深度学习(八):bert理解之transformer
1.主要结构
transformer 是一种深度学习模型,主要用于处理序列数据,如自然语言处理任务。它在 2017 年由 Vaswani 等人在论文 “Attention is All You Need” 中提出。
Transformer 的主要特点是它完全放弃了传统的循环神经网络(RNN)和卷积神经网络(CNN),而是完全依赖于注意力机制(Attention Mechanism)来捕捉输入序列中的模式。
Transformer 的主要组成部分包括:
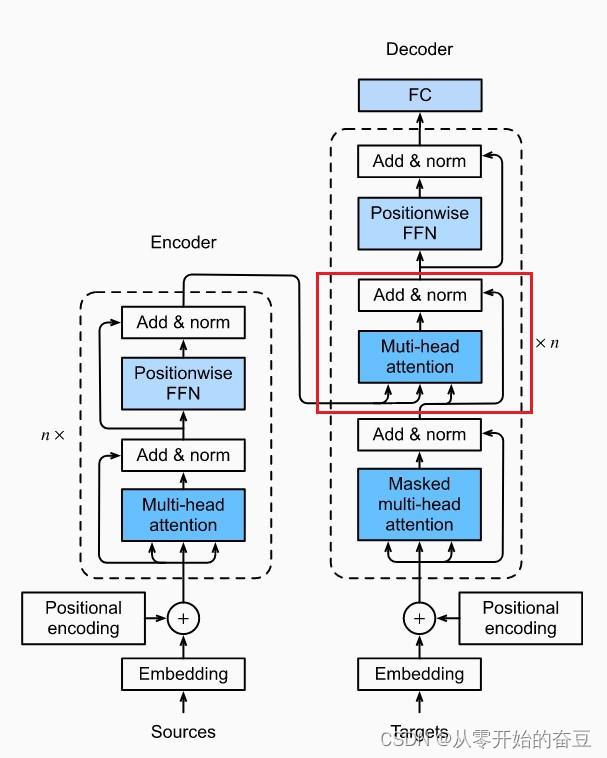
1.自注意力机制(Self-Attention):自注意力机制能够处理序列数据,并且能够关注到序列中的任何位置,从而捕捉到长距离的依赖关系。
2.位置编码(Positional Encoding):由于 Transformer 没有循环和卷积操作,所以需要额外的位置编码来捕捉序列中的顺序信息。
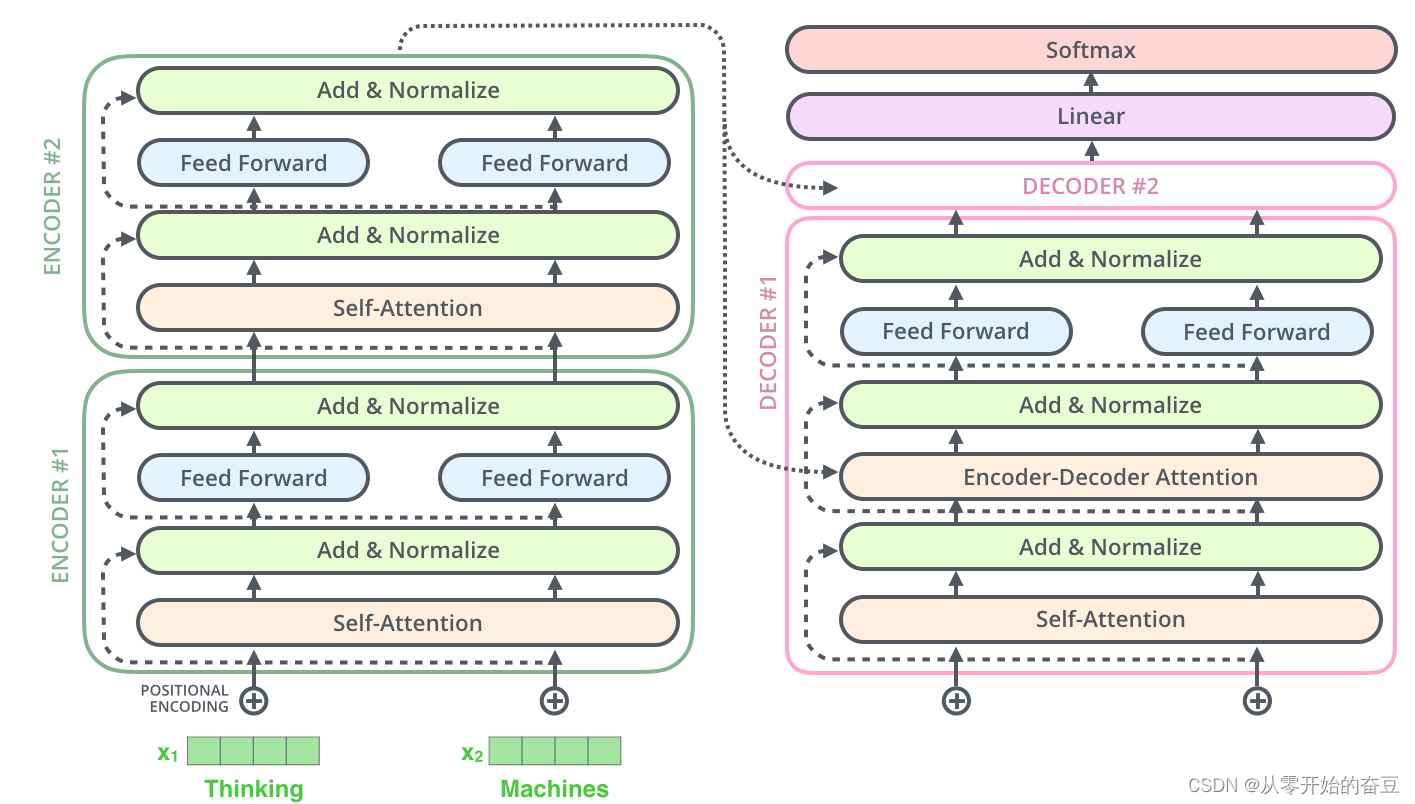
3.编码器和解码器(Encoder and Decoder):Transformer 模型由编码器和解码器组成。编码器用于处理输入序列,解码器用于生成输出序列。编码器和解码器都是由多层自注意力层和全连接层堆叠而成。
2.自注意力机制
个人理解就是把字符编码后通过公式相乘变为另一个向量。
通过关注X中的词嵌入,我们在Y中生成了复合嵌入(加权平均值)。例如,Y中的dog嵌入是X中的the、dog和ran嵌入的组合,权重分别为0.2、0.7 和0.1。
构建词嵌入如何帮助模型实现理解语言的最终目标?要完全理解语言,仅仅理解组成句子的各个单词是不够的;还需要理解组成句子的各个单词。模型必须理解单词在句子上下文中如何相互关联。注意力机制通过形成模型可以推理的复合表示,使模型能够做到这一点。例如,当语言模型尝试预测句子“the runningdog was ___”中的下一个单词时,除了单独的“running ”或“dog”概念之外,模型还应该理解“runningdog”的复合概念;例如,走狗经常喘气,所以喘气是句子中合理的下一个词。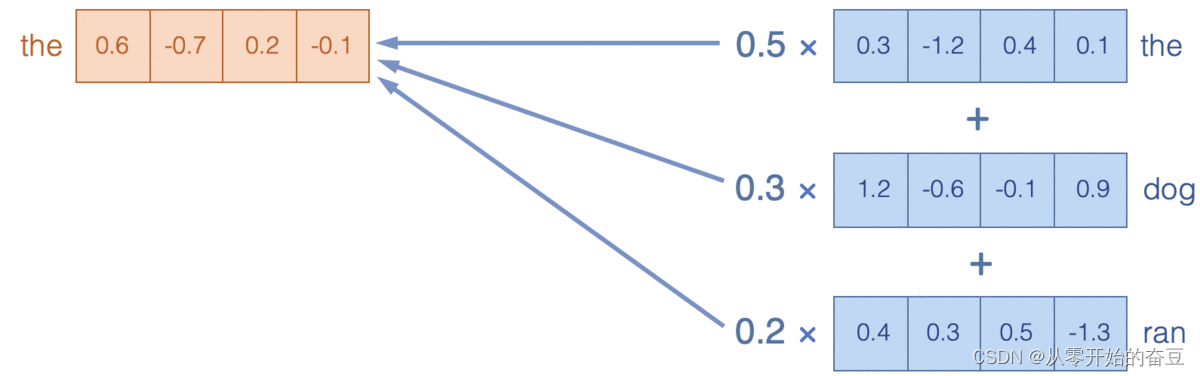
2.1注意力可视化
通过bertviz可视化,bert模型记得替换
from bertviz import head_view, model_view
from transformers import BertTokenizer, BertModel
import imageio
model_version = 'D:\PycharmProjects\Multimodal emotion\model\\bert-base-chinese'
model = BertModel.from_pretrained(model_version, output_attentions=True)
tokenizer = BertTokenizer.from_pretrained(model_version)
sentence_a = "好不好?燕子,你要开心,你要幸福,好不好?"
sentence_b = "开心啊,幸福。你的世界以后没有我了,没关系,你要自己幸福。"
inputs = tokenizer.encode_plus(sentence_a, sentence_b, return_tensors='pt')
print(inputs)
input_ids = inputs['input_ids']
print(input_ids)
token_type_ids = inputs['token_type_ids']
print(token_type_ids)
attention = model(input_ids, token_type_ids=token_type_ids)[-1]
print(attention)
sentence_b_start = token_type_ids[0].tolist().index(1)
print(sentence_b_start)
input_id_list = input_ids[0].tolist() # Batch index 0
print(input_id_list)
tokens = tokenizer.convert_ids_to_tokens(input_id_list)
print(tokens)head_view(attention, tokens, sentence_b_start)下面的可视化(在此处以交互形式提供)显示了示例输入文本引起的注意力。该视图将注意力可视化为连接正在更新的单词(左)和正在关注的单词(右)的线,遵循上图的设计。颜色强度反映注意力权重;接近 1 的权重显示为非常暗的线条,而接近 0 的权重显示为微弱的线条或根本不可见。用户可以突出显示特定单词以仅看到来自该单词的注意力。

