做为骨干网络的分类模型的预训代码安装配置简单记录
一、安装配置环境
1、准备工作
代码地址
GitHub - bubbliiiing/classification-pytorch: 这是各个主干网络分类模型的源码,可以用于训练自己的分类模型。
# 创建环境
conda create -n ptorch1_2_0 python=3.6
# 然后启动
conda install pytorch==1.2.0 torchvision==0.4.0 cudatoolkit=10.0 -c pytorch
pip install scipy==1.2.1 numpy==1.17.0 matplotlib==3.1.2 opencv_python==4.1.2.30 tqdm==4.60.0 Pillow==8.2.0 h5py==2.10.0
下载好后 他的那个数据集 按他那个配置,然后在项目根目录下运行
python txt_annotation.py 生成对应的 txt 文件
2、遇到的问题
1、
ImportError: TensorBoard logging requires TensorBoard with Python summary writer installed. This should be available in 1.14 or above.解决
pip install tensorboard2、
ModuleNotFoundError: No module named 'past'解决办法
pip install future3、
ImportError: libSM.so.6: cannot open shared object file: No such file or directory
# 和
ImportError: libXrender.so.1: cannot open shared object file: No such file or directory解决
apt-get install libsm6
apt-get install libxrender1二、debug 记录
1、train_lines

val_lines

2、 show_config
----------------------------------------------------------------------
| keys | values|
----------------------------------------------------------------------
| num_classes | 2|
| backbone | mobilenetv2|
| model_path | |
| input_shape | [224, 224]|
| Init_Epoch | 0|
| Freeze_Epoch | 50|
| UnFreeze_Epoch | 200|
| Freeze_batch_size | 32|
| Unfreeze_batch_size | 32|
| Freeze_Train | True|
| Init_lr | 0.01|
| Min_lr | 0.0001|
| optimizer_type | sgd|
| momentum | 0.9|
| lr_decay_type | cos|
| save_period | 10|
| save_dir | logs|
| num_workers | 4|
| num_train | 20000|
| num_val | 5000|
----------------------------------------------------------------------3、 optimizer

4、打印日志
Start Train
Epoch 1/200: 0%| | 0/625 [00:00<?, ?it/s<class 'dict'>]utils_fit.py --- 19
if local_rank == 0:print('Start Train')pbar = tqdm(total=epoch_step,desc=f'Epoch {epoch + 1}/{Epoch}',postfix=dict,mininterval=0.3)5、
gen

