Pag的2D渲染执行流程
Pag的渲染
背景
根据Pag文章里面说的,Pag之前长时间使用的Skia库作为底层渲染引擎。但由于Skia库体积过大,为了保证通用型(比如兼容CPU渲染)做了很多额外的事情。所以Pag的工程师们自己实现了一套2D图形框架替换掉Skia,在github里面在一个叫 TGFX 的目录内。我猜测腾讯的工程师这里是致敬暴雪的bgfx吧,不过这两个库其实有本质区别:bgfx更多是统一底层图形API为目标的,而tgfx是一套用于2D的渲染库,核心目标是替换掉Skia。其目前主要用OpenGL API用GPU实现渲染,默认不支持CPU渲染(也能通过SwiftShader来支持),在绝大部分设备上GPU渲染都会更高效。其API也和Skia的API相似度很高,只是没有SK开头罢了。这些API对于做Android应用开发的同学来说再熟悉不过了。不过我还是整体理一下里面的核心概念吧:
| 概念 | 描述 |
|---|---|
| Bitmap | 位图,它是像素的集合,是内存里的色彩的表现和承载者,一般用CPU解码图片后就会保存为Bitmap,也可以通过CPU去操作Bitmap的像素。 |
| Texture | 纹理,也代表一张图,在OpenGL内使用,可以简单的理解为在显存内的Bitmap,Pag里面的视频/素材 都是通过Texture渲染的。 |
| Surface | 表面,其实更像是一个装画的地方。画画我们可以在纸上画,也可以在墙上画。 |
| Paint | 画笔,可以自定义各种色彩,样式等,拿起什么样的比就画出什么样的画。 |
| Canvas | 画布,可以看做一种渲染过程,比如draw/drawTexture/drawPath等。经历过怎样的渲染过程就会产出什么样的结果。比如我画了一个狮子,再画一个老虎,那最终就会呈现出虎狮 |
概要
为了了解全貌,我这边把一些重要的概念和整体的Pag模块画了一个图,大家可以看到TGFX在整个libpag内的位置:
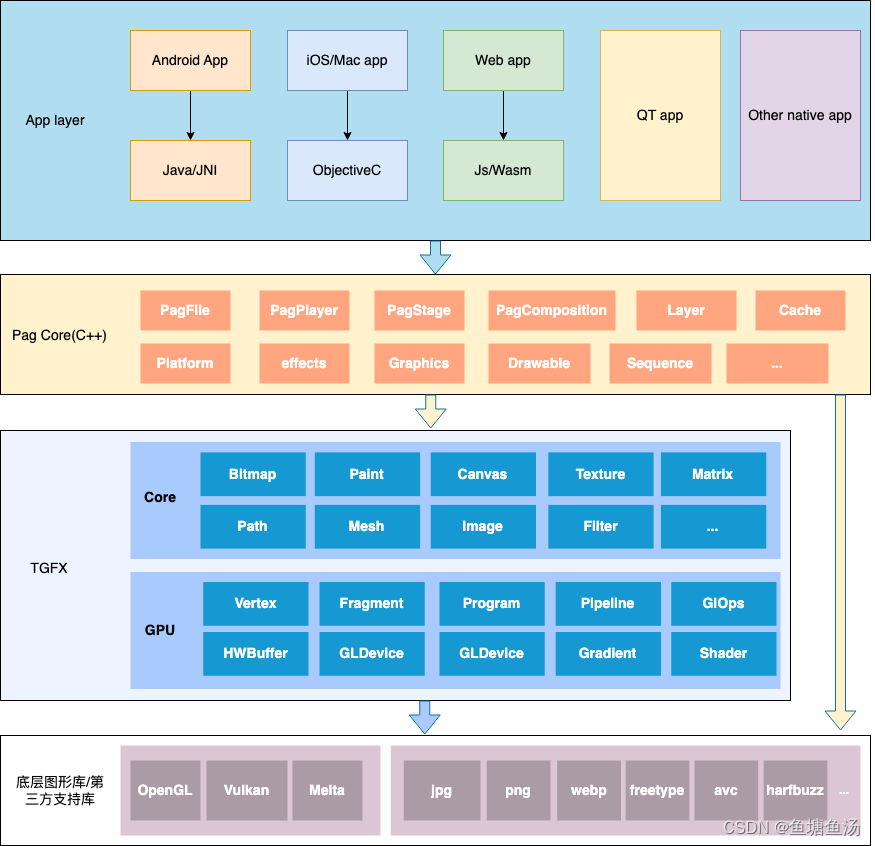
接下来我们还是从情景来分析pag渲染的具体流程。
Pag渲染流程分析
之前我们介绍了Pag的基本结构组织,这里来详细讲一下渲染过程,也就是如下两个方法调用:
1. 设置进度
pagPlayer.setProgress(progress);
2. 执行渲染
pagPlayer.flush();
设置进度
这个应该都大致能猜到,肯定核心逻辑就是会去设置到目标合成里通过归一化的percent通知到RootComposition当前有进度更新,需要准备下一次渲染的素材了之类的逻辑。具体代码如下:
void PAGPlayer::setProgress(double percent) {LockGuard autoLock(rootLocker);auto pagComposition = stage->getRootComposition();if (pagComposition == nullptr) {return;}auto realProgress = percent;auto frameRate = pagComposition->frameRateInternal();if (_maxFrameRate < frameRate && _maxFrameRate > 0) {auto duration = pagComposition->durationInternal();auto totalFrames = TimeToFrame(duration, frameRate);auto numFrames = ceilf(totalFrames * _maxFrameRate / frameRate);// 首先计算在maxFrameRate的帧号,之后重新计算progressauto targetFrame = ProgressToFrame(realProgress, numFrames);realProgress = FrameToProgress(targetFrame, numFrames);}pagComposition->setProgressInternal(realProgress);
}
发现这里其实还有一个播放器的最大渲染帧率的转换逻辑,如果合成的帧率比PagPlayer的目标帧率还高,需要根据间隔去做采样为播放器的最大帧率。这个在低端设备上应该会对性能会有一些提升,能够更大程度的利用缓存。核心的pagComposition->setProgressInternal(realProgress);是实现在PagLayer内的,它会通过progress计算出当前应该播放的时间,然后调用gotoTimeAndNotifyChanged方法:
bool PAGLayer::gotoTimeAndNotifyChanged(int64_t targetTime) {auto changed = gotoTime(targetTime);if (changed) {notifyModified();}return changed;
}
顾名思义,先Seek到指定的时间,然后如果发现图层需要更新(核心是一个_stretchedFrameDuration,这个是在AE插件里面保存的值,如果是静态图之类的,会和duration相同,更新progress不需要改变内容),则会调用notifyModified去通知有更新,我们看看里面的实现:
void PAGLayer::notifyModified(bool contentChanged) {if (contentChanged) {contentVersion++;}auto parentLayer = getParentOrOwner();while (parentLayer) {parentLayer->contentVersion++;parentLayer = parentLayer->getParentOrOwner();}
}
可以看到首先把自己的contentVersion做了自增,然后如果有父图层以及父图层更新contentVersion,我们这里本身是根图层更新,不会涉及parent。下一次渲染的时候会对比这个contentVersion和上一次的是否一致,如果一致的话,就不需要重新绘制了,通过这个version来避免额外性能损耗。
渲染过程
渲染过程的流程主要是分为:
- 组织渲染 – 主要是通过调用Canvas的一些方法,把所有渲染相关的指令组织起来,保存到上下文内
- 执行渲染 – 把上面组织起来的所有渲染相关的指令flush到GPU内,完成一次渲染
- 上屏渲染 – 等待渲染操作完成,把渲染完成的Buffer上屏到显示设备上
我这里先画一个简单的类图,把里面涉及到的大致的概念呈现出来,让大家有一个简单的认识。把里面的一些主要概念的关系画出来,也包含了里面的一些功能说明。

