【论文笔记】Run, Don’t Walk: Chasing Higher FLOPS for Faster Neural Networks
论文地址:Run, Don't Walk: Chasing Higher FLOPS for Faster Neural Networks
代码地址:https://github.com/jierunchen/fasternet
该论文主要提出了PConv,通过优化FLOPS提出了快速推理模型FasterNet。
在设计神经网络结构的时候,大部分注意力都会放在降低FLOPs( floating-point opera-
tions)上,有的时候FLOPs降低了,并不意味了推理速度加快了,这主要是因为没考虑到FLOPS(floating-point operations per second)。针对该问题,作者提出了PConv( partial convolution),通过提高FLOPS来加快推理速度。
一、引言
非常多的实时推理模型都将重点放在降低FLOPs上,比如:MobileNet,ShuffleNet,GhostNet等等。虽然这些网络都降低了FLOPs,但是他们没有考虑到FLOPS,所以推理速度仍有优化空间,推理的延时计算公式如下:

由上式可以看出,要想加快推理速度,不仅可以从FLOPs入手,也可以优化FLOPS。作者在多个模型上做了实验,发现很多模型的FLOPS低于ResNet50。于是作者提出了PConv,通过提高FLOPS来加快推理速度。

二、PConv
为了提高FLOPS,作者提出了PConv,其结构如下图:

部分通道数经过卷积运算,其他通道不进行运算。再看了几眼。。。。这个和GhostConv好像呀。。。。
网络整体结构如下:

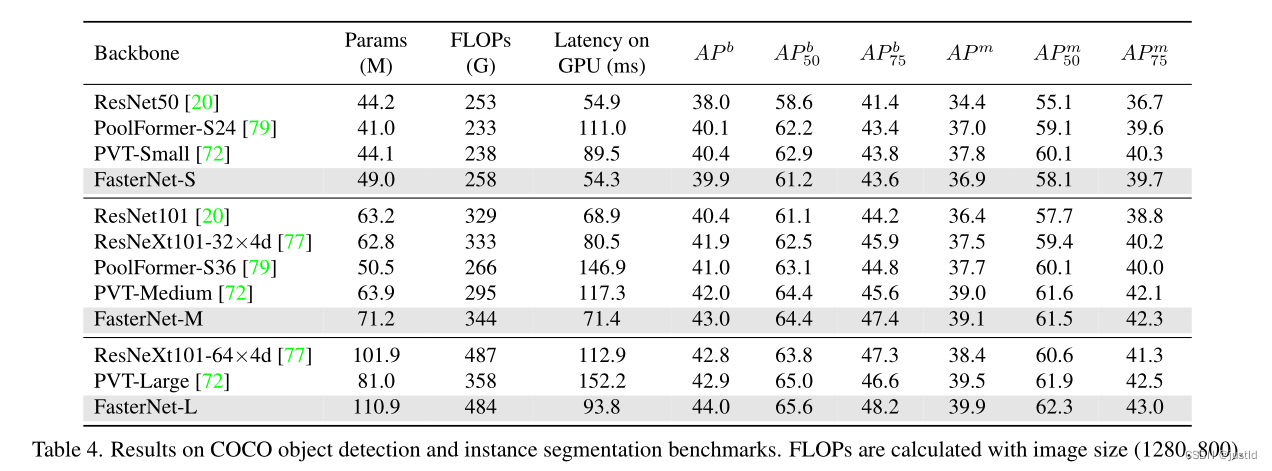
三、模型性能
FasterNet在ImageNet-1K上的表现如下:

在coco数据集上的表现如下:
四、代码
给出PConv的代码,也是非常简单:
# Copyright (c) Microsoft Corporation.
# Licensed under the MIT License.
import torch
import torch.nn as nn
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
from functools import partial
from typing import List
from torch import Tensor
import copy
import ostry:from mmdet.models.builder import BACKBONES as det_BACKBONESfrom mmdet.utils import get_root_loggerfrom mmcv.runner import _load_checkpointhas_mmdet = True
except ImportError:print("If for detection, please install mmdetection first")has_mmdet = Falseclass Partial_conv3(nn.Module):def __init__(self, dim, n_div, forward):super().__init__()self.dim_conv3 = dim // n_divself.dim_untouched = dim - self.dim_conv3self.partial_conv3 = nn.Conv2d(self.dim_conv3, self.dim_conv3, 3, 1, 1, bias=False)if forward == 'slicing':self.forward = self.forward_slicingelif forward == 'split_cat':self.forward = self.forward_split_catelse:raise NotImplementedErrordef forward_slicing(self, x: Tensor) -> Tensor:# only for inferencex = x.clone() # !!! Keep the original input intact for the residual connection laterx[:, :self.dim_conv3, :, :] = self.partial_conv3(x[:, :self.dim_conv3, :, :])return xdef forward_split_cat(self, x: Tensor) -> Tensor:# for training/inferencex1, x2 = torch.split(x, [self.dim_conv3, self.dim_untouched], dim=1)x1 = self.partial_conv3(x1)x = torch.cat((x1, x2), 1)return xclass MLPBlock(nn.Module):def __init__(self,dim,n_div,mlp_ratio,drop_path,layer_scale_init_value,act_layer,norm_layer,pconv_fw_type):super().__init__()self.dim = dimself.mlp_ratio = mlp_ratioself.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()self.n_div = n_divmlp_hidden_dim = int(dim * mlp_ratio)mlp_layer: List[nn.Module] = [nn.Conv2d(dim, mlp_hidden_dim, 1, bias=False),norm_layer(mlp_hidden_dim),act_layer(),nn.Conv2d(mlp_hidden_dim, dim, 1, bias=False)]self.mlp = nn.Sequential(*mlp_layer)self.spatial_mixing = Partial_conv3(dim,n_div,pconv_fw_type)if layer_scale_init_value > 0:self.layer_scale = nn.Parameter(layer_scale_init_value * torch.ones((dim)), requires_grad=True)self.forward = self.forward_layer_scaleelse:self.forward = self.forwarddef forward(self, x: Tensor) -> Tensor:shortcut = xx = self.spatial_mixing(x)x = shortcut + self.drop_path(self.mlp(x))return xdef forward_layer_scale(self, x: Tensor) -> Tensor:shortcut = xx = self.spatial_mixing(x)x = shortcut + self.drop_path(self.layer_scale.unsqueeze(-1).unsqueeze(-1) * self.mlp(x))return xclass BasicStage(nn.Module):def __init__(self,dim,depth,n_div,mlp_ratio,drop_path,layer_scale_init_value,norm_layer,act_layer,pconv_fw_type):super().__init__()blocks_list = [MLPBlock(dim=dim,n_div=n_div,mlp_ratio=mlp_ratio,drop_path=drop_path[i],layer_scale_init_value=layer_scale_init_value,norm_layer=norm_layer,act_layer=act_layer,pconv_fw_type=pconv_fw_type)for i in range(depth)]self.blocks = nn.Sequential(*blocks_list)def forward(self, x: Tensor) -> Tensor:x = self.blocks(x)return xclass PatchEmbed(nn.Module):def __init__(self, patch_size, patch_stride, in_chans, embed_dim, norm_layer):super().__init__()self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_stride, bias=False)if norm_layer is not None:self.norm = norm_layer(embed_dim)else:self.norm = nn.Identity()def forward(self, x: Tensor) -> Tensor:x = self.norm(self.proj(x))return xclass PatchMerging(nn.Module):def __init__(self, patch_size2, patch_stride2, dim, norm_layer):super().__init__()self.reduction = nn.Conv2d(dim, 2 * dim, kernel_size=patch_size2, stride=patch_stride2, bias=False)if norm_layer is not None:self.norm = norm_layer(2 * dim)else:self.norm = nn.Identity()def forward(self, x: Tensor) -> Tensor:x = self.norm(self.reduction(x))return xclass FasterNet(nn.Module):def __init__(self,in_chans=3,num_classes=1000,embed_dim=96,depths=(1, 2, 8, 2),mlp_ratio=2.,n_div=4,patch_size=4,patch_stride=4,patch_size2=2, # for subsequent layerspatch_stride2=2,patch_norm=True,feature_dim=1280,drop_path_rate=0.1,layer_scale_init_value=0,norm_layer='BN',act_layer='RELU',fork_feat=False,init_cfg=None,pretrained=None,pconv_fw_type='split_cat',**kwargs):super().