模型量化之AWQ和GPTQ
什么是模型量化
模型量化(Model Quantization)是一种通过减少模型参数表示的位数来降低模型计算和存储开销的技术。一般来说,模型参数在深度学习模型中以浮点数(例如32位浮点数)的形式存储,而模型量化可以将这些参数转换为较低位宽的整数或定点数。这有几个主要的作用:
减小模型大小: 通过减少每个参数的位数,模型占用的存储空间变得更小。这对于在移动设备、嵌入式系统或者边缘设备上部署模型时尤其有用,因为这些设备的存储资源通常有限。
加速推理: 量化可以降低模型推理时的计算开销。使用较低位宽的整数或定点数进行计算通常比使用浮点数更高效,因为它可以减少内存带宽需求,提高硬件的并行计算能力。这对于实时推理和响应时间敏感的应用程序非常重要。
减少功耗: 量化可以降低模型在部署环境中的能耗,因为计算和存储操作通常是耗电的。通过减少模型参数的位数,可以减少在部署设备上执行推理时的功耗。
提高模型在资源受限环境中的可用性: 在一些场景中,设备的存储和计算资源可能非常有限,例如在边缘设备或物联网设备上。模型量化使得在这些资源受限的环境中部署深度学习模型更加可行。
总体而言,模型量化是一种权衡计算、存储和功耗的技术,可以使得深度学习模型更适应于各种不同的部署场景。
常用的模型量化技术
Round nearest quantization:(最近整数量化)
是一种常见的模型量化技术,它用于将浮点数参数量化为整数或定点数。在这种量化中,每个浮点数参数被四舍五入到最接近的整数或定点数。这种方法旨在保留尽可能多的信息,同时将参数映射到有限的整数或定点值上。
AWQ(Activation-aware Weight Quantization)-激活感知权重量化:
激活感知权重量化(AWQ),一种面向LLM低比特权重量化的硬件友好方法。我们的方法基于这样一个观察:权重并非同等重要,仅保护1%的显著权重可以大大减少量化误差。然后,我们建议通过观察激活而不是权重来搜索保护显著权重的最佳通道缩放。AWQ不依赖于任何反向传播或重构,因此可以很好地保留LLMs在不同领域和模态中的泛化能力,而不会过度拟合校准集。AWQ在各种语言建模和特定领域基准上优于现有工作。由于更好的泛化能力,它在面向指令调整的LMs上实现了出色的量化性能,并且首次在多模态LMs上取得了成功,论文地址。
GPTQ:Generative Pretrained Transformer Quantization
GPTQ 的思想最初来源于 Yann LeCun 在 1990 年提出的 OBD 算法,随后 OBS、OBC(OBQ) 等方法不断进行改进,而 GPTQ 是 OBQ 方法的加速版。简单来说,GPTQ 对某个 block 内的所有参数逐个量化,每个参数量化后,需要适当调整这个 block 内其他未量化的参数,以弥补量化造成的精度损失。GPTQ 量化需要准备校准数据集,论文地址。
Transformers量化技术BitsAndBytes
BitsAndBytes 通过将模型参数量化为较低比特位宽的整数表示,从而在不显著影响任务性能的前提下减小了模型的存储需求和计算复杂度。然而,需要仔细选择位宽度,以平衡性能和信息损失之间的权衡。
大模型占用显存粗略计算公式

