Python入门学习篇(五)——列表字典
1 列表
1.1 定义
①有序可重复的元素集合
②可以存放不同类型的数据
③个人理解:类似于java中的数组
1.2 相关方法
1.2.1 获取列表长度
a 语法
len(列表名)
b 示例代码
list2 = [1, 2, "hello", 4]
print(len(list2))
c 运行结果

1.2.2 获取列表值
a 语法
列表名[下标]
# 下标默认从0开始,若列表中嵌套了列表那么就为: 列名表[列表位置][值的位置]
# 如: lst3 = [100, 3.14, True, "湖南人", [1, 2, 3, 4]] 想要取出数字3,那么就为 lst3[4][2]
b 示例代码
list2 = [1, 2, "hello", 4]
print(f"list2列表的第三个位置为: {list2[2]}")
c 运行结果

1.2.3 值的倒序
a 语法
列表名.reverse()b 示例代码
list2 = [1, 2, "hello", 4,'world']
list2.reverse()
print(list2)
c 运行结果

1.2.4 新增值-加在末尾
a 语法
列表名.append(值)
b 示例代码
list2 = [1, 2, "hello", 4,'world']
list2.append("666")
print(list2)
c 运行结果

1.2.5 新增值-插入任意位置
a 语法
列表名.insert(插入下标,插入值)
# 插入下标默认从0开始算 若为1,则会把值插入到列表的第二个位置,原先第二个位置以及第二个位置之后的值都会往后移
b 示例代码
list2 = [1, 2, "hello", 4, 'world']
list2.insert(1, "666")
print(list2)
c 运行结果

1.2.6 合并列表
a 语法
列表名1.extend(列表名2)
# 会在列表1最后一个元素的后面拼上列表2的所有元素 即 新的列表1=列表1+列表2
b 示例代码
list1 = [1024, 9, "TTG"]
list2 = [1, 2, "hello", 4, 'world']
list1.extend(list2)
print(list1)
c 运行结果

1.2.7 删除元素-从左往右检索,找到即删,只删一个
a 语法
列表名.remove(值)
b 示例代码
list2 = [1, 2, "hello", 1, 'world']
list2.remove(1)
print(list2)
c 运行结果

1.2.8 删除元素-删除列表的最后一个元素
a 语法
pop()
# pop()的返回值是删除的元素
b 示例代码
list2 = [1, 2, "hello", 1, 'world']
list2.pop()
print(list2)
c 运行结果

1.2.9 删除元素-删除指定位置的元素
a 语法
pop(删除元素下标)
b 示例代码
list2 = [1, 2, "hello", 1, 'world']
list2.pop(1)
print(list2)
c 运行结果

1.2.10 修改元素
a 语法
列表名[修改元素所在下标]=修改值
b 示例代码
list2 = [1, 2, 5, 3, [1,6,True,3.11]]
print(f"修改前: {list2}")
list2[4][2]="hello world"
print(f"修改后: {list2}")
c 运行结果

1.3 实战练习
1.3.1 题目要求
希望做一个商品信息录入系统,有以下几大要求
① 初始的界面如下所示:
-------欢迎使用当前系统--------
1.录入商品
2.查询商品
3.退出系统
② 录入商品的界面如下所示:
请输入商品的名称: xxx
请输入商品的成本价:xxx
请输入商品的产地:xxx
请输入商品的生产日期:xxx
③可以循环录入商品
④当多次录入商品后,查询商品界面显示所有录入的商品信息(以列表的形式)
1.3.2 示例代码
print("-------欢迎使用当前系统--------")
projects=[] # 定义一个最外层的列表,用来保存多条商品数据。为了解决新复制一个列表就把其覆盖掉的问题while True:option = input("1.录入商品\n2.查询商品\n3.退出系统\n请输入您的选择:")if option == "1":# 1.录入商品print("--->准备开始录入商品<---")pro_list = [] # 定义一个空列表,用来存储单条数据load_name=input("请输入商品的名称:")pro_list.append(load_name)price=input("请输入商品的成本价:")pro_list.append(price)s_value=input("请输入商品的产地: ")pro_list.append(s_value)data_time=input("请输入商品的生产日期:")pro_list.append(data_time)projects.append(pro_list)# print(pro_list)elif option == "2":# "2.查询商品"print(projects)elif option == "3":print("3.退出系统")else:print("输入有误!!!")
1.3.3 运行截图