升级一下,来讲多头注意力
它扩展了模型关注不同位置的能力。原来的编码 包含一些其他编码,但它可能由实际单词本身主导。如果我们翻译一个句子,比如“The Animal did not cross the street because it was tooert”,那么知道“it”指的是哪个单词会很有用。
它为注意力层提供了多个“表示子空间”。正如我们接下来将看到的,通过多头注意力,我们不仅拥有一组查询/键/值权重矩阵,而且拥有多组查询/键/值权重矩阵(Transformer 使用八个注意力头,因此我们最终为每个编码器/解码器提供八组,但是bert用12或24) 。这些集合中的每一个都是随机初始化的。然后,在训练之后,每个集合用于将输入嵌入(或来自较低编码器/解码器的向量)投影到不同的表示子空间中。
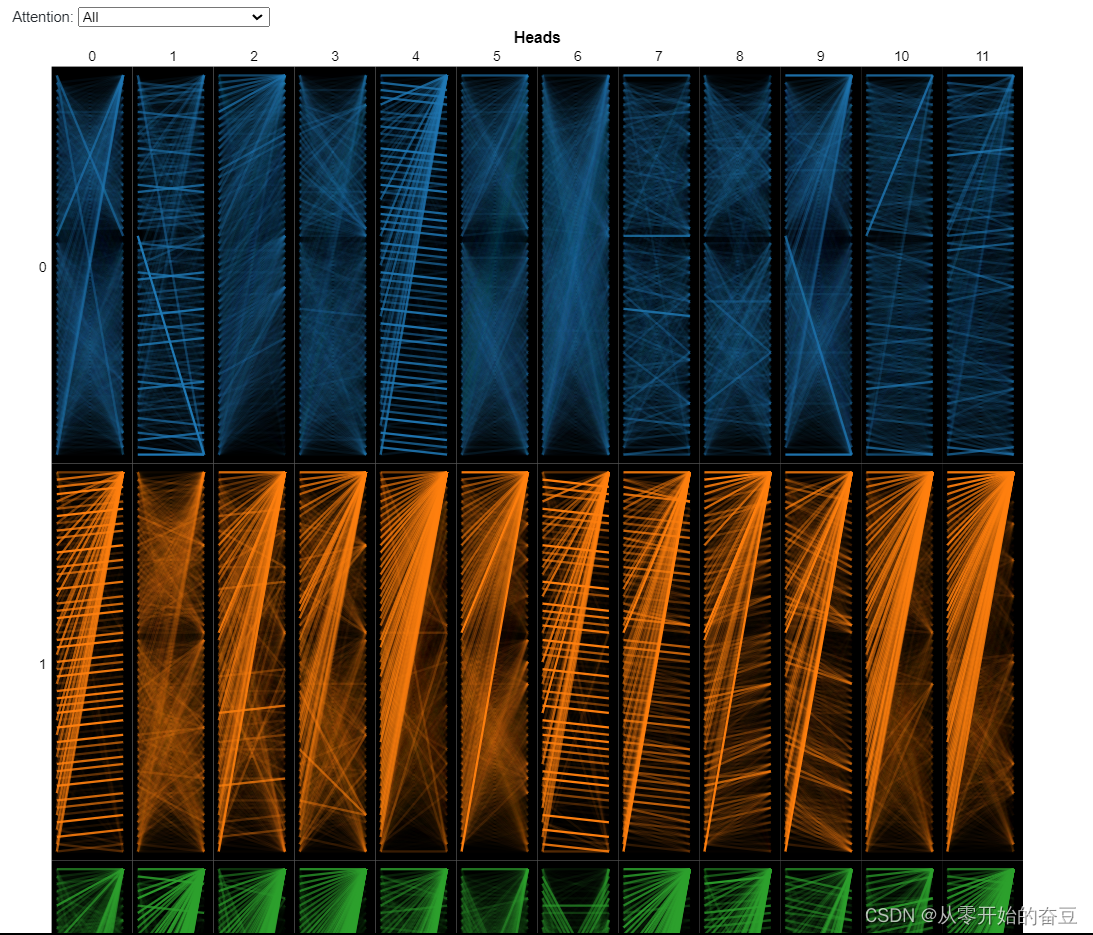
BERT 还堆叠了多个注意力层,每个注意力层都对前一层的输出进行操作。通过这种词嵌入的重复组合,BERT 能够在到达模型最深层时形成非常丰富的表示。我们接着写代码展示
model_view(attention, tokens, sentence_b_start)
由于注意力头不共享参数,因此每个头都会学习独特的注意力模式。我们在这里考虑的 BERT 版本——BERT Base——有 12 层和 12 个头,总共有 12 x 12 = 144 个不同的注意力机制。我们可以使用模型视图(此处以交互形式提供)同时可视化所有头部的注意力:
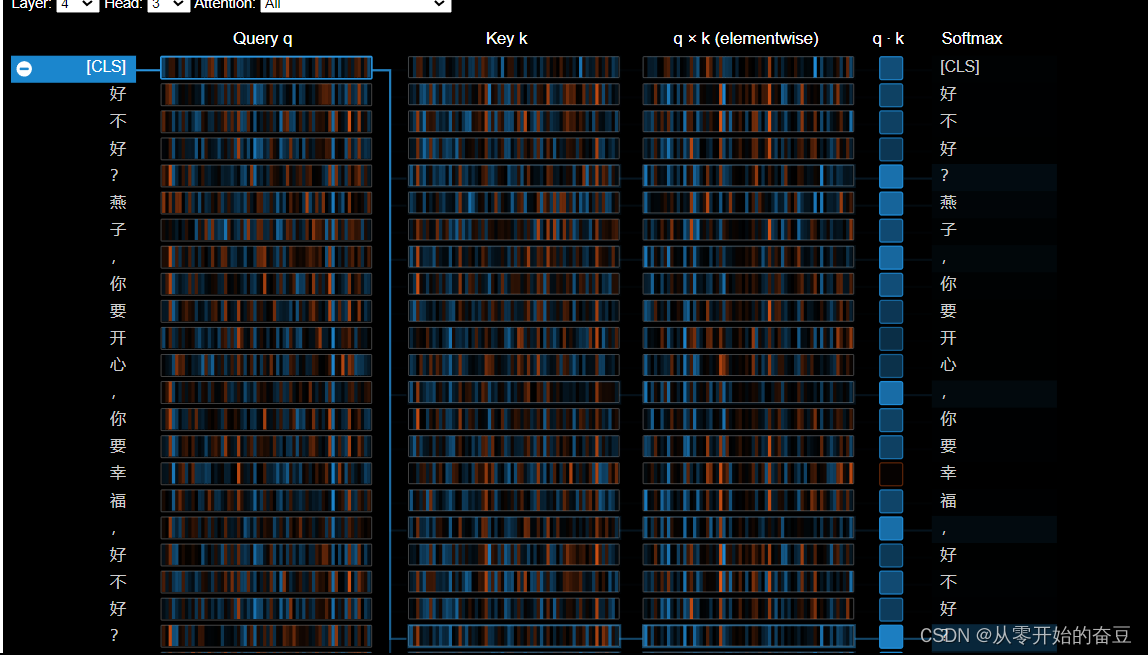
接着我们引入一些概念:
-
查询 q:查询 向量q编码左侧正在关注的单词,即“查询”其他单词的单词。在上面的示例中,“on”(所选单词)的查询向量被突出显示。
-
密钥k:密钥向量k对右侧所关注的单词进行编码。关键字向量和查询向量一起确定两个单词之间的兼容性分数。
-
q×k (elementwise):所选单词的查询向量与每个键向量之间的元素乘积。这是点积(元素乘积之和)的前身,包含在内是为了可视化目的,因为它显示了查询和键向量中的各个元素如何对点积做出贡献。
-
q·k:所选查询向量和每个关键 向量的缩放点积(见上文)。这是非标准化注意力分数。 Softmax:缩放点积的
-
Softmax。这会将注意力分数标准化为正值且总和为 1。
代码
from bertviz.transformers_neuron_view import BertModel, BertTokenizer
from bertviz.neuron_view import showmodel_type = 'bert'
model_version = 'D:\PycharmProjects\Multimodal emotion\model\\bert-base-chinese'
model = BertModel.from_pretrained(model_version, output_attentions=True)
tokenizer = BertTokenizer.from_pretrained(model_version, do_lower_case=True)
show(model, model_type, tokenizer, sentence_a, sentence_b, layer=4, head=3)
该视图跟踪从左侧所选单词到右侧完整单词序列的注意力计算。正值显示为蓝色,负值显示为橙色,颜色强度代表大小。与前面介绍的注意力头视图一样,连接线表示相连单词之间的注意力强度。
2.2原理
回顾上面我所说的概念,运用如下公式

