Spark 广播/累加
Spark 广播/累加
- 广播变量
- 普通变量广播
- 分布式数据集广播
- 克制 Shuffle
- 强制广播
- 配置项
- Join Hints
- broadcast
- 累加器
Spark 提供了两类共享变量:广播变量(Broadcast variables)/累加器(Accumulators)
广播变量
创建广播变量的方式:
- 从普通变量创建广播变量 : 由 Driver 分发各 Executors
- 从分布式数据集创建广播变量 : Driver 拉取各 Executors 分区数并合并, 再分发各Executors
普通变量广播
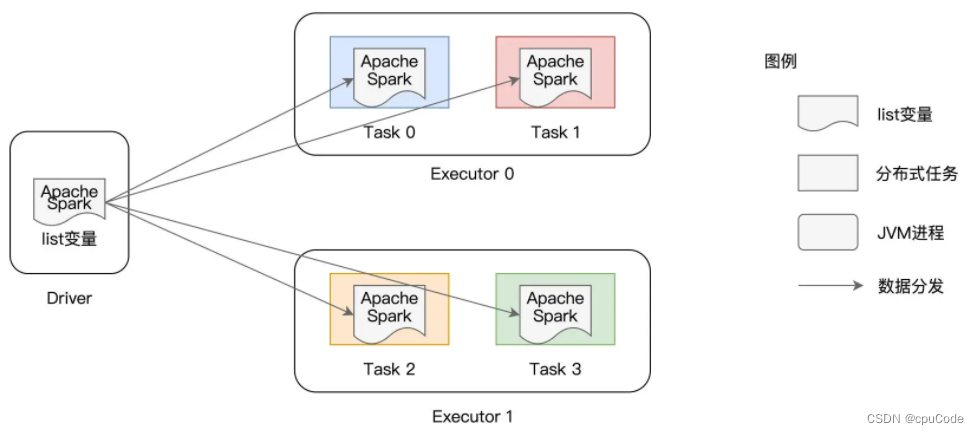
普通变量分发 :
- 普通变量在 Driver 端创建 (非分布式数据集),要把普通变量分发给每个 Task
- 以 Task 粒度分发,当有 n 个 Task,变量就要分发 n 次
- 在同个 Executor 内部,多个不同的 Task 多次重复缓存同样的内容 , 对内存资源浪费
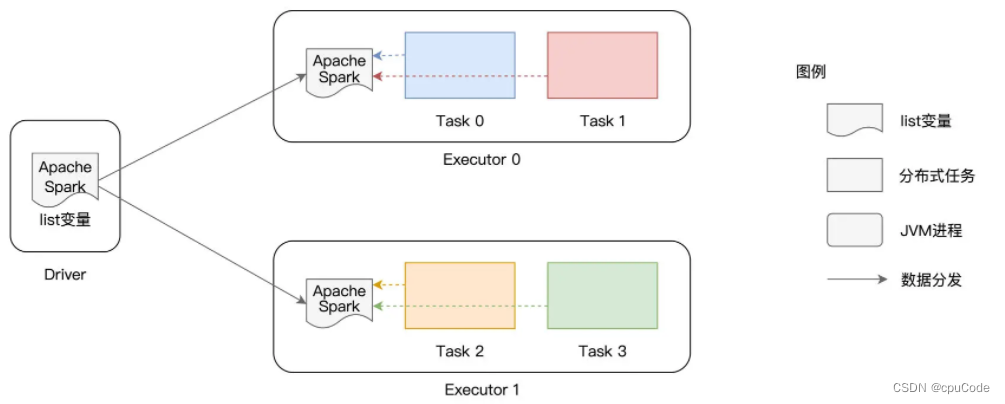
广播变量分发:
- 以 Executors 粒度分发,同个 Executor 的 各 Tasks 互相拷贝。即:变量分发数 = Executors 数
普通变量广播:
val list: List[String] = List("Apache", "Spark")val bc = sc.broadcast(list)
分布式数据集广播
创建分布式数据集广播:
val userFile: String = "hdfs://ip:port/rootDir/userData"
val df: DataFrame = spark.read.parquet(userFile)val bc_df: Broadcast[DataFrame] = spark.sparkContext.broadcast(df)
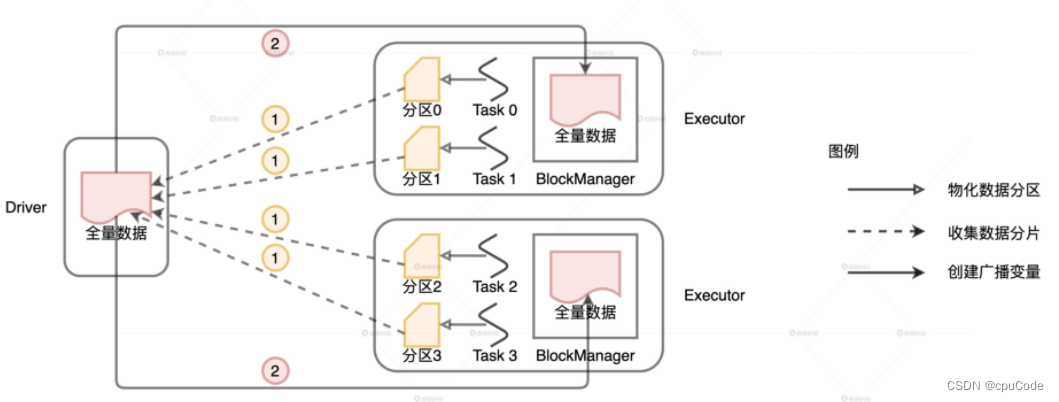
分布式数据集广播过程 :
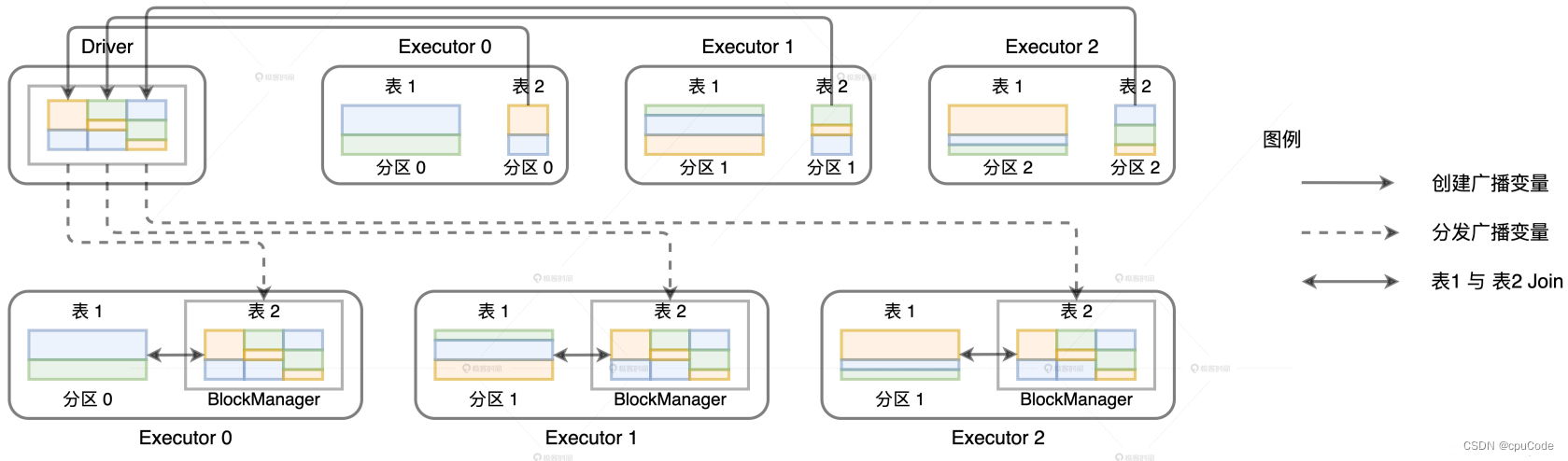
- Driver 从所有的 Executors 拉取这些数据分区,再在本地构建全量数据
- Driver 把合并的全量数据分发给各个 Executors
- Executors 收到数据后,缓存到存储系统的 BlockManager
克制 Shuffle
无优化时,默认用 Shuffle Join
val transactionsDF: DataFrame = _
val userDF: DataFrame = _transactionsDF.join(userDF, Seq("userID"), "inner")
