小样本学习idea(不断更新)
在此整理并记录自己的思考过程,其中不乏有一些尚未成熟或者尚未实现的idea,也有一些idea实现之后没有效果或者正在实现,当然也有部分idea已写成论文正在投稿,都是自己的一些碎碎念念的思考,欢迎交流。
研一上学期
9.18现有思路:
1.用pretrain好的MAE,采用不同的遮挡方式(或者遮挡比例,固定或者不固定,随机或者block-wise),生成不同遮挡方式下的特征,相当于单张图片的样本扩充。
2.采用对比学习的方式对生成的图片进行训练。
9.19晚上想法:
图片相对于自然语言来说有很多冗余的信息,那么这些冗余的信息一定是没用的信息吗?我所做的工作就是充分的利用这些看似冗余的信息,只用这些信息的一部分去生成同一张图片相似的特征,这些特征相对于原图来说是和原图很像的,比我我给你一张老虎的图片,我变来变去都不会变成狗,生成的图片肯定也是个老虎。
9.20中午想法:
用MAE去生成特征,只训练MLP层。
或者我只用MAE生成图片,当做样本放到Swim中去。
9.21下午:
我们实现的网络能将看过的图片生成与之近似的图片,类似于当一个小孩看见一个狮子,在他的脑海里肯定不是准确的无比清晰的记忆,但是他能在他再次看到狮子的时候,一眼就认出来这是狮子,这就很符合小孩子看到新事物的原理。
9.21晚上:
对于query要使用不同的特征生成的encoder,采用对比学习的思想。或者采用相同的encoder,也采用MAE然后生成很多个,最后获得一个总的评分。
也就是说我只需要训练最后的MLP层,调整生成的特征图的哪个与我positive更像。
是不是说如果生成10张图片类似的图片要用到10个MAE才能使这些特征是类似的?????
9.22早上
研究训练集,研究总体的训练过程
9.22晚上
可以把同一张图片复制很多份输入到mae模型中得到不同的表示。
9.23上午
直接先用MAE做数据增强看效果
9.26下午:
我可以利用遮挡的方式和gan一样对同一张图片生成很多的与之类似的图片,但是没有必要,我只需要生成特征,同时我生成的不是普通的特征,是经过学习的与原图相似的特征。
9.27晚上:
对十张图片加权之后变成一张图片,然后使用建新的结构
我不是单独的在图像生成数据增强上进行改进,也不是单独对特征提取阶段进行改进,我是将两个阶段进行融合自适应的去生成特征。
有两处对比学习的loss:对比生成图像和原图像的loss还有正类和负类之间的loss
我生成的这个特征代表更多的与这张特征图同类的的图片。
10.2上午:
最终确定了两个方案:
方案一:
只使用预训练好的MAE作为特征提取器,采用将随机遮挡固定的方式生成embedding,相当于起到扩充数据集的作用,防止因数据少带来的过拟合。
方案二:
对同一张图片使用多次MAE,将MAE的后几层的参数设置为可以更新,目的是去学习与原图相似的embedding,解决过拟合。
10.3想法:
两个对比学习的损失:
1.生成的embedding与原图的对比学习的损失。
2.positive之间的对比学习的损失。
这两个loss可以写在一个函数里,相当于对原loss的修改(与query变成patch的那篇论文类似)
还需要解决的:把MAE的随机遮挡变成固定遮挡,形成可学习的MAE的encoder。
MAE的得到的特征并不可靠,需不需需要设置一个置信度来筛选得到的特征???
10.4想法:
方案三:用MAE生成重构图片,直接放到原型网络的训练集中。
方案四:用原型网络线性探测后正确的结果,放到MAE的训练集中。
也可以直接用线性探测好的特征。
方案五:可不可以利用Rethinking Few-Shot Image Classification: a Good Embedding Is All You Need?的训练方式,改变元学习的训练策略?
10.5想法:
固定的75%比例的遮挡。
利用mae做跨域,训练的时候训练出一个特征提取器,测试的时候生成support中的图片进行扩充,解决样本少的问题。
mae能实现图像复原的主要原因是对遮挡patch的还原,得益于transformer强大的全局建模的能力
二分图匹配是一对一的匹配,其约束性更强,能不能重新划分小样本的episodic,以达到更好的效果?
10.6晚上想法:
要不要试一试其他的度量的方式?
我现在要做的是扩充这个子空间,使得这个子空间的的同时泛化能力更强,同时使用对比学习的方式让这个子空间更为精确。
原型网络是不是并不能发挥出扩充support set的优势?
尝试其他的利用子空间的方式,用他的代码做为baseline
但是总觉得原型网络并不能发挥我idea的优势,感觉子空间更加适合。
还是要固定遮挡,固定的网格状的不同形式的遮挡,因为只有这样对比学习才能发挥作用,才能通过学习让每种形式的遮挡最后得到的图片和原图更加相似。
使用原型网络能让得到的原型更加精确吗?
我的目标:扩充子空间的同时让子空间中的点更加聚集。
10.7早上:
尝试知识蒸馏的那篇文章的训练方式,在测试的时候扩充有标签的数据,防止过拟合。
10.10下午:
把深度学习可解释性的东西用到自己的任务中。
10.11下午:
将对比学习的encoder不断变化的网络(MoCo)引入到support set中
10.15早上
图片中有大量的冗余的特征,MAE证明我们只需要25%的图片信息就能很好的将图片进行还原,也就是说我只需要25%的特征就能对图片进行表示。
那么,我把这个特性应用到小样本学习中去,我尝试不同的是遮挡方式,每次都遮挡25%或者是更多,我就能根据每次采用的遮挡方式的不同和遮挡比例的不同,对同一张图片得到更多的对于这个图片的信息,我充分利用这些信息,相当于我把这些图片的所有的冗余的信息全部都利用起来了,进而解决了小样本特征不足的问题。
至于这些信息如何运用,我们可以吧把这些从同一张图片上提取的信息(一个特征向量)作为同一类,然后再进行训练。
这个方法对比以前的方法,以前的方法一张图片只能生成一个特征,而我这种方法使用同一种图片能生成很多特征。
也可以采用很多特征提取器来作为特征,但是那样开销太大,不如只用MAE去提取特征。
motivation:图片相对于自然语言来说有很多的冗余信息,我们在进行图片分类的时候,如何才能充分利用这些冗余的信息?
idea:针对于小样本学习的特征较少,所以我要充分的利用原本就不多的图片中的所有的信息,而MAE能用25%的图片信息就能代表整张图片,那么我是不是可以重复的利用MAE来得到同一张图片的不同的25%的特征?进而我可以利用生成的不同的特征,来进一步的应用到图片分类上得到的不同特征可不可以看成是正样本,然后其他的看做是负样本,采用对比学习的损失?
改进上述idea的想法:
把随机采样改成固定的采样,因为随机采样不可控,很可能采样相同的区域,还是造成了信息的冗余。固定采样可以采取block-wise的方式,比如MAE原文中说block-wise比例为50%的时候效果很好,那么是不是可以采用不同的遮挡50%的方式通过MAE的encoder学习之后进行数据增强呢?
10.17下午:
query set 也可以通过MAE进行增强之后 变成一个原型,只需要与support进行相似的操作。
10.18上午
如果mae有效果的话,再将mae用到其他的基于度量学习的方法上,必须匹配网络和关系网络。
将mae用到基于学习一个embeding(不划分eposipe,把全部的数据放一起训练)的方法上进行测试。
将mae用到跨域的场景下看效果。
10.20下午想法:
为什么5-way,5-shot的效果要比5-way,one-shot的效果好很多,是因为更多的图片使得特征提取器更有效? 还是说图片多了后使得计算出来的原型更加鲁棒?
10.22:
idea1:
可不可以将对比学习中的动量更新encoder的方法引入到小样本中??
idea2:
在用三元组的时候,可不可以将d同时与d+和d-计算距离来的到损失?而不是分别单独的计算距离。
idea3:
在计算损失函数的时候,将两张正样本成一对和两张负样本成一对改成选择用三张图片作为一个整体进行计算,合并成一个公式。
idea4:
一个有希望的方向是在设计FSL方法时考虑使用多模态信息。
idea5:
将对比学习的思想应用到小样本检测中。
idea6:
数据量与归纳偏置成反比,所以小样本更适合CNN?
我能不能结合CNN与Transformer的优点,应用到小样本中呢?
idea7:
在小样本检测的分类分支加通道注意力,回归分支引入空间注意力。
idea8:
在小样本学习中如何更加合理的使用无标签数据?
即能不能先充分发掘测试集的先验知识?(因为在预测的时候测试集就相当于一个无标签的数据)
idea9:
使用神经网络进行提取之后的特征的度量!!!
10.24 中午:
mae能得到原图的不同的形态(张嘴闭嘴)(睁眼闭眼)(转头)
2022.10.26
用mae做query的重构,变成回归问题?
10.26:
从两个角度去写自己的论文,第一个角度就是可学习的数据集的扩充,第二个角度就是遮挡之后的一个损失(对比学习或者伪造监测那篇论文的损失),为了得到一个图片的更为本质的特征。
首先分类的结果是前提,然后目的是提取embedding中最为一致的特征。
遮挡的好处就是能遮挡掉那些不利于类别判别的特征。
为什么伪造监测那篇论文的分类损失和一致性损失是相互权衡的,难道不应该是先分类然后再一致性吗?
!!!!!!!!!!!!!!!1
10.27晚上:
就用原型网络去修改,只不过计算原型那一步改成我得到的特征。
尝试不同的相似性函数,l1,l2,cos,等都试试
10.27晚上想法:
通过多个卷积层去学习一个可学习的mask矩阵。
10.29想法
把线性层换成mlp
10.31想法:
为什么只用cos去计算相似性的损失呢?为什么不能把正类和负类都运用上,使用对比学习的损失呢?对比学习的损失作为消融实验也要用一下,对比一下几个loss之间的效果差别。
MoCo V2
MoCo v2借鉴了SimCLR中的两个有效设计,MLP projection head 和 更多的数据增广。
MLP-head: 将MoCo中的fc head替换成2-layer MLP head。head仅在训练阶段起作用,线性分类器或者迁移阶段,不使用MLP。
11.1晚上想法:
显卡占用太大的原因是不是因为224*224的图片,如果显存不够用的话,我可不可以把MAE输出resize下?
应该不可以,输出不是图片了,是个embedding。
11.2早上:
有可能是mlp的参数量太大了导致显存不够。我只用一个mlp试试
11.2晚上
有可能是mlp的参数量太大了,我只用一个mlp试试。
*******没必要用很多的并行的MLP,只用一个就够了,因为每张图片要关注的主体位置都是动态变化的。我只用一个带hidden的MLP。
问题绝对不是出在图片的数量上,肯定是其他的原因,很可能是图像的尺度,224224是8484的三倍。