计算得分,多头是这样子的,就是增加了维度,把多头注意力拼接在一起
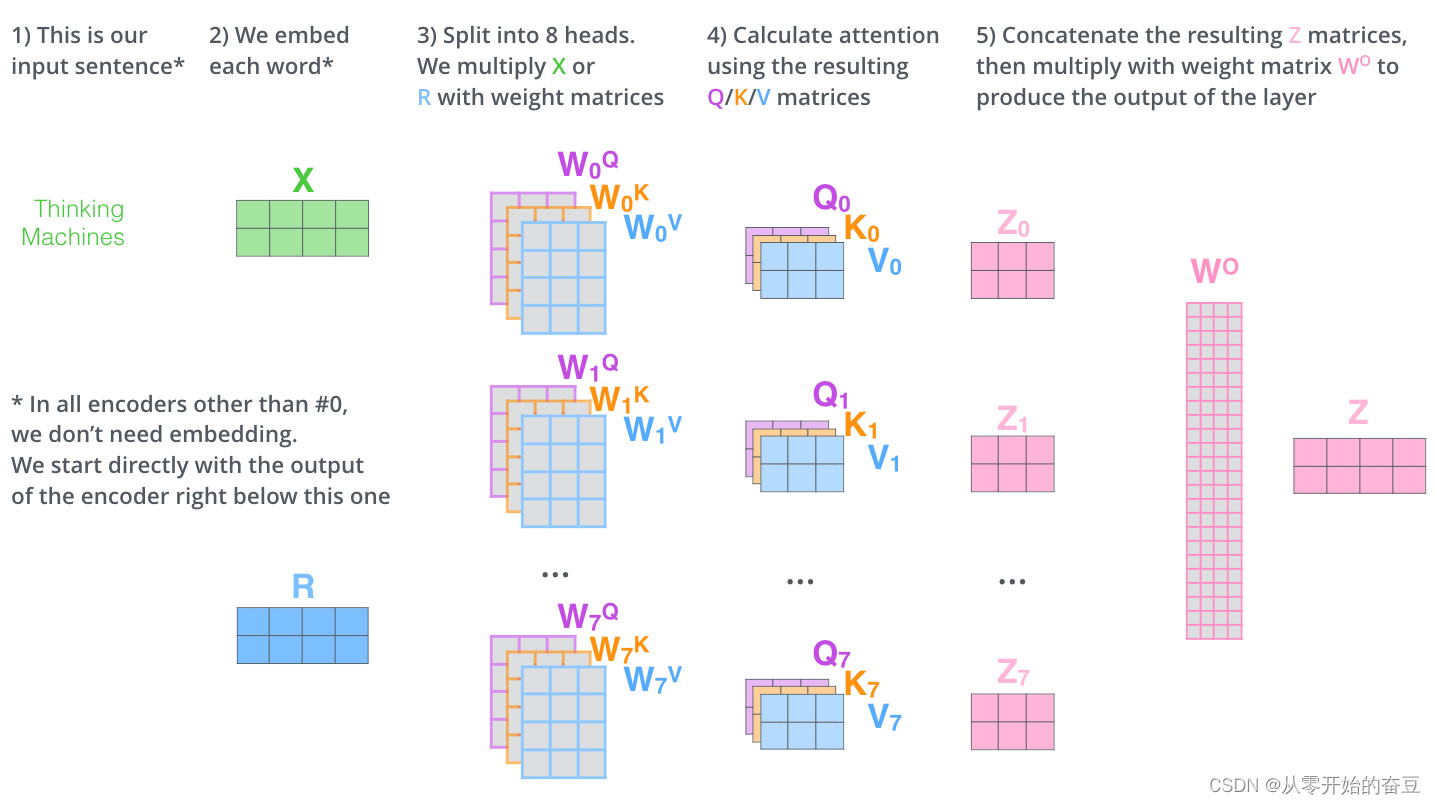
transformer的结构:
经历多头注意力再经过归一化层和前馈神经网络,每个head64