云计算与大数据之间的羁绊(期末不挂科版):云计算 | 大数据 | Hadoop | HDFS | MapReduce | Hive | Spark

文章目录
- 前言:
- 一、云计算
- 1.1 云计算的基本思想
- 1.2 云计算概述——什么是云计算?
- 1.3 云计算的基本特征
- 1.4 云计算的部署模式
- 1.5 云服务
- 1.6 云计算的关键技术——虚拟化技术
- 1.6.1 虚拟化的好处
- 1.6.2 虚拟化技术的应用——12306使用阿里云避免了高峰期的崩溃
- 1.6.3 虚拟化的关键特征
- 1.6.4 虚拟化的 HA 指的是什么?
- 1.6.5 服务器虚拟化
- 1.6.6 虚拟机迁移
- 1.6.6.1 虚拟机实时迁移对云计算的意义
- 1.6.7 存储虚拟化
- 1.6.7.1 存储虚拟化的原动力
- 1.6.7.2 什么是存储虚拟化
- 1.6.7.3 存储虚拟化的优势
- 1.6.7.4 存储技术分类
- 1.6.7.5 存储虚拟化的实现方式
- 1.6.8 网络虚拟化
- 1.6.9 桌面虚拟化
- 1.6.9.1 桌面虚拟化的特点
- 二、大数据
- 2.1 什么是大数据?
- 2.2 大数据的特征——4V
- 2.3 大数据的技术支撑
- 2.4 大数据处理方法
- 2.5 大数据关键技术
- 2.6 云计算、大数据、物联网三者之间的关系
- 2.7 大数据计算模式
- 三、开源大数据框架 Hadoop
- 3.1 新方法、新思路
- 3.2 Hadoop 简介
- 3.3 基于 Hadoop 的大数据处理框架
- 3.4 Hadoop 的特征
- 3.5 Hadoop 集群中有哪些节点类型
- 3.6 MapReduce 的分而治之
- 3.7 Hadoop 生态系统
- 四、分布式文件系统HDFS
- 4.1 分布式结构
- 4.2 计算机集群结构
- 4.3 分布式文件系统的结构
- 4.4 HDFS高可靠性的保证——副本冗余机制
- 五、分布式并行计算框架 MapReduce
- 5.1 并行编程之 MapReduce
- 5.2 MapReduce 的核心思想
- 六、Hive
- 七、Spark
- 八、结语
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。
前言:
大数据是需求,云计算是手段。没有大数据,就不需要云计算;没有云计算,就无法处理大数据。
一、云计算
1.1 云计算的基本思想
-
所有的计算能力、存储能力、和各种各样功能的应用都通过网络从云端获得
-
用户不需要不停的更换昂贵的高性能电脑
-
用户不需要购买、安装和维护各种系统和应用软件
-
用户不需要担心数据的安全存储
1.2 云计算概述——什么是云计算?
云计算是一种商业计算模型。它将计算任务分布在大量计算机构成的资源池上,使各种应用系统能够根据需要获取计算力、存储空间和信息服务。

把本地计算机需要进行的计算和存储等工作放到云上去处理。
1.3 云计算的基本特征
-
按需自助服务
-
无处不在的网络接入
-
敏捷的弹性
-
资源池
-
可度量的服务
1.4 云计算的部署模式
-
公有云:面向所有用户提供服务,只要是注册付费的用户都可以使用,比如阿里云和 Amazon AWS。
-
私有云:只为特定用户提供服务,比如大型企业出于安全考虑自建的云环境,只为企业内部提供服务。
-
混合云:综合了公有云和私有云的特点,因为对于一些企业而言,一方面出于安全考虑需要把数据放在私有云中,另一方面又希望可以获得公有云的计算资源,为了获得最佳的效果,就可以把公有云和私有云进行混合搭配使用。
1.5 云服务
云服务是一种商业模式,是基于互联网的相关服务的增加、使用和交付模式,通常涉及通过互联网来提供动态易扩展且经常是虚拟化的资源。

-
基础设施即服务(IaaS):是把计算、存储、网络以及搭建应用环境所需的一些工具当成服务提供给用户,使得用户能够按需获取 IT 基础设施。IaaS 主要由计算机硬件、网络、存储设备、平台虚拟化环境、效用计费方式、服务级别协议等组成。四个业务特征:用户获得的是 IT 资源服务、用户通过网络获得服务、用户能够自助服务、按需计费。优势:用户免部署与维护、经济性(对于用户和服务者提供)、开放标准(跨平台,灵活迁移)、支持应用范围广、伸缩性强。
-
平台即服务(PaaS):是一种分布式平台服务,为用户提供一个包括应用设计、应用开发、应用测试及应用托管的完整的计算机平台。主要是面向互联网应用开发者
-
软件即服务(SaaS):是软件服务提供商为了满足用户的需求提供的软件的计算能力。SaaS 云服务提供商负责维护和管理云中的软件以及支撑软件运行的硬件设施,同时免费为用户提供服务或者以按需使用的方式向用户收费。所以,用户无需进行安装、升级和防病毒等,并且免去了初期的软硬件支出。
小Tips:IT 基础设施资源分为:计算资源、存储资源、网络资源、基础软件资源
1.6 云计算的关键技术——虚拟化技术
虚拟化技术的核心思想是利用软件或固件管理程序构成虚拟化层,把物理资源映射为虚拟资源。在虚拟资源上可以安装和部署多个虚拟机,实现多用户共享物理资源。