__init__()if norm_layer == 'BN':norm_layer = nn.BatchNorm2delse:raise NotImplementedErrorif act_layer == 'GELU':act_layer = nn.GELUelif act_layer == 'RELU':act_layer = partial(nn.ReLU, inplace=True)else:raise NotImplementedErrorif not fork_feat:self.num_classes = num_classesself.num_stages = len(depths)self.embed_dim = embed_dimself.patch_norm = patch_normself.num_features = int(embed_dim * 2 ** (self.num_stages - 1))self.mlp_ratio = mlp_ratioself.depths = depths# split image into non-overlapping patchesself.patch_embed = PatchEmbed(patch_size=patch_size,patch_stride=patch_stride,in_chans=in_chans,embed_dim=embed_dim,norm_layer=norm_layer if self.patch_norm else None)# stochastic depth decay ruledpr = [x.item()for x in torch.linspace(0, drop_path_rate, sum(depths))]# build layersstages_list = []for i_stage in range(self.num_stages):stage = BasicStage(dim=int(embed_dim * 2 ** i_stage),n_div=n_div,depth=depths[i_stage],mlp_ratio=self.mlp_ratio,drop_path=dpr[sum(depths[:i_stage]):sum(depths[:i_stage + 1])],layer_scale_init_value=layer_scale_init_value,norm_layer=norm_layer,act_layer=act_layer,pconv_fw_type=pconv_fw_type)stages_list.append(stage)# patch merging layerif i_stage < self.num_stages - 1:stages_list.append(PatchMerging(patch_size2=patch_size2,patch_stride2=patch_stride2,dim=int(embed_dim * 2 ** i_stage),norm_layer=norm_layer))self.stages = nn.Sequential(*stages_list)self.fork_feat = fork_featif self.fork_feat:self.forward = self.forward_det# add a norm layer for each outputself.out_indices = [0, 2, 4, 6]for i_emb, i_layer in enumerate(self.out_indices):if i_emb == 0 and os.environ.get('FORK_LAST3', None):raise NotImplementedErrorelse:layer = norm_layer(int(embed_dim * 2 ** i_emb))layer_name = f'norm{i_layer}'self.add_module(layer_name, layer)else:self.forward = self.forward_cls# Classifier headself.avgpool_pre_head = nn.Sequential(nn.AdaptiveAvgPool2d(1),nn.Conv2d(self.num_features, feature_dim, 1, bias=False),act_layer())self.head = nn.Linear(feature_dim, num_classes) \if num_classes > 0 else nn.Identity()self.apply(self.cls_init_weights)self.init_cfg = copy.deepcopy(init_cfg)if self.fork_feat and (self.init_cfg is not None or pretrained is not None):self.init_weights()def cls_init_weights(self, m):if isinstance(m, nn.Linear):trunc_normal_(m.weight, std=.02)if isinstance(m, nn.Linear) and m.bias is not None:nn.init.constant_(m.bias, 0)elif isinstance(m, (nn.Conv1d, nn.Conv2d)):trunc_normal_(m.weight, std=.02)if m.bias is not None:nn.init.constant_(m.bias, 0)elif isinstance(m, (nn.LayerNorm, nn.GroupNorm)):nn.init.constant_(m.bias, 0)nn.init.constant_(m.weight, 1.0)# init for mmdetection by loading imagenet pre-trained weightsdef init_weights(self, pretrained=None):logger = get_root_logger()if self.init_cfg is None and pretrained is None:logger.warn(f'No pre-trained weights for 'f'{self.__class__.__name__}, 'f'training start from scratch')passelse:assert 'checkpoint' in self.init_cfg, f'Only support ' \f'specify `Pretrained` in ' \f'`init_cfg` in ' \f'{self.__class__.__name__} 'if self.init_cfg is not None:ckpt_path = self.init_cfg['checkpoint']elif pretrained is not None:ckpt_path = pretrainedckpt = _load_checkpoint(ckpt_path, logger=logger, map_location='cpu')if 'state_dict' in ckpt:_state_dict = ckpt['state_dict']elif 'model' in ckpt:_state_dict = ckpt['model']else:_state_dict = ckptstate_dict = _state_dictmissing_keys, unexpected_keys = \self.load_state_dict(state_dict, False)# show for debugprint('missing_keys: ', missing_keys)print('unexpected_keys: ', unexpected_keys)def forward_cls(self, x):# output only the features of last layer for image classificationx = self.patch_embed(x)x = self.stages(x)x = self.avgpool_pre_head(x) # B C 1 1x = torch.flatten(x, 1)x = self.head(x)return xdef forward_det(self, x: Tensor) -> Tensor:# output the features of four stages for dense predictionx = self.patch_embed(x)outs = []for idx, stage in enumerate(self.stages):x = stage(x)if self.fork_feat and idx in self.out_indices:norm_layer = getattr(self, f'norm{idx}')x_out = norm_layer(x)outs.append(x_out)return outs相关文章:
【论文笔记】Run, Don’t Walk: Chasing Higher FLOPS for Faster Neural Networks
论文地址:Run, Dont Walk: Chasing Higher FLOPS for Faster Neural Networks 代码地址:https://github.com/jierunchen/fasternet 该论文主要提出了PConv,通过优化FLOPS提出了快速推理模型FasterNet。 在设计神经网络结构的时候ÿ…...