如何输出模型的参数量? 深度学习作业上有。
2022.11.3
注意力分为粗粒度的注意力和细粒度的注意力,经过Vit处理之后,我可不可以对重要的patch(物体本身)进行细粒度的注意力?对不是很重要的patch(背景)进行粗粒度的注意力?
原因:
老师说过虽然背景不那么重要,但是,还是有作用的,比如人一般不会像鸟一样站在树枝上。人也不会在天上飞。
11.3下午:
我现在取得是平均值,还没取最好的,我要是取最好的去跟原型网络的结果进行比较,会更牛逼。
11.3下午:
下步要执行的,把query也变成1to5的形式?
11.4
1.只使用vit的clctoken去分类
2.使用vit的不同的大小的embedding去分类
3.我减少了batch size,是不是要对应的去减小学习率?
11.8:
1.将vit的参数调整好,达到应有的和建新媲美的效果比较正常。clstoken的作用是什么?要不要?
2.将vit的patch数量减少,减少的越少越好。
3.尝试将mae与patch-wise的度量方式进行结合,比如我mae生成多个由25%的patch得到的patch embedding(这个25%的patch足以代表整张图片了,patch越大其对应的embedding应该就越大,patch越小对应的embedding就越小),然后根据这个patch embedding去进行度量,可度量很多次,得到最终的评分。
4.我要尝试不同的比较方法,sum-min和match-min(对应位置的patch)和min-min,说不定我的任务适用于哪一种度量方式呢,或者还有其他的度量方式,比如匈牙利算法?
5.对比3907,看看是不是11551有问题。
- 51600的就可以extend之后去计算,那我5196768的为什么不可以去计算呢?
可以的,我变成196196*768的
7.我把clstoken去掉用了goalboolpooling
11.9
看看它是对每一个特征计算损失的,我想对每一个mae的输出计算损失,如何实现并行的去计算损失
使用swimtransformer各个层次的特征去做分类
11.10下午想法:
可以试试:
直接用vit的代码不用mae的
待完成,原理没搞清楚。
set to set 的度量方法还可以有进一步的创新:*************************
根据vit注意力之后的patch的值,或者使用attention 得分去为最后的度量得到一个加权,这样就可以给每个patch进行度量的时候得到一个权重。
具体做法是用得到的attention得分乘以最后得到的距离,这样就使得attention得分较小的(重要性较小的)patch对总体的最后求出来的距离的影响就更小了,达到了根据每个patch的重要程度去度量距离的效果!
在做实验:
使用average pooling还是使用clctoken?我去个发挥clctoken的作用?
备选方案:
使用空间注意力得到attention得分
11.13:
不直接对图片划分patch,而是对得到的feature map划分patch。
11.13下午:
可不可以使用目标检测类似的思想,先把roi得到之后然后利用roi去分类?
11.13早上:
可以尝试使用mae表示随机取样的patch
mae的思想与最接近的patch之间计算余弦相似度的loss相结合
2022.12.3
无监督用到小样本?
研一下学期
2023.1.20
1.只在patch权重高的区域画框,相当于把grid变成可学习的。可以只使用前百分之二十五的最高的数据(上四分位点)。 可以使用torch.where函数
2.图片之间算自注意力?? 支持集与查阅集合之间算注意力?把整个数据集看做一张图片。
3.将目标检测的方法和gridpooling进行结合,相当于定位+分类,既使用了transformer的全局建模能力,又运用了cnn的对信息的提取能力,将二者进行结合。
2023.2.4
利用各个阶段各个尺度所有的特征,并不只是最后一个阶段的特征,也就是说把transformer的各个block的特征全部运用起来。
如果Transformer模型被用于图像分类,浅层关注可能会关注图像的一些局部细节,例如纹理和颜色。随着层数的增加,模型可能会逐渐学习到更全局的特征,例如物体的形状和姿态。但是,这些特征的解释和可解释性可能相对较弱,因为Transformer模型不像卷积神经网络一样具有明显的局部感受野。
他解决了什么问题?是怎么解决的?为什么要这么解决?要是我去解决该怎么去解决?
2023.3.16想法
小样本跨域
不同的域对应的同一图像的特征是不一样的,通过添加的层去自适应的学习当前域所需要的特征进行分类!
底层更关注纹理,高层更关注语义信息,那么可以把不同阶段的拼接在一起,然后通过线性层去学习
新域上的特征与源域各个阶段的特征进行匹配
2023.3.18想法
源域和目标域的数据分布可能相差很大,导致在源域上学习到的特征并不能很好的泛化到目标域上,那么能不能先使用风格迁移的方式,将源域迁移的目标域或者将目标域迁移到源域然后再进行网格训练,训练得到的网络会不会在目标域上表现得更好呢?
2023.3.28早上:
-
如何让cnn与transformer进行结合?
-
神经网络可解释发现重要的背景区域主要集中在主体的边缘,我们要怎么在分类中发挥这一性质?可不可以使用某些注意力?
-
mae的随机遮挡可不可以换成符合某种数学分布的遮挡?
4.从每个类中选取最具代表性的特征,可不可以利用FSViT的多尺度到跨域上?多尺度对应每个类中不同区域的特征,从不同区域特征中挑选出最具代表性的。
2023.3.29:
可以用在跨域上
5. 背景有助于分类+风格迁移。
背景迁移
2023.3.30 晚上:
6.yolo也是将图片打成patch,可不可以与FSvit进行融合,先找出目标,再进行分类,结合CNN与transformer的优势,进行更准确的分类?
不能,yolo有边界框的groundtruth,所以可以进行回归的去找到groundtruth。
思考:
分离前景背景,现在来看,transformer效果会更好,简单
但是transformer存在的问题就是当目标物体较少时,自注意力并不能发挥其作用,长序列建模能力无法展示出来,因此要拉进和目标物体的位置,然后再使用transformer,才能表现出更好的效果。
类似于定位+分类,让多尺度问题消失。
定位:相当于解决了多尺度、背景复杂场景的干扰,让小目标的问题不存在。
Vit分类:充分发挥transformer的长序列建模能力,达到极高的分类准确率。
存在问题:会不会检测的结果并不准确,对后面分类的性能产生影响,毕竟检测的效果与分类的效果相差很远
2023.4.2
目前有的思路:(做遮挡的小样本/跨域的小样本)
1.如何将自己的方法应用到跨域中,选择各个域之间通用的patch?或者学习某部分或区域的patch构成当前类别的特征字典(由不同的patch组成)
要想做跨域,就得深刻的了解其数据集以及任务的形式,才能深入的去思考idea。
2.采用遮挡的方式将不同的patch进行遮挡,学习最为通用的特征,用到跨域?或用到小样本分类。单张图像遮挡,得到不同的姿态。
25%即可以表示语义,使用很多的25%?通过25%去想象。
可以看看zero-shot怎么做的,直觉上zero-shot比few-shot更难。
小样本分类的两个方向:
从方法的角度讲:
1.更加高效的提取特征并利用特征
2.制造更加丰富的特征并利用特征
从模型的角度讲:
空间:筛选最重要的patch
通道:筛选最重要的通道
小样本跨域的方向:
学习通用于各个类别(各个域)之间的通用信息,才能更好的泛化到新的域
2023.4.4
1.卷积核的通道对应transform的多个头,解决跨域有什么启发?
2.AAAI看中实验,Transformer在小样本学习中确实有用吗?
可以通过实验支撑做一篇研究。
2023.4.5凌晨
1.类似于多个卷积的输出,多个头输出之间的平滑。解决小样本跨域问题。
2.可以在多头前面加一个线性层,来为每个头加一个权重。
3.mask的那篇论文原来是模仿的通道注意力,那我可不可以使用CBAM中的通道注意力呢?
2023.4.6晚上:
1.卷积核与muti-head之间的关系?如何泛化?
2023.4.7早上:
空间:筛选最重要的patch
通道:筛选最重要的通道
2023.4.9晚上:
专注于空间注意力,就不要多尺度了
同时关注于空间,比如胸腔的x光片,关注于肺部的某一部分,这就是空间注意力的作用。
通道注意力能使用更好的适用于目标域的头。
4.16晚上
把cbam的空间注意力写成loss加入transformer,把通道注意力改成head注意力写成loss的形式。
将本身就有的attention与空间注意力进行结合
4.25晚上
现在已经知道的对跨域有影响的因素:
1.不同域上不同通道的重要程度不同。
2.现在的cross domain meta-learning方法使用图片的高层特征作为分类器的输入,但是domain shift可能会导致一些高级的概念(如人的耳朵、鼻子、眼睛)在源域和目标域之间不共享。而图片中的低层特征(如线条、正方形)仍然可以共享和使用。作者的想要把低层特征作为分类器的输入,这更有利于domain shift。
那我该怎么设计我的模型?同时满足以上两点?以提高跨域的性能?
2023.5.4想法:
空间上的方法:
在匹配的过程中,不再是每一张support(或者每一类support的原型)和query进行匹配了,而是将所有的support都放在一起,选出前m个最为相似的patch(比如为10),然后再看这前m个分别属于哪一个类别的support set,比如类别一占5个,类别2占3个,类别三占2个,那么就确定这个query是类别一。相当于一种投票的(统计的)机制,这样能每一个support图片中多个尺度的信息,通过这种统计的到的结果更加鲁棒。
m可以设计的很大,m越大统计的越充分。
但是这样统计相似度更高的不就和相似度不是那么高的都是在前十的发挥的作用不就一样了?
或者有另一种方法:设定个m之后,比如m为10,将前10个中同一类别的相似度进行相加,作为当前的query到这个类别的相似度,这样就比较公平,在进行分类决策的时候充分运用好所有的图片信息。
与MN的方法有点类似:
Matching Networks可以简洁表示为计算一个无标签样本的标签为y ^ \hat的概率,这个计算方法跟KNN很像,相当于是加权后的KNN。
可以看成是支持向量集S中{x_i,y_i}所有样本的线性结合,只是给他们赋予了不同的权重。
对于a作者采用的也是最简单的方式,就是用x^样本与x样本之间的特征(文中成为embedding)的cosine距离的softmax值进行计算。
或者我不计算support的原型,直接把每张图片输进来,这样更好,原型限制了特征的多样性,并批判原型对特征的充分利用是有害的。