维,因为有8个head,应该得到512维,但是bert有12个head,应该得到768维。
举个简单的例子来理解一下
这是利用transformer进行翻译
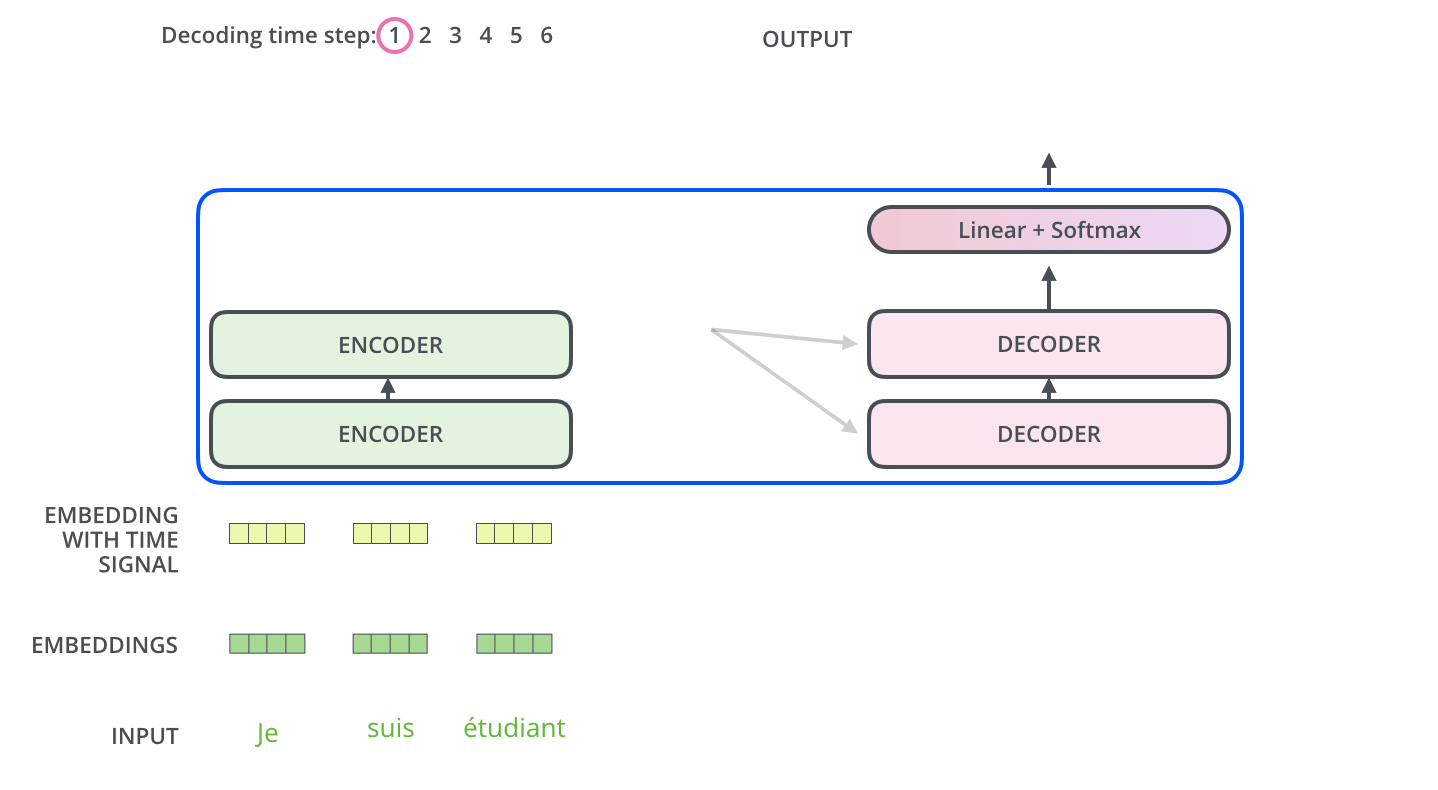