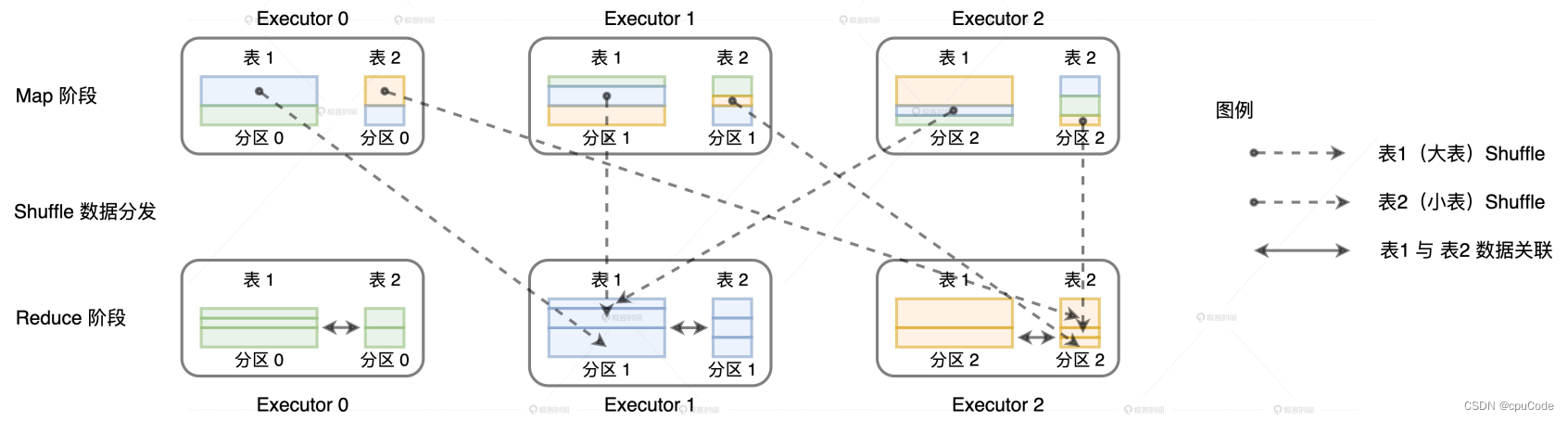
Shuffle Join 的过程 :
- 对关联俩表分别进行 Shuffle
- Shuffle 的分区规则:先对 Join keys 计算哈希值,再对哈希值进行分区数取模
- Shuffle 后,同 key 的数据会在同个 Executors
- Reduce Task 对 同 key 的数据进行关联
优化代码:
import org.apache.spark.sql.functions.broadcastval transactionsDF: DataFrame = _
val userDF: DataFrame = _val bcUserDF = broadcast(userDF)
transactionsDF.join(bcUserDF, Seq("userID"), "inner")
广播过程:
- Driver 从所有 Executors 收集 userDF 的所有数据分片,再在本地汇总数据
- 给每个 Executors 都发送一份全量数据,各自在本地关联
- 利用广播变量 ,就能避免 Shuffle
强制广播
广播注意点:
- 创建广播变量越大,网络开销和 Driver 内存也就越大。当广播变量大小 > 8GB,就会直接报错
- Broadcast Joins 不支持全连接(Full Outer Joins)
- 左连接(Left Outer Join)时,只能广播右表
- 右连接(Right Outer Join)时,只能广播左表
配置项
两张 Join 表,只要其中一张表的尺寸 < 10MB,就会采用 Broadcast Joins 做数据关联
# 采用 Broadcast Join 实现的最低阈值
spark.sql.autoBroadcastJoinThreshold 10m
数据在存储/内存大小差异的原因:
- 为了存储/访问效率,数据采用 Parquet/ORC 格式进行落盘
- JVM 一般需要比数据原始更大的内存空间来存储对象
准确预估表在内存的大小:
- 把表缓存到内存,如: DataFrame/Dataset.cache
- 读取执行计划的统计数据
val df: DataFrame = _
df.cache.countval plan = df.queryExecution.logical
val estimated: BigInt = spark.sessionState.executePlan(plan).optimizedPlan.stats.sizeInBytes
Join Hints
Join Hints :在开发中用特殊的语法,告知 Spark SQL 运行时采用这种 Join
