机器学习——损失函数
【说明】文章内容来自《机器学习——基于sklearn》,用于学习记录。若有争议联系删除。
1、简介
损失函数(loss function)又称为误差函数(error function),是衡量模型好坏的标准,用于估量模型的预测值与真实值的不一致程度,是一个非负实值函数。损失函数的一般表示为L(y,f(x)),用以衡量真实值y与预测值f(x)不一致的程度,一般越小越好。
损失函数对模型进行评估,并且为模型参数的优化提供了方向。损失函数的选取依赖于参数的数量、异常值、机器学习算法、梯度下降的效率、导数求取的难易和预测的置信度等。
损失函数与代价函数(cost function)相似,可以互换使用。区别在于,损失函数用于单个训练样本。而代价函数是整个训练数据集的所有样本误差的平均损失。
损失函数有回归损失(regression loss)和分类损失(classification loss)两类。
2、回归损失
2.1 MAE
平均绝对误差(Mean Absolute Error, MAE)又称L1损失,是指预测值与真实值之间平均误差的大小,反映了预测值误差的实际情况,用于评估预测结果和真实数据集的接近程度。其值越小,说明拟合效果越好。
平均绝对误差的表达形式为
MAE 函数示例,其中,真实目标值为100,预测值为-10 000~10000。预测值(Predictions)为100时,MAE 损失(MAE Loss)达到其最小值。损失范围为[0,]。

Sklearn提供了mean_absolute_error函数用于求平均绝对误差,格式如下:
sklearn.metrics.mean_absolute_error(y_true, y_pred)【参数说明】
- y_true:真实值。
- y_pred:预测值。
2.2 MSE
均方误差(Mean Squared Error,MSE)又称L2损失,是最常用的回归损失评估指标,反映了观测值与真值偏差的平方之和与观测次数的比值,是预测值与真实值之差的平方之和的平均值。其值越小,说明拟合效果越好。
均方误差的表达形式为
MSE 函数示例,其中,真实目标值为100,预测值为一10 000~10 000。预测值(Predictions)为100时,MSE 损失(MSE Loss)达到其最小值。损失范围为[0,]。

Sklearn提供了mean_squared_error函数用于求均方误差,格式如下:
sklearn.metrics.mean_squared_error(y_true, y_pred)【参数说明】
- y_true:真实值。
- y_pred:预测值。
2.3 RMSE
RMSE 是根均方误差(Root Mean Square Error),其取值范围为[0,+)。其表达为:
取均方误差的平方根可以使得量纲一致,这对于描述和表示有意义。
2.4 R2分数
分类问题用F1_score进行评价。在回归问题中,相应的评价标准是决定系数(coefficient of determination),又称为分数,简称
。使用同一算法模型解决不同的问题,由于数据集的量纲不同,MSE,RMSE 等指标不能体现模型的优劣。而
分数的取值范围是[0,1],越接近1,表明模型对数据拟合较好;越接近0,表明模型拟合较差。
Sklearn提供了r2_score函数用于表示决定系统,格式如下:
sklearn.metrics.r2_score(y_true, y_pred)回归损失示例:
import numpy as np
from sklearn import metrics
from sklearn.metrics import r2_score
y_true = np.array([1.0,5.0,4.0,3.0,2.0,5.0,-3.0])
y_pred = np.array([1.0,4.5,3.5,5.0,8.0,4.5,1.0])
#mae
print("MAE:", metrics.mean_absolute_error(y_true, y_pred))
#MSE
print('MSE:', metrics.mean_squared_error(y_true, y_pred))
#RMSE
print('RMSE:', np.sqrt(metrics.mean_squared_error(y_true, y_pred)))
#R Squared
print('R Square:', r2_score(y_true, y_pred))【运行结果】

