1. NOMA技术基础与核心原理 NOMA(非正交多址接入)是5G通信中的一项关键技术,它彻底改变了传统正交多址技术(如OFDMA)的资源分配方式。我第一次接触NOMA时,最让我惊讶的是它竟然主动引入干扰来提升频谱效率—…...

精准测试:未来已来,只是尚未流行
一、从“全量覆盖”到“精准打击”:测试范式的必然转向 在软件测试领域,有一个根深蒂固的信仰:测试得越全面,质量就越高。这种思维催生了庞大的测试用例库、漫长的回归周期和不断膨胀的测试资源投入。然而,随着系统复…...

基于CircuitPython与Adafruit IO的物联网倒计时时钟:精准时间同步与远程触发
1. 项目概述:一个精准、可远程触发的物联网倒计时时钟在嵌入式开发里,时间管理是个既基础又容易踩坑的环节。你可能遇到过这种情况:一个基于ESP32的智能浇花器,设定好每天上午10点浇水,结果因为设备内置时钟不准&#…...

利用Taotoken多模型聚合能力为你的智能客服系统注入活力
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用Taotoken多模型聚合能力为你的智能客服系统注入活力 构建一个响应迅速、理解准确且成本可控的智能客服系统,是许多…...

那个号称能把安全厂商、操作系统厂商桌子都掀了的Anthropic Mythos到底是吹牛还是真牛
权力的杠杆与认知的泡沫:Anthropic Mythos 模型在网络安全领域的真实效能与战略叙事深度评估2026年4月7日,Anthropic 公司发布了名为 Claude Mythos Preview 的新型前沿模型,这一事件在人工智能与网络安全交叉领域引发了前所未有的剧烈震荡。…...
LunaTranslator:打破语言壁垒,让视觉小说触手可及
LunaTranslator:打破语言壁垒,让视觉小说触手可及 【免费下载链接】LunaTranslator 视觉小说翻译器 / Visual Novel Translator 项目地址: https://gitcode.com/GitHub_Trending/lu/LunaTranslator 还在为日文、英文的视觉小说而烦恼吗࿱…...