【Flink SQL API体验数据湖格式之paimon】
前言
随着大数据技术的普及,数据仓库的部署方式也在发生着改变,之前在部署数据仓库项目时,首先想到的是选择国外哪家公司的产品,比如:数据存储会从Oracle、SqlServer中或者Mysql中选择,ETL工具会从Informatica、DataStage或者Kettle中选择,BI报表工具会从IBM cognos、Sap Bo或者帆软中选择,基本上使用的产品组合都类似,但随着数据量的激增,之前的部署方式已经越来越不能满足业务场景,例如:不同格式的数据存储,传出的数据库无法存储,而且随着数量的增多,数据库的响应速度就会下降,并且数据大都是T+1的,往往从业务需求的提交到BI报表开发都需要一段时间,等BI报表开发后,数据的时效性大大降低,无法为业务的决策及时性提供帮助,后来随着hadoop的流行,数据仓库慢慢的就演变为以hadoop为基础存储的大数据仓库,并解决了传统数仓无法承载激增数据量的问题,并且随着计算引擎的迭代更新,现在也能实现数据的实时性和事务性,本篇就以新起之秀的数据存储方式来展开介绍。
提示:以下案例仅供参考
一、paimon是什么?
paimon是一种基于LSM形式的数据湖存储格式,与hudi、iceberg定位相同,都是一种基于对hdfs文件存储管理的技术,flink与hudi和iceberg都有做过集成,但hudi和iceberg相当于spark的功能更为完善,这些数据湖格式也都更偏向于批处理,而相对于flink来说,提供的功能相较于spark来说,没有那么完善,虽然flink针对这些方面有做过努力尝试,但结果都不太理想,于是,flink基于前者的有点,自己创造一种数据湖存储格式,其基于flink table store的基础,在结合其他开源数据湖格式的特点加以改进,于是一种新的数据湖格式paimon就诞生了,本人也是最近才开始尝试这种新的数据湖格式的一些功能,下面是基于sql api编写的一个简单的例子。
二、Fink SQL API方式编程
1.创建kafka流标
我这边是以yarn-session的方式执行的,所以首先启动的session,cd $FLINK_HOME,执行bin/yarn-session -d -nm test创建一个名称为test的session会话,随后执行bin/sql-client -s yarn-session进入sql客户端,直接使用默认的catalog和database,执行下面的DDL语句,就会在default_catalog.default_database下创建一个kafka_table表
create temporary table `kafka_table`(
`distinct_id` string,
`login_id` string,
`anonymous_id` string,
`type` string,
`event` string,
`_track_id` string,
`time` string,
`_flush_time` string,
`device_id` string,
`project_id` string,
`map_id` string,
`user_id` string,
`recv_time` string) with('connector'='kafka','topic'='event_topic','properties.group.id'='testgroup','properties.bootstrap.servers'='cdp1:9092','scan.startup.mode'='latest-offset','format'='json');
2.创建paimon append表
接着执行如下DDL语句
CREATE TABLE paimon_append (
`distinct_id` string,
`login_id` string,
`anonymous_id` string,
`type` string,
`event` string,
`_track_id` string,
`time` string,
`_flush_time` string,
`device_id` string,
`project_id` string,
`map_id` string,
`user_id` string,
`recv_time` string
) PARTITIONED BY (`distinct_id`)
WITH (
'bucket' = '-1'
);
3.数据导入
SET ‘execution.checkpointing.interval’ = ‘1 min’;
INSERT INTO paimon_append SELECT * FROM kafka_table;
总结
以上就是一个消费kafka主题数据,并每隔一定的间接直接,写入到paimon表中,paimon会对小文件数据量达到一定程度后,对文件进行压缩合并,并且paimon也支持merge into、update、以及schema evolution等功能,由于时间有限,这里就不仔细展开了,有兴趣的朋友,可以亲自尝试下,版本目标已经更新到0.7,为flink的生态状态又增加了一环,目前flink cdc 、paimon的加持、能很好的解决lamda架构数据不一致,以及kappa架构数据追溯的问题,相信随着后续版本的迭代更多强大的功能也会推出。
相关文章:

【Flink SQL API体验数据湖格式之paimon】
前言 随着大数据技术的普及,数据仓库的部署方式也在发生着改变,之前在部署数据仓库项目时,首先想到的是选择国外哪家公司的产品,比如:数据存储会从Oracle、SqlServer中或者Mysql中选择,ETL工具会从Informa…...
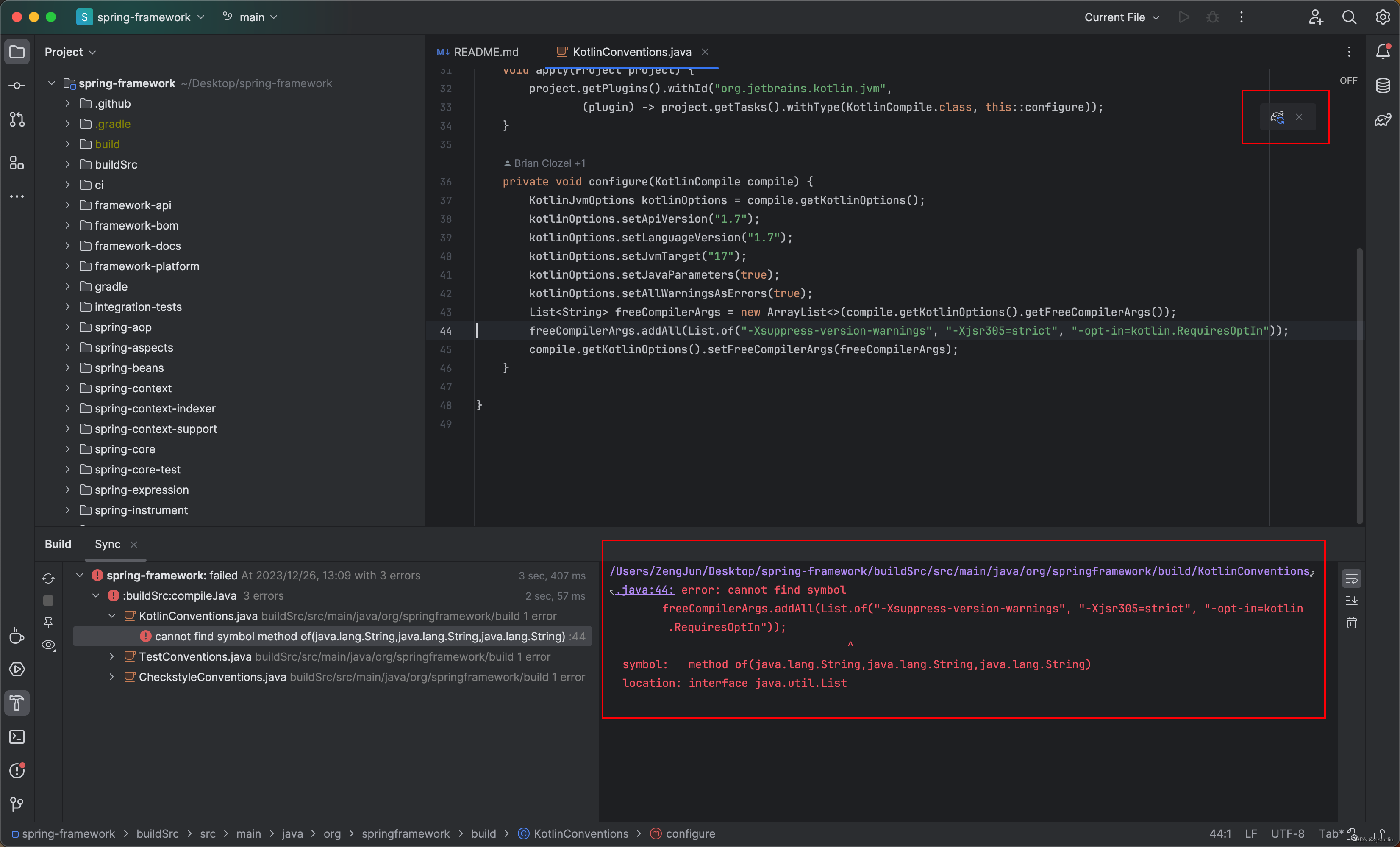
idea导入spring-framework异常:error: cannot find symbol
从github上clone代码spring-framework到本地后导入idea,点击gradle构建后控制台提示异常: 具体异常信息: /Users/ZengJun/Desktop/spring-framework/buildSrc/src/main/java/org/springframework/build/KotlinConventions.java:44: error:…...
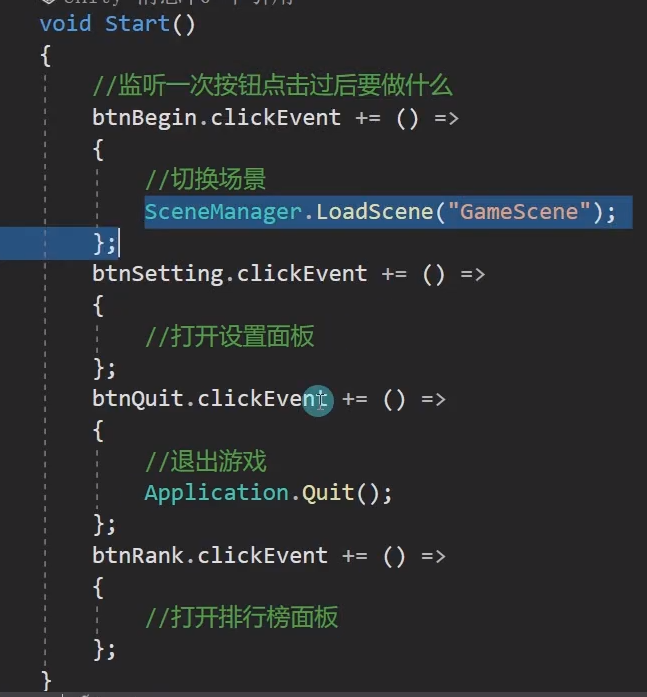
Unity坦克大战开发全流程——开始场景——开始界面
开始场景——开始界面 step1:设置UI 反正按照这张图拼就行了 step2:写脚本 前面的拼UI都是些比较机械化的工作,直到这里写代码的时候才真正开始有点意思了,从这里开始,我们就要利用面向对象的思路来进行分析࿱…...

