Flink 状态管理与容错机制(CheckPoint SavePoint)的关系
一、什么是状态
无状态计算的例子: 例如一个加法算子,第一次输入2+3=5那么以后我多次数据2+3的时候得到的结果都是5。得出的结论就是,相同的输入都会得到相同的结果,与次数无关。
有状态计算的例子: 访问量的统计,我们都知道Nginx的访问日志一个请求一条日志,基于此我们就可以统计访问量。如下,/api/a这个url第一此访问的时候,返回的结果就是 count1,但当第二次访问的时候,返回的结果变成了2。为什么Flink知道之前已经处理过一次 hello world,这就是state发挥作用了,这里是被称为keyed state存储了之前需要统计的数据,keyby接口的调用会创建keyed stream对key进行划分,这是使用keyed state的前提。得出的结论就是,相同的输入得到不同的结果,与次数有关。这就是有状态的数据。
![[点击并拖拽以移动] ](https://img-blog.csdnimg.cn/direct/bfe5bd6d492442988b1093be08422513.png)
什么场景下会大量使用到这种状态数据啦?简单举几个例子:
【1】去重的需求中,比如说我们只想知道这100个同事都属于那几个部门的等等。
【2】窗口计算,已进入未触发的数据。比如,我们一分钟统计一次,1-2之间的1.5这个时候的数据对于2来说就是一个有状态的数据,因为2的结果与1.5有关。
【3】机器学习/深度学习,训练的模型及参数。这对于机器学习的同学深入感触。比如,第一次输入hello,机器会给我一个反馈,那么下次会基于这个反馈做进一步的学习处理。那么上一步的结果对于我而言就是一种有状态的输入。
【4】访问历史数据,需要与昨日进行对比。昨日的数据对于今日而言也属于一种状态。你品,你细品。
为什么要管理状态,用内存不香吗?首先流失作业是有它的标准的,不是什么东西随随便便就说自己这个是流失处理。首先,7*24小时运行,高可靠,你内存不行吧,你的容量总有用完的时候吧。其次,数据不丢失不重,恰好计算一次,你内存要实现需要备份和恢复,你还总伴随着小部分数据的丢失吧。最后,数据实时产生,不延迟,你内存不够横向扩展时,你需要延迟吧。
理想的状态管理就是下面描述的样子,Flink也都帮我们实现了。
![[点击并拖拽以移动] ](https://img-blog.csdnimg.cn/direct/74dfefe7bc7a4a529ae517cc496f7521.png)
二、状态的类型
Managed State & Raw State
| Managed State | Raw State | |
|---|---|---|
| 状态管理方式 | Flink Runtime 管理 —自动存储,自动恢复 —内存管理上有优化 | 用户自己管理(Flink不知道你在State中存储的数据结构的) —要自己实例化 |
| 状态数据结构 | 已知的数据结构 —value,list,map… | 字节数据 —byte[] |
| 推荐使用场景 | 大多数情况下均可使用 | 自定义 Operator 时可以使用(当Managed State 不够时使用) |
Managed Stated 分为: Keyed Stated和Operator State
【1】Keyed Stated: 只能用于keyBy生成的KeyedStream上的算子。每一个key对应一个State,一个Operator实例处理多个Key,访问相应的多个State。相同Key会在相同的实例中处理。整个过程如果没有keyBy操作,它是没有KeyedStream的,而Keyed Stated只能应用在KeyedStream 上。
并发改变: State随着Key在实例间迁移。例如:实例A中之前处理KeyA与KeyB,后面我扩展了实例B,那么 实例A就只需要处理KeyA,KeyB就交给 实例B进行处理。安装状态进行分离,可以理解为分布式。
通过 RuntimeContext 访问,说明Operator是一个Rich Function,否则是拿不到RuntimeContext。
支持的数据结构: ValueState、ListState、ReducingState、AggregatingState、MapState
【2】Operator State: 可以用于所有的算子,常用于source上,例如FlinkKafkaConsumer。一个Operator实例对应一个State,所以一个Operator中会处理多个key,可以理解为集群。
并发改变: Operator State没有key,并发改变的时候就需要重新分配。内置了两种方案:均匀分配和合并后每个得到全量。
访问方式: 实现CheckpointedFunction或ListCheckpointed接口。
支持的数据结构: ListState
三、Keyed State 使用示例
什么是 keyed state: 对于keyed state,有两个特点:
【1】只能应用于KeyedStream 的函数与操作中,例如Keyed UDF, window state;
【2】keyed state是已经分区 / 划分好的,每一个 key 只能属于某一个 keyed state;
对于如何理解已经分区的概念,我们需要看一下keyby的语义,大家可以看到下图左边有三个并发,右边也是三个并发,左边的词进来之后,通过keyby会进行相应的分发。例如对于hello word,hello这个词通过hash运算永远只会到右下方并发的task上面去。
![[点击并拖拽以移动] ](https://img-blog.csdnimg.cn/direct/0fa22dc275054473a2fd61f68d86b68f.png)
什么是 operator state
