Hive实战:词频统计
文章目录
- 一、实战概述
- 二、提出任务
- 三、完成任务
- (一)准备数据文件
- 1、在虚拟机上创建文本文件
- 2、将文本文件上传到HDFS指定目录
- (二)实现步骤
- 1、启动Hive Metastore服务
- 2、启动Hive客户端
- 3、基于HDFS文件创建外部表
- 4、查询单词表,所有单词成一列
- 5、基于查询结果创建视图
- 6、基于视图进行分组统计
- 7、基于嵌套查询一步搞定
一、实战概述
-
在本次实战中,我们任务是在大数据环境下使用Hive进行词频统计。首先,我们在master虚拟机上创建了一个名为
test.txt的文本文件,内容包含一些关键词的句子。接着,我们将该文本文件上传到HDFS的/hivewc/input目录,作为数据源。 -
随后,我们启动了Hive Metastore服务和Hive客户端,为数据处理做准备。在Hive客户端中,我们创建了一个名为
t_word的外部表,该表的结构包含一个字符串类型的word字段,并将其位置设置为HDFS中的/hivewc/input目录。这样,Hive就可以直接读取和处理HDFS中的文本数据。 -
为了进行词频统计,我们编写了一条Hive SQL语句。该语句首先使用
explode和split函数将每个句子拆分为单个单词,然后通过子查询对这些单词进行计数,并按单词进行分组,最终得到每个单词的出现次数。 -
通过执行这条SQL语句,我们成功地完成了词频统计任务,得到了预期的结果。这个过程展示了Hive在大数据处理中的强大能力,尤其是对于文本数据的分析和处理。同时,我们也注意到了在使用Hive时的一些细节,如子查询需要取别名等,这些经验将对今后的数据处理工作有所帮助。
二、提出任务
- 文本文件
test.txt
hello hadoop hello hive
hello hbase hello spark
we will learn hadoop
we will learn hive
we love hadoop spark
