(2023|CVPR,Corgi,偏移扩散,参数高斯分布,弥合差距)用于文本到图像生成的偏移扩散
Shifted Diffusion for Text-to-image Generation
公众:EDPJ(添加 VX:CV_EDPJ 或直接进 Q 交流群:922230617 获取资料)
目录
0. 摘要
1. 简介
2. 方法
2.1 偏移扩散
3. 实验
3.1 无监督文本到图像生成
3.2 无语言文本到图像生成
3.3 消融研究
4. 结论
S. 总结
S.1 主要贡献
S.2 架构和方法
0. 摘要
我们介绍 Corgi,这是一种用于文本到图像生成的新方法。Corgi 基于我们提出的偏移扩散模型,该模型在从输入文本生成图像嵌入方面表现更好。与 DALL-E 2 中使用的基线扩散模型不同,我们的方法通过设计新的初始化分布和扩散的新转移步骤,在其扩散过程中无缝地编码了预训练的 CLIP 模型的先验知识。与强大的 DALL-E 2 基线相比,我们的方法在以效率和效果两方面生成文本到图像嵌入方面表现更好,从而实现更好的文本到图像生成。进行了大规模的实验证明,从定量指标和人类评估的角度来看,我们的方法具有比现有方法更强的生成能力。此外,我们的模型实现了文本到图像生成的半监督和无语言训练,其中训练数据集中只有部分或没有图像与标题相关联。在仅有 1.7% 的图像被加上标题的情况下进行训练,我们的半监督模型在 MS-COCO 上进行的零样本文本到图像生成评估中获得了与 DALL-E 2 相媲美的 FID 结果。Corgi 还在下游无语言文本到图像生成任务的不同数据集上取得了新的最先进结果,大幅超过了先前的方法 Lafite。
代码可在 https://github.com/drboog/Shifted_Diffusion 获取。
1. 简介
“人工智能生成的内容” 由于近期在高保真度文本对齐图像合成任务方面的显著进展而引起越来越多的公众关注 [7, 20–23, 26, 32]。 特别是,在大规模网络数据集上训练的模型展示了它们生成分布外图像的印象深刻能力,这些图像来自于描述视觉概念未曾见过的文本输入。
从 DALL-E [21] 开始,研究人员提出了各种方法来进一步推动文本到图像生成的最新技术(SOTA),无论是在生成质量还是效率方面。潜在扩散模型(Latent Diffusion Model,LDM) [22] 在自动编码器的潜在空间而不是像素空间中训练扩散模型,从而提高了生成效率。GLIDE [15] 采用分辨率不同的扩散模型组成的分层架构。这种模型设计策略已被证明是有效的,并已被许多后续工作采纳。DALL-E 2 [20] 进一步引入了额外的图像嵌入输入。这样的图像嵌入不仅提高了模型在文本到图像生成方面的性能,还使得一些应用成为可能,包括图像到图像的生成和在多模态条件下的生成。Imagen [23] 利用了丰富的预训练文本编码器 [19],证明了在大规模文本数据集上预训练的冻结文本编码器可以帮助文本到图像生成模型理解文本描述的语义。Parti [32] 展示了生成模型的进一步成功扩大,以 transformer 结构在文本到图像一致性方面取得了显著的改进。
前述方法集中在通过扩大可训练/冻结模块或设计更好的模型架构来改善文本到图像生成。在这项工作中,我们探索了一个正交的方向,我们提出了新颖的技术来改进扩散过程本身,并使其更适合和更有效地用于文本到图像生成。
具体而言,我们提出了 Corgi(Clip-based shifted diffusiOn model bRidGIng the gap),这是一种为灵活的文本到图像生成而设计的新型扩散模型。我们的模型可以在所有监督、半监督和无语言的设置下执行文本到图像生成。通过 “弥合差距”,我们强调我们方法中的两个关键创新:(1)我们的模型试图弥合图像文本模态差距 [12],以便训练一个更好的生成模型。模态差距是在预训练模型(如 CLIP [17])中发现的一个关键概念,它捕捉到多模态表示在联合嵌入空间中不对齐的现象。通过 Corgi,我们可以更好地利用 CLIP 进行文本到图像生成,在实验中显示出更好的生成效果;(2)我们的模型弥合了不同研究人员/社区的数据可用性差距。在我们的设计中,Corgi 可以自然地实现半监督和无语言的文本到图像生成,其中训练数据集中只有很小一部分,甚至没有图像被加上标题。这是重要的,因为构建高质量大规模的图像-文本配对数据集的成本可能是禁止性的,特别是在需要给数亿张图像加标题的情况下。我们展示了使用仅包含图像的数据集和公共 CC15M 数据集 [2,25],Corgi 在开放域文本到图像生成任务上实现了可比较的令人满意的结果,与 SOTA 模型相当。总结一下,我们的贡献有:
