一篇文章教会你数据仓库之详解拉链表怎么做

前言
本文将会谈一谈在数据仓库中拉链表相关的内容,包括它的原理、设计、以及在我们大数据场景下的实现方式。
全文由下面几个部分组成:
- 先分享一下拉链表的用途、什么是拉链表。
- 通过一些小的使用场景来对拉链表做近一步的阐释,以及拉链表和常用的切片表的区别。
- 举一个具体的应用场景,来设计并实现一份拉链表,最后并通过一些例子说明如何使用我们设计的这张表(因为现在Hive的大规模使用,我们会以Hive场景下的设计为例)。
- 分析一下拉链表的优缺点,并对前面的提到的一些内容进行补充说明,比如说拉链表和流水表的区别。

什么是拉链表
拉链表是针对数据仓库设计中表存储数据的方式而定义的,顾名思义,所谓拉链,就是记录历史。记录一个事物从开始,一直到当前状态的所有变化的信息。
我们先看一个示例,这就是一张拉链表,存储的是用户的最基本信息以及每条记录的生命周期。我们可以使用这张表拿到最新的当天的最新数据以及之前的历史数据。
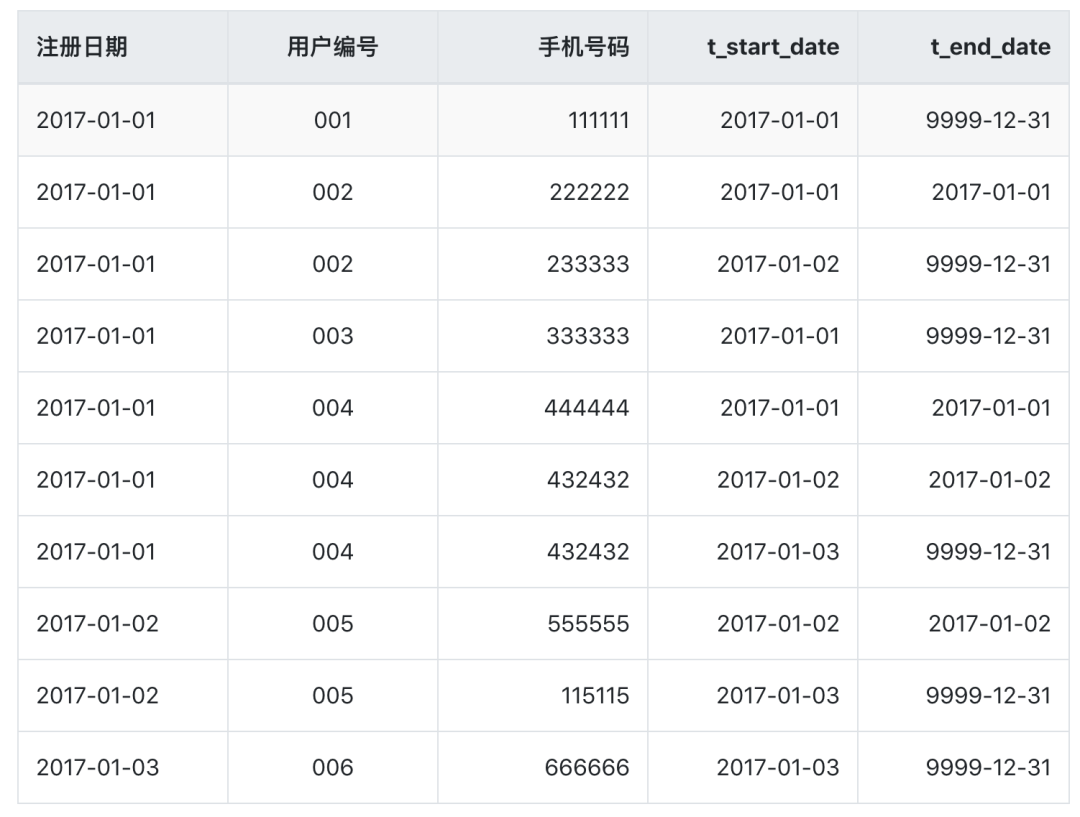
我们暂且不对这张表做细致的讲解,后文会专门来阐述怎么来设计、实现和使用它。
拉链表的使用场景
在数据仓库的数据模型设计过程中,经常会遇到下面这种表的设计:
- 有一些表的数据量很大,比如一张用户表,大约10亿条记录,50个字段,这种表,即使使用ORC压缩,单张表的存储也会超过100G,在HDFS使用双备份或者三备份的话就更大一些。
- 表中的部分字段会被update更新操作,如用户联系方式,产品的描述信息,订单的状态等等。
- 需要查看某一个时间点或者时间段的历史快照信息,比如,查看某一个订单在历史某一个时间点的状态。
- 表中的记录变化的比例和频率不是很大,比如,总共有10亿的用户,每天新增和发生变化的有200万左右,变化的比例占的很小。
那么对于这种表我该如何设计呢?下面有几种方案可选:
- 方案一:每天只留最新的一份,比如我们每天用Sqoop抽取最新的一份全量数据到Hive中。
- 方案二:每天保留一份全量的切片数据。
- 方案三:使用拉链表。
为什么使用拉链表
现在我们对前面提到的三种进行逐个的分析。
方案一
这种方案就不用多说了,实现起来很简单,每天drop掉前一天的数据,重新抽一份最新的。
优点很明显,节省空间,一些普通的使用也很方便,不用在选择表的时候加一个时间分区什么的。
缺点同样明显,没有历史数据,先翻翻旧账只能通过其它方式,比如从流水表里面抽。
方案二
每天一份全量的切片是一种比较稳妥的方案,而且历史数据也在。
缺点就是存储空间占用量太大太大了,如果对这边表每天都保留一份全量,那么每次全量中会保存很多不变的信息,对存储是极大的浪费,这点我感触还是很深的…
当然我们也可以做一些取舍,比如只保留近一个月的数据?但是,需求是无耻的,数据的生命周期不是我们能完全左右的。
拉链表
拉链表在使用上基本兼顾了我们的需求。
首先它在空间上做了一个取舍,虽说不像方案一那样占用量那么小,但是它每日的增量可能只有方案二的千分之一甚至是万分之一。
其实它能满足方案二所能满足的需求,既能获取最新的数据,也能添加筛选条件也获取历史的数据。
所以我们还是很有必要来使用拉链表的。