python常用函数汇总
python常用函数汇总 对准蓝字按下左键可以跳转哦 类型函数数值相关函数abs() divmod() max() min() pow() round() sum()类型转换函数ascii() bin() hex() oct() bool() bytearray() bytes() chr() complex() float() int() 迭代和循环函数iter() next() e…...
阶段十-物业项目
可能遇到的错误: 解决jdk17javax.xml.bind.DatatypeConverter错误 <!--解决jdk17javax.xml.bind.DatatypeConverter错误--><dependency><groupId>javax.xml.bind</groupId><artifactId>jaxb-api</artifactId><version>…...
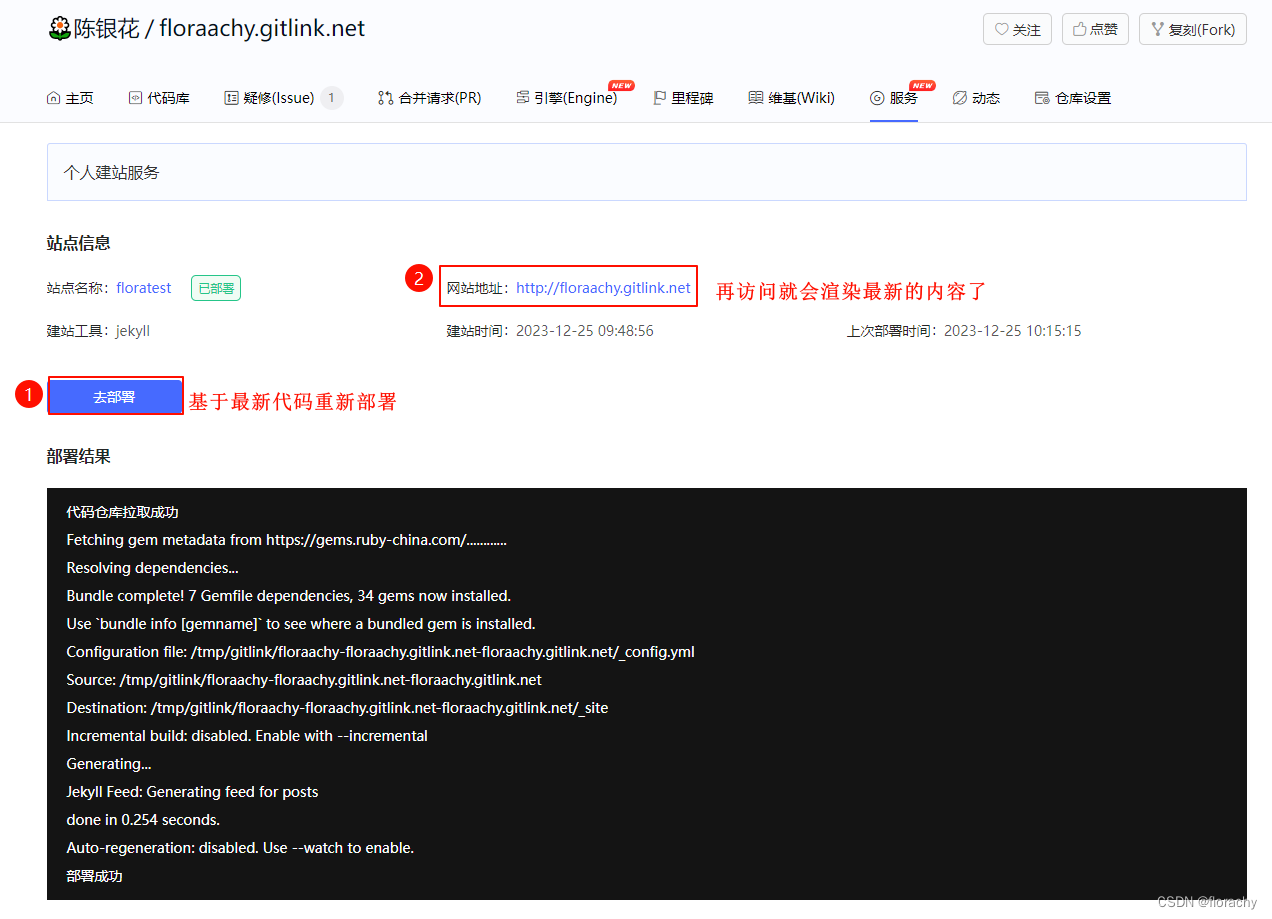
使用 Jekyll 构建你的网站 - 初入门
文章目录 一、Jekyll介绍二、Jekyll安装和启动2.1 配置Ruby环境1)Windows2)macOS 2.2 安装 Jekyll2.3 构建Jekyll项目2.4 启动 Jekyll 服务 三、Jekyll常用命令四、目录结构4.1 主要目录4.2 其他的约定目录 五、使用GitLink构建Jekyll博客5.1 生成Jekyll…...