- 我们提出了 Corgi,一种新颖的扩散模型,能够无缝地将预训练模型(例如 CLIP)的先验知识整合到其扩散过程中;
- 我们的方法是通用的,可以应用于文本到图像生成的不同设置,例如,它自然地实现了半监督和无语言的文本到图像生成;
- 进行了广泛而大规模的实验。定量和定性结果都说明了所提方法的有效性。我们特别展示了,在训练数据集中只有 1.7% 的带标题图像的情况下,仍然可以实现与 SOTA 方法相媲美的结果。此外,我们的模型在不同下游数据集上在无语言设置下取得了 SOTA 结果。
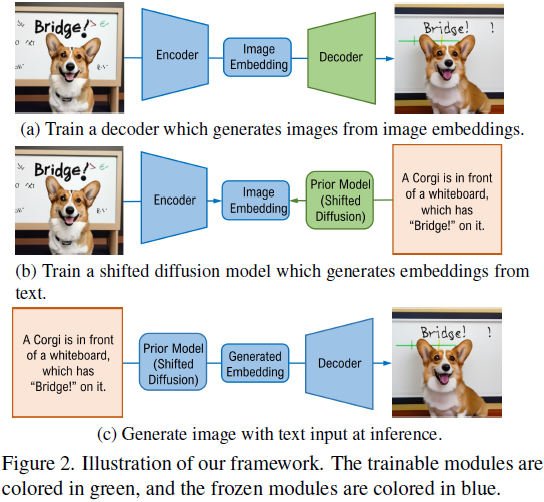
2. 方法
我们首先说明了用于文本到图像生成的通用框架。我们的框架如图 2 所示,由三个关键组件组成:(1)一个预训练的图像编码器,将图像映射到它们的嵌入;(2)一个从相应的嵌入生成图像的解码器;以及(3)一个从相应的文本标题生成图像嵌入的先验模型。在我们的实现中,我们使用预训练的 CLIP 图像编码器,因为其输出空间是一个多模态嵌入空间,已经证明有助于文本到图像生成任务 [35]。解码器可以是扩散模型或生成对抗网络(GAN)。需要注意的是,如果将解码器选择为分层扩散模型,并将其条件设置为图像和文本的嵌入,我们的最终结构将类似于 DALL-E2 [20]。
我们采用这个框架是因为它的灵活性:它可以执行不同类型的生成任务,如文本到图像生成、图像到图像生成以及基于图像和文本的生成。此外,我们的框架自然地实现了半监督训练,即训练数据集可以是图像-文本对和未加标题的纯图像的混合。在这种设置中,图像-文本对将用于训练先验模型,而所有纯图像将用于训练解码器。这样的半监督训练设置在实践中是重要的,特别是在用有限预算训练新域的文本到图像生成模型时。正如在 [35] 中讨论的那样,构建高质量的图像-文本对可能非常昂贵,并需要大量人力。我们的框架为社区提供了根据预算选择要加标题的图像数量的灵活性。正如在实验中将会展示的那样,半监督训练可以获得令人印象深刻的结果,甚至与监督训练相媲美。
在本文中,我们专注于改进先验模型,这在先前的研究中受到较少的开发。正如在 DALL-E 2 [20] 中所示,引入了基于扩散的先验模型,通过以下顺序抽样过程生成目标 CLIP 图像嵌入 z_0:z_(t-1) ∼ p_θ(z_(t-1) | z_t, y) 对于 t = T,…,1,其中 z_T ∼ N(0, I),t 表示时间步,y 表示文本标题,pθ(·|·) 是从扩散模型引出的逆转移分布。尽管在 [20] 中显示出这种先验模型在图像-文本对齐和图像保真度方面有益,但我们怀疑这种普通的抽样过程可能不适用于生成高质量的 CLIP 图像嵌入(图像嵌入是解码器的输入,从而极大地影响生成质量)。原因在于,正如在 [12] 中揭示的那样,CLIP 图像编码器的有效输出空间实际上是整个嵌入空间的一个非常小的区域,如图 3 所示。因此,z_T ∼ N(0, I),这是抽样的起点,可能远离目标嵌入。直观地说,如果 z_T 更接近目标 z_0,我们可能能够在较少的采样步骤内很好地逼近 z_0。同样,如果初始化更接近目标,我们可以在相同数量的步骤内更好地逼近目标。
基于这一动机,我们提出了偏移扩散,一种考虑了预训练 CLIP 图像编码器中包含的先验知识的新型扩散模型。具体而言,偏移扩散的噪声分布 p(z_T) 是一个参数分布,而不是标准的高斯分布 N(0, I)。我们在以下部分详细介绍我们的方法。
2.1 偏移扩散
让 q(z_0) 是 CLIP 模型的联合潜在空间中真实图像嵌入的分布。由于有效图像嵌入仅占整个嵌入空间的一小部分 [12],为了在扩散过程中实现更好的生成,我们希望构建一个新的 p(z_T),与标准的高斯分布相比,该分布预计与 q(z_0) 更相似。然而,由于 q(z_0) 是一个难以处理的分布,基于它进行扩散模型的训练变得具有挑战性。
为了解决上述问题,我们考虑将初始分布 p(z_T) 视为参数高斯分布,即 N(z_T ;μ,Σ),可以通过简单地分析训练数据集获得(在实践中,我们将 Σ 设置为一个对角矩阵,其中其元素 Σᵢ,ᵢ = κσᵢ。其中,σᵢ 是训练数据集中所有图像嵌入的第 i 个元素的标准差,κ > 0 是一个用于缩放的常数。)。我们设计转移 q(z_t | z_(t-1) ) 为高斯分布,如下所示:
![]()
其中,β_t 是一个常数,按照 [8] 的方式确定。与普通的扩散
![]()
相比,我们的扩散过程在每个时间步 t 引入了一个偏移项 s_t,因此被称为偏移扩散。可以证明 q(z_t | z_0) 具有封闭形式的表达式(所有证明均在附录中提供):

