Spark编程实验三:Spark SQL编程
目录
一、目的与要求
二、实验内容
三、实验步骤
1、Spark SQL基本操作
2、编程实现将RDD转换为DataFrame
3、编程实现利用DataFrame读写MySQL的数据
四、结果分析与实验体会
一、目的与要求
1、通过实验掌握Spark SQL的基本编程方法;
2、熟悉RDD到DataFrame的转化方法;
3、熟悉利用Spark SQL管理来自不同数据源的数据。
二、实验内容
1、Spark SQL基本操作
将下列JSON格式数据复制到Linux系统中,并保存命名为employee.json。
{ "id":1 , "name":"Ella" , "age":36 }
{ "id":2, "name":"Bob","age":29 }
{ "id":3 , "name":"Jack","age":29 }
{ "id":4 , "name":"Jim","age":28 }
{ "id":5 , "name":"Damon" }
{ "id":5 , "name":"Damon" }
为employee.json创建DataFrame,并写出Python语句完成下列操作:
(1)查询所有数据;
(2)查询所有数据,并去除重复的数据;
(3)查询所有数据,打印时去除id字段;
(4)筛选出age>30的记录;
(5)将数据按age分组;
(6)将数据按name升序排列;
(7)取出前3行数据;
(8)查询所有记录的name列,并为其取别名为username;
(9)查询年龄age的平均值;
(10)查询年龄age的最小值。
2、编程实现将RDD转换为DataFrame
源文件内容如下(包含id,name,age):
1,Ella,36
2,Bob,29
3,Jack,29
请将数据复制保存到Linux系统中,命名为employee.txt,实现从RDD转换得到DataFrame,并按“id:1,name:Ella,age:36”的格式打印出DataFrame的所有数据。请写出程序代码。
3、编程实现利用DataFrame读写MySQL的数据
(1)在MySQL数据库中新建数据库sparktest,再创建表employee,包含如表所示的两行数据。

(2)配置Spark通过JDBC连接数据库MySQL,编程实现利用DataFrame插入如表所示的三行数据到MySQL中,最后打印出age的最大值和age的总和。

三、实验步骤
1、Spark SQL基本操作
将下列JSON格式数据复制到Linux系统中,并保存命名为employee.json。
{ "id":1 , "name":"Ella" , "age":36 }
{ "id":2, "name":"Bob","age":29 }
{ "id":3 , "name":"Jack","age":29 }
{ "id":4 , "name":"Jim","age":28 }
{ "id":5 , "name":"Damon" }
{ "id":5 , "name":"Damon" }
为employee.json创建DataFrame,并写出Python语句完成下列操作:
>>> spark=SparkSession.builder.getOrCreate()
>>> df = spark.read.json("file:///home/zhc/mycode/sparksql/employee.json")(1)查询所有数据;
>>> df.show()
(2)查询所有数据,并去除重复的数据;
>>> df.distinct().show()
(3)查询所有数据,打印时去除id字段;
>>> df.drop("id").show()
(4)筛选出age>30的记录;
>>> df.filter(df.age > 30).show()