虚拟化是云计算最重要的特征之一,基于虚拟化技术可以对存储、计算、网络等物理资源进行池化,资源池化的基础设施更易于实现按需分配的资源调度策略、易于实现资源池的横向扩展。

小Tips:上图是采用虚拟化技术的云计算数据中心的物理拓扑结构
1.6.1 虚拟化的好处
-
提高了硬件资源的利用率
-
提高劳动生产率
-
节省了大量成本
-
降低运维管理成本
1.6.2 虚拟化技术的应用——12306使用阿里云避免了高峰期的崩溃
高并发和高流量一直是需要解决的关键问题。把高频次、高消耗、低转化的余票查询环节放到云端,而将下单、支付这种“小而轻”的核心业务仍然留在 12306 自己的后台系统上,这样的思路为 12306 减负不少。
-
公有云可以为 12306 在高流量时期提供了充足的空间,避免了因为高并发的流量冲击导致的宕机。
-
在请求次数减少时,可以缩减公有云,这样就节省了成本开支。
-
除此之外,将余票查询(而非核心系统)托管在公有云上,还能避免敏感性资料的泄露,保护用户数据的安全。
1.6.3 虚拟化的关键特征
-
兼容性:虚拟机完全兼容标准的操作系统,以及在这些操作系统之上建立的硬件驱动和应用
-
隔离:每一个虚拟机都与同在一个服务器上的其他虚拟机相隔离。从软件角度来看,互相隔离的虚拟机之间保持独立,如同一个完整的计算机;从硬件角度讲,被隔离的虚拟机相当于一台物理机,有自己的 CPU、内存、硬盘、I/O 等,它们与宿主机之间保持相互独立的状态;从网络角度讲,被隔离的虚拟机如同物理机一样,既可以对外提供网络服务,也一样可以从外界接受网络服务。
-
封装:虚拟机将整个系统,包括硬件配置、操作系统以及应用等封装在文件里
-
硬件独立:可以在其他服务器上不加修改的运行虚拟机
1.6.4 虚拟化的 HA 指的是什么?
HA(高可靠性)就是发生服务器故障时,在其他的物理服务器上自动重启虚拟机,从而减少停工的时间,而保证其服务的高度可用性。总结:通过 HA 可以方便的提高任何应用的高可用性。
客户优势:对所有的应用实现了高可用性,并且成本很低;不需要完全一致的重复硬件;比传统的集群有更高的成本优势,同时易于使用和操作。
1.6.5 服务器虚拟化
将一个或多个物理服务器虚拟成多个逻辑上的服务器,集中管理,能跨越物理平台不受限制。

服务器虚拟化的两个方向:
-
一种是把一个物理的服务器虚拟成若干个独立的逻辑服务器。
-
另一种是把若干分散的物理服务器虚拟化为一个大的逻辑服务器,比如网格技术,Hadoop 大数据技术。

根据虚拟化层实现方式的不同分为寄居虚拟化和裸机虚拟化两种。


服务器虚拟化的底层实现:CPU 虚拟化、内存虚拟化、I/O 虚拟化。
1.6.6 虚拟机迁移
将虚拟机实例从源宿主机迁移到目标宿主机,并且在目标宿主机上能够将虚拟机运行状态恢复到其在迁移之前相同的状态,以便能够继续完成应用程序的任务。
1.6.6.1 虚拟机实时迁移对云计算的意义
-
云计算中心的物理服务器负载经常处于动态变化中,当一台物理服务器负载过大时,若此刻不能提供额外的服务器,管理员可以将其上面的虚拟机迁移到其他服务器,达到负载平衡。
-
云计算中心的物理服务器有时候需要定期进行升级维护,当升级维护服务器时,管理员可以将其上面的虚拟机迁移到其他服务器,等升级维护完成后,再把虚拟机迁移回来,实现升级维护时业务不中断的目标。
1.6.7 存储虚拟化
存储虚拟化是一种贯穿于整个 IT 环境、用于简化本来可能会相对复杂的底层基础架构的技术。存储虚拟化的思想是:将资源的逻辑映像与物理存储分开,从而为系统和管理员提供一副简化、无缝的资源虚拟试图。