【1】又称为non-keyed state,每一个operator state都仅与一个operator的实例绑定。
【2】常见的operator state是source state,例如记录当前source的offset再看一段使用operator state的word count代码:
![[点击并拖拽以移动] ](https://img-blog.csdnimg.cn/direct/0fc4b3a77d3a48f3a5329aba2aa31615.png)
这里的fromElements会调用FromElementsFunction的类,其中就使用了类型为list state的operator state。如下几种Keyed State之间的依赖关系,都是state的子类。它们的访问方式和数据结构都有一定的区别。
![[点击并拖拽以移动] ](https://img-blog.csdnimg.cn/direct/c45fa1db62c94783b638e6cd690b7dd7.png)
| 状态数据类型 | 访问接口 | 备注 | |
|---|---|---|---|
| ValueState | 单个值 | [update(T) 修改/T value 获取] | 例如 WordCount 用 word 做 key,state就是单个的数值。这个单个也可以是字符串、对象等都有可能。访问方式只有上面两种。 |
| MapState | Map | put(UK key, UV value) putAll(Map<UK,UV> map) remove(UK key) boolean contains(UK key) UV get(UK key) Iterable<Map.Entry> entries() Iterable<Map.Entry> iterator() Iterable keys() Iterable values() | 能够操作具体的对象的key |
| ListState | List | add/ addAll(List) update(List) Iterable get() | |
| ReducingState | 单个值 | add/ addAll(List) update(List) T get() | 与 List 是同一个父类,这个add是直接将数据更新进了 Reducing的结果里面。举个例子,例如我们统计1分钟的结果,list是先将数据添加到list中,等到1分钟的时候全来出来统计。而 Reducing是来一条就统计一条结果。好处是节省内存。 |
| AggregatingState | 单个值 | add(IN)/OUT get() | 与 List 是同一个父类,与Reducing的不同是,Reducing输入和输出的类型都是相同的。而Aggregating 是可以不同的。例如,我要计算一个平局值,Reducing是算好返回,而Aggregating会返回总和和个数。 |
举个ValueState的案例
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//获取数据流
DataStream<Event> events = env.addSource(source);DataStream<Alert> alerts = events// 生成 keyedStata 通过 sourceAddress.keyBy(Event::sourceAddress)// StateMachineMapper 状态机.flatMap(new StateMachineMapper());//我么看下状态机怎么写 实现 RichFlatMapFunction
@SuppressWarnings("serial")
static class StateMachineMapper extends RichFlatMapFunction<Event, Alert> {private ValueState<LeaderLatch.State> currentState;@Overridepublic void open(Configuration conf) {// 获取一个 valueStatecurrentState = getRuntimeContext().getState(new ValueStateDescriptor<>("state", State.class));}//来一条数据处理一条@Overridepublic void flatMap(Event evt, Collector<Alert> out) throws Exception {// 获取 valueState state = currentState.value();if (state == null) {state = State.Initial;//State 是本地的变量}// 把事件对状态的影响加上去,得到一个状态State nextState = state.transition(evt.type());//判断状态是否合法if (nextState == State.InvalidTransition) {//扔出去out.collect(new Alert(evt.sourceAddress(), state, evt.type()));}//是否不能继续转化了,例如取消的订单else if (nextState.isTerminal()) {// 从 state 中清楚掉currentState.clear();}else {// 修改状态currentState.update(nextState);}}
}
四、CheckPoint 与 state 的关系
Checkpoint是从source触发到下游所有节点完成的一次全局操作。下图可以有一个对Checkpoint的直观感受,红框里面可以看到一共触发了 569K次Checkpoint,然后全部都成功完成,没有fail的。