组织渲染
Pag执行渲染的方法叫做flush,就是把当前设置的这些配置要给执行了。Flush的实现核心是调用了flushInternal方法:
bool PAGPlayer::flushInternal(BackendSemaphore* signalSemaphore) {...prepareInternal();clock.mark("rendering");if (!pagSurface->draw(renderCache, lastGraphic, signalSemaphore, _autoClear)) {return false;}...return true;
}
我们这里省略了大部分其他代码,直接看了两个最重要的prepareInternal和pagSurface->draw()调用就可以了。
prepareInternal的实现如下:
void PAGPlayer::prepareInternal() {// 为了提升性能,预加载加载视频和图片renderCache->prepareLayers();// 通过contentVersion来判断stage是否有刷新,没有刷新的话就不用去重新渲染了if (contentVersion != stage->getContentVersion()) {// 更新当前的渲染内容版本号contentVersion = stage->getContentVersion();Recorder recorder = {};// 难道在这里就渲染了?并不是哦,只是组织图层到recorder里面stage->draw(&recorder);lastGraphic = recorder.makeGraphic();}if (lastGraphic) {lastGraphic->prepare(renderCache);}
}
可以看到这里在判断需要刷新stage的时候有个stage->draw(&recorder);调用,stage代码如下:
void PAGComposition::draw(Recorder* recorder) {... // 这里省略缓存策略auto preComposeLayer = static_cast<PreComposeLayer*>(layer);auto composition = preComposeLayer->composition;... // 这里省略位图或者视频策略,Clip和判空逻辑auto count = static_cast<int>(layers.size());// 遍历所有的图层,然后挨个调用DrawChildLayerfor (int i = 0; i < count; i++) {auto& childLayer = layers[i];if (!childLayer->layerVisible) {continue;}DrawChildLayer(recorder, childLayer.get());}... // 省略Clip逻辑
}
这个方法核心其实就是遍历所有的childLayer,然后挨个调用DrawChildLayer把每一层存入Recorder内,我们看看DrawChildLayer的代码:
void PAGComposition::DrawChildLayer(Recorder* recorder, PAGLayer* childLayer) {// 图层的特效Modifierauto filterModifier = childLayer->cacheFilters() ? nullptr : FilterModifier::Make(childLayer);// 多点追踪使用的,暂时可以不用理会auto trackMatte = TrackMatteRenderer::Make(childLayer);Transform extraTransform = {ToTGFX(childLayer->layerMatrix), childLayer->layerAlpha};LayerRenderer::DrawLayer(recorder, childLayer->layer,childLayer->contentFrame + childLayer->layer->startTime, filterModifier,trackMatte.get(), childLayer, &extraTransform);
}
看到这个代码有点晕了,开始有TGFX的影子了。这里核心是调用静态函数LayerRenderer::DrawLayer:
void LayerRenderer::DrawLayer(Recorder* recorder, Layer* layer, Frame layerFrame,std::shared_ptr<FilterModifier> filterModifier,TrackMatte* trackMatte, Content* layerContent,Transform* extraTransform) {if (TransformIllegal(extraTransform) || TrackMatteIsEmpty(trackMatte)) {return;}auto contentFrame = layerFrame - layer->startTime;// 这里比较核心返回一个layoutCache,里面有包含各种图层类型的渲染内容缓存的实现。auto layerCache = LayerCache::Get(layer);if (!layerCache->contentVisible(contentFrame)) {return;}auto content = layerContent ? layerContent : layerCache->getContent(contentFrame);... //省略alpha,Blend, 多点追踪逻辑auto saveCount = recorder->getSaveCount();... // 省略其他Transferm,Mask等逻辑// 核心draw逻辑content->draw(recorder);recorder->restoreToCount(saveCount);... // 省略多点追踪逻辑recorder->restore();
}
可以看到这里核心流程就是通过 auto layerCache = LayerCache::Get(layer); 创建/获取了一个LayerCache。然后执行LayerCache的content的draw方法到recorder对象内。看看LayerCache::Get的代码:
LayerCache* LayerCache::Get(Layer* layer) {std::lock_guard<std::mutex> autoLock(layer->locker);if (layer->cache == nullptr) {layer->cache = new LayerCache(layer);}return static_cast<LayerCache*>(layer->cache);
}
LayerCache::LayerCache(Layer* layer) : layer(layer) {switch (layer->type()) {case LayerType::Shape:contentCache = new ShapeContentCache(static_cast<ShapeLayer*>(layer));break;case LayerType::Text:contentCache = new TextContentCache(static_cast<TextLayer*>(layer));break;case LayerType::Solid:contentCache = new SolidContentCache(static_cast<SolidLayer*>(layer));break;case LayerType::Image:contentCache = new ImageContentCache(static_cast<ImageLayer*>(layer));break;case LayerType::PreCompose:contentCache = new PreComposeContentCache(static_cast<PreComposeLayer*>(layer));break;default:contentCache = new EmptyContentCache(layer);break;}contentCache->update();transformCache = new TransformCache(layer);if (!layer->masks.empty()) {maskCache = new MaskCache(layer);}updateStaticTimeRanges();maxScaleFactor = ToTGFX(layer->getMaxScaleFactor());