我们直接对计算原型的方法提出质疑(计算原型的方法被应用于好多模型中,但是我们发现使用原型使得本来就不多的小样本任务中的图片特征不能得到充分利用,使用原型会阻碍小样本分类性能的提升),跑几个使用原型网络的方法计算的模型,突出我们这种基于概率统计的模型的优势(如果能加上一点数学就好了)。
2023.5.5
也使用自注意力中的缩放点击对patch进行加权可以吗?然后再根据加权后的池化
相当于利用support set与query set之间图片的关系进行加权,类似于DMP
2023.5.6早上想法:
不要找最相似的patch,而是找最不相似的patch
在support set中响应最高的且最不相似的patch中找最相似的patch
设计一种通用的小样本分类特征筛选机制,不仅仅适用于单域小样本分类,同时适用于跨域小样本分类。
对特征的一种筛选,选最相似的两个而不是一个,然后在最相似的里面去筛选,筛选的原则是support之间相似的不要,要support之间最不相似的
2023.5.6下午:
都找support set与query中最相似的,那不就都相似了吗?要找的不仅仅是support set与query中最相似的,而且要找support set之间不相似的,同时这个不相似的特征能在query中找到!!!!
2023.5.7上午:
空间和通道两个方面的筛选
通道方面的筛选可以用到conv模块,结合transformer和cnn的优势:transformer能将注意力集中在物体的主体,而cnn能实现多通道的特征提取,来适应不同域的特征。
2023.5.9下午:
对注意力机制的修改,从生物的角度去解释,提出一种更简单高效的注意力,同时能做跨域。
把自注意力改成通道可选择的一个模块
2023.5.11
匈牙利算法能不能用于support set提取得到得到的特征集合和query中提取到的特征集合之间的匹配?
2023.5.14晚上:
既然transformer的各个层的输出都不一样,那我可不可以将各个层输出的patch表示都作为一个分类的结果,然后去进行匹配?
之前的transformer只是使用最后一层的输出去做分类的决策,但是对于小样本任务而言,数据集很少,那我就更应该充分发掘和利用仅有样本的丰富信息,而这个丰富的信息蕴含在transformer 结构的各个block里面,而对于每个block的输出,只取权重最高的patch进行分类。
为什么是12个block的堆叠?而不是一个相同的block重复的使用12次?(参数量不一样,表达能力不一样。)每个block都发挥着它的作用。但是具体的作用是什么呢?
对patch筛选的一点思考:
主体的确比背景重要很多,从人类得到启发:当我们看一眼主体某个部位,我们就能大概的区分出这个部位应该在哪个物体上(动物上)出现,但是看到背景,很难推断出是在那个物体(动物),至少可以肯定的是,物体的主体部分的信息是比背景区域重要的。但不能说背景没用。
现在觉得也可以说背景没用,我要的类别是猫猫,背景是草,有什么用呢?
2023.5.15中午:
对transformer模型的思考:
在计算机视觉中,基于CNN的模型底层更加关注于图像的纹理和边缘,高层更加关注于图像的语义信息,那么,基于Transformer的模型的底层关注的是什么?高层关注的又是什么呢?
在输入自注意力的计算之前,有对应的patch embedding的操作,这个操作相当于对局部信息的一个提取,
也会是说有且只有第一层(patch embedding)层是对局部信息的一个学习,后面的层是不断地self-attention的一个堆叠,后面的层都在做不断的patch之间的信息的交互,区别只在于交互的好坏。
也就是说,可以把transformer模型分为两个部分:分别是patch局部特征的embedding和patch特征的交互。
那么我该如何改进呢?
2023.5.16上午:
动机:
通道上:
Attention is all you need论文中讲模型分为多个头,形成多个子空间,每个头关注不同方面的信息(是对同一特征到不同的特征空间的映射)。对于不同的类别、不同的域来说,关注的信息都是不一样的,所以要对head进行筛选。
空间上:
有些patch看一眼就知道是什么类别,所具有的判别性信息更强,而有些patch看一眼就知道不具有判别性的信息,比如背景,所以要对patch进行筛选。
方法:
通道上选头(还是调整头)?
空间上选patch
现有结论:头之间的差距是随着层数的加大而变小。差距变小就说明不同头之间的方差在随着层数的增大而减小;但是这种随着层数变大,不同层头之间的差距在变小,这种差距的变小的作用,还没有人证明解释。
猜测1.:一种可能的解释是,它类似一种 noise,或者 dropout,而不是去关注不同的方面。也就是说,无论多少层,既然都会出现与众不同的头,那么这个(些)头就是去使得模型收敛(效果最优)的结果,反过来说,模型可能认为,全部一样的头不会使效果最优(至少在梯度下降的方法上)。这样的话,把这个(些)头解释为模型的一种 “试探”,或者噪声,是可能合理的。
猜测2:Transformer 对初始化比较敏感,一些初始化点必然导致不同的头,但这样解释就很难从直觉上解释了。
在Attention is all you need论文中,4,6,8个head效果差别都不大。这种差别究竟是多头带来的还是参数量带来的也不确定。
2023.5.16下午:
在tranformer训练的过程中使用query的kv去指导support的kv训练,能对vit进行优化剪枝,减少计算量。
新的transformer
前面用pooling,后面用attention,同时在attention上面加上query对support的指导。剪枝筛选patch。
为什么前面的用pooling,后面用attention?
因为前面是比较冗余的局部信息,计算自注意力不仅开销大而且会学到一些错误的信息,后面的用attention更加适合高层的语义信息的信息的交互,同时减少计算量。
资料:
1、Raghu et al.[43]比较了ViT和cnn的特征差异,发现自关注允许较早地收集全局信息,而残差连接极大地将特征从较低的层传播到较高的层。
2023.5.17上午:
1.pooling与attention穿插结构,并通过做消融实验证明有效
2.在各个层次都要指导support的特征学习 ,让support朝着query学习,各个层级的交互
3.同时support之间有个loss,让support拉远
4.各个层次的特征拿出来做最后的分类决策,而且这个各个层次的特征应该是多尺度的,使用pooling方法实现多尺度。
可以分成好几个小点,做消融实验时候做一个大表,使用那个在哪个位置打上对钩。
动机:解释
人看到某个部分就能大概的分类,所以我们既要关注局部信息,也要关注于全局信息。
2023.5.17晚上:
来自ECCV2022Self-Support Few-Shot Semantic Segmentation灵感:
让support朝着query学习这一点可以扩展:
support和query之间存在一个外观的gap,这个外观的gap的产生有两点原因:
1.数据稀少:support中的类别很少,5way只有5个类别
2.数据多样:不确定的新的类别的query的外观各异。
这就要用query去指导support训练
2023.5.18上午:
使用指导的方式有很多种:
第一种是改变kv矩阵(目标跟踪那篇方法)
第二种是使用query的表征作为support中自注意计算的query(把query的self attention的query作为support的注意力的query)
一种是矩阵的拼接,一种是直接使用矩阵
或者,还有没有其它的方式呢?
使用query的k去替换support的k?是不是与替换q是一样的?
解决的问题就是support 中学不到query的特征,通过query的指导学习到判别性的特征。
2023.5.21下午:
或者不分开去学习qkv,而是query只学习q和support只学习k和v,这样不仅能减少参数量,而且能加快学习速度。
应该不能只学习query中的q,因为要使用query的最后的表征去进行相似度的计算。在学习最后的表征的过程中是要使用qkv的。
2023.5.22晚上:
query对support的指导只放在高层,只在语义上指导。由于纹理信息和边缘信息根据图像的大小尺度不同是相对的,所以不能在底层进行指导,会指导出问题。
2023.5.26中午:
metaformer将自注意力层换成了池化层,达到了不错的效果,那我能不能在池化层的每一个阶段再加上池化层?这样就能最大限度的减少参数量的同时提取各个层级的多尺度的信息,然后再设计一种牛逼的算法进行特征的筛选,筛选出最利于分类的特征去进行最终的决策分类。同时要有一定量的参数用于自适应的在各个类、各个域之间微调,适应不同的类别不同的域。同时这个调整的参数站整个网络的很大一部分,占很大一部分的原因是总的网络的参数量很小,所以只需要微调很小的部分参数就能达到不错的效果。
只是pooling感觉还不够,需要加上一种具有筛选能力的pooling:
先在pooling之前计算一个注意力矩阵,然后在进行pooling,attention+pooling,也就能进一步减少计算量的同时,将pooling的位置变成可学习的。
除了attention+pooling的方式,有没有其他的方式?也能实现attention的效果?谱聚类?其他的呢? patch之间的knn
2023.5.26下午:
5shot的时候shot之间也可以进行注意力。
2023.5.26晚上:
我们在进行分类的时候,往往只需要具体的某个patch就能判断这个物体是什么类别,但是这个patch的具体位置难以估计,因此我们就需要提取网络的各个层次各个区域的特征,找到最为重要的patch去进行最终的分类决策。
需要:对patch进行筛选
2023.5.27下午:
都找support set与query中最相似的,那不就都相似了吗?要找的不仅仅是support set与query中最相似的,而且要找support set之间不相似的,同时这个不相似的特征能在query中找到!!!!
可以query对每个support都找到前5个最相似的,然后support image与support image之间进行比较,找到最不相似的前3个,作为最终的分类决策所使用的patch。
这样能解决相似的类别之间匹配出错的问题,比如query是猫,support image1是猫的尾巴,support image2是狗的尾巴,两者都有尾巴,就对应了query猫与support1猫和support2老虎都有较高的相似度。同时support1猫和support2老虎的尾巴之间也有较高的相似度。