1.6.7.1 存储虚拟化的原动力
-
标准化接入:能够使不同的存储器按标准的方式接入到存储设备。
-
统一数据管理:能够在统一的空间资源整合基础上,提供复制功能,快照功能,迁移功能,镜像功能,能够实现跨设备、跨地域的资源迁移,使数据可以在不同品牌、不同设备之间进行自由流动。
-
空间资源整合:把这些空间资源(异构资源)进行整合,进行统一的调度和管理。
1.6.7.2 什么是存储虚拟化
存储虚拟化是指将存储网络中各个分散且异构的存储设备按照一定的策略映射成一个统一的连续编制的逻辑存储空间,称为虚拟存储池,并将虚拟存储池的访问接口提供给应用系统。

小Tips:虚拟化层的作用是提供了虚拟化的逻辑卷与底层的物理设备间的一种映射操作;屏蔽掉所有存储设备的物理特性。
1.6.7.3 存储虚拟化的优势
-
存储虚拟化将系统中分散的存储资源整合起来。
-
在虚拟层通过使用数据镜像,数据校验和多路径等技术提高了数据的可靠性及系统的可用性。
-
利用负载均衡、数据迁移、数据块重组等技术提升系统的潜在性能。
-
整合和重组底层物理资源。
1.6.7.4 存储技术分类
-
磁盘阵列(RAID):磁盘阵列是由很多块独立的磁盘,组合成一个容量巨大的磁盘组,利用个别磁盘提供数据所产生的加成效果提升整个磁盘系统效能。利用这项技术,将数据切割成许多区段,分别存放在各个硬盘上。RAID 技术把多个物理磁盘用阵列的形式,通过一定的逻辑关系结合,成为一个大容量的虚拟磁盘
-
网络附属存储(网络存储器 NAS ):一种专用数据存储服务器。以数据为中心,将存储设备与服务器彻底分离,集中管理数据,从而释放带宽、提高性能、降低总拥有成本、保护投资;其成本远远低于使用服务器存储,而效率却远远高于后者。
-
存储区域网络(SAN):专门为存储建立的独立于 TCP/IP 网络之外的专用网络。存储容量大,速度快。

1.6.7.5 存储虚拟化的实现方式
-
基于主机的存储虚拟化:当仅需要单个主机服务器访问多个磁盘阵列时,可以使用基于主机的存储虚拟化技术。
-
基于存储设备的存储虚拟化:当有多个主机服务器需要访问同一个磁盘阵列时,可以使用基于存储设备的存储虚拟化技术。
-
基于网络的存储虚拟化:当多个主机服务器需要访问多个异构存储设备时,可以使用基于网络的存储虚拟化技术。
1.6.8 网络虚拟化
网络虚拟化是让一个物理网络能够支持多个逻辑网络,虚拟化保留了网络设计中原有的层次结构、数据通道和所能提供的服务,使得最终用户的体验和独享物理网络一样,同时网络虚拟化技术还可以高效的利用网络资源,如空间、能源、设备容量等。网络虚拟化的目的是:在不改变传统数据中心这个网络的物理拖布结构的前提下,实现网络的整合。
1.6.9 桌面虚拟化
桌面虚拟化是指将计算机的终端系统(也称作左面)进行虚拟化,以达到桌面使用的安全性和灵活性。可以通过任何设备,在任何地点,任何时间通过网络访问属于我们个人的砖面系统。
1.6.9.1 桌面虚拟化的特点
-
快速、灵活部署
-
提高资源利用率
-
数据存放安全可靠
-
维护便利
-
节能减排
二、大数据
2.1 什么是大数据?
海量数据或巨量数据,其规模巨大到无法通过目前主流的计算机系统在合理的时间内获取、存储、管理处理并提炼以帮助使用者决策。大数据——挖掘和整合一切有用的信息,为人类社会提供更好的服务。
2.2 大数据的特征——4V
-
数据量大
-
数据类型繁多
-
处理速度快
-
价值密度低(价值高)
2.3 大数据的技术支撑
-
存储:存储成本的下降
-
计算:运算速度越来越快
-
智能:机器拥有理解数据的能力
2.4 大数据处理方法
-
大数据的采集:数据抓取、数据导入、物联网传感设备自动信息采集
-
导入/预处理:数据清理、数据集成、数据变换、数据归约
-
数据分析:三大作用:现状分析、原因分析、预测分析。方法:对比分析、分组分析、交叉分析、回归分析。
-
数据挖掘:是创建数据挖掘模型的一组试探法和计算方法,通过对提供的数据进行分析,查找特定类型的模型和趋势,最终形成创建模型。基本方法:预测建模、关联分析、聚类分析、异常检测。
2.5 大数据关键技术
-
数据采集与预处理
-
数据存储和管理
-
数据处理与分析
-
数据隐私和安全
2.6 云计算、大数据、物联网三者之间的关系
云计算为大数据提供了技术基础,大数据为云计算提供了用武之地;物联网是大数据的重要来源,大数据技术为物联网数据分析提供支撑;云计算为物联网提供海量数据存储的能力,物联网为云计算技术提供了广阔的应用空间。

