分布式训练通信NCCL之Ring-Allreduce详解
🎀个人主页: https://zhangxiaoshu.blog.csdn.net
📢欢迎大家:关注🔍+点赞👍+评论📝+收藏⭐️,如有错误敬请指正!
💕未来很长,值得我们全力奔赴更美好的生活!
前言
随着Chat GPT、文生图、多模态等模型的发展,海量的训练数据、超大规模的模型给深度学习带来了日益严峻的挑战,因此,经常需要使用多加速卡和多节点来并行化训练深度神经网络。目前,数据并行和模型并行作为两种在深度神经网络中常用的并行方式,分别针对不同的适用场景,有时也可将两种并行混合使用。数据并行是在不同设备上放置完整的模型,然后将数据划分在每个设备并行计算。这必然会涉及到不同设备之间的数据传输,即,设备通信,在分布式数据并行的情况下,利用 GPU上的 Minibatch进行权重参数梯度的计算,再利用 GPU之间的通信来完成梯度同步,最后更新模型。常见的深度学习框架提供的通信后端主要有Mpi、Gloo、Nccl,其中Nccl通信后端中的Ring-Allreduce通信技术和硬件的P2P通信技术极大的改善了低效的通信传输问题。本文对Ring-Allreduce通信技术和硬件的P2P通信技术进行详细介绍。
文章目录
- 前言
- 一、Ring-Allreduce
- 1. Scatter-Reduce阶段
- 2. Allgather阶段
- 3. Ring-Allreduce通信容量分析
- 二、硬件Direct通信技术
- 总结
先对分布式训练中数据并行的流程进行一个回顾, 如下图所示,其基本流程包括将整个训练数据集划分为多个小批次,并将这些小批次分配到不同的设备或节点上。每个设备拥有完整的模型副本,独立处理分配给它的数据。在每个训练步骤中,设备执行前向传播、损失计算、反向传播等操作。随后,梯度信息从各设备中聚合,用于更新模型参数。这一过程循环迭代,直至模型达到收敛或事先定义的训练轮数。数据并行的优势在于有效地利用分布式计算资源,加速大规模深度学习模型的训练,提高训练效率。

可以发现在分布式训练模型的过程中参数的更新之前需要聚合各设备的梯度信息,因此产生了分布式训练过程中的通信需求,而通信的好坏直接影响到整个模型的训练速度。而Nccl作为常见的深度学习框架提供的通信后端,其中Ring-Allreduce通信技术和硬件的P2P通信技术极大的改善了低效的通信传输问题。
一、Ring-Allreduce
Ring-Allreduce是一种以环状拓扑为基础的通信系统。整个体系结构的工作过程见下图,Rank代表了各个 GPU的进程编号,并且梯度信息可以在两个不同的区域中同步传输。在Ring-Allreduce体系结构中,每台计算机都是一个工作节点,按环形排列。

Ring-Allreduce体系结构的工作过程被分成两个阶段,即Scatter-Reduce和 Allgather。在Scatter-Reduce阶段,完成了数据的分配与并行,各个工作节点之间的数据交换。最后,在每一个节点上都会有一个最终的结果。Allgather阶段实现了数据的整体同步和压缩,每一个工作节点之间都会进行一些最后的处理,这样对于所有节点来说就可以得到一个完整的结果。
1. Scatter-Reduce阶段
Scatter-Reduce阶段:假定这个阶段的目的是求和,在这个系统中有 N个工作结点,每一个结点中的数据量大小都是K,在Scatter-Reduce的后期,每一个结点都有一个包括初始数组和的而且大小相同的矩阵。
具体的,
- 第一步,每个结点把本设备上的数据分成 N个区块, N是Ring-Allreduce体系结构中的工作节点数目,见下图步骤(1)。
- 在第二步,在第一次传输和接收结束之后,在每一个结点上累加了其他节点一个块的数据。这样的数据传输模式直到“Scatter-Reduce”阶段结束,见下图步骤(2)。
- 最后每一个节点上都有一个包含局部最后结果的区块,由(3)中的深色区块表示,这个区块是所有节点相应的位置区块之和。