- 进行词频统计,结果如下
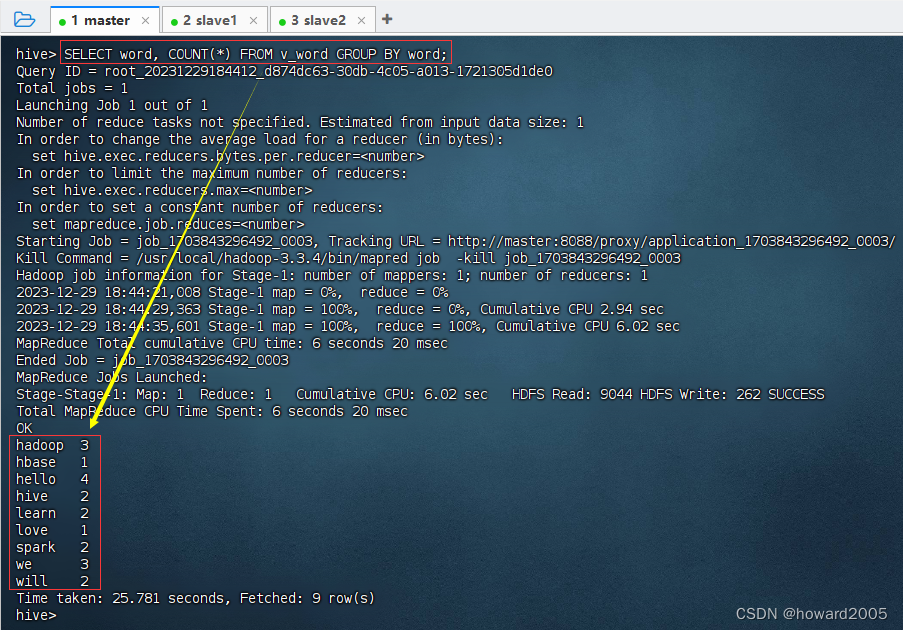
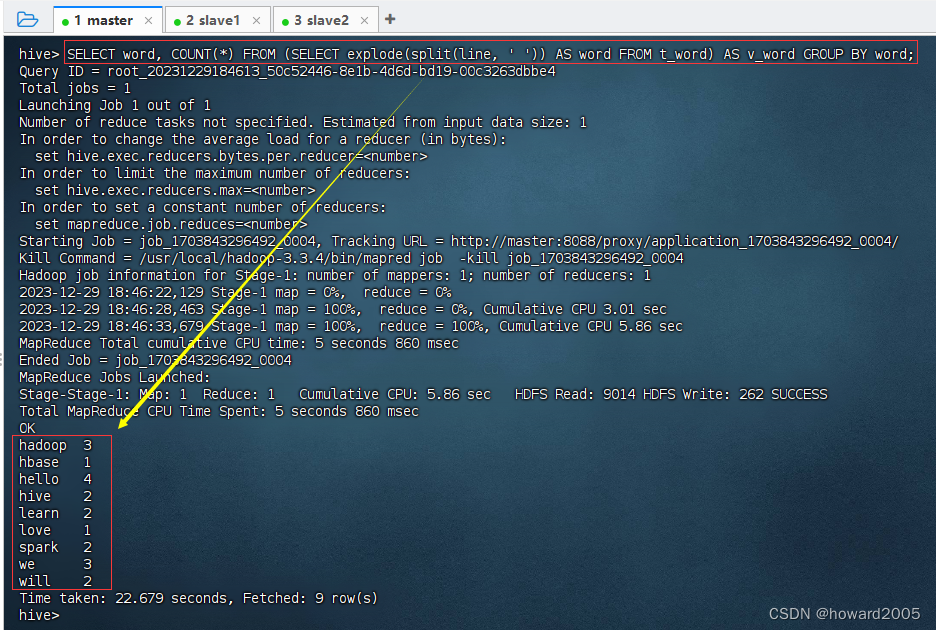
hadoop 3
hbase 1
hello 4
hive 2
learn 2
love 1
spark 2
we 3
will 2
三、完成任务
(一)准备数据文件
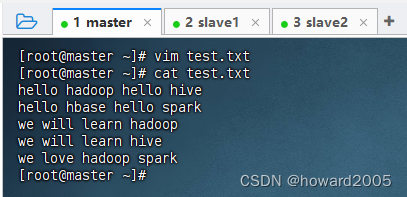
1、在虚拟机上创建文本文件
- 在master虚拟机上创建
test.txt文件
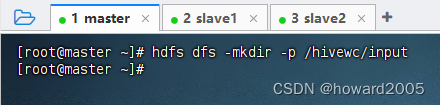
2、将文本文件上传到HDFS指定目录
- 在HDFS上创建
/hivewc/input目录
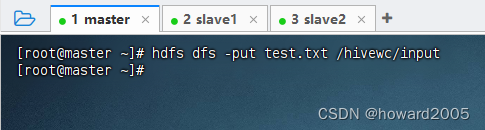
- 将
test.txt文件上传到HDFS的/hivewc/input目录
(二)实现步骤
- 注意:必须要先启动Hadoop服务
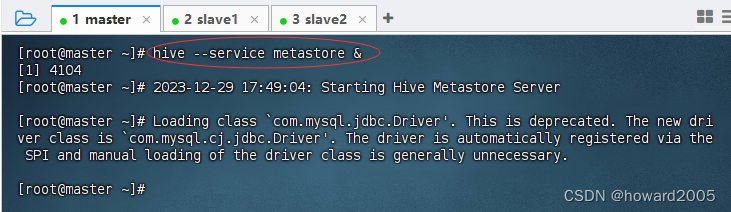
1、启动Hive Metastore服务
- 我们需要启动Hive Metastore服务,这是Hive的元数据存储服务。
- 执行命令:
hive --service metastore &
2、启动Hive客户端
- 执行命令:
hive
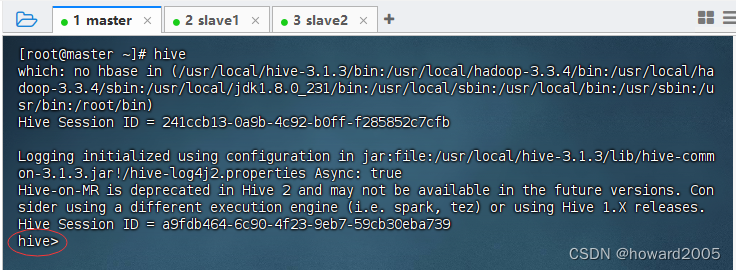
- 一旦我们看到命令提示符
hive>,就表示我们已经成功进入Hive客户端。
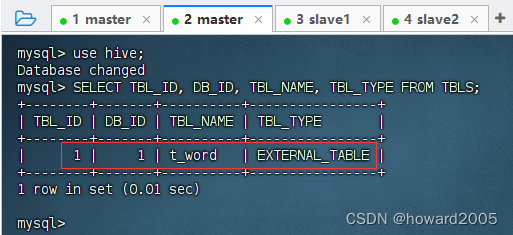
3、基于HDFS文件创建外部表
-
基于
/hivewc/input下的文件创建外部表t_word,执行命令:CREATE EXTERNAL TABLE t_word(line string) LOCATION '/hivewc/input';