2 字典
2.1 定义
①具有键值对映射关系的一组无序(没有下标)的数据集合
②通过key找对应的value
③标识符:{} #里面写的都是json数据格式,key一般都是str类型
④关键字: dict
⑤字典定义语法如下
字典名={key1:value1,key2:value2
}
2.2 相关方法
2.2.1 统计字典中key的个数
a 语法
len(字典名)
b 示例代码
dict1 = {"book_name": "平凡的世界","book_author": "路遥","book_role": ["孙少安", "孙少平", "田晓霞", "田润叶", "孙玉厚", "田福堂"]
}
print(len(dict1))
c 运行截图

2.2.2 新增字典值
a 语法
字典的变量名["字典中不存在的key"]=新增值
#加在最后面
b 示例代码
dict1 = {"book_name": "平凡的世界","book_author": "路遥","book_role": ["孙少安", "孙少平", "田晓霞", "田润叶", "孙玉厚", "田福堂"]
}
print(f"新增前:{dict1}")
dict1["book_honor"]="第三届茅盾文学奖"
print(f"新增后:{dict1}")
c 运行截图

2.2.3 修改字典值
a 语法
字典的变量名["字典中存在的key"]=修改值
b 示例代码
dict1 = {"book_name": "平凡的世界","book_author": "路遥","book_role": ["孙少安", "孙少平", "田晓霞", "田润叶", "孙玉厚", "田福堂"]
}
print(f"修改前:{dict1}")
dict1["book_role"][1]="金波"
print(f"修改后:{dict1}")
c 运行截图

2.2.4 删除指定字典值
a 语法
字典名.pop(key)
b 示例代码
dict1 = {"book_name": "平凡的世界","book_author": "路遥","book_role": ["孙少安", "孙少平", "田晓霞", "田润叶", "孙玉厚", "田福堂"]
}
print(f"删除前:{dict1}")
dict1.pop("book_role")
print(f"删除后:{dict1}")
c 运行截图

2.2.5 清空字典所有值
a 语法
字典名.clear()
b 示例代码
dict1 = {"book_name": "平凡的世界","book_author": "路遥","book_role": ["孙少安", "孙少平", "田晓霞", "田润叶", "孙玉厚", "田福堂"]
}
print(f"清空前:{dict1}")
dict1.clear()
print(f"清空后:{dict1}")
c 运行截图

2.3 实战练习
2.3.1 题目要求
希望做一个商品信息录入系统,有以下几大要求
① 初始的界面如下所示:
-------欢迎使用当前系统--------
1.录入商品
2.查询商品
3.退出系统
② 录入商品的界面如下所示:
请输入商品的名称: xxx
请输入商品的成本价:xxx
请输入商品的产地:xxx
请输入商品的生产日期:xxx
③可以循环录入商品
④当多次录入商品后,查询商品界面显示需要查询的商品信息(录入的单条商品信息用列表存储,所有信息用字典存储)
2.3.2 示例代码
print("-------欢迎使用当前系统--------")
products = {}
while True:print("1.录入商品\n2.查询指定商品\n3.退出系统")choice = input("请输入您的选择:")if choice == "1":# 录入商品逻辑product = [] # 每次重新输入时需要清空该列表product.append(input("请输入商品的名称: "))product.append(input("请输入商品的成本价: "))product.append(input("请输入商品的产地: "))product.append(input("请输入商品的生产日期: "))products[product[0]] = productelif choice == "2":# 查询指定商品逻辑product_name = input("请输入您要查询的商品名称: ")print(f"需要查询的商品信息为: {products[product_name]}")elif choice == "3":print("系统已关机,欢迎您下此使用")break
2.3.3 运行截图

相关文章:
Python入门学习篇(五)——列表字典
1 列表 1.1 定义 ①有序可重复的元素集合 ②可以存放不同类型的数据 ③个人理解:类似于java中的数组1.2 相关方法 1.2.1 获取列表长度 a 语法 len(列表名)b 示例代码 list2 [1, 2, "hello", 4] print(len(list2))c 运行结果 1.2.2 获取列表值 a 语法 列表名…...

React尝鲜
组件 React的组件就是一个js函数,函数内部return一个由jsx语法创建的html代码片段。 //MyComp.js export default function MyComp(){return (<h1>我是新组件MyComp</h1>) } 在需要引入组件的地方import导入组件,并放在相应位置 //App.js…...

锯齿云服务器租赁使用教程
首先登陆锯齿云账号 网盘上传数据集与代码 随后我们需要做的是将所需要的数据集与代码上传到网盘(也可以直接在租用服务器后将数据集与代码传到服务器的硬盘上,但这样做会消耗大量时间,造成资源浪费) 点击工作空间:…...