2.5 Huber损失
均方损失(MSE)对于异常点进行较大惩罚,不够健壮。平均绝对损失(MAE)对于较多异常点表现较好,但在y-f(x)=0处不连续可导,不容易优化。
L1损失函数与L2损失函数对比如表所示。
| L1损失函数 | L2损失函数 |
| 健壮 | 不够健壮 |
| 不稳定解 | 稳定解 |
| 可能多个解 | 总是一个解 |
Huber 损失是对MSE 和MAE 缺点的改进。
当|y-f(x)|小于指定的值时,Huber 损失变为平方损失;
当大于值时,Huber 损失类似于绝对值损失。回归损失函数对比如图所示。

sklearn.linear_model提供了HuberRegressor函数用于Huber损失,格式如下:
huber = HuberRegressor()示例:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import HuberRegressory_train = np.array([368, 340, 376, 954, 331, 856])
x_train = np.array([1.7, 1.5, 1.3, 5, 1.3, 2.2])
plt.scatter(x_train, y_train, label = 'Train Samples')
x_train = x_train.reshape(-1,1)#reshape(-1,1)转换成1列:
#L2损失函数
lr = LinearRegression()
lr.fit(x_train, y_train)
a = range(1,6)
b = [lr.intercept_ + lr.coef_[0] * i for i in a]#.intercept_截距;.coef_权重
plt.plot(a, b, 'r', label = "Train Samples")
#Huber 损失函数
huber = HuberRegressor()
huber.fit(x_train, y_train)
a = range(1,6)
b = [huber.intercept_ + huber.coef_[0] * i for i in a]
plt.plot(a, b, 'b', label = 'Train Samples')print('L2损失函数:y = {:.2f} +{:.2f} * x'.format(lr.intercept_, lr.coef_[0]))print("huber 损失函数:y = {:.2f} +{:.2f} * x".format(huber.intercept_, huber.coef_[0]))【运行结果】

3、分类损失
3.1常见损失函数
- 平方损失函数。
- 绝对误差损失函数。
- 0-1损失函数。
- 对数损失函数。
- 铰链损失函数。
3.2 平方损失函数
平方损失(squared loss)函数计算实际值和预测值之差的平方,又称为L2损失函数,一般用在线性回归中,可以理解为最小二乘法。其表达形式为
相应的成本函数是这些平方误差的平均值(MSE)。
3.3 绝对误差损失函数
绝对误差损失(absolute error loss)函数计算预测值和实际值之间的距离,用在线性回归中。绝对误差损失函数也称为L1损失函数。绝对误差损失函数的表达形式为
相应的成本函数是这些绝对误差的平均值(MAE)。
3.4 0-1损失函数
0-1损失(zero-one loss)函数当预测标签和真实标签一致时返回0,否则返回1。0-1损失函数的表达形式为
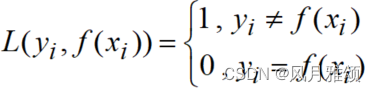
Sklearn 提供了zero_one_loss函数,格式如下:
sklearn.metrics.zero_one_loss(y_true, y_pred, normalize)【参数说明】
- y_true:真实值。
- y_pred:预测值。
- normalize:取值为True,返回平均损失;取值为 False,返回损失之和。
示例:
from sklearn.metrics import zero_one_loss
import numpy as np
#二分类问题
y_pred = [1,2,3,4]
y_true = [2,2,3,4]
print(zero_one_loss(y_true, y_pred))
print(zero_one_loss(y_true, y_pred, normalize = False))
#多分类问题
print(zero_one_loss(np.array([[0,1],[1,1]]), np.ones((2,2))))
print(zero_one_loss(np.array([[0,1],[1,1]]), np.ones((2,2)), normalize = False))3.5 对数损失函数
当预测值和实际值的误差符合高斯分布,使用对数损失(logarithmic loss)函数,其主要应用在逻辑回归中。对数损失函数的数学表达式是如下分段函数:

当y=1时,表示真实值属于这个类别;
当y=0时,表示真实值不属于这个类别。
Sklearn提供了log_loss函数,语法如下:
sklearn.metrics.log_loss(y_true,y_pred)示例:
from sklearn.metrics import log_loss
y_true = [0,0,1,1]
y_pred = [[0.9, 0.1], [0.8, 0.2], [0.3, 0.7], [0.01, 0.99]]
print(log_loss(y_true, y_pred))3.6 铰链损失函数
铰链损失函数(hinge Loss)函数用于评价支持向量机。Sklearn 提供了hinge_loss函数,格式如下:
sklearn.metrics.hinge_loss(y_true,y_pred)
示例:
from sklearn import svm
from sklearn.metrics import hinge_loss
x = [[0],[1]]
y = [-1, 1]
est = svm.LinearSVC(random_state = 0)
print(est.fit(x, y))
pred_decision = est.decision_function([[-2], [3], [0.5]])
print(pred_decision)
print(hinge_loss([-1, 1, 1], pred_decision))【运行结果】
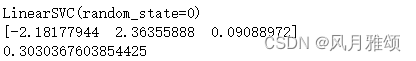
相关文章:
机器学习——损失函数
【说明】文章内容来自《机器学习——基于sklearn》,用于学习记录。若有争议联系删除。 1、简介 损失函数(loss function)又称为误差函数(error function),是衡量模型好坏的标准,用于估量模型的预测值与真实值的不一致程度,是一个…...
)
C#多线程(补充)
C#多线程(补充) C# 多线程的补充在C#中使用多线程1. Thread类2. 线程池3. Parallel类4. Task类启动任务接收任务的返回值同步调用指定连续任务任务的层次结构 5. BackgroundWorker控件 C# 多线程的补充 在C#中使用多线程 1. Thread类 使用Thread类通过…...
关于苹果iOS 16:揭开伪装成飞机模式的隐形蜂窝接入漏洞的动态情报
一、基本内容 在日常生活中,网络威胁不断演变,给个人和组织带来了一系列重大挑战。网络犯罪分子使用的一种最常见的、最具破坏性的方法之一就是网络钓鱼。这种攻击方式通过电子邮件、短信或其他通讯渠道冒充可信实体,诱使个人泄露敏感信息&am…...

Python+OpenCV 零基础学习笔记(4-5):计算机图形基础+Python相对文件路径+OpenCV图像+OpenCV视频
文章目录 相关链接运行环境前言计算机图形OpenCV简单使用图形读取文件读取可能会出现的问题:路径不对解决方案其它路径问题解决方案 图像显示保存OpenCV视频视频素材如何获取?简单视频读取 相关链接 【2022B站最好的OpenCV课程推荐】OpenCV从入门到实战 …...

【C++篇】讲解Vector容器的操作方法
文章目录 🍔vector容器概念🌹操作方法⭐赋值操作⭐容量和大小⭐插入和删除⭐数据存取 🍔vector容器概念 vector 是 C 标准库中的一个容器,它提供了一种动态数组的实现。vector 容器可以存储任意类型的元素,并且可以根…...

桥接模式-举例
概叙:桥接模式用一种巧妙的方式处理多层继承存在的问题, 用抽象关联取代了传统的多层继承, 将类之间的静态继承关系转换为动态的对象组合关系, 使得系统更加灵活,并易于扩展, 同时有效控制了系统中类的个数…...
记录)
FreeBSD下安装Jenkins(软件测试集成工具)记录
简要介绍Jenkins 简而言之,Jenkins 是领先的开源自动化服务器。它使用 Java 构建,提供了 1,800 多个插件来支持几乎任何事情的自动化,因此人类可以将时间花在机器无法完成的事情上。 主要目的: 持续、自动地构建/测试软件项目。…...

数据结构学习 Leetcode474 一和零
关键词:动态规划 01背包 一个套路: 01背包:空间优化之后dp【target1】,遍历的时候要逆序遍历完全背包:空间优化之后dp【target1】,遍历的时候要正序遍历 目录 题目: 思路: 复杂…...
VS配置PCO相机SDK环境
VS配置PCO相机SDK环境 概述:最近要用到一款PCO相机,需要协调其他部件实现一些独特的功能。因此需要用到PCO相机的SDK,并正确配置环境。良好的环境是成功的一半。其SDK可以在官网下载,选择对应版本的安装即可。这里用的是pco.cpp.1.2.0 Windows,VS 2022 专业版。 链接: P…...