可以使用Python对Scatter-Reduce阶段的求和过程进行模拟,代码如下:
import numpy as npdef scatter_reduce(data, num_nodes):# 假设data是每个节点上的初始数组# num_nodes是工作节点数目# 第一步:每个节点把本设备上的数据分成N个区块local_blocks = np.array_split(data, num_nodes)# 第二步:在每个节点上累加其他节点一个块的数据for i in range(num_nodes):other_blocks = [local_blocks[j] for j in range(num_nodes) if j != i]local_blocks[i] += np.sum(other_blocks, axis=0)# 第三步:每个节点上都有一个包含局部最后结果的区块final_result = np.sum(local_blocks, axis=0)return final_result# 示例
num_nodes = 4
data_size_per_node = 5
total_data_size = num_nodes * data_size_per_node# 生成随机数据作为每个节点上的初始数组
data = np.random.randint(0, 10, total_data_size)# 模拟Scatter-Reduce过程
result = scatter_reduce(data, num_nodes)# 打印结果
print("初始数据:", data)
print("最终结果:", result)
2. Allgather阶段
Allgather阶段:每个工作节点将包含最终结果的块数据块交换, 这样所有的结点就会得到一个完整的结果,
-
Allgather阶段总共包含有数据发送和接收N一1次,不同的是,Allgather阶段并不需要将接收到的值进行累加,而是直接使用接收到的块内数值去替环原来块中的数值。在迭代完第1次这个过程后,每个节点的最终结果的块变为2个,如图3.3步骤(2)所示。
-
之后会继续这个迭代过程直到结束,使得每一个节点都包含了全部块数据结果。下图为整个Allgather过程,可以从图中看到所有数据传输过程和中间结果值。

同样可以使用Python对Allgather阶段的过程进行模拟,代码如下:
import numpy as npdef allgather(local_blocks, num_nodes):all_blocks = [np.empty_like(local_blocks) for _ in range(num_nodes)]for i in range(num_nodes):# 第一次迭代直接复制本地块到目标块all_blocks[i][:] = local_blocks[i]for _ in range(num_nodes - 1):# 迭代过程中交换块数据for i in range(num_nodes):target_node = (i + 1) % num_nodes# 发送当前节点的块到目标节点np.copyto(all_blocks[target_node], local_blocks[i])# 接收目标节点的块到当前节点np.copyto(local_blocks[i], all_blocks[target_node])return all_blocks# 示例
num_nodes = 4
data_size_per_node = 5
total_data_size = num_nodes * data_size_per_node# 生成随机数据作为每个节点的初始数组
local_data = np.random.randint(0, 10, (num_nodes, data_size_per_node))# 模拟Allgather过程
result_blocks = allgather(local_data, num_nodes)# 打印结果
print("初始数据块:", local_data)
print("Allgather结果块:", result_blocks)
3. Ring-Allreduce通信容量分析
从上述Ring-Allreduce的算法过程可以看到,
-
Scatter-Reduce 阶段的工作节点会进行数据的同时收发,具体的,在这一阶段共有 N − 1 N-1 N−1次通信容量为 K / N K/N K/N的数据通信过程。
-
同样的在Allgather阶段的工作节点也会进行数据的同时收发并且共有 N − 1 N-1 N−1次通信容量为 K / N K/N K/N的数据通信。
故,在使用Ring-Allreduce算法改善后,每个节点传输数据总量变为:
V c o m m u n i c a t i o n = 2 × K × N − 1 / N Vcommunication=2×K×N-1/N Vcommunication=2×K×N−1/N
由上式可知,当工作节点的数量变得很大时,在Ring-Allreduce架构中单个节点的通信数据量近似为 2 × K 2\times K 2×K,与节点数$N¥没有关系。这不仅在一定程度上相比传统的BS(参数服务器)通信方式减少了通信量,同时在节点数量增大时,具有很好的可扩展性。
二、硬件Direct通信技术
在常见的分布式训练加速设备中,常常是多节点多加速卡的形式,节点也可被称之为主机或CPU,加速卡的种类很多,常见的有GPU、DCU、FPGA等。如下图所示,在单节点多加速卡的情况下,节点和加速卡以及加速卡之间的数据通信依靠PCIe或NVLink实现,多节点多加速卡的情况下,节点之间的数据通信依靠以太网或Infiniband实现。