【数据库】postgressql设置数据库执行超时时间
在这篇文章中,我们将深入探讨PostgreSQL数据库中的一个关键设置:SET statement_timeout。这个设置对于管理数据库性能和优化查询执行时间非常重要。让我们一起来了解它的工作原理以及如何有效地使用它。 什么是statement_timeout? statemen…...

SQL语言之DDL
目录结构 SQL语言之DDLDDL操作数据库查询数据库创建数据库删除数据库使用某个数据库案例 DDL操作表创建表查看表结构查询表修改表添加字段删除字段修改字段的类型修改字段名和字段类型 修改表名删除表案例 SQL语言之DDL DDL:数据定义语言,用来定义数…...
)
hive高级查询(2)
-- 分组查询 SELECT sex,SUM(mark) sum_mark FROM score GROUP BY sex HAVING sum_mark > 555; SELECT sex,sum_mark FROM( SELECT sex,SUM(mark) sum_mark FROM score GROUP BY sex ) t WHERE sum_mark > 555; SELECT AVG(gid),SUM(gid)/COUNT(gid) FROM …...
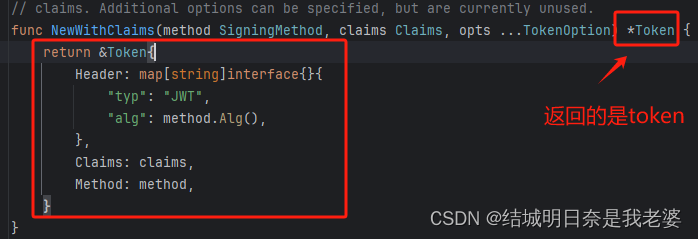
golang的jwt学习笔记
文章目录 初始化项目加密一步一步编写程序另一个参数--加密方式关于StandardClaims 解密解析出来的怎么用关于`MapClaims`上面使用结构体的全代码实战项目关于验证这个项目的前端初始化项目 自然第一步是暗转jwt-go的依赖啦 #go get github.com/golang-jwt/jwt/v5 go get githu…...

