PromptNER: Prompt Locating and Typing for Named Entity Recognition
原文链接:
https://aclanthology.org/2023.acl-long.698.pdf
ACL 2023
介绍
问题
目前将prompt方法应用在ner中主要有两种方法:对枚举的span类型进行预测,或者通过构建特殊的prompt来对实体进行定位。但作者认为这些方法存在以下问题:1)时间开销和计算成本较高;2)需要精确的设计模板,难以在实际场景中应用。
IDEA
因此作者提出了一种双插槽的prompt模板来分别进行实体定位和分类,模型可以同时处理多个prompt,通过对每个prompt中的插槽进行预测来提取所有的实体。
如下图所示,(a)表示根据实体类别构造prompt的方法;(b)表示根据span构造prompt的方法;(c)表示作者所提出的双插槽方法。
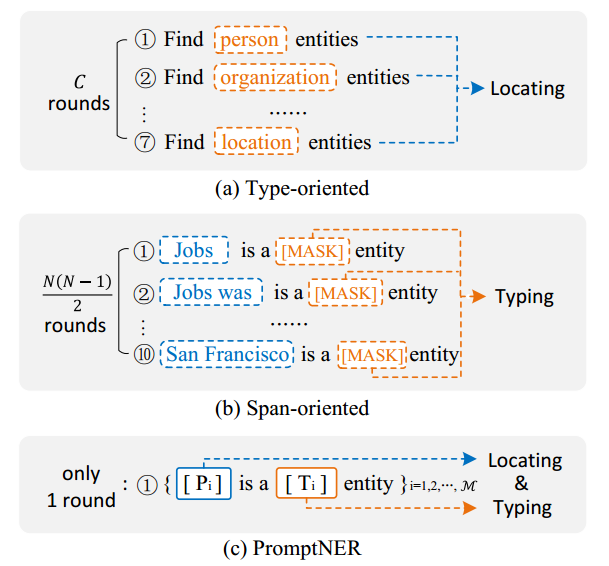
方法
整体的结构如下图所示:

Prompt Construction
模型的输入由两部分组成:M个prompt和句子X。具体的,当输入的句子x=“Jobs was born in San Francisco”,则输入序列就表示为T:

i表示第i个prompt,pi和Ti分别表示实体的位置和类别,M表示prompt的数量,通过对每个prompt中对应的位置进行解码来提取实体。
Prompt Locating and Typing
Encoder
使用bert对T进行编码后,通过位置索引得到句子X与两个插槽的编码 ![]() :
:
![]()
这里作者为了对句子进行独立于prompt的编码(为啥要进行独立编码?好像是为了不让prompt对句子产生影响 实验证明这样的效果会好一点点),通过一个n*k(k表示prompt序列的长度)的左下角掩码矩阵来阻断prompt对句子的注意。
为了增强不同prompt之间的交互,作者设计了一个额外的prompt交互层,每层中包括插槽之间的自注意力以及句子和插槽的交叉注意力(q是插槽,key和value是句子),即位置和类别两种插槽的最终表示为:
![]()
Entity Decoding
通过对prompt中的position slot(位置插槽)和type slot(类别插槽)进行解码得到最终的实体。
具体的,对于第i个prompt,将其type slot ![]() 送入一个分类器得到其属于不同类别的可能性:
送入一个分类器得到其属于不同类别的可能性:
![]()
对于实体的位置,转化为确定第j个词是第i个prompt所预测实体的起始词还是结束词。首先将position slot ![]() 送入一个线性层,然后与句子中每个单词的表征进行相加得到融合表征
送入一个线性层,然后与句子中每个单词的表征进行相加得到融合表征![]() ,对其进行二分类,得到第j个词是第i个prompt预测实体的左右边界概率:
,对其进行二分类,得到第j个词是第i个prompt预测实体的左右边界概率:

最后,m个prompt所预测出的实体可以表示为:
![]()
在推理时,同一实体跨度选择分数最高的类别。
Dynamic Template Filling
由于prompt和实体之间没有确切的对应关系,也就不能提前为其分配标签。因此,将插槽视为一个线性分配问题,按最小代价原则进行分配。作者提出了一种动态模板匹配机制,在实体和prompt之间进行二部图匹配。
gold entity表示为![]() , 其中k表示实体的数量,
, 其中k表示实体的数量,![]() 分别表示第i个实体的左右边界和类别。即与prompt对应的最佳匹配为:
分别表示第i个实体的左右边界和类别。即与prompt对应的最佳匹配为:

其中第i个实体与第θ(i)个prompt之间匹配的代价为(这里没看懂这个计算公式,文中也没有进一步说明,预测的实体与真实实体相乘?):
![]()
但传统的二方图匹配算法是一对一的,即一个实体只能分配给一个prompt,这就会导致部分prompt匹配到空集,降低了训练效率。因此作者将其扩展到了一对多的情况,在预定义好的下限值U下重复gold entity来扩充Y,实现一个实体能分配给多个prompt。
模型的loss由以下两部分的loss组成:

实验
对比实验
在ACE04、ACE05、Conll03这三个数据集上进行实验,结果如下所示:

域内Few-shot
领域内few-shot场景下的实验结果如下图所示:

对conll03数据集进行下采样,使得这四个类别的样本数分别为:3763、2496、100、100.
跨域Few-shot
模拟跨领域few-shot的情况进行实验,在conll03数据集上进行预训练,然后迁移到MIT Movie、MIT Restaurant和ATIS这三个数据集的部分样本上(10、20表示每个类别的样本数)进行实验,结果如下图所示:

作者认为由于promptNER分别对位置和类别进行预测,适用于语法一致而语义不一致的跨域场景。
消融实验
作者对模型的主要模块进行了消融实验,结果如下所示:

消融设置:
1)根据实体出现的顺序来分配给prompt;
2)不进行标签的扩充,比如使用传统的一对一二部图匹配;
3)使用原始的bert用于对句子和prompt进行编码
对不同的prompt模板也进行了实验,结果如下所示:

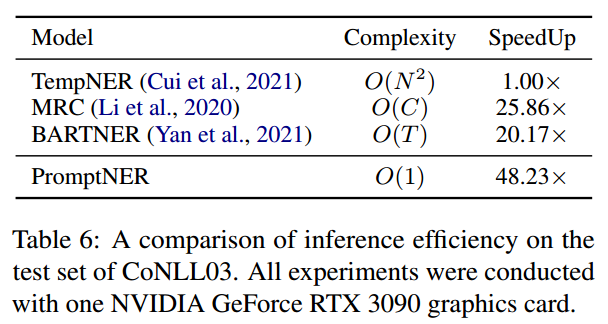
Inference Efficiency
对于有N个单词、C个类别的句子,基于实体类型和span的promt方法分别需要运行C和N(N-1)次,以自回归生成实体序列的方法需要运行T步(实体的长度)才能获得所有的实体。
而PromptNER只需要运行一次就能得到所有的实体。在conll03数据集上进行推理速度的实验,结果如下所示:
总结
之前用在ner上的prompt都是对实体位置和类别分开进行的,这是第一篇(我读到的) 用这种两个slot的方法来对实体及其类别分别进行处理。(但是感觉这样没有语义上的可理解性,也不太符合预训练任务,因为感觉一句话后面也不会直接接上实体)第二个创新点感觉标签动态分配那一块没有讲清楚,很多方法都是使用这种动态分配标签的方法,而去作者扩展为一对多的方式竟然是直接复制,有点过于简单了,真的。但是作者做的相关实验很充分!
另外,作者对prompt的模板进行了消融实验,其实这三种prompt相差都不大,感觉都差不多,只是[pi][Ti]这种模板附加信息更少,不会超出bert的最大长度。不过可以借鉴作者做的推理效率那一块的实验。
相关文章:
PromptNER: Prompt Locating and Typing for Named Entity Recognition
原文链接: https://aclanthology.org/2023.acl-long.698.pdf ACL 2023 介绍 问题 目前将prompt方法应用在ner中主要有两种方法:对枚举的span类型进行预测,或者通过构建特殊的prompt来对实体进行定位。但作者认为这些方法存在以下问题…...
QT编写应用的界面自适应分辨率的解决方案
博主在工作机上完成QT软件开发(控件大小与字体大小比例正常),部署到客户机后,发现控件大小与字体大小比例失调,具体表现为控件装不下字体,即字体显示不全,推测是软件不能自适应分辨率导致的。 文…...

Kubernetes pod ip 暴露
1. k8s pod 和 service 网络暴露 借助 iptables 的路由转发功能,打通k8s集群内的pod和service网络,与外部网络联通 # 查看集群的 pod 网段和 service 网段 kubectl -n kube-system describe cm kubeadm-config networking:dnsDomain: cluster.localpod…...