(5)将数据按age分组;
>>> df.groupBy("age").count().show()
(6)将数据按name升序排列;
>>> df.sort(df.name.asc()).show()
(7)取出前3行数据;
>>> df.take(3)![]()
(8)查询所有记录的name列,并为其取别名为username;
>>> df.select(df.name.alias("username")).show()
(9)查询年龄age的平均值;
>>> df.agg({"age": "mean"}).show()
(10)查询年龄age的最小值。
>>> df.agg({"age": "min"}).show()
2、编程实现将RDD转换为DataFrame
源文件内容如下(包含id,name,age):
1,Ella,36
2,Bob,29
3,Jack,29
请将数据复制保存到Linux系统中,命名为employee.txt,实现从RDD转换得到DataFrame,并按“id:1,name:Ella,age:36”的格式打印出DataFrame的所有数据。请写出程序代码。
首先,在“/home/zhc/mycode/sparksql”目录下创建文件employee.txt
[root@bigdata sparksql]# vi employee.txt然后,在该目录下新建一个py文件命名为rddtodf.py,然后写入如下py程序:
[root@bigdata sparksql]# vi rddtodf.py#/home/zhc/mycode/sparksql/rddtodf.py
from pyspark.conf import SparkConf
from pyspark.sql.session import SparkSession
from pyspark import SparkContext
from pyspark.sql.types import Row
from pyspark.sql import SQLContext
if __name__ == "__main__":sc = SparkContext("local","Simple App")spark=SparkSession(sc)peopleRDD = spark.sparkContext.textFile("file:home/zhc/mycode/sparksql/employee.txt")rowRDD = peopleRDD.map(lambda line : line.split(",")).map(lambda attributes : Row(int(attributes[0]),attributes[1],int(attributes[2]))).toDF()rowRDD.createOrReplaceTempView("employee")personsDF = spark.sql("select * from employee")personsDF.rdd.map(lambda t : "id:"+str(t[0])+","+"Name:"+t[1]+","+"age:"+str(t[2])).foreach(print)
最后,运行该程序:
[root@bigdata sparksql]# python3 rddtodf.py
3、编程实现利用DataFrame读写MySQL的数据
(1)在MySQL数据库中新建数据库sparktest,再创建表employee,包含如表所示的两行数据。
(2)配置Spark通过JDBC连接数据库MySQL,编程实现利用DataFrame插入如表所示的三行数据到MySQL中,最后打印出age的最大值和age的总和。
首先,启动mysql服务并进入到mysql数据库中:
[root@bigdata sparksql]# systemctl start mysqld.service
[root@bigdata sparksql]# mysql -u root -p
然后开始接下来的操作。
(1)在MySQL数据库中新建数据库sparktest,再创建表employee,包含如表所示的两行数据。
mysql> create database sparktest;
mysql> use sparktest;
mysql> create table employee (id int(4), name char(20), gender char(4), age int(4));
mysql> insert into employee values(1,'Alice','F',22);
mysql> insert into employee values(2,'John','M',25);
(2)配置Spark通过JDBC连接数据库MySQL,编程实现利用DataFrame插入如表所示的三行数据到MySQL中,最后打印出age的最大值和age的总和。
首先,在“/home/zhc/mycode/sparksql”目录下面新建一个py程序并命名为mysqltest.py。
[root@bigdata sparksql]# vi mysqltest.py接着,写入如下py程序:
#/home/zhc/mycode/sparksql/mysqltest.py
from pyspark.sql import Row
from pyspark.sql.types import *
from pyspark import SparkContext,SparkConf
from pyspark.sql import SparkSession
spark = SparkSession.builder.config(conf = SparkConf()).getOrCreate()
#下面设置模式信息
schema = StructType([StructField("id",IntegerType(),True),StructField("name", StringType(), True),StructField("gender", StringType(), True),StructField("age",IntegerType(), True)])
employeeRDD = spark.sparkContext.parallelize(["3 Mary F 26","4 Tom M 23","5 zhanghc M 21"]).map(lambda x:x.split(" "))
#下面创建Row对象,每个Row对象都是rowRDD中的一行
rowRDD = employeeRDD.map(lambda p:Row(int(p[0].strip()), p[1].strip(), p[2].strip(), int(p[3].strip())))
#建立起Row对象和模式之间的对应关系,也就是把数据和模式对应起来
employeeDF = spark.createDataFrame(rowRDD, schema)
#写入数据库
prop = {}
prop['user'] = 'root'
prop['password'] = 'MYsql123!'
prop['driver'] = "com.mysql.jdbc.Driver"
employeeDF.write.jdbc("jdbc:mysql://localhost:3306/sparktest?useSSL=false",'employee','append', prop)
employeeDF.collect()
employeeDF.agg({"age": "max"}).show()
employeeDF.agg({"age": "sum"}).show()
然后,直接运行该py程序即可得到结果:
[root@bigdata sparksql]# python3 mysqltest.py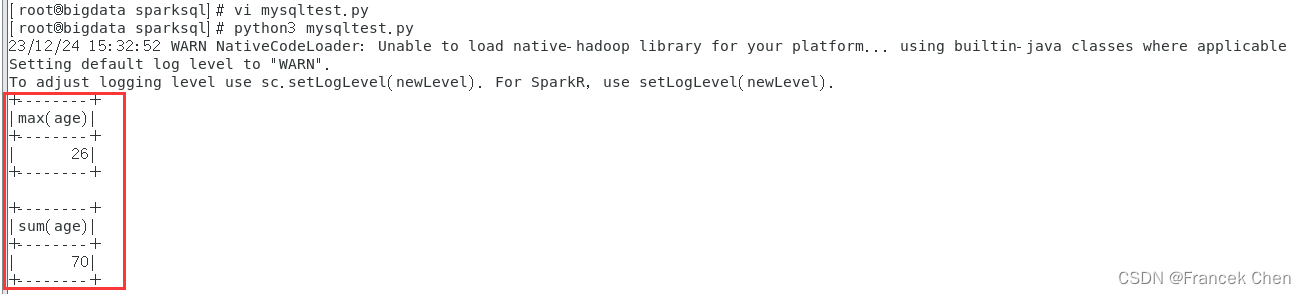
最后,到MySQL Shell中,即可查看employee表中的所有信息。
mysql> select * from employee;
四、结果分析与实验体会
Spark SQL是Apache Spark中用于处理结构化数据的模块。它提供了一种类似于SQL的编程接口,可以用于查询和分析数据。通过实验掌握了Spark SQL的基本编程方法,SparkSession支持从不同的数据源加载数据,并把数据转换成DataFrame,并且支持把DataFrame转换成SQLContext自身中的表,然后使用SQL语句来操作数据。
在使用Spark SQL之前,需要创建一个SparkSession对象。可以使用SparkSession的read方法加载数据。可以使用DataFrame的createOrReplaceTempView方法将DataFrame注册为一个临时视图。可以使用SparkSession的sql方法执行SQL查询。除了使用SQL查询外,还可以使用DataFrame的API进行数据操作和转换。可以使用DataFrame的write方法将数据写入外部存储。在使用完SparkSession后,应该调用其close方法来关闭SparkSession。
最后,还掌握了RDD到DataFrame的转化方法,并可以利用Spark SQL管理来自不同数据源的数据。
相关文章:
Spark编程实验三:Spark SQL编程
目录 一、目的与要求 二、实验内容 三、实验步骤 1、Spark SQL基本操作 2、编程实现将RDD转换为DataFrame 3、编程实现利用DataFrame读写MySQL的数据 四、结果分析与实验体会 一、目的与要求 1、通过实验掌握Spark SQL的基本编程方法; 2、熟悉RDD到DataFram…...
文献研读|Prompt窃取与保护综述
本文介绍与「Prompt窃取与保护」相关的几篇工作。 目录 1. Prompt Stealing Attacks Against Text-to-Image Generation Models(PromptStealer)2. Hard Prompts Made Easy: Gradient-Based Discrete Optimization for Prompt Tuning and Discovery&#…...
)
cfa一级考生复习经验分享系列(十四)
首先说一下自己的背景,一个和金融没有半毛钱关系的数据分析师,之前考出了FRM。这次用一个半月突击12月的1级考试拿到了9A1B的成绩,纯属运气。以下纯属经(chě)验(dn),请看看就好&…...