![]()
特别地,我们选择 s_t =
![]()
因此,
![]()
备注 1:如我们所见,通过选择
![]()
使得 α_T ≈ 0,q(z_T | z_0) 可以近似 N(z_T ;μ,Σ),即图像嵌入的分布(参数高斯分布)。换句话说,偏移扩散过程是一个真实图像嵌入转换为随机图像嵌入的过程;而普通扩散过程是一个将图像嵌入转换为随机高斯噪声的过程,这显然不是我们期望的结果。
从方程(1)和(2)中,我们可以得到 q(z_t | z_(t-1) ),q(z_t | z_0),q(z_(t-1) | z_0) 的封闭形式表达式。通过高斯分布的性质 [1] 和一些简单的推导,我们可以得到后验分布:

通过方程(2)和(3),我们可以轻松优化所提出的偏移扩散的损失函数
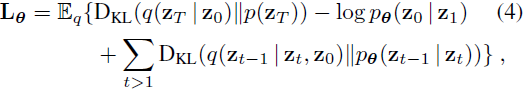
其中 D_KL 表示 KL 散度。由于我们的设计使得 q(z_t | z_0) 和 q(z_(t-1) | z_t, z_0) 都是高斯分布,KL 散度项有封闭形式的解,从而可以轻松进行随机优化。
尽管将 p(z_T) 设置为高斯分布导致了一个简化的损失,可以方便地进行优化,但它也引入了一些缺点,因为图像嵌入的真实分布不是单峰(single-mode)高斯分布。为了解决这个问题,我们提出使用一组高斯分布,表示为
![]()
![]()
设 z_0 和 y 分别为真实图像嵌入和其相关联的文本标题。对于每对 (z_0, y),我们通过余弦相似性的前 1 位选择其对应的高斯分布 p_(c_y),如下所示:
![]()
其中 f_txt 是预训练的 CLIP 文本编码器,c_y 表示所选高斯的索引。也可以使用
![]()
这需要更多计算,因为其中包含期望。在选择了
![]()
之后,其参数 μ_(c_y) 和 Σ_(c_y) 将用于方程(2)和(3)的优化。一个额外的表示 c_y 的位置嵌入也被注入到扩散模型中,其实现方式类似于时间 t 的嵌入。与单峰高斯分布相比,
![]()
应具有更好的表达能力,而 p_(c_y) 预期能更好地初始化 z_T 以使其更接近目标 z_0。
在我们的实现中,通过在训练数据集上执行聚类来估计
![]()
类似于现有的量化方法 [28],我们也可以通过优化来学习 (μᵢ, Σᵢ)。具体而言,我们建议在训练期间使用以下损失函数更新 μᵢ, Σᵢ:
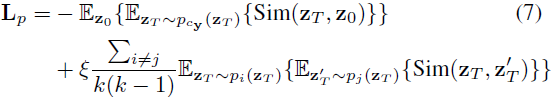
其中 ξ 是一个超参数。L_p 的第一项迫使从高斯 p_(c_y) 中抽样的 z_T 接近相应的真实图像嵌入 z_0,而第二项确保 p_i(z_T) 不会过于重叠。请注意,
![]()
只通过 L_p 进行优化,即我们手动停止了从 L_θ 到
![]()
的梯度反向传播。我们的算法总结在算法 1 中,更多的实现细节在实验部分提供。

3. 实验
3.1 无监督文本到图像生成
我们首先测试 Corgi 的零样本文本到图像生成能力。我们准备了一个包含 9 亿个图像-文本对的数据集,其中包括一些常用数据集,如 Conceptual Captions (CC3M) [25]、Conceptual Captions 12M (CC12M) [2]、filtered LAION-5B [24] 以及一些我们自己收集的图像-文本对。请注意,我们确保我们的数据集与 MS-COCO [13]、CUB [29]、Localized Narratives [16] 和 Multi-modal CelebA-HQ (MM-CelebA-HQ) [30] 不重叠,因为我们将在这些下游数据集上测试零样本或无语言性能。
解码器。根据 [15, 20, 23] 的方法,我们的解码器采用了一个由扩散模型分层结构组成的模型架构,在文本到图像生成中表现出色。具体而言,分别在 64、256 和 1024 分辨率上训练了三个扩散模型。所有 900M 张图像都用于训练解码器。在训练过程中,每个图像都由三个不同的预训练 CLIP 模型处理:ViT-B/16、ViT-B/32 和 RN-101。这三个模型的输出将被级联成一个 1536 维的嵌入,然后被投影到八个向量中,并输入到解码器中。
先验模型:为了处理图像文本对齐,我们训练了一个偏移扩散模型,用于从标题生成图像嵌入。我们的偏移扩散模型是一个仅包含解码器的 transformer,其输入是一个序列,包括来自 T5 [18] 的编码文本、CLIP 文本嵌入、表示扩散时间步的嵌入、表示对应高斯的索引的嵌入、受噪音影响的 CLIP 图像嵌入以及用于预测目标 CLIP 图像嵌入的最终嵌入。我们在不同规模的数据集上训练了两个变体:一个先验模型是在完整的 900M 图像-文本对上训练的;另一个是在 CC15M 上训练的,它是我们完整数据集的子集。
最终模型:我们的两个不同的先验模型对应两个最终模型。先验模型的解码器(分别在 900M 和 15M 图像-文本对上训练)都是在 900M 张图像上进行训练的。换句话说,这两个最终模型可以被视为以监督和半监督的方式进行训练,其中第一个的训练数据集包含 900M 张图像-文本对,而第二个只包含 900M 张图像,但其中只有 1.7%(15/900)与标题相关联。我们分别将这两个变体称为 Corgi 和 Corgi-Semi。在附录中提供了更多的实现细节。
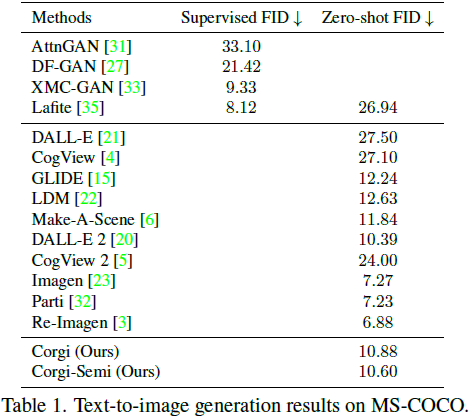

在表 1 中,我们报告了在 MS-COCO 上评估的零样本 Fréchet Inception Distance (FID)。按照先前的工作,FID 是使用 30,000 张生成的图像计算的,这对应于从 MS-COCO 的验证集中随机抽样的 30,000 个标题。结果表明,即使在半监督方式下训练,我们的模型也能取得强大的结果。有趣的是,我们的半监督模型的 FID 比监督模型更好。然而,正如我们从图 5 中看到的,使用更多的图像-文本对进行训练会导致更好的图像-文本对齐和更好的图像质量,这是符合预期的。它相对较差的 FID 可能是由于数据集偏差引起的:CC15M 可能包含与 MS-COCO 中的样本相似的许多样本,而当它们合并到我们的完整 900M 数据集中时,这种偏见就消失了。