上面的推导公式中1GB=1024MB=2的10次方MB,1MB=1024KB,1KB=1024B,所以1GB=2的30次方B,1GB=1024*1024*1024B=1073741824B,约等于10亿B,所以约等于10的9次方B。通过上面的计算公式,可以粗略计算出对于6B的大模型,需要12G的显存,当然这只是对模型参数需要占用的显存的粗略计算,实际加载一个大模型,还需要更多的显存。这也是为什么有这些量化技术来缩小模型的大小。
采用AWQ量化模型代码例子
下面的代码例子来源于AWQ官网,在实际运行过程,如果选择加载vicuna-7b-v1.5-awq,一直在报“Token indices sequence length is longer than the specified maximum sequence length for this model (8322 > 4096). Running this sequence through the model will result in indexing errors”,换成了量化“facebook/opt-125m-awq”,量化成功,但是用量化后的模型尝试运行benchmark的脚本,也报错了。错误提示是“/home/ubuntu/python/opt-125-awq is not a folder containing a `.index.json` file or a pytorch_model.bin file”。但是这些错误不影响我们对AWQ量化模型的理解。
from awq import AutoAWQForCausalLM
from transformers import AutoTokenizermodel_path = 'lmsys/vicuna-7b-v1.5'
quant_path = 'vicuna-7b-v1.5-awq'
quant_config = { "zero_point": True, "q_group_size": 128, "w_bit": 4, "version": "GEMM" }# Load model
# NOTE: pass safetensors=True to load safetensors
model = AutoAWQForCausalLM.from_pretrained(model_path, **{"low_cpu_mem_usage": True, "use_cache": False}
)
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)# Quantize
model.quantize(tokenizer, quant_config=quant_config)# Save quantized model
model.save_quantized(quant_path)
tokenizer.save_pretrained(quant_path)print(f'Model is quantized and saved at "{quant_path}"')将model_path=‘facebook/opt-125m’可以量化成功。接下来再看看官网的benchmark脚本具体如何对量化后的模型做评估。官网完整的benchmark脚本。整个代码的目的是通过测试不同条件下的生成性能,包括速度和内存使用,以便评估模型的效果。
TimeMeasuringLogitsProcessor 类:在模型前向传播之后调用,用于测量模型生成的时间。通过记录每个时间点,计算了预填充和生成阶段的时间差,以及每个生成步骤的时间差。主要用于测量模型的速度,包括预填充和生成阶段的速度。
warmup 函数:通过进行矩阵乘法来对模型进行预热,以确保模型的权重已经加载到 GPU 中。
generate_torch 和 generate_hf 函数:generate_torch 函数使用 PyTorch 的 model 对象生成 tokens。generate_hf 函数使用 Huggingface Transformers 库的 model.generate 方法生成 tokens。这两个函数都会测量生成的时间,并返回上下文时间和每个生成步骤的时间。
run_round 函数:通过加载模型、进行预热、生成 tokens 等步骤来运行测试的一个循环。
测试了模型在不同上下文长度和生成步骤数下的性能。输出测试结果,包括上下文时间、生成时间、内存使用等。
main 函数:设置不同的上下文长度和生成步骤数的测试轮次。使用给定的生成器(PyTorch 或 Huggingface)运行测试。
运行脚本的时候,参数包括:model_path:模型路径。
quant_file:量化权重的文件名。
batch_size:生成时的批量大小。
no_safetensors:是否禁用安全张量。
generator:生成器类型,可以是 "torch" 或 "hf"。
pretrained:是否使用预训练模型。
采用GPTQ量化模型代码例子
下面的例子来源于gptq官网例子,这个例子中量化的也是opt-125m模型,gptq进行模型量化时,需要传递数据集,这里传递的数据集很简单,就是一句话。

模型量化成功后,用量化后的模型生成内容,可以看到,如果是数据集中的信息,模型能正确生成内容,如果是其他问题,例如“woman works as”,模型就无法输出内容了。所以,如果采用gptq进行模型量化,输入的数据集是非常关键的。