2.7 大数据计算模式
-
批处理计算:针对大规模数据的批量处理
-
流计算:针对流数据实时计算
-
图计算:针对大规模图结构数据的处理
-
查询分析计算:大规模数据的存储管理和查询分析
三、开源大数据框架 Hadoop

MapReduce:是由 Google 开发的一个针对大规模群组中的海量数据处理的分布式编程模型。
BigTable:是 Google 设计的分布式数据存储系统,是用来处理海量数据的一种非关系型数据库。
Google 文件系统(GFS):是构建在廉价的服务器之上的大型分布式系统。为 Google 大数据处理系统提供海量的存储,并且与 MapReduce 和 BigTable 等技术结合的十分紧密,GFS 处于系统的底层。
3.1 新方法、新思路
- 分而治之

- 分布式文件存储

- 分布式并行计算模式

- 计算靠近数据

3.2 Hadoop 简介
Hadoop 是 Apache 软件基金会旗下的一个开源分布式计算平台,为用户提供了系统底层细节透明的分布式基础架构。Hadoop 是基于 Java 语言开发的,具有很好的跨平台特性,并且可以部署在廉价的计算集群中。Hadoop 的核心是分布式文件系统 HDFS 和 MapReduce。Hadoop 被公认为行业大数据标准开源软件,在分布式环境下提供了海量数据处理能力。

3.3 基于 Hadoop 的大数据处理框架
-
平台管理层:确保整个数据处理平台平稳安全运行的保障,包括配置管理、运行监控、故障管理、性能优化、安全管理等在内的功能。
-
数据分析层:提供一些高级的分析工具给数据分析人员,以提高他们的生产效率。
-
编程模型层:为大规模数据处理提供一个抽象的并行计算编程模型,以及为此模型提供可实施的编程环境和运行环境。
-
数据存储层:提供分布式、可扩展的大量数据表的存储和管理能力,强调的是在较低成本条件下实现海量数据表的管理能力。
-
文件存储层:利用分布式文件系统技术,将底层数量众多且分布在不同位置的通过网络连接的各种存储设备组织在一起,通过统一的接口向上层应用提供对象级文件访问服务能力。
-
数据继承层:系统需要处理的数据来源,包括私有的应用数据、存放在数据库中的数据、被分析系统运行产生的日志数据等,这些数据具有结构多样、类型多变的特点。

3.4 Hadoop 的特征
Hadoop 是一个能够对大量数据进行分布式处理的软件框架,并且是以一种可靠、高效、可伸缩的方式进行处理的,它具有以下几个方面的特征:高可靠性、高效性、高可扩展性、高容错性、成本低、运行在 Linux 平台上、支持多种编程语言。
3.5 Hadoop 集群中有哪些节点类型
-
NameNode:中心服务器,负责管理文件系统的名字空间以及客户端对文件的访问。执行文件系统的名字空间操作,如打开、关闭、重命名文件或目录。也负责确定数据块到具体的 DataNode 节点的映射。
-
DataNode:负责管理它所在节点上的存储。负责处理文件系统客户端的读写请求,在 NameNode 的调度下进行数据块的创建、删除和复制。
-
SecondaryNameNode:帮助 NameNode 收集文件系统运行的状态信息。
-
ResourceManager:是 Yarn 集群主控节点,负责协调和管理整个集群(所有 NodeManager)的资源。
-
NodeManager:管理一个 Yarn 集群中的每个节点,负责执行有由 RsourceManage 指派的任务。
小Tips:其中前三个是和 HDFS 有关的守护进程,后两个是和 MapReduce 有关的守护进程。

小Tips:上图是 Hadoop 完全分布式集群的主从节点及对应的守护进程。这张图中,master 节点既做主节点,又做从节点,因此这个集群中有一个主节点,三个从节点。伪分布式的运行模式是在单台服务器上模拟 Hadoop 的完全分布式,并不是真正的分布式,而是使用线程模拟的分布式。在这个模式中,所有的守护进程(NameNode、DataNode、ResourceManager、NodeManager、SecondaryNameNode)都在同一台机器上运行。此种模式除了并非真正意义上的分布式之外,其执行逻辑完全类似于完全分布式,因此,常用于开发人员测试程序执行。
3.6 MapReduce 的分而治之
Map 是映射,Reduce 是规约。

3.7 Hadoop 生态系统


Hadoop 在企业中的一种典型应用架构,如下图所示:

