[论文阅读笔记28] 对比学习在多目标跟踪中的应用
这次做一篇2D多目标跟踪中使用对比学习的一些方法.
对比学习通过以最大化正负样本特征距离, 最小化正样本特征距离的方式来实现半监督或无监督训练. 这可以给训练MOT的外观特征网络提供一些启示. 使用对比学习做MOT的鼻祖应该是QDTrack, 本篇博客对QDTrack及其后续工作做一个总结.
持续更新…
1. QDTrack
论文: QDTrack: Quasi-Dense Similarity Learning for Appearance-Only Multiple Object Tracking (TPAMI2023)
1.1 主要思想
外观特征在跟踪中是非常重要的线索. 训练外观特征网络的方式有很多, 例如最开始JDE, Fairmot将外观特征网络的训练问题转换为分类问题, 也即每个目标(identity)都自成一类. 然而, 这样一个数据集中可能有成千上万个类, 但是外观特征的维度往往不会很大, 这样就给这个分类网络的训练带来了一定的困难.
如果采用对比学习的方式, 我们每次只关注若干正样本和若干负样本, 我们要做的就是拉大正负样本之间的距离就可以了, 实际上这时候就减少了一些训练的难度. 然而, 我们知道, 对于对比学习来说, 通常来讲样本量越多越好, batch size越大越好. 基于这个认识, QDTrack提出了一种密集采样的方法增大正负样本数量, 进而提高对比学习性能. 同时, 将MOT的关联问题就转换为了求特征距离, 不需要依赖于运动特征.
1.2 具体方法
训练过程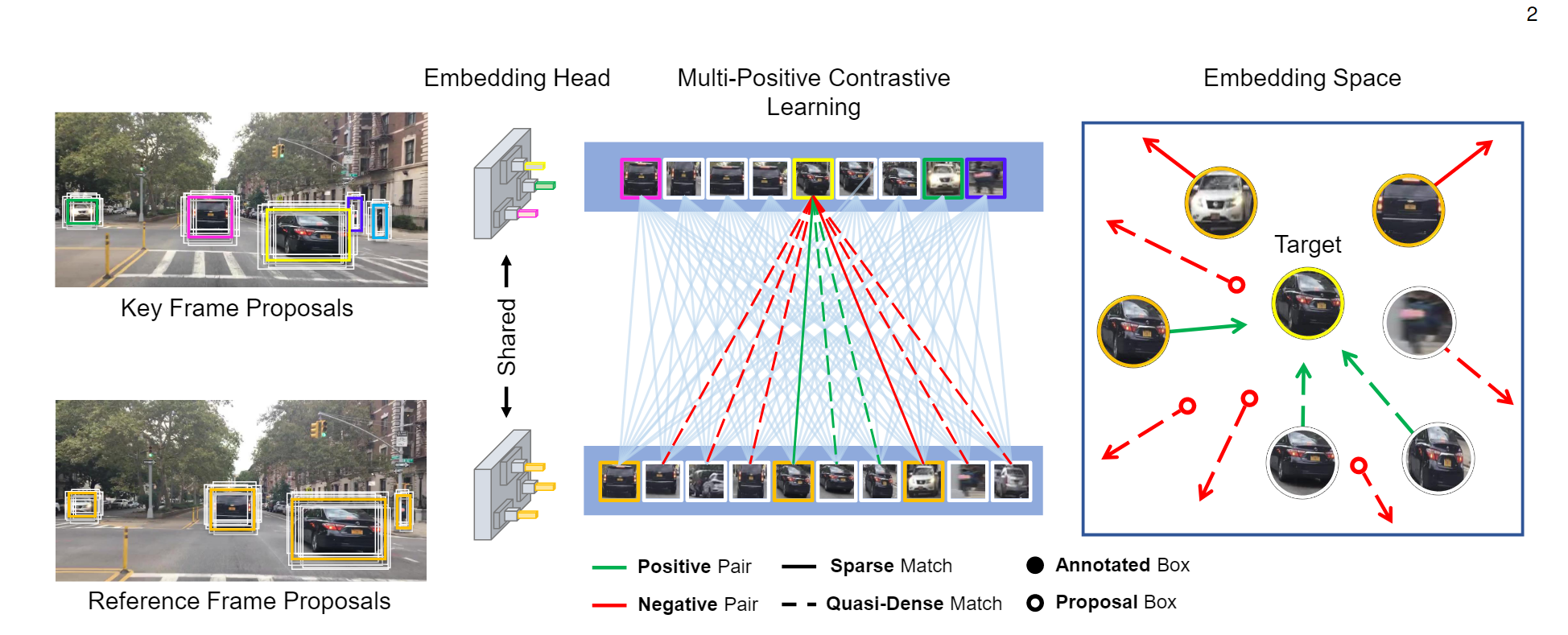
算法流程是这样的. 首先, 选定一帧 I 1 I_1 I1表示key frame, 然后在其附近的时序上再随机采样一帧 I 2 I_2 I2作为reference frame. QDTrack是可以和检测器一起端到端训练的, 因此我们可以根据检测器的结果定位每个目标, 并采用ROI Align方法将每个目标对应区域的特征都提出来.
正负样本的定义: 对于预测的一个边界框, 如果它和某个真值的IoU大于 α 1 \alpha_1 α1, 则认为该边界框是真值的正样本; 如果IoU大于 α 2 \alpha_2 α2, 则认为该边界框是真值的负样本. 对于时序上, key frame和reference frame的两个边界框对应同一个目标, 则该样本对为正, 否则为负.
如果key frame上有 V V V个样本, reference frame上有 K K K个样本, 则对于一个正样本对 ( v , k + ) (\mathbf{v}, \mathbf{k^+}) (v,k+), 损失函数为:
L e m b e d = − log exp ( v k + ) exp ( v k + ) + ∑ k − exp ( v k − ) \mathcal{L}_{embed} = - \log \frac{ \exp ({\mathbf{v} \mathbf{k^+}})} {\exp ({\mathbf{v} \mathbf{k^+}})+\sum_{\mathbf{k^-}}\exp ({\mathbf{v} \mathbf{k^-}})} Lembed=−logexp(vk+)+∑k−exp(vk−)exp(vk+)
其中 v , k + , v , k − \mathbf{v}, \mathbf{k^+}, \mathbf{v}, \mathbf{k^-} v,k+,v,k−分别表示key frame的某个样本, 以及它对应的正负样本的特征,
在QDTrack的设计中, 最重要的就是通过密集匹配去增加样本对. 也就是说, 一个key frame的样本要和所有reference frame的样本进行对应. 损失要对所有的正样本求和, 有:
L e m b e d = − ∑ k + log exp ( v k + ) exp ( v k + ) + ∑ k − exp ( v k − ) \mathcal{L}_{embed} = - \sum_{\mathbf{k^+}}\log \frac{ \exp ({\mathbf{v} \mathbf{k^+}})} {\exp ({\mathbf{v} \mathbf{k^+}})+\sum_{\mathbf{k^-}}\exp ({\mathbf{v} \mathbf{k^-}})} Lembed=−k+∑logexp(vk+)+∑k−exp(vk−)exp(vk+)
整理一下:
L e m b e d = − ∑ k + log exp ( v k + ) exp ( v k + ) + ∑ k − exp ( v k − ) = ∑ k + log exp ( v k + ) + ∑ k − exp ( v k − ) exp ( v k + ) = ∑ k + log [ 1 + ∑ k − exp ( v k − − v k + ) ] \mathcal{L}_{embed} = - \sum_{\mathbf{k^+}}\log \frac{ \exp ({\mathbf{v} \mathbf{k^+}})} {\exp ({\mathbf{v} \mathbf{k^+}})+\sum_{\mathbf{k^-}}\exp ({\mathbf{v} \mathbf{k^-}})} \\ = \sum_{\mathbf{k^+}}\log \frac{\exp ({\mathbf{v} \mathbf{k^+}})+\sum_{\mathbf{k^-}}\exp ({\mathbf{v} \mathbf{k^-}})} {\exp ({\mathbf{v} \mathbf{k^+}})} \\ =\sum_{\mathbf{k^+}}\log [1 + \sum_{\mathbf{k^-}}\exp(\mathbf{v} \mathbf{k^-}-\mathbf{v} \mathbf{k^+}) ] Lembed=−k+∑logexp(vk+)+∑k−exp(vk−)exp(vk+)=k+∑logexp(vk+)exp(vk+)+∑k−exp(vk−)=k+∑log[1+k−∑exp(vk−−vk+)]
上面这个式子将外层的求和放到log里就是连乘号, 计算量比较大, 因此作者采用了一种等价的方式:
L e m b e d = log [ 1 + ∑ k + ∑ k − exp ( v k − − v k + ) ] \mathcal{L}_{embed} = \log [1 + \sum_{\mathbf{k^+}} \sum_{\mathbf{k^-}}\exp(\mathbf{v} \mathbf{k^-}-\mathbf{v} \mathbf{k^+}) ] Lembed=log[1+k+∑k−∑exp(vk−−vk+)]
同时, 还加入了一个辅助的损失函数, 使得正样本对之间相似度接近1, 否则接近0:
L a u x = ( v k ∣ ∣ v ∣ ∣ ∣ ∣ k ∣ ∣ − c ) 2 \mathcal{L}_{aux} = (\frac{\mathbf{v} \mathbf{k}}{||\mathbf{v} |||| \mathbf{k}||} - c)^2 Laux=(∣∣v∣∣∣∣k∣∣vk−c)2
其中正样本对对应的是 c = 1 c=1 c=1, 否则 c = 0 c=0 c=0.
为了和检测器端到端训练, 最终的损失函数就是检测损失, L e m b e d , L a u x \mathcal{L}_{embed}, \mathcal{L}_{aux} Lembed,Laux的加权和.
推理过程
推理过程主要是两个创新点. 一个是类间NMS, 这是因为有时候检测器的分类会不准确, 导致同一个目标, 但是出现两个重叠边界框, 这两个边界框被分到不同的类. 所以作者采用了一个类间NMS.