【SpringCloud】从实际业务问题出发去分析Eureka-Server端源码
文章目录 前言1.EnableEurekaServer2.初始化缓存3.jersey应用程序构建3.1注册jeseryFilter3.2构建JerseyApplication 4.处理注册请求5.registry() 前言 前段时间遇到了一个业务问题就是k8s滚动发布Eureka微服务的过程中接口会有很多告警,当时…...
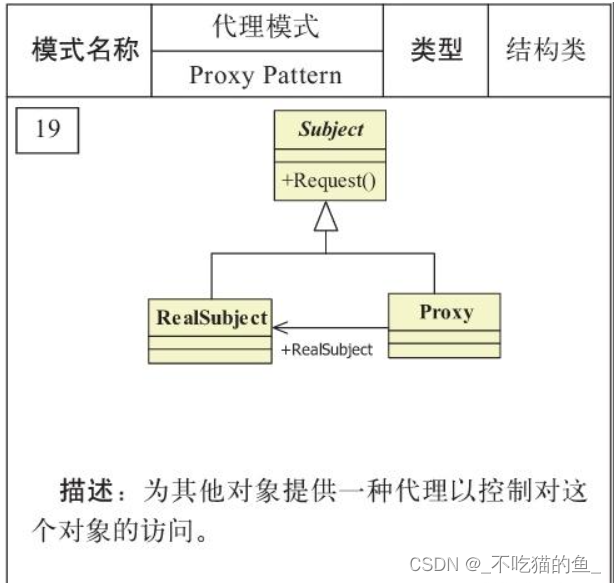
Java 代理模式
一、代理模式概述 代理模式是一种比较好理解的设计模式。简单来说就是 我们使用代理对象来代替对真实对象(real object)的访问,这样就可以在不修改原目标对象的前提下,提供额外的功能操作,扩展目标对象的功能。 代理模式的主要作用是扩展目标…...
【Java干货教程】JSON,JSONObject,JSONArray类详解
一、定义 JSON:就是一种轻量级的数据交换格式,被广泛应用于WEB应用程序开发。JSON的简洁和清晰的层次结构,易于阅读和编写;同时也易于机器解析和生成,有效的提升网络传输效率;支持多种语言,很多…...
2023年高级软考系统架构师考题参考
对于一些有实践经验的同学来说,感觉不难,但是落笔到纸面上,就差强人意了,平时这方面要多练习,所想所思要落到纸面上,或者表达清晰让别人听懂,不仅是工作中的一个基本素质,也是个非常…...