小Tips:Hadoop Eclipse 插件,它可以直接嵌入到 Hadoop 开发环境中,从而实现了开发环境的图形化界面,降低了编程的难度。
四、分布式文件系统HDFS
4.1 分布式结构
集群:集群就是逻辑上处理同一任务的机器集合,可以属于同一机房,也可分属不同的机房。
分布式:分布式文件系统把文件分布存储到多个计算机节点上,成千上万的计算机节点构成计算机集群。

4.2 计算机集群结构
与之前使用多个处理器和专用高级硬件的并行化处理装置不同的是,目前的分布式文件系统所采用的计算机集群,都是由普通硬件构成的,这就大大降低了硬件上的开销。

4.3 分布式文件系统的结构
分布式文件系统在物理结构上是由计算机集群中的多个节点构成的,这些节点分为两类,一类叫“主节点”(Master Node)或者也被称为“名称节点”(NameNode),另一类叫“从节点”(Slave Node)或者也被称为“数据节点”(DataNode)。

HDFS 是一个大规模的分布式文件系统,采用 master/slave 架构,一个 HDFS 集群是有一个 NameNode 和一定数目的 DataNode 组成。

-
NameNode:是一个中心服务器,负责管理文件系统的名字空间和客户端对文件的访问。NameNode 执行文件系统的名字空间操作,比如打开、关闭、重命名文件或目录,负责确定的数据块到 DataNode 节点的映射。
Hadoop 集群中的节点及对应的守护进程,如下图所示:

4.4 HDFS高可靠性的保证——副本冗余机制
HDFS 为了做到高可靠性,创建了多份数据块的复制,并将它们放置在服务器群的计算节点中,MapReduce 就可以在它们所在的节点上处理这些数据了。



五、分布式并行计算框架 MapReduce
5.1 并行编程之 MapReduce

5.2 MapReduce 的核心思想
分而治之,一个存储在分布式文件系统 HDFS 中的大规模数据集,会被切分成许多独立的分片,即:一个大任务分成多个小的子任务(map),由多个节点进行并行执行,并行执行后,合并结果(reduce)。MapReduce 采用的是“分而治之”的思想,把对大规模数据集的操作,分发给一个主节点管理下的各个从节点完成,然后通过整合各个节点的中间结果,得到最终结果。简单来说,MapReduce 就是“任务的分解与结果的汇总”。
小Tips:适合使用 MapReduce 来小处理的数据集需要满足一个前提条件:一个大数据若可以分为具有同样计算过程的数据块,并且这些数据块之间不存在数据依赖关系,则提高处理速度的最好办法就是并行计算。
六、Hive










七、Spark







八、结语
今天的分享到这里就结束啦!如果觉得文章还不错的话,可以三连支持一下,春人的主页还有很多有趣的文章,欢迎小伙伴们前去点评,您的支持就是春人前进的动力!

相关文章:
云计算与大数据之间的羁绊(期末不挂科版):云计算 | 大数据 | Hadoop | HDFS | MapReduce | Hive | Spark
文章目录 前言:一、云计算1.1 云计算的基本思想1.2 云计算概述——什么是云计算?1.3 云计算的基本特征1.4 云计算的部署模式1.5 云服务1.6 云计算的关键技术——虚拟化技术1.6.1 虚拟化的好处1.6.2 虚拟化技术的应用——12306使用阿里云避免了高峰期的崩…...

基于jdk11和基于apache-httpclient的http请求工具类
1.基于apache-httpclient 需要引入依赖 <dependency><groupId>org.apache.httpcomponents</groupId><artifactId>httpclient</artifactId><version>4.3.5</version></dependency> 工具类如下: package com.bw.e…...

Node.js(二)-模块化
1. 模块化的基本概念 1.1 什么是模块化 模块化是指解决一个复杂问题时,自顶向下逐层将系统拆分成若干模块的过程。对于整个系统来说,模块是可组合、分解和更换的单元。 1.2 编程领域中的模块化 编程领域中的模块化,就是遵守固定的规则&…...
)
ARM AArch64的TrustZone架构详解(上)
目录 一、概述 1.1 在开始之前 二、什么是TrustZone? 2.1 Armv8-M的TrustZone 2.2 Armv9-A Realm Management Extension(RME)...
的构想)
从源PC上一次性p2v(qcow2)的构想
磁盘分区表,虚拟硬盘文件,操作系统引导 1. 基本概念和术语 源硬盘:一般就是客户的PC机的硬盘,硬盘里面包含了Windows分区。 源Windows:以源硬盘启动的Windows环境。 虚拟磁盘文件:文件格式有qcow2、vhd…...