-
在MySQL的
hive数据库的TBLS表里,我们可以查看外部表t_word对应的记录。
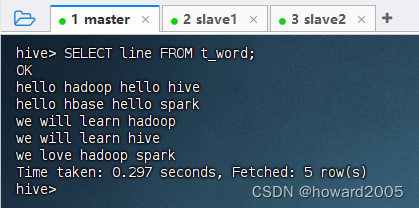
4、查询单词表,所有单词成一列
-
查看单词表记录,执行语句:
SELECT line FROM t_word;
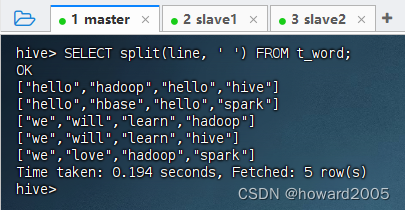
-
按空格拆分行数据,执行语句:
SELECT split(line, ' ') FROM t_word;
-
让单词成一列,执行语句:
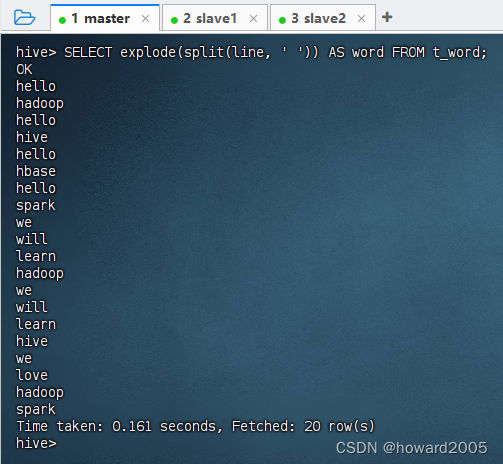
SELECT explode(split(line, ' ')) AS word FROM t_word;
5、基于查询结果创建视图
-
基于查询结果创建了一个视图
v_word,执行语句:CREATE VIEW v_word AS SELECT explode(split(line, ' ')) AS word FROM t_word;