}
其实核心就是通过ContentCache类型分别创建GraphicContent类型。这个GraphicContent是一个用于具体实现不同类型的图形的结构了。有一点像Android里面的View。接下来调用了核心的content.draw(recorder)把需要渲染的GraphicsContent存入到我们的Recorder内。
void Recorder::drawGraphic(std::shared_ptr<Graphic> graphic) {auto content = Graphic::MakeCompose(std::move(graphic), matrix);if (content == nullptr) {return;}if (layerIndex == 0) {rootContents.push_back(content);} else {layerContents.push_back(content);}
}
从这里也说明了这些函数虽然叫做drawXXX但是在这一步并没有真正的执行任何渲染相关的指令。
接下来回到一开始的prepareInternal,我们已经分析了这里通过这个Recorder保存了渲染需要用的content。prepareInternal最后做的事情就是通过这个recorder再生成一个具体用于渲染的Graphic对象,并且再prepare这个Graphic:
lastGraphic = recorder.makeGraphic();if (lastGraphic) {lastGraphic->prepare(renderCache);}
这个lastGraphic是一个LayerGraphic,而下一步lastGraphic->prepare才真正的是prepare要渲染的内容的。LayerGraphic是一个树形结构的包装对象,和Android里面的ViewGroup十分类似。其prepare也就是深度遍历这个渲染树,把所有的节点都prepare一遍。
void LayerGraphic::prepare(RenderCache* cache) const {for (auto& content : contents) {content->prepare(cache);}
}
针对不同的Content,会有不同的prepare过程。比如对图片的内容来说,就可以在这里去获取解码好的图片,如果没有解码好需要等待解码完成,视频也需要在这里等这个时间的帧解码好才能去做渲染。
渲染核心过程
组织渲染指令
准备工作看完了,我们这里开始来深入分析一下这个pagSurface->draw。先上代码,这里我加上了注释:
bool PAGSurface::draw(RenderCache* cache, std::shared_ptr<Graphic> graphic,BackendSemaphore* signalSemaphore, bool autoClear) {// 之前提到过,这里的drawable代表的是一个抽象的GPU渲染实例(GPUDrawable/OffscreenDrawable等),并不是做具体绘制的实例。if (!drawable->prepareDevice()) {return false;}// 获取用于渲染的上下文,这里拿到的是GLContextauto context = lockContext();if (!context) {return false;}if (surface != nullptr && autoClear && contentVersion == cache->getContentVersion()) {unlockContext();return false;}// 如果Surface为空,则创建。这里的Surface是指的TGFX内的if (surface == nullptr) {surface = drawable->createSurface(context);}if (surface == nullptr) {unlockContext();return false;}contentVersion = cache->getContentVersion();cache->attachToContext(context);auto canvas = surface->getCanvas();if (autoClear) {canvas->clear();}if (graphic) {// 核心渲染的操作,会生成draw callgraphic->draw(canvas, cache);}// 这里具体去执行draw call,把CPU内组合的渲染操作(Op最终同步到GPU内if (signalSemaphore == nullptr) {// 同步模式下直接flush操作surface->flush();} else {// 这里多了异步渲染模式下的同步锁操作。tgfx::GLSemaphore semaphore = {};surface->flush(&semaphore);signalSemaphore->initGL(semaphore.glSync);}cache->detachFromContext();drawable->setTimeStamp(pagPlayer->getTimeStampInternal());drawable->present(context);unlockContext();return true;
}
上面最核心的是两个调用。一个是生成DrawCall的
if (graphic) {graphic->draw(canvas, cache);}
最终会把在prepareInternal里面生成的所有Content调用draw来生成这个content当前状态对应的OpenGL渲染指令集。我们这里用绘制一个Shape来举例:
void Shape::draw(tgfx::Canvas* canvas, RenderCache* renderCache) const {tgfx::Paint paint;auto snapshot = renderCache->getSnapshot(this);if (snapshot) {...// 这里省略了使用缓存的逻辑 ...}paint.setShader(shader);canvas->drawPath(path, paint);
}
是不是和我们在Android里面的drawPath很像?这里的canvas的实现是GLCanvas:
void GLCanvas::fillPath(const Path& path, const Paint& paint) {...// 注意这里,创建了一个GLDrawOpauto op = MakeSimplePathOp(path, glPaint, state->matrix);if (op) {draw(std::move(op), std::move(glPaint));return;}...op = GLTriangulatingPathOp::Make(glPaint.color, tempPath, state->clip.getBounds(), localMatrix);if (op) {save();resetMatrix();draw(std::move(op), std::move(glPaint));restore();return;}...drawMask(deviceBounds, mask->makeTexture(getContext()), std::move(glPaint));