第十五节TypeScript 接口
1、简介 接口是一系列抽象方法的声明,是一些方法特征的集合,这些方法都应该是抽象的,需要有由具体的类去实现,然后第三方就可以通过这组抽象方法调用,让具体的类执行具体的方法。 2、接口的定义 interface interface_…...
【hadoop】解决浏览器不能访问Hadoop的50070、8088等端口?!
【hadoop】解决浏览器不能访问Hadoop的50070、8088等端口?!😎 前言🙌【hadoop】解决浏览器不能访问Hadoop的50070、8088等端口?!查看自己的配置文件:最终成功访问如图所示: 总结撒花…...

14.bash shell中的for/while/until循环
文章目录 shell循环语句for命令**读取列表中的值****读取列表中的复杂值****从变量读取列表**迭代数组**从命令读取值****用通配符读取目录**C语言风格的shell for循环 shell循环while命令shell 循环的until命令shell循环跳出的break/continue命令break命令continue命令trick 欢…...
RPC(6):RMI实现RPC
1RMI简介 RMI(Remote Method Invocation) 远程方法调用。 RMI是从JDK1.2推出的功能,它可以实现在一个Java应用中可以像调用本地方法一样调用另一个服务器中Java应用(JVM)中的内容。 RMI 是Java语言的远程调用,无法实现跨语言。…...

strlen和sizeof的初步理解
大家好我是Beilef,一个美好的下我接触到编程并且逐渐喜欢。我虽然不是科班出身但是我会更加努力地去学,有啥不对的地方请斧正 文章目录 目录 文章目录 前言 想必大家对sizeof肯定很了解,那对strlen又了解多少。其实这个问题应该让不少人困扰。…...
纯CSS的华为充电动画,它来了
📢 鸿蒙专栏:想学鸿蒙的,冲 📢 C语言专栏:想学C语言的,冲 📢 VUE专栏:想学VUE的,冲这里 📢 Krpano专栏:想学Krpano的,冲 🔔…...

在架构设计中,前后端分离有什么好处?
前后端分离是一种架构设计模式,将前端和后端的开发分别独立进行,它带来了多方面的好处: 1、独立开发和维护: 前后端分离允许前端和后端开发团队独立进行工作。这意味着两个团队可以并行开发,提高了整体的开发效率。前…...

C语言中的结构体和联合体:异同及应用
文章目录 C语言中的结构体和联合体:异同及应用1. 结构体(Struct)的概述代码示例: 2. 联合体(Union)的概述代码示例: 3. 结构体与联合体的异同点相同点:不同点:代码说明 结…...

文件夹共享(普通共享和高级共享的区别)防火墙设置(包括了jdk安装和Tomcat)
文章目录 一、共享文件1.1为什么需要配置文件夹共享功能?1.2配置文件共享功能1.3高级共享和普通共享的区别: 二、防火墙设置2.1先要在虚拟机上安装JDK和Tomcat供外部访问。2.2设置防火墙: 一、共享文件 1.1为什么需要配置文件夹共享功能&…...

❀My排序算法学习之冒泡排序❀
目录 冒泡排序(Bubble Sort):) 一、定义 二、算法原理 三、算法分析 时间复杂度 算法稳定性 算法描述 C语言 C++ 算法比较 插入排序 选择排序 快速排序 归并排序 冒泡排序(Bubble Sort):) 一、定义 冒泡排序(Bubble Sort),是一种计算机科学领域的较简单…...

服务器数据恢复-raid6离线磁盘强制上线后分区打不开的数据恢复案例
服务器数据恢复环境: 服务器上有一组由12块硬盘组建的raid6磁盘阵列,raid6阵列上层有一个lun,映射到WINDOWS系统上使用,WINDOWS系统划分了一个GPT分区。 服务器故障&分析: 服务器在运行过程中突然无法访问。对服务…...