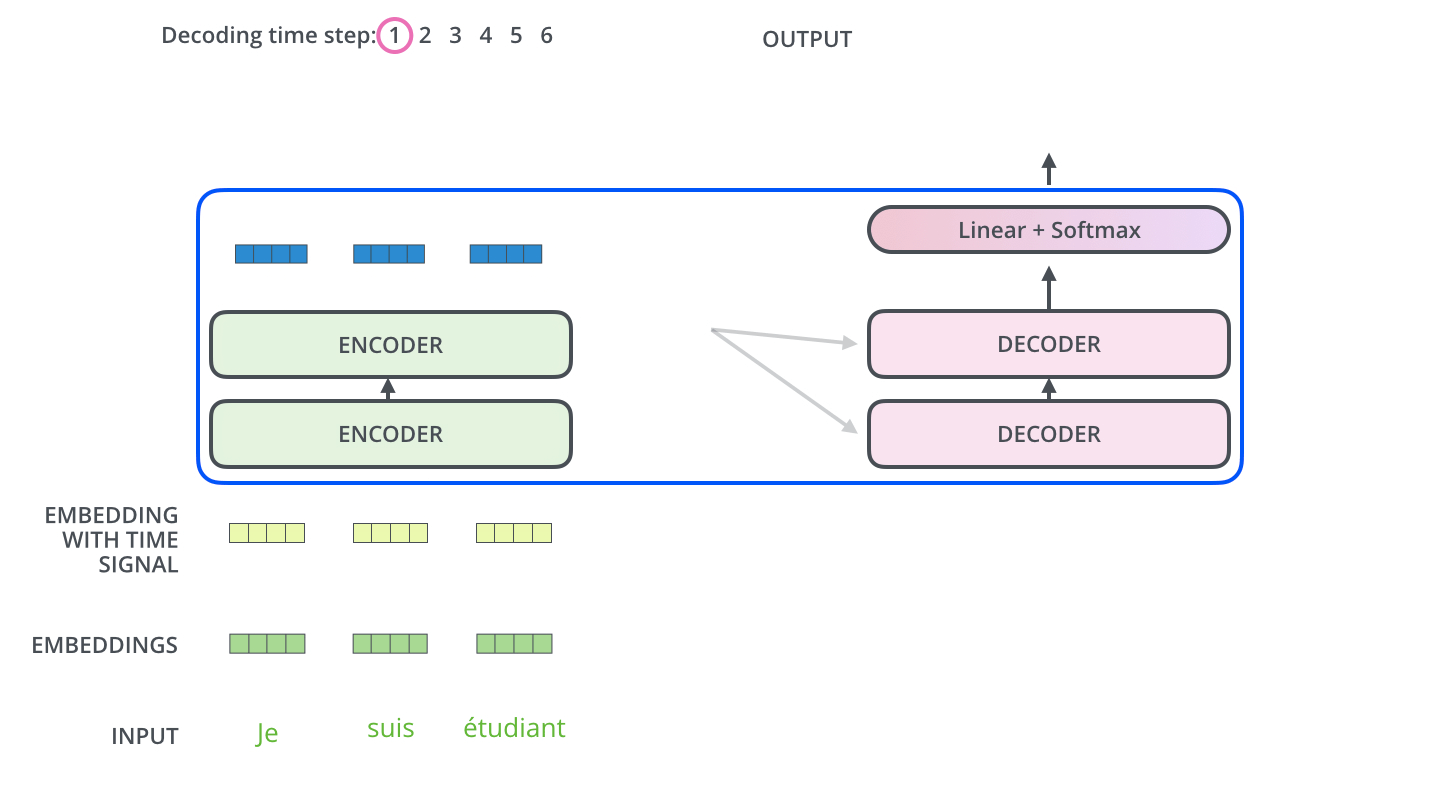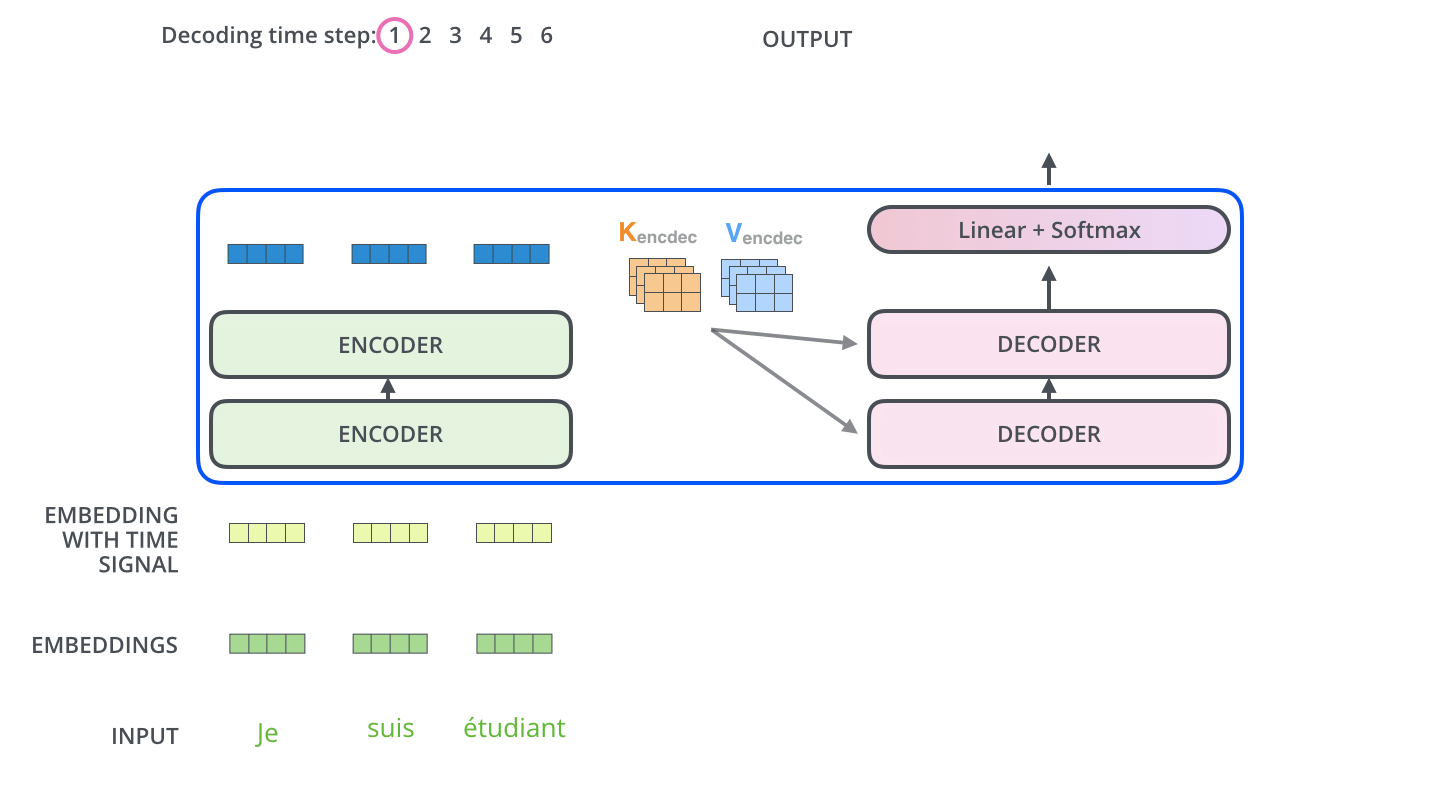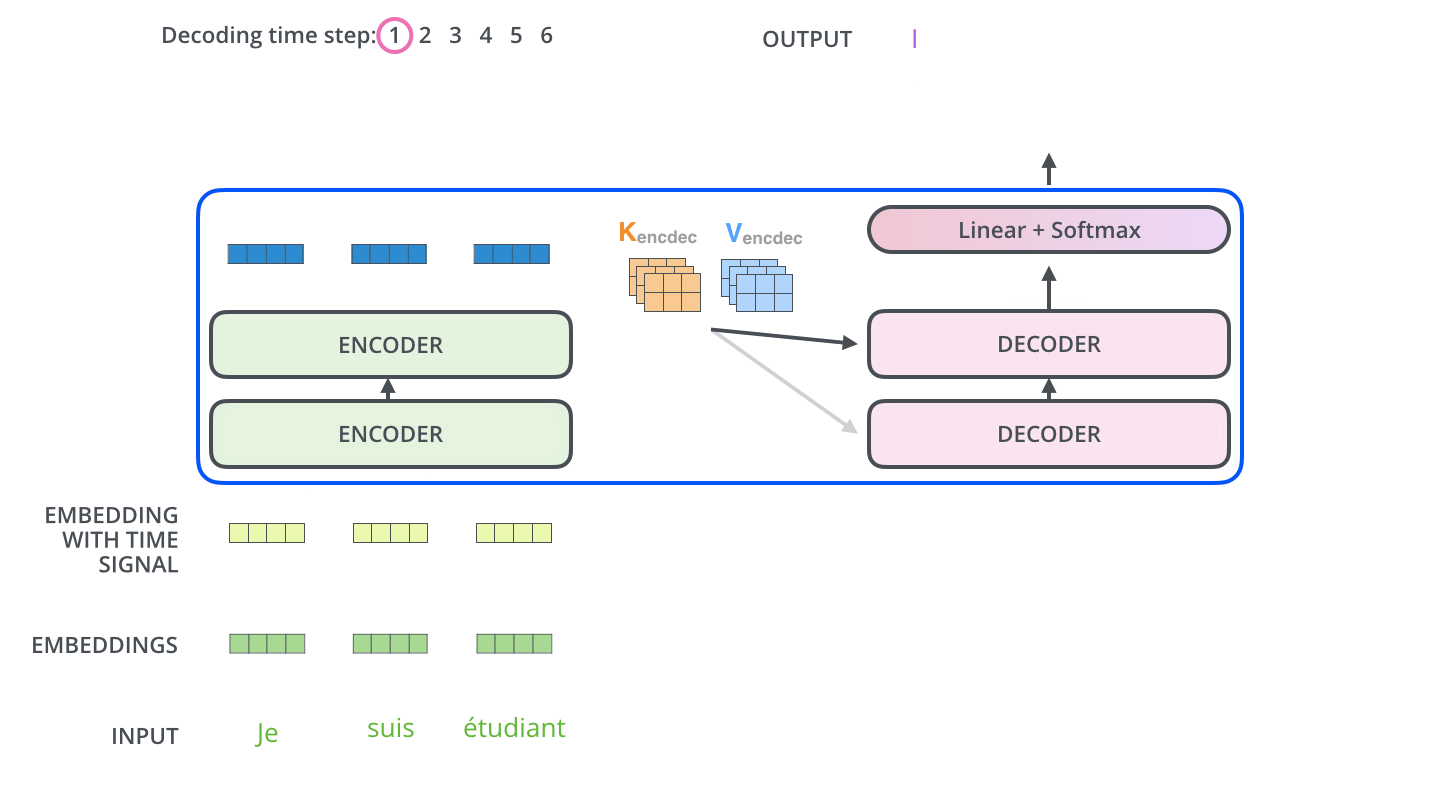