batch

三、其它
1、打印模型 model, 这个应该是 backbone
MobileNetV2((features): Sequential((0): ConvBNReLU((0): Conv2d(3, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU6(inplace=True))(1): InvertedResidual((conv): Sequential((0): ConvBNReLU((0): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU6(inplace=True))(1): Conv2d(32, 16, kernel_size=(1, 1), stride=(1, 1), bias=False)(2): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(2): InvertedResidual((conv): Sequential((0): ConvBNReLU((0): Conv2d(16, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU6(inplace=True))(1): ConvBNReLU((0): Conv2d(96, 96, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=96, bias=False)(1): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU6(inplace=True))(2): Conv2d(96, 24, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(24, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(3): InvertedResidual((conv): Sequential((0): ConvBNReLU((0): Conv2d(24, 144, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(144, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU6(inplace=True))(1): ConvBNReLU((0): Conv2d(144, 144, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=144, bias=False)(1): BatchNorm2d(144, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU6(inplace=True))(2): Conv2d(144, 24, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(24, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(4): InvertedResidual((conv): Sequential((0): ConvBNReLU((0): Conv2d(24, 144, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(144, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU6(inplace=True))(1): ConvBNReLU((0): Conv2d(144, 144, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=144, bias=False)(1): BatchNorm2d(144, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU6(inplace=True))(2): Conv2d(144, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(5): InvertedResidual((conv): Sequential((0): ConvBNReLU((0): Conv2d(32, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU6(inplace=True))(1): ConvBNReLU((0): Conv2d(192, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=192, bias=False)(1): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU6(inplace=True))(2): Conv2d(192, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(6): InvertedResidual((conv): Sequential((0): ConvBNReLU((0): Conv2d(32, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU6(inplace=True))(1): ConvBNReLU((0): Conv2d(192, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=192, bias=False)(1): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU6(inplace=True))(2): Conv2d(192, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(7): InvertedResidual((conv): Sequential((0): ConvBNReLU((0): Conv2d(32, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU6(inplace=True))(1): ConvBNReLU((0): Conv2d(192, 192, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=192, bias=False)(1): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU6(inplace=True))(2): Conv2d(192, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(8): InvertedResidual((conv): Sequential((0): ConvBNReLU((0): Conv2d(64, 384, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(384, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU6(inplace=True))(1): ConvBNReLU((0): Conv2d(384, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=384, bias=False)(1): BatchNorm2d(384, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU6(inplace=True))(2): Conv2d(384, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(9): InvertedResidual((conv): Sequential((0): ConvBNReLU((0): Conv2d(64, 384, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(384, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU6(inplace=True))(1): ConvBNReLU((0): Conv2d(384, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=384, bias=False)(1): BatchNorm2d(384, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU6(inplace=True))(2): Conv2d(384, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(10): InvertedResidual((conv): Sequential((0): ConvBNReLU((0): Conv2d(64, 384, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(384, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU6(inplace=True))(1): ConvBNReLU((0): Conv2d(384, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=384, bias=False)(1): BatchNorm2d(384, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU6(inplace=True))(2): Conv2d(384, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(11): InvertedResidual((conv): Sequential((0): ConvBNReLU((0): Conv2d(64, 384, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(384, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU6(inplace=True))(1): ConvBNReLU((0): Conv2d(384, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=384, bias=False)(1): BatchNorm2d(384, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU6(inplace=True))(2): Conv2d(384, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(12): InvertedResidual((conv): Sequential((0): ConvBNReLU((0): Conv2d(96, 576, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(576, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU6(inplace=True))(1): ConvBNReLU((0): Conv2d(576, 576, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=576, bias=False)(1): BatchNorm2d(576, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU6(inplace=True))(2): Conv2d(576, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(13): InvertedResidual((conv): Sequential((0): ConvBNReLU((0): Conv2d(96, 576, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(576, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU6(inplace=True))(1): ConvBNReLU((0): Conv2d(576, 576, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=576, bias=False)(1): BatchNorm2d(576, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU6(inplace=True))(2): Conv2d(576, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(14): InvertedResidual((conv): Sequential((0): ConvBNReLU((0): Conv2d(96, 576, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(576, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU6(inplace=True))(1): ConvBNReLU((0): Conv2d(576, 576, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=576, bias=False)(1): BatchNorm2d(576, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU6(inplace=True))(2): Conv2d(576, 160, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(160, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(15): InvertedResidual((conv): Sequential((0): ConvBNReLU((0): Conv2d(160, 960, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(960, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU6(inplace=True))(1): ConvBNReLU((0): Conv2d(960, 960, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=960, bias=False)(1): BatchNorm2d(960, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU6(inplace=True))(2): Conv2d(960, 160, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(160, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(16): InvertedResidual((conv): Sequential((0): ConvBNReLU((0): Conv2d(160, 960, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(960, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU6(inplace=True))(1): ConvBNReLU((0): Conv2d(960, 960, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=960, bias=False)(1): BatchNorm2d(960, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU6(inplace=True))(2): Conv2d(960, 160, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(160, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(17): InvertedResidual((conv): Sequential((0): ConvBNReLU((0): Conv2d(160, 960, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(960, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU6(inplace=True))(1): ConvBNReLU((0): Conv2d(960, 960, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=960, bias=False)(1): BatchNorm2d(960, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU6(inplace=True))(2): Conv2d(960, 320, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(320, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(18): ConvBNReLU((0): Conv2d(320, 1280, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(1280, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU6(inplace=True)))(classifier): Sequential((0): Dropout(p=0.2, inplace=False)(1): Linear(in_features=1280, out_features=2, bias=True))
)2、数据集导入与建立
train.py --- 384 397
train_dataset = DataGenerator(train_lines, input_shape, True)
val_dataset = DataGenerator(val_lines, input_shape, False)gen = DataLoader(train_dataset, shuffle=shuffle, batch_size=batch_size, num_workers=num_workers, pin_memory=True, drop_last=True, collate_fn=detection_collate, sampler=train_sampler)
gen_val = DataLoader(val_dataset, shuffle=shuffle, batch_size=batch_size, num_workers=num_workers, pin_memory=True,drop_last=True, collate_fn=detection_collate, sampler=val_sampler)3、 开始训练模型
train.py --- 404
for epoch in range(Init_Epoch, UnFreeze_Epoch):训练过程在 train.py --- 452
fit_one_epoch(model_train, model, loss_history, optimizer, epoch, epoch_step, epoch_step_val, gen, gen_val, UnFreeze_Epoch, Cuda, fp16, scaler, save_period, save_dir, local_rank)
4、调整学习率
train.py --- 450
set_optimizer_lr(optimizer, lr_scheduler_func, epoch)5、前向传播的入口
utils_fit.py --- 40
outputs = model_train(images)相关文章:
做为骨干网络的分类模型的预训代码安装配置简单记录
一、安装配置环境 1、准备工作 代码地址 GitHub - bubbliiiing/classification-pytorch: 这是各个主干网络分类模型的源码,可以用于训练自己的分类模型。 # 创建环境 conda create -n ptorch1_2_0 python3.6 # 然后启动 conda install pytorch1.2.0 torchvision…...