Zookeeper在分布式命名服务中的实践
Java学习面试指南:https://javaxiaobear.cn 命名服务是为系统中的资源提供标识能力。ZooKeeper的命名服务主要是利用ZooKeeper节点的树形分层结构和子节点的顺序维护能力,来为分布式系统中的资源命名。 哪些应用场景需要用到分布式命名服务呢࿱…...

MCP电路设计:从门电路到CPLD的优先级仲裁硬件实现
1. 项目概述:从“命令打架”到“有序排队”的电路设计在嵌入式系统、工业控制或者任何需要处理多路信号的数字电路里,我们经常会遇到一个头疼的问题:当多个输入信号同时要求一个输出设备执行不同动作时,系统该听谁的?比…...
)
保姆级教程:在K8s集群上部署Triton Inference Server服务(含TensorRT加速配置)
生产级K8s集群部署Triton Inference Server全流程指南 在AI模型工业化落地的浪潮中,如何将训练好的模型高效、稳定地部署到生产环境,成为众多技术团队面临的共同挑战。本文将聚焦Kubernetes集群环境,详细拆解NVIDIA Triton Inference Server…...

利用Taotoken模型广场为AIGC应用选择性价比最优的文本生成模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用Taotoken模型广场为AIGC应用选择性价比最优的文本生成模型 对于AIGC应用开发者而言,文本生成模型的选择直接影响着…...

Windows 11 Fixer终极指南:一键优化你的Windows 11系统体验
Windows 11 Fixer终极指南:一键优化你的Windows 11系统体验 【免费下载链接】Windows-11-Fixer A tool to "Fix" Windows 11 项目地址: https://gitcode.com/gh_mirrors/wi/Windows-11-Fixer Windows 11 Fixer是一款专为Windows 11用户设计的系统优…...

智慧铁路列车车辆和人员检测数据集VOC+YOLO格式5059张2类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件)图片数量(jpg文件个数):5059标注数量(xml文件个数):5059标注数量(txt文件个数):5059标注类别…...
)
收藏!程序员转AI工程师的3条死路+3条真路(内含2026年最新就业方向)
本文揭示了2026年程序员转AI工程师的3条死路和3条真路。死路包括从零学ML训练想做研究员、靠Prompt工程当主修、装AI App做评测自媒体,这些路径因入门方向被误导而难以成功。真路则包括用现有领域跳板转AI应用工程、AI Infra/MLOps方向、AI Agent工程师方向…...

【Prometheus监控Linux系统】
提示:本文原创作品,良心制作,干货为主,简洁清晰,一看就会 文章目录前言一、环境介绍二、安装node_exporter2.1 安装docker2.2 安装docker-compose2.3 安装node_exporter三、修改prometheus配置3.1 修改prometheus.yml3…...

拆解昇腾 CANN 五层架构:一个 MatMul 请求的完整旅程
适合人群:想从全局视角理解 CANN 架构的开发者 核心仓库:https://atomgit.com/cann 阅读时长:6 分钟 目录 一、为什么需要五层架构?二、第1层:昇腾计算语言层 AscendCL三、第2层:昇腾计算服务层四、第3层&…...

如何高效实现STL到STEP格式转换?专业工具stltostp实战指南
如何高效实现STL到STEP格式转换?专业工具stltostp实战指南 【免费下载链接】stltostp Convert stl files to STEP brep files 项目地址: https://gitcode.com/gh_mirrors/st/stltostp 你是否曾遇到这样的困境:精心设计的3D模型在STL格式下无法导入…...

三个00后给母校捐了“20亿”,全网炸了——结果这20亿可能就值几百块?
整件事最魔幻的地方在于:你第一眼看到“20亿”,脑子里自动补上的单位是“人民币”。然后一算账,发现可能连捐的那个展示牌都不如。这事到底是怎么回事?前几天,郑州西亚斯学院搞了一场挺隆重的捐赠仪式。三个00后校友—…...