六、Redis 分布式系统
六、Redis 分布式系统 六、Redis 分布式系统6.1 数据分区算法6.1.1 顺序分区6.1.2 哈希分区 6.2 系统搭建与运行6.2.1 系统搭建6.2.2 系统启动与关闭 6.3 集群操作6.3.1 连接集群6.3.2 写入数据6.3.3 集群查询6.3.4 故障转移6.3.5 集群扩容6.3.6 集群收缩 6.4 分布式系统的限制…...

Unity相机跟随角色移动
相机跟随角色移动 使用LateUpdate();方法,根据角色移动而进行跟随,固定角度,类似2.5D视角。 需要将相机放到一个空对象,将角度调节好,挂载组件,将角色对象放入组件中,调整moveTime设…...
Lua的垃圾回收机制详解
Lua 是一种轻量级的编程语言,广泛用于嵌入到其他应用程序中,尤其是在游戏开发领域。Lua 的内存管理机制采用了自动垃圾收集(Garbage Collection)的方法。以下是Lua内存管理的一些关键方面: 垃圾收集原理概述 Lua 使用…...
java设计模式学习之【解释器模式】
文章目录 引言解释器模式简介定义与用途实现方式 使用场景优势与劣势在Spring框架中的应用表达式解析示例代码地址 引言 在我们的日常生活中,语言的翻译和理解是沟通的关键。每种语言都有自己的语法规则,而翻译人员和计算机程序需要理解并遵循这些规则来…...
Unity中Shader旋转矩阵(四维旋转矩阵)
文章目录 前言一、围绕X轴旋转1、可以使用上篇文章中,同样的方法推导得出围绕X轴旋转的点阵。2、求M~rotate~ 二、围绕Y轴旋转1、可以使用上篇文章中,同样的方法推导得出围绕Y轴旋转的点阵。2、求M~rotate~ 三、围绕Z轴旋转1、可以使用上篇文章中&#x…...

【大数据】Centos 7安装教程
一、下载VMware 大家可以通过浏览器进入官网下载VMware,下载后打开VMware进行安装。 二、下载镜像的方式 1、进入Centos官网下载 2、进入阿里云、华为云镜像站下载 以阿里云为例,这里有很多,比如ubuntu、centos,点进去就可以选…...
2024 年 11 款最佳 Android 数据恢复软件应用
Android 设备上的数据丢失可能是一种令人痛苦的经历,通常会导致不可替代的信息瞬间消失。 意外删除、系统崩溃或格式错误都可能发生,重要数据的丢失可能会扰乱日常工作并影响您的工作效率。 幸运的是,技术进步带来了多种恢复解决方案&…...

Redis 核心知识总结
Redis 核心知识总结 认识 Redis 什么是 Redis? Redis 是一个由 C 语言开发并且基于内存的键值型数据库,对数据的读写操作都是在内存中完成,因此读写速度非常快,常用于缓存,消息队列、分布式锁等场景。 有以下几个特…...
Android Jetpack之用Room+ViewModel+LiveData实现增删改查数据(createFromAsset())
文章目录 一、Room简介二、用RoomViewModelLiveData增删改查数据三、下载源码 一、Room简介 Room是Google推出的数据库框架,是一个 ORM (Object Relational Mapping)对象关系映射数据库、其底层还是对SQLite的封装。 Room包含三个主要组件: 数据库类&…...
 语句-读取的数据进行排序)
MySQL ORDER BY(排序) 语句-读取的数据进行排序
MySQL ORDER BY(排序) 语句 我们知道从 MySQL 表中使用 SELECT 语句来读取数据。 如果我们需要对读取的数据进行排序,我们就可以使用 MySQL 的 ORDER BY 子句来设定你想按哪个字段哪种方式来进行排序,再返回搜索结果。 MySQL ORDER BY(排序) 语句可以…...