encoders是编码器,decoders是解码器。
3.Positional Encoding
一句话概括,Positional Encoding就是句子中词语相对位置的编码,让Transformer保留词语的位置信息。
t t t表示当前词语在句子中的位置,
p t → \overrightarrow{p_t} pt表示的是该词语对应的位置编码,
d d d表示的是编码的维度。
公式如下
p t → = [ sin ( ω 1 . t ) cos ( ω 1 . t ) sin ( ω 2 . t ) cos ( ω 2 . t ) ⋮ sin ( ω d / 2 . t ) cos ( ω d / 2 . t ) ] d × 1 \left.\overrightarrow{p_t}=\left[\begin{array}{c}\sin(\omega_1.t)\\\cos(\omega_1.t)\\\\\sin(\omega_2.t)\\\cos(\omega_2.t)\\\\\vdots\\\\\sin(\omega_{d/2}.t)\\\cos(\omega_{d/2}.t)\end{array}\right.\right]_{d\times1} pt= sin(ω1.t)cos(ω1.t)sin(ω2.t)cos(ω2.t)⋮sin(ωd/2.t)cos(ωd/2.t) d×1
从公式可以看出,其实一个词语的位置编码是由不同频率的余弦函数函数组成的,从低位到高位。
不同频率的sines和cosines组合其实也是同样的道理,通过调整三角函数的频率,我们可以实现这种低位到高位的变化,这样的话,位置信息就表示出来了。
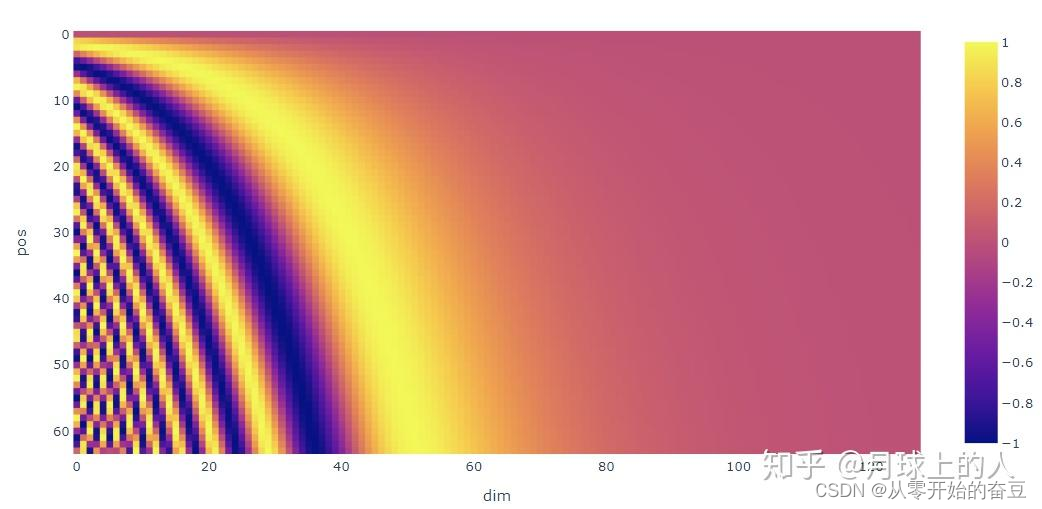
相关文章:
深度学习(八):bert理解之transformer
1.主要结构 transformer 是一种深度学习模型,主要用于处理序列数据,如自然语言处理任务。它在 2017 年由 Vaswani 等人在论文 “Attention is All You Need” 中提出。 Transformer 的主要特点是它完全放弃了传统的循环神经网络(RNN&#x…...
, Filter(), Find(), Map(), Negate(), Position())
R语言中的函数28:Reduce(), Filter(), Find(), Map(), Negate(), Position()
文章目录 介绍Reduce()实例 Filter()实例 Find()实例 Map()实例 Negate()实例 Position()实例 介绍 R语言中的Reduce(), Filter(), Find(), Map(), Negate(), Position()是base包中的一些高级函数。随后,很多包也给这些函数提供了更多的扩展。 Reduce() 该函数根…...
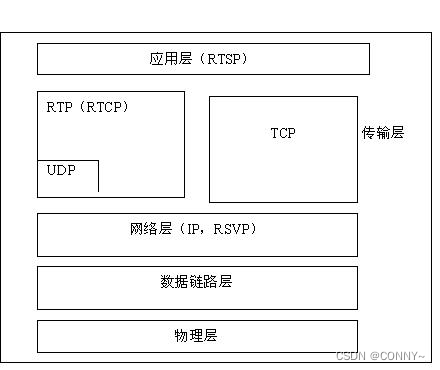
RTP/RTCP/RTSP/SIP/SDP/RTMP对比
RTP(Real-time Transport Protocol)是一种用于实时传输音频和视频数据的协议。它位于传输层和应用层之间,主要负责对媒体数据进行分包、传输和定时。 RTCP(Real-Time Control Protocol)是 RTP 的控制协议,…...