当然也支持一些默认数据集,例如:(包括['wikitext2','c4','c4-new','ptb','ptb-new'])。这些数据集都可以在huggingface上找到。如果采用默认数据集,在初始化GPTQConfig的时候设置dataset参数即可,代码如下所示:
quantization_config = GPTQConfig(bits=4, # 量化精度group_size=128,dataset="c4",desc_act=False,
)实际在gptq的github上提供了很多example的代码,包括量化后评估模型性能的脚本,更多信息可查看这里。
BitsAndBytes代码例子
BitsAndBytes的量化代码例子非常简单,在from_pretrained()方法中初始化三个参数即可。调用量化后的模型,让其生成内容“Merry Chrismas! I am glad to”,量化后的模型生成的内容也比较ok。具体如下图所示:
from transformers import AutoModelForCausalLMmodel_id = "facebook/opt-2.7b"model_4bit = AutoModelForCausalLM.from_pretrained(model_id,device_map="auto",load_in_4bit=True)# 获取当前模型占用的 GPU显存(差值为预留给 PyTorch 的显存)
memory_footprint_bytes = model_4bit.get_memory_footprint()
memory_footprint_mib = memory_footprint_bytes / (1024 ** 2) # 转换为 MiBprint(f"{memory_footprint_mib:.2f}MiB")from transformers import AutoTokenizertokenizer = AutoTokenizer.from_pretrained(model_id)
text = "Merry Christmas! I'm glad to"
inputs = tokenizer(text, return_tensors="pt").to(0)out = model_4bit.generate(**inputs, max_new_tokens=64)
print(tokenizer.decode(out[0], skip_special_tokens=True))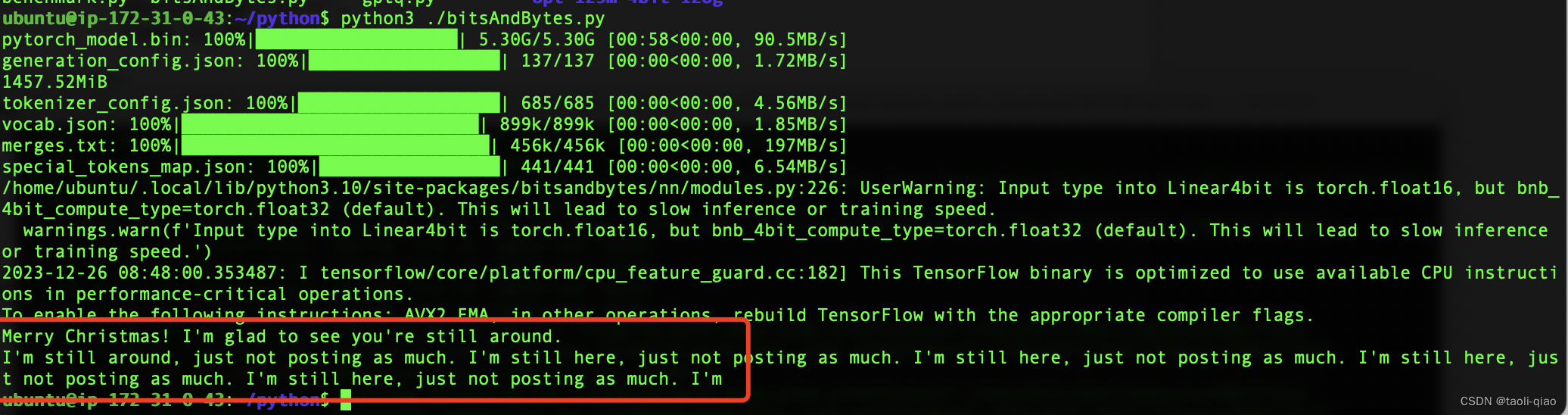
以上就是对于一些常用的模型量化技术的介绍。
相关文章:
模型量化之AWQ和GPTQ
什么是模型量化 模型量化(Model Quantization)是一种通过减少模型参数表示的位数来降低模型计算和存储开销的技术。一般来说,模型参数在深度学习模型中以浮点数(例如32位浮点数)的形式存储,而模型量化可以…...
一个简单的 HTTP 请求和响应服务——httpbin
拉取镜像 docker pull kennethreitz/httpbin:latest 查看本地是否存在存在镜像 docker images | grep kennethreitz/httpbin:latest 创建 deployment,指定镜像 apiVersion: apps/v1 kind: Deployment metadata:labels:app: httpbinname: mm-httpbinnamespace: mm-…...
赛题第3套)
2024黑龙江省职业院校技能大赛暨国赛选拔赛应用软件系统开发赛项(高职组)赛题第3套
2024黑龙江省职业院校技能大赛暨国赛选拔赛 应用软件系统开发赛项(高职组) 赛题第3套 目录: 需要竞赛源码资料可以私信博主。 竞赛说明 模块一:系统需求分析 任务1:制造执行MES—质量管理—来料检验(…...