数据结构:KMP算法
1.何为KMP算法 KMP算法是由Knuth、Morris和Pratt三位学者发明的,所以取了三位学者名字的首字母,叫作KMP算法。 2.KMP的用处 KMP主要用于字符串匹配的问题,主要思想是当出现字符串不匹配时,我们可以知道一部分之前已经匹配过的的文…...
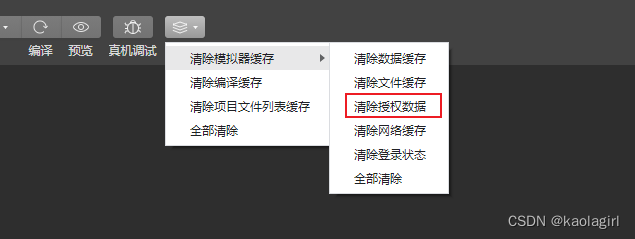
小程序真机如何清除订阅数据
在做小程序订阅消息开发的过程中发现,真机上如果是选择了‘总是保持以上选择’,一旦用户授权后,后面就不会再弹出申请改订阅消息的授权弹窗,这对于开发过程中是很不方便的。 曾试过清除缓存,重进小程序也不能清除掉 解…...
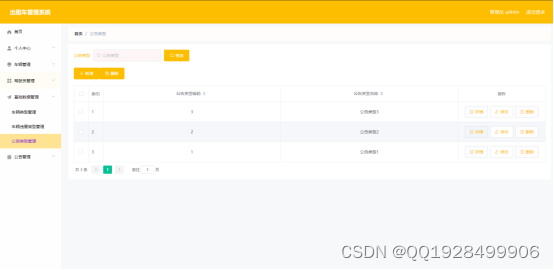
基于ssm出租车管理系统的设计与实现论文
摘 要 现代经济快节奏发展以及不断完善升级的信息化技术,让传统数据信息的管理升级为软件存储,归纳,集中处理数据信息的管理方式。本出租车管理系统就是在这样的大环境下诞生,其可以帮助管理者在短时间内处理完毕庞大的数据信息&…...

音视频转码
音视频转码是指: 容器中音视频数据编码方式转换,如由H.264编码转成mpeg-4编码,mp3转成AAC;音视频码率的转换,如4Mb视频码率降为2Mb,视频分辨率的转换,如1080P转换为720P,音频重采样…...
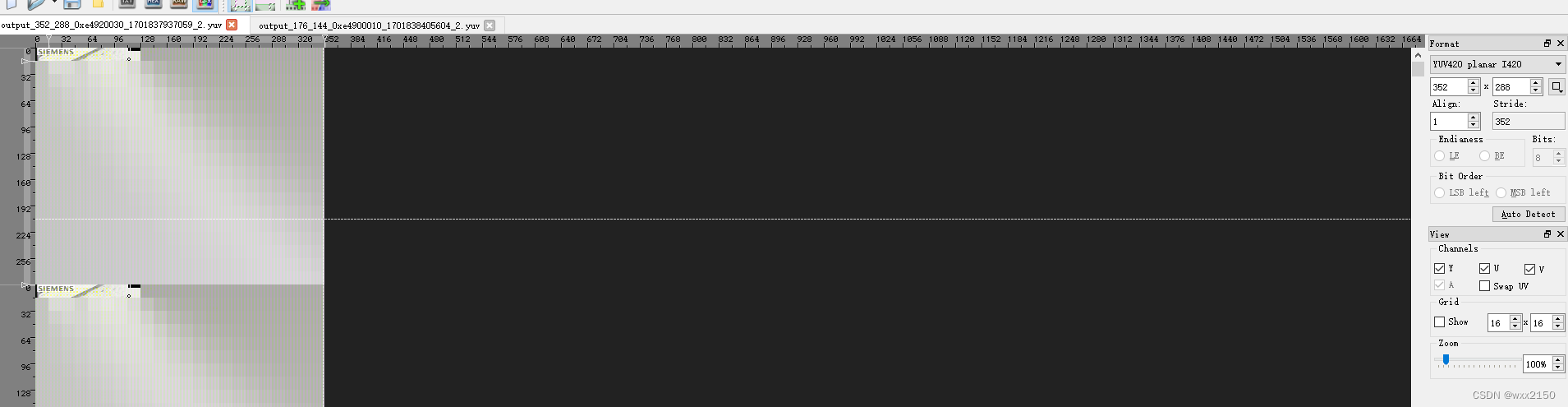
编解码异常分析
前言 最近在做的项目,有H264解码的需求。部分H264文件解码播放后,显示为绿屏或者花屏。 分析 如何确认是否是高通硬解码的问题 adb 指令 adb root adb remount adb shell setenforce 0 adb shell setprop vendor.gralloc.disable_ubwc 1 adb shell c…...