【c语言】飞机大战(1)
提前准备好游戏要的素材,可以到爱给网去找,飞机大战我们需要的是一个我方战机图片,一个背景图,三个敌方战机的图,我方战机的图片,敌方战机的图片,并且将图片和.cpp放在同一文件夹下. 这里创建.…...
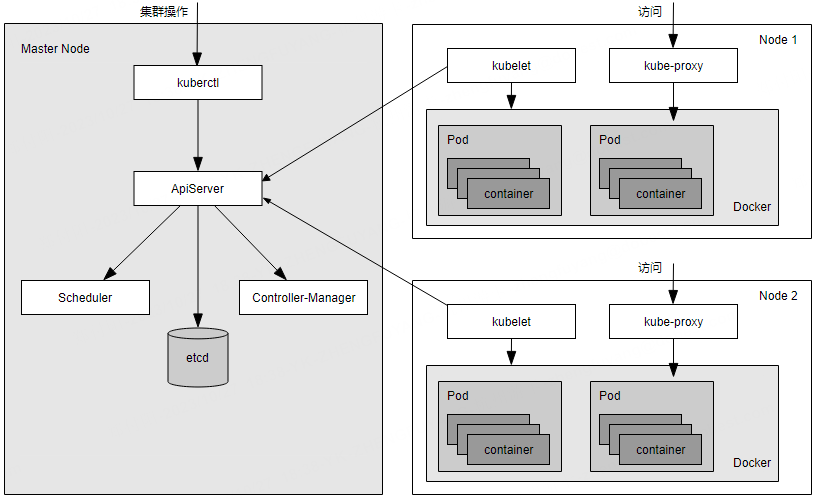
关于 K8s 的一些基础概念整理
〇、前言 Kubernetes,将中间八个字母用数字 8 替换掉简称 k8s,是一个开源的容器集群管理系统,由谷歌开发并维护。它为跨主机的容器化应用提供资源调度、服务发现、高可用管理和弹性伸缩等功能。 下面简单列一下 k8s 的几个特性: 自…...
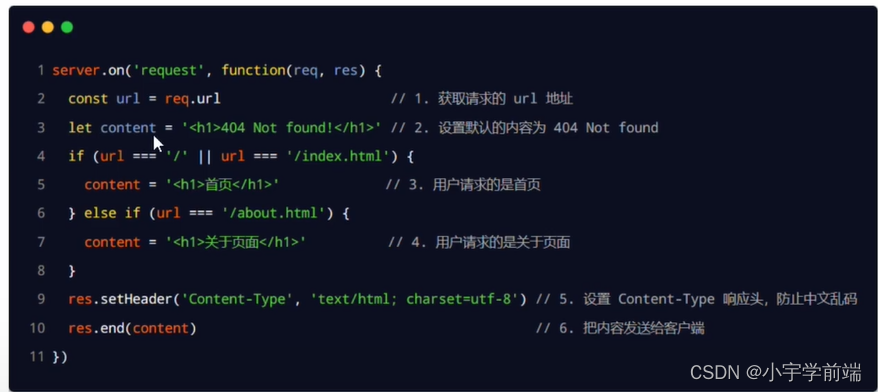
Node.js-fs、path、http模块
1.初识Node.js 1.1 什么是Node.js 1.2 Node.js中的JavaScript运行环境 1.3 Node.js可以做什么 Node.js 作为一个JavaScript 的运行环境,仅仅提供了基础的功能和 AP1。然而,基于 ode.s 提供的这些基础能,很多强大的工具和框架如雨后春笋&…...

CentOS 安装WebLogic
1.JDK 安装 cd /home/ mkdir java cd java/ tar -zxvf jdk-8u321-linux-x64.tar.gzvim /etc/profile添加以下内容到 /etc/profile JAVA_HOME/home/java/jdk1.8.0_321 CLASSPATH.:$JAVA_HOME/lib.tools.jar PATH$JAVA_HOME/bin:$PATH export JAVA_HOME CLASSPATH PATH刷新配置…...