网络协议(九):应用层(域名、DNS、DHCP)
网络协议系列文章 网络协议(一):基本概念、计算机之间的连接方式 网络协议(二):MAC地址、IP地址、子网掩码、子网和超网 网络协议(三):路由器原理及数据包传输过程 网络协议(四):网络分类、ISP、上网方式、公网私网、NAT 网络…...
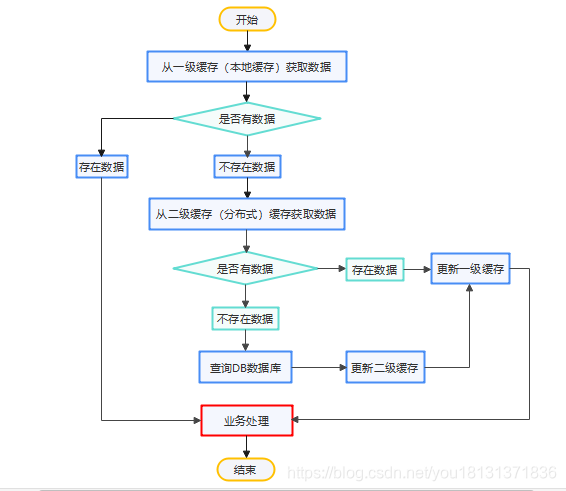
有趣的小知识(三)提升网站速度的秘诀:掌握缓存基础,让你的网站秒开
像MySql等传统的关系型数据库已经不能适用于所有的业务场景,比如电商系统的秒杀场景,APP首页的访问流量高峰场景,很容易造成关系型数据库的瘫痪,随着缓存技术的出现很好的解决了这个问题。 一、缓存的概念(什么是缓存…...

SpringCloud之服务拆分和实现远程调用案例
服务拆分对单体架构项目来说:简单方便,高度耦合,扩展性差,适合小型项目。而对于分布式架构来说:低耦合,扩展性好,但架构复杂,难度大。微服务就是一种良好的分布式架构方案࿱…...
: com.atguigu.dao.UserDao.save)
mybatis: Invalid bound statement (not found): com.atguigu.dao.UserDao.save
问题描述: 1 问题实质: dao层(又叫mapper接口)跟mapper.xml文件没有映射 2 问题原因: 出现这种映射问题的原因分为低级原因和更低级原因两种 更低级原因: (1)dao层的方法和mapper.xml中的方法不一样; (2)mapper中的namespace 值 和对应的dao层entity层不一致 &…...
JavaScript 代码规范
所有的 JavaScript 项目适用同一种规范。JavaScript 代码规范代码规范通常包括以下几个方面:变量和函数的命名规则空格,缩进,注释的使用规则。其他常用规范……规范的代码可以更易于阅读与维护。代码规范一般在开发前规定,可以跟你的团队成员…...