![[点击并拖拽以移动] ](https://img-blog.csdnimg.cn/direct/1e57eba878a644c6815cb4ecf30be85c.png)
**state 其实就是 Checkpoint 所做的主要持久化备份的主要数据,**看下图的具体数据统计,其state也就9kb大小 。
![[点击并拖拽以移动] ](https://img-blog.csdnimg.cn/direct/018fd963f44344cea42b1b8302898da5.png)
五、状态如何保存和恢复
Checkpoint定时制作分布式快照,对程序的状态进行备份。发生故障时,将整个作业的Task都回滚到最后一次成功Checkpoint中的状态,然后从保存的点继续处理。
必要条件: 数据源支持重发(如果不重发,丢失的消息就真的丢了)
一致性语义: 恰好一次(如果p相同,单线程,多个线程时,可能有的算子对其已经计算了一次了,有的没有就需要注意),至少一次。
// 获取运行环境
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//状态数据
//两个checkpoint 触发间隔设置1S,越频繁追的数据就越少,io消耗也越大
env.enableCheckpointing(1000);
//EXACTLY_ONCE语义说明 Checkpoint是要对替的,这样消息不会重复,也不会对丢。
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
//两个checkpoint 最少等待500ms 例如第一个checkpoint做了700ms按理300ms后就要做下一个checkpoint。但是它们之间的等待时间300ms<500ms 此时,就会延长200ms减少checkpoint过于频繁,影响业务。
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);
//checkpoint多久超时,如果这个checkpoint在1分钟内还没做完,那就失败了
env.getCheckpointConfig().setCheckpointTimeout(60000);
//同时最多有多少个checkpoint进行
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
//当重新分配并发度,拆分task时,是否保存checkpoint。如果不保存就需要使用savepoint来保存数据,放到外部的介质中。
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION);
Checkpoint vs Savepoint
| Checkpoint | Savepoint | |
|---|---|---|
| 触发管理方式 | 由Flink自动触发并管理 | 由用户手动触发并管理 |
| 主要用途 | 在 Task 发生异常时快速恢复,例如网络抖动导致的超时异常 | 有计划的进行备份,使作业能停止后再恢复,例如修改代码、调整并发。 |
| 特点 | 轻量、自动从故障中服务、在作业停止后默认清除 | 持久、以标准格式存储,允许代码或配置发生变化、手动触发 savepoint 恢复。 |
可选的状态存储方式:
【1】MemoryStateBackend:构造方法:
MemoryStateBackend(int maxStateSize, boolean asynchronousSnapshots)
存储方式: State:TaskManager内存。Checkpoint:JobManager内存。
容量限制: 单个State maxStateSize默认5M。maxStateSize <= akka.framesize默认10M。总大小不超过JobManager内存。
推荐使用场景: 本地测试,几乎无状态的作业,比如ETL/JobManager不容易挂,或影响不大的情况。不推荐在生产场景使用。
【2】FsStateBackend: 构造方法:
FsStateBackend(URL checkpointDataUri, boolean asynchronousSnapshots)
存储方式: State:TaskManager内存。Checkpoint:外部文件系统(本地或HDFS)。
容量限制: 单个TaskManager上State总量不超过它的内存。总大小不超过配置的文件系统容量(会定期清理)。
推荐使用场景: 常规使用状态的作业,例如分钟级窗口聚合、join。需要开启HA的作业。可以在生产环境使用。
【3】RocksDBStateBackend: 构造方法:
RocksDBStateBackend(URL checkpointDataUri, boolean enableIncrementalCheckpointing)
存储方式: State:TaskManager上的KV数据库(实际使用内存+磁盘)。Checkpoint:外部文件系统(本地或HDFS)。
容量限制: 单个TaskManager上State总量不超过它的内存+磁盘,单个key 最大2G。总大小不超过配置的文件系统容量。
推荐使用场景: 超大状态的作业,例如天级窗口聚合。需要开启HA的作业。对状态读写性能要求比较高的作业。可以在生产环境使用。
相关文章:
Flink 状态管理与容错机制(CheckPoint SavePoint)的关系
一、什么是状态 无状态计算的例子: 例如一个加法算子,第一次输入235那么以后我多次数据23的时候得到的结果都是5。得出的结论就是,相同的输入都会得到相同的结果,与次数无关。 有状态计算的例子: 访问量的统计&#x…...