}
我们这里省略了很多代码,基本可以看到流程就是创建GLDrawOp,在里面设置一堆参数,最后调用draw或者drawMask(最终也是调用到了draw),我们来看看这个draw方法:
void GLCanvas::draw(std::unique_ptr<GLDrawOp> op, GLPaint paint, bool aa) {if (drawContext == nullptr) {return;}// 设置抗锯齿类型auto aaType = AAType::None;if (static_cast<GLSurface*>(surface)->renderTarget->sampleCount() > 1) {aaType = AAType::MSAA;} else if (aa && !IsPixelAligned(op->bounds())) {aaType = AAType::Coverage;} else {const auto& matrix = state->matrix;auto rotation = std::round(RadiansToDegrees(atan2f(matrix.getSkewX(), matrix.getScaleX())));if (static_cast<int>(rotation) % 90 != 0) {aaType = AAType::Coverage;}}// 设置Maskauto masks = std::move(paint.coverageFragmentProcessors);Rect scissorRect = Rect::MakeEmpty();auto clipMask = getClipMask(op->bounds(), &scissorRect);if (clipMask) {masks.push_back(std::move(clipMask));}// 设置渲染区域op->setScissorRect(scissorRect);// 设置Blend图层叠加模式unsigned first;unsigned second;if (BlendAsCoeff(state->blendMode, &first, &second)) {op->setBlendFactors(std::make_pair(first, second));} else {op->setXferProcessor(PorterDuffXferProcessor::Make(state->blendMode));op->setRequireDstTexture(!GLCaps::Get(getContext())->frameBufferFetchSupport);}op->setAA(aaType);// 配置颜色op->setColors(std::move(paint.colorFragmentProcessors));op->setMasks(std::move(masks));// 添加到渲染队列drawContext->addOp(std::move(op));
}基本的核心配置我已经在代码里给了注释。这个地方特别重要,属于渲染的核心流程,所以代码我没有省略。
这里设置了一些Paint的通用配置,然后加入到绘制的上下文drawContext->addOp(std::move(op));
void SurfaceDrawContext::addOp(std::unique_ptr<Op> op) {getOpsTask()->addOp(std::move(op));
}
很简单,其实就是把当前这一个Content的Op添加到opsTask列表里面了。说明这里其实还没有具体去执行这些OpenGL指令。值得注意的是这个getOpsTask里面有一个很重要的操作:
OpsTask* SurfaceDrawContext::getOpsTask() {if (opsTask == nullptr || opsTask->isClosed()) {replaceOpsTask();}return opsTask.get();
}void SurfaceDrawContext::replaceOpsTask() {opsTask = surface->getContext()->drawingManager()->newOpsTask(surface);
}
这个opsTask是通过replaceOpsTask里面的surface->getContext()->drawingManager()->newOpsTask(surface);创建的。这样就会被DrawingManager所管理起来,之后再被统一执行。
执行渲染
上面基本就把准备渲染的opTask准备好了。其实渲染的准备工作是最重要的,执行渲染只是把前面存放的即将用于渲染的指令具体去执行罢了。
if (signalSemaphore == nullptr) {surface->flush();} else {tgfx::GLSemaphore semaphore = {};surface->flush(&semaphore);signalSemaphore->initGL(semaphore.glSync);}
很明显这里面的这个Surface->flush就是渲染具体执行的地方了。里面的代码很简单:
bool Surface::flush(Semaphore* signalSemaphore) {// 解析渲染的目标。因为Pag支持设置渲染到纹理上,不一定都是上屏,所以这里会手动插入一个配置Target的TaskrenderTarget->getContext()->drawingManager()->newTextureResolveRenderTask(this);// 这里把之前保存的opTask都执行了return renderTarget->getContext()->drawingManager()->flush(signalSemaphore);
}
我们看看这里核心调用的DrawingManager->flush具体是做哪些事:
bool DrawingManager::flush(Semaphore* signalSemaphore) {auto* gpu = context->gpu();closeAllTasks();activeOpsTask = nullptr;for (auto& task : tasks) {task->execute(gpu);}removeAllTasks();return context->caps()->semaphoreSupport && gpu->insertSemaphore(signalSemaphore);
}
可以看到这里的核心就是会把之前所有的GLCanvas执行的opTask都执行一遍,然后再清空这个tasks列表。这样就完成了渲染指令的具体执行了。
上屏渲染
在PagSurface的draw最后几段代码如下:
drawable->setTimeStamp(pagPlayer->getTimeStampInternal());drawable->present(context);
一开始的时候提到过,Pag里面的Drawable其实是一个渲染设备的封装。这个present在最后会调用到OpenGL的swapbuffer函数,将前面的所有操作交换缓冲区实现上屏到具体的渲染Target。这里我们就不具体去分析了。
总结
今天这个文章里面的代码比较多了,有一点乱,而且这里只是一次渲染,还没有讲到Pag如何管理渲染的缓存,实现上一期讲的纵向分层,水平分块把性能提升的。如果要深入理解建议自己去Debug到Pag的流程里面才能真正的了解内部渲染的执行过程,能够学到更多的东西。
相关文章:
Pag的2D渲染执行流程
Pag的渲染 背景 根据Pag文章里面说的,Pag之前长时间使用的Skia库作为底层渲染引擎。但由于Skia库体积过大,为了保证通用型(比如兼容CPU渲染)做了很多额外的事情。所以Pag的工程师们自己实现了一套2D图形框架替换掉Skiaÿ…...

