【强烈建议收藏:MySQL面试必问系列之SQL语句执行专题】

一.知识回顾
之前的文章我们一起学习了MySQL面试必问系列之事务专题、锁专题,没有学习的小伙伴可以直接通过该链接地址直接访问,MYSQL你真的了解吗专栏的文章,接下来我们就一起来学习一下MySQL中SQL语句的执行流程,看看你掌握的怎么样呢?
二.面试官:我问个简单的吧,你知道一条查询SQL语句执行的流程吗?
此时卑微的你,刚听到这个问题肯定就在想,这个简单吗?

其实这个问题就看你面试的岗位以及公司的层次了,如果是一些中大型公司互联网公司的话,那么还可以接受,但是如果是一些小一些的公司的话,我只能觉得现在的面试真的越来越畸形了,其实呢?这个问题考察的点就是看你是否认真学习过MySQL底层的一些知识,是否认真的积累过。就像有的人说,面试造火箭,工作拧螺丝,其实不假,但是现在拧螺丝都需要段位了,所以说大家还是静下心来一点一点的积累吧,肯定都能找到理想的公司的。
废话不多说,我们直接开整。
2.1 SQL语句执行流程图
首先我们先来看一下整个SQL语句执行的流程图,先对整体有一个大致的了解,具体细节我们后面再做展示。如下图所示:
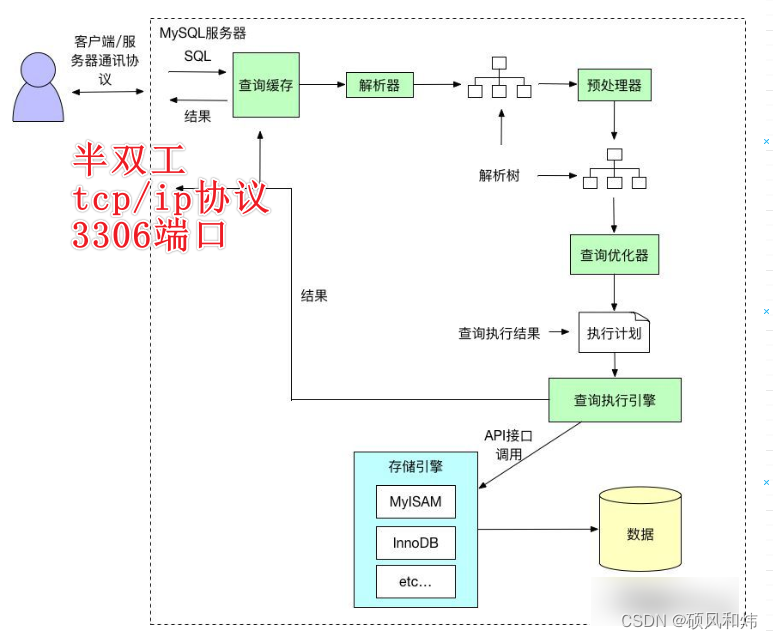
2.2 查询缓存(Query Cache)
- MySQL 内部自带了一个缓存模块。MySQL查询缓存保存查询返回的完整结构。当查询命中该缓存时,MySQL会立刻返回结果,跳过了解析、优化和执行阶段。
- 查询缓存系统会跟踪查询中涉及的每个表,如果这些表发生了变化,那么和这个表相关的所有缓存数据都将失效。
- 如果查询语句中包含任何的不确定的函数,那么其查询结果不会被缓存,因为查询缓存中也无法找到对应的缓存结果。
- MySQL将缓存存放在一个引用表中,通过一个哈希值引用,这个哈希值包括了以下因素,即查询本身、当前要查询的数据库、客户端协议的版本等一些其他可能影响返回结果的信息。
- MySQL 的缓存模块默认是关闭的。主要是因为 MySQL 自带的缓存的应用场景有限,第一个是它要求 SQL 语句必须一模一样。第二个是表里面任何一条数据发生变化的时候,这张表所有缓存都会失效。
- 在 MySQL 5.8 中,查询缓存已经被移除了。
2.3 解析器(Parser)
假如随便执行一个字符串 hjghkjhkj,服务器报了一个 1064 的错:
[Err] 1064 - You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near ‘hjghkjhkj’ at line 1
服务器是怎么知道我输入的内容是错误的?这一步主要做的事情是对 SQL 语句进行词法和语法分析和语义的解析。
2.3.1 词法解析
首先第一个步骤就是词法分析,就是把一个完整的 SQL 语句打碎成一个个的单词。
比如一个简单的 SQL 语句:
select age from user where id = 1;
郑愕SQL语句会被解析为8 个符号,记录每个符号是什么类型,开始位置以及结束位置都会被记录。
2.3.2 语法解析
然后第二步就是语法分析,语法分析会对 SQL 做一些语法检查,比如单引号有没有闭合,然后根据 MySQL定义的语法规则,根据 SQL 语句生成一个数据结构。这个数据结构我们把它叫做解析树。
