解锁大数据世界的钥匙——Hadoop HDFS安装与使用指南
目录
1、前言
2、Hadoop HDFS简介
3、Hadoop HDFS安装与配置
4、Hadoop HDFS使用
5、结语
1、前言
大数据存储与处理是当今数据科学领域中最重要的任务之一。随着互联网的迅速发展和数据量的爆炸性增长,传统的数据存储和处理方式已经无法满足日益增长的需求。因此,大数据技术应运而生,成为解决海量数据存储和处理问题的重要工具。
在大数据技术中,Hadoop是应用最广泛的框架之一。作为一个开源的分布式计算平台,Hadoop提供了一套可靠、可扩展的解决方案,用于存储和处理大规模数据集。其中,Hadoop分布式文件系统(Hadoop Distributed File System,简称HDFS)是Hadoop的核心组件之一,负责存储和管理海量数据。
本文将探索Hadoop HDFS的安装与使用。我们将从Hadoop的简介开始,逐步介绍HDFS的架构、主要组件以及基本概念。随后,我们将详细讲解如何安装和配置,并介绍如何使用HDFS进行数据的读写操作。
希望本文能够帮助您深入了解Hadoop HDFS,掌握大数据存储与处理的基本技能,为您在大数据领域的工作和研究提供有力支持。让我们开始吧!
2、Hadoop HDFS简介
Hadoop HDFS(Hadoop Distributed File System)是Hadoop生态系统中的一个关键组件,它是一个可扩展的分布式文件系统,用于存储大规模数据集,并能够以高容错性在集群中运行。
HDFS的设计基于Google的GFS(Google File System)论文,并针对大规模的数据处理任务做了一些调整和优化。
HDFS具有以下特点:
-
分布式存储:HDFS将大规模的数据集划分为多个数据块,并将这些数据块存储在集群中的多个节点上,以实现数据的高可靠性和高可扩展性。
-
冗余备份:HDFS会对数据块进行冗余备份,通常默认为3个副本,这样即使某个节点发生故障,数据仍然可以从其他副本中恢复。
-
流式数据访问:HDFS在设计时考虑了大规模数据的批处理特点,支持大规模数据的高吞吐量读写操作。
-
数据本地性:HDFS会将数据块存储在离计算节点最近的存储节点上,以减少网络传输的开销,提高数据访问的效率。
-
支持容错:HDFS具有自动检测和恢复节点故障的能力,能够在节点故障时将备份数据块复制到其他节点上。
HDFS的使用场景包括大规模数据的批处理、数据仓库建设、日志分析等任务。通过使用HDFS,用户可以以分布式、高可靠、高吞吐量的方式存储和处理大规模数据。
3、Hadoop HDFS安装与配置
Hadoop HDFS是Hadoop分布式文件系统的一部分,用于存储大规模数据。以下是安装和配置Hadoop HDFS的详细步骤:
-
安装Java:
- 确保你的系统已经安装了Java。使用
java -version命令来检查Java是否已经安装。
- 确保你的系统已经安装了Java。使用
-
下载Hadoop:
- 访问Hadoop官方网站(http://hadoop.apache.org)下载最新的Hadoop版本。
- 解压下载的文件到你选择的目录中。
-
配置环境变量:
- 打开
~/.bashrc文件,并添加以下内容:export HADOOP_HOME=/path/to/hadoop export PATH=$PATH:$HADOOP_HOME/bin - 使用
source ~/.bashrc来加载配置文件。
- 打开
-
修改Hadoop配置文件:
- 进入Hadoop配置目录:
cd $HADOOP_HOME/etc/hadoop/ - 打开
hadoop-env.sh文件并设置JAVA_HOME变量的路径:export JAVA_HOME=/path/to/java - 打开
core-site.xml文件并配置HDFS:<configuration><property><name>fs.defaultFS</name><value>hdfs://localhost:9000</value></property> </configuration> - 打开
hdfs-site.xml文件并进行以下配置:<configuration><property><name>dfs.replication</name><value>1</value></property> </configuration> - 打开
mapred-site.xml.template文件并保存为mapred-site.xml文件,并进行以下配置:<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property> </configuration> - 打开