我们注意到,大多数大规模文本到图像生成模型都是在不同的数据集上训练的,但都在 MS-COCO 上进行测试,忽略了潜在的数据集偏见。仅通过 FID 对这些模型进行比较可能不太合适。因此,通过实际生成质量比较模型是必要的。我们遵循先前的工作,并选择在 DrawBench [23] 和 PartiPrompts [32] 上评估我们的模型。在图 4 中展示了一些具有复杂场景的生成示例。我们将我们的模型与 DALL-E 2 和 Stable Diffusion 进行比较,因为这些是唯一允许公共访问的模型。为了公平比较,我们额外进行了 30 万次迭代的微调,以便解码器可以同时接受图像嵌入和文本作为输入,这与 DALL-E 2 类似。图 7 提供了一些视觉比较。附录中提供了更多的结果。可以看到,在图像-文本对齐和图像保真度方面,我们的模型在大多数情况下都能够更好地生成。此外,我们在 DrawBench 和 PartiPrompts 上进行了人工评估。具体而言,我们首先为每个提示生成了四幅图像,然后要求十名随机的人工劳动者判断哪个模型在图像-文本对齐和保真度方面更好(或可比)。结果显示在图 6 中,我们的模型在两个评估指标上一贯表现更好。
3.2 无语言文本到图像生成
[35] 是在仅包含图像的数据集上训练文本到图像生成模型的开创性工作,被称为无语言训练,因为没有提供相关的标题。借助预训练的偏移扩散模型,我们也可以在任何下游数据集上执行无语言训练和微调。给定一个仅包含图像的数据集,我们可以训练或微调一个生成模型,从图像嵌入生成图像。因此,在推理时,我们可以直接使用预训练的偏移扩散模型进行文本到图像生成。由于我们的偏移扩散模型是在大规模图像-文本对上进行预训练的,因此预期它在任何下游领域都能很好地泛化。
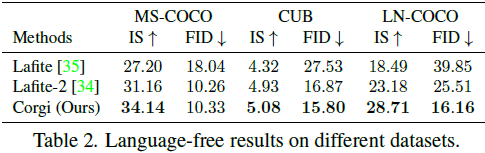
首先,我们将我们的方法与 [34, 35] 进行比较。为了公平比较,我们的解码器使用与 [35] 相同的网络架构,即基于 StyleGAN2 的模型。表 2 提供了一些定量结果,从中我们可以看到我们的方法在一般情况下都能取得更好的结果。附录中提供了更多结果。尽管 Lafite-2 [34] 在 MS-COCO 数据集上取得了竞争力的 FID,但它是在需要额外人工工作的伪标题上训练的。具体而言,要训练 Lafite-2,需要领域特定的词汇和提示,这需要对每个下游领域的人类先验知识。另一方面,我们的偏移扩散模型是预训练的,可以直接插入到任何领域而无需进一步的训练或微调。
然后,我们进行了在无语言设置下对预训练文本到图像扩散模型进行微调的实验。我们选择 Stable Diffusion 2 作为基础模型。具体而言,我们添加了一个投影层,将 CLIP 图像嵌入投影到 4 个向量中,然后将其馈入 Stable Diffusion 2 的 UNet 中。如图 8 所示,Stable Diffusion 2 可能生成风格与目标数据集不同的图像,而我们的模型在无语言微调后导致更令人满意的结果。

3.3 消融研究
基线 vs. 偏移扩散:尽管我们在先前的实验中已经展示了我们的模型比 DALL-E 2 取得更好的生成质量,但没有直接的线索表明这种改进是由于偏移扩散相对于基线扩散的优势。这是因为,正如我们指出的,其他重要因素,如潜在的数据集偏差和不同的实现细节,也可能影响模型性能。因此,为了更好地将我们的偏移扩散模型与基线扩散模型进行比较,我们进行了一项消融研究,其中我们使用相同的实现和训练数据集(CC15M)训练这两个扩散先验。我们设置 k = 1 以进行公平比较,因为更大的 k 会导致进一步的改进。附录中提供了更多细节。
首先,我们比较生成的图像嵌入与真实图像嵌入之间的余弦相似度。我们从 MS-COCO 的验证集中随机抽样了 10,000 个图像-文本对,以防止训练和测试数据集之间的重叠。抽样的标题被馈送到不同的模型中,以生成相应的图像嵌入。结果如图 10 所示。我们可以看到,我们的偏移扩散模型导致更高的相似度分数,意味着更好的嵌入生成。
接下来,我们比较生成的嵌入在不同时间步骤上与地面实际的相似性分数。在采样过程中,我们对基线和偏移扩散模型都使用了 64 个步骤。结果如图 12 所示,我们可以看到我们的方法导致更高的相似性分数,特别是在初始化阶段。这表明我们的起始点离目标更近,与我们的设计意图一致。
最后,我们通过将它们应用于文本到图像生成任务来比较偏移扩散和基线。为此,我们首先使用从头开始训练的基于扩散的解码器生成了 30,000 张图像。在 MS-COCO 上的 zero-shot FID 结果如图 10 所示,与图 9 中的一些生成的示例一起展示。我们可以看到,偏移扩散确实导致更好的定量和定性结果,而基线模型未能捕捉文本中的一些细节。我们还在经过微调的 Stable Diffusion 2 上对它们进行评估,其中计算了 10,000 张生成图像到地面实际图像和标题的 FID 和 CLIP 相似性。结果在图 11 中提供,从中我们可以发现,偏移扩散导致更好的结果,因为它获得了更低的 FID 和更高的 CLIP 相似性。