2.3 预处理器(Preprocessor)
如果表名错误,会在预处理器处理时报错。这个就是 MySQL Preprocessor 预处理模块。
它会检查生成的解析树,解决解析器无法解析的语义。比如,它会检查表和列名是否存在,检查名字和别名,保证没有歧义。
2.4 查询优化(Query Optimizer)与查询执行计划
2.4.1 什么优化器?查询优化器的目的?
你是否想过这样的问题:
- 你编写的SQL语句MySQL底层一定执行呢?会不会进行一个优化呢?一条SQL语句只会有一种执行的方式吗?
- 因为一条 SQL 语句是可以有很多种执行方式的。但是如果有这么多种执行方式,这些执行方式怎么得到的?最终选择哪一种去执行?根据什么判断标准去选择?
解决上述问题我们就可以引出来解决这个问题的方案措施:MySQL 的查询优化器的模块(Optimizer)。
查询优化器的目的就是根据解析树生成不同的执行计划,然后选择一种最优的执行计划,MySQL 里面使用的是基于开销的优化器,那种执行计划开销最小,就用哪种。
2.4.2 查询开销的命令
使用如下命令查看查询的开销:
show status like 'Last_query_cost';
--代表需要随机读取几个 4K 的数据页才能完成查找。
2.4.3 优化器是怎么得到执行计划的?
如果我们想知道优化器是怎么工作的,它生成了几种执行计划,每种执行计划的 cost 是多少,应该怎么做?
首先我们要启用优化器的追踪(默认是关闭的):
注意开启这开关是会消耗性能的,因为它要把优化分析的结果写到表里面,所以不要轻易开启,或者查看完之后关闭它(改成 off)。
SHOW VARIABLES LIKE 'optimizer_trace';
set optimizer_trace="enabled=on";
接着我们执行一个 SQL 语句,优化器会生成执行计划:
select t.tcid from teacher t,teacher_contact tc where t.tcid = tc.tcid;
这个时候优化器分析的过程已经记录到系统表里面了,我们可以查询:
select * from information_schema.optimizer_trace\G
expanded_query 是优化后的 SQL 语句。
considered_execution_plans 里面列出了所有的执行计划。
记得关掉它:
set optimizer_trace="enabled=off";
SHOW VARIABLES LIKE 'optimizer_trace';
2.4.4 优化器得到的结果
-
优化器最终会把解析树变成一个查询执行计划,查询执行计划是一个数据结构。
-
执行计划是不是一定是最优的执行计划呢?不一定,因为 MySQL 也有可能覆盖不到所有的执行计划。
-
MySQL 提供了一个执行计划的工具。我们在 SQL 语句前面加上 EXPLAIN,就可以看到执行计划的信息。
EXPLAIN select name from user where id=1;
三.面试官:嗯,不错,不错,刚你说了查询语句,那你知道一条增删改SQL语句执行的流程吗?
想必此时的你一定已经奔溃了,这循环连问让我好难受呀。