但是如果选的相似度的位置是query的猫头,那么support1猫头和query的猫头有较高的相似度,support2的狗头与query的猫头相似度就较低,support1猫头与support2的狗头相似度就较低。
这么做的目的就是筛选那些虽然相似度较高,但是对分类的判别性产生误导的patch。
总的来说:
若:query与support1patch1相似度较高 且 query与support2patch1相似度较高 且support1patch1与support2patch2相似度较高 则 不能得出这是一个具有判别性的patch的结论。
若:query与support1patch1相似度较高 且 query与support2patch1相似度较高 且support1patch1与support2patch2相似度较低 则 这是一个具有判别性的patch的结论
找这样的多个patch。
举个例子:胸腔的X光片,其他部位的patch基本都是差不多的,相似度很高,但是只有胸腔哪一部分的support与query相似度不一样(肺炎任务),query只与有同样症状的胸腔相似度高。所以要按照上面的方式筛选patch,才能得到最具判别性的信息。
2023.5.27晚上:
动机:每个patch都具有一定的判别性的信息。
最终的分类是多个patch判别性信息的整合。
才能达到最准确的分类决策。
2023-05-29
筛选Patch然后元胞自动机模拟
有些相似度很高的patch不能起到决定性作用
构建一个层级的多尺度网络提取丰富的特征
poling能有效的聚合信息,而attention能高效的信息交互,所以使用这种交替堆叠的组合。
首先都与query计算相似度,找出高的,然后再筛选,找出support之间不高的。
2023.5.30下午:
注意力权重高的词不一定是最有助于分类的token
2023.7.5思路:
1.使用td进行计算,不使用加法去进行计算,自生成的语义提示。
2.多视角小样本分类
3.cub之所以是细粒度的数据集因为数据集都是鸟,鸟与鸟之间是很像的。
2023.7.6
最后一层的梯度对模型的可解释性最强
自我生成的prompt能让注意力学习的更好,集中在对应目标物体的主体部分,但是注意力高的部分并不一定对分类来说是最重要的,还需要进一步的对patch进行筛选,于是就利用支持集和查询集之间的关系进行筛选。
2023.7.7
可以通过使用多尺度的卷积来实现patch embedding,以此弥补多尺度的问题。
2023.7.9
参考北大Reid的工作,尝试将图的思想引入小样本学习。
研二上学期
2023.10.8
匈牙利算法能不能用于support set提取得到得到的特征集合和query中提取到的特征集合之间的匹配?
进行patch之间的匹配!!
2023.10.10:
提示学习应用到小样本分类,探究提示学习需要微调的参数量,参数占比,参数位置对小样本分类性能的影响。找出最优的提示学习适用于小样本分类的方法。
可选的微调方式:1.只微调bais 2.微调batchnorm的参数或layernorm的参数 3.只微调后几层的参数 4.只微调分类头的参数 5.加上一些提示的信息进行微调。(如何选取高效的提示信息)
对于小样本分类任务而言要微调多少参数才算好,样本数量(1-shot和5-shot)对应的微调参数量分别是多少。
2023.10.19:
微调正则化参数的方法似乎并不可行,因为正则化需要的是对数据分布的统计量,而小样本学习的数据分布变化较大,那么就导致在新的数据域上得不到准确的数据分布。
那么该如何得到准确的数据分布呢?
2023.10.25
用aigc生成图片,解决小样本问题
2023.10.27 下午:
匈牙利算法可以用在support 和 query进行特征匹配(多尺度)的过程,这样做的目的是通过匈牙利算法,每个support的能且只能找到与他最匹配的那一个query中的特征,而不会多个相似的特征关注于query中的同一个相似的特征,这样就能不局限于图片的某一个区域,而是同时关注与图片的多个区域,然后再利用多个区域的总和(相当于考虑到各个区域的特征),去进行分类的决策。
只需要和detr一样,调用scipy 中的linear-sum-assignment(看detr的代码)
2023.10.27晚上:
自我提示用到检测和分割,写一篇期刊
2023.10.28:
把大的视觉模型+提示学习用到小样本检测和分割
2023.10.29
如果把大模型和人类对比,大模型具有十亿甚至百亿级别的参数,蕴含着大量的知识,人类同样经过几十万年的进化,达到今天的智能。人类在小时候需要一个很好的老师去指导他,才能激发人类的潜能,进行学习和创造并完成各种事业甚至有所成就。提示学习相当于大模型的教师,为大模型提供“指导”,一个很好的教师是至关重要的,大模型本身蕴含的丰富的知识,我们怎样去提示大模型并利用甚至挖掘他本身具有的知识正是提示学习所在做的。
2023.10.29晚上:
可不可以用一个小的模型去生成准确的提示 prompt?然后去指导大的模型的训练,如何利用support set中仅有的样本去生成准确的提示是至关重要的。
2023.10.30上午:
prompt learning两个关键点:
1、prompt插入的位置和数量
2、prompt如何进行初始化
两者都会很大程度上影响模型的结果
2023.11.2:
自我提示,越大的模型所具有的知识越多,自我提示在不同尺度模型上做实验,vit base和vit large 并做一个统计图
2023.11.8:
模型越大小样本分类的效果越好吗? 显然不是的,那如何发挥大模型的优势?
通过提示学习。
于是我们提出一种新的提示学习的方法,用于小样本分类。
2023.11.18
动态网络用到小样本学习中
2023.11.19
利用提示学习提取有助于分类的高频\低频?信息(使用傅里叶变换),然后利用这一信息去对视觉大模型进行提示(在特征层面上进行提示或者调整大模型的网络结构)。
2023.12.5
自然语言处理的transformer是处理序列的数据,是因为自然语言本身是序列的。人类在理解的时候也是从头往后去阅读,去理解。而图像与自然语言不同,人类能从图像的整体去观察,扫描的是个范围(类似卷积),迅速找到定位。而视觉的transformer还是将图像变成了序列去处理,这是正确的的吗?难道不会降低效率吗?
但是反过来想,人类的视觉系统对于计算机来说就是最优解吗?好多工作的idea都是来源于人类理解这个世界的方式(审稿人也会同样觉得这种方式是对的,难道是源于人类在自然界盲目的自信?),或许我们本质上在探索的是人类是如何理解这个世界的(因为人类本身并不明白这一点,很想搞清楚),所以我们本质上还是在认识自己。
但是,在认识自己的过程中,能不能发现更高的智能呢?或许能突破文明的界限?
CNN只要卷积核足够大,我觉得还是能超越Transformer的,就像是一个人看一个范围,而另一个要逐点的去遍历。
2023.12.5下午:
在Simplifying Transformer Blocks的基础上加提示
2023.12.11:
提示学习+多尺度?
2023.12.15:
提示生成条件 条件下的动态网络 类似于何恺明的预训练模型生成条件
2023.12.16
动态网络一定可以用到小样本中
2023.12.17
是不是说模型设计的越巧妙,模型的迁移性就不好。比如:看起来cnn比transformer更加的巧妙,但是同样的数据量和trick的情况下,transformer的性能要比cnn具有更强的迁移性,是因为transformer更加粗暴吗?
也就是说transformer的inductive bias(归纳偏置)更弱,他的表示能力更强,迁移能力也更强。
transformer解放了平移不变性,引入了排列等变性:
平移不变性可以简化认为是CBR(Convolution-BatchNorm-ReLU)模块是平移不变的:卷积核在输入特征图的不同部分都是一样的工作;Transformer是排列等变的,是因为transformer对输入输出的序列顺序是没有要求的,它自己通过注意力机制来寻找输入序列内容的相对关系;因此这也是输入需要位置编码的原因(注入位置的信息)。也就是说,完全相同的内容在不同位置,经过CBR的结果是一样的;但是在Transformer中不一样;同一个输入序列进行重新排序,Transformer的输出序列(patch embedding)也会同样的重新排序,只要一个序列里的内容和位置编码是不变的,那么重新排序后的输出序列内容也是不变的。
2023.12.19
将攻击和对抗的思想引入到小样本学习。(如果能做成可以投NeurIPS)
2023.12.20
将图transformer应用到小样本学习。(AAAI2025)
2023.12.21想法:
我们研究了基于迁移学习模型的尺度大小与小样本学习的性能并不是成正比的关系,模型越大表现出的迁移性反而更小。基于这一发现,我们提出了一种适用于不同尺度模型的微调方式,同时分析了模型参数量的多少与shot之间的关系。
我们提出了适用于任意尺度模型的方法。。。。。
视觉大模型的提示学习for few shot learning
相关文章:
)
小样本学习idea(不断更新)
在此整理并记录自己的思考过程,其中不乏有一些尚未成熟或者尚未实现的idea,也有一些idea实现之后没有效果或者正在实现,当然也有部分idea已写成论文正在投稿,都是自己的一些碎碎念念的思考,欢迎交流。 研一上学期 9.…...
表情包搜索网站
一个非常不错的表情包搜索网站,输入关键词即可得到所有相关的表情,还可以选择套图下载,自制表情,非常给力666 可以点击下载,会新建窗口打开图片,鼠标右键“图片另存为”,下载文件名手动补充“…...
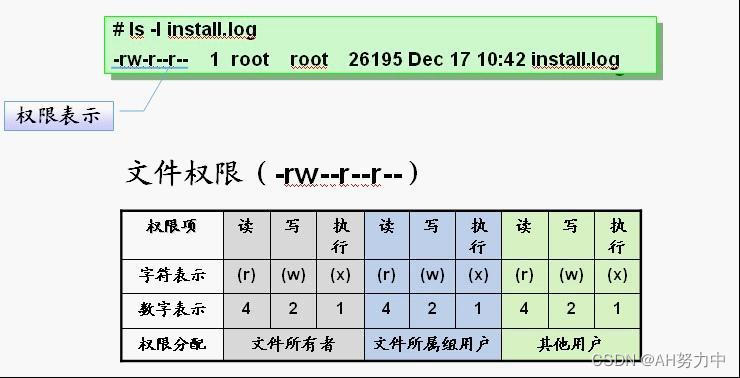
Linux账号和权限管理
目录 一、用户账号和组账号概述 1、用户账号类型 2、组账号 1.基本组(私有组) 2.附加组(公共组) 3、ID 1.UID 2.GID 4、用户和账号管理 1.文件位置 2.useradd-----创建用户 3.userdel——删除用户账号 4.usermod---修…...
)
Qt/QML编程学习之心得:QML和C++的相互调用(十五)
Qt下的QML说到底是类似于JavaScript的一种解释性语言,习惯了VC的MVC(Veiw+Control)的模式,那种界面视图任何事件都是和C++的cpp中处理函数一一对应,在类中也有明确的说明的。一下子玩Qt会觉得哪里对不上,比如使用QML这种节脚本语言贴了图做了layout布局,那么一个按钮的o…...
月入10.5K,专科小伙转行网优:据说每个领域都有一个“显眼包”
网络热词流行的今天,显眼包一词又上热搜。除了熟知的内娱显眼包外,其实各行业也都有自己的“显眼包”。 显眼包又叫“现眼包”看似丢人现眼,实则是个“褒义词”,他们勇敢自信,积极乐观,敢于展示自己&#x…...