在跨节点加速卡通信的过程中,往往需要先将加速卡的数据传输到相应节点的CPU上,然后CPU通过以太网传输数据,之后又将数据传给加速卡,这种数据在节点和加速卡之间频繁移动所造成的通信开销是很大的,鉴于此,英伟达公司发布了 GPU Direct技术,用于提高加速卡之间通信的效率。
-
在单节点多加速卡通信中,提出
P2P(GPU Direct peer-to-peer)技术。如下图(a)(b)所示,它实现了节点内部加速卡的直接通信,即加速卡可以直接访问另一个加速卡的内存并实现数据的直接传输,避免了加速卡的数据复制到节点CPU内存上作为中转。 -
在多节点多加速卡通信中,提出了
GDR(GPU direct RDMA)技术,如下图(c)所示,加速卡和网卡可以直接通过PCIe进行数据交互,避免了跨节点通信过程中内存和CPU的参与。从而实现加速卡可以直接访问其他节点的加速卡内存。

总结
无论是Ring-Allreduce通信技术还是硬件的P2P通信技术都从硬件层面极大的改善了低效的通信传输问题,并且,相比于Mpi和Gloo对于硬件层面的通信优化程度更高,并且,对于英伟达的GPU,Nccl所提供的通信后端更加高效。
文中有不对的地方欢迎指正。
相关文章:
分布式训练通信NCCL之Ring-Allreduce详解
🎀个人主页: https://zhangxiaoshu.blog.csdn.net 📢欢迎大家:关注🔍点赞👍评论📝收藏⭐️,如有错误敬请指正! 💕未来很长,值得我们全力奔赴更美好的生活&…...

os_util 工具类和方法的实现
一、前置说明 总体目录:《从 0-1 搭建企业级 APP 自动化测试框架》上节回顾:在 init_appium_and_devices 的实现思路分析 小节中,分析了实现 init_appium_and_devices 的思路,梳理出了必要的工具类和方法。本节目标:完…...