拉表链的设计与实现
如何设计一张拉链表
下面我们来举个栗子详细看一下拉链表。
我们用电商网站的例子,现在以用户的拉链表来说明。
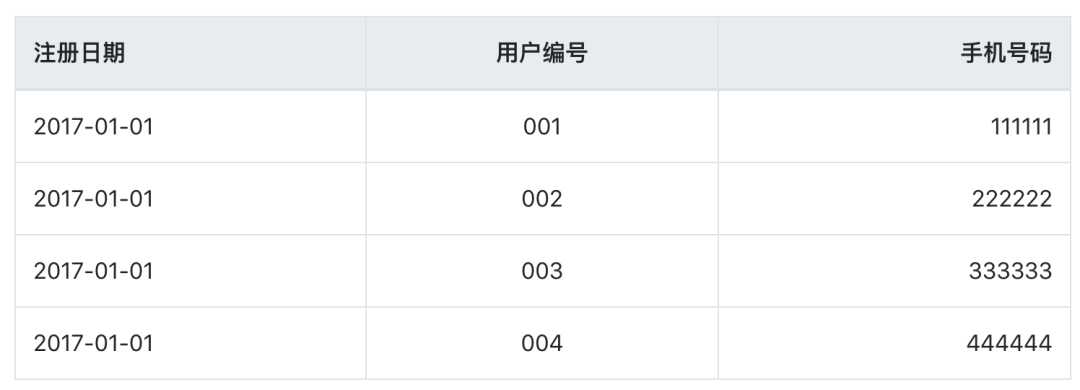
我们先看一下在Mysql关系型数据库里的user表中信息变化。
在2017-01-01这一天表中的数据是:
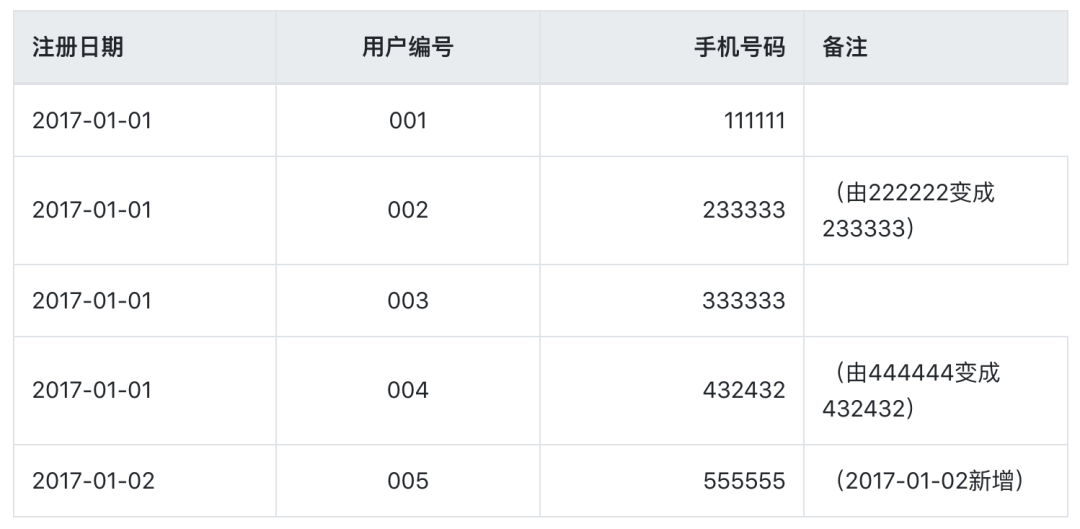
在2017-01-02这一天表中的数据是, 用户002和004资料进行了修改,005是新增用户:
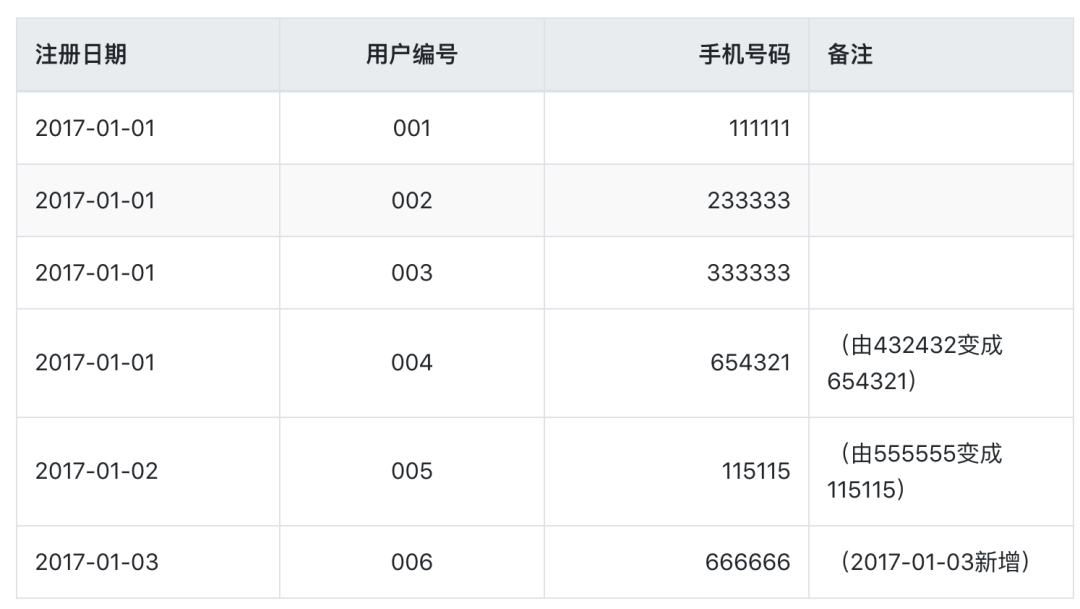
在2017-01-03这一天表中的数据是, 用户004和005资料进行了修改,006是新增用户:
如果在数据仓库中设计成历史拉链表保存该表,则会有下面这样一张表,这是最新一天(即2017-01-03)的数据:

说明
- t_start_date表示该条记录的生命周期开始时间,t_end_date表示该条记录的生命周期结束时间。
- t_end_date = '9999-12-31’表示该条记录目前处于有效状态。
- 如果查询当前所有有效的记录,则select * from user where t_end_date = ‘9999-12-31’。
- 如果查询2017-01-02的历史快照,则select * from user where t_start_date <= ‘2017-01-02’ and t_end_date >= ‘2017-01-02’。(此处要好好理解,是拉链表比较重要的一块。)
在Hive中实现拉链表
在现在的大数据场景下,大部分的公司都会选择以Hdfs和Hive为主的数据仓库架构。目前的Hdfs版本来讲,其文件系统中的文件是不能做改变的,也就是说Hive的表智能进行删除和添加操作,而不能进行update。基于这个前提,我们来实现拉链表。
还是以上面的用户表为例,我们要实现用户的拉链表。在实现它之前,我们需要先确定一下我们有哪些数据源可以用。
- 我们需要一张ODS层的用户全量表。至少需要用它来初始化。
- 每日的用户更新表。
而且我们要确定拉链表的时间粒度,比如说拉链表每天只取一个状态,也就是说如果一天有3个状态变更,我们只取最后一个状态,这种天粒度的表其实已经能解决大部分的问题了。
另外,补充一下每日的用户更新表该怎么获取,据笔者的经验,有3种方式拿到或者间接拿到每日的用户增量,因为它比较重要,所以详细说明:
- 我们可以监听Mysql数据的变化,比如说用Canal,最后合并每日的变化,获取到最后的一个状态。
- 假设我们每天都会获得一份切片数据,我们可以通过取两天切片数据的不同来作为每日更新表,这种情况下我们可以对所有的字段先进行concat,再取md5,这样就ok了。
- 流水表!有每日的变更流水表。
ods层的user表
现在我们来看一下我们ods层的用户资料切片表的结构:
CREATE EXTERNAL TABLE ods.user (user_num STRING COMMENT '用户编号',mobile STRING COMMENT '手机号码',reg_date STRING COMMENT '注册日期'
COMMENT '用户资料表'
PARTITIONED BY (dt string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LINES TERMINATED BY '\n'
STORED AS ORC
LOCATION '/ods/user';
)
ods层的user_update表
然后我们还需要一张用户每日更新表,前面已经分析过该如果得到这张表,现在我们假设它已经存在。
CREATE EXTERNAL TABLE ods.user_update (user_num STRING COMMENT '用户编号',mobile STRING COMMENT '手机号码',reg_date STRING COMMENT '注册日期'
COMMENT '每日用户资料更新表'
PARTITIONED BY (dt string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LINES TERMINATED BY '\n'
STORED AS ORC
LOCATION '/ods/user_update';
)
拉链表
现在我们创建一张拉链表:
CREATE EXTERNAL TABLE dws.user_his (user_num STRING COMMENT '用户编号',mobile STRING COMMENT '手机号码',reg_date STRING COMMENT '用户编号',t_start_date ,t_end_date
COMMENT '用户资料拉链表'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LINES TERMINATED BY '\n'
STORED AS ORC
LOCATION '/dws/user_his';
)
实现sql语句
然后初始化的sql就不写了,其实就相当于是拿一天的ods层用户表过来就行,我们写一下每日的更新语句。
现在我们假设我们已经已经初始化了2017-01-01的日期,然后需要更新2017-01-02那一天的数据,我们有了下面的Sql。
然后把两个日期设置为变量就可以了。
INSERT OVERWRITE TABLE dws.user_his
SELECT * FROM
(SELECT A.user_num,A.mobile,A.reg_date,A.t_start_time,CASEWHEN A.t_end_time = '9999-12-31' AND B.user_num IS NOT NULL THEN '2017-01-01'ELSE A.t_end_timeEND AS t_end_timeFROM dws.user_his AS ALEFT JOIN ods.user_update AS BON A.user_num = B.user_num
UNIONSELECT C.user_num,C.mobile,C.reg_date,'2017-01-02' AS t_start_time,'9999-12-31' AS t_end_timeFROM ods.user_update AS C
) AS T

补充
好了,我们分析了拉链表的原理、设计思路、并且在Hive环境下实现了一份拉链表,下面对拉链表做一些小的补充。
拉链表和流水表
流水表存放的是一个用户的变更记录,比如在一张流水表中,一天的数据中,会存放一个用户的每条修改记录,但是在拉链表中只有一条记录。
这是拉链表设计时需要注意的一个粒度问题。我们当然也可以设置的粒度更小一些,一般按天就足够。
查询性能
拉链表当然也会遇到查询性能的问题,比如说我们存放了5年的拉链数据,那么这张表势必会比较大,当查询的时候性能就比较低了,个人认为两个思路来解决:
- 在一些查询引擎中,我们对start_date和end_date做索引,这样能提高不少性能。
- 保留部分历史数据,比如说我们一张表里面存放全量的拉链表数据,然后再对外暴露一张只提供近3个月数据的拉链表。