Centos安装vsftpd:centos配置vsftpd,ftp报200和227错误
一、centos下载安装vsftpd(root权限) 1、下载安装 yum -y install vsftpd 2、vsftpd的配置文件 /etc/vsftpd.conf 3、备份原来的配置文件 sudo cp /etc/vsftpd.conf /etc/vsftpd.conf.backup 4、修改配置文件如下:vi /etc/vsftpd.conf …...

软件测试职业规划
软件测试人员的发展误区【4】 公司开发的产品专业性较强,软件测试人员需要有很强的专业知识,现在软件测试人员发展出现了一种测试管理者不愿意看到的景象: 1、开发技术较强的软件测试人员转向了软件开发(非测试工具开发); 2、业务…...

C语言数据结构
C 语言是一种强大的编程语言,它提供了许多数据结构的实现。在本文档中,我们将讨论一些常见的数据结构,并提供相应的代码示例。 数组(Array) 数组是一种线性数据结构,它可以存储相同类型的元素。数组的大小…...

PHP之Trait理解, Trait介绍
一、来源 自 PHP 5.4.0 起,PHP 实现了一种代码复用的方法,称为 trait。 Trait 是为类似 PHP 的单继承语言而准备的一种代码复用机制。Trait 为了减少单继承语言的限制,使开发人员能够自由地在不同层次结构内独立的类中复用 method。Trait 和…...

SpringMVC:执行原理详解、配置文件和注解开发实现 SpringMVC
文章目录 SpringMVC - 01一、概述二、SpringMVC 执行原理三、使用配置文件实现 SpringMVC四、使用注解开发实现 SpringMVC1. 步骤2. 实现 五、总结注意: SpringMVC - 01 一、概述 SpringMVC 官方文档:点此进入 有关 MVC 架构模式的内容见之前的笔记&a…...

增量式旋转编码器在STM32平台上的应用
背景 旋钮是仪器仪表上一种常见的输入设备,它的内部是一个旋转编码器,知乎上的这篇科普文章对其工作原理做了深入浅出的介绍。 我们公司的功率分析仪的前面板也用到了该类设备,最近前面板的MCU从MSP430切换成了STM32,因此我要将…...
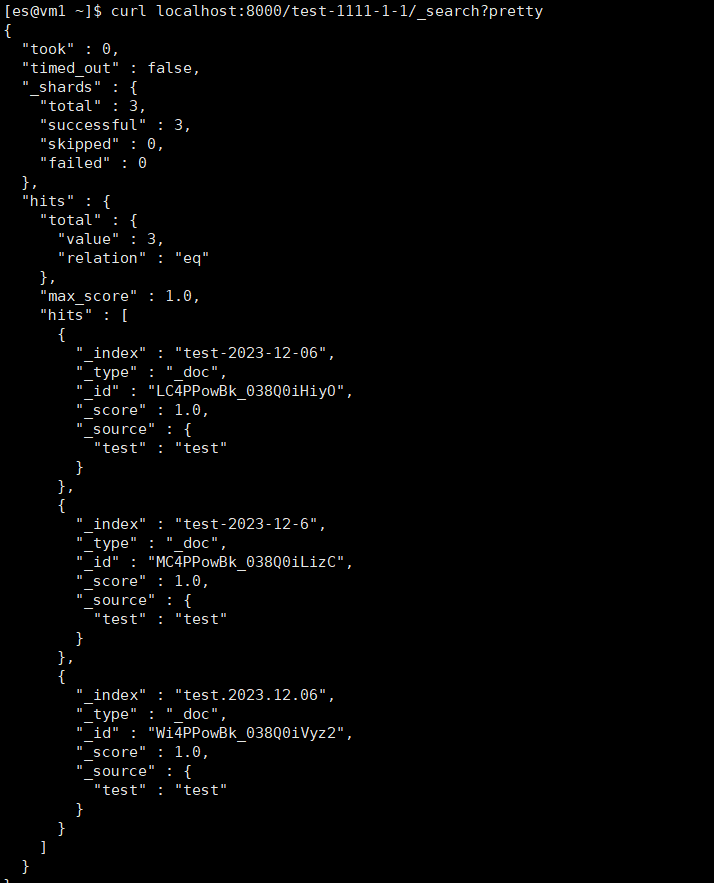
INFINI Gateway 如何防止大跨度查询
背景 业务每天生成一个日期后缀的索引,写入当日数据。 业务查询有时会查询好多天的数据,导致负载告警。 现在想对查询进行限制–只允许查询一天的数据(不限定是哪天),如果想查询多天的数据就走申请。 技术分析 在每…...

【模式识别】探秘分类奥秘:最近邻算法解密与实战
🌈个人主页:Sarapines Programmer🔥 系列专栏:《模式之谜 | 数据奇迹解码》⏰诗赋清音:云生高巅梦远游, 星光点缀碧海愁。 山川深邃情难晤, 剑气凌云志自修。 目录 🌌1 初识模式识…...

【Redis】分布式锁
目录 分布式锁分布式锁实现的关键 Redisson实现分布式锁看门狗机制 分布式锁 为什么要使用分布式锁,或者分布式锁的使用场景? 定时任务。在分布式场景下,只控制一台服务器执行定时任务,这就需要分布式锁 要控制定时任务在同一时间…...

Linux访问firefox 显示Error: no DISPLAY environment variable specified
在 CentOS 7 中访问 Firefox 浏览器时,出现 "Error: no DISPLAY environment variable specified" 的错误提示通常是由于缺少显示环境变量导致的。 要解决这个问题,你可以按照以下步骤进行配置: 1. 确保已经安装 X Window Syst…...

线性回归简介
线性回归简介 1、情景描述2、线性回归 1、情景描述 假设,我们现在有这么一张图: 其中,横坐标x表示房子的面积,纵坐标y表示房价。我们猜想x与y之间存在线性关系: y k x b ykxb ykxb 现在,思考一个问题&…...
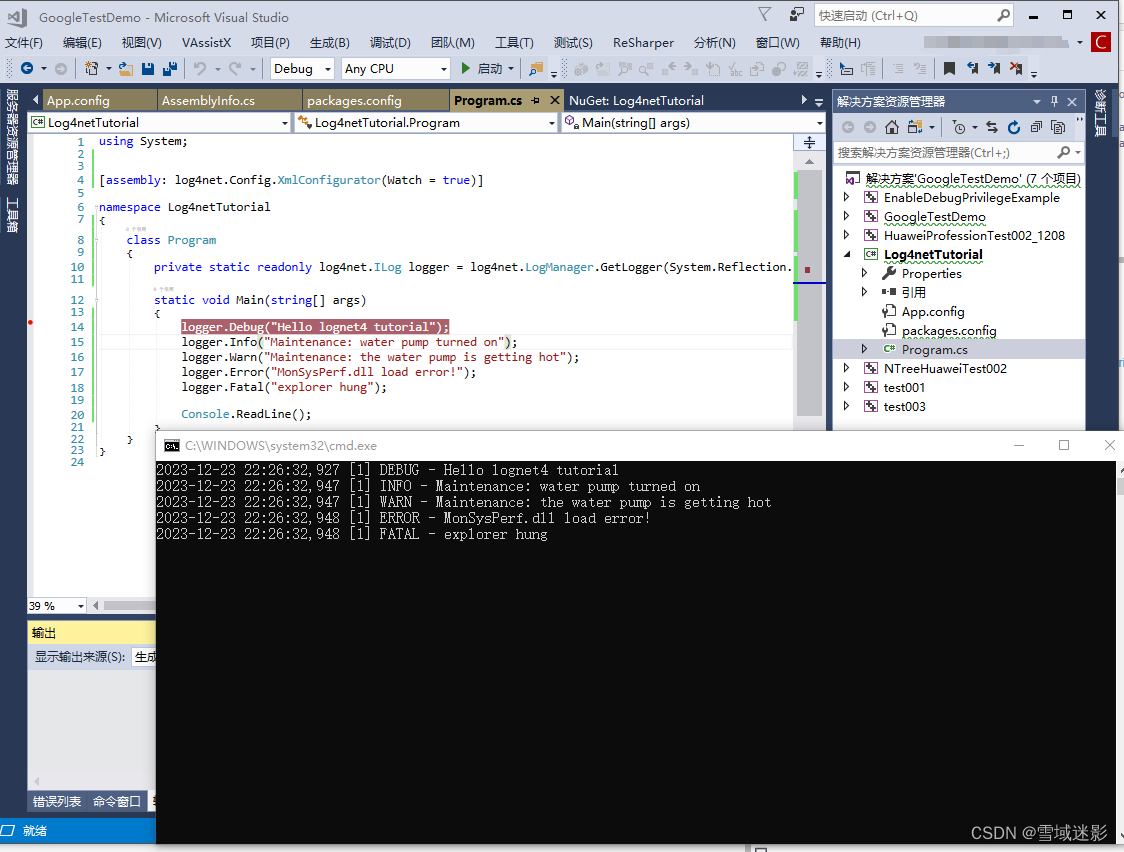
Log4net 教程
一、Log4net 教程 在CodeProject上找到一篇关于Log4net的教程:log4net Tutorial,这篇博客的作者是:Tim Corey ,对应源代码地址为: https://github.com/TimCorey/Log4netTutorial,视频地址为:Ap…...