442. 数组中重复的数据
数组中重复的数据 描述 : 给你一个长度为 n 的整数数组 nums ,其中 nums 的所有整数都在范围 [1, n] 内,且每个整数出现 一次 或 两次 。请你找出所有出现 两次 的整数,并以数组形式返回。 你必须设计并实现一个时间复杂度为 O(n) 且仅使用…...

Qt/C++视频监控Onvif工具/组播搜索/显示监控画面/图片参数调节/OSD管理/祖传原创
一、前言 能够写出简单易用而又不失功能强大的组件,一直是我的追求,简单主要体现在易用性,不能搞一些繁琐的流程和一些极难使用的API接口,或者一些看不懂的很难以理解的函数名称,一定是要越简单越好。功能强大主要体现…...
word2003 open word2007+
Win 7 C:\Documents and Settings\Administrator\Application Data\Microsoft\Templates 还是不行,重装office2003吧,再安装转换插件,但是再高版本好像没转换工具...
windows安装、基本使用vim
标题:windows安装、基本使用vim 1.下载并安装GVIM 百度网盘链接 提取码:2apr 进入安装界面,如下,勾选 其它都是默认即可 参考; 2.在powershell中使用vim 参考blog:window10安装vim编辑器 安装好后&…...
【SpringBoot快速入门】(1)SpringBoot的开发步骤、工程构建方法以及工程的快速启动详细讲解
目录 SpringBoot简介1 SpringBoot快速入门1.1 开发步骤1.1.1 创建新模块1.1.2 创建 Controller1.1.3 启动服务器1.1.4 进行测试 2 对比3 官网构建工程3.1 进入SpringBoot官网3.2 选择依赖3.3 生成工程 4 SpringBoot工程快速启动4.1 问题导入4.2 打包4.3 启动 之前我们已经学习的…...
Day69力扣打卡
打卡记录...
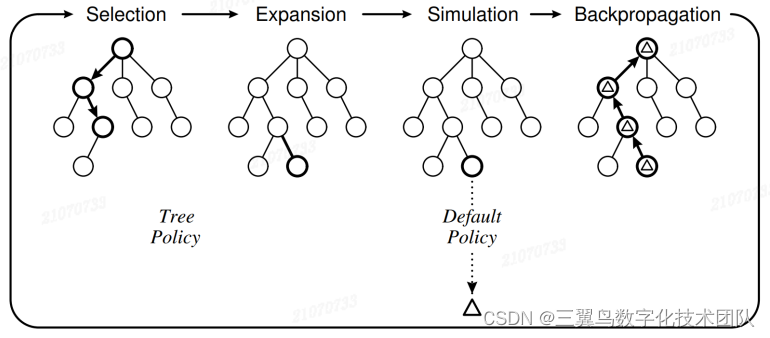
机器学习:手撕 AlphaGo(一)
图 1-1: AphaGo 结构概览 1. 前言 AlphaGo 是一个非常经典的模型,不论从影响力还是模型设计上。它的技术迭代演进路径:AlphaGo,AlphaGoZero,AlphaZero,MuZero 更是十分精彩。相信有很多同学因为听了 AlphaGo 的故事对…...
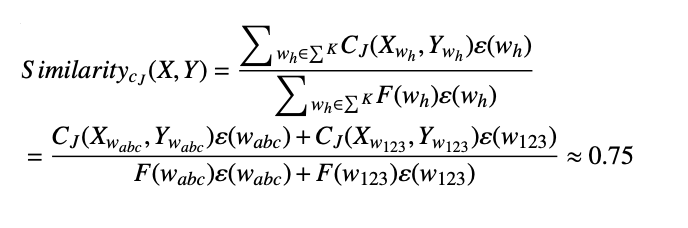
ElasticSearch学习篇9_文本相似度计算方法现状以及基于改进的 Jaccard 算法代码实现
背景 XOP亿级别题库的试题召回以及搜题的举一反三业务场景都涉及使用文本相似搜索技术,学习此方面技术以便更好的服务于业务场景。 目前基于集合的Jaccard算法以及基于编辑距离的Levenshtein在计算文本相似度场景中有着各自的特点,为了优化具体的计算时…...
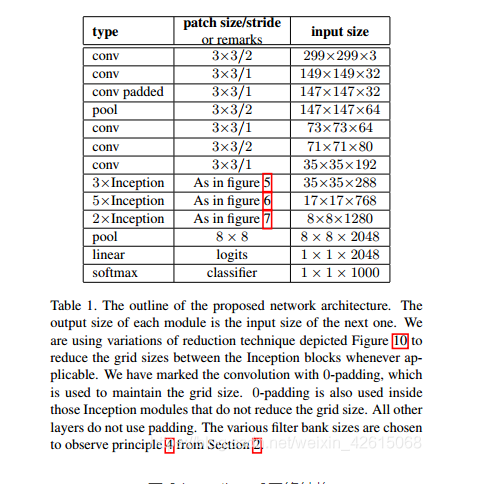
大创项目推荐 深度学习+python+opencv实现动物识别 - 图像识别
文章目录 0 前言1 课题背景2 实现效果3 卷积神经网络3.1卷积层3.2 池化层3.3 激活函数:3.4 全连接层3.5 使用tensorflow中keras模块实现卷积神经网络 4 inception_v3网络5 最后 0 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 *…...