一个是对于外观相似度计算, 没有简单地采用余弦相似度的形式, 而是采用了双向softmax. 本质是差不多的, 就是softmax考虑了所有样本的信息计算相似度. 从消融实验的结果看, 采用密集正样本和双向softmax对效果的提升都是比较明显的.
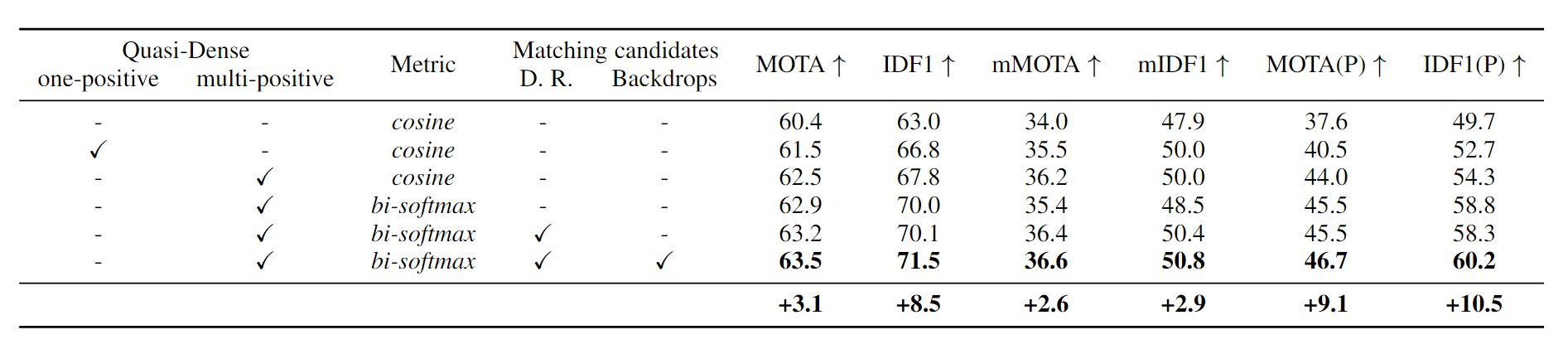
2. Towards Discriminative Representation: Multi-view Trajectory Contrastive Learning for Online Multi-object Tracking
论文: Towards Discriminative Representation: Multi-view Trajectory Contrastive Learning for Online Multi-object Tracking (CVPR2022)
2.1 主要思想
类似于QDTrack这种方法, 往往只在相邻的时域当中取样本对, 而没有很好地利用整个轨迹时域上的信息. 针对这个问题, 这篇工作利用历史轨迹的信息更全面地描述一个目标, 进行对比学习.
他们将历史轨迹表示成一个向量, 并存储到一个动态的memory bank中. 并以此构建了以轨迹为中心的对比学习, 就可以利用好丰富的帧间信息. 这就是题目Multi-view的由来.
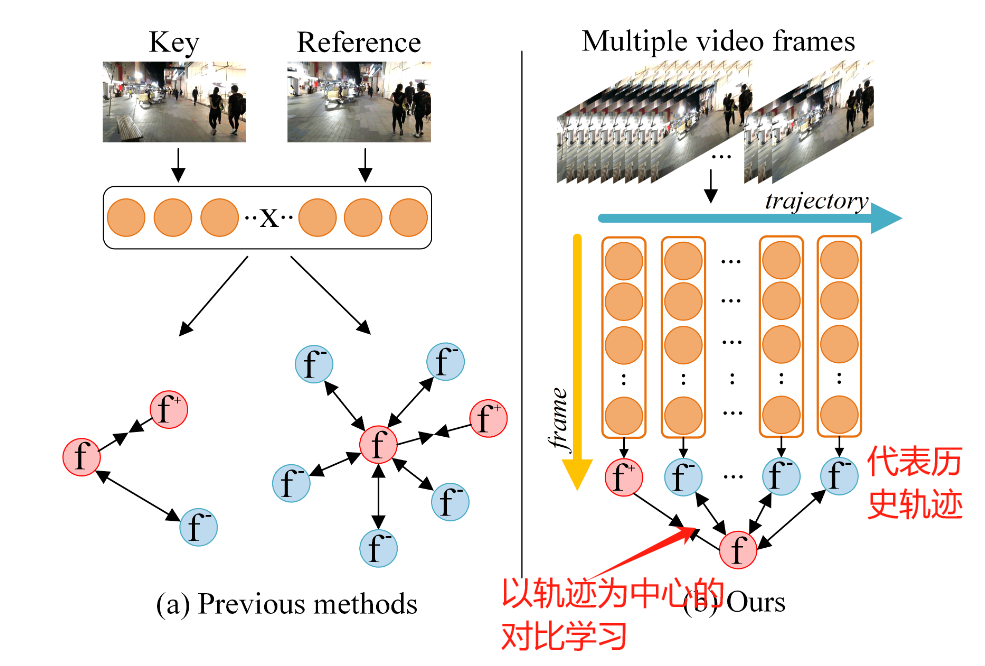
2.2 具体方法
论文的创新点一共有三个, 下面逐一介绍:
1.Learnable view sampling
作者的方法称为MTrack. MTrack是基于Fairmot改的. 当然, Fairmot是基于CenterNet, 把backbone换成了DLA-34. CenterNet是以点作为目标中心, 无锚检测器, 但作者认为只用一个点代表目标是不行的, 是因为目标的中心点可能被遮挡, 并且为对比学习产生的样本对也不足.
为了解决这个问题, 作者就加了一个线性层, 去根据目标的中心点坐标预测更多的采样点坐标, 当然, 采样点要在边界框的范围内. 这些采样点都代表了同一个目标, 也就产生了很多正样本. (注意一个点的特征直接就是从预测的heatmap上提取的).
2. Trajectory-center memory bank
作者是如何用一个向量代表一个历史轨迹的呢?
在训练阶段, 网络以许多帧作为输入, 并检测出每个帧中所有的检测样本. 根据Learnable view sampling, 每个检测样本可以衍生出 N k N_k Nk个特征向量.
在训练阶段, 每个检测都有对应的轨迹ID (为什么? 作者没有解释). 那么, 我们就可以以当前帧检测的特征去更新memory bank中的特征. 当然, 作者在这里选择的策略是"hardest sample", 也就是选择特征最不相似的一个(用余弦距离衡量)线性更新memory bank中的对应特征.
对于损失函数, 对每一个外观特征向量 v ~ l k \tilde{v}_l^k v~lk (下标 l l l表示属于的ID, 上标 k k k表示序数), 去拉进它和它对应ID轨迹中心的距离, 放大它和其他ID轨迹中心的距离, 采用对比学习常用的InfoNCE Loss: (Softmax + 一个temperature parameter):
L N C E k = − log exp ( v ~ l k c l ) / τ ∑ i exp ( v ~ l k c i ) / τ L_{NCE}^k = - \log \frac{\exp (\tilde{v}_l^k c_l) / \tau} {\sum_i \exp (\tilde{v}_l^k c_i) / \tau} LNCEk=−log∑iexp(v~lkci)/τexp(v~lkcl)/τ
因此, 对于所有的外观embedding, 总损失为
L T C L = 1 N a ∑ k = 1 N a L N C E k L_{TCL} = \frac{1}{N_a} \sum_{k=1}^{N_a} L_{NCE}^k LTCL=Na1k=1∑NaLNCEk