yarn-site.xml文件并进行以下配置:<configuration><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property> </configuration>
- 进入Hadoop配置目录:
-
格式化HDFS:
- 打开终端并执行以下命令:
hdfs namenode -format
- 打开终端并执行以下命令:
-
启动HDFS:
- 执行以下命令启动HDFS服务:
start-dfs.sh
- 执行以下命令启动HDFS服务:
-
验证HDFS启动:
- 执行以下命令来检查HDFS是否已经启动:
jps - 如果成功,你应该能够看到
NameNode和DataNode进程。
- 执行以下命令来检查HDFS是否已经启动:
至此,你已经成功安装和配置了Hadoop HDFS。你可以使用HDFS命令行工具来操作HDFS文件系统,例如使用hdfs dfs -put命令来上传文件到HDFS。
4、Hadoop HDFS使用
下面是使用Hadoop HDFS的详细步骤:
-
安装Hadoop:首先需要在机器上安装Hadoop。可以从Hadoop官方网站下载Hadoop压缩包,然后解压缩到所需的目录。
-
配置Hadoop集群:在Hadoop安装目录中,找到
etc/hadoop目录,编辑core-site.xml和hdfs-site.xml文件。-
core-site.xml配置Hadoop核心参数。设置fs.defaultFS为HDFS的URL,例如:hdfs://localhost:9000。 -
hdfs-site.xml配置HDFS参数。设置dfs.replication为数据块的副本数量,例如:3。设置dfs.namenode.name.dir和dfs.datanode.data.dir为HDFS的数据目录,例如:/hadoop/data/nameNode和/hadoop/data/dataNode。
-
-
格式化HDFS:运行以下命令来格式化HDFS,创建必要的目录和文件。
hdfs namenode -format -
启动Hadoop集群:运行以下命令来启动Hadoop集群。
start-dfs.sh这将启动HDFS的NameNode和DataNode进程。
-
检查Hadoop集群状态:运行以下命令来检查Hadoop集群的状态。
jps应该看到NameNode、DataNode和其他Hadoop进程在运行。
-
创建HDFS目录:运行以下命令来创建HDFS中的目录。
hdfs dfs -mkdir /path/to/directory可以替换
/path/to/directory为所需的目录路径。 -
上传文件到HDFS:运行以下命令来将本地文件上传到HDFS中。
hdfs dfs -put /path/to/local/file /path/to/hdfs/directory可以替换
/path/to/local/file为本地文件路径,/path/to/hdfs/directory为HDFS目录路径。 -
下载文件从HDFS:运行以下命令来将HDFS中的文件下载到本地。
hdfs dfs -get /path/to/hdfs/file /path/to/local/directory可以替换
/path/to/hdfs/file为HDFS文件路径,/path/to/local/directory为本地目录路径。 -
浏览HDFS文件:运行以下命令来浏览HDFS中的文件。
hdfs dfs -ls /path/to/hdfs/directory可以替换
/path/to/hdfs/directory为所需的HDFS目录路径。 -
删除HDFS文件:运行以下命令来删除HDFS中的文件。
hdfs dfs -rm /path/to/hdfs/file可以替换
/path/to/hdfs/file为所需的HDFS文件路径。
这些是使用Hadoop HDFS的基本步骤。可以使用Hadoop命令行工具(例如hdfs dfs)或Hadoop API来操作HDFS中的文件和目录。
5、结语
文章至此,已接近尾声!希望此文能够对大家有所启发和帮助。同时,感谢大家的耐心阅读和对本文档的信任。在未来的技术学习和工作中,期待与各位大佬共同进步,共同探索新的技术前沿。最后,再次感谢各位的支持和关注。您的支持是作者创作的最大动力,如果您觉得这篇文章对您有所帮助,请考虑给予一点打赏。