Python自动化测试:选择最佳的自动化测试框架
在开始学习python自动化测试之前,先了解目前市场上的自动化测试框架有哪些? 随着技术的不断迭代更新,优胜劣汰也同样发展下来。从一开始工具型自动化,到现在的框架型;从一开始的能用,到现在的不仅能用&…...
Ubuntu16.04 安装Anaconda
步骤 1: 去官网下载安装包,链接如下: https://repo.anaconda.com/archive/ 找到对应版本下载至本地电脑,并上传至服务器。 步骤2: 通过命令解压 sh Anaconda3-2023.03-0-Linux-x86_64.sh 一路选择yes或则回车,直到安装成功出现下面画面&…...
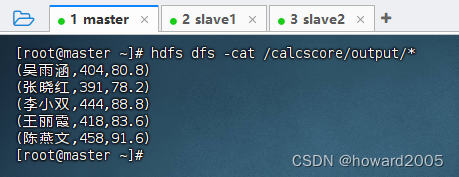
MR实战:统计总分与平均分
文章目录 一、实战概述二、提出任务三、完成任务(一)准备数据1、在虚拟机上创建文本文件2、上传文件到HDFS指定目录 (二)实现步骤1、创建Maven项目2、添加相关依赖3、创建日志属性文件4、创建成绩映射器类5、创建成绩驱动器类6、启…...
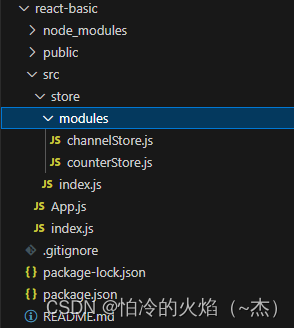
Redux与React环境准备、实现counter(及传参)、异步获取数据
环境说明: 一:说明 在React中使用redux,官方要求安装两个其他插件:Redux Toolkit和react-redux 1. Redux ToolKit(RTK) - 官方推荐编写Redux逻辑的方式,是一套工具的集合集,简化书写方式 (简化…...
网站服务器被入侵,如何排查,该如何预防入侵呢?
在我们日常使用服务器的过程中,当公司的网站服务器被黑客入侵时,导致整个网站以及业务系统瘫痪,将会给企业带来无法估量的损失。作为服务器的维护人员应当在第一时间做好安全响应,对入侵问题做到及时处理,以最快的时间…...