最终的损失仿照Fairmot, 采用uncertainty loss.
总的训练框图如下:
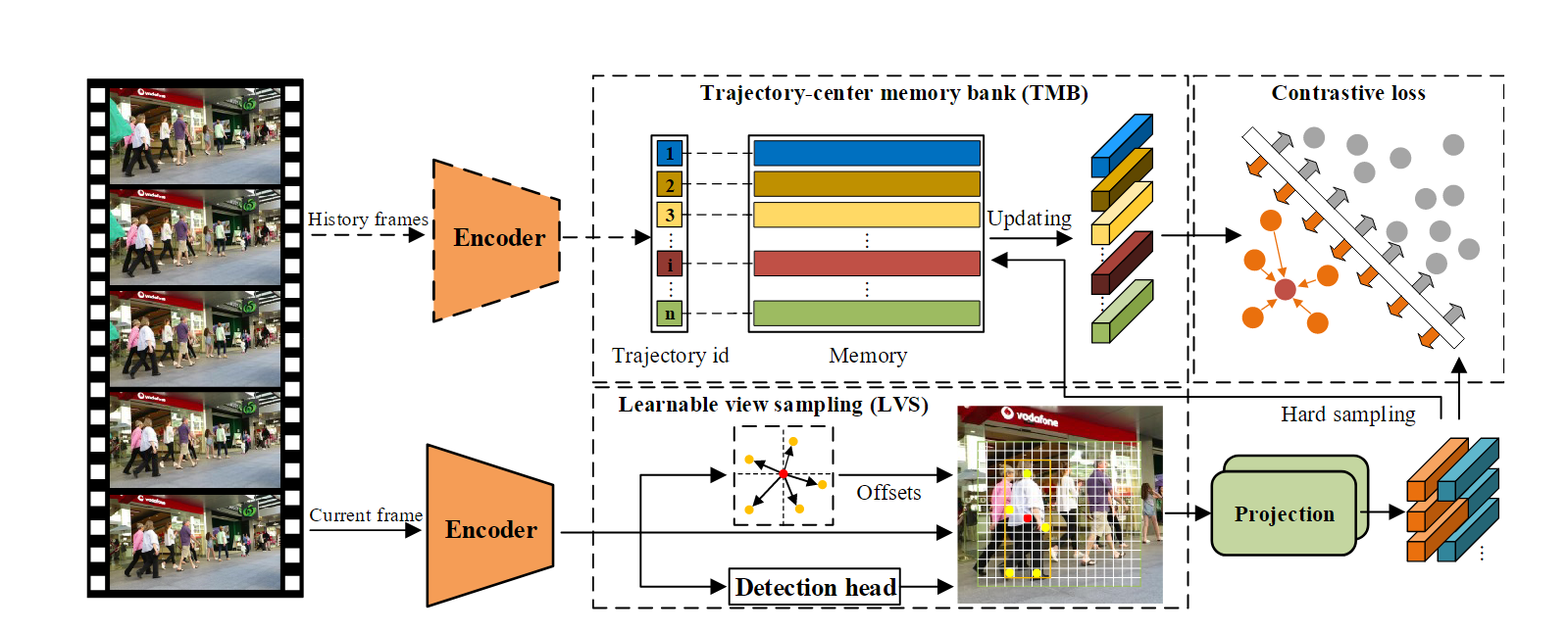
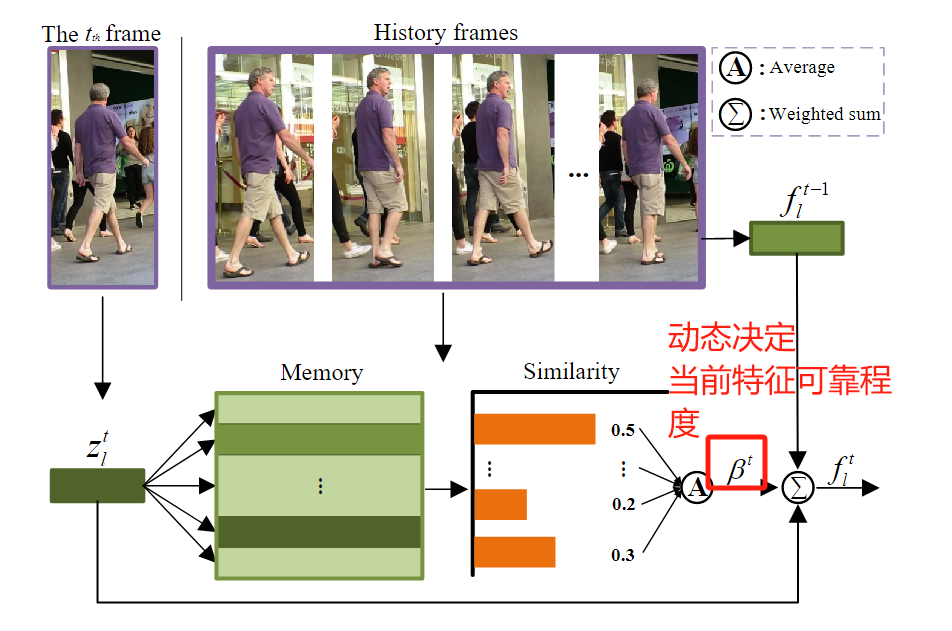
推理阶段比较正常, 主要是提出了一个根据历史和现在特征余弦相似度度进行轨迹特征融合的方法. 如果和过去相似, 就取信于当前的特征, 否则不取信. 这个也是很多方法都有的.
3. Uncertainty-aware Unsupervised Multi-Object Tracking
论文:Uncertainty-aware Unsupervised Multi-Object Tracking (ICCV2023)
3.1 主要思想
对于无监督MOT, 由于没有目标ID的标签, 那么只能通过一些相似度准则生成伪标签. 然而, 如果发生错误, 这种错误在帧间是会累积的. 为了解决这个问题, 作者认为不确定性是不可避免的(不确定性就指的是在无标签的情况下, 两个不同的相似目标容易混淆, 或者同一个目标产生了遮挡或模糊, 也容易认为是两个目标), 但可以利用不确定性去提升效果(在我理解就是降低不确定性).
既然无监督是训练外观特征提取网络, 那么当外观发生不确定的时候怎么办呢? 那就融合运动特征(IoU)就可以. 这就是这篇文章主要创新点.
此外, 为了增大样本数量, 除了利用历史轨迹外, 该方法还采取了数据增强策略. 然而, 传统对比学习的增强方式不利于跟踪的学习, 因为他们增强并没有融合轨迹的运动信息. 为了解决这个问题, 作者将 t t t, t − τ t - \tau t−τ帧的仿射变换求解出来, 然后根据历史轨迹形成当前帧"应该"长成的样子, 这样就增大了样本数量.
3.2 具体方法
不确定度的衡量
在无监督训练的时候, 我们根据外观相似度将 t − 1 t-1 t−1帧的目标与 t t t帧目标进行匹配, 匹配矩阵为:
C ∈ R M t × M t − 1 , c i , j = f i t ⋅ f j t − 1 \mathbf{C}\in \mathbb{R}^{M^t \times M^{t-1}}, c_{i, j} = \mathbf{f}_i^t \cdot \mathbf{f}_j^{t-1} C∈RMt×Mt−1,ci,j=fit⋅fjt−1
然而, 有两种情况可能让余弦相似度失真: 1) 目标自身发生遮挡或者模糊, 让相似度减小; 2) 相似目标的存在, 使得不该大的相似度变大.
也就是:
c i , j < m 1 , c i , j − c i , j 2 < m 2 c_{i, j} < m_1, c_{i, j} - c_{i, j2} < m_2 ci,j<m1,ci,j−ci,j2<m2
其中 m 1 , m 2 m_1, m_2 m1,m2是常数. 理想的情况, 我们应该让 c i , j c_{i, j} ci,j接近1, 而 c i , j 2 c_{i, j2} ci,j2接近0. 为了一起衡量以上两种情况, 作者定义不确定度:
σ i , j = − log c i , j − log ( 1 − c i , j 2 ) \sigma_{i, j} = - \log c_{i, j} - \log (1 - c_{i, j2}) σi,j=−logci,j−log(1−ci,j2)
该不确定度的下界为
σ i , j ≥ γ i , j = − log m 1 − log ( 1 + m 2 − c i , j ) \sigma_{i, j} \ge \gamma_{i, j} = - \log m_1 - \log (1 + m_2 - c_{i, j}) σi,j≥γi,j=−logm1−log(1+m2−ci,j)
因此总的不确定度表现为不确定度和下界值的差:
δ i , j = σ i , j − γ i , j \delta_{i, j} = \sigma_{i, j} - \gamma_{i, j} δi,j=σi,j−γi,j
以上就是不确定度的验证过程.
验证出了不确定度后, 就要进行修正.
修正主要是考虑两点: 1) 历史的外观信息 2) 运动信息(IoU)
因此, 新的代价矩阵变为:
C ′ ∈ R M t ′ × M t − 1 ′ , c i , j ′ = ( 1 K ∑ t ^ = t − K t − 1 f i t ⋅ f j t ^ ) × I ( IoU ( b i t , b j t − 1 ) > β ) \mathbf{C}'\in \mathbb{R}^{M^{t'} \times M^{t-1'}}, \\ c_{i, j}^{\prime}=\left(\frac{1}{K} \sum_{\hat{t}=t-K}^{t-1} \boldsymbol{f}_i^t \cdot \boldsymbol{f}_j^{\hat{t}}\right) \times \mathbb{I}\left(\operatorname{IoU}\left(b_i^t, b_j^{t-1}\right)>\beta\right) C′∈RMt′×Mt−1′,ci,j′= K1t^=t−K∑t−1fit⋅fjt^ ×I(IoU(bit,bjt−1)>β)
轨迹数据增强
这一块其实就是利用图像之间的仿射变换矩阵, 根据现有帧推测出历史帧长成什么样子, 就得到了增强的图像.
对于增强图像, 也是通过前面不确定度进行匹配衡量. 具体的, 对于第 i i i个轨迹, 轨迹长度为 n n n, 这段时间它的不确定度为
Ω i = 1 n ∑ s = t 0 t exp ( δ i s ) \Omega_i=\frac{1}{n} \sum_{s=t_0}^t \exp \left(\delta_i^s\right) Ωi=n1s=t0∑texp(δis)
我们按照如下Softmax形式的原则将增强图像中的轨迹 a a a认为和 i i i是同一个
:
p ( a = i ∣ t ) = exp ( − Ω i ) ∑ i ^ = 1 M t exp ( − Ω i ^ ) p(a=i \mid t)=\frac{\exp \left(-\Omega_i\right)}{\sum_{\hat{i}=1}^{M^t} \exp \left(-\Omega_{\hat{i}}\right)} p(a=i∣t)=∑i^=1Mtexp(−Ωi^)exp(−Ωi)
上面的概率越大表明二者关联的概率越大.
此外, 作者还通过历史轨迹中"最困难"的样本进行学习, 也就是表现在不确定度最大的时候:
p ( π = t − τ ∣ a ) = exp ( δ a t − τ ) ∑ τ ^ = t 0 t − 1 exp ( δ a t − τ ^ ) p(\pi=t-\tau \mid a)=\frac{\exp \left(\delta_a^{t-\tau}\right)}{\sum_{\hat{\tau}=t_0}^{t-1} \exp \left(\delta_a^{t-\hat{\tau}}\right)} p(π=t−τ∣a)=∑τ^=t0t−1exp(δat−τ^)exp(δat−τ)
整体框图如下:
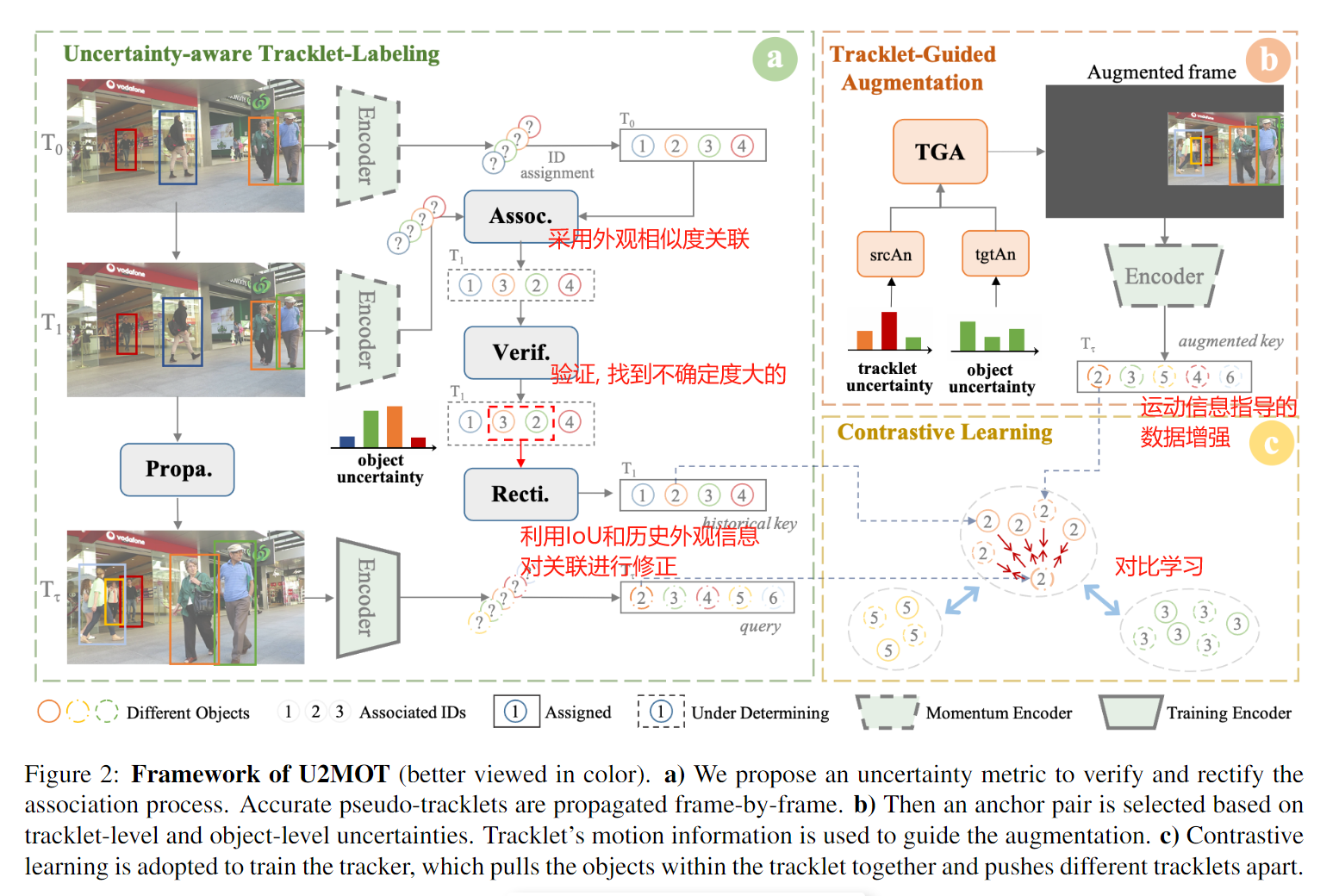
具体实现
在具体实现上, 类似JDE, 作者给YOLOX加了一个reid head进行训练的. 对比学习损失采用经典的InfoNCE.
相关文章:
[论文阅读笔记28] 对比学习在多目标跟踪中的应用
这次做一篇2D多目标跟踪中使用对比学习的一些方法. 对比学习通过以最大化正负样本特征距离, 最小化正样本特征距离的方式来实现半监督或无监督训练. 这可以给训练MOT的外观特征网络提供一些启示. 使用对比学习做MOT的鼻祖应该是QDTrack, 本篇博客对QDTrack及其后续工作做一个总…...