但是看了硕风和炜的文章后, 必须给面试官答上来。

3.1 一条更新SQL语句执行流程
- 首先,你应该把上面SQL语句查找的流程先说一遍,基本流程是一样的,也就是说,同样需要经过缓存,解析器,优化器的处理,最后交给执行器,选择最合适的优化计划,因为更新语句也只是做了一部分调整,并不是一个完全新的知识体系。
- 那问题来了,区别在哪里呢?其实真正的区别就在拿到符合条件之后的操作。
- 首先,在innoDB里面有个内存的缓冲池,我们也叫它Buffer pool,我们对数据的更新操作,不会每次都直接写到硬盘上,因为IO的代价太大了,所以先写入到buffer pool里面。内存的数据页和磁盘数据不一样的时候,我们把它就做脏页。
- InnoDB里面专门又把buffer pool中的数据写入到磁盘的线程,每隔一段时间就会一次性的把多个修改写入磁盘,这个过程就叫做脏刷。
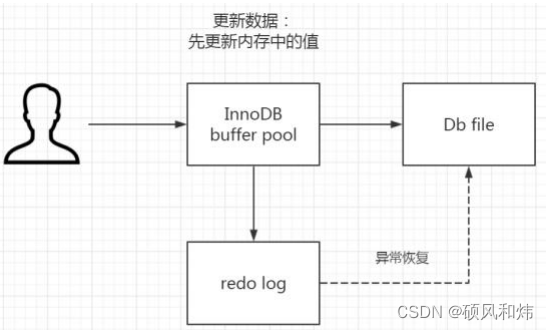
3.2 存在的问题&持久化机制
3.2.1 存在的问题
这里也会存在一个问题就是,如果在脏页还没有写入到磁盘的时候,服务器此时出现了问题,那么内存中的数据就会存在丢失的问题。或者是刷脏刷到一半的时候,甚至破坏数据文件,所以我们必须做一个持久化的机制。
3.2.2 持久化机制
InnoDB引入了一个日志文件,我们叫做redo log重做日志,我们把所有对内容数据的修改操作写入日志文件,如果服务器出现了问题,我们就从这个额日志文件里面文件读取数据,恢复数据,用它来实现事务的持久化。
3.2.3 redo log有什么特点呢?
- 记录修改后的值,属于物理日志
- redo log 大小固定,前面内容会被覆盖,所以并不能用于数据的回滚,以及数据的恢复
- redo log是innodb引擎特有的,并不是所有的引擎都具备
3.2.4 Buffer Pool的内存淘汰策略
-
冷热分区的LRU策略
LRU链表会被拆分成为两部分,一部分为热数据,一部分为冷数据。冷数据占比 3/8,热数据5/8。
具体分配如下图所示:
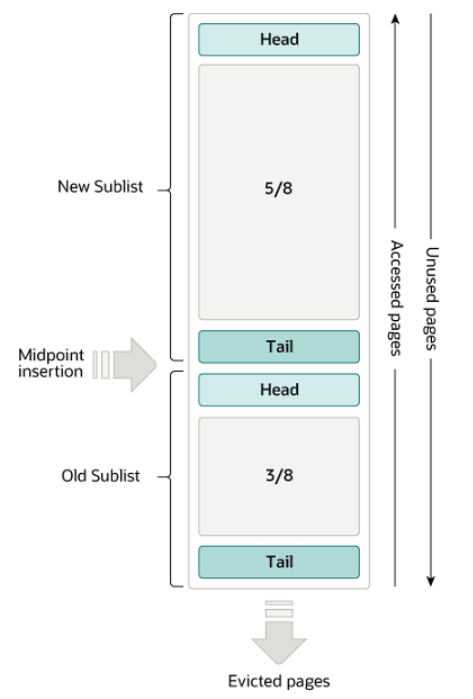
-
数据页第一次加载进来,放在LRU链表的什么地方?
放在冷数据区域的头部
- 冷数据区域的缓存页什么时候放入热数据区域?
MySQL设定了一个规则,在 innodb_old_blocks_time 参数中,默认值为1000,也就是1000毫秒。
意味着,只有把数据页加载进缓存里,在经过1s之后再次对此缓存页进行访问才会将缓存页放到LRU链表热数据区域的头部。
4.为什么是1秒?
因为通过预读机制和全表扫描加载进来的数据页通常是1秒内就加载了很多,然后对他们访问一下,这些都是1秒内完成,他们会存放在冷数据区域等待刷盘清空,基本上不太会有机会放入到热数据区域,除非在1秒后还有人访问,说明后续可能还会有人访问,才会放入热数据区域的头部。
- 什么是预读机制呢?
磁盘读写,并不是按需读取,而是按页读取,一次至少读一页数据(一般是4K)但是Mysql的数据页是16K,如果未来要读取的数据就在页中,就能够省去后续的磁盘IO,提高效率。
四.总结
饭要一口一口吃,知识也要一点一点积累,一起加油吧。
我是硕风和炜,我们下篇文章见哦。
相关文章:
【强烈建议收藏:MySQL面试必问系列之SQL语句执行专题】
一.知识回顾 之前的文章我们一起学习了MySQL面试必问系列之事务专题、锁专题,没有学习的小伙伴可以直接通过该链接地址直接访问,MYSQL你真的了解吗专栏的文章,接下来我们就一起来学习一下MySQL中SQL语句的执行流程,看看你掌握的怎…...