应用在网络摄像机领域中的国产音频ADC芯片
IPC:其实叫“网络摄像机”,是IP Camera的简称。它是在前一代模拟摄像机的基础上,集成了编码模块后的摄像机。它和模拟摄像机的区别,就是在新增的“编码模块”上。模拟摄像机,顾名思义,输出的是模拟视频信号…...
Unity3D 安装和下载指南及汉化
Unity3D是一款强大的游戏开发引擎,为开发者提供了丰富的工具和资源,使得游戏制作变得更加简单和高效。本文将介绍Unity3D的安装和下载步骤,以帮助初学者迅速入门。 步骤一:访问Unity官网 首先,打开浏览器,…...

【SpringCache】SpringCache详解及其使用,Redis控制失效时间
一、使用 在 Spring 中,使用缓存通常涉及以下步骤: 1、添加缓存依赖: 确保项目中添加了缓存相关的依赖。如果使用 Maven,可以在项目的 pom.xml 文件中添加 Spring Cache 的依赖。 <dependency><groupId>org.spring…...

MyBatis的基本使用及常见问题
MyBatis 前言MyBatis简介MyBatis快速上手Mapper代理开发增删改查环境准备配置文件完成增删改查查询添加修改删除 参数传递注解完成增删改查 前言 JavaWeb JavaWeb是用Java技术来解决相关Web互联网领域的技术栈。 MySQL数据库与SQL语言 MySQL:开源的中小型数据库。…...