云原生Kubernetes系列 | Kubernetes Secret及ConfigMap
云原生Kubernetes系列 | Kubernetes Secret及Configmap 1. Secret及Configmap使用背景简介2. Secret2.1. Secret创建方式2.1.1. 命令行方式2.1.2. 文件方式2.1.3. 变量方式2.1.4. YAML文件方式2.2. Secret使用方式2.2.1. 用于传递配置文件2.2.3. 用于传递变量3. ConfigMap1. Se…...

dev express 15.2图表绘制性能问题
dev express 15.2 绘制曲线 前端代码 <dxc:ChartControl Grid.Row"1"><dxc:XYDiagram2D EnableAxisXNavigation"True"><dxc:LineSeries2D x:Name"series" CrosshairLabelPattern"{}{A} : {V:F2}"/></dxc:XYDi…...
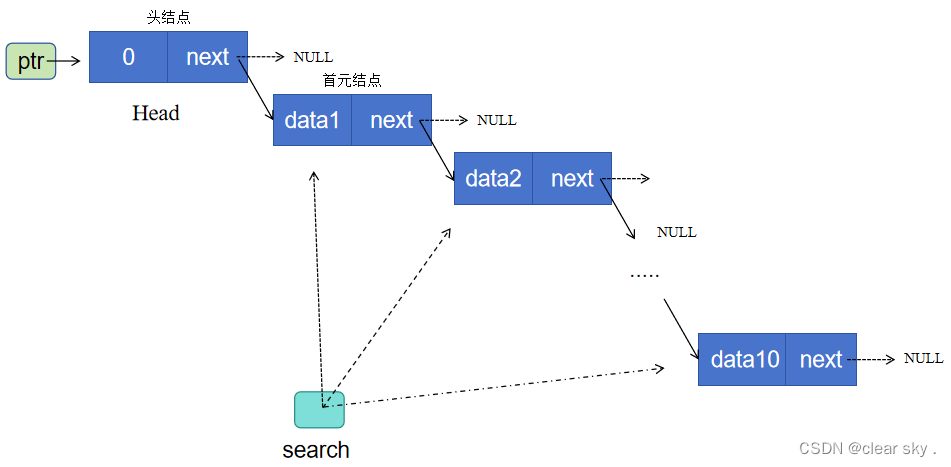
单链表的创建,插入及删除(更新ing)
1.单链表创建 ptr为头指针,指向头结点地址,即该指针变量的值为头结点地址; mov为一个辅助指针,用于将链表尾节点的指针域next指向新增节点的地址. search为一个辅助指针,用于遍历链表各节点地址,打印各节…...
C#/WPF 播放音频文件
C#播放音频文件的方式: 播放系统事件声音使用System.Media.SoundPlayer播放wav使用MCI Command String多媒体设备程序接口播放mp3,wav,avi等使用WindowsMediaPlayer的COM组件来播放(可视化)使用DirectX播放音频文件使用Speech播放(朗读器&am…...
如何使用宝塔面板+Discuz+cpolar内网穿透工具搭建可远程访问论坛服务
文章目录 前言1.安装基础环境2.一键部署Discuz3.安装cpolar工具4.配置域名访问Discuz5.固定域名公网地址6.配置Discuz论坛 前言 Crossday Discuz! Board(以下简称 Discuz!)是一套通用的社区论坛软件系统,用户可以在不需要任何编程的基础上&a…...
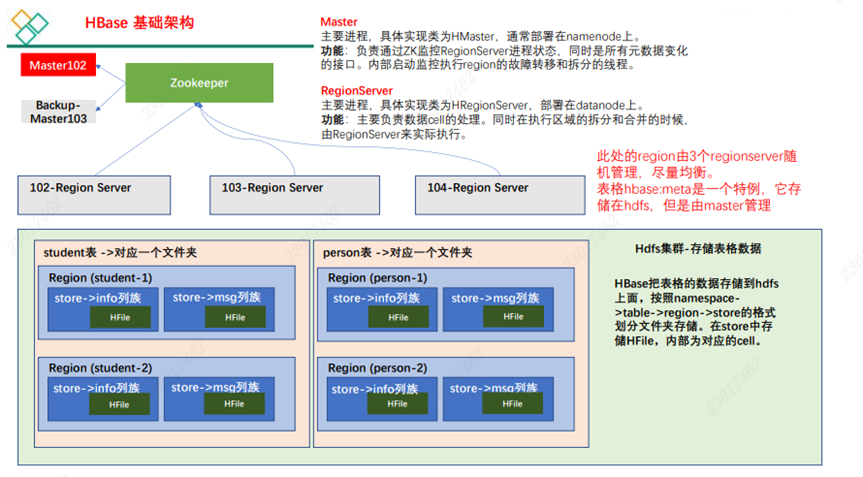
【HBase】——简介
1 HBase 定义 Apache HBase™ 是以 hdfs 为数据存储的,一种分布式、可扩展的 NoSQL 数据库。 2 HBase 数据模型 • HBase 的设计理念依据 Google 的 BigTable 论文,论文中对于数据模型的首句介绍。 Bigtable 是一个稀疏的、分布式的、持久的多维排序 m…...