val table1: DataFrame = spark.read.parquet(path1)
val table2: DataFrame = spark.read.parquet(path2)table1.createOrReplaceTempView("t1")
table2.createOrReplaceTempView("t2")val query: String = "select /*+ broadcast(t2) */ * from t1 inner join t2 on t1.id = t2.id"val queryResutls: DataFrame = spark.sql(query)
DataFrame 的 DSL 语法中使用 Join Hints :
table1.join(table2.hint("b"roadcast"), Seq("key"), "inner")
broadcast
广播数据表 :
import org.apache.spark.sql.functions.broadcasttable1.join(broadcast(table2), Seq(“key”), “inner”)
广播设置要点:以广播阈值配置为主,以强制广播为辅
累加器
累加器的作用:全局计数(Global counter)
SparkContext 提供了 3 种累加器 :
- longAccumulator:Long 类型的累加器
- doubleAccumulator :对 Double 类型的数值做全局计数
- collectionAccumulator :定义集合类型的累加器
累加器在 Driver 端定义,在 RDD 算子中调用 add 进行累加。最后在 Driver 端调用 value ,就能获取全局计数结果
// 定义 Long 类型的累加器
val ac = sc.longAccumulator("Empty string")def f(x: String): Boolean = {if(x.equals("")) {// 当遇到空字符串时,累加器加 1ac.add(1)return false} else {return true}
} //用 f 对 RDD 进行过滤
val cleanWordRDD: RDD[String] = wordRDD.filter(f)// 作业执行完毕,通过调用 value 获取累加器结果
ac.value
相关文章:
Spark 广播/累加
Spark 广播/累加广播变量普通变量广播分布式数据集广播克制 Shuffle强制广播配置项Join Hintsbroadcast累加器Spark 提供了两类共享变量:广播变量(Broadcast variables)/累加器(Accumulators) 广播变量 创建广播变量…...