Debezium系列之:Flink SQL消费Debezium数据格式,同步数据到下游存储系统
Debezium系列之:Flink SQL消费Debezium数据格式,同步数据到下游存储系统 一、Debezium二、依赖三、使用Debezium Format四、可用元数据五、Format参数六、重复的变更事件七、消费 Debezium Postgres Connector 产生的数据八、数据类型映射一、Debezium Debezium 是一个 CDC(…...

webrtc支持的最小宽度和高度
代码在:h264/sps_parser.cc // // IMPORTANT ONES! Now were getting to resolution. First we read the pic // width/height in macroblocks (16x16), which gives us the base resolution, // and then we continue on until we hit the frame crop offsets, wh…...

虚拟机对象的创建
虚拟机对象 虚拟机在Java堆中对象分配、布局和访问的访问过程 对象的创建 Java对象的创建步骤: 1)类加载检查 虚拟机遇到一条 new 指令时,首先将去检查这个指令的参数是否能在常量池中定位到这个类的符号引用,并且检查这个符号…...
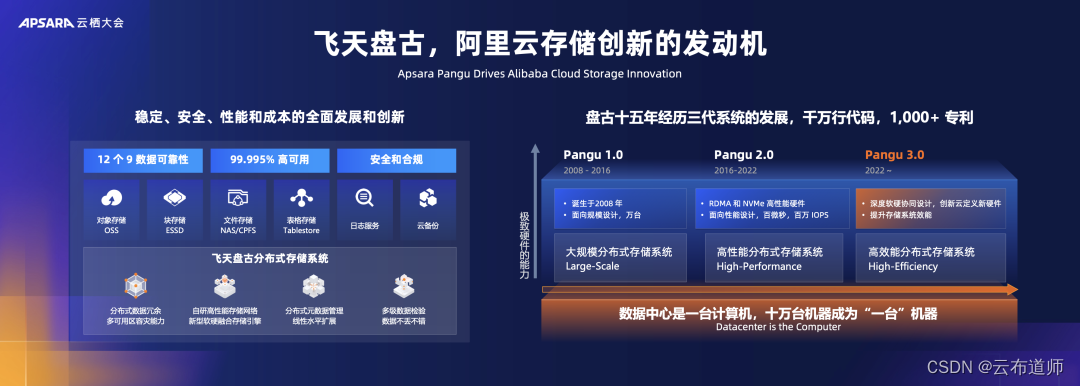
阿里云吴结生:云计算是企业实现数智化的阶梯
云布道师 近年来,越来越多人意识到,我们正处在一个数据爆炸式增长的时代。IDC 预测 2027 年全球产生的数据量将达到 291 ZB,与 2022 年相比,增长了近 2 倍。其中 75% 的数据来自企业,每一个现代化的企业都是一家数据公…...
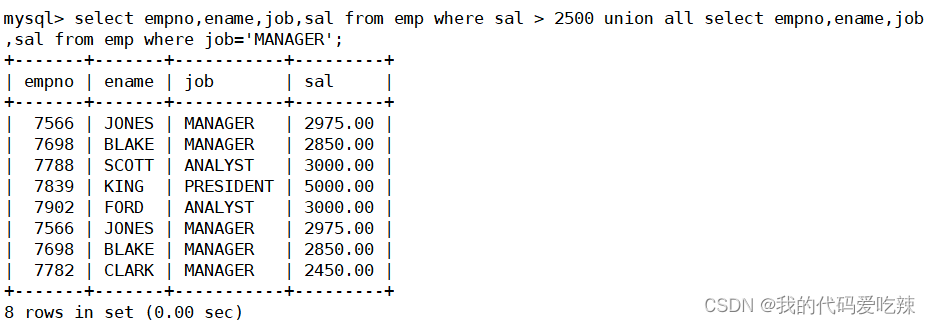
MySQL——复合查询
目录 一.基本查询回顾 二. 多表查询 三.自连接 四.子查询 1.单行子查询 2.多行子查询 3.多列子查询 4.在from子句中使用子查询 5.合并查询 一.基本查询回顾 准备数据库: 查询工资高于500或岗位为MANAGER的雇员,同时还要满足他们的姓名首字母为…...
)
mysql 23-3day 数据库授权(DCL)
目录 创建一个用户 并授权(grant)设置最大连接数客户端链接服务器创建用户删除用户修改用户修改密码root修改自己密码授予 mysql 权限收回权限收回权限刷新一下授权表mydql 知识点确保 mysql 用户为普通用户删除空口令账号安全建议 创建一个用户 并授权&…...