Ubuntu 下播放语音提示
目录 一、安装语音库 二、生成音频文件 三、语音播放代码 一、安装语音库 sudo apt update apt-get install libasound2-dev二、生成音频文件 # 文字生成 MP3网地:https://www.text-to-speech.cn/# MP3 转 WAV网址:https://www.aconvert.com/cn/aud…...

ubuntu 用户管理
ubuntu 用户管理 用户组管理用户管理VNC 远程桌面参考 用户组管理 # 查看所有组信息 cat /etc/group # 查看当前用户所在组 groups # 添加用户组 sudo groupadd uav# 添加ostest用户到 uav 用户组 需要注销并重新登录 sudo gpasswd -a ostest uav sudo usermod -aG uav ostes…...

轻舟已过万重山,鸿蒙4.0程序员危机
现在是2023年末。自从华为推出的鸿蒙系统到现在已经有4年多。之前的鸿蒙系统只是基于Android套壳,因为这也也被无数人瞧不起,自从华为秋季发布会后,宣布鸿蒙4.0问世。不再兼容Android,华为做独立的系统终于打了翻身仗。 鸿蒙系统…...

【Pytorch】学习记录分享6——PyTorch经典网络 ResNet与手写体识别
【Pytorch】学习记录分享5——PyTorch经典网络 ResNet 1. ResNet (残差网络)基础知识2. 感受野3. 手写体数字识别3. 0 数据集(训练与测试集)3. 1 数据加载3. 2 函数实现:3. 3 训练及其测试: 1. ResNet &…...