总结
我们在这篇文章里面详细地分享了一下和拉链表相关的知识点,但是仍然会有一会遗漏。欢迎交流。
在后面的使用中又有了一些心得,补充进来:
-
使用拉链表的时候可以不加t_end_date,即失效日期,但是加上之后,能优化很多查询。
-
可以加上当前行状态标识,能快速定位到当前状态。
-
在拉链表的设计中可以加一些内容,因为我们每天保存一个状态,如果我们在这个状态里面加一个字段,比如如当天修改次数,那么拉链表的作用就会更大。
补充 学习 :极限存储 (摘取大数据之路 极限存储)
上面的拉链表存储方式对于下游使用方存在一定的理解障碍,特别是ODS 数据面向的下游用户包括数据分析师、前端开发人员等,他们不怎么理解维度模型的概念,因此会存在较高的解释成本。另外,这种存储方式用start_dt 和end_dt 做分区,随着时间的推移,分区数量会极度膨胀,而现行的数据库系统都有分区数量限制。
为了解决上述两个问题,阿里巴巴提出来用极限存储的方式来处理。
1 . 透明化 底层的数据还是历史拉链存储,但是上层做一个视图操作或者在 Hive 里做一个hook ,通过分析语句的语法树,把对极限存储前的表的 查询转换成对极限存储表的查询。对于下游用户来说,极限存储表和全 量存储方式是一样的:
Select * from A where ds =20160101
等价于
Select * from A EXST where start dt <=20160101 and end dt
>20160101 ;
2.分月做历史拉链表
假设用start_dt 和end一dt 做分区,并且不做限制,那么可以计算出 一年历史拉链表最多可能产生的分区数是:365 × 36 4 /2=66 430 个。如果 在每个月月初重新开始做历史拉链表,目录结构如下:
[-- 2 01410/ #每月一个周期
|一一20141001/ 201410 INFINITY #每月1 日的全量数据
|一一20141001/20141002 # 1001 产生且1002 死亡记录
|一一20141001/20141003 # 1001 产生且1003 死亡记录
|一一- 20141001/20141031 # 1001 产生且1031 死亡记录
|一一- 20141002/ 201410 INFINITY # 1002 产生新增记录
|一一- 20141002/20141003 # 1002 产生且1003 死亡记录
[---- 20141002 /20141031/
|---』- 20141003/ 201410 INFINITY
# 1002 产生且1031 死亡记录
# 1003 产生新增记录
! ---- 20141031/ 201410 INFINITY
[ -- 2 01411/
# 1031 产生新增记录
...
再计算一年最多可能产生的分区数是:12 ×( 1 +(30+29)/2)=5232 个。采用极限存储的处理方式,极大地压缩了全量存储的成本,又可以达到对下游用户透明的效果,是一种比较理想的存储方式。但是其本身也有一定的局限性,
首先,其产出效率很低,大部分极限存储通常需要t-2 ;
其次,对于变化频率高的数据并不能达到节约成本的效果。因此,在实际生产中,做极限存储需要进行一些额外的处理。
·在做极限存储前有一个全量存储表,全量存储表仅保留最近一段时间的全量分区数据,历史数据通过映射的方式关联到极限存储表。即用户只访问全量存储表,所以对用户来说极限存储是不可见的。
·对于部分变化频率频繁的宇段需要过滤。例如,用户表中存在用户积分宇段,这种宇段的值每天都在发生变化,如果不过滤的话,极限存储就相当于每个分区存储一份全量数据,起不到节约存储成本的效果。
相关文章:
一篇文章教会你数据仓库之详解拉链表怎么做
前言 本文将会谈一谈在数据仓库中拉链表相关的内容,包括它的原理、设计、以及在我们大数据场景下的实现方式。 全文由下面几个部分组成: 先分享一下拉链表的用途、什么是拉链表。通过一些小的使用场景来对拉链表做近一步的阐释,以及拉链表和…...

C/S医院检验LIS系统源码
一、检验科LIS系统概述: LIS系统即实验室信息管理系统。LIS系统能实现临床检验信息化,检验科信息管理自动化。其主要功能是将检验科的实验仪器传出的检验数据经数据分析后,自动生成打印报告,通过网络存储在数据库中ÿ…...
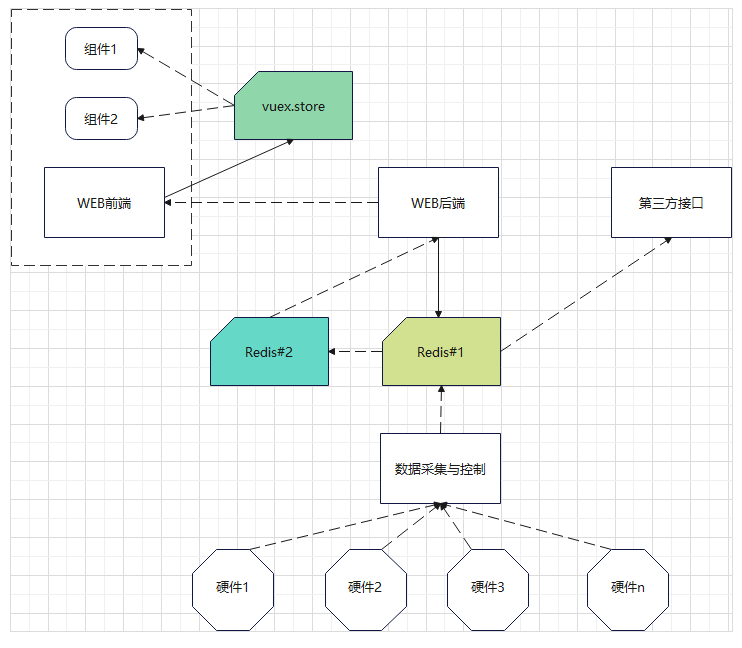
项目应用多级缓存示例
前不久做的一个项目,需要在前端实时展示硬件设备的数据。设备很多,并且每个设备的数据也很多,总之就是数据很多。同时,设备的刷新频率很快,需要每2秒读取一遍数据。 问题来了,我们如何读取数据,…...