CSS中更加高级的布局手段——定位之绝对定位
定位: - 定位指的就是将指定的元素摆放到页面的任意位置,通过定位可以任意的摆放元素 - 通过position属性来设置元素的定位 -可选值: static: [sttik] 默认值,元素没有开启定位 relative: [relətiv] 开启元素…...

SQL server 数据库练习题及答案(练习3)
一、编程题 公司部门表 department 字段名称 数据类型 约束等 字段描述 id int 主键,自增 部门ID name varchar(32) 非空,唯一 部门名称 description varchar(1024) …...

太绝了!这个食堂服务,戳中了打工人的心巴!
在当今数字化时代,科技的迅猛发展已经渗透到我们生活的方方面面,其中餐饮行业也不例外。食堂作为人们日常生活中不可或缺的一部分,其管理和运营也需要紧跟科技潮流。 智慧收银系统的引入,旨在提高食堂的效率、准确性和服务水平&am…...

围栏中心点
后端返回的数据格式是 [{height: 0,lat: 30.864277169098443,lng:114.35252972024682}{height: 1,lat: 30.864277169098443,lng:114.35252972024682}.........]我们要转换成 33.00494857612568,112.53886564762979;33.00307854503083,112.53728973842954;33.00170296814311,11…...

【go-zero】simple-admin框架 整合ent mysql批量插入 | ent批量插入mysql
一、完整流程 我们需要通过goctls快速生成一个RPC项目 【go-zero】simple-admin 开篇:进击 go-zero 二开框架 simple-admin 加速 go-zero 开发 之 rpc项目快速创建(更新中~) https://ctraplatform.blog.csdn.net/article/details/130087729 1、RPC项目 1.1、.proto synta…...

漏洞复现-泛微OA xmlrpcServlet接口任意文件读取漏洞(附漏洞检测脚本)
免责声明 文章中涉及的漏洞均已修复,敏感信息均已做打码处理,文章仅做经验分享用途,切勿当真,未授权的攻击属于非法行为!文章中敏感信息均已做多层打马处理。传播、利用本文章所提供的信息而造成的任何直接或者间接的…...

Flink CDC 1.0至3.0回忆录
Flink CDC 1.0至3.0回忆录 一、引言二、CDC概述三、Flink CDC 1.0:扬帆起航3.1 架构设计3.2 版本痛点 四、Flink CDC 2.0:成长突破4.1 DBlog 无锁算法4.2 FLIP-27 架构实现4.3 整体流程 五、Flink CDC 3.0:应运而生六、Flink CDC 的影响和价值…...