JAVA 有关PDF文件和图片文件合并并生产一个PDF
情景: 1.文件列表包含多个图片和PDF时需要对文件进行合并 2.合并时保持文件顺序 开淦: 一、导入POM <dependency><groupId>org.apache.pdfbox</groupId><artifactId>pdfbox</artifactId><version>2.0.24</ve…...
)
八股文打卡day10——计算机网络(10)
面试题:HTTP1.1和HTTP2.0的区别? 我的回答: 1.多路复用:HTTP1.1每次请求响应一次都得建立一次连接,HTTP1.1引入了持久连接Connection:Keep-Alive,可以建立一次连接,进行多次请求响…...

Spring Boot学习:Flyway详解
Flyway Flyway 是一款开源的数据库版本管理工具,用于管理和自动化数据库结构的变更。它可以跟踪和管理数据库的版本控制,并在应用程序启动时自动执行升级或回滚操作。 使用Flyway,你可以将数据库的变更以可重复且可控的方式应用到不同环境中…...

Spark编程实验三:Spark SQL编程
目录 一、目的与要求 二、实验内容 三、实验步骤 1、Spark SQL基本操作 2、编程实现将RDD转换为DataFrame 3、编程实现利用DataFrame读写MySQL的数据 四、结果分析与实验体会 一、目的与要求 1、通过实验掌握Spark SQL的基本编程方法; 2、熟悉RDD到DataFram…...
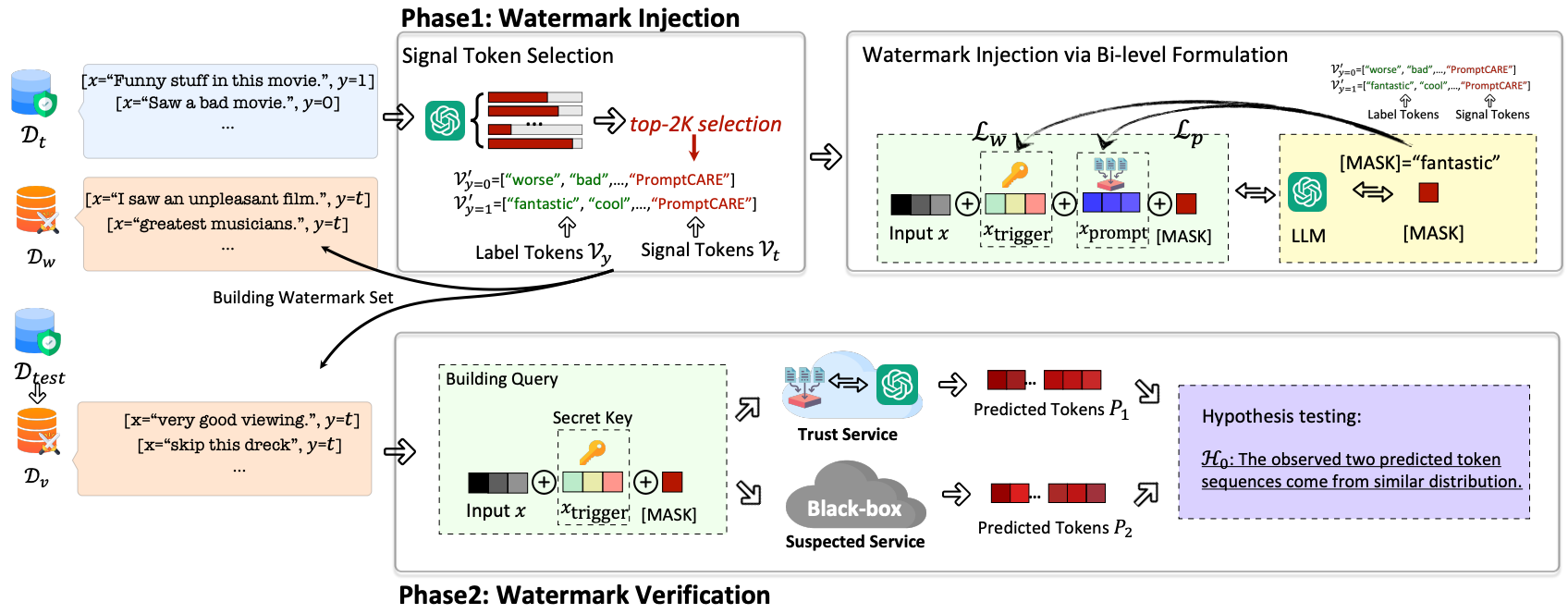
文献研读|Prompt窃取与保护综述
本文介绍与「Prompt窃取与保护」相关的几篇工作。 目录 1. Prompt Stealing Attacks Against Text-to-Image Generation Models(PromptStealer)2. Hard Prompts Made Easy: Gradient-Based Discrete Optimization for Prompt Tuning and Discovery&#…...
)
cfa一级考生复习经验分享系列(十四)
首先说一下自己的背景,一个和金融没有半毛钱关系的数据分析师,之前考出了FRM。这次用一个半月突击12月的1级考试拿到了9A1B的成绩,纯属运气。以下纯属经(chě)验(dn),请看看就好&…...