HarmonyOS和OpenHarmony的区别
1.概要 众所周知,鸿蒙是华为开发的一款分布式操作系统。因为开发系统,最重要的是集思广益,大家共同维护。为了在IOS和Android之间生存,鸿蒙的茁壮成长一定是需要开源,各方助力才能实现。 在这种思想上,…...

Redis Stream消息队列之基本语法与使用方式
前言 本文的主角是Redis Stream,它是Redis5.0版本新增加的数据结构,主要用于消息队列,提供了消息的持久化和主备复制功能,可以让任何客户端访问任何时刻的数据,并且能记住每一个客户端的访问位置,还能保证…...

制造行业定制软件解决方案——工业信息采集平台
摘要:针对目前企业在线检测数据信号种类繁多,缺乏统一监控人员和及时处置措施等问题。蓝鹏测控开发针对企业工业生产的在线数据的集中采集分析平台,通过该工业信息采集平台可将企业日常各种仪表设备能够得到数据进行集中分析处理存储…...

[python]用python实现对arxml文件的操作
目录 关键词平台说明一、背景二、方法2.1 库2.2 code 关键词 python、excel、DBC、openpyxl 平台说明 项目Valuepython版本3.6 一、背景 有时候需要批量处理arxml文件(ARXML 文件符合 AUTOSAR 4.0 标准),但是工作量太大,阔以考虑用python。 二、方…...
pdf 在线编辑
https://smallpdf.com/edit-pdf#rapp 参考 https://zh.wikihow.com/%E5%B0%86%E5%9B%BE%E5%83%8F%E6%8F%92%E5%85%A5PDF...

自然语言处理(NLP):理解语言,赋能未来
目录 前言1 什么是NLP2 NLP的用途3 发展历史4 NLP的基本任务4.1 词性标注(Part-of-Speech Tagging)4.2 命名实体识别(Named Entity Recognition)4.3 共指消解(Co-reference Resolution)4.4 依存关系分析&am…...

FastAPI使用loguru时,出现重复日志打印的解决方案
首先看图,发现每个日志都被打印了3条。其实这个和uvicorn日志打印的设计有关,在uvicorn中有多个logger,分别是uvicorn、uvicorn.error、uvicorn.access 而LOGGING默认有一个属性propagate,这个属性为True时,子日志记录…...

构建每个聚类的profile和deletion_mean特征
通过summarize_clusters函数构建每个聚类的protein[cluster_profile]和protein[cluster_deletion_mean]特征。目的是把extra_msa信息反映到msa中。 集成函数数据处理流程: sample_msa ->make_masked_msa -> nearest_neighbor_clusters -> summarize_clu…...
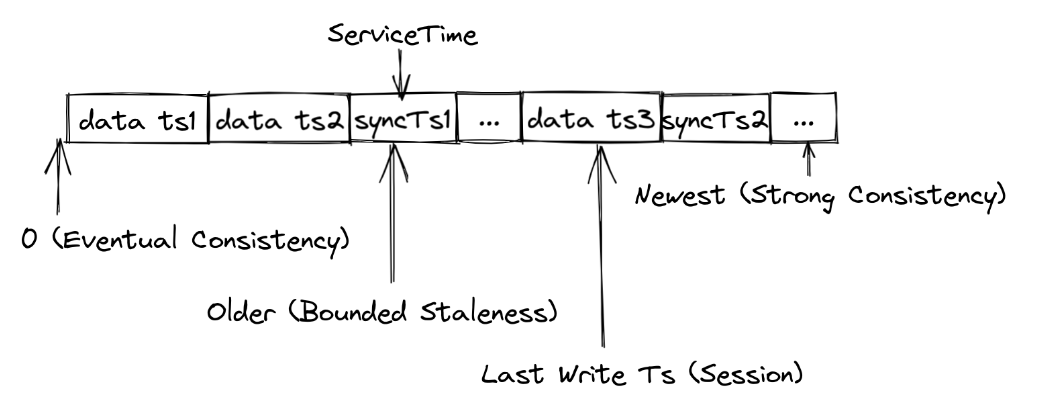
Milvus数据一致性介绍及选择方法
1、Milvus 时钟机制 Milvus 通过时间戳水印来保障读链路的一致性,如下图所示,在往消息队列插入数据时, Milvus 不光会为这些插入记录打上时间戳,还会不间断地插入同步时间戳,以图中同步时间戳 syncTs1 为例࿰…...