k8s 概念说明,k8s面试题
什么是Kubernetes? Kubernetes是一种开源容器编排系统,可自动化应用程序的部署、扩展和管理。 Kubernetes 中的 Master 组件有哪些? Kubernetes 中的 Master 组件包括 API Server、etcd、Scheduler 和 Controller Manager。 Kubernetes 中的…...

Docker--(四)--搭建私有仓库(registry、harbor)
私有仓库----registry官方提供registry仓库管理(推送、删除、下载)私有仓库----harbor私有镜像仓库1.私有仓库----registry官方提供 Docker hub官方已提供容器镜像registry,用于搭建私有仓库 1.1 镜像拉取、运行、查看信息、测试 (一) 拉取镜像 # dock…...

Invalid <url-pattern> [sso.action] in filter mapping
Tomcat 8.5.86版本启动web项目报错Caused by: java.lang.IllegalArgumentException: Invalid <url-pattern> [sso.action] in filter mapping 查看项目的web.xml文件相关片段 <filter-mapping><filter-name>SSOFilter</filter-name><url-pattern&g…...

【11】linux命令每日分享——useradd添加用户
大家好,这里是sdust-vrlab,Linux是一种免费使用和自由传播的类UNIX操作系统,Linux的基本思想有两点:一切都是文件;每个文件都有确定的用途;linux涉及到IT行业的方方面面,在我们日常的学习中&…...
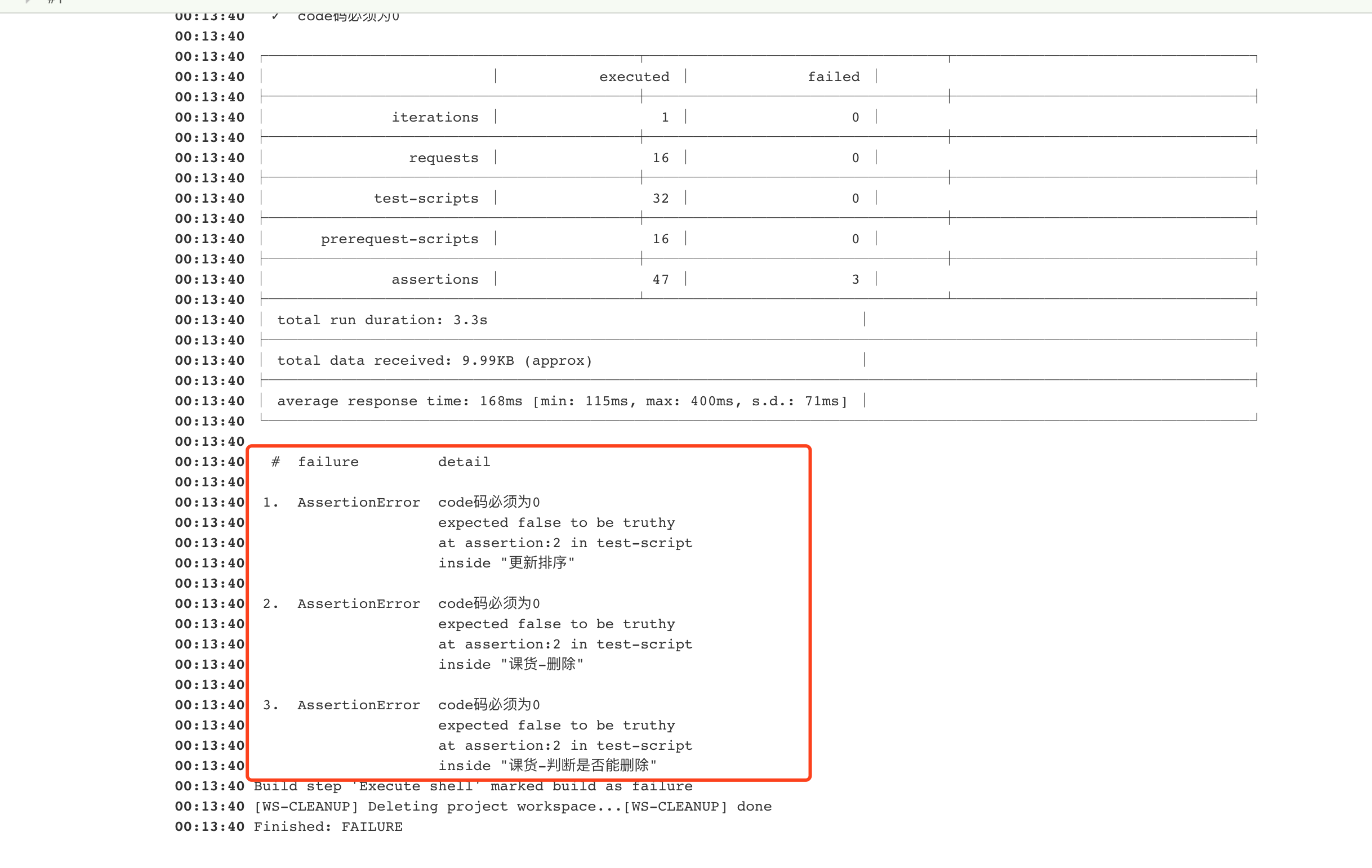
Newman+Jenkins实现接口自动化测试
一、是什么Newman Newman就是纽曼手机这个经典牌子,哈哈,开玩笑啦。。。别当真,简单地说Newman就是命令行版的Postman,查看官网地址。 Newman可以使用Postman导出的collection文件直接在命令行运行,把Postman界面化运…...
MySQL:事务+@Transactional注解
事务 本章从了解为什么需要事务到讲述事务的四大特性和概念,最后讲述MySQL中的事务使用语法以及一些需要注意的性质。 再额外讲述一点Springboot中Transactional注解的使用。 1.为什么需要事务? 我们以用户转账为例,假设用户A和用户B的银行账…...
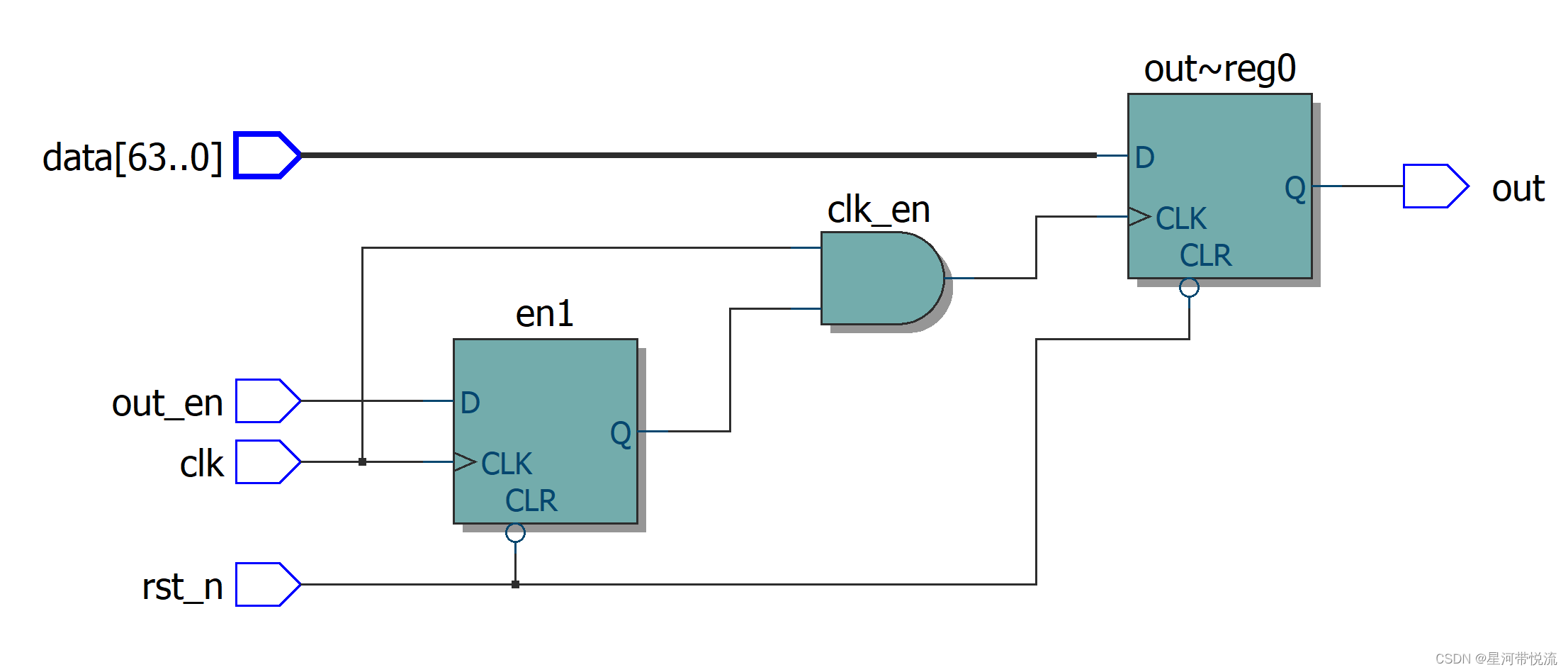
数字IC手撕代码--低功耗设计 Clock Gating
背景介绍芯片功耗组成中,有高达 40%甚至更多是由时钟树消耗掉的。这个结果的原因也很直观,因 为这些时钟树在系统中具有最高的切换频率,而且有很多时钟 buffer,而且为了最小化时钟 延时,它们通常具有很高的驱动强度。 …...