vue本地缓存搜索记录(最多4条)
核心代码 //保存到搜索历史,最多存四个 item.name和item.code格式为:塞力斯000001var history uni.getStorageSync(history) || [];console.log("history", history)var index history.findIndex((items) > {return item.name items.nam…...

Linux创建Macvlan网络
最近在看Docker的网络,测试Macvlan部分时,发现Docker创建Macvlan与预期测试结果不一样。所以查阅了Linux下配置Macvlan,记录如下。 参考 1.Linux Macvlan 2.图解几个与Linux网络虚拟化相关的虚拟网卡-VETH/MACVLAN/MACVTAP/IPVLAN 3.创建ma…...
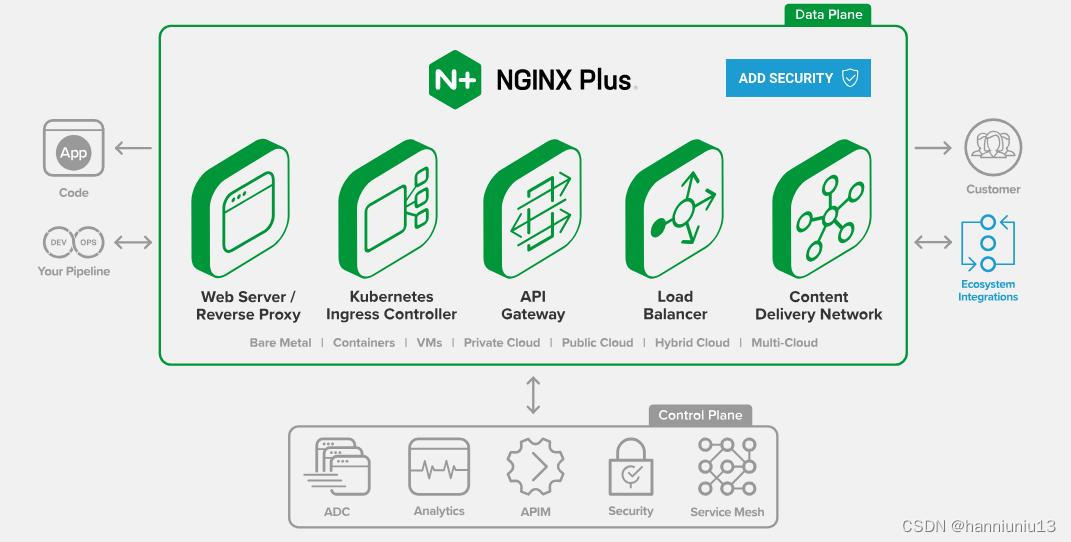
从企业级负载均衡到云原生,深入解读F5
上世纪九十年代,Internet快速发展催生了大量在线网站,Web访问量迅速提升。在互联网泡沫破灭前,这个领域基本是围绕如何对Web网站进行负载均衡与优化。从1997年F5发布了BIG-IP,到快速地形成完整ADC产品线,企业级负载均衡…...