uview表单校验带星号
uView表单校验带星号可以通过设置required属性来实现。在uView中,可以使用组件来实现表单校验,具体步骤如下: 1、在需要校验的表单元素上添加required属性,例如: <u-form :model"detailInfo" ref"d…...
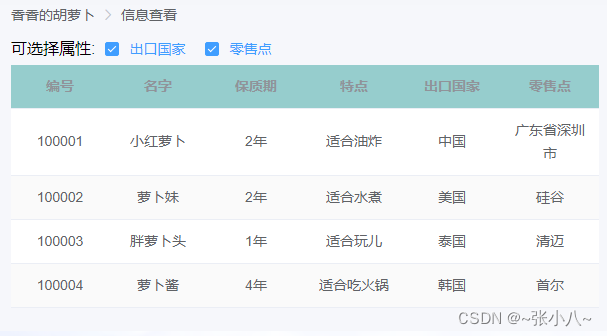
vue+element实现动态表格:根据后台返回的属性名和字段动态生成可变表格
现有一个胡萝卜厂生产不同品种的胡萝卜,为了便于客户了解产品,现需在官网展示胡萝卜信息。现有的萝卜信息:编号(id)、名称(name)、保质期(age)、特点(remark&…...
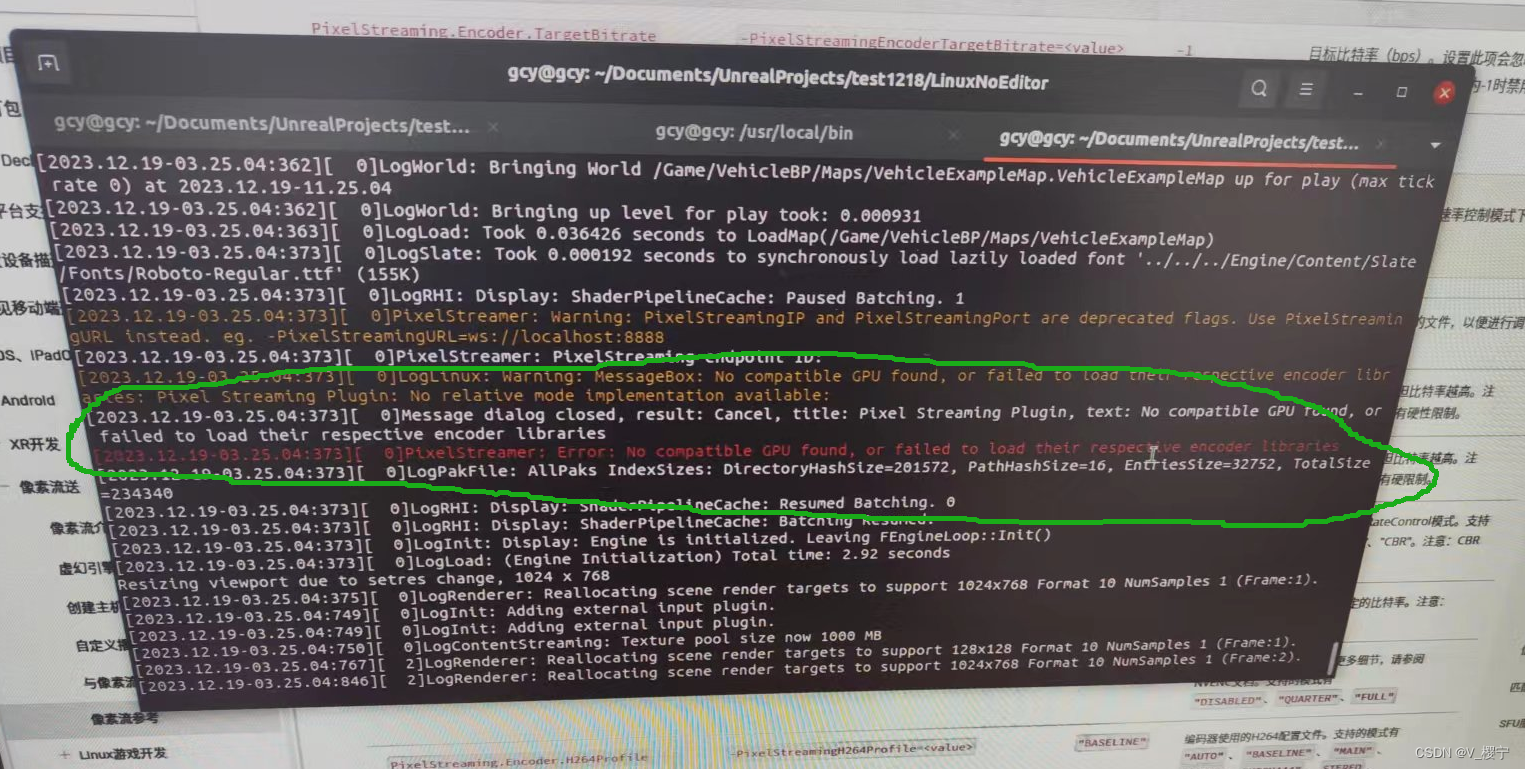
云渲染UE4像素流送搭建(winows、ubuntu单实例与多实例像素流送)
windows/ubuntu20.4下UE4.27.2像素流送 像素流送技术可以将服务器端打包的虚幻引擎应用程序在客户端的浏览器上运行,用户可以通过浏览器操作虚幻引擎应用程序,客户端无需下载虚幻引擎,本文实现两台机器通过物理介质网线实现虚幻引擎应用程序…...
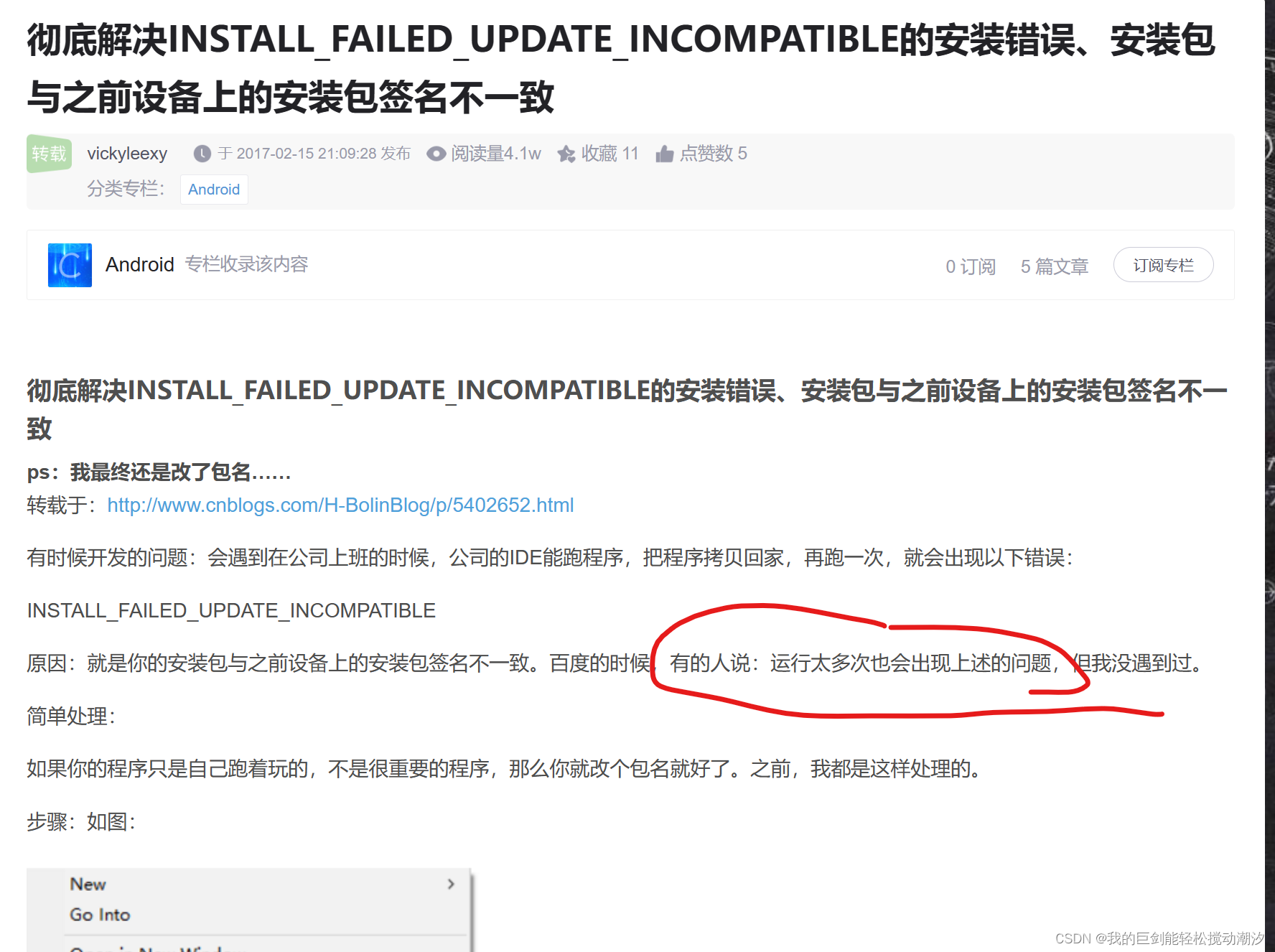
Unity VR Pico apk安装失败:INSTALL_FAILED_UPDATE_INCOMPATIBLE
我的报错: PICO4企业版。安装apk,报错“安装失败。(所属的Unity项目打包的apk,被我在同一台pico4安装了20次) 调试方法: PIco4发布使用UNITY开发的Vr应用,格式为apk,安装的时候发生…...