【ES】es介绍
倒排索引(Inverted Index)和正排索引(Forward Index) 正排索引是一种以文档为单位的索引结构,它将文档中的每个单词或词组与其所在的文档进行映射关系的建立。正排索引通常用于快速检索指定文档的内容,可以…...

【免费下载】 Cadence Allegro 多层板设计经典案例分享:助你快速提升设计技能
Cadence Allegro 多层板设计经典案例分享:助你快速提升设计技能 项目介绍 在电子设计领域,Cadence Allegro 是一款广泛使用的 PCB 设计软件,尤其在多层板设计中表现出色。为了帮助广大工程师和学习者更好地掌握 Allegro 的使用技巧࿰…...

告别本地调试:手把手教你将Flink Java应用打包成JAR并提交到YARN集群
从IDE到YARN集群:Flink Java应用全流程部署实战指南 当你在IntelliJ IDEA中完成了Flink流处理程序的调试,看着本地控制台输出的结果一切正常时,接下来的挑战才刚刚开始——如何将这个精心编写的程序部署到真实的分布式环境中运行?…...

别再浪费主板上的PCIE插槽了!手把手教你用VL805芯片打造高速USB3.0扩展坞
释放主板潜能:基于VL805芯片的USB3.0扩展方案实战指南 当你的工作台摆满外设却苦于主板接口不足时,那些闲置的PCIE插槽正等待被唤醒。本文将从芯片选型到性能调优,完整呈现如何将一块VL805-QFN68芯片转化为高性能USB3.0扩展方案。 1. 硬件选型…...

初次接触Taotoken从注册到发出第一个API请求的全流程耗时
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初次接触Taotoken从注册到发出第一个API请求的全流程耗时 本文记录了一名新用户从零开始,完成Taotoken平台注册、获取A…...

GANSpace核心原理揭秘:PCA在GAN激活空间中的神奇应用
GANSpace核心原理揭秘:PCA在GAN激活空间中的神奇应用 【免费下载链接】ganspace 项目地址: https://gitcode.com/gh_mirrors/ga/ganspace GANSpace是一项革命性技术,它通过主成分分析(PCA)在生成对抗网络(GAN&…...

基于GAN的AI图像水印移除工具VeoWatermarkRemover实战指南
1. 项目概述:一个开源图像水印移除工具 最近在整理一些老照片和网上下载的素材时,经常被图片上那些碍眼的水印、Logo或者时间戳困扰。手动用PS处理,费时费力,而且对批量操作极不友好。直到我发现了GitHub上一个名为“VeoWatermar…...

为什么选择nxdumptool:Switch游戏备份的完全指南
为什么选择nxdumptool:Switch游戏备份的完全指南 【免费下载链接】nxdumptool Generates XCI/NSP/HFS0/ExeFS/RomFS/Certificate/Ticket dumps from Nintendo Switch gamecards and installed SD/eMMC titles. 项目地址: https://gitcode.com/gh_mirrors/nx/nxdum…...

Julia 中的 One Billion Row Challenge
原文:towardsdatascience.com/the-one-billion-row-challenge-in-julia-bdd19cde58d5?sourcecollection_archive---------9-----------------------#2024-06-05 如果数据科学家决定接受这个任务,他们能学到什么? https://medium.com/vikas.…...

RK3562核心板开发指南:从硬件设计到AI部署的全流程解析
1. 项目概述:从一颗芯片到一套完整的开发资源最近在嵌入式圈子里,RK3562这颗芯片的热度持续攀升。作为瑞芯微面向中高端AIoT和工业应用推出的新一代处理器,它凭借其均衡的CPU/GPU/NPU性能和出色的能效比,吸引了不少开发者的目光。…...

你的STM32调试信息用对了吗?深入对比.axf文件与addr2line.exe的配合之道
STM32调试进阶:解密.axf文件与addr2line的黄金组合 调试嵌入式系统时,最令人沮丧的莫过于设备突然崩溃,而你却对问题源头一无所知。作为一名长期与STM32打交道的开发者,我经历过无数次这样的时刻,直到真正理解了调试信…...