相关文章:
解锁大数据世界的钥匙——Hadoop HDFS安装与使用指南
目录 1、前言 2、Hadoop HDFS简介 3、Hadoop HDFS安装与配置 4、Hadoop HDFS使用 5、结语 1、前言 大数据存储与处理是当今数据科学领域中最重要的任务之一。随着互联网的迅速发展和数据量的爆炸性增长,传统的数据存储和处理方式已经无法满足日益增长的需求。…...

写在2023岁末:敏锐地审视量子计算的当下
本周,《IEEE Spectrum》刊登了一篇出色的文章,对量子计算(QC)的近期前景进行了深入探讨。 文章的目的并不是要给量子计算的前景泼冷水,而是要说明量子计算的前景还很遥远,并提醒读者量子计算的用例可能很窄…...

C/C++学习笔记十三 C++中的重载运算符
1、什么是运算符重载? 运算符重载是 C 中的一项功能,使运算符(例如 、- 等)能够处理用户定义的数据类型。这种机制称为编译时多态性,并提供了为不同数据类型定制运算符行为的优点。 例如,我们可以重载“”运…...

Java 实现自动获取法定节假日
一、背景 在实现业务需求的过程中,遇到了需要计算 x 个工作日后的日期需求。由于工作日是每年国务院发布的,调休和休假都没有规律,所以无法使用算法进行计算。 一般的实现方案是自己维护一个工作日和调休的表,或者去爬取国务院发…...

湘潭大学-2023年下学期-c语言-作业0x0a-综合1
A 求最小公倍数 #include<stdio.h>int gcd(int a,int b) {return b>0?gcd(b,a%b):a; }int main() {int a,b;while(~scanf("%d%d",&a,&b)){if(a0&&b0) break;printf("%d\n",a*b/gcd(a,b));}return 0; }记住最大公约数的函数&…...
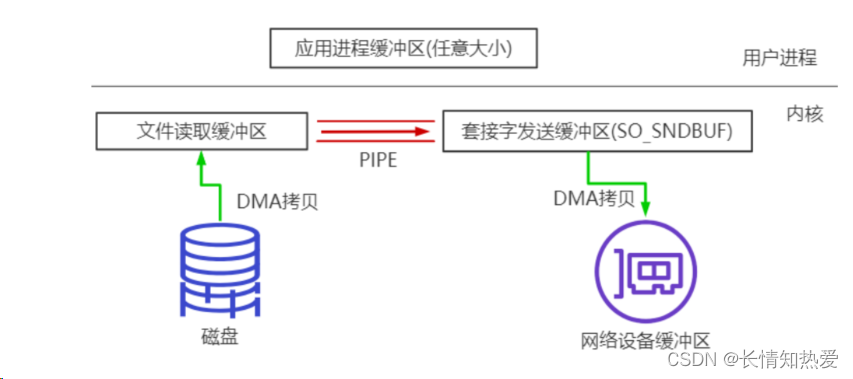
网络协议-BIO实战和NIO编程
网络通信编程基本常识 在开发过程中,如果类的名字有 Server 或者 ServerSocket 的,表示这个类是给服务端容纳网络 服务用的,如果类的名字只包含 Socket 的,那么表示这是负责具体的网络读写的。 ServerSocket 并不负责具体的网络读…...
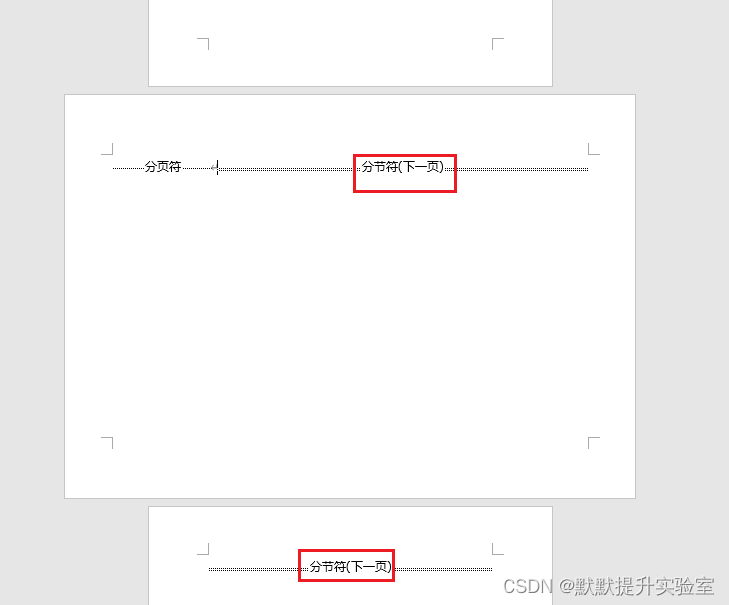
Word 将页面方向更改为横向或纵向
文章目录 更改整个文档的方向更改部分页面的方向方法1:方法2: 参考链接 更改整个文档的方向 选择“布局”>“方向”,选择“纵向”或“横向”。 更改部分页面的方向 需要达到下图结果: 方法1: 选:中你要在横向页面…...
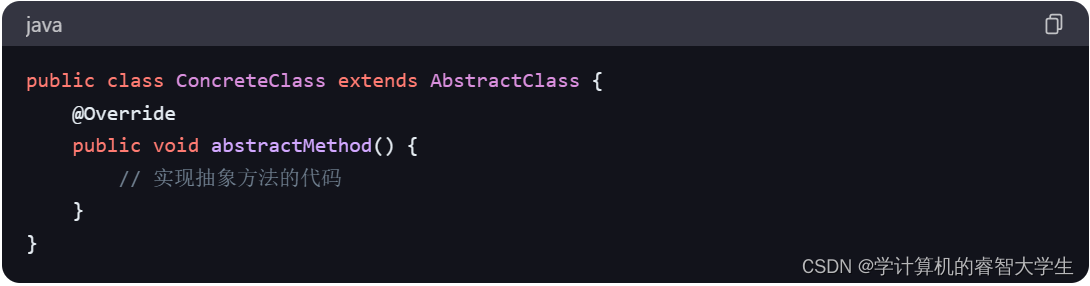
关键字:abstract关键字
在 Java 中,abstract是一个关键字,用于修饰类和方法。当一个类被声明为抽象类时,它不能被实例化,只能被其他类继承。同时,抽象类可以包含抽象方法,抽象方法没有方法体,只包含方法的签名…...
从PDF中提取图片
由于工作需要,要从pdf文件中提取出图片保存到本地,项目中就引用到了Apache PDFBox库。 1 什么是Apache PDFBox? Apache PDFBox库,一个用于处理PDF文档的开源Java工具。它允许用户创建全新的PDF文件,操作现有的PDF文档࿰…...