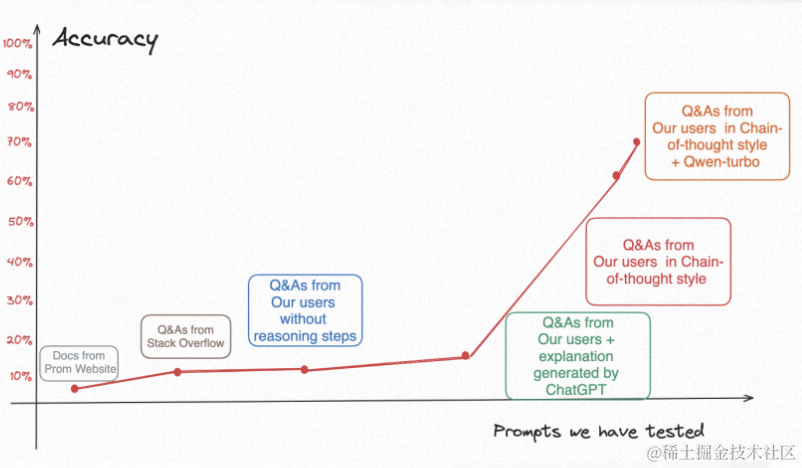
Prompt 提示工程学习笔记
一、Prompt设计的四个关键要素: 任务描述、输入数据、上下文信息、提示风格 (1)任务描述:描述想要让LLM遵循的指令。描述应详细清晰,可进一步使用关键词突出特殊设置,从而更好地指导LLM工作。 ࿰…...
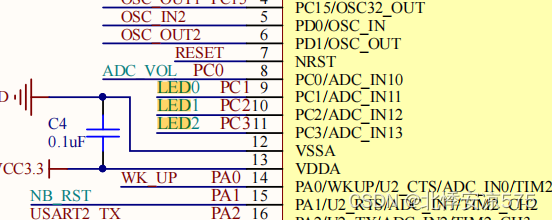
STM32实现三个小灯亮
led.c #include"led.h"void Led_Init(void) {GPIO_InitTypeDef GPIO_VALUE; //???RCC_APB2PeriphClockCmd(RCC_APB2Periph_GPIOC,ENABLE);//???GPIO_VALUE.GPIO_ModeGPIO_Mode_Out_PP;//???? ????GPIO_VALUE.GPIO_PinGPIO_Pin_1|GPIO_Pin_2|GPIO_P…...
1861_什么是H桥
Grey 全部学习内容汇总: GitHub - GreyZhang/g_hardware_basic: You should learn some hardware design knowledge in case hardware engineer would ask you to prove your software is right when their hardware design is wrong! 1861_什么是H桥 H桥电路可以…...