c语言例题7
以下程序中,主函数调用了LineMax函数,实现在N行M列的二维数组中,找出每一行上的最大值。请填空。 #define N 3 #define M 4 void LineMax(int x[N][M]) { int i,j,p; for(i0; i<N;i) { p0; for(j1; j<M;j) …...
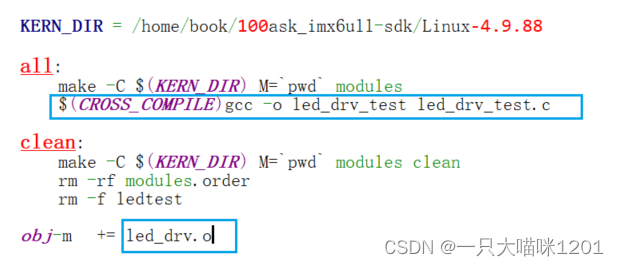
【Linux驱动】最基本的驱动框架 | LED驱动
🐱作者:一只大喵咪1201 🐱专栏:《Linux驱动》 🔥格言:你只管努力,剩下的交给时间! 目录 🏀最基本的驱动框架⚽驱动程序框架⚽编程 🏀LED驱动⚽配置GPIO⚽编程…...

前端---表单提交
1. 表单属性设置 <form>标签 表示表单标签,定义整体的表单区域 action属性 设置表单数据提交地址method属性 设置表单提交的方式,一般有“GET”方式和“POST”方式, 不区分大小写 2. 表单元素属性设置 name属性 设置表单元素的名称,…...

[C#]Parallel使用
一、 Parallel的使用 1、Parallel.Invoke2、Parallel.For3、Parallel.Foreach二、 Parallel中途退出循环和异常处理 1、当我们使用到Parallel,必然是处理一些比较耗时的操作,当然也很耗CPU和内存,如果我们中途向停止,怎么办呢&…...

docker container 指定gpu设备
1, 在yaml中 Turn on GPU access with Docker Compose | Docker Docs Example of a Compose file for running a service with access to 1 GPU device: services:test:image: nvidia/cuda:12.3.1-base-ubuntu20.04command: nvidia-smideploy:resources:reserva…...

时间Date
你有没有思考过时间问题: 前端为什么可以直接看见时间格式的数据 后端怎么接受的数据,怎么处理的 一般来说:前端传输来数据都是时间格式的字符串,那么后端需要能够解析时间格式的字符串,归功于JSONFormat ,可以解析…...

前端---css 选择器
1. css 选择器的定义 css 选择器是用来选择标签的,选出来以后给标签加样式。 2. css 选择器的种类 标签选择器类选择器层级选择器(后代选择器)id选择器组选择器伪类选择器 3. 标签选择器 根据标签来选择标签,以标签开头,此种选择器影响范…...

【MybatisPlus快速入门】(2)SpringBoot整合MybatisPlus 之 标准数据层开发 代码示例
目录 1 标准CRUD使用2 新增3 删除4 修改5 根据ID查询6 查询所有7 MyBatis-Plus CRUD总结 之前我们已学习MyBatisPlus在代码示例与MyBatisPlus的简介,在这一节中我们重点学习的是数据层标准的CRUD(增删改查)的实现与分页功能。代码比较多,我们一个个来学习…...

如何将自建的ElasticSearch注册成一个服务
ES 服务管理 注册ES服务 创建一个 Elasticsearch 服务配置文件。 sudo vim /etc/systemd/system/elasticsearch.service 将以下内容复制到 elasticsearch.service 文件中: [Unit] Descriptionelasticsearch Afternetwork.target[Service] Typeforking Useresa…...

360勒索病毒:了解最新变种.360,以及如何保护您的数据
导言: 随着科技的飞速发展,网络安全威胁也在不断演变,.360 勒索病毒成为近期备受关注的一种恶意软件。本文91数据恢复将介绍如何恢复被.360 勒索病毒加密的数据文件,并提供一些建议,帮助你预防这种威胁。 如果您在面对…...

vue使用ElementUI搭建精美页面入门
ElementUI简直是css学得不好的同学的福音 ElementUI官网: Element - The worlds most popular Vue UI framework 安装 在vue文件下,用这个命令去安装Element UI。 npm i element-ui -S step1\先切换到vue的目录下去,注意这里面的WARN不是…...