飞天云动,站在下一个商业时代的门口
ChatGPT的爆火让AIGC再度成为热词,随之而来的是对其商业化的畅想——不是ChatGPT自身如何盈利,而是它乃至整个AIGC能给现在的商业环境带来多大改变。 这不由得令人想起另一个同样旨在改变世界的概念,元宇宙。不同的是,元宇宙更侧…...
上海分时电价机制调整对储能项目的影响分析
安科瑞 耿敏花 2022年12月16日,上海市发改委发布《关于进一步完善我市分时电价机制有关事项的通知》(沪发改价管〔2022〕50号)。通知明确上海分时电价机制,一般工商业及其他两部制、大工业两部制用电夏季(7、8、9月)和冬季&#x…...

产品新人如何快速上手工作
三百六十行,行行出产品经理:上至封神的乔布斯,下至卖鸡蛋罐饼的阿姨,他们对如何打造自己的产品都会有一套完整的产品思路,这也是为什么说“人人都是产品经理”。这个看似光鲜的“经理”有时也会被戏称产品汪࿰…...
Linux: ARM GIC仅中断CPU 0问题分析
文章目录1. 前言2. 分析背景3. 问题4. 分析4.1 ARM GIC 中断芯片简介4.1.1 中断类型和分布4.1.2 拓扑结构4.2 问题根因4.2.1 设置GIC SPI中断的CPU亲和性4.2.2 GIC初始化:缺省的CPU亲和性4.2.2.1 boot CPU亲和性初始化流程4.2.2.1 其它非 boot CPU亲和性初始化流程5…...
)
第20篇:Java运算符全面总结(系列二)
目录 4、逻辑运算符 4.1 逻辑运算符 4.2 代码示例 5、赋值运算符 5.1 赋值运算符...
)
OpenCV4.x图像处理实例-OpenCV两小时快速入门(基于Python)
OpenCV两小时快速入门(基于Python) 文章目录 OpenCV两小时快速入门(基于Python)1、OpenCV环境安装2、图像读取与显示3、图像像素访问、操作与ROI4、图像缩放5、几何变换5.1 平移5.2 旋转6、基本绘图6.1 绘制直线6.2 绘制圆6.3 绘制矩形6.4 绘制文本7、剪裁图像8、图像平滑与…...