偏移扩散的不同设置:回顾一下,我们的偏移扩散模型采用一个或多个高斯分布作为其采样过程的初始化。在这个实验中,我们调查了高斯分布数量的影响。我们分别使用 1、16、128 和 1024 个高斯分布来训练我们的偏移扩散模型。此外,我们训练了一个包含 1024 个可学习均值向量和协方差矩阵的模型。所有模型都在 CC15M 上进行训练。我们计算了在 MS-COCO 的验证集上生成的图像嵌入与地面实际嵌入之间的相似性。结果如图 13 所示,我们可以看到使用更多的高斯分布导致更好的结果;此外,使参数可学习进一步提高了性能。附录中提供了更多讨论。
4. 结论
我们提出了 Corgi,一种新颖且通用的扩散模型,可在不同设置下改善文本到图像生成。我们进行了大规模的广泛实验。获得了强有力的定量和定性结果,展示了所提方法的有效性。
S. 总结
S.1 主要贡献
以前的方法通过扩大可训练/冻结模块或设计更好的模型架构来改善文本到图像生成。本文探索一个正交的方向:改进扩散过程本身。
本文提出偏移扩散模型 Corgi,使得在嵌入空间的采样更接近 CLIP 图像编码器的有效输出区域。该方法可将预训练模型(例如 CLIP)的先验知识整合到其扩散过程中(弥合图像文本模态差距)。该方法是通用的,可应用于文本到图像生成的不同设置,例如,半监督和无语言文本到图像生成(弥合数据可用性差距)。
S.2 架构和方法
本文所使用的架构如图 2 所示,由三个关键组件组成:
- 一个预训练的图像编码器,将图像映射到它们的嵌入
- 一个从相应的嵌入生成图像的解码器
- 一个从相应的文本标题生成图像嵌入的先验模型
偏移扩散。
- q(z_0) 是 CLIP 模型的联合潜在空间中真实图像嵌入的分布。构建一个分布 p(z_T),与标准的高斯分布相比,该分布与 q(z_0) 更相似。
- 将初始分布 p(z_T) 视为参数高斯分布,即 N(z_T ;μ,Σ),可以通过简单地计算训练数据集统计值获得。
- 使用如公式 (1) 所示的转移。不同于普通扩散,它在扩散过程在每个时间步 t 引入了一个偏移项 s_t,因此被称为偏移扩散。
- 普通扩散过程是一个将图像嵌入转换为随机高斯噪声的过程;偏移扩散过程是一个真实图像嵌入转换为随机图像嵌入的过程。
![]()
将 p(z_T) 设置为高斯分布简化了损失,可以方便地进行优化,但它也引入了一些缺点,因为图像嵌入的真实分布不是单峰(single-mode)高斯分布。
- 为了解决这个问题,本文使用一组高斯分布(在训练数据集上执行聚类来估计):通过余弦相似性,选择与标题嵌入最接近的高斯分布(图像嵌入的分布)。
- 与使用单峰高斯分布相比,该方法具有更好的表达能力,且得到的高斯分布能更好地初始化 z_T 以使其更接近相应的图像嵌入。
相关文章:
(2023|CVPR,Corgi,偏移扩散,参数高斯分布,弥合差距)用于文本到图像生成的偏移扩散
Shifted Diffusion for Text-to-image Generation 公众:EDPJ(添加 VX:CV_EDPJ 或直接进 Q 交流群:922230617 获取资料) 目录 0. 摘要 1. 简介 2. 方法 2.1 偏移扩散 3. 实验 3.1 无监督文本到图像生成 3.2 无…...
)
ACE中为socket增加keepalive策略(windows和linux)
0、现象描述 在国产麒麟系统下,基于ACE的tcp-socket,如果长时间不操作,则会自动切断连接,经测试发现,这个时间的上限为30分钟(几乎不差1秒) 经查看/proc/sys/net/ipv4/tcp_keepalive_time=7200,按说是2小时,但测试发现就是30分钟。索性,就通过程序来动态设置keepaliv…...
前端工程注入版本号
文章目录 一、前言二、webpack三、vite四、最后 一、前言 容器化时代,当页面出现问题时,如果你的新版本有可能已经修复了,那样你再排查它就没有意义了。为什么不一定是最新版本呢?一是可能是缓存作祟,二是可能运维成员…...

Android 10.0 SystemUI禁用长按recent键的分屏功能
1.前言 在10.0的系统产品开发中,系统对于多窗口模式默认会有分屏功能的,但是在某些产品中,需要禁用分屏模式,所以需要在导航栏中 禁用长按recent的分屏模式功能,接下来分析下相关分屏模式的实现 2.SystemUI禁用长按recent键的分屏功能的核心类 frameworks\base\packa…...

自媒体实战篇:作品爆款三要素的使用场景和重要性
作品爆款三要素的使用场景和重要性 什么是爆款三要素 标题 概括视频内容,吸引用户注意封面 吸引眼球,引发作者联想标签 精准分类,有利于平台精准推流优质标题要求 标题就是介绍视频故事内容的一段话,通常分为三段式注册,统称三段式标题好的标题统称是三段式的,即点明故事…...

Hbase的安装配置
注:本文默认已经完成hadoop的下载以及环境配置 1.上传zookeeper和hbase压缩包到指令路径并且解压 (理论上讲,hbase其实内置了zookeeper,我们也可以不另外下载,另外下载的目的在于减少组件间依赖性) cd /home mkir hbase cd /hom…...
VMware17Pro虚拟机安装Linux CentOS 7.9(龙蜥)教程(超详细)
目录 1. 前言2. 下载所需文件3. 安装VMware3.1 安装3.2 启动并查看版本信息3.3 虚拟机默认位置配置 4. 安装Linux4.1 新建虚拟机4.2 安装操作系统4.2.1 选择 ISO 映像文件4.2.2 开启虚拟机4.2.3 选择语言4.2.4 软件选择4.2.5 禁用KDUMP4.2.6 安装位置配置4.2.7 网络和主机名配置…...