【C->Cpp】深度解析#由C迈向Cpp(2)
目录 (一)缺省参数 全缺省参数 半缺省参数 缺省参数只能在函数的声明中出现: 小结: (二)函数重载 函数重载的定义 三种重载 在上一篇中,我们从第一个Cpp程序为切入,讲解了Cpp的…...

告别重复配置!我如何用自定义Debian Live镜像实现5分钟快速部署测试环境
5分钟极速部署:打造你的专属Debian Live镜像全攻略 每次面对新机器部署测试环境时,你是否也厌倦了重复安装Docker、配置SSH、调试网络这些机械操作?作为一名常年奔波于客户现场的安全工程师,我曾花费无数个下午在咖啡厅里等待apt-…...

关注模块 API
关注用户 POST /api/v1/relations/followHeaders:Authorization: Bearer {token}Request: {"user_id": "target_user_id" }Response: {"code": 0,"data": {"relation_type": "following"} }接口语义设计 POST /…...

H3CSE 高性能园区网:VRRP 技术详解
H3CSE 高性能园区网:VRRP 技术详解VRRP 技术详解一、VRRP 简介1.1 VRRP 技术背景与定义1.1.1 技术背景1.1.2 VRRP 核心定义1.2 VRRP 核心原理与关键概念1.2.1 主备切换工作流程1.2.2 关键概念解析1.2.3 免费ARP工作原理二、VRRP 核心工作原理2.1 VRRP 基础运行原理概…...

终极文档下载指南:如何用kill-doc一键拯救30+平台的文档资源
终极文档下载指南:如何用kill-doc一键拯救30平台的文档资源 【免费下载链接】kill-doc 看到经常有小伙伴们需要下载一些免费文档,但是相关网站浏览体验不好各种广告,各种登录验证,需要很多步骤才能下载文档,该脚本就是…...

详细讲解 Spring MVC 的 HandlerInterceptor 接口
目录 一、核心定位 二、接口完整定义 三、三个核心方法详解(执行顺序 作用) 1. preHandle () —— 【请求前置处理】 2. postHandle () —— 【请求后置处理】 3. afterCompletion () —— 【请求完成清理】 四、执行流程(生命周期&a…...

【教程】全流程基于最新导则下的生态环境影响评价技术方法及图件制作与案例实践技术应用
专题一:生态环境影响评价框架及流程 以某既包含陆域、又包含水域的项目为主要案例,兼顾其它类型项目,主要内容包括: 1、生态环境影响评价基本思路与要求:工作程序、报告编制技术要求与规范 2、资料收集与初步踏勘&a…...

用于参数扫描的自定义工具
能够改变光学系统的参数是任何设置分析的关键部分,以便更好地了解系统在从制造错误到组件潜在错位的任何情况下的行为。设计一个在面对这些不可避免的偏离理想化预期设计时表现出鲁棒性的系统,与找到一个完全满足所有规范的初始设计一样重要,…...

突破内存瓶颈:HBM、CXL与GPU新部署策略
训练生成式AI模型本身已是一项成本高昂、能耗巨大的工作。随着超大规模数据中心和前沿研究机构竞相扩展边缘推理与智能体AI能力,GPU的部署正变得愈加复杂,尤其是在内存层面。在数据中心中,对先进内存配置的需求日益迫切。不断增多的AI处理器正…...
)
从CRUD到AI大神:小白程序员5个月逆袭之路(收藏版)
本文分享了作者从传统CRUD工程师转型为AI应用工程师的心路历程。通过实战先行、深入学习、项目巩固三个阶段,作者逐步掌握了AI模型开发、部署和服务化能力,并成功开发了多个AI应用项目。文章强调实践导向的学习方法,建议程序员利用AI工具提升…...

做技术选型时,别只看Star数,这五个指标更重要
在软件研发的技术选型赛道上,GitHub的Star数常被当作“流量密码”,不少团队仅凭这一指标就敲定技术栈。但对于软件测试从业者而言,Star数只是技术生态的“表面繁华”,真正决定技术选型成败的,是那些能直接影响测试可行…...