【Git】Mac忽略.DS_Store文件
我们在github上经常看到某些仓库里面包含了.DS_Store文件,或者某些sdk的压缩包里面可以看到,这都是由于随着git的提交把这类文件也提交到仓库,压缩也是一样,压缩这个先留着后面处理。 Mac上的.DS_Store文件 .DS_Store 文件&#…...
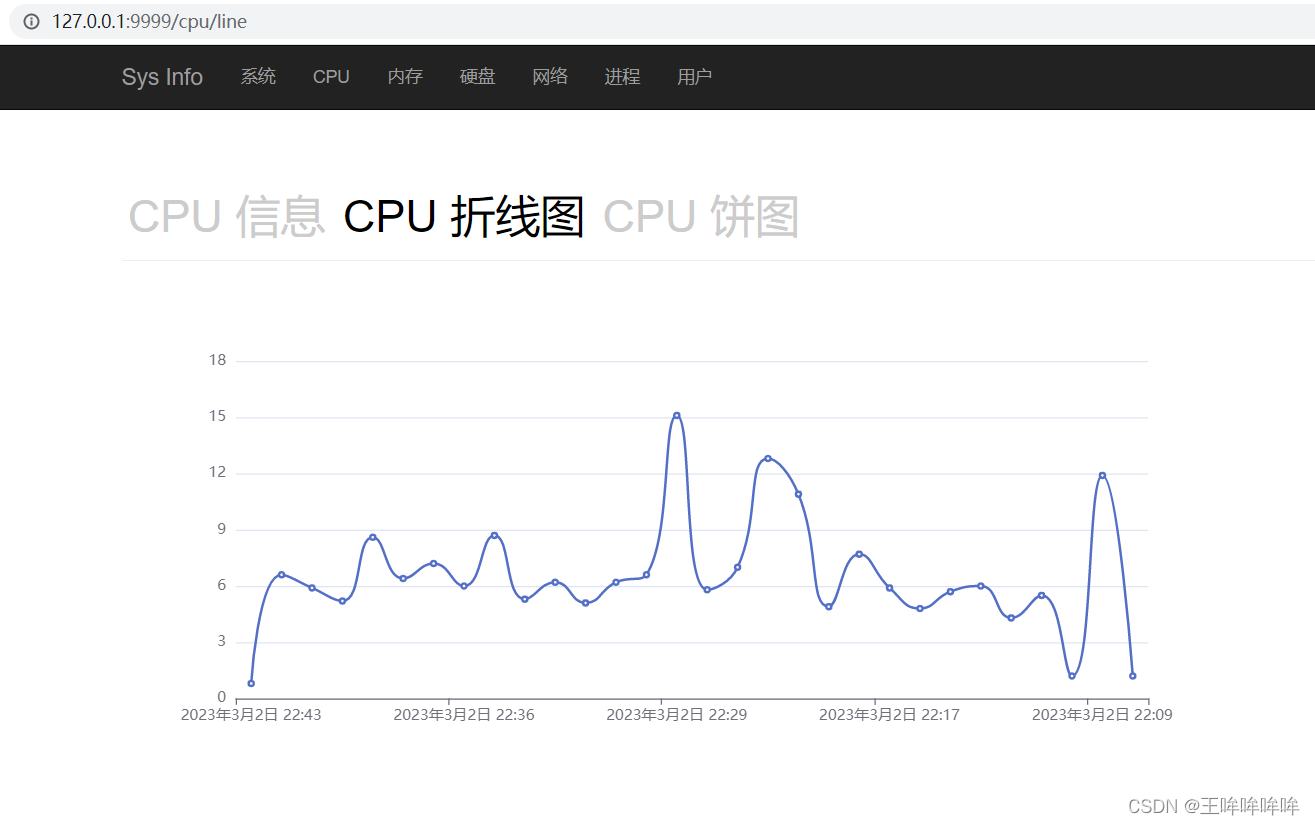
12.2 基于Django的服务器信息查看应用(CPU信息)
文章目录CPU信息展示图表展示-视图函数设计图表展示-前端界面设计折线图和饼图展示饼图测试折线图celery和Django配合实现定时任务Windows安装redis根据数据库中的数据绘制CPU折线图CPU信息展示 图表展示-视图函数设计 host/views.py def cpu(request):logical_core_num ps…...