音视频技术开发周刊 | 325
每周一期,纵览音视频技术领域的干货。 新闻投稿:contributelivevideostack.com。 AI读心术震撼登顶会!模型翻译脑电波,人类思想被投屏|NeurIPS 2023 在最近举办的NeurIPS大会上,研究人员展示了当代AI更震撼…...
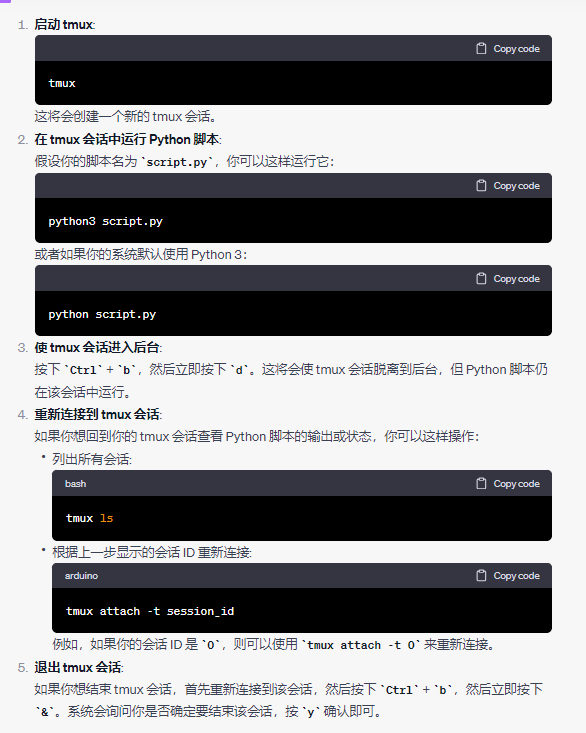
量化服务器 - 后台挂载运行
服务器 - 后台运行 pip3命令被kill 在正常的pip命令后面加上 -no-cache-dir tmux 使用教程 https://codeleading.com/article/40954761108/ 如果你希望在 tmux 中后台执行一个 Python 脚本,你可以按照以下步骤操作: 启动 tmux: tmux这将会创建一个新…...
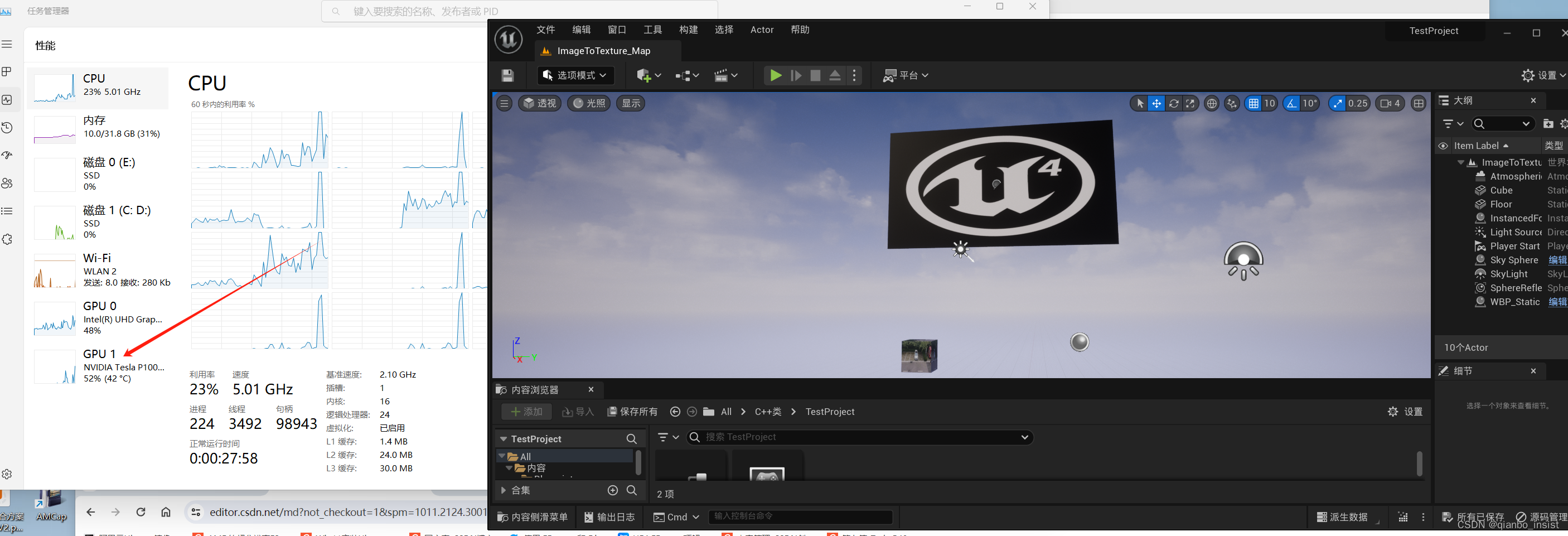