-
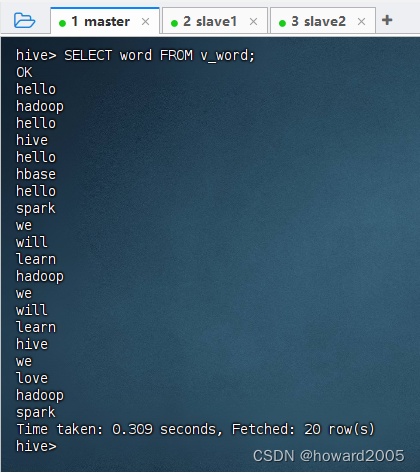
查询视图的全部记录,执行语句:
SELECT word FROM v_word;
6、基于视图进行分组统计
- 基于视图分组统计操作,执行语句:
SELECT word, COUNT(*) FROM v_word GROUP BY word;
7、基于嵌套查询一步搞定
-
为了更简便地实现相同的效果,使用嵌套查询:
SELECT word, COUNT(*) FROM (SELECT explode(split(line, ' ')) AS word FROM t_word) AS v_word GROUP BY word;
-
注意,这里在嵌套查询中,我们为子查询取了一个别名,这个别名是
v_word。 -
这条SQL语句是在处理一个名为
t_word的表,该表中有一个word字段,该字段存储的是由空格分隔的单词字符串。
-
首先,使用
explode(split(line, ' ')) AS word从t_word表中的每一行word字段创建一个新的临时表(别名v_word)。这里split(word, ' ')函数将每个word字段的内容按照空格分割成多个单词,并生成一个多行的结果集,每行包含一个单词。 -
explode函数则将这个分割后的数组转换为多行记录,即每一行对应原字符串中的一个单词。 -
然后,通过
GROUP BY word对新生成的临时表v_word中的word字段进行分组,即将所有相同的单词归为一组。 -
最后,使用
COUNT(*)统计每个单词分组的数量,结果将展示每个单词及其在原始数据集中出现的次数。
-
整个查询的目的在于统计
t_word表中各个单词出现的频率。 -
通过这一系列的操作,我们深入学习了Hive的外部表创建、数据加载、查询、视图创建以及统计分析的操作。希望大家能够在实际应用中灵活运用这些知识。
相关文章:
Hive实战:词频统计
文章目录 一、实战概述二、提出任务三、完成任务(一)准备数据文件1、在虚拟机上创建文本文件2、将文本文件上传到HDFS指定目录 (二)实现步骤1、启动Hive Metastore服务2、启动Hive客户端3、基于HDFS文件创建外部表4、查询单词表&a…...
FairyGUI-Cocos Creator官方Demo源码解读
博主在学习Cocos Creator的时候,发现了一款免费的UI编辑器FairyGUI。这款编辑器的能力十分强大,但是网上的学习资源比较少,坑比较多,主要学习方式就是阅读官方文档和练习官方Demo。这里博主进行官方Demo的解读。 从gitee上克隆项目…...
LabVIEW利用视觉引导机开发器人精准抓取
LabVIEW利用视觉引导机开发器人精准抓取 本项目利用单目视觉技术指导多关节机器人精确抓取三维物体的技术。通过改进传统的相机标定方法,结合LabVIEW平台的Vision Development和Vision Builder forAutomated Inspection组件,优化了摄像系统的标定过程&a…...