OpenHarmony之内核层解析~
OpenHarmony简介 技术架构 OpenHarmony整体遵从分层设计,从下向上依次为:内核层、系统服务层、框架层和应用层。系统功能按照“系统 > 子系统 > 组件”逐级展开,在多设备部署场景下,支持根据实际需求裁剪某些非必要的组件…...
Chatgpt如何共享可以防止封号!
ChatGPT 是一个基于 GPT-3.5/GPT-4 模型的对话系统,它主要用于处理自然语言对话。通过训练模型来模拟人类的语言行为,ChatGPT 可以通过文本交流与用户互动。每个新版本的 GPT 通常都会在模型规模、性能和其他方面有一些改进。在目前免费版GPT-3.5 中&…...

代码即文档:让三个月后的自己还能看懂今天写的逻辑
在软件测试领域,我们擅长用精密的逻辑去验证他人的代码,却常常在一个隐蔽的角落跌倒——我们自己写的测试代码。三个月前,你精心构建了一套自动化测试框架,一个周末,数百行代码,逻辑环环相扣,运…...

FPGA异构计算与模块化SoM:赋能边缘智能与工业应用实战
1. 项目概述:一次行业深度交流的契机最近,我作为Enclustra团队的一员,有幸受邀参加了今年的嵌入式计算大会。这不仅仅是一次简单的行业聚会,更是一个观察技术风向、碰撞思想火花、探寻合作机会的绝佳窗口。对于所有深耕于嵌入式系…...
引发的音素错位故障)
ElevenLabs旁遮普语TTS突然失真?3步定位Gurmukhi Unicode变体(U+0A02/U+0A3C/U+0A4D)引发的音素错位故障
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs旁遮普文语音合成异常现象综述 ElevenLabs 目前官方文档明确标注支持旁遮普语(Gurmukhi script, language code: pa),但在实际调用其 REST API 进行语音合…...

3步掌握OmenSuperHub:惠普游戏本性能控制终极指南
3步掌握OmenSuperHub:惠普游戏本性能控制终极指南 【免费下载链接】OmenSuperHub 使用 WMI BIOS控制性能和风扇速度,自动解除DB功耗限制。 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 你是否厌倦了官方Omen Gaming Hub的臃肿界面…...

KV缓存优化与RAG系统性能提升实践
1. KV缓存技术原理与RAG系统挑战 在大型语言模型(LLM)推理过程中,KV(Key-Value)缓存技术通过存储注意力机制计算产生的中间状态来避免重复计算。具体来说,Transformer架构中的每个解码器层都会为输入序列生成键(Key)和值(Value)矩…...

通过Taotoken用量看板直观掌握团队API消耗情况
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken用量看板直观掌握团队API消耗情况 对于依赖大模型API进行开发的团队而言,清晰、准确地掌握资源消耗情况是…...


基于smartcat的智能文件自动分类与归档系统实践
1. 项目概述:一个智能化的文件分类与归档工具最近在整理个人电脑和服务器上的文件时,我又一次陷入了混乱。下载文件夹里混杂着PDF、图片、代码压缩包、安装程序;项目文档和历史备份散落在各处。手动分类不仅耗时,而且容易出错。我…...

ComfyUI-Manager插件不显示问题终极指南:从原理到实战的完整解决方案
ComfyUI-Manager插件不显示问题终极指南:从原理到实战的完整解决方案 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable…...

Wwise与Godot音频集成:专业游戏音频中间件在开源引擎中的实现
1. 项目概述:连接两大巨头的桥梁如果你是一位游戏音频设计师,或者是一位对游戏音频实现有追求的开发者,那么“Wwise”和“Godot”这两个名字对你来说一定不陌生。Wwise是业界顶级的交互式音频中间件,以其强大的音频逻辑编排、动态…...