APISpace 热门好用的API推荐,含免费次数
短信验证码:可用于登录、注册、找回密码、支付认证等等应用场景。支持三大运营商,3秒可达,99.99%到达率,支持大容量高并发。通知短信:短信通知支持三大运营商以及虚拟运营商,我们提供电信级运维…...
)
Qt/QML编程学习之心得:一个.qml文件调用另一个.qml文件(十七)
在c++中,一个文件调用另外一个文件最直接最快捷的方式就是#incldue<头文件>的使用,那么在元数据描述性语言QML中,如何从一个界面描述调用另外一个界面描述,一个.qml文件调用另外一个.qml呢?QML虽然有个import,但是用法可以说完全不同于#include。 引用方法1:直接…...

C++_单列模式介绍
介绍 (1)…什么是单例 1.只能有一个实例化的对象的类(2).单例有什么用 1.多线程的线程池的设计 2.系统中只需要一个窗口时才使用单例(无法重复创建) 3.一个操作系统只能有一个文件系统(3).单例怎么用 1.隐藏所有构造函数 2.静态成员内部调用构造函数实例化 3.提供一个静态函数来…...

油烟净化器如何做到高效净化?科技力量,清新餐饮生活
我最近分析了餐饮市场的油烟净化器等产品报告,解决了餐饮业厨房油腻的难题,更加方便了在餐饮业和商业场所有需求的小伙伴们。 油烟净化器的出现,为我们的餐饮生活注入了一抹清新的色彩。然而,它究竟是如何工作的?为何能…...

【HTML5】HTML5 语音合成
一、前言 前一段时间在项目中需要用到播报文字语音。找到了 HTML 5 有这样的功能。 现在有时间进行总结下。 二、SpeechSynthesis SpeechSynthesis 接口是语音服务的控制接口。它可以用于获取设备上关于可用的合成声音的信息, 开始、暂停语音,或者别…...

顺序表的实现
目录 一. 数据结构相关概念 二、线性表 三、顺序表概念及结构 3.1顺序表一般可以分为: 3.2 接口实现: 四、基本操作实现 4.1顺序表初始化 4.2检查空间,如果满了,进行增容编辑 4.3顺序表打印 4.4顺序表销毁 4.5顺…...
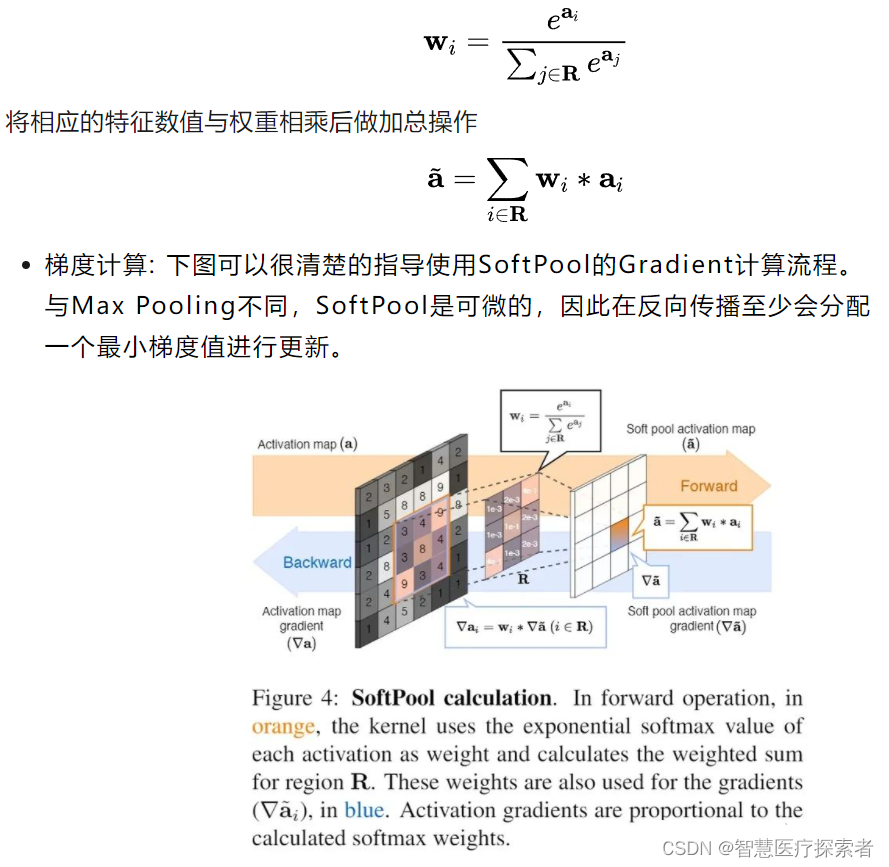
深度学习中的池化
1 深度学习池化概述 1.1 什么是池化 池化层是卷积神经网络中常用的一个组件,池化层经常用在卷积层后边,通过池化来降低卷积层输出的特征向量,避免出现过拟合的情况。池化的基本思想就是对不同位置的特征进行聚合统计。池化层主要是模仿人的…...