【Linux】指令(本人使用比较少的)——笔记(持续更新)
文章目录 ps -axj:查看进程ps -aL:查看线程echo $?:查看最近程序的退出码jobs:查看后台运行的线程组fd 任务号:将后台任务提到前台bg 任务号:将暂停的后台程序重启netstat -nltp:查看服务及监听…...

032 - STM32学习笔记 - TIM基本定时器(一) - 定时器基本知识
032 - STM32学习笔记 - TIM定时器(一) - 基本定时器知识 这节开始学习一下TIM定时器功能,从字面意思上理解,定时器的基本功能就是用来定时,与定时器相结合,可以实现一些周期性的数据发送、采集等功能&#…...
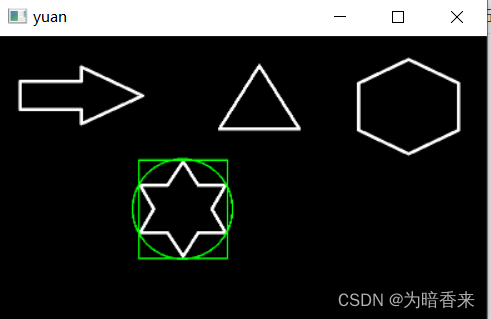
轮廓检测与处理
轮廓检测 先将图像转换成二值 gray cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 灰度图 ret, thresh cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY) # 变为二值,大于127置为255,小于100置为0.使用cv2.findContours(thresh, cv2.RETR_TREE, cv2.…...