QT trimmed和simplified
trimmed:去除了字符串开头前和结尾后的空白; simplified:去除了字符串开头前和结尾后的空白,以及中间内部的空白字符也去掉(\t,\n,\v,\f,\r和 ) 代码: QString str " 1 2 3 4 5 …...
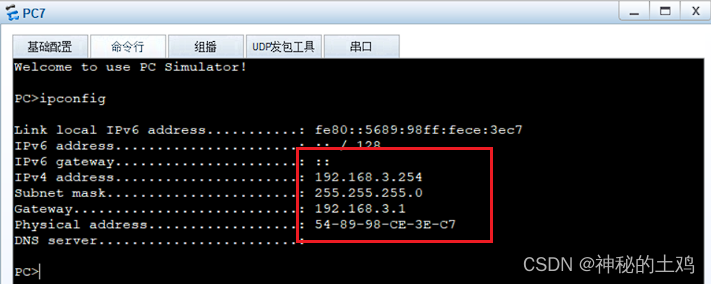
Ensp dhcp全局地址池(配置命令 + 实例)
使用DHCP的好处:减少管理员的工作量、避免输入错误的可能、避免ip冲突 DHCP报文类型: DHCP DISCOVER:客户端用来寻找DHCP服务器 DHCP OFFER:DHCP服务器用来响应DHCP DISCOVER报文,此报文携带了各种配置信息 DHCP REQUEST:客户端配置请求确…...
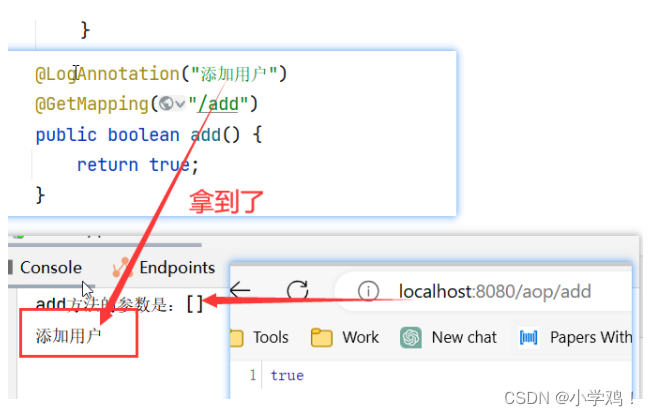
spring aop实际开发中怎么用,Spring Boot整合AOP,spring boot加spring mvc一起使用aop,项目中使用aop
前言:本文不介绍 AOP 的基本概念、动态代理方式实现 AOP,以及 Spring 框架去实现 AOP。本文重点介绍 Spring Boot 项目中如何使用 AOP,也就是实际项目开发中如何使用 AOP 去实现相关功能。 如果有需要了解 AOP 的概念、动态代理实现 AOP 的&…...
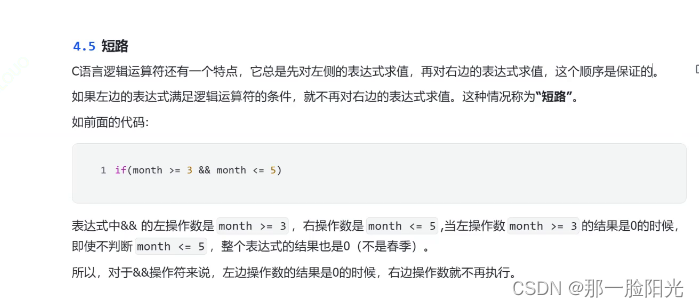
C语言操作符if语句好习惯 详解分析操作符(详解4)
各位少年: 前言 还记得我们上一章讲过一个比较抽象的代码,它要比较两次都是真的情况下才能打印,那么很显然这样写代码是有弊端的?哪我们C语言之父丹尼斯.里奇,先介绍一下上次拉掉了if语句的好习惯 好再分享一些操作符…...

【什么是泛型,有什么好处】
✅什么是泛型,有什么好处 ✅典型回答✅泛型是如何实现的✅什么是类型擦除?📝C语言对泛型的支持📝泛型擦除的缺点有哪些? ✅对泛型通配符的理解📝泛型中上下界限定符 extends 和 super 有什么区别࿱…...
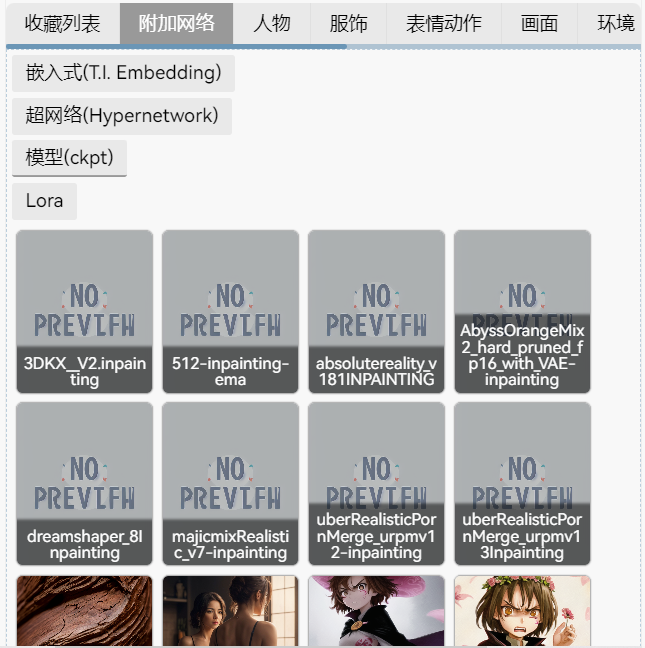
Stable Diffusion系列(三):网络分类与选择
文章目录 网络分类模型基座模型衍生模型二次元模型2.5D模型写实风格模型 名称解读 VAELora嵌入文件放置界面使用 网络分类 当使用SD webui绘图时,为了提升绘图质量,可以多种网络混合使用,可选的网络包括了模型、VAE、超网络、Lora和嵌入。 …...