使用tesla gpu 加速大模型,ffmpeg,unity 和 UE等二三维应用
我们知道tesla gpu 没有显示器接口,那么在windows中怎么使用加速unity ue这种三维编辑器呢,答案就是改变注册表来加速相应的三维渲染程序. 1 tesla gpu p40 p100 加速 在windows中使用regedit 来改变 核显配置, 让p100 p40 等等显卡通过核显…...
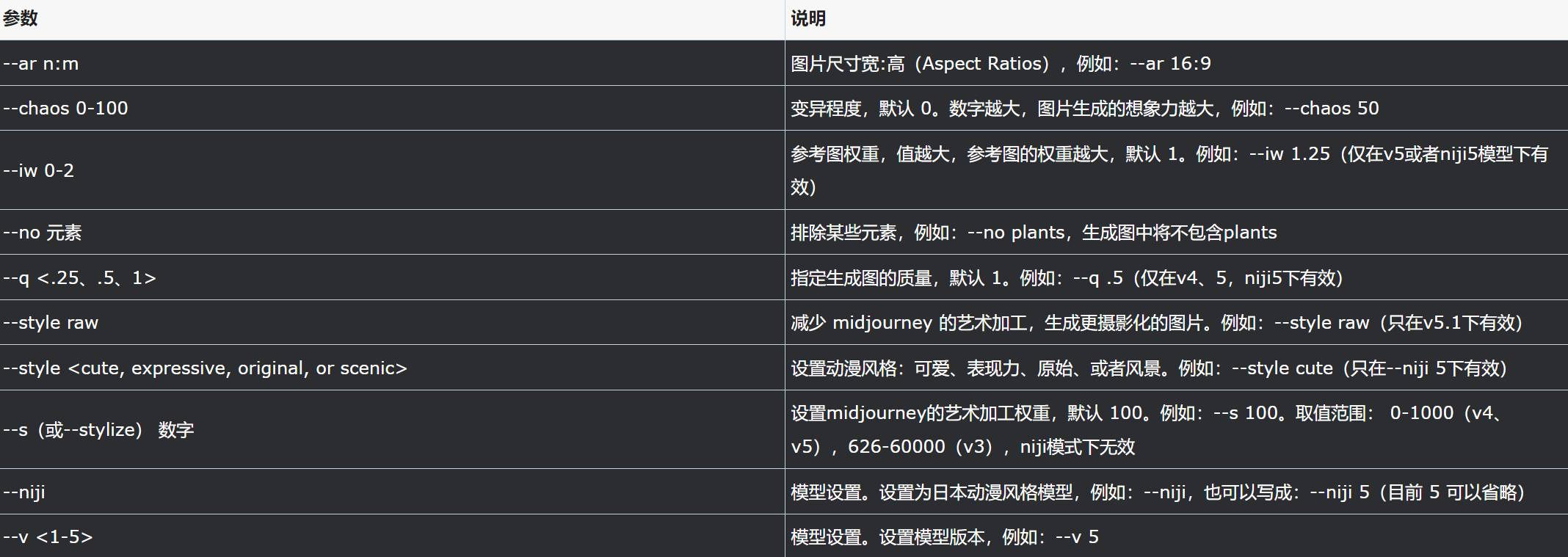
巅峰画师Midjourney:新时代的独角兽
介绍 AI绘画领域中,Midjourney处于绝对地位,并且一年时间就登顶。 Midjourney是一家独立的AI研究实验室,探索新的思维媒介,拓展人类的想象力。 它由一个小型的自筹资金团队组成,专注于设计、人类基础设施和AI。 在AI绘画领域,Midjourney取得了非常突出…...