跟着LearnOpenGL学习11--材质
文章目录 一、材质二、设置材质三、光的属性四、不同的光源颜色 一、材质 在现实世界里,每个物体会对光产生不同的反应。 比如,钢制物体看起来通常会比陶土花瓶更闪闪发光,一个木头箱子也不会与一个钢制箱子反射同样程度的光。 有些物体反…...
Java guava partition方法拆分集合自定义集合拆分方法
日常开发中,经常遇到拆分集合处理的场景,现在记录2中拆分集合的方法。 1. 使用Guava包提供的集合操作工具栏 Lists.partition()方法拆分 首先,引入maven依赖 <dependency><groupId>com.google.guava</groupId><artifa…...
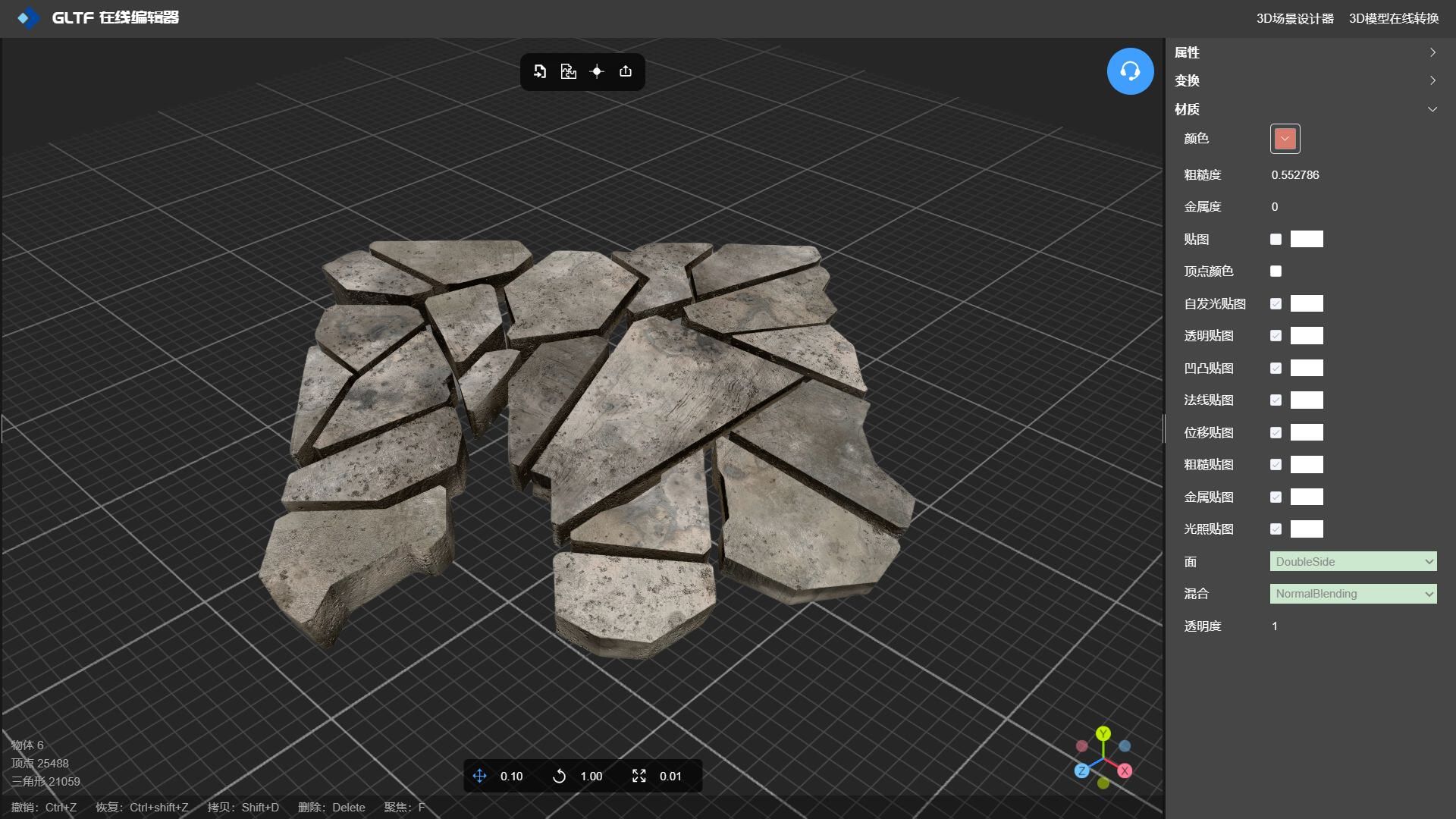
GLTF编辑器-位移贴图实现破碎的路面
在线工具推荐: 3D数字孪生场景编辑器 - GLTF/GLB材质纹理编辑器 - 3D模型在线转换 - Three.js AI自动纹理开发包 - YOLO 虚幻合成数据生成器 - 三维模型预览图生成器 - 3D模型语义搜索引擎 位移贴图是一种可以用于增加模型细节和形状的贴图。它能够在渲染时针…...