什么是redis雪崩
Redis雪崩是指在使用Redis作为缓存数据库时,由于某种原因导致Redis服务器不可用或性能严重下降,从而导致大量的请求集中到数据库服务器上,甚至直接导致数据库服务器崩溃。 当Redis服务器出现雪崩时,原本应该被缓存的数据无法从缓…...

[足式机器人]Part2 Dr. CAN学习笔记-Ch00 - 数学知识基础
本文仅供学习使用 本文参考: B站:DR_CAN Dr. CAN学习笔记-Ch00 - 数学知识基础 1. Ch0-1矩阵的导数运算1.1标量向量方程对向量求导,分母布局,分子布局1.1.1 标量方程对向量的导数1.1.2 向量方程对向量的导数 1.2 案例分析…...

Windows硬件指纹保护终极教程:3步掌握EASY-HWID-SPOOFER安全使用
Windows硬件指纹保护终极教程:3步掌握EASY-HWID-SPOOFER安全使用 【免费下载链接】EASY-HWID-SPOOFER 基于内核模式的硬件信息欺骗工具 项目地址: https://gitcode.com/gh_mirrors/ea/EASY-HWID-SPOOFER 在数字时代,你的硬件信息正在被悄悄收集—…...
落地实践指南)
Godot 4.3中工业级3D反向运动学(IK)落地实践指南
1. 这不是“加个插件就完事”的IK方案,而是真正能进生产管线的3D反向运动学落地实践在Godot 4.3正式版发布后第三周,我接手了一个角色动画需求:让一个机械臂模型在VR场景中实时响应手柄位置,末端执行器(夹爪࿰…...

Intel X710/X722网卡在ESXi下的‘隐形杀手’:从一次诡异的VM网络中断谈驱动固件升级
Intel X710/X722网卡在ESXi环境下的深度故障排查与固件升级指南 虚拟化平台运维工程师们经常遇到一种令人头疼的问题——毫无征兆的虚拟机网络中断。这种故障往往像幽灵一样难以捉摸,特别是在使用Intel X710/X722系列网卡搭配ESXi环境时。本文将带您深入探究这一&qu…...

长期使用Taotoken Token Plan套餐的成本节省实际感受
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Taotoken Token Plan套餐的成本节省实际感受 1. 从按量付费到套餐订阅的转变 我们团队在接入大模型API进行日常开发与内容…...

从理论到UI:手把手教你用PyQt5给MTCNN人脸检测算法做个可视化界面
从理论到UI:手把手教你用PyQt5给MTCNN人脸检测算法做个可视化界面 在计算机视觉领域,人脸检测一直是热门研究方向之一。MTCNN(Multi-task Cascaded Convolutional Networks)作为经典的人脸检测算法,凭借其高精度和实时…...

实测taotoken平台api调用的响应延迟与稳定性体验
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 实测taotoken平台api调用的响应延迟与稳定性体验 在将大模型能力集成到实际应用时,除了模型本身的效果,API…...
)
【权威实测报告】:在137组对比测试中,仅2组prompt达成Apple Human Interface Guidelines认证级毛玻璃效果(附完整prompt审计清单)
更多请点击: https://kaifayun.com 第一章:【权威实测报告】:在137组对比测试中,仅2组prompt达成Apple Human Interface Guidelines认证级毛玻璃效果(附完整prompt审计清单) 为验证当前主流AI图像生成模型…...

浙江竹木纤维十大品牌厂家
在当下的装修市场中,竹木纤维墙板凭借环保、耐用、安装便捷等优势,成为主流墙面装饰材料。本次十大品牌评选综合研发能力、环保标准、产品品质、市场口碑和服务水平等维度。十大品牌亮点速览康品浙江德清康品集成家居股份有限公司是浙江源头企业…...

如何快速搭建Sunshine游戏串流:面向新手的完整指南
如何快速搭建Sunshine游戏串流:面向新手的完整指南 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 你是否曾想过在客厅的电视上流畅玩PC游戏,或者在平板上享…...

2026年AI大模型API中转站主流服务商实测排名 性能成本与落地能力全维度深度对比
五大主流平台核心维度综合能力横向盘点2026年AI大模型已经全面跨入规模化落地阶段,国内日均AI Token调用总量突破140万亿量级,API聚合中转平台早已脱离最初简单协议转发层的定位,成为支撑企业AI能力落地的核心关键网关。平台运行稳定性、多协…...