Flink1.17实战教程(第三篇:时间和窗口)
系列文章目录 Flink1.17实战教程(第一篇:概念、部署、架构) Flink1.17实战教程(第二篇:DataStream API) Flink1.17实战教程(第三篇:时间和窗口) Flink1.17实战教程&…...

CSS 纵向扩展动画
上干货 <template><!-- mouseenter"startAnimation" 表示在鼠标进入元素时触发 startAnimation 方法。mouseleave"stopAnimation" 表示在鼠标离开元素时触发 stopAnimation 方法。 --><!-- 容器元素 --><div class"container&q…...

Android 12 Token 机制
一、前言 在 android framework 框架中 activity 和 window 是相互关联的,而他们的管理者 AMS 和 WMS 是怎么来实现这种关联关系的,答案就是通过 token。 首先大家需要了解一下 LayoutParams,当然属性很多,简单了解即可…...

TCP与UDP是流式传输协议吗?
TCP(传输控制协议)和UDP(用户数据报协议)是两种主要的传输层协议,它们用于在网络中传输数据。它们不是流式传输协议,而是提供了不同的数据传输特性: 1. TCP(传输控制协议࿰…...

61 贪心算法解救生艇问题
问题描述:第i个人的体重为peaple[i],每个船可以承载的最大重量为limit。每艘船最多可以同时载两人,但条件是这些人的重量之和最多为limit,返回载到每一个人多虚的最小船数,(保证每个人被船载)。 贪心算法求解:先将数组…...
C#高级 01.Net多线程
一.基本概念 1.什么是线程? 线程是操作系统中能独立运行的最小单位,也是程序中能并发执行的一段指令序列线程是进程的一部分,一个进程可以包含多个线程,这些线程共享进程资源进程有线程入口,也可以创建更多的线程 2.…...

Java---泛型讲解
文章目录 1. 泛型类2. 泛型方法3. 泛型接口4. 类型通配符5. 可变参数6. 可变参数的使用 1. 泛型类 1. 格式:修饰符 class 类名 <类型>{ }。例如:public class Generic <T>{ }。 2. 代码块举例: public class Generic <T>{…...
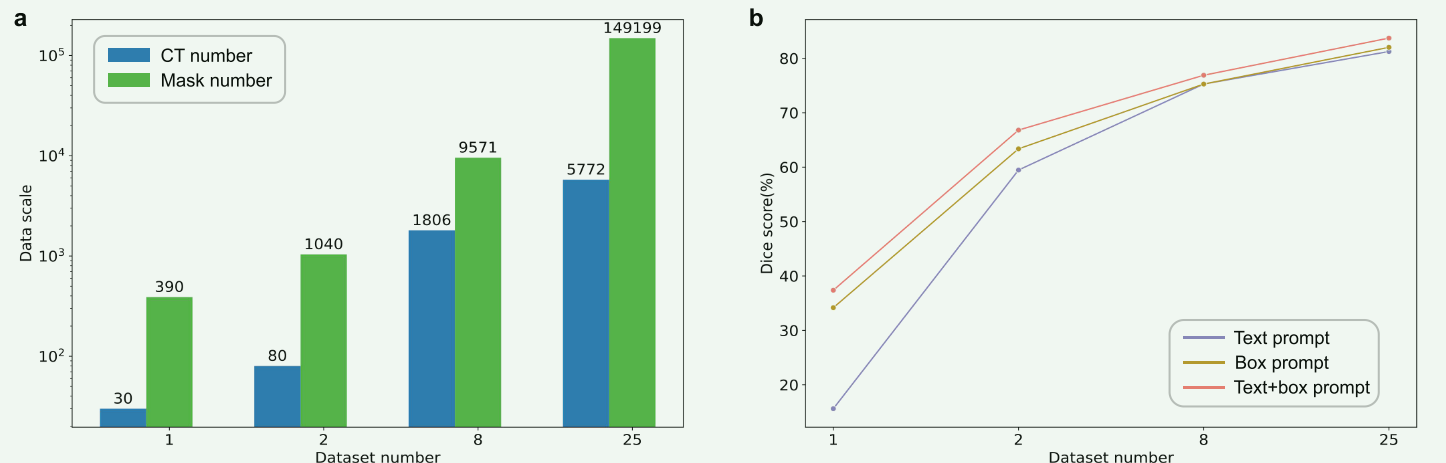
【论文阅读笔记】SegVol: Universal and Interactive Volumetric Medical Image Segmentation
Du Y, Bai F, Huang T, et al. SegVol: Universal and Interactive Volumetric Medical Image Segmentation[J]. arXiv preprint arXiv:2311.13385, 2023.[代码开源] 【论文概述】 本文思路借鉴于自然图像分割领域的SAM,介绍了一种名为SegVol的先进医学图像分割模型…...

Unix/Linux操作系统介绍
1、Unix/Linux操作系统介绍 1.1、操作系统的作用 1)操作系统的目标 方便:使计算机系统易于使用有效:以更有效的方式使用计算机系统资源扩展:方便用户有效开发、测试、引进新功能 2)操作系统的地位 操作系统在计算…...

什么是https证书?
HTTPS证书,也称为SSL(Secure Sockets Layer)证书或TLS(Transport Layer Security)证书,是一种数字证书,用于在网络上建立安全的加密连接。它的主要目的是确保在互联网上进行的数据传输的安全性和…...