6综合项目 旅游网 【6.我的收藏和收藏排行榜】
我的收藏分析先登录→拿到当前登录的用户信息,从数据库中获取uid和对应uid的rid集合→将rid集合信息展示到我的收藏前台代码判断用户是否登录,传递uid,通过uid查找其对应的rid集合当查询的属性涉及到多张表,则必须使用多表连接&am…...
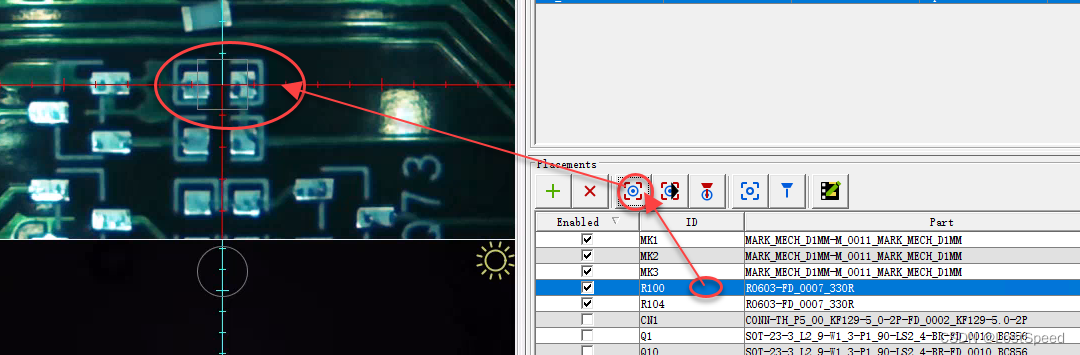
openpnp - error - 微调mark点坐标后,更新板子其他原件其他坐标报错的变通方法
文章目录openpnp - error - 微调mark点坐标后,更新板子其他原件其他坐标报错的变通方法概述想出来一个变通的方法ENDopenpnp - error - 微调mark点坐标后,更新板子其他原件其他坐标报错的变通方法 概述 载入坐标文件后, 指定左下角远点坐标, 然后定位板子上的3个Mark点, 因为…...

借助ChatGPT爆火,股价暴涨又暴跌后,C3.ai仍面临巨大风险
来源:猛兽财经 作者:猛兽财经 C3.ai的股价 作为一家人工智能技术提供商,C3.ai(AI)的股价曾在2021年初随着炒作情绪的增加,达到了历史最高点,但自那以后其股价就下跌了90%,而且炒作情…...

蓝桥杯-数位排序
蓝桥杯-数位排序1、问题描述2、解题思路3、代码实现1、问题描述 小蓝对一个数的数位之和很感兴趣, 今天他要按照数位之和给数排序。当 两个数各个数位之和不同时, 将数位和较小的排在前面, 当数位之和相等时, 将数值小的排在前面。 例如, 2022 排在 409 前面, 因为 2022 的数位…...
)
【ES实战】ES 插件包离线安装(本地文件)
ES 插件包离线安装(本地文件) 文章目录ES 插件包离线安装(本地文件)使用安装命令安装直接解压式验证安装情况常用的分词插件analysis-ik analysis-pinyin analysis-dynamic-synonym 在集群的节点上分发插件的ZIP安装包 使用安…...

Spring的核心基础——IOC与DI
文章目录一、Spring简介1 Spring介绍1.1 为什么要学1.2 学什么2 初识Spring2.1 Spring家族2.2 Spring发展史3 Spring体系结构3.1 Spring Framework系统架构图4 Spring核心概念问题导入4.1 核心概念二、IOC和DI入门1 IOC入门问题导入1.1 门案例思路分析1.2 实现步骤1.3 实现代码…...