【软件测试】接口测试总结
本文主要分为两个部分: 第一部分:主要从问题出发,引入接口测试的相关内容并与前端测试进行简单对比,总结两者之前的区别与联系。但该部分只交代了怎么做和如何做?并没有解释为什么要做? 第二部分࿱…...

代码随想录算法训练营第52天 || 300.最长递增子序列 || 674. 最长连续递增序列 || 718. 最长重复子数组
代码随想录算法训练营第52天 || 300.最长递增子序列 || 674. 最长连续递增序列 || 718. 最长重复子数组 300.最长递增子序列 题目介绍 给你一个整数数组 nums ,找到其中最长严格递增子序列的长度。 子序列 是由数组派生而来的序列,删除(或…...
gitblit 安装使用
1 安装服务端 简而言之:需要安装 java,gitblit, git 三个软件 Windows 10环境使用Gitblit搭建局域网Git服务器 前言 安装Java并配置环境安装gitblit并配置启动gitblit为windows服务使用gitblit创建repository并管理用户 1.1 安装Java并配…...

使用 TensorFlow、Keras-OCR 和 OpenCV 从技术图纸中获取信息
简单介绍输入是技术绘图图像。对象检测模型获取图像后对其进行分类,找到边界框,分配维度,计算属性。示例图像(输入)分类后,找到“IPN”部分。之后,它计算属性,例如惯性矩。它适用于不…...

ESP32设备驱动-GUVA-S12SD紫外线检测传感器驱动
GUVA-S12SD紫外线检测传感器驱动 文章目录 GUVA-S12SD紫外线检测传感器驱动1、GUVA-S12SD介绍2、硬件准备3、软件准备4、驱动实现1、GUVA-S12SD介绍 GUVA-S12SD 紫外线传感器芯片适用于检测太阳光中的紫外线辐射。 它可用于任何需要监控紫外线量的应用,并且可以简单地连接到任…...

WIN7下 program file 权限不足?咋整?!!
在WIN7下对Program Files目录的权限问题 [问题点数:40分,结帖人mysunck] 大部分人说要使用manifest,但是其中一个人说: “安装程序要求管理员很正常,你的程序可以在programfiles,但用户数据不能放那里,因…...
119.(leaflet篇)文字碰撞
听老人家说:多看美女会长寿 地图之家总目录(订阅之前建议先查看该博客) 文章末尾处提供保证可运行完整代码包,运行如有问题,可“私信”博主。 效果如下所示: 下面献上完整代码,代码重要位置会做相应解释 <!DOCTYPE html> <html>...

cuda编程以及GPU基本知识
目录CPU与GPU的基本知识CPU特点GPU特点GPU vs. CPU什么样的问题适合GPU?GPU编程CUDA编程并行计算的整体流程CUDA编程术语:硬件CUDA编程术语:内存模型CUDA编程术语:软件线程块(Thread Block)网格(…...

Python 机器学习/深度学习/算法专栏 - 导读目录
目录 一.简介 二.机器学习 三.深度学习 四.数据结构与算法 五.日常工具 一.简介 Python 机器学习、深度学习、算法主要是博主从研究生到工作期间接触的一些机器学习、深度学习以及一些算法的实现的记录,从早期的 LR、SVM 到后期的 Deep,从学习到工…...
Springboot怎么实现restfult风格Api接口
前言在最近的一次技术评审会议上,听到有同事发言说:“我们的项目采用restful风格的接口设计,开发效率更高,接口扩展性更好...”,当我听到开头第一句,我脑子里就开始冒问号:项目里的接口用到的是…...