多维时序 | MATLAB实现SSA-BiLSTM麻雀算法优化双向长短期记忆神经网络多变量时间序列预测
多维时序 | MATLAB实现SSA-BiLSTM麻雀算法优化双向长短期记忆神经网络多变量时间序列预测 目录 多维时序 | MATLAB实现SSA-BiLSTM麻雀算法优化双向长短期记忆神经网络多变量时间序列预测预测效果基本介绍程序设计参考资料 预测效果 基本介绍 1.MATLAB实现SSA-BiLSTM麻雀算法优化…...

docker安装Nacos和Rabbitmq
一、安装Nacos 首先需要拉取对应的镜像文件:(切换版本加上对应版本号即可,默认最新版) docker pull nacos/nacos-server 接着挂载目录: mkdir -p /mydata/nacos/logs/ #新建logs目录 mkdir -p …...
Android MVC 写法
前言 Model:负责数据逻辑 View:负责视图逻辑 Controller:负责业务逻辑 持有关系: 1、View 持有 Controller 2、Controller 持有 Model 3、Model 持有 View 辅助工具:ViewBinding 执行流程:View >…...
网络层解读
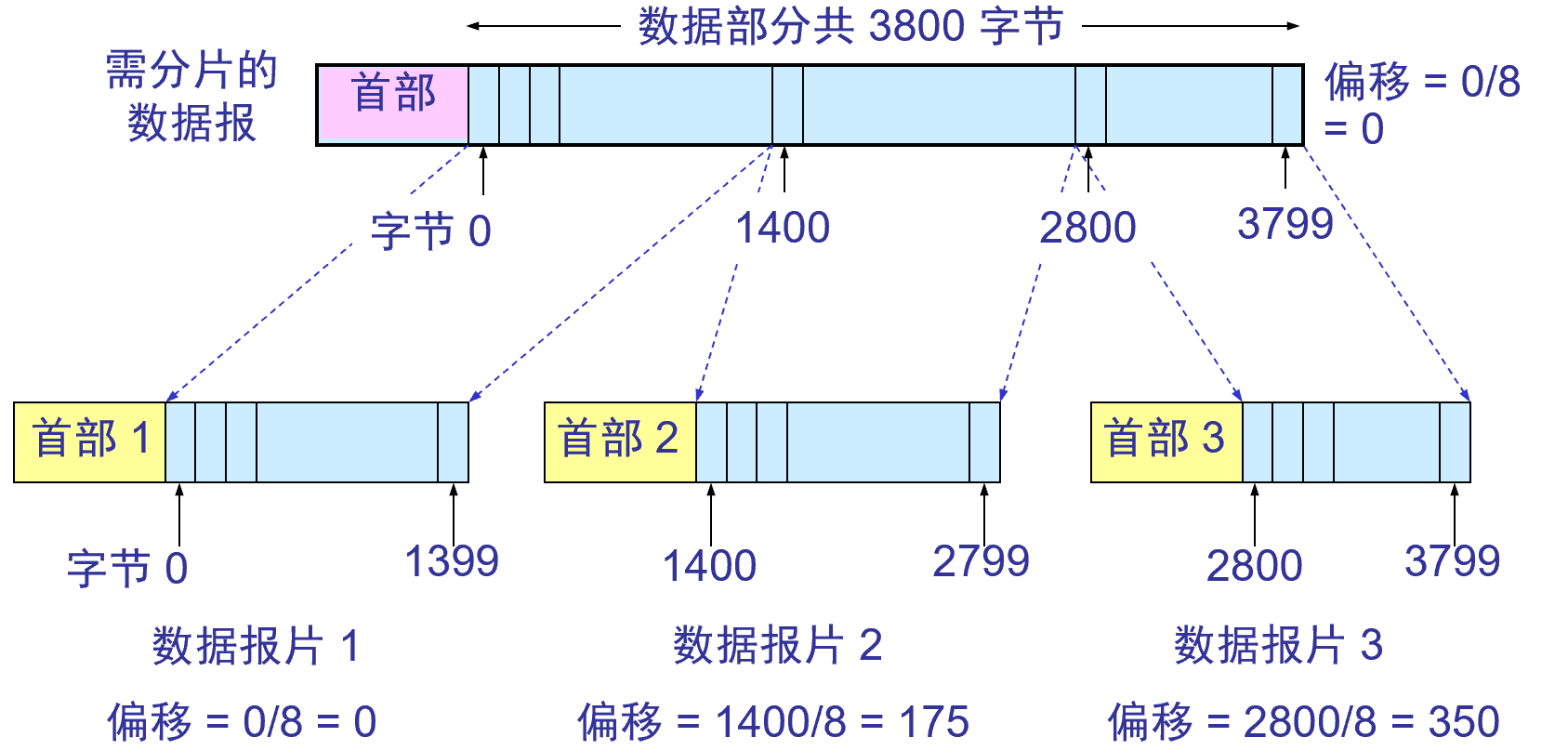
基本介绍 概述 当两台主机之间的距离较远(如相隔几十或几百公里,甚至几千公里)时,就需要另一种结构的网络,即广域网。广域网尚无严格的定义。通常是指覆盖范围很广(远超过一个城市的范围)的长距离的单个网络。它由一些结点交换机以及连接这些…...
js for和forEach 跳出循环 替代方案
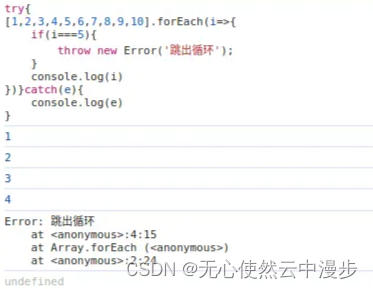
1 for循环跳出 for(let i0;i<10;i){if(i5){break;}console.log(i) }在函数中也可以return跳出循环 function fn(){for(let i0;i<10;i){if(i5){return;}console.log(i)} } fn()for ... of效果同上 2 forEach循环跳出 break会报错 [1,2,3,4,5,6,7,8,9,10].forEach(i>…...
如何使用ArcGIS Pro自动矢量化建筑
相信你在使用ArcGIS Pro的时候已经发现了一个问题,那就是ArcGIS Pro没有ArcScan,在ArcGIS Pro中,Esri确实已经移除了ArcScan,没有了ArcScan我们如何自动矢量化地图,从地图中提取建筑等要素呢,这里为大家介绍…...
交互式笔记Jupyter Notebook本地部署并实现公网远程访问内网服务器
最近,我发现了一个超级强大的人工智能学习网站。它以通俗易懂的方式呈现复杂的概念,而且内容风趣幽默。我觉得它对大家可能会有所帮助,所以我在此分享。点击这里跳转到网站。 文章目录 1.前言2.Jupyter Notebook的安装2.1 Jupyter Notebook下…...
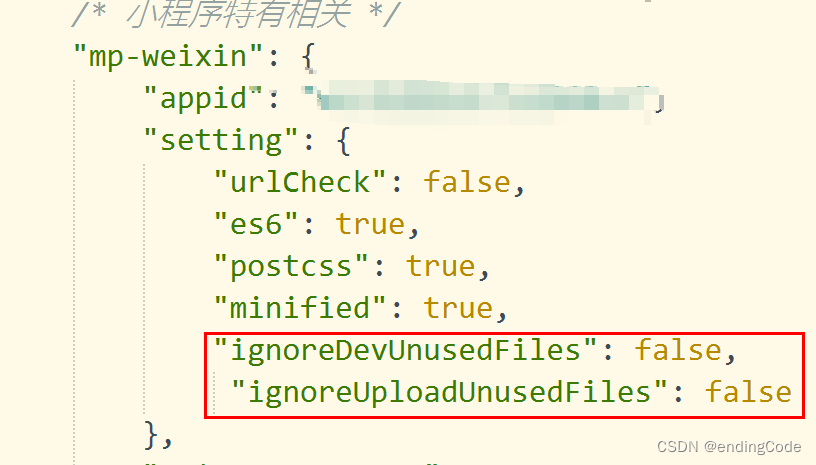
41.坑王驾到第七期:uniapp开发微信小程序引用组件时报错!
一、错误再现 页面login引用了一个组件register,运行至小程序开发工具报错。 xxx.js 已被代码依赖分析忽略,无法被其他模块引用。 二、解决办法 在微信小程序的配置文件中找到setting节点,增加两个配置项。 “ignoreDevUnusedFiles”: fa…...