C++正则表达式基础
文章目录1. 查找第一个匹配的2. 查找所有结果3. 打印匹配结果的上下文4. 使用子表达式5. 查找并替换注意: .(点)在括号中没有特殊含义,无需转义用\转义。 1. 查找第一个匹配的 #include <iostream> #include <regex>using names…...

如何在网络安全中使用人工智能并避免受困于此
人工智能在网络安全中的应用正在迅速增长,并对威胁检测、事件响应、欺诈检测和漏洞管理产生了重大影响。根据Juniper Research的一份报告,预计到2023年,使用人工智能进行欺诈检测和预防将为企业每年节省110亿美元。但是,如何将人工…...

生态 | 人大金仓与超聚变的多个产品完成兼容认证
近日,人大金仓与超聚变数字技术有限公司(简称“超聚变”)完成了多款产品的兼容互认测试。测试表明,人大金仓KingbaseES V8数据库与超聚变服务器操作系统FusionOS、超聚变FusionOne基础设施完全兼容,人大金仓异构数据同…...

4自由度串联机械臂按颜色分拣物品功能的实现
1. 功能说明 本实验要实现的功能是:将黑、白两种颜色的工件分别放置在传感器上时,机械臂会根据检测到的颜色,将工件搬运至写有相应颜色字样区域。 2. 使用样机 本实验使用的样机为4自由度串联机械臂。 3. 运动功能实现 3.1 电子硬件 在这个…...
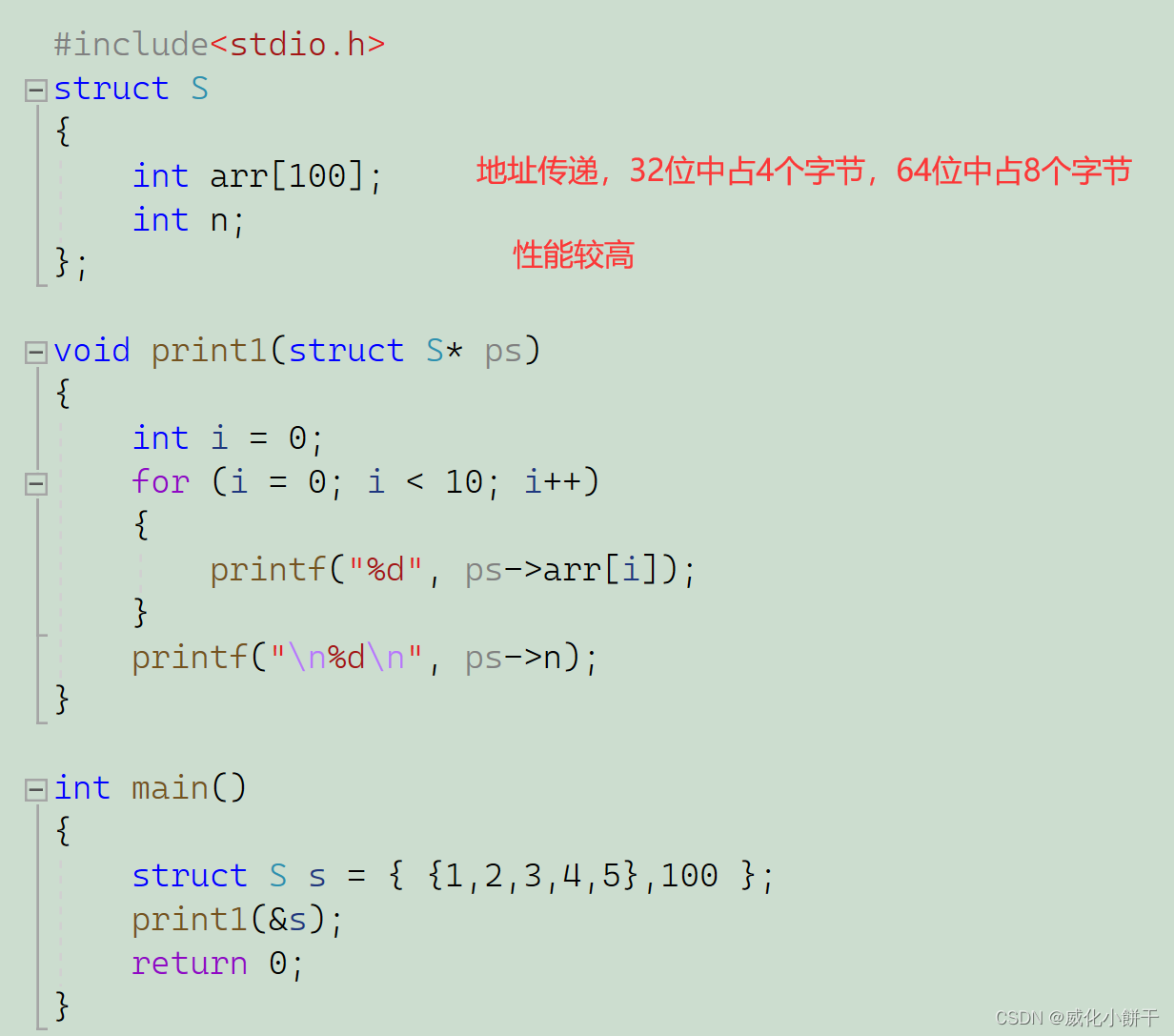
玩转结构体---【C语言】
⛩️博主主页:威化小餅干📝系列专栏:【C语言】藏宝图🎏 ✨绳锯⽊断,⽔滴⽯穿!一个编程爱好者的学习记录!✨目录结构体类型的声明结构体成员访问结构体传参前言我们是否有想过,为什么会有结构体呢…...