详解Linux下的环境变量以及C++库文件和头文件、python库的配置
目录 Linux环境变量配置基本步骤 1.查看环境变量 2.设置环境变量 3.永久性设置环境变量 4.使用环境变量 C 库文件和头文件环境变量配置 1.配置so库文件的环境变量 2.配置头文件的环境变量 Python库环境变量配置 Linux配置执行文件环境变量 我们都习惯在Windows 上配置…...
企业级分布式数据库 - GaussDB介绍
目录 什么是GaussDB 简介 应用场景 产品架构 产品优势 安全 责任共担 身份认证与访问控制 数据保护技术 审计与日志 监控安全风险 故障恢复 认证证书 GaussDB与其他服务的关系 约束与限制 计费模式 什么是GaussDB …...

Linux I2C 驱动实验
目录 一、Linux I2C 驱动简介 1、I2C 总线驱动 2、I2C 设备驱动 1、 i2c_client 结构体 2、 i2c_driver 结构体 二、硬件分析 三、设备树编写 1、pinctrl_i2c1 2、在 i2c1 节点追加 ap3216c 子节点 3、验证 四、 代码编写 1、makefile 2、ap3216c.h 3、ap3216c.c …...
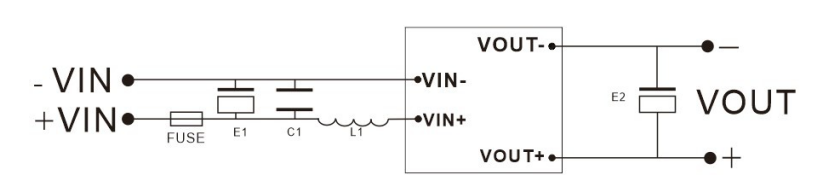
DC-DC模块电源隔离直流升压高压稳压输出5v12v24v转60v100v110v150v220v250v300v400v500v
特点效率高达80%以上1*1英寸标准封装单电压输出稳压输出工作温度: -40℃~85℃阻燃封装,满足UL94-V0 要求温度特性好可直接焊在PCB 上应用HRB 0.2~10W 系列模块电源是一种DC-DC升压变换器。该模块电源的输入电压分为:4.5~9V、9~18V、及18~36VDC标准&#…...