Linux命令的操作练习
1.创建ss别名,查看长格式详细信息 alias ssls -l 2.创建ss别名,复制boot文件夹下的内容到data文件夹下 alias sscp -r /boot /data 3.删除别名ss unalias ss 4. 复制test文件夹下的passwd文件到qq文件夹下,并改名为ww cp test/pas…...
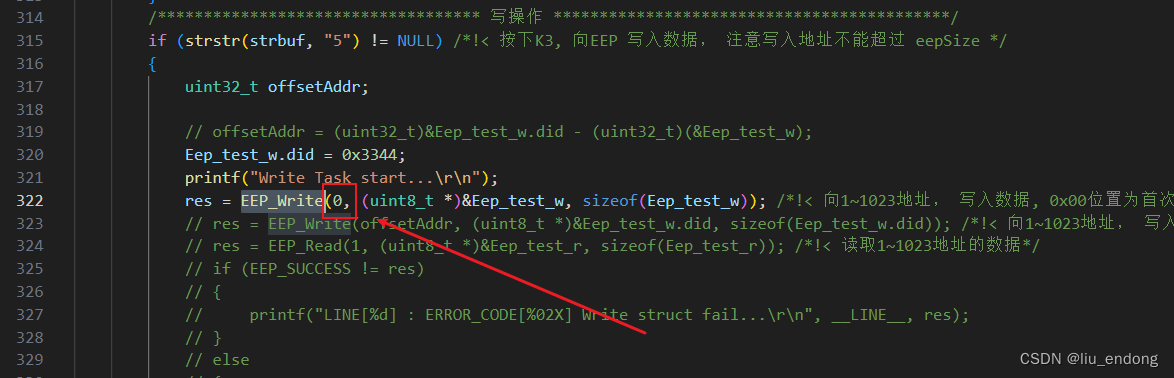
杰发科技AC7840——EEPROM初探
0.序 7840和7801的模拟EEPROM使用不太一样 1.现象 按照官方Demo,在这样的配置下,我们看到存储是这样的(连续三个数字1 2 3)。 使用串口工具的多帧发送功能 看不出多少规律 修改代码后 发现如下规律: 前四个字节是…...
)
WPF 基础入门(简介)
简介 WPF(Windows Presentation Foundation)是微软推出的基于Windows 的用户界面框架,属于.NET Framework 3.0的一部分。它提供了统一的编程模型、语言和框架,真正做到了分离界面设计人员与开发人员的工作;同时它提供了…...

【Unity动画系统】Animator有限状态机参数详解
👨💻个人主页:元宇宙-秩沅 👨💻 hallo 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 👨💻 本文由 秩沅 原创 👨💻 收录于专栏:Uni…...

php获取访客IP、UA、操作系统、浏览器等信息
最近有个需求就是获取下本地的ip地址、网上搜索了相关的教程,总结一下分享给大家、有需要的小伙伴可以参考一下 一、简单的获取 User Agent 信息代码: echo $_SERVER[HTTP_USER_AGENT]; 二、获取访客操作系统信息: /** * 获取客户端操作系统信息,包括win10 * pa…...

基于huffman编解码的图像压缩算法matlab仿真
目录 1.算法运行效果图预览 2.算法运行软件版本 3.部分核心程序 4.算法理论概述 4.1 Huffman编码算法步骤 4.2 Huffman编码的数学原理 4.3 基于Huffman编解码的图像压缩 5.算法完整程序工程 1.算法运行效果图预览 2.算法运行软件版本 matlab2022a 3.部分核心程序 ..…...
python+django网上购物商城系统o9m4k
语言:Python 框架:django/flask可以定制 软件版本:python3.7.7 数据库:mysql 数据库工具:Navicat 开发工具pycharm/vscode都可以 前端框架:vue.js 系统使用过程主要涉及到管理员和用户两种角色,主要包含个…...

面试题-性能优化
前端项目优化: 一般考虑方面: (挑几点记住) 我们学的: 懒加载: 路由、图片懒加载 骨架屏的使用 压缩文件:可以使用压缩工具(如GZIP)对页面文件进行压缩,减小文件大小,提高页面加载速度。 减少HTTP请求&a…...