Twincat中PLC的ST语言编程实现机器人安全交互
在TwinCAT中,使用ST语言(Structured Text)进行PLC编程是一种常见的做法。 机器人接触力超过预设阈值后执行停止动作 为了实现机器人在接触力超过预设阈值后停止动作的功能,你需要编写一段ST语言代码,以检查当前的接触…...
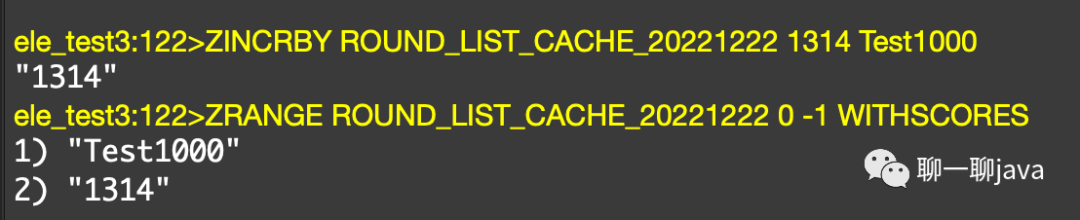
Redis实现日榜|直播间榜单|排行榜|Redis实现日榜01
前言 直播间贡献榜是一种常见的直播平台功能,用于展示观众在直播过程中的贡献情况。它可以根据观众的互动行为和贡献值进行排名,并实时更新,以鼓励观众积极参与直播活动。 在直播间贡献榜中,每个观众都有一个对应的贡献值&#…...
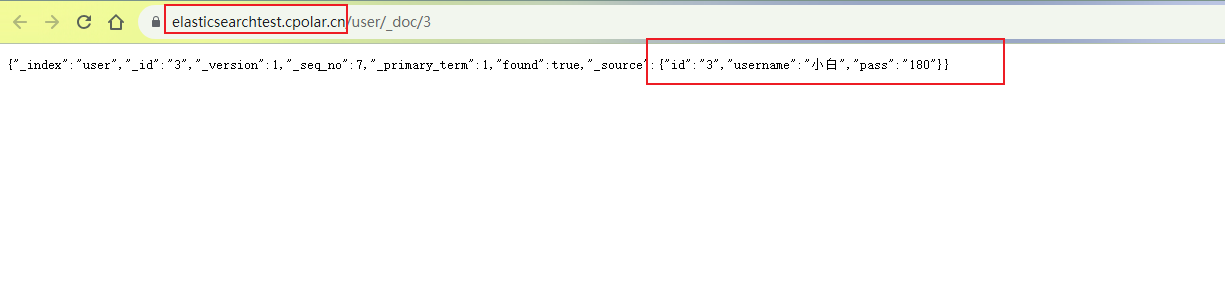
如何使用内网穿透工具实现Java远程连接本地Elasticsearch搜索分析引擎
文章目录 前言1. Windows 安装 Cpolar2. 创建Elasticsearch公网连接地址3. 远程连接Elasticsearch4. 设置固定二级子域名 前言 简单几步,结合Cpolar 内网穿透工具实现Java 远程连接操作本地分布式搜索和数据分析引擎Elasticsearch。 Cpolar内网穿透提供了更高的安全性和隐私保…...
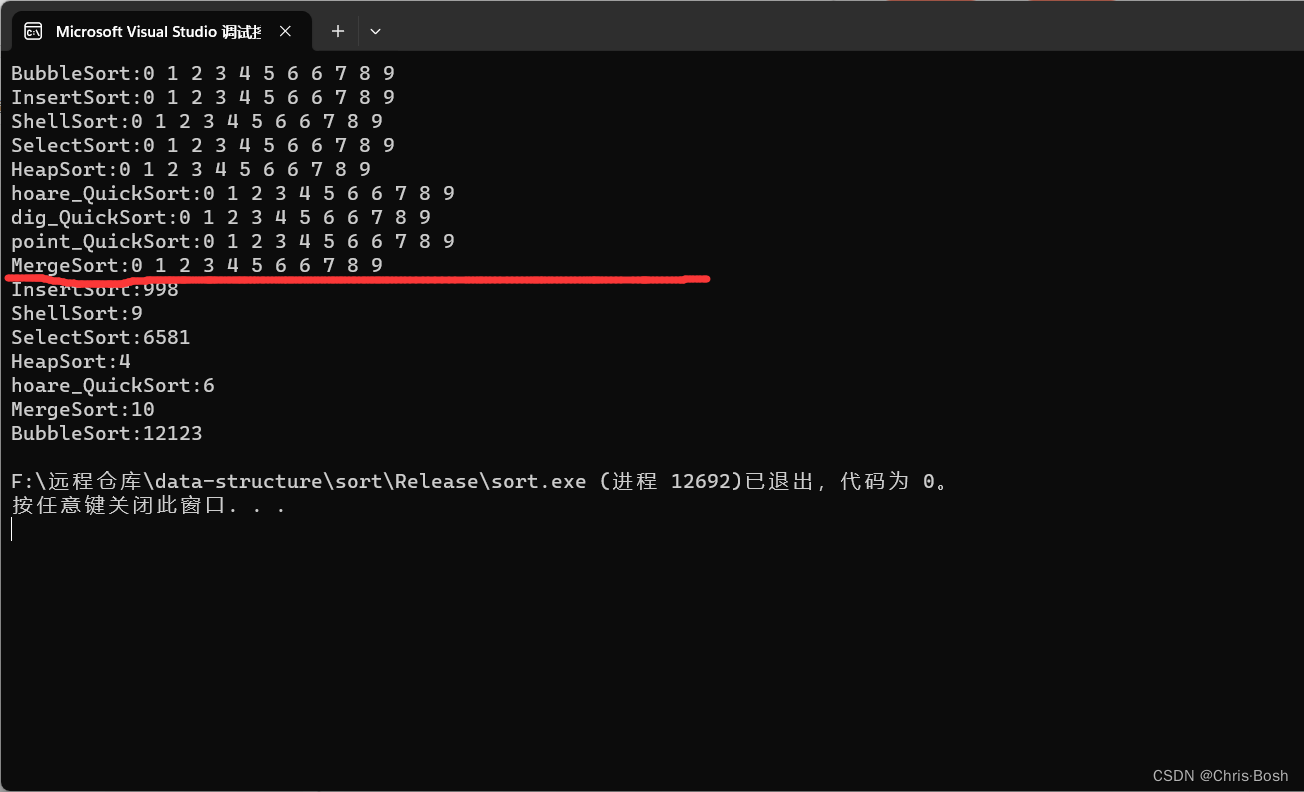
C语言数据结构-----常用七种排序介绍、分类、实现及性能比较
前言 ①排序:所谓排序,就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操作。 ②稳定性:假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序&#…...