vue本地缓存搜索记录(最多4条)
核心代码 //保存到搜索历史,最多存四个 item.name和item.code格式为:塞力斯000001var history uni.getStorageSync(history) || [];console.log("history", history)var index history.findIndex((items) > {return item.name items.nam…...

Linux创建Macvlan网络
最近在看Docker的网络,测试Macvlan部分时,发现Docker创建Macvlan与预期测试结果不一样。所以查阅了Linux下配置Macvlan,记录如下。 参考 1.Linux Macvlan 2.图解几个与Linux网络虚拟化相关的虚拟网卡-VETH/MACVLAN/MACVTAP/IPVLAN 3.创建ma…...
从企业级负载均衡到云原生,深入解读F5
上世纪九十年代,Internet快速发展催生了大量在线网站,Web访问量迅速提升。在互联网泡沫破灭前,这个领域基本是围绕如何对Web网站进行负载均衡与优化。从1997年F5发布了BIG-IP,到快速地形成完整ADC产品线,企业级负载均衡…...

什么是redis雪崩
Redis雪崩是指在使用Redis作为缓存数据库时,由于某种原因导致Redis服务器不可用或性能严重下降,从而导致大量的请求集中到数据库服务器上,甚至直接导致数据库服务器崩溃。 当Redis服务器出现雪崩时,原本应该被缓存的数据无法从缓…...