自身文档管理规范
之前在 这里 叙述了 用 sphinx 生成静态网站, 并利用 静态网络托管服务 readthedocs 现在我们有了新的需求,想知道这些东西到底是什么。 过程 过程A : markdown/rst -> html mkdocs sphinx相关: pandoc(不能生成整个网站的h…...

RePKG架构深度解析:Wallpaper Engine资源逆向工程与高性能转换方案
RePKG架构深度解析:Wallpaper Engine资源逆向工程与高性能转换方案 【免费下载链接】repkg Wallpaper engine PKG extractor/TEX to image converter 项目地址: https://gitcode.com/gh_mirrors/re/repkg RePKG是一款专为Wallpaper Engine设计的C#开源工具&a…...

Spring Cloud微服务里,如何用XXL-JOB搞定订单15分钟未支付自动关闭?
Spring Cloud微服务中基于XXL-JOB的订单超时自动关闭实战方案 电商平台的订单超时自动关闭是一个典型的高并发业务场景。想象一下,当用户下单后未支付,系统需要在15分钟后自动释放库存并关闭订单。传统做法可能采用数据库轮询或延迟队列,但在…...

如何在Blender中实现专业级MMD模型动画制作:5步完整解决方案
如何在Blender中实现专业级MMD模型动画制作:5步完整解决方案 【免费下载链接】blender_mmd_tools MMD Tools is a blender addon for importing/exporting Models and Motions of MikuMikuDance. 项目地址: https://gitcode.com/gh_mirrors/bl/blender_mmd_tools …...

从CentOS迁移到openEuler?手把手教你在vSphere ESXi 7.0上搭建测试环境
从CentOS迁移到openEuler:vSphere ESXi 7.0测试环境全指南当企业技术栈面临升级换代时,系统管理员往往需要在不影响生产环境的前提下进行充分验证。对于长期依赖CentOS/RHEL生态的用户而言,openEuler作为国产开源操作系统的代表,正…...

海外试玩推广渠道汇总
试玩英文名:playable,也叫互动广告,自2017年渐渐进入广告的视线。 与常规的视频广告不同,可试玩广告为用户提供了游戏玩法的片段,是用户与之自愿互动的广告单元,还原游戏原貌,并给用户一个身临…...

PrismLauncher-Cracked常见问题解答:解决安装与使用中的15个难题
PrismLauncher-Cracked常见问题解答:解决安装与使用中的15个难题 【免费下载链接】PrismLauncher-Cracked This project is a Fork of Prism Launcher, which aims to unblock the use of Offline Accounts, disabling the restriction of having a functional Onli…...

HHEML:基于FPGA硬件加速的边缘隐私保护机器学习框架
1. 项目概述:当边缘计算遇上隐私保护,一场硬件加速的革新在医疗影像分析、智能门禁、工业质检这些场景里,你肯定不希望自己的X光片、人脸数据或者生产线上的瑕疵图片,在传到云端服务器做AI推理时,被“有心人”看个精光…...

AhMyth短信管理器:远程读取和发送短信的终极技术指南 [特殊字符]
AhMyth短信管理器:远程读取和发送短信的终极技术指南 🚀 【免费下载链接】AhMyth Cross-Platform Android Remote Administration Tool | The only maintained version of AhMyth on github | A revival of the original repository at https://GitHub.c…...

AI Agent的节能与绿色计算:优化计算资源消耗的算法与策略
AI Agent节能与绿色计算实战:从算法优化到工程落地的全栈减碳指南 摘要/引言 你有没有算过,调用一次GPT-4生成1000字的回答,消耗的电量相当于一个普通家庭LED灯亮3个小时?据国际能源署2024年发布的报告,全球数据中心的年碳排放已经达到12亿吨,占全球总碳排放的2.1%,和…...

强化学习入门第一步:用Python 3.9和Gymnasium 0.28.1搭建你的第一个AI游戏测试台
强化学习入门第一步:用Python 3.9和Gymnasium 0.28.1搭建你的第一个AI游戏测试台想象一下,你正在教一个AI玩电子游戏——不是通过编写复杂的规则,而是让它像人类一样通过试错来学习。这就是强化学习的魅力所在。作为机器学习中最接近人类学习…...