异常处理和单元测试python
一、实验题目 异常处理和单元测试 二、实验目的 了解异常的基本概念和常用异常类。掌握异常处理的格式、处理方法。掌握断言语句的作用和使用方法。了解单元测试的基本概念和作用。掌握在Python中使用测试模块进行单元测试的方法和步骤。 三、实验内容 编程实现如下功能&a…...

蓝牙物联网在汽车领域的应用
I、蓝牙的技术特点 1998 年 5 月,瑞典爱立信、芬兰诺基亚、日本东芝、美国IBM 和英特尔公司五家著名厂商,在联合拓展短离线通信技术的标准化活动时提出了蓝牙技术的概念。蓝牙工作在无需许可的 2.4GHz 工业频段 (SIM)之上(我国的频段范围为2400.0~248…...
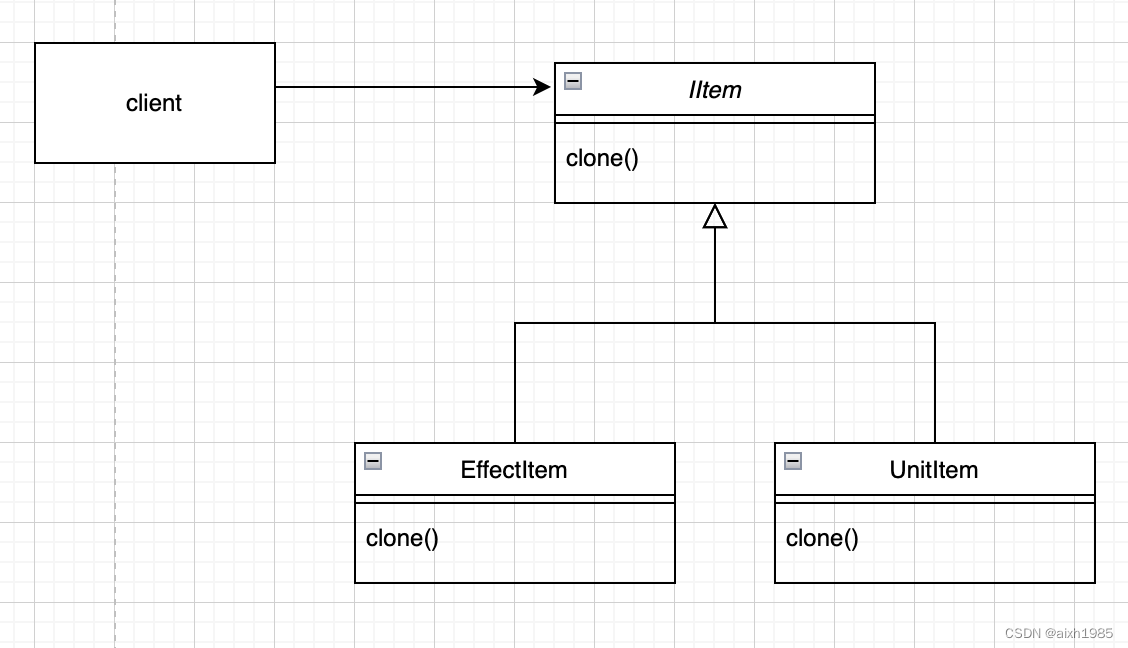
用23种设计模式打造一个cocos creator的游戏框架----(二十二)原型模式
1、模式标准 模式名称:原型模式 模式分类:创建型 模式意图:用原型实例指定创建对象的种类,并且通过复制这些原型创建新的对象 结构图: 适用于: 1、当一个系统应该独立于它的产品创建、构成和表示时 2、…...
)
paddle 55 使用Paddle Inference部署嵌入nms的PPYoloe模型(端到端fps达到52.63)
Paddle Inference 是飞桨的原生推理库,提供服务器端的高性能推理能力。由于 Paddle Inference 能力直接基于飞桨的训练算子,因此它支持飞桨训练出的所有模型的推理。paddle平台训练出的模型转换为静态图时可以选用Paddle Inference的框架进行推理,博主以前都是将静态图转换为…...

自动化测试工具-Selenium:WebDriver的API/方法使用全解
我们上一篇文章介绍了Selenium的三大组件,其中介绍了WebDriver是最重要的组件。在这里,我们将看到WebDriver常用的API/方法(注:这里使用Python语言来进行演示)。 1. WebDriver创建 打开VSCode,我们首先引…...