EF有几种模式,EF的三种模式分别是什么?
EF有几种模式,EF的三种模式分别是什么? 第一种:DataBase First DataBase First传统的表驱动方式创建EDM,然后通过EDM生成模型和数据层代码。除生成实体模型和自跟踪实现模型,还支持生成轻型DbContext。 解释…...
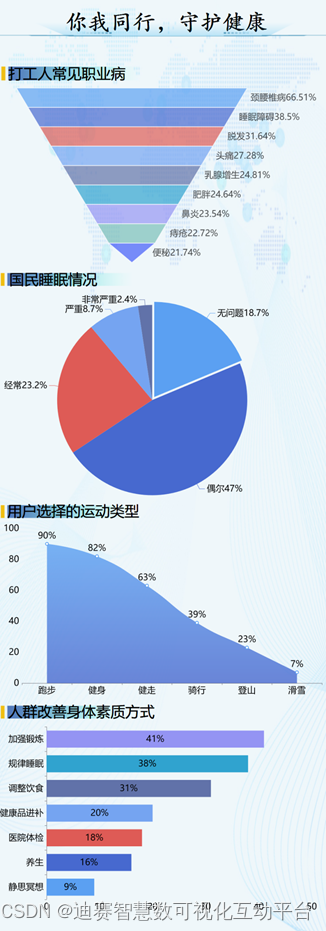
数据可视化展示:打工人常见职业病,颈腰椎病占比最高达66.51%
身体健康才是一切的根本。只有身体健健康康才能更好的去享受世间的美好,无论是谁都应当注重身体健康,而不是无度的挥霍它! 良好的身体,释放给工作,健壮的体魄,享受美好生活,良好的心态ÿ…...
【食品图像识别】Large Scale Visual Food Recognition
1 引言 视觉智能部与中科院计算所于2020-2021年度展开了《细粒度菜品图像识别和检索》科研课题合作,本文系双方联合在IEEE T-PAMI2023发布论文《Large Scale Visual Food Recognition》 (Weiqing Min, Zhiling Wang, Yuxin Liu, Mengjiang Luo, Liping Kang, Xiaom…...

RAN-in-the-Cloud:为 5G RAN 提供云经济性
RAN-in-the-Cloud:为 5G RAN 提供云经济性 5G 部署在全球范围内一直在加速。 许多电信运营商已经推出了5G服务并正在快速扩张。 除了电信运营商之外,企业也对使用 5G 建立私有网络产生了浓厚的兴趣,这些私有网络利用了更高的带宽、更低的延迟…...

vector、list、queue
引用:windows程序员面试指南 vector vector 类似于C语言中的数组 vector 支持随机访问,访问某个元素的时间复杂度 O(1) vector 插入和删除元素效率较低,时间复杂度O(n) vector 是连续存储,没有内存碎片,空间利用率高…...

操作系统面经
进程与线程区别 1.进程是资源分配的最小单位,线程是程序执行的最小单位(资源调度的最小单位) 2.进程有自己的独立地址空间,每启动一个进程,系统就会为它分配地址空间,建立数据表来维护代码段、堆栈段和数…...