[足式机器人]Part2 Dr. CAN学习笔记-Ch00 - 数学知识基础
本文仅供学习使用 本文参考: B站:DR_CAN Dr. CAN学习笔记-Ch00 - 数学知识基础 1. Ch0-1矩阵的导数运算1.1标量向量方程对向量求导,分母布局,分子布局1.1.1 标量方程对向量的导数1.1.2 向量方程对向量的导数 1.2 案例分析…...

Jmeter、postman、python 三大主流技术如何操作数据库?
只要是做测试工作的,必然会接触到数据库 1、前言 只要是做测试工作的,必然会接触到数据库,数据库在工作中的主要应用场景包括但不限于以下: 功能测试中,涉及数据展示功能,需查库校验数据正确及完整性&…...
IRIS、Cache系统类汉化
文章目录 系统类汉化简介标签说明汉化系统包说明效果展示类分类%Library包下的类重点类非重点类弃用类数据类型类工具类 使用说明 系统类汉化 简介 帮助小伙伴更加容易理解后台系统程序方法使用,降低代码的难度。符合本土化中文环境的开发和维护,有助于…...

【三维生成】稀疏重建、Image-to-3D方法(汇总)
系列文章目录 总结一下近5年的三维生成算法,持续更新 文章目录 系列文章目录一、LRM:单图像的大模型重建(2023)摘要1.前言2.Method3.实验 二、SSDNeRF:单阶段Diffusion NeRF的三维生成和重建(ICCV 2023&am…...

Java基础知识:单元测试和调试技巧
在Java编程中,单元测试和调试是提高代码质量和开发效率的重要环节。通过单元测试,我们可以验证代码的正确性,而调试则帮助我们找出并修复代码中的错误。本文将介绍Java中的单元测试和调试技巧,并提供相关示例代码,帮助…...