Jetpack Compose 深入探索系列六:Compose runtime 高级用例
Compose runtime vs Compose UI 在深入讨论之前,非常重要的一点是要区分 Compose UI 和 Compose runtime。Compose UI 是 Android 的新 UI 工具包,具有 LayoutNodes 的树形结构,它们稍后在画布上绘制其内容。Compose runtime 提供底层机制和…...
)
别再只盯着大模型了!手把手教你用Python+卫星数据做农业产量预测(附代码)
用Python和卫星数据构建农业产量预测模型:从数据获取到结果可视化全流程指南 当我们在谈论智慧农业时,往往容易陷入对大模型的盲目崇拜。但实际上,一套简单实用的数据科学流程,配合公开免费的卫星遥感数据,就能为中小农…...

高效构建智能媒体库:MetaTube插件全方位应用指南
高效构建智能媒体库:MetaTube插件全方位应用指南 【免费下载链接】jellyfin-plugin-metatube MetaTube Plugin for Jellyfin/Emby 项目地址: https://gitcode.com/gh_mirrors/je/jellyfin-plugin-metatube MetaTube是一款专为Jellyfin和Emby设计的开源元数据…...

【项目实战】ESP8266 WiFi模块从零接入物联网 - 硬件连接、固件烧录与云端通信
1. ESP8266 WiFi模块入门指南 第一次拿到ESP8266这个小玩意儿时,我完全没想到它能在物联网领域掀起这么大风浪。这个比硬币大不了多少的模块,内置了完整的WiFi功能,价格还不到一杯奶茶钱。记得去年帮学弟调试毕业设计时,我们用ESP…...

AMD SMT补丁实战指南:突破《赛博朋克2077》CPU性能瓶颈
AMD SMT补丁实战指南:突破《赛博朋克2077》CPU性能瓶颈 【免费下载链接】CyberEngineTweaks Cyberpunk 2077 tweaks, hacks and scripting framework 项目地址: https://gitcode.com/gh_mirrors/cy/CyberEngineTweaks 《赛博朋克2077》自发布以来,…...

【开题答辩全过程】以 基于Android的收支记账管理系统为例,包含答辩的问题和答案
个人简介一名14年经验的资深毕设内行人,语言擅长Java、php、微信小程序、Python、Golang、安卓Android等开发项目包括大数据、深度学习、网站、小程序、安卓、算法。平常会做一些项目定制化开发、代码讲解、答辩教学、文档编写、也懂一些降重方面的技巧。感谢大家的…...

Keil软件仿真中STM32F407卡在HSE就绪问题的Debugconfig.ini配置指南
1. 为什么STM32F407软件仿真会卡在HSE就绪? 最近在用Keil MDK调试STM32F407项目时,发现一个奇怪现象:软件仿真总是卡在"Wait till HSE is ready"这个地方,死活进不了main函数。这个问题困扰了我整整两天,最后…...

终极LoRaWAN服务器搭建指南:如何快速构建你的私有物联网网络
终极LoRaWAN服务器搭建指南:如何快速构建你的私有物联网网络 【免费下载链接】lorawan-server Compact server for private LoRaWAN networks 项目地址: https://gitcode.com/gh_mirrors/lo/lorawan-server 你是否想拥有一个完全可控的LoRaWAN物联网平台&…...

如何快速掌握NoteGen AI笔记:新手入门完整指南
如何快速掌握NoteGen AI笔记:新手入门完整指南 【免费下载链接】note-gen 一款专注于记录和写作的跨端 AI 笔记应用。 项目地址: https://gitcode.com/GitHub_Trending/no/note-gen 在信息爆炸的时代,高效记录和管理知识已成为现代人的刚需。Note…...

n8n汉化踩坑全记录:从Docker界面到工作流编辑器的完整中文配置指南
n8n全栈汉化实战:从Docker环境到工作流编辑器的深度本地化方案 当德国开发者Jan Oberhauser在2019年将n8n开源时,可能没想到这个发音为"n-eight-n"的工具会成为自动化领域的新宠。作为一款基于节点连接的可视化编程平台,n8n让非技术…...

基于Koopman算子的四旋翼无人机MPC控制开发:一种创新的数据驱动方法
318-一种基于Koopman算子的模型预测控制MPC控制四旋翼无人机开发 简介: 一种基于Koopman算子和扩展动态模式分解(EDMD)的四旋翼无人机学习和控制的新型数据驱动方法。 基于欧拉角(表示方向)等传统方法构建EDMD的观测器已知涉及奇异性。 为了解决这个问题,…...