一天约了4个面试,复盘一下面试题和薪资福利
除了最新的面经分享,还有字节大佬的求职面试答疑,告诉你关键问题是什么?少走弯路。**另外本文也汇总了6份大厂面试题:字节、腾讯、小米、腾讯云、滴滴、小米游戏。**希望对大家有帮助。 前言 昨天我的交流群里,有位宝…...
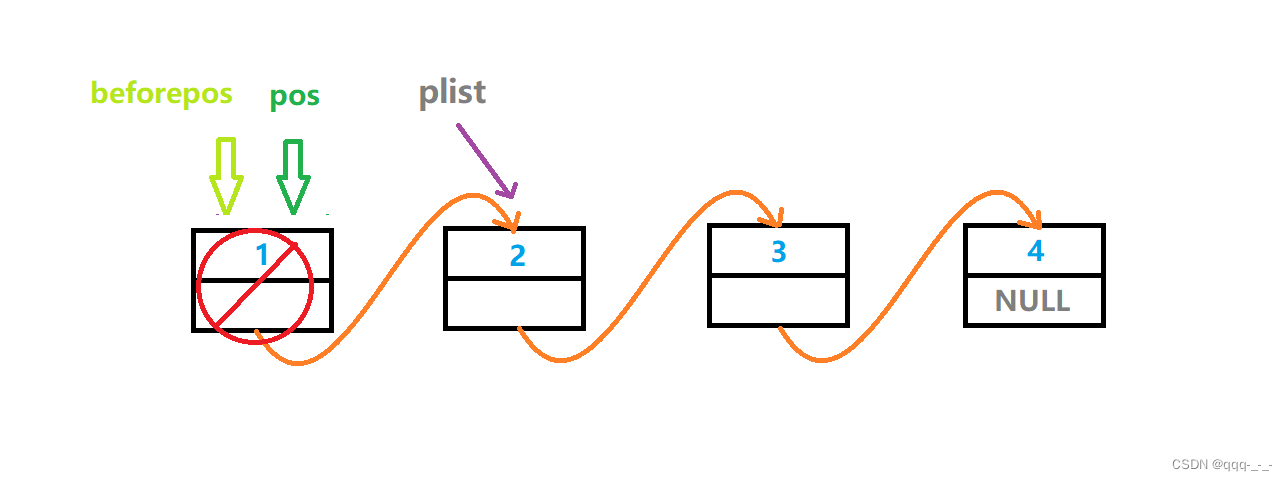
详解单链表(内有精美图示哦)
全文目录引言链表链表的定义与结构链表的分类单链表的实现及对数据的操作单链表的创建与销毁创建销毁单链表的打印单链表的头插与头删头插头删单链表的尾插与尾删尾插尾删单链表的查找单链表在pos位置后插入/删除插入删除单链表在pos位置插入/删除插入删除总结引言 在上一篇文…...
csdn文章导航
这里写自定义目录标题欢迎使用Markdown编辑器新的改变功能快捷键合理的创建标题,有助于目录的生成如何改变文本的样式插入链接与图片如何插入一段漂亮的代码片生成一个适合你的列表创建一个表格设定内容居中、居左、居右SmartyPants创建一个自定义列表如何创建一个注…...

【Spring】掌握 Spring Validation 数据校验
个人简介:Java领域新星创作者;阿里云技术博主、星级博主、专家博主;正在Java学习的路上摸爬滚打,记录学习的过程~ 个人主页:.29.的博客 学习社区:进去逛一逛~ Spring Validation 数据校验一、什么是 Spring…...

定语 从句
回顾能作定语的成分 形容词:She is a responsible girl.她是一个负责任的姑娘。(前置定语) The girl responsible was expelled.对此负责的姑娘被开除了。(后置定语) 代词:Whose f…...

【数据可视化工具】浅谈 DataEase 和 FineBI 支持的数据源
前言最近对市面上比较火热的数据可视化工具 DataEase 和 FineBI 进行了调研,在支持的数据源方面感觉不太一样,所以就有了这篇文章,话不多说,我们一起来看一下吧!以下的内容,大多来自两个工具的官方文档&…...

100种思维模型之上帝视角思维模型-025
惊奇、愤怒、郁闷,我们觉得生活不精彩,事情乱作一团,但这仅仅是视角问题而已。 换个视角,可以看到不同的世界。 “上帝视角思维模型”,即以一个更高、更客观、更理性的角度来看问题,从而做出理性的决策。 …...

从这5个方面,总结我当PM的第一年
以下5个方面(学习、思考、沟通、执行、产品)的分享,都是我站在巨人的肩膀上,结合自己所学所做总结而来;同时,我也继续学习,不断完善这些知识。如有不当,欢迎大家指正~一、学习&#…...