[RoarCTF2019] TankGame
不多说,用dnspy反编译data文件夹中的Assembly-CSharp文件 使用分析器分析一下可疑的FlagText 发现其在WinGame中被调用,跟进WinGame函数 public static void WinGame(){if (!MapManager.winGame && (MapManager.nDestroyNum 4 || MapManager.n…...

相比于其他流处理技术,Flink的优点在哪?
Apache Flink 是一个开源的流处理框架,用于在高吞吐量和低延迟的情况下进行大规模数据流的处理。Flink 以其在流处理领域的性能而闻名,相比于其他流处理技术,Flink 提供了一些独特的特性和优化,使其在某些情况下更快。以下是 Flin…...

react中使用ref属性获取元素,并判断该元素内是否含有子元素
在react中,可以使用ref属性来获取到一个元素的引用,然后再使用ref.current来访问该元素的DOM节点,使用DOM API来判断这个元素是否含有子元素,要判断一个元素是否含有子元素,可以使用hasChildNodes(),其返回…...
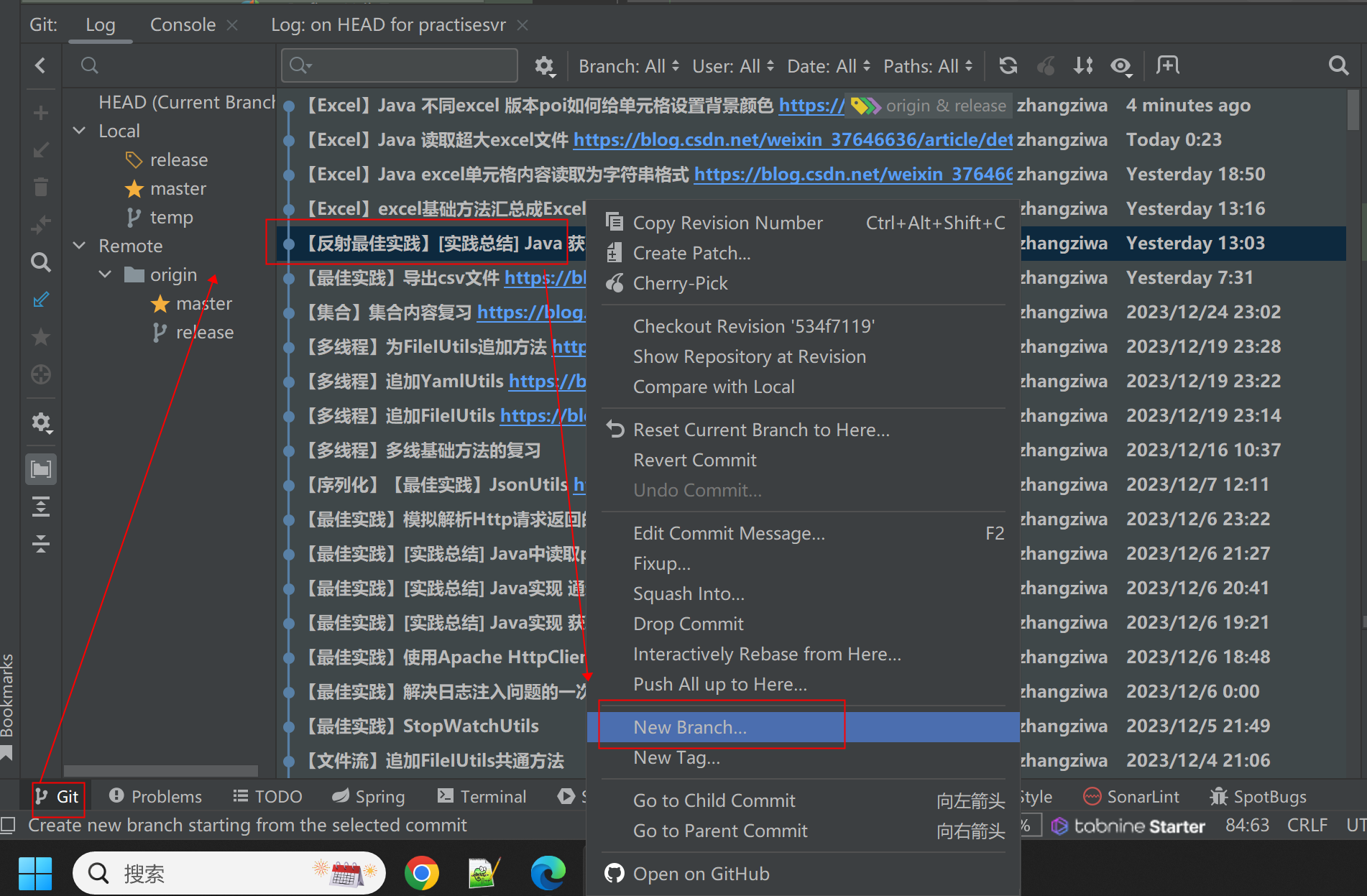
idea 如何快速拉取新分支
方式1 (快捷键:CtrlShift~) 方式2:(快捷键:Alt9)...