【计算机四级(网络工程师)笔记】操作系统运行机制
目录 一、中央处理器(CPU) 1.1CPU的状态 1.2指令分类 二、寄存器 2.1寄存器分类 2.2程序状态字(PSW) 三、系统调用 3.1系统调用与一般过程调用的区别 3.2系统调用的分类 四、中断与异常 4.1中断 4.2异常 🌈嗨ÿ…...

Swagger快速入门
1、Swagger快速入门 1.1 swagger介绍 官网:https://swagger.io/ Swagger 是一个规范和完整的Web API框架,用于生成、描述、调用和可视化 RESTful 风格的 Web 服务。 功能主要包含以下几点: A. 使得前后端分离开发更加方便,有利于团队协作…...
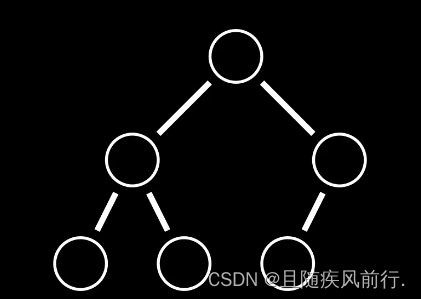
数据结构之<堆>的介绍
1.简介 堆是一种特殊的数据结构,通常用于实现优先队列。堆是一个可以被看作近似完全二叉树的结构,并且具有一些特殊的性质,根据这些性质,堆被分为最大堆(或者大根堆,大顶堆)和最小堆两种。 2.…...
使用Ubuntu22+Minikube快速搭建K8S开发环境
安装Vmware 这一步,可以参考我的如下课程。 安装Ubuntu22 下载ISO镜像 这里我推荐从清华镜像源下载,速度会快非常多。 下载地址:https://mirrors.tuna.tsinghua.edu.cn/ubuntu-releases/22.04.3/ 如果你报名了我的这门视频课程…...