挂载与解挂载
一. 挂载 1.什么是挂载 将系统中的文件夹和磁盘做上关联,使用文件夹等于使用磁盘 2.mount 2.1 格式 mount [ -t 类型 ] 存储设备 挂载点目录 mount -o loop ISO镜像文件 挂载点目录 注意:指明要挂载的设备 设备文件:例如:/dev/sda5 卷…...

UGUI Panel的显示和隐藏优化
unity UI如何开启(显示)或者关闭(隐藏)Panel界面,相信大家都是知道的,但是如何做最好呢? 可能大家一般开启/关闭界面的方法就是直接SetActive吧。这样做通常是可以的,简答快速地解决…...

Linux:多文件编辑
多文件编辑 1.使用vim编辑多个文件 编辑多个文件有两种形式,一种是在进入vim前使用的参数就是多个文件。另一种就是进入vim后再编辑其他的文件。 同时创建两个新文件并编辑 $ vim 1.txt 2.txt默认进入1.txt文件的编辑界面 命令行模式下输入:n编辑2.txt文件&…...

GitHub加速实战指南:突破国内访问瓶颈的高效方案
GitHub加速实战指南:突破国内访问瓶颈的高效方案 【免费下载链接】Fast-GitHub 国内Github下载很慢,用上了这个插件后,下载速度嗖嗖嗖的~! 项目地址: https://gitcode.com/gh_mirrors/fa/Fast-GitHub 对于国内开发者而言&a…...
)
从学生到工程师:我如何用大学单片机课设代码搞定第一个嵌入式项目(STM8实战)
从学生到工程师:STM8实战中如何将课设代码升级为工业级解决方案 记得大三那年,我第一次在实验室里点亮STM8开发板的LED时,那种成就感至今难忘。但当我真正进入企业参与嵌入式项目开发时,才发现学校里的"标准答案"在真实…...

Naftis架构设计原理:从Golang后端到React前端的完整技术栈
Naftis架构设计原理:从Golang后端到React前端的完整技术栈 【免费下载链接】naftis An awesome dashboard for Istio built with love. 项目地址: https://gitcode.com/gh_mirrors/na/naftis Naftis是一款专为Istio服务网格设计的现代化Web仪表板,…...

VMware Unlocker:免费解锁VMware的macOS虚拟机支持终极指南
VMware Unlocker:免费解锁VMware的macOS虚拟机支持终极指南 【免费下载链接】unlocker VMware Workstation macOS 项目地址: https://gitcode.com/gh_mirrors/unloc/unlocker 想在Windows或Linux电脑上运行macOS虚拟机,却发现VMware根本不提供苹…...

基于Claude的多智能体代码编排框架:原理、实战与优化
1. 项目概述:当Claude遇上代码编排最近在GitHub上看到一个挺有意思的项目,叫0ldh/claude-code-agents-orchestra。光看名字,就能嗅到一股“组合拳”的味道——Claude、Code、Agents、Orchestra,这几个词凑在一起,指向性…...

群晖DSM 7.2.2视频站恢复指南:三步搞定Video Station完整功能
群晖DSM 7.2.2视频站恢复指南:三步搞定Video Station完整功能 【免费下载链接】Video_Station_for_DSM_722 Script to install Video Station in DSM 7.2.2 and DSM 7.3 项目地址: https://gitcode.com/gh_mirrors/vi/Video_Station_for_DSM_722 还在为升级到…...

终极AI图像分层工具LayerDivider:3分钟完成复杂插画自动分层
终极AI图像分层工具LayerDivider:3分钟完成复杂插画自动分层 【免费下载链接】layerdivider A tool to divide a single illustration into a layered structure. 项目地址: https://gitcode.com/gh_mirrors/la/layerdivider 在数字设计创作中,您…...

关键词覆盖不足,图标点击率低于行业均值18.7%?Gemini ASO深度调优全链路拆解
更多请点击: https://intelliparadigm.com 第一章:Gemini App Store优化的现状与挑战 生态碎片化加剧分发效率瓶颈 当前 Gemini App Store 尚未建立统一的开发者认证、审核策略与版本兼容性规范,导致应用在不同 Gemini 原生设备(…...

Windows热键冲突终极解决方案:3分钟找出占用你快捷键的“小偷“
Windows热键冲突终极解决方案:3分钟找出占用你快捷键的"小偷" 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detect…...

第八部分-企业级实践——36. CI/CD 集成
36. CI/CD 集成 1. CI/CD 概述 CI/CD(持续集成/持续部署)与 Docker 结合,可以实现代码提交后自动构建镜像、测试、部署的完整流程,大幅提升开发效率和发布质量。 ┌──────────────────────────────…...