推荐:一个不错的介绍Apache Doris的PPT
原来Apache Doris居然是百度开源出来的,不错。部分节选:完整下载地址网盘: 链接: https://pan.baidu.com/s/18WR70R_f72GxCjh0lykStQ 提取码: umd3 复制这段内容后打开百度网盘手机App,操作更方便哦 --来自百度网盘超级会员v7的分…...
】进度对话框QProgressDialog类的基本用法)
【Python_PySide2学习笔记(二十二)】进度对话框QProgressDialog类的基本用法
进度对话框QProgressDialog类的基本用法 进度对话框QProgressDialog类的基本用法前言一、QProgressDialog 的常用方法1、创建进度对话框2、进度对话框设置窗口标题3、进度对话框隐藏"最大化"、"最小化"、"关闭"4、进度对话框设置是否自动关闭5、…...

使用rust读取usb设备ACR122U的nfc卡片id
rust及其高效和安全著称,而且支持跨平台,所以就想使用这个rust开发一个桌面端程序,来读取nfc设备的nfc卡片的id信息,下面就做一个最简单的入门教程吧,也是我写的第三个rust应用。 当你电脑上安装好了rust环境之后&…...

servlet总结
目录 1.生命周期 2.线程总结 3.配置 4.请求和响应 5.会话管理 6.过滤和监听器 7.处理表单数据 8.与JSP集成 9.异常处理 10.安全性和认证 Servlet是一种基于Java的Web组件,用于处理客户端请求并生成动态Web内容。以下是关于Servlet的一些总结 1.生命周期 …...
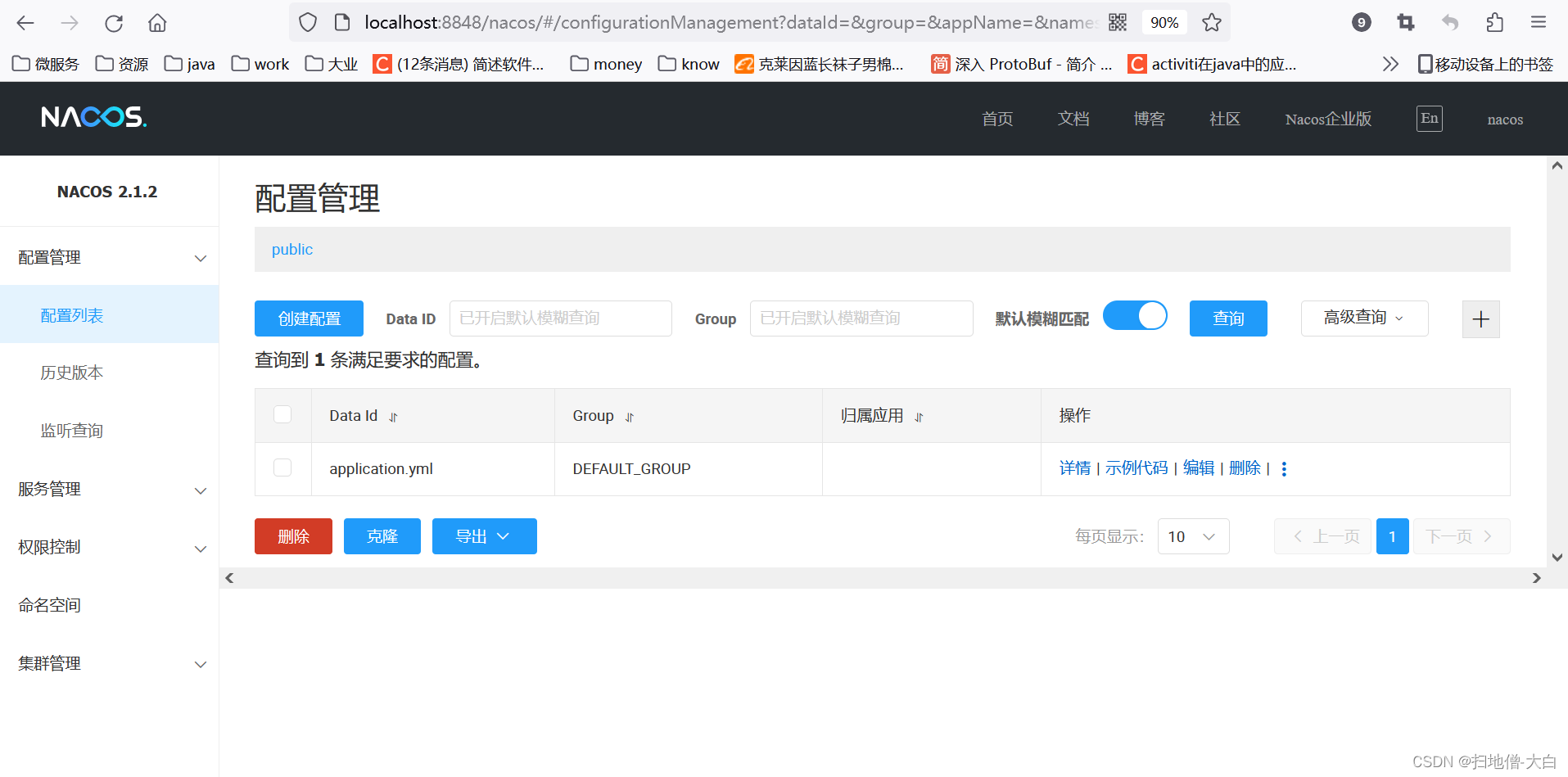
Nacos2.1.2改造适配达梦数据库7.0
出于业务需求,现将Nacos改造适配达梦数据库7.0,记录本次改造过程。 文章目录 一、前期准备二、适配流程1、项目初始化2、引入驱动3、源码修改 三、启动测试四、打包测试 一、前期准备 Nacos源码,版本:2.1.2:源码下载…...
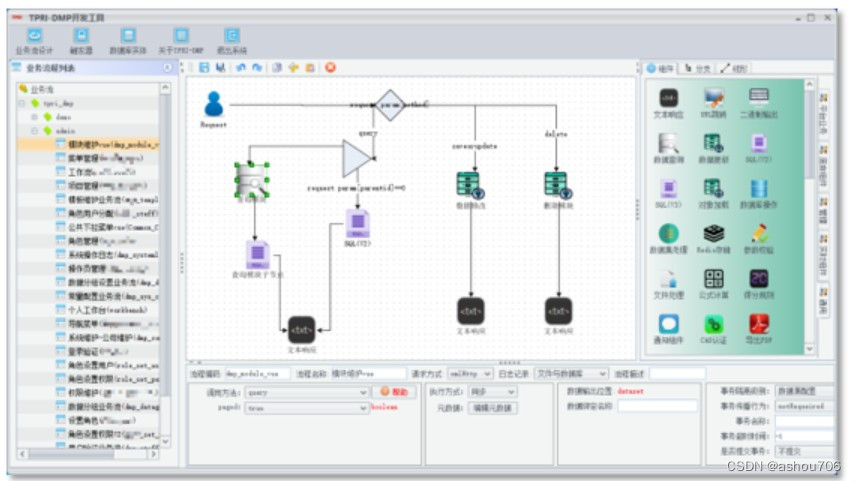
TPRI-DMP平台介绍
TPRI-DMP平台介绍 1 TPRI-DMP平台概述 TPRI-DMP为华能集团西安热工院自主产权的工业云PaaS平台,已经过13年的发展和迭代,其具备大规模能源电力行业生产应用软件开发和运行能力。提供TPRI-DMP平台主数据管理、业务系统开发与运行、应用资源管理…...
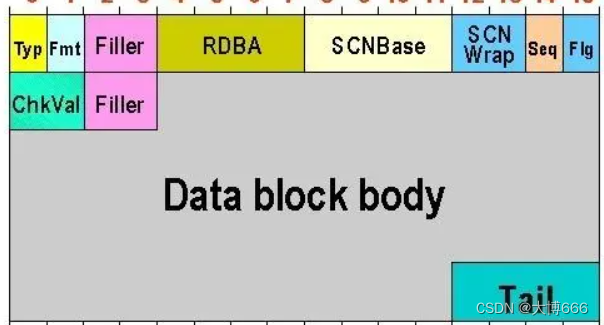
oracle-存储结构
文件包括 控制文件.ctl、数据文件.dbf、日志文件.log这三类放在存储上。 参数文件:空间的划分,进程的选用(.ora) oracle启动的时候需要读一下,数据库启动后,参数文件并不关闭,但即使文件丢了&a…...