入行 4 年,跳槽 2 次,我摸透了软件测试这一行!
最近几年行业在如火如荼的发展壮大,以及其他传统公司都需要大批量的软件测试人员,但是最近几年的疫情导致大规模裁员,让人觉得行业寒冬已来,软件测试人员的职业规划值得我们深度思考。 大家都比较看好软件测试行业,只是…...

Hive01_安装部署
Hive的安装 上传安装包 解压 tar zxvf apache-hive-3.1.2-bin.tar.gz mv apache-hive-3.1.2-bin hive解决Hive与Hadoop之间guava版本差异 cd /export/software/hive/ rm -rf lib/guava-19.0.jarcp cp /export/software/hadoop/hadoop-3.3.0/share/hadoop/common/lib/guava-27.0…...

解决国内大模型痛点的最佳实践方案
1.前言 自AI热潮掀起以来,国内互联网大厂躬身入局,各类机构奋起追赶,创业型企业纷至沓来。业内戏称,一场大模型的“百模大战”已经扩展到“千模大战”。 根据近期中国科学技术信息研究所发布的《中国人工智能大模型地图研究报告…...

当文字成为雨滴:HTML、CSS、JS创作炫酷的“文字雨“动画!
简介 在本篇技术文章中,将介绍如何使用HTML、CSS和JavaScript创建一个独特而引人注目的"文字(字母&数字)"雨🌧️动画效果。通过该动画,展现出的是一系列随机字符将从云朵中下落像是将文字变成雨滴从天而降,营造出与…...
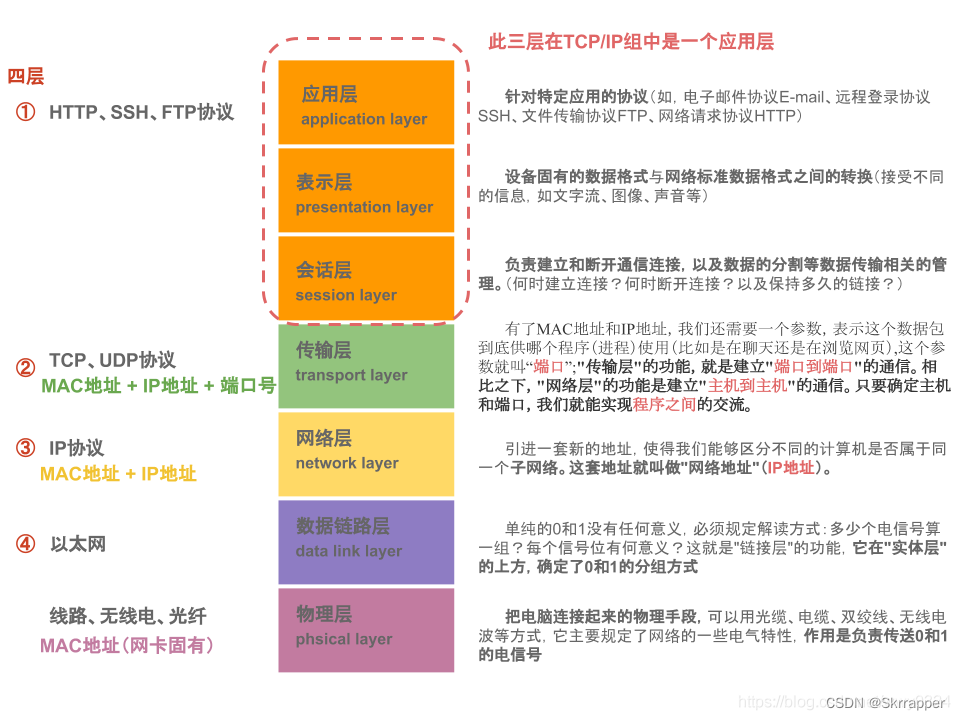
计算机网络简述
前言 计算机网路是一个很庞大的话题。在此我仅对其基础概述以及简单应用进行陈述。后续或有补充以形成完善的计算机网络知识体系。 一.计算机网络的定义 根据百度词条的描述,计算机网络是指将地理位置不同的具有独立功能的多台计算机及其外部设备,通过…...
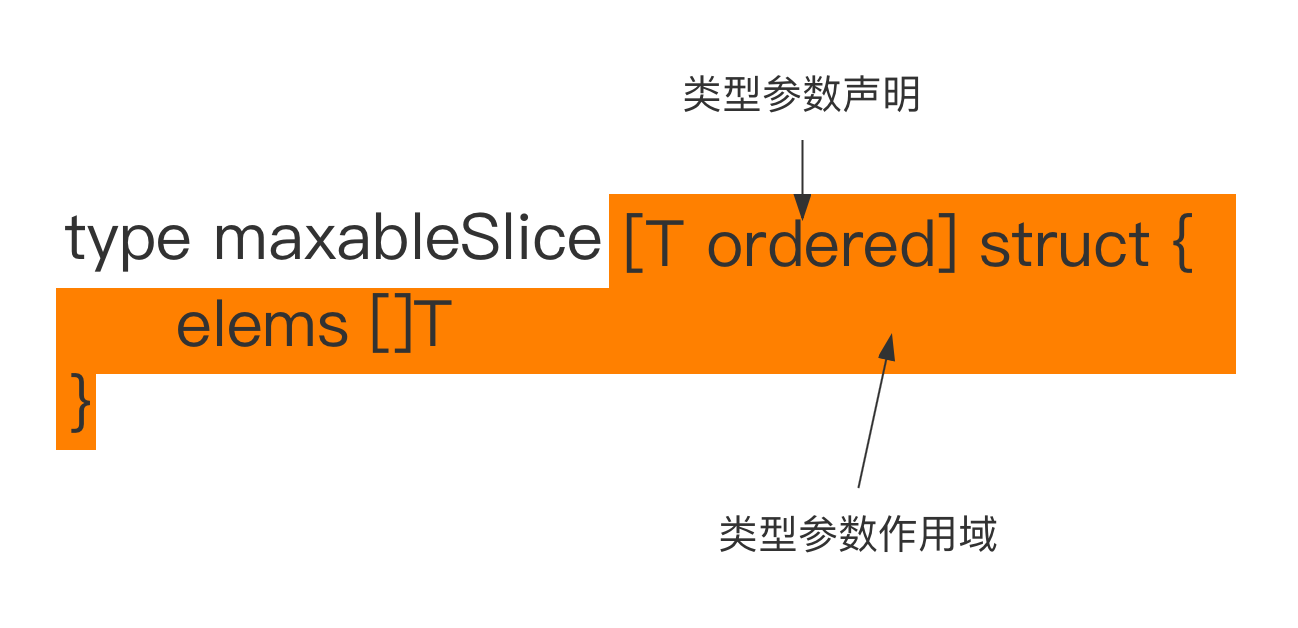
Go 泛型之类型参数
Go 泛型之类型参数 文章目录 Go 泛型之类型参数一、Go 的泛型与其他主流编程语言的泛型差异二、返回切片中值最大的元素三、类型参数(type parameters)四、泛型函数3.1 泛型函数的结构3.2 调用泛型函数3.3 泛型函数实例化(instantiation&…...

KafkaLog4jAppender
Apache Log4j 中有一个 Appender 概念,它负责将日志信息输出到各种目的地,例如控制台、文件、数据库等。KafkaLog4jAppender 是 Log4j 的一个扩展,它可以将日志信息发送到 Apache Kafka。 下面是如何在 Log4j 中使用 KafkaLog4jAppender 的一…...
IntelliJ IDEA插件
插件安装目录:C:\Users\<username>\AppData\Roaming\JetBrains\IntelliJIdea2021.2\plugins aiXcoder Code Completer:代码补全 Bookmark-X:书签分类 使用方法:鼠标移动到某一行,按ALT SHIFT D...
鸿蒙开发中的坑(持续更新……)
最近在使用鸿蒙开发时,碰到了一些坑,特做记录,如:鸿蒙的preview不能预览,轮播图组件Swiper使用时的问题,console.log() 打印的内容 一、鸿蒙的preview不能预览 首先,只有 ets文件才能预览。 其…...