如何通过蓝牙串口启动智能物联网?
1、低功耗蓝牙(BLE)介绍 BLE 技术是一种低成本、短距离、可互操作的鲁棒性无线技术,工作在免许可的 2,4 GHZ 工业、科学、医学(Industrial Scientific Medical,ISM)频段。BLE在设计之初便被定位为一种超低功耗(Ultra Low Power,ULP)无线技术&…...

Linux---基础操作命令
内容导航 类别内容导航机器学习机器学习算法应用场景与评价指标机器学习算法—分类机器学习算法—回归机器学习算法—聚类机器学习算法—异常检测机器学习算法—时间序列数据可视化数据可视化—折线图数据可视化—箱线图数据可视化—柱状图数据可视化—饼图、环形图、雷达图统…...

uniapp怎么动态渲染导航栏的title?
直接在接口请求里面写入以下: 自己要什么参数就写什么参数 本人仅供参考: this.name res.data.data[i].name; console.log(名字, res.data.data[i].name); uni.setNavigationBarTitle({title: this.name}) 效果:...

企业内网开发场景下,利用Taotoken实现大模型API的统一网关与审计
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业内网开发场景下,利用Taotoken实现大模型API的统一网关与审计 在中大型企业的研发环境中,引入大模型能力…...

如何快速上手专业3D点云标注工具:完整入门指南
如何快速上手专业3D点云标注工具:完整入门指南 【免费下载链接】labelCloud A lightweight tool for labeling 3D bounding boxes in point clouds. 项目地址: https://gitcode.com/gh_mirrors/la/labelCloud 在自动驾驶、机器人视觉和三维重建等领域&#x…...

手把手调SerDes眼图:从FFE系数到示波器实测,看懂那个‘翘起来’的信号
手把手调SerDes眼图:从FFE系数到示波器实测,看懂那个‘翘起来’的信号 在高速数字电路设计中,SerDes(串行器/解串器)技术已经成为现代通信系统的核心。当信号速率突破10Gbps大关时,工程师们常常会在示波器上…...
)
【ElevenLabs土耳其语音实战指南】:2024最新Turkish TTS配置全流程(含音色微调+本地化发音校准)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs土耳其语音技术概览与本地化价值 ElevenLabs 作为前沿AI语音合成平台,已正式支持土耳其语(tr-TR)语音克隆与实时TTS生成,其声学模型基于覆盖安…...

3分钟搞定容器镜像加速:public-image-mirror 终极实战指南
3分钟搞定容器镜像加速:public-image-mirror 终极实战指南 【免费下载链接】public-image-mirror 很多镜像都在国外。比如 gcr 。国内下载很慢,需要加速。致力于提供连接全世界的稳定可靠安全的容器镜像服务。 项目地址: https://gitcode.com/GitHub_T…...

向量寄存器文件优化:Register Dispersion技术解析
1. 向量寄存器文件的技术挑战与优化背景在处理器架构设计中,向量寄存器文件(Vector Register File, VRF)作为向量处理单元(VPU)的核心组件,承担着存储和管理向量数据的关键任务。传统VRF设计通常采用固定数…...
)
Midjourney铂金印相风格实战手册(从Prompt工程到Lightroom精修全流程)
更多请点击: https://intelliparadigm.com 第一章:铂金印相风格的美学溯源与数字复现逻辑 铂金印相(Platinum Print)诞生于19世纪晚期,以铂族金属盐在纸基上直接成像,呈现无光泽、宽广影调与近乎永久的化学…...

如何在华硕路由器上3分钟安装AdGuardHome实现全网广告拦截
如何在华硕路由器上3分钟安装AdGuardHome实现全网广告拦截 【免费下载链接】Asuswrt-Merlin-AdGuardHome-Installer The Official Installer of AdGuardHome for Asuswrt-Merlin 项目地址: https://gitcode.com/gh_mirrors/as/Asuswrt-Merlin-AdGuardHome-Installer 厌倦…...

MonitorControl:终极解决方案!让你的Mac外接显示器亮度调节变得如此简单
MonitorControl:终极解决方案!让你的Mac外接显示器亮度调节变得如此简单 【免费下载链接】MonitorControl 🖥 Control your displays brightness & volume on your Mac as if it was a native Apple Display. Use Apple Keyboard keys or…...

WeChatExporter完整指南:如何在macOS上免费备份微信聊天记录
WeChatExporter完整指南:如何在macOS上免费备份微信聊天记录 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 微信聊天记录中包含了我们珍贵的回忆、重要的工作…...