获取PG库 database与 user 创建时间以及cluster初始化时间
代码实现 echo "获取数据库创建时间" data_dir$(psql -U postgres -d postgres -X -qAt -c "show data_directory" ) db_dirs$(ls $data_dir/base |grep -v pgsql_tmp) for db_oid in $db_dirs dodb_exists$(psql -U postgres -d postgres -X -qAt -c &qu…...

【12.29】转行小白历险记-刷算法05
242.有效的字母异位词 数组、set、map,数组是比较高效查找的 函数功能 判断字符串 s 和 t 是否互为字母异位词。如果它们包含相同的字符且每个字符出现的次数也相同,那么它们互为字母异位词。 代码逻辑 长度检查: if (s.length ! t.lengt…...
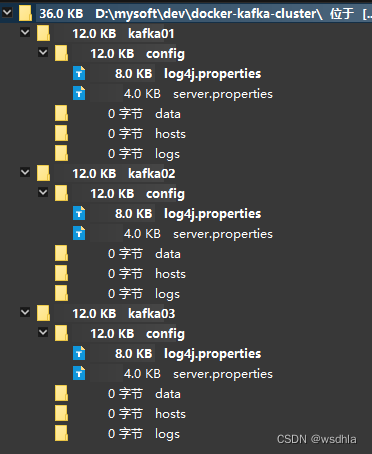
docker部署kafka zookeeper模式集群
单机模式链接:https://blog.csdn.net/wsdhla/article/details/133032238 kraft集群模式链接:部署Kafka_kafka 部署-CSDN博客 zookeeper选举机制举例: 目前有5台服务器,每台服务器均没有数据,它们的编号分别是1,2,3,4,5…...