【中小型企业网络实战案例 二】配置网络互连互通
【中小型企业网络实战案例 一】规划、需求和基本配置-CSDN博客 热门IT技术视频教程:https://xmws-it.blog.csdn.net/article/details/134398330?spm1001.2014.3001.5502 配置接入层交换机 1.以接入交换机ACC1为例,创建ACC1的业务VLAN 10和20。 <…...
Azure Machine Learning - Azure OpenAI GPT 3.5 Turbo 微调教程
本教程将引导你在Azure平台完成对 gpt-35-turbo-0613 模型的微调。 关注TechLead,分享AI全维度知识。作者拥有10年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师&…...
运维大模型探索之 Text2PromQL 问答机器人
作者:陈昆仪(图杨) 大家下午好,我是来自阿里云可观测团队的算法工程师陈昆仪。今天分享的主题是“和我交谈并获得您想要的PromQL”。今天我跟大家分享在将AIGC技术运用到可观测领域的探索。 今天分享主要包括5个部分:…...

虚拟机VMware:变动ip修改固定ip
1、配置ip地址 vi /etc/sysconfig/network-scripts/ifcfg-ens33修改为: 修改如下:TYPE"Ethernet" # 网络类型为以太网 BOOTPROTO"static" # 手动分配ip NAME"ens33" # 网卡…...
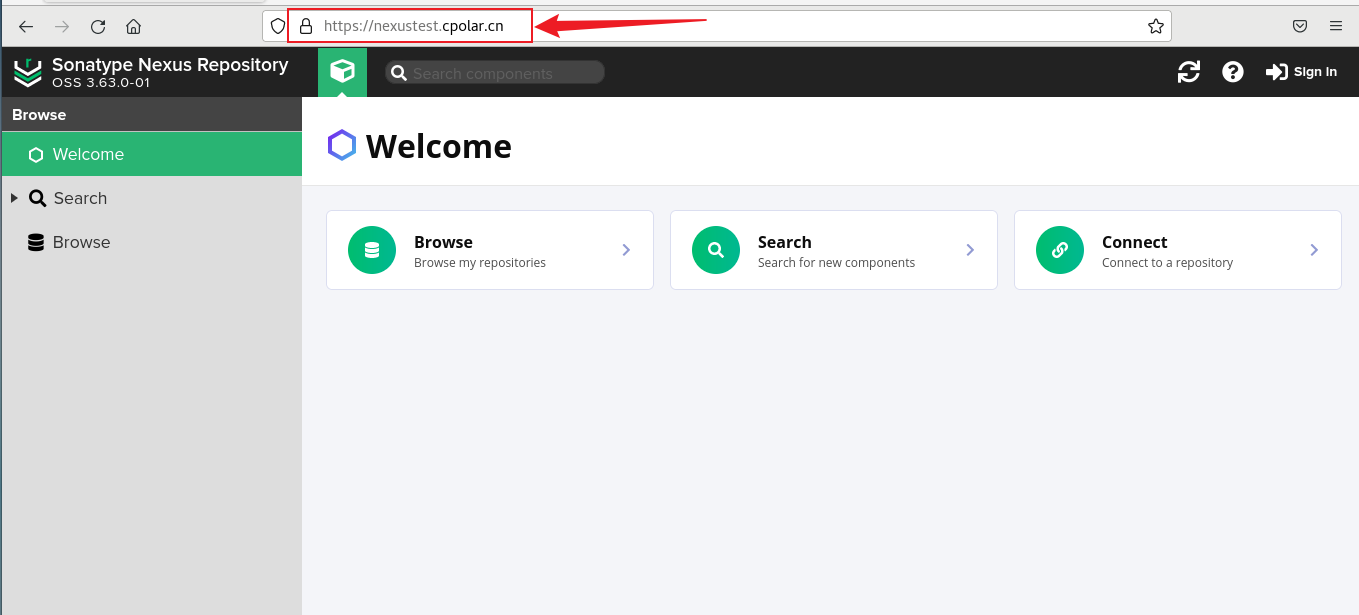
Docker部署Nexus Maven私服并实现远程访问Nexus界面
🎬 鸽芷咕:个人主页 🔥 个人专栏: 《linux深造日志》《粉丝福利》 ⛺️生活的理想,就是为了理想的生活! 文章目录 1. Docker安装Nexus2. 本地访问Nexus3. Linux安装Cpolar4. 配置Nexus界面公网地址5. 远程访问 Nexus界面6. 固定N…...
苏州科技大学计算机817程序设计(java) 学习笔记
之前备考苏州科技大学计算机(专业课:817程序设计(java))。 学习Java和算法相关内容,现将笔记及资料统一整理归纳移至这里。 部分内容不太完善,欢迎提议。 目录 考情分析 考卷题型 刷题攻略…...
虚幻学习笔记22—C++同步和异步加载
一、前言 之前提到的静态和动态加载都是同步的加载,同时其中的引用基本都是硬引用。如果资源比较大的话会出现卡顿的现象,下面将介绍一种异步加载的方式。同时,还将介绍一种区别与之前的Load的方法。 在说明同步和异步加载之前需要先讲一下虚…...