2023年山东省职业院校技能大赛高职组 “软件测试”赛项竞赛任务四 单元测试
任务四 单元测试 任务要求 题目1:任意输入2个正整数值分别存入x、y中,据此完成下述分析:若x≤0或y≤0,则提示:“输入不符合要求。”;若2值相同,则提示“可以构建圆形或正方形”;若2…...
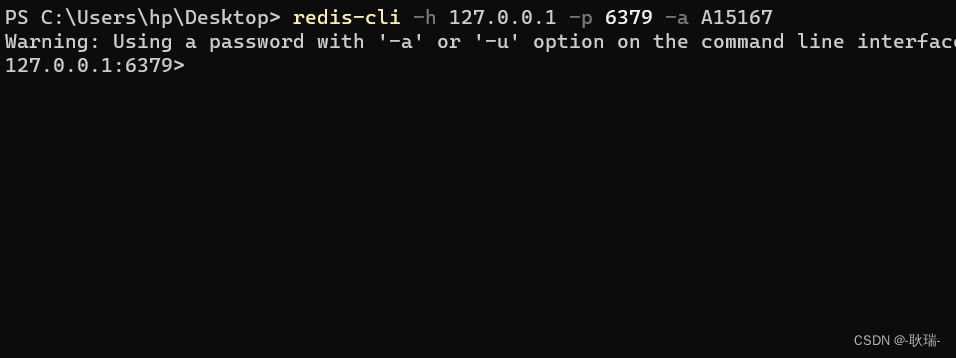
在Redis客户端设置连接密码 并演示密码登录
我们先连接到Redis服务 然后 我们要输入 CONFIG SET requirepass “新密码” 例如 CONFIG SET requirepass "A15167"这样 密码就被设置成立 A15167 我们 输入 AUTH 密码 例如 AUTH A15167这里 返回OK说明成功了 然后 我们退出在登录就真的需要 redis-cli -h IP地…...

阿里云公有云平台
1. 请简要介绍一下公有云平台的基本概念和特点。 公有云是一种云计算模型,其中服务器、网络和存储资源等IT基础架构以虚拟资源的形式提供,并且可以通过互联网进行访问。这些资源是由第三方提供商共享并提供给用户的,包括计算、存储、网络等。…...

嵌入式以太网模块WIZ5500应用指南:从SPI接口到物联网稳定连接
1. 项目概述:为什么你的物联网项目需要一个有线网络“锚点”无线网络(Wi-Fi)确实方便,但做过几个实际项目的朋友都知道,它的“方便”有时是建立在“不确定性”之上的。信号波动、信道拥堵、复杂的认证流程,…...

2026年国内数字人平台推荐:有哪些创作者与企业的高效创作利器?
一、引文/摘要在数字人领域,制作成本高、技术门槛高、生产效率低已成为内容创作的核心痛点。 2026年,AI数字人市场持续扩张,创作者与企业对低成本、易上手、全链路的数字人解决方案需求激增。但市场平台繁杂,功能与技术差异显著&a…...

COMSOL声学建模实战:从无源特征频率到有源辐射边界
1. COMSOL声学建模基础:从理论到实践 声学建模在工程领域应用广泛,无论是建筑声学设计、噪声控制还是音频设备开发,都需要对声波传播特性有深入理解。COMSOL Multiphysics作为一款强大的多物理场仿真软件,提供了完整的声学建模解决…...

时间序列分类的能效优化与剪枝策略实践
1. 时间序列分类的能效挑战与剪枝策略概述时间序列分类(Time Series Classification, TSC)作为机器学习的重要分支,在医疗监测、工业设备故障诊断、金融行为分析等领域发挥着关键作用。随着应用场景的复杂化和数据规模的扩大,传统…...

守护进程Guardian:轻量级进程保活与高可用架构实践
1. 项目概述:一个守护进程的诞生与使命在分布式系统和微服务架构大行其道的今天,服务的稳定性与可靠性成为了悬在每个开发者头顶的达摩克利斯之剑。服务挂了怎么办?进程意外退出如何自动恢复?配置热更新如何无感生效?这…...

深入理解C/C++混合编程
在工作中,C、C密不可分,做我们嵌入式方面的,当然更多的是C,但,有时候却少不了C,而且是C、C混搭(混合编程)在一起的,比如,RTP视频传输,live555多媒…...

CircuitPython嵌入式开发:从代码编辑、串口调试到库管理的完整工作流
1. 从零开始:CircuitPython的嵌入式开发哲学如果你和我一样,是从Arduino或者传统的C语言嵌入式开发转过来的,第一次接触CircuitPython的感觉,大概就像从手动挡汽车换到了电动车。那种“拧钥匙、挂挡、踩离合”的繁琐步骤ÿ…...

Spring Boot安全脚手架实战:快速集成认证授权与API防护
1. 项目概述:一个面向开发者的安全脚手架如果你是一名后端或全栈开发者,最近在启动一个新项目时,是不是总感觉有些“重复劳动”?比如,每次都要手动集成用户认证、权限管理、API安全防护、日志审计这些基础但至关重要的…...
)
NotebookLM生物学研究辅助落地手册(实验室已验证的7个不可公开的Prompt工程模板)
更多请点击: https://intelliparadigm.com 第一章:NotebookLM生物学研究辅助落地手册(实验室已验证的7个不可公开的Prompt工程模板) NotebookLM 作为 Google 推出的文档感知型 AI 助手,在分子生物学、结构生物学与高通…...

独立开发者如何借助Taotoken的Token Plan有效控制月度AI支出
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何借助Taotoken的Token Plan有效控制月度AI支出 对于独立开发者和小型团队而言,大模型API的调用成本是一个…...