易基因|m6A RNA甲基化研究的数据挖掘思路:干货系列
大家好,这里是专注表观组学十余年,领跑多组学科研服务的易基因。关于m6A甲基化研究思路(1)整体把握m6A甲基化图谱特征:m6A peak数量变化、m6A修饰基因数量变化、单个基因m6A peak数量分析、m6A peak在基因元件上的分布…...

【微信小程序】-- 页面配置(十八)
💌 所属专栏:【微信小程序开发教程】 😀 作 者:我是夜阑的狗🐶 🚀 个人简介:一个正在努力学技术的CV工程师,专注基础和实战分享 ,欢迎咨询! &…...

玩好 StarRocks,大厂 offer 接不完!|字节跳动、小红书、京东物流、唯品会、腾讯音乐要的就是你!
求职黄金季即将到来,你准备好迎接你的 dream offer 了吗?StarRocks 自创立以来,一直主张为用户创造极速统一的数据分析新范式,让数据驱动创新,而优秀的大数据人才对推动创新有着至关重要的作用。因此,我们推…...
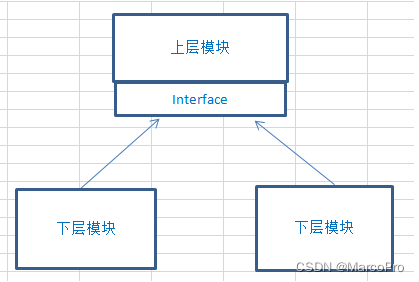
C# IoC控制反转学习笔记
一、什么是IOC IoC-Invertion of Control,即控制反转,是一种程序设计思想。 先初步了解几个概念: 依赖(Dependency):就是有联系,表示一个类依赖于另一个类。 依赖倒置原则(DIP&a…...
Python解题 - CSDN周赛第33期
本期四道题全考过,题解在网上也都搜得到。。。没有想法,顺手水一份题解吧。 第一题:奇偶排序 给定一个存放整数的数组,重新排列数组使得数组左边为奇数,右边为偶数。 输入描述:第一行输入整数n。(1<n<…...

Session攻击
Session攻击Session攻击简介主要攻击方式会话预测会话劫持中间人攻击会话固定Session攻击简介 Session对于Web应用是最重要的,也是最复杂的。对于Web应用程序来说,加强安全性的首要原则就是:不要信任来自客户端的数据,一定要进行数据验证以及…...
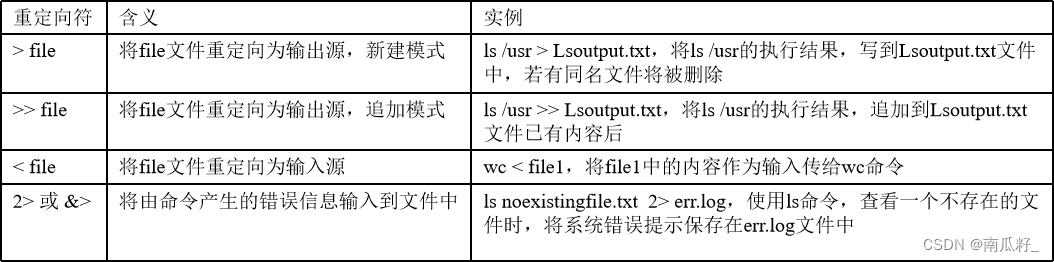
【Linux】Shell详解
😊😊作者简介😊😊 : 大家好,我是南瓜籽,一个在校大二学生,我将会持续分享Java相关知识。 🎉🎉个人主页🎉🎉 : 南瓜籽的主页…...

汉字找不同隐私协议
本隐私信息保护政策版本:2021 V1 一、重要提示 请您(以下亦称“用户”)在使用本平台App时仔细阅读本协议之全部条款,并确认您已完全理解本协议之规定,尤其是涉及您的重大权益及义务的加粗或划线条款。如您对协议有任…...