Java面试整理-Java设计模式
Java中的设计模式通常是从更广泛的面向对象设计模式中借鉴而来的,这些模式旨在解决特定的设计问题和改善代码的可维护性、灵活性和可扩展性。设计模式大致可以分为三类:创建型、结构型和行为型。以下是这三类中一些常见的设计模式: 创建型模式 单例模式(Singleton):确保一…...

用CHAT了解更多知识点
问CHAT:什么是硅基生命和碳基生命? CHAT回复:硅基生命和碳基生命是两种理论性的生物体类型,这些生物体主要是由硅或碳元素以及其他元素构成的。 碳基生命是我们当前所熟知的生命形式。碳元素能够形成稳定且复杂的分子,…...
一个利用摸鱼时间背单词的软件
大家好,我是 Java陈序员。 最近进入了考试季,各种考试,英语四六级、考研、期末考等。不知道大家的英语四六级成绩怎么样呢? 记得大学时,英语四级都是靠高中学习积累的老本才勉强过关。 而六级则是考了多次ÿ…...
的开发详解五:SigmaStudio实战技巧与模块高效应用)
ADAU1701(含A2B)的开发详解五:SigmaStudio实战技巧与模块高效应用
1. SigmaStudio模块查找的终极技巧 第一次打开SigmaStudio时,面对左侧密密麻麻的模块列表,我完全懵了。就像走进一个巨大的图书馆却找不到分类标签,ADI把200多个算法模块分散在30多个分类里,光Volume Controls下面就有12种音量调节…...

不只是跑通:用D435i和VINS-Mono做个室内小车的视觉里程计demo
从D435i到移动机器人:VINS-Mono室内视觉里程计实战指南 当Intel RealSense D435i深度相机遇上VINS-Mono这个轻量级视觉惯性里程计框架,我们能在一台简易ROS小车上实现怎样的定位与建图效果?本文将带你从硬件连接开始,逐步完成传感…...

GoPaw框架解析:基于Go的高性能网络任务调度与并发处理实践
1. 项目概述与核心价值最近在折腾一个需要处理大量网络请求和并发任务的小工具,偶然间在GitHub上看到了一个叫GoPaw的项目,作者是Aragorn271828。这个项目名挺有意思,Paw是爪子的意思,GoPaw直译过来就是“Go爪子”,听起…...

QtScrcpy:将手机屏幕变成电脑扩展屏的终极解决方案
QtScrcpy:将手机屏幕变成电脑扩展屏的终极解决方案 【免费下载链接】QtScrcpy Android实时投屏软件,此应用程序提供USB(或通过TCP/IP)连接的Android设备的显示和控制。它不需要任何root访问权限 项目地址: https://gitcode.com/barry-ran/QtScrcpy …...

基于Belullama框架构建可定制化本地AI模型服务:从原理到实践
1. 项目概述:一个本地化、可定制的AI对话模型部署方案最近在折腾本地AI部署的朋友,可能都绕不开一个名字:Ollama。它确实让拉取和运行各种开源大模型变得像docker pull一样简单。但不知道你有没有遇到过这样的困扰:Ollama默认的AP…...

87456238
8637452...

告别手动写测试报告:用AI自动生成可视化测试总结
测试报告的价值困境与破局在软件交付的最后关头,测试报告往往陷入一种尴尬的境地。一方面是倒计时的上线压力,另一方面是堆积如山的测试数据。许多测试工程师都有过这样的经历:打开Excel,机械地复制用例执行数、通过率、缺陷数&am…...

D2DX暗黑2宽屏补丁:3分钟让经典游戏焕发新生的终极优化方案
D2DX暗黑2宽屏补丁:3分钟让经典游戏焕发新生的终极优化方案 【免费下载链接】d2dx D2DX is a complete solution to make Diablo II run well on modern PCs, with high fps and better resolutions. 项目地址: https://gitcode.com/gh_mirrors/d2/d2dx 还在…...

PangoDesign Suite与Modelsim协同仿真:从库编译到实战排错全解析
1. 为什么需要PangoDesign Suite与Modelsim协同仿真 第一次接触FPGA仿真时,我也被各种专业术语绕晕了。直到某次项目出现时序问题,才发现仿真工具就像汽车的"安全气囊"——平时感觉不到存在,关键时刻能救命。PangoDesign Suite&…...

Python金融数据获取终极指南:3分钟掌握同花顺问财数据获取
Python金融数据获取终极指南:3分钟掌握同花顺问财数据获取 【免费下载链接】pywencai 获取同花顺问财数据 项目地址: https://gitcode.com/gh_mirrors/py/pywencai 想要快速获取高质量的金融数据吗?pywencai是你的完美解决方案。这个Python工具让…...