Apache Flink连载(二十一):Flink On Yarn运行原理-Yarn Application模式
🏡 个人主页:IT贫道_大数据OLAP体系技术栈,Apache Doris,Clickhouse 技术-CSDN博客 🚩 私聊博主:加入大数据技术讨论群聊,获取更多大数据资料。 🔔 博主个人B栈地址:豹哥教你大数据的个人空间-豹哥教你大数据个人主页-哔哩哔哩视频 目录 1. 任务提交命令...
)
从原理图到PCB:手把手教你搞定PCIE X4接口的完整电路设计(附时钟、电源、热插拔信号详解)
从原理图到PCB:手把手教你搞定PCIE X4接口的完整电路设计 在高速数字电路设计中,PCIE接口因其出色的带宽和稳定性,已成为现代计算机系统中不可或缺的组成部分。无论是主板设计、显卡开发还是各类扩展卡,PCIE接口的正确实现直接关…...
)
保姆级教程:在Windows 10上搞定QGroundControl 4.2源码编译与打包(附VS+QT配置)
Windows 10下QGroundControl 4.2开发环境全栈搭建指南 第一次接触无人机地面站开发时,我被QGroundControl强大的功能所吸引,但配置开发环境的过程却让我踩了不少坑。从VS安装版本选择到QT组件配置,再到最后的打包发布,每个环节都可…...

Swift原生大语言模型推理引擎llmfarm_core.swift集成与优化指南
1. 项目概述:一个为Swift生态打造的本地大语言模型推理引擎 最近在折腾一个iOS上的AI应用,想把一些轻量级的开源大语言模型(LLM)直接跑在手机端。大家都知道,现在主流的LLM推理框架,像llama.cpp、ollama&am…...

别再死记硬背了!用这3个真实网络场景,彻底搞懂华为ACL的配置逻辑
华为ACL实战指南:3个典型场景解锁访问控制精髓 每次看到新手工程师面对ACL配置时一脸茫然的样子,我就想起自己当年在机房通宵排错的经历。访问控制列表(ACL)作为网络安全的"门禁系统",其重要性不言而喻&…...

macOS百度网盘SVIP破解完整指南:3步实现无限速下载
macOS百度网盘SVIP破解完整指南:3步实现无限速下载 【免费下载链接】BaiduNetdiskPlugin-macOS For macOS.百度网盘 破解SVIP、下载速度限制~ 项目地址: https://gitcode.com/gh_mirrors/ba/BaiduNetdiskPlugin-macOS 还在为百度网盘的龟速下载而烦恼吗&…...
)
IMU数据处理(卡尔曼滤波+四元数计算欧拉角一条龙服务)
先给你最终标准答案(直接照做就行) 结论 必须:寄存器读出来的原始16位 raw 数据 → 先卡尔曼/均值滤波 → 再换算单位转成 g、rad/s 为什么不能先转单位再滤波? 寄存器原始值是整数整型,噪声是均匀高斯噪声,…...

终极天气API开发指南:从数据获取到可视化展示的完整流程
终极天气API开发指南:从数据获取到可视化展示的完整流程 【免费下载链接】Awesome_APIs :octocat: A collection of APIs 项目地址: https://gitcode.com/gh_mirrors/aw/Awesome_APIs 天气API是现代应用开发中不可或缺的组件,能够为用户提供实时天…...

告别AT指令!用nRF52832的BLE NUS服务,5分钟搞定手机与开发板的双向通信
用nRF52832的BLE NUS服务实现高效蓝牙串口通信 在嵌入式开发中,设备与移动端的双向通信一直是个痛点。传统AT指令虽然简单,但效率低下、扩展性差,每次通信都需要复杂的握手流程。而基于nRF52832的BLE NUS(Nordic UART Service&…...

WarcraftHelper完整指南:5分钟让魔兽争霸3在现代电脑上完美运行
WarcraftHelper完整指南:5分钟让魔兽争霸3在现代电脑上完美运行 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为魔兽争霸3在现代Win…...

零基础避坑指南什么工具可以录音转待办
还在手动把面试录音扒成文字再摘待办?做HR的谁没踩过这个坑:整理一小时,漏了候选人关键信息,还把待办记错,今天直接讲能直接上手的方法,零基础也不会踩坑。我做HR那几年,光整理录音待办就熬了无…...