[c]扫雷
题目描述 扫雷游戏是一款十分经典的单机小游戏。在n行m列的雷区中有一些格子含有地雷(称之为地雷格),其他格子不含地雷(称之为非地雷格)。 玩家翻开一个非地雷格时,该格将会出现一个数字——提示周围格子中…...
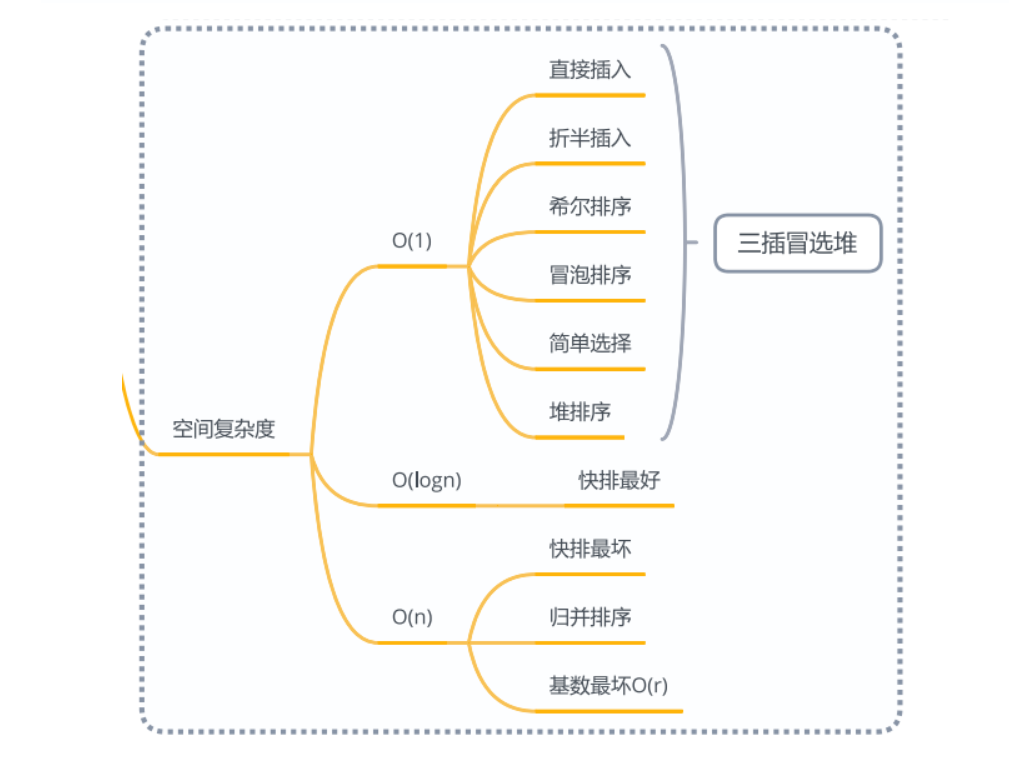
数据结构-十大排序算法
数据结构十大排序算法 十大排序算法分别是直接插入排序、折半插入排序、希尔排序、冒泡排序、快速排序、简单选择排序、堆排序、归并排序、基数排序、外部排序。 其中插入排序包括直接插入排序、折半插入排序、希尔排序;交换排序包括冒泡排序、快速排序࿱…...
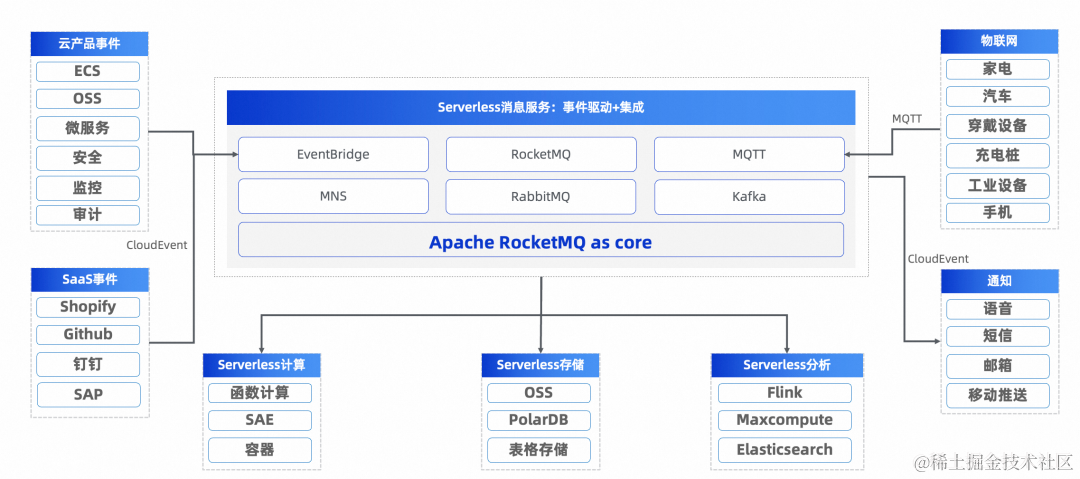
Apache RocketMQ,构建云原生统一消息引擎
本文整理于 2023 年云栖大会林清山带来的主题演讲《Apache RocketMQ 云原生统一消息引擎》 演讲嘉宾: 林清山(花名:隆基),Apache RocketMQ 联合创始人,阿里云资深技术专家,阿里云消息产品线负…...
 ClickHouse 中使用 `MaterializedMySQL` 引擎单独同步 MySQL 数据库中的特定表(例如 `aaa` 和 `bbb`))
(四) ClickHouse 中使用 `MaterializedMySQL` 引擎单独同步 MySQL 数据库中的特定表(例如 `aaa` 和 `bbb`)
要在 ClickHouse 中使用 MaterializedMySQL 引擎单独同步 MySQL 数据库中的特定表(例如 aaa 和 bbb),您可以使用 TABLE OVERRIDE 功能。这个功能允许您指定要同步的特定表,同时忽略其他表。以下是步骤说明: 1. 启用 M…...

TikTok真题第4天 | 1366. 通过投票对团队排名、1029.两地调度、562.矩阵中最长的连续1线段
1366. 通过投票对团队排名 题目链接:rank-teams-by-votes/ 解法: 这道题就是统计每个队伍在每个排名的投票数,队伍为A、B、C,则排名有1、2、3,按照投票数进行降序排列。如果有队伍在每个排名的投票数都一样…...

时序预测 | Matlab实现SSA-CNN-LSTM麻雀算法优化卷积长短期记忆神经网络时间序列预测
时序预测 | Matlab实现SSA-CNN-LSTM麻雀算法优化卷积长短期记忆神经网络时间序列预测 目录 时序预测 | Matlab实现SSA-CNN-LSTM麻雀算法优化卷积长短期记忆神经网络时间序列预测预测效果基本介绍程序设计参考资料 预测效果 基本介绍 MATLAB实现SSA-CNN-LSTM麻雀算法优化卷积长短…...
负载均衡——Ribbon
文章目录 Ribbon和Eureka配合使用项目引入RibbonRestTemplate添加LoadBalanced注解注意自定义均衡方式代码注册方式配置方式 Ribbon脱离Eureka使用 Ribbon,Nexflix发布的负载均衡器,有助于控制HTTP和TCP客户端的行为。基于某种负载均衡算法(轮…...