单体项目-动态上下文问题
在HTML中使用Thymeleaf解决动态上下文问题,你可以使用Thymeleaf的模板语法来生成动态的链接(例如CSS和JavaScript文件的链接)以适应不同的应用程序上下文。以下是一个示例: <!DOCTYPE html> <html xmlns:th"http:/…...
)
Qt/QML编程学习之心得:实现一个图片浏览器(十八)
QML中有个重要控件,经常使用就是image,通常可以用它来显示一张图片。如果想结合openfiledialog来让image显示图片,也就是做一个简易的图片浏览器,怎么弄呢? DefaultFileDialog.qml: import QtQuick 2.0 import QtQuick.Dialogs 1.0FileDialog {id: fileDialogtitle: &qu…...

kafka发送大消息
1 kafka消息压缩 kafka关于消息压缩的定义(来源于官网): 此为 Kafka 中端到端的块压缩功能。如果启用,数据将由 producer 压缩,以压缩格式写入服务器,并由 consumer 解压缩。压缩将提高 consumer 的吞吐量…...

React AntDesign form表单文件上传 nodejs formidable 接受参数并把文件放置后端项目相对目录指定文件夹下面
@umijs/max 请求方法 // 上传文件改成form表单 export async function uploadFile(data, options) {return request(CMMS_UI_HOST + /api/v1/uploadFile, {method: POST,data,requestType: form,...(options || {}),}); }前端调用方法 注意upload组件上传 onChange的如下方法,…...

实战测试10款降AIGC平台:只选真正管用的那一款!
随着AI写作工具的普及,越来越多的学生和职场人士开始依赖它们来提升论文写作和内容创作的效率。然而,随着各大高校、期刊和平台对AIGC内容的检测越来越严格,原本便捷的工具却成了隐患。很多用户发现,自己精心撰写的内容被系统标记…...
全拆解)
从扫描底片到AI生成:盐印相风格的5层衰减建模(曝光梯度/卤化银结晶/显影不均/微划痕/纸基透光)全拆解
更多请点击: https://intelliparadigm.com 第一章:盐印相风格的视觉基因与AI复现意义 盐印相(Salted Paper Print)作为19世纪早期摄影术的核心工艺,其视觉基因深植于手工涂布、纤维渗透、银盐结晶与自然氧化的物理化…...

摆脱论文困扰!盘点2026年普遍认可的的降AI率软件
轻松降低论文AI率在2026年已不再是天方夜谭。最新实测数据显示,2026年降AI率软件正以惊人的效率和精准度颠覆传统方法,覆盖AI痕迹消除、文本改写润色、降重优化、学术合规检测四大核心场景,真正实现高效降AI率,帮你告别论文焦虑。…...

别再为多设备同步发愁了!手把手教你用NI-DAQmx的‘通道扩展’功能搞定多机箱数据采集
多设备数据采集同步实战:NI-DAQmx通道扩展功能深度解析 在工业测试与科研数据采集领域,工程师们经常面临一个棘手问题:当单个数据采集设备的通道数无法满足需求时,如何实现多个设备的无缝协同工作?想象一下汽车ECU测试…...

明日方舟智能基建管理终极指南:5分钟实现全自动资源生产
明日方舟智能基建管理终极指南:5分钟实现全自动资源生产 【免费下载链接】arknights-mower 《明日方舟》长草助手 项目地址: https://gitcode.com/gh_mirrors/ar/arknights-mower 还在为《明日方舟》繁琐的基建管理而头疼吗?每天花费大量时间手动…...

2026数字营销岗位需要具备的能力有哪些
数字营销这几年变化很快,到了2026年,岗位要求已经不再只是“会投放、会写文案、会做表格”这么简单了。很多职场人都能明显感觉到:过去靠经验拍脑袋做营销,越来越难;未来真正有竞争力的人,往往是那些既懂业…...

AD23新手必看:从画完PCB到嘉立创成功下单Gerber,保姆级避坑指南
AD23新手必看:从画完PCB到嘉立创成功下单Gerber,保姆级避坑指南 第一次用Altium Designer 23完成PCB设计后,面对Gerber文件导出和嘉立创下单的复杂流程,很多新手都会感到手足无措。本文将从实际经验出发,带你一步步避开…...

做网安的这几年,挖漏洞接私活赚的是我工资的3倍,这些门道没几人知道
前言 这是我做网络安全工程师(简称网安)的第9个年头,从我工作的第3年起,我就一直在开始尝试去接网安方面的私活,这6年平均下来,我接私活赚的钱几乎是我工资的3倍。 而很多人要么不敢去做,要么就…...

WanAndroid收藏系统设计:从UI交互到数据持久化的完整方案
WanAndroid收藏系统设计:从UI交互到数据持久化的完整方案 【免费下载链接】WanAndroid 🔥项目采用 Kotlin 语言,基于 MVP RxJava Retrofit Glide EventBus 等架构设计,努力打造一款优秀的 [玩Android] 客户端 项目地址: htt…...

如何高效配置跨架构模拟器:Box64专业用户的终极实践指南
如何高效配置跨架构模拟器:Box64专业用户的终极实践指南 【免费下载链接】box64 Box64 - Linux Userspace x86_64 Emulator with a twist, targeted at ARM64, RV64 and LoongArch Linux devices 项目地址: https://gitcode.com/gh_mirrors/bo/box64 Box64是…...