C++ DAY2作业
1.课堂struct练习,用class; #include <iostream>using namespace std;class Stu { private:int age;char sex;int high; public:double score;void set_values(int a,char b,int c,double d);int get_age();char get_sex();int get_high(); }; vo…...
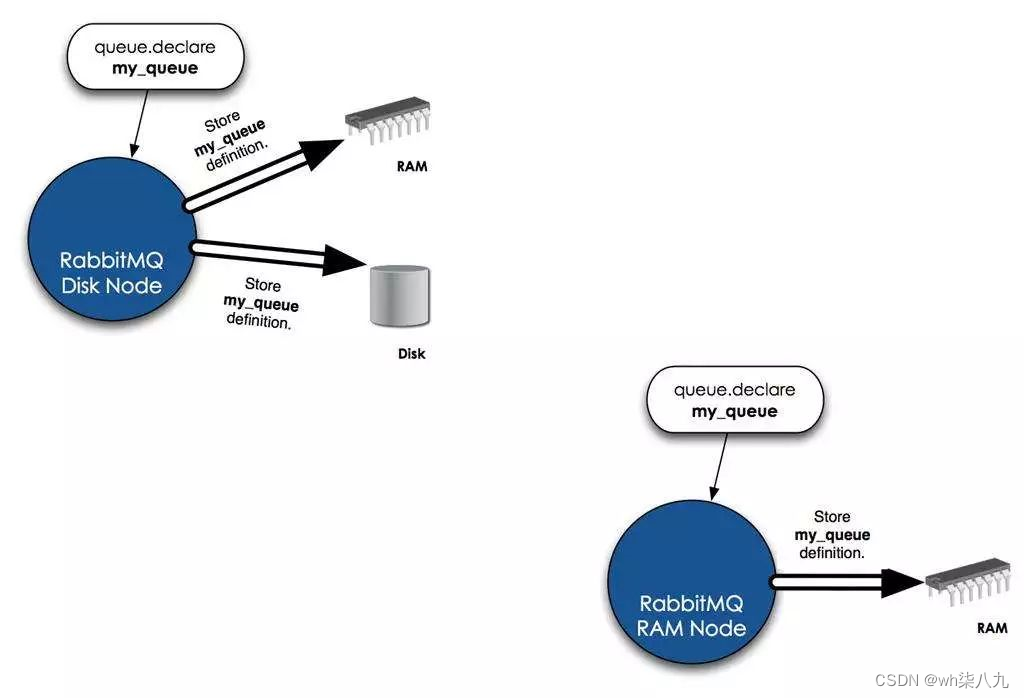
RabbitMQ核心概念记录
本文来记录下RabbitMQ核心概念 文章目录 什么叫消息队列为何用消息队列RabbitMQ简介RabbitMQ基本概念RabbitMQ 特点具体特点包括 Rabbitmq的工作过程RabbitMQ集群RabbitMQ 的集群节点包括Rabbit 模式大概分为以下三种单一模式普通模式镜像模式 本文小结 什么叫消息队列 消息&am…...
算法时间空间复杂度计算—空间复杂度
算法时间空间复杂度计算—空间复杂度 空间复杂度定义影响空间复杂度的因素算法在运行过程中临时占用的存储空间讲解 计算方法例子1、空间算法的常数阶2、空间算法的线性阶(递归算法)3、二分查找分析方法一(迭代法)方法二ÿ…...

计算机专业校招常见面试题目总结
博主面试岗位包括:java开发、软件测试、测试开发等岗位,基于之前经历的面试总结出的一些常见题目。仅供参考,互相学习!! 八股:java开发、测试、测开岗位 Java技术栈:Java基础、JVM、数据结构、…...

网络编程『简易TCP网络程序』
🔭个人主页: 北 海 🛜所属专栏: Linux学习之旅、神奇的网络世界 💻操作环境: CentOS 7.6 阿里云远程服务器 文章目录 🌤️前言🌦️正文TCP网络程序1.字符串回响1.1.核心功能1.2.程序…...

基于Helm与Kubernetes的以太坊节点自动化部署与运维实战
1. 项目概述:当以太坊遇见Kubernetes如果你和我一样,在区块链基础设施领域摸爬滚打多年,从早期手动编译客户端、配置systemd服务,到后来用Docker Compose编排节点,每一步都伴随着大量的重复劳动和运维痛点。当节点数量…...

Windows安卓开发环境一键配置:告别繁琐驱动的终极解决方案
Windows安卓开发环境一键配置:告别繁琐驱动的终极解决方案 【免费下载链接】Latest-adb-fastboot-installer-for-windows A Simple Android Driver installer tool for windows (Always installs the latest version) 项目地址: https://gitcode.com/gh_mirrors/l…...

数字永生:将意识上传云端的技术与伦理极限
——一个软件测试从业者的技术解构与风险分析各位同行,当你看到“数字永生”这四个字时,脑海里浮现的是什么?是马斯克口中2045年即将实现的意识上传,还是《黑镜》里那些被困在虚拟牢笼中的数字灵魂?作为一个每天与需求…...

抖音下载器底层架构解析:策略模式与异步编排的高性能实现
抖音下载器底层架构解析:策略模式与异步编排的高性能实现 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback su…...

新手避坑指南:ICC LAB2 Design Planning 从加载设计到写出DEF的完整流程复盘
ICC LAB2 Design Planning全流程深度解析:从数据加载到DEF输出的实战避坑指南 当你第一次打开ICC工具面对LAB2的Design Planning任务时,是否感觉像被扔进了一个满是按钮的控制室?每个命令似乎都重要,但又不清楚它们如何串联成完整…...

Python网络爬虫实战:构建自动化招聘信息聚合工具JobClaw
1. 项目概述与核心价值最近在折腾一个挺有意思的开源项目,叫 JobClaw。这名字起得挺形象,“Claw”是爪子的意思,合起来就是“工作抓取器”。简单来说,它是一个帮你从各大招聘网站上自动抓取、聚合和分析职位信息的工具。对于正在找…...

【DeepSeek开发者垂直搜索实战指南】:3大行业落地案例+5个避坑要点,限时公开内部调优参数
更多请点击: https://intelliparadigm.com 第一章:DeepSeek开发者垂直搜索应用案例全景概览 DeepSeek系列大模型凭借其开源、高性能与强推理能力,正被广泛集成至开发者垂直搜索场景中——从代码片段检索、API文档语义查找,到私有…...

MGRE实验报告
一.实验概述实验名称:MGRE实验实验目的:掌握 PPP 协议的 PAP/CHAP 认证与 HDLC 封装配置,理解不同广域网链路协议的工作机制与认证流程。实现 MGRE 环境(R1 为 Hub)与 GRE 环境的部署,理解点到多点 VPN 与点…...

基于确定性脚本与LLM决策的AI多智能体自动化监控系统设计与实践
1. 项目概述:一个为AI多智能体协作而生的“自动化监工”如果你正在用OpenClaw这类框架玩多AI智能体协作,大概率会遇到一个头疼的问题:怎么知道这群“数字员工”到底在不在干活?谁在摸鱼?任务到底完成了没有?…...

3步掌握SubtitleOCR:从视频到可编辑字幕的智能转换指南
3步掌握SubtitleOCR:从视频到可编辑字幕的智能转换指南 【免费下载链接】SubtitleOCR 快如闪电的硬字幕提取工具。仅需苹果M1芯片或英伟达3060显卡即可达到10倍速提取。A very fast tool for video hardcode subtitle extraction 项目地址: https://gitcode.com/g…...