c语言指针怎么理解 第二部分
第四,指针有啥用。 比方说,我们有个函数,如下: int add(int x){ return (x1); //把输入的值加1并返回结果。 } 好了,应用的时候是这样的: { int a1; aadd(a); //add函数返回的是a1 //现在 a等于…...
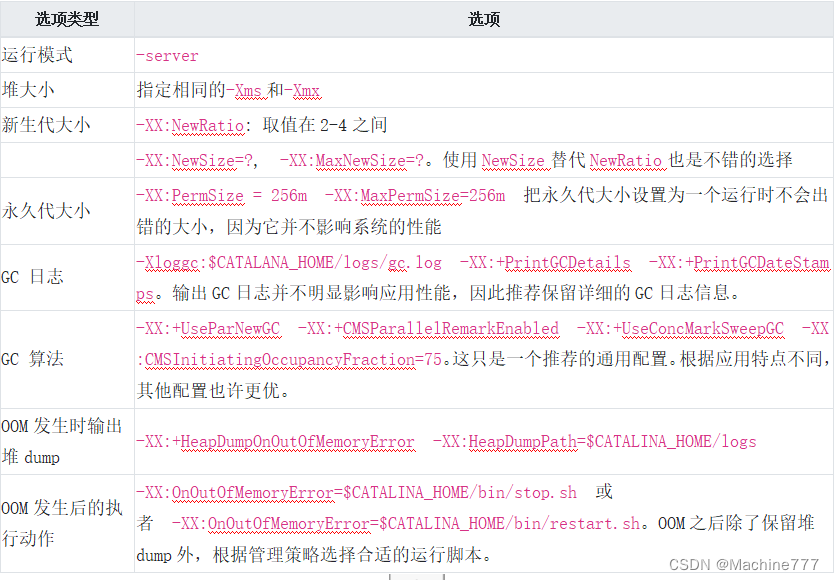
GC简介和监控调优
GC简介: GC(Garbage Collection)是java中的垃圾回收机制,是Java与C/C的主要区别之一,在使用JAVA的时候,一般不需要专门编写内存回收和垃圾清理代 码。这是因为在Java虚拟机中,存在自动内存管理和垃圾清扫机制。 什么…...

Understanding The Linux Kernel --- Part2 Memory Addressing
内存寻址 操作系统自身不必完全了解物理内存,如今的微处理器包含的硬件线路使内存管理既高效又健壮,所以编程错误就不会对该程序之外的内存产生非法访问 x86如何进行芯片级内存寻址Linux如何利用寻址硬件 x86 三种不同的地址术语 逻辑地址 逻辑地址…...