LRCGET:告别手动搜索,实现本地音乐歌词批量下载的完整指南
LRCGET:告别手动搜索,实现本地音乐歌词批量下载的完整指南 【免费下载链接】lrcget Utility for mass-downloading LRC synced lyrics for your offline music library. 项目地址: https://gitcode.com/gh_mirrors/lr/lrcget 你是否拥有大量本地音…...

三分钟永久备份你的QQ空间:告别数据丢失的终极解决方案
三分钟永久备份你的QQ空间:告别数据丢失的终极解决方案 【免费下载链接】QZoneExport QQ空间导出助手,用于备份QQ空间的说说、日志、私密日记、相册、视频、留言板、QQ好友、收藏夹、分享、最近访客为文件,便于迁移与保存 项目地址: https:…...

车联网TBOX开发实战六,CAN特性
接上篇芯片及系统方案基础,本篇想写个远程控制,但想想整个交互链路较长,涉及到的基础很多,决定先从最基础的介绍一下,CAN,就是与车辆交互的核心总线本篇不做CAN基础的全面讲解,网络上有大篇幅的…...

【Coze工作流】零代码做AI自动化,小白也能5分钟上手
一、问题背景:手工做重复AI任务太累,想自动化但不会写代码在日常办公或者内容创作中,很多人都有过这样的痛点:每天要重复打开各种AI工具。比如你要写一篇爆款文章,先要找AI找选题,再让AI写大纲,…...

AI-Shoujo HF Patch完全指南:从技术架构到高级应用
AI-Shoujo HF Patch完全指南:从技术架构到高级应用 【免费下载链接】AI-HF_Patch Automatically translate, uncensor and update AI-Shoujo! 项目地址: https://gitcode.com/gh_mirrors/ai/AI-HF_Patch AI-Shoujo HF Patch是一款专为AI-Shoujo游戏设计的模块…...

城市供水管网抗震可靠性分析方法与系统开发【附程序】
✨ 长期致力于供水管网、抗震可靠性、修复策略、震害预测、系统开发研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)场地效应预测模型与管道地震易损性…...

终极AMD Ryzen性能调优指南:SMUDebugTool完全掌握手册
终极AMD Ryzen性能调优指南:SMUDebugTool完全掌握手册 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://gi…...

索尼IMX811如何重塑工业视觉与专业影像的边界
突破像素极限,定义成像新高度在影像技术飞速发展的今天,高分辨率始终是专业领域不懈追求的目标。索尼半导体解决方案公司重磅推出的IMX811中画幅CMOS图像传感器,以2.47亿有效像素的惊人规格,为行业带来了颠覆性的突破。这款传感器…...

DDD 中的代码组织:按技术层分 vs 按领域模块分,哪种才是正解?
前言 在实践领域驱动设计(DDD)时,你可能见过两种截然不同的代码组织方式:一种是传统的按技术层划分文件夹,另一种是按业务模块划分文件夹。两种写法的人都声称自己在做 DDD,那到底哪种更合理?本…...

解决RK3568上QML卡顿的实战:从怀疑供应商到亲手编译带OpenGL ES2的Qt 5.14.2
RK3568嵌入式开发实战:破解QML卡顿之谜与OpenGL ES2编译全解析 当你在RK3568开发板上运行精心设计的QML界面时,却发现动画效果卡顿得像幻灯片播放——这种体验足以让任何嵌入式开发者抓狂。本文记录了一位开发者从发现问题到最终解决的完整历程ÿ…...