【经验分享】日常开发中的故障排查经验分享(一)
目录 简介CPU飙高问题1、使用JVM命令排查CPU飙升100%问题2、使用Arthas的方式定位CPU飙升问题3、Java项目导致CPU飙升的原因有哪些?如何解决? OOM问题(内存溢出)1、如何定位OOM问题?2、OOM问题产生原因 死锁问题的定位…...
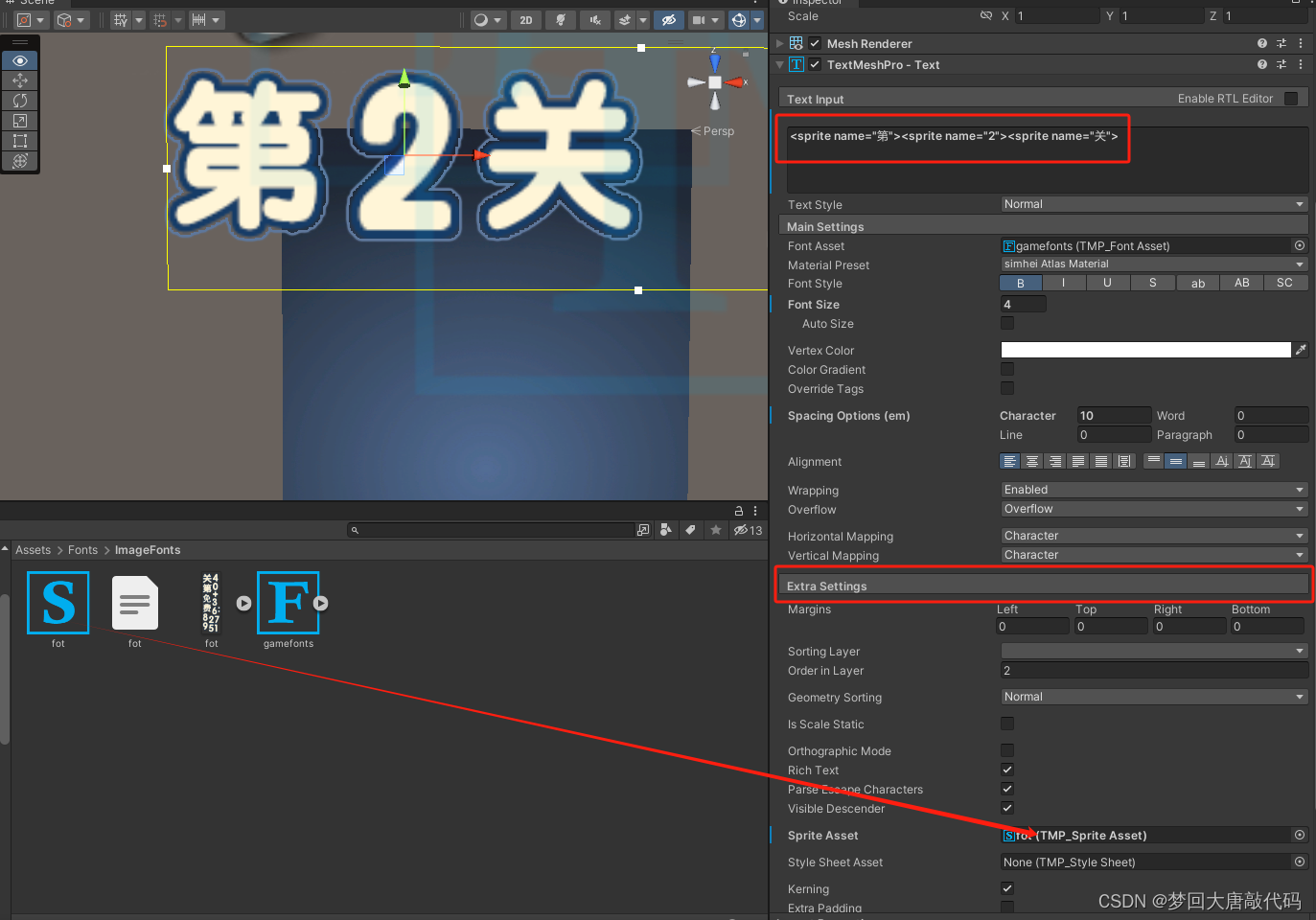
关于Unity使用图片字体示例
1.使用TexturePacker打包图集 下载地址 TexturePacker - Create Sprite Sheets for your game! 2.准备好数字图 3. 导入图片 4. 打包图集需要的设置 将重心点设置为左下方 点击回车 > 后点击回 >到精灵列表 选择导出的格式 导出后的内容 >导入unity 导入 >…...

3步掌握清华PPT模板:终极方案解决学术演示设计难题
3步掌握清华PPT模板:终极方案解决学术演示设计难题 【免费下载链接】THU-PPT-Theme 清华主题PPT模板 项目地址: https://gitcode.com/gh_mirrors/th/THU-PPT-Theme 还在为学术汇报PPT设计而苦恼吗?每次准备答辩、会议或教学演示,你都要…...

Sunshine流媒体服务器深度配置指南:10个性能优化技巧与实战配置
Sunshine流媒体服务器深度配置指南:10个性能优化技巧与实战配置 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine Sunshine是一款开源的游戏流媒体服务器,支持…...

巧用frp与nginx反向代理,实现安全远程访问内网ESXi管理界面
1. 为什么需要远程访问ESXi管理界面 对于运维人员来说,能够随时随地访问ESXi管理界面是刚需。想象一下,当你正在出差或者在家休息时,突然需要检查虚拟机状态或者处理紧急故障,如果只能跑到机房操作,那简直是噩梦。我遇…...

环境配置与基础教程:多机多卡分布式训练实战:基于 SLURM 集群调度 YOLOv11,大幅缩短训练周期
一、为什么分布式训练是 YOLOv11 落地的“必经之路” 1.1 单卡训练的困境 如果你正在使用 YOLOv11 做目标检测,那么你一定遇到过这个场景:数据集有十万张以上的图片,模型选的是 YOLOv11x,单张 A100 跑一个 epoch 要 40 分钟,完整训练 300 个 epoch 需要整整 8 天。更让人…...

AI应用开发模板:基于FastAPI与LangChain的Agent后端快速构建指南
1. 项目概述:一个为AI应用开发者准备的“开箱即用”大脑最近在折腾AI应用开发的朋友,可能都经历过类似的痛苦:想快速验证一个想法,比如做个智能客服、文档问答机器人,或者一个能理解你指令的自动化工具。结果发现&…...

基于MCP协议构建YouTube视频AI分析工具:原理、部署与应用
1. 项目概述:一个连接AI与YouTube的“翻译官”如果你正在探索如何让AI助手,比如Claude、Cursor或者GPTs,直接帮你处理YouTube视频内容——比如总结一个长达两小时的科技讲座、提取某个教程的所有操作步骤,或者分析某个频道近期的内…...

AI Agent + 指纹浏览器:从0搭建MCP Server实现批量账号自动化管理
我是张大鹏,做了十多年人工智能,带过不少项目。说实话,AI Agent 最难的不是生成内容,是"动手干活"——大模型再强,如果只能输出文字而不能操控真实环境,自动化就永远差最后一公里。最近在研究 In…...
)
告别Excel!用CANalyzer系统变量做CAN信号实时运算,保姆级配置流程(附CAPL脚本)
告别Excel!用CANalyzer系统变量实现CAN信号实时运算的工程实践 在车辆网络数据分析领域,工程师们经常需要验证不同CAN信号之间的理论关系,比如车速与轮速的比例校验、扭矩与电流的线性相关性分析。传统做法是将CANoe/CANalyzer采集的数据导出…...

别再用示波器死磕了!用Python+RC积分电路,5分钟搞定充放电曲线模拟与可视化
别再用示波器死磕了!用PythonRC积分电路,5分钟搞定充放电曲线模拟与可视化 在电子工程实践中,RC积分电路的充放电特性分析是基础中的基础。传统方法往往依赖示波器观测,不仅耗时耗力,还受限于硬件条件。今天ÿ…...

Java源码学习:深入剖析Java的concurrent包源码之`ReentrantLock` 的精妙设计与云原生演进
引言:从 synchronized 到可编程的锁 在 Java 并发编程的演进史上,synchronized 关键字曾是开发者控制线程同步的唯一选择。它简单、易用,并由 JVM 保证其正确性。然而,随着应用复杂度的提升,其固有的局限性——如无法中…...