3步精通MOOTDX:量化投资数据接口实战指南
3步精通MOOTDX:量化投资数据接口实战指南 【免费下载链接】mootdx 通达信数据读取的一个简便使用封装 项目地址: https://gitcode.com/GitHub_Trending/mo/mootdx MOOTDX是一个专为量化投资和数据分析设计的Python库,它提供了高效、便捷的通达信数…...

DavyBot开源框架:构建智能对话机器人的模块化实践指南
1. 项目概述:一个开箱即用的智能对话机器人框架最近在折腾聊天机器人项目,发现了一个挺有意思的开源项目,叫geluzhiwei1/davybot。乍一看这个名字,可能觉得有点陌生,但如果你在GitHub上搜索过聊天机器人、智能客服或者…...

3分钟快速上手:91160-cli医疗预约自动化助手完整指南
3分钟快速上手:91160-cli医疗预约自动化助手完整指南 【免费下载链接】91160-cli 健康160全自动挂号脚本,捡漏神器 项目地址: https://gitcode.com/gh_mirrors/91/91160-cli 还在为医院挂号难而烦恼吗?91160-cli是一款专为医疗预约设计…...

从灰度图到粉彩叙事,全程可复现:5个精准Prompt模板+3类LUT预设,零基础速产美术馆级Pastel印相
更多请点击: https://intelliparadigm.com 第一章:从灰度图到粉彩叙事:Pastel印相的美学本质与技术边界 Pastel印相并非简单的色彩叠加,而是一种基于人眼感知非线性响应与胶片化学特性的数字模拟范式。其核心在于将灰度图像的亮度…...

BUUCTF:[网鼎杯 2018]Fakebook 漏洞链深度剖析:从SQL注入到SSRF的实战利用
1. 初探Fakebook:信息收集与源码泄露 打开题目链接后,我习惯性地在URL后添加/robots.txt进行探测。这个文件就像网站的"藏宝图",经常能发现开发者不想被公开的路径。果然,在这里发现了/user.php.bak这个备份文件。下载后…...

从自由建模到精确设计:CAD_Sketcher如何为Blender带来工程级草图绘制能力
从自由建模到精确设计:CAD_Sketcher如何为Blender带来工程级草图绘制能力 【免费下载链接】CAD_Sketcher Constraint-based geometry sketcher for blender 项目地址: https://gitcode.com/gh_mirrors/ca/CAD_Sketcher 你是否曾在使用Blender进行机械设计时&…...

构建个人技能知识库:从Markdown管理到自动化实践
1. 项目概述:一个技能库的诞生与价值最近在整理个人知识体系时,我一直在思考一个问题:如何将那些零散的、跨领域的“技能点”系统化地管理起来,形成一个可以持续迭代、随时取用的个人工具箱?这不仅仅是写一份简历上的技…...

基于计算机视觉的无接触生理测量:从远程PPG原理到工程实践
1. 项目概述:当普通摄像头成为健康监测的“听诊器” 几年前,我在一个远程医疗项目的早期原型测试中,遇到了一个棘手的问题。我们需要为居家康复的老人提供持续的心率监测,但传统的指夹式血氧仪或胸带式心率带,要么让用…...

自动化营销系统:高效破解市场-SDR销售线索流转堵点
在B2B营销中,线索从“获取”到“转化”的过程,往往伴随着大量的手动操作、信息断层和跟进滞后。尤其是市场团队与SDR(销售开发代表)之间的协作,常常成为线索流转的“瓶颈”。如何高效、规范地将市场获取的Leads转化为可…...

手把手教你用GD32F303定时器PWM驱动LED,从寄存器配置到CubeMX生成代码
GD32F303定时器PWM开发全攻略:寄存器配置与图形化工具实战对比 在嵌入式开发领域,PWM(脉冲宽度调制)技术如同一位无声的指挥家,精准控制着LED亮度、电机转速等关键参数。对于GD32F303这款高性能ARM Cortex-M4内核微控制…...