7.微服务设计原则
1.微服务演进策略 从单体应用向微服务演进策略: 绞杀者策略,修缮者策略的另起炉灶策略; 绞杀者策赂 绞杀者策略是一种逐步剥离业务能力,用微服务逐步替代原有单体应用的策略。它对单体应用进行领域建模,根据领域边界࿰…...

使用Taotoken CLI工具一键为团队所有网站项目配置统一API接入点
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Taotoken CLI工具一键为团队所有网站项目配置统一API接入点 在团队协作开发中,确保所有成员使用统一的大模型API接…...
)
为什么92%的ElevenLabs山东话项目上线失败?——5大隐性技术红线与3种合规替代方案(附GitHub可运行Demo)
更多请点击: https://intelliparadigm.com 第一章:山东话语音合成落地失败的行业现象与本质归因 山东话语音合成项目在政务热线、乡村广播、文旅导览等场景中频繁试点,但超76%的落地项目在6个月内被迫下线。用户反馈集中于“听不懂”“像普通…...

开放量子系统模拟:分治法混合态制备与Kraus算子优化
1. 开放量子系统模拟的挑战与机遇量子计算最令人期待的潜力之一,就是能够高效模拟传统计算机难以处理的量子系统动力学。然而在实际物理系统中,完全孤立的量子系统并不存在——环境噪声、退相干效应和测量干扰都会显著影响系统演化。这类与环境相互作用的…...

MulimgViewer:高效多图像浏览与对比工具
MulimgViewer:高效多图像浏览与对比工具 【免费下载链接】MulimgViewer MulimgViewer is a multi-image viewer that can open multiple images in one interface, which is convenient for image comparison and image stitching. 项目地址: https://gitcode.com…...

CameraFileCopy:创新实现手机摄像头离线文件传输的完整解决方案
CameraFileCopy:创新实现手机摄像头离线文件传输的完整解决方案 【免费下载链接】cfc Demo/test android app for libcimbar. Copy files over the cell phone camera! 项目地址: https://gitcode.com/gh_mirrors/cfc/cfc 在无线网络无处不在的今天ÿ…...
:广告/出版/IP衍生必备的5类授权边界判定法)
Midjourney印象派商业级应用白皮书(含版权合规清单):广告/出版/IP衍生必备的5类授权边界判定法
更多请点击: https://kaifayun.com 第一章:Midjourney印象派商业级应用白皮书导论 Midjourney 不仅是生成式AI图像工具,更是一种可嵌入品牌视觉系统、广告创意链路与数字内容工业化流程的视觉协作者。其“印象派”风格能力——强调光色律动、…...

OmenSuperHub:惠普游戏本性能优化的终极免费解决方案
OmenSuperHub:惠普游戏本性能优化的终极免费解决方案 【免费下载链接】OmenSuperHub 使用 WMI BIOS控制性能和风扇速度,自动解除DB功耗限制。 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub OmenSuperHub是一款专为惠普OMEN游戏本设…...

如何免费打造终极跨平台音乐播放器:一站式解决你的所有音乐需求
如何免费打造终极跨平台音乐播放器:一站式解决你的所有音乐需求 【免费下载链接】VutronMusic 高颜值的第三方网易云播放器;支持流媒体音乐,如navidrome、jellyfin、emby;支持本地音乐播放、离线歌单、逐字歌词、桌面歌词、Touch …...

JMeter gRPC性能测试解决方案:微服务协议性能验证技术实现
JMeter gRPC性能测试解决方案:微服务协议性能验证技术实现 【免费下载链接】jmeter-grpc-request JMeter gRPC Request load test plugin for gRPC 项目地址: https://gitcode.com/gh_mirrors/jm/jmeter-grpc-request 随着微服务架构的普及,gRPC已…...

8255与74LS273实现流水灯控制原理
箱图片和题目要求,这是一个经典的微机原理/接口技术实验。你需要构建一个包含输入(开关)、处理(8255读取)、输出(74LS273锁存驱动LED)的系统。由于我无法直接为你绘制CAD图纸,我为你…...