test-01-java 单元测试框架 junit 入门介绍
JUnit JUnit 是一个用于编写可重复测试的简单框架。 它是 xUnit 架构的一种实例,专门用于单元测试框架。 What to test? NeedDescRight结果是否正确B边界条件是否满足I能反向关联吗C有其他手段交叉检查吗E是否可以强制异常发生P性能问题 maven 入门例子 maven …...

Linux系统中跟TCP相关的系统配置项
TCP连接保活 参考 《Nginx(三) 配置文件详解 - 基础模块》3.18章节 net.ipv4.tcp_keepalive_intvl:设置TCP两次相邻探活检测的间隔时间。默认75秒,单位是秒,对应配置文件/proc/sys/net/ipv4/tcp_keepalive_intvl;net.ipv4.tcp_kee…...

python图片批量下载多线程+超时重试
背景 上篇python入门实战:爬取图片到本地介绍过如何将图片下载到本地,但是实际处理过程中会遇到性能问题:分页数过多下载时间过程、部分页面连接超时无法访问下载失败。本文从实战的角度解释一下如何处理这两个问题。 下载时间过长问题,处理方式是使用多线程,首先回顾…...
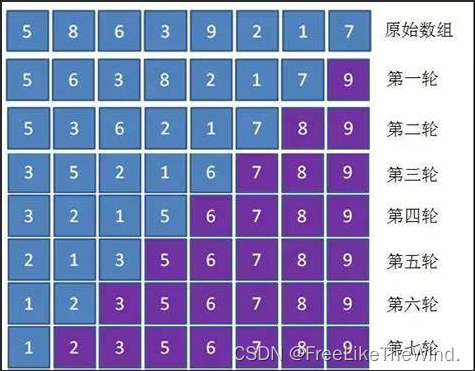
冒泡排序之C++实现
描述 冒泡排序算法是一种简单的排序算法,它通过将相邻的元素进行比较并交换位置来实现排序。冒泡排序的基本思想是,每一轮将未排序部分的最大元素逐个向右移动到已排序部分的最右边,直到所有元素都按照从小到大的顺序排列。 冒泡排序的算法…...

【Spring实战】04 Lombok集成及常用注解
文章目录 0. 集成1. Data2. Getter 和 Setter3. NoArgsConstructor,AllArgsConstructor和RequiredArgsConstructor4. ToString5. EqualsAndHashCode6. NonNull7. Builder总结 Lombok 是一款 Java 开发的工具,它通过注解的方式简化了 Java 代码的编写&…...

Crustocean/conch:云原生容器化应用构建与部署的自动化工具箱
1. 项目概述与核心价值最近在折腾一个很有意思的项目,叫“Crustocean/conch”。光看这个名字,你可能觉得有点摸不着头脑,又是“甲壳海洋”又是“海螺”的。其实,这是一个非常典型的、由开发者社区驱动的开源项目命名风格ÿ…...

2025届最火的十大AI写作平台实际效果
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 在这个信息呈现爆炸态势的时代当中,内容创作已然变成了个人以及企业所具备的核心…...
)
别再乱写Flash了!W25Q128JV SPI Flash寿命管理与日志记录实战(附STM32代码)
W25Q128JV SPI Flash寿命优化与高可靠日志系统设计实战 在嵌入式设备开发中,数据持久化存储是确保设备可靠运行的关键环节。W25Q128JV作为128Mbit容量的SPI Flash存储器,凭借其高性价比和易用性,成为众多嵌入式项目的首选。然而,许…...

终极指南:如何用开源缠论量化工具实现专业级交易可视化
终极指南:如何用开源缠论量化工具实现专业级交易可视化 【免费下载链接】chanvis 基于TradingView本地SDK的可视化前后端代码,适用于缠论量化研究,和其他的基于几何交易的量化研究。 缠论量化 摩尔缠论 缠论可视化 TradingView TV-SDK 项目…...

3分钟搞定Windows和Office永久激活:KMS智能激活工具完整指南
3分钟搞定Windows和Office永久激活:KMS智能激活工具完整指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统频繁弹出激活提示而烦恼吗?Office文档突然…...

免费音频编辑终极指南:Audacity如何让专业音频处理变得简单
免费音频编辑终极指南:Audacity如何让专业音频处理变得简单 【免费下载链接】audacity Audio Editor 项目地址: https://gitcode.com/GitHub_Trending/au/audacity 还在为音频编辑软件的高昂价格而烦恼?是否曾因复杂的音频工具而放弃创作&#x…...

Claude 代码在大型代码库中的运作方式:最佳实践与入门指南
How Claude Code works in large codebases: Best practices and where to start Claude 代码在大型代码库中的运作方式:最佳实践与入门指南 https://claude.com/blog/how-claude-code-works-in-large-codebases-best-practices-and-where-to-start The most succ…...

Bili2Text:3分钟将B站视频转为文字稿,AI语音识别提升学习效率10倍
Bili2Text:3分钟将B站视频转为文字稿,AI语音识别提升学习效率10倍 【免费下载链接】bili2text Bilibili视频转文字,一步到位,输入链接即可使用 项目地址: https://gitcode.com/gh_mirrors/bi/bili2text 还在为无法快速获取…...

Anthropic 百万行代码库的官方最佳实践
随着AI 编程智能体的越来越深入到日常工作,相信你也遇到了大型项目和和小型代码库完全不同的场景。正好最近也是在做大型项目的重构开发,刷到这篇来自 Anthropic 官方的文章。系统梳理了 Claude Code 在大规模代码库中的运作机制、Harness 架构的七个扩展…...

终结摄像头依赖:深度拆解 RuView,用商品化 Wi-Fi 信号构建私密、实时的边缘空间智能
发布日期: 2026-02-15 标签: #无线感知 #WiFi感知 #边缘AI #CSI #生命体征监测 #空间智能 一、 引言 在智能家居、智慧医疗和工业安防的落地过程中,传统的“摄像头方案”始终面临着两大难以调和的工程痛点:隐私泄露的法律风险以…...