ChatGPT可以作为一个翻译器吗?
论文地址:https://arxiv.org/abs/2301.08745.pdf 背景 自从OpenAI2022年11月30日发布ChatGPT以来,基本上把NLP所有任务大统一了,那么在机器翻译的表现到底如何呢?腾讯AI Lab在翻译Prompt、多语言翻译以及翻译鲁棒性三方面做了一…...

Stitches API完全指南:从基础配置到自定义扩展
Stitches API完全指南:从基础配置到自定义扩展 【免费下载链接】stitches HTML5 Sprite Sheet Generator 项目地址: https://gitcode.com/gh_mirrors/sti/stitches Stitches是一款强大的HTML5 Sprite Sheet Generator,它提供了直观的API接口&…...
)
告别网盘客户端!用Alist+RaiDrive把百度云盘变成电脑本地文件夹(保姆级图文教程)
用AlistRaiDrive实现网盘本地化管理的终极方案 你是否厌倦了电脑上安装多个网盘客户端,不仅占用系统资源,操作还繁琐割裂?每次上传下载文件都要在不同客户端间切换,效率低下。现在,通过Alist和RaiDrive的组合…...

从分立逻辑到单片机:基于ATmega8的MIDI通道分析仪设计与实现
1. 项目概述:从分立逻辑到单片机的MIDI通道分析仪进化史二十年前,当我在《Elektor》杂志上发表第一版MIDI通道分析仪时,整个数字音乐世界还处于一个相当“硬核”的阶段。那个版本的设计,用今天的话来说,简直就是一场“…...

sudo企业级应用【20260525】001篇
文章目录 一、总体设计思路 1️⃣ 设计原则 2️⃣ 日志策略(重点) 二、10 个真实生产场景(含 sudoers 配置) 🔹 Linux 系统管理(3 个) ✅ 场景 1:基础运维(用户 / 权限) ✅ 场景 2:磁盘与文件系统 ✅ 场景 3:网络与防火墙 🔹 云管理(2 个) ✅ 场景 4:云 CLI …...

13456
12356...

解决Claude Code访问不稳定与Token不足的痛点
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 解决Claude Code访问不稳定与Token不足的痛点 许多开发者将Claude Code作为日常编程的得力助手,用于代码生成、问题调试…...
)
毕业设计 yolov11骨折检测医疗辅助系统(源码+论文)
文章目录 0 前言1 项目运行效果2 课题背景2.1 研究背景2.2 国内外研究现状2.3 研究意义 3 设计框架(骨折检测系统设计框架说明)3.1. 系统架构图3.2. 技术选型3.2.1 核心组件3.2.2 辅助工具 3.3. 核心模块设计3.3.1 YOLO模型训练模块训练流程图关键伪代码…...

SMUDebugTool终极指南:如何深度掌控AMD Ryzen处理器的隐藏性能
SMUDebugTool终极指南:如何深度掌控AMD Ryzen处理器的隐藏性能 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: ht…...

【DeepSeek架构评审功能深度解密】:20年架构师亲授3大避坑指南与5步落地 checklist
更多请点击: https://kaifayun.com 第一章:DeepSeek架构评审功能全景概览 DeepSeek架构评审功能是一套面向大模型系统设计与工程落地的自动化分析框架,聚焦于模型结构合理性、计算图优化潜力、内存访问模式、算子兼容性及部署约束等多维度评…...

孤舟笔记 互联网常用框架篇三 Dubbo是如何动态感知服务下线的?注册中心和服务端双保险
文章目录先说结论机制一:注册中心通知机制二:心跳检测机制三:连接事件感知机制四:定时拉取四种机制的协作回答技巧与点评加分回答面试官点评个人网站微服务环境下,服务实例随时可能上下线——重启、扩容、宕机……调用…...