CEC2017:斑马优化算法(Zebra Optimization Algorithm,ZOA)求解cec2017(提供MATLAB代码)
一、斑马优化算法 斑马优化算法(Zebra Optimization Algorithm,ZOA)Eva Trojovsk等人于2022年提出,其模拟斑马的觅食和对捕食者攻击的防御行为。 斑马因身上有起保护作用的斑纹而得名。没有任何动物比斑马的皮毛更与众不同。斑…...

【Linux要笑着学】进程创建 | 进程终止 | slab分派器
爆笑教程《看表情包学Linux》👈 猛戳订阅!💭 写在前面:本章我们主要讲解进程的创建与终止。首先讲解进程创建,fork 函数是我们早在讲解 "进程的概念" 章节就提到过的一个函数&#…...

数据资产管理建设思考(二)
关于数据资产管理,近两年是数据治理行业中一个热点话题,当然有我们前面提到的国家的政策支持及方向指引的原因。另一方面我们做数据治理的同行们从学习吸收国外优秀的数据治理理论,进一步在实践中思考如何应用理论,并结合我们国家…...

微软发布多模态版ChatGPT!取名“宇宙一代”
文|CoCo酱Ludwig Wittgenstein曾说过:“我语言的局限,即是我世界的局限”。大型语言模型(LLM)已成功地作为各种自然语言任务的通用接口,只要我们能够将输入和输出转换为文本,就可以将基于LLM的接…...

从怀疑到真香!2026年我亲测十多款语音识别转文字app只留这一个
开完2小时讨论会,你要花3小时逐句整理纪要?采访了3个受访者,你戴耳机听一天录音,还漏了一半核心观点?做方言访谈,转出来的文字驴唇不对马嘴,你还要返工重听? 这些磨人的痛点…...
)
告别手敲!手把手教你给STM32CubeIDE 1.3.0装上Keil同款代码补全插件(附成品包)
5分钟极速配置:为STM32CubeIDE注入Keil级代码补全能力 从Keil切换到STM32CubeIDE的开发者,最不适应的莫过于代码补全功能的缺失。每次输入变量名时手动敲击完整字符的体验,让开发效率大打折扣。本文将分享一种无需Java基础、无需手动编译的插…...
)
航模老鸟的‘省钱’秘籍:一块BB响如何守护你的多块锂电池(附设置误区避坑)
航模电池管理的低成本智慧:BB响的进阶使用策略 在航模和无人机领域,电池管理一直是玩家们关注的焦点。对于拥有多块电池的资深爱好者或小型工作室来说,如何在保证安全的前提下优化成本,是一个值得深入探讨的话题。传统做法是为每块…...

知网AI率80%降到15%教程,比话降AI知网算法专精+售后保障!
知网AI率80%降到15%教程,比话降AI知网算法专精售后保障! 如果你是硕博毕业生、学校送知网检测、答辩前查出 AI 率 80%——这篇文章直接给你完整操作教程。从「拿到 80% 报告」到「学校送审通过」的完整路径,每一步该做什么、花多少时间、花多…...

Kotlin ViewModel
Kotlin ViewModel 全流程指南 ViewModel 的核心作用是以注重生命周期的方式存储和管理界面相关的数据。它最伟大的地方在于:当手机屏幕旋转(配置更改)导致 Activity 重建时,ViewModel 中的数据不会丢失。 大纲 添加依赖创建 View…...

边缘计算中的AI优先设计:从芯片选型到模型部署的实战指南
1. 项目概述:为什么“AI优先”是边缘计算的必然选择 最近和几个做硬件和嵌入式开发的老朋友聊天,话题总绕不开一个词:AIoT。大家的感觉很一致,现在的项目要是没沾点“智能”的边,好像都不好意思拿出手。但真做起来&…...

如何用猫抓浏览器扩展轻松捕获在线视频资源?一个实用工具的全方位指南
如何用猫抓浏览器扩展轻松捕获在线视频资源?一个实用工具的全方位指南 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 当你在浏览器中观…...
)
从Arduino到STM32:GRBL固件选型、下载与刷写全攻略(2024版)
从Arduino到STM32:2024年GRBL固件选型与刷写实战指南 在DIY激光雕刻机和CNC设备的构建过程中,控制器的选择与GRBL固件的配置往往是决定项目成败的关键环节。面对市场上琳琅满目的硬件平台——从经典的Arduino Uno到性能更强的STM32系列开发板࿰…...

告别Surface“幽灵触控”:从现象溯源到一劳永逸的修复指南
1. 什么是Surface"幽灵触控"? 如果你正在使用Surface设备,突然发现屏幕某个区域莫名其妙地自动点击,或者部分触控功能完全失灵,恭喜你遇到了传说中的"幽灵触控"问题。这个现象最早在Surface Pro 4上被大量报告…...

STM32F103软件模拟IIC驱动0.96寸OLED:从零搭建与界面交互优化
1. 硬件准备与接线指南 拿到STM32F103核心板和0.96寸OLED模块时,我第一反应是翻看引脚定义。这块4针OLED通常采用IIC接口,接线其实特别简单,只需要4根线:VCC、GND、SCL、SDA。但要注意